
Curso
Projetando Sistemas Agentes com LangChain
3 h
12.1K
Executar um modelo com um trilhão de parâmetros como o Kimi K2.5 normalmente requer um enorme cluster multi-GPU e um orçamento de infraestrutura compatível, muitas vezes excedendo US$ 40/hora. Mas, com as ferramentas certas de otimização, você pode usar esse modelo supermoderno sem gastar muito.
Neste tutorial, vou mostrar como rodar o Kimi K2.5 localmente usando uma única GPU NVIDIA H200 no RunPod. Ao usar o llama.cpp para fazer inferências de forma eficiente e conectá-lo à CLI do Kimi, você pode evitar infraestruturas empresariais complicadas e começar a criar softwares de alto nível rapidinho.
Kimi K2.5 é um modelo de linguagem aberto e super avançado, feito pra raciocínio avançado, programação e geração de texto de alta qualidade. Desenvolvido pela Moonshot AI, é um modelo com trilhões de parâmetros feito pra raciocínio avançado, geração de código de alta qualidade e tarefas de escrita geral complexas.
Na prática, parece estar no mesmo nível do Claude Opus 4.5 para muitos fluxos de trabalho, especialmente programação, raciocínio estruturado e geração de textos longos.
Uma das maiores vantagens do Kimi K2.5 é que ele é totalmente open source. Isso quer dizer que qualquer pessoa pode baixar os pesos e rodar o modelo por conta própria, sem precisar depender de APIs pagas ou plataformas fechadas. A desvantagem, claro, é a escala.
Esta seção explica os requisitos de hardware, memória e GPU necessários para rodar o Kimi K2.5 localmente, incluindo o desempenho esperado em uma única GPU H200.
Espaço em disco
Memória (RAM + VRAM)
Requisitos da GPU
Drivers de GPU e CUDA
Agora vamos configurar um pod de GPU no RunPod e prepará-lo para rodar o Kimi K2.5.
Comece criando um novo pod no RunPod e selecionando a GPU NVIDIA H200. Para a imagem do contêiner, escolha omodelo PyTorch mais recente do , pois ele já inclui a maioria das dependências CUDA e de aprendizado profundo de que precisamos. Depois de escolher o modelo, clique em“Editar” ( ) para ajustar as configurações padrão do pod.
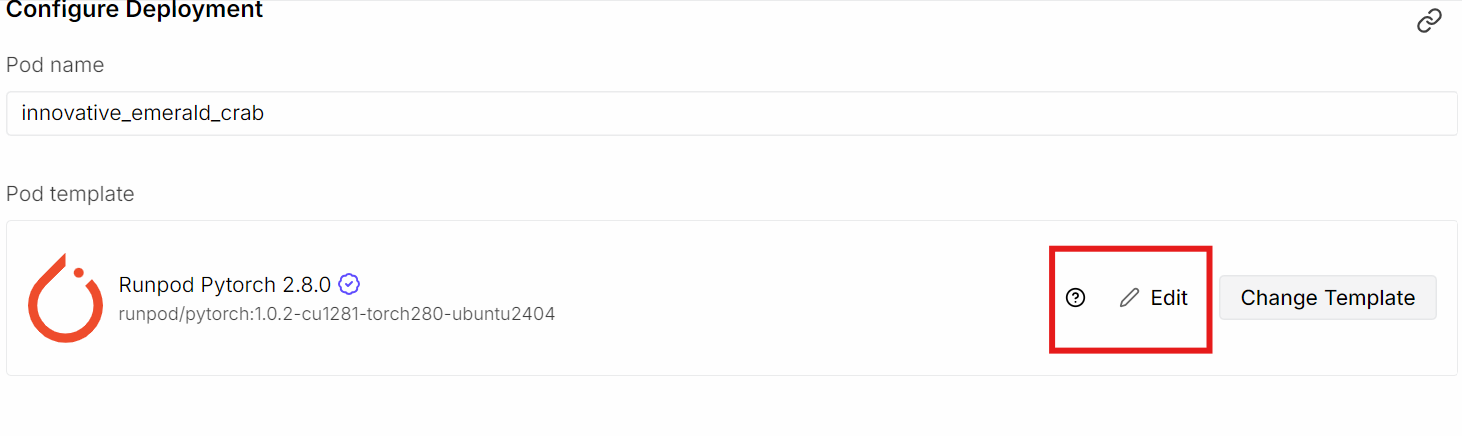
Atualize a configuração de armazenamento assim:
Depois, abra uma porta extra:
A gente expõe a porta 8080 pra poder acessar o servidor llama.cpp e a interface do usuário da Web direto do navegador, seja localmente ou remotamente, assim que o servidor estiver funcionando.
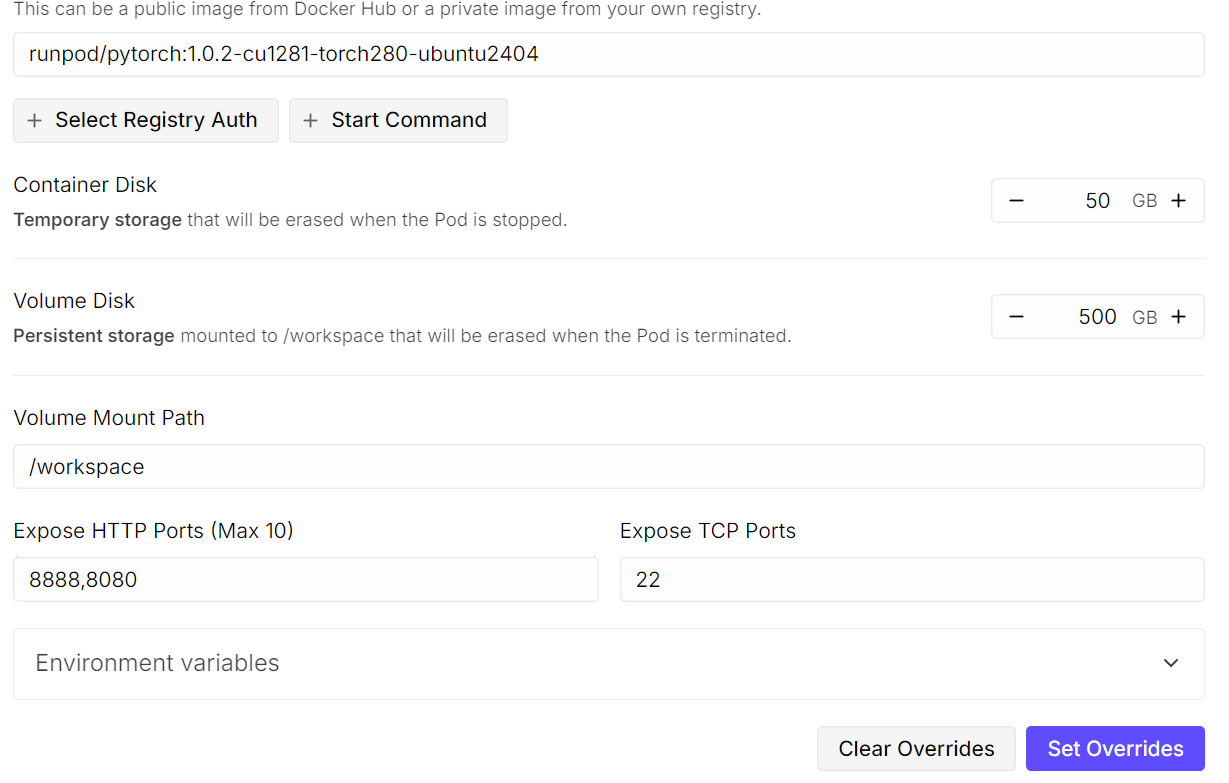
Depois de salvar essas configurações, implante o pod. Mesmo com uma única GPU, rodar um modelo como o Kimi K2.5 é caro, mas o RunPod oferece opções bem mais econômicas do que os provedores de nuvem tradicionais.
Quando o pod estiver pronto, abra a interface do Jupyter Lab. No Jupyter Lab, abra uma sessão do Terminal.
Usar o terminal dentro do Jupyter é prático porque você pode abrir várias sessões de terminal instantaneamente sem precisar gerenciar conexões SSH separadas.
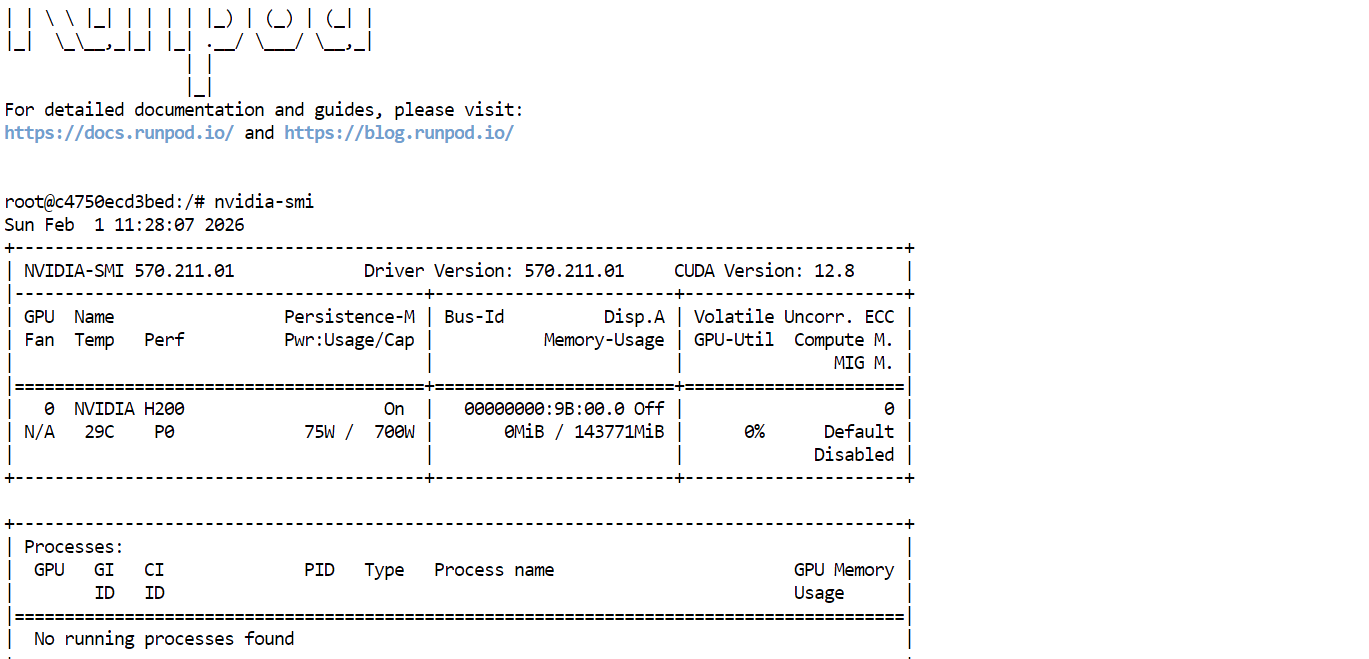
Primeiro, dá uma olhada se os drivers da GPU e o CUDA estão instalados direitinho, executando:
nvidia-smiSe tudo estiver configurado corretamente, você deverá ver a GPU H200 listada com aproximadamente 144 GB de VRAM disponível.
Depois, instale os pacotes Linux necessários para compilar o llama.cpp a partir do código-fonte:
sudo apt-get update
sudo apt-get install -y build-essential cmake curl git libcurl4-openssl-devAgora vamos compilar o llama.cpp a partir do código-fonte, porque é rápido, leve e nos dá o melhor desempenho na GPU H200.
llama.cpp é um mecanismo de inferência C e C++ de código aberto feito pra rodar modelos de linguagem grandes. Ele inclui um servidor HTTP integrado chamado llama-server, que oferece pontos finais REST e uma interface de usuário da Web para interagir com o modelo a partir do seu navegador.
Ele também suporta kernels CUDA personalizados e inferência híbrida de CPU e GPU, o que ajuda quando os modelos não cabem totalmente na VRAM.
Primeiro, clona o repositório oficial llama.cpp:
git clone https://github.com/ggml-org/llama.cppDepois, configura a compilação com o suporte CUDA ativado. A gente tá falando da arquitetura CUDA 90, que é necessária pra GPUs NVIDIA H200:
cmake /workspace/llama.cpp -B /workspace/llama.cpp/build \
-DGGML_CUDA=ON \
-DBUILD_SHARED_LIBS=OFF \
-DCMAKE_CUDA_ARCHITECTURES=90Agora, compile o binário do lama-server. Esse servidor vai ser usado depois para rodar o Kimi K2.5 e mostrar um endpoint HTTP e uma interface de usuário web:
cmake --build /workspace/llama.cpp/build -j --clean-first --target llama-serverQuando a compilação terminar, copie o binário para um lugar que seja fácil de encontrar:
cp /workspace/llama.cpp/build/bin/llama-server /workspace/llama.cpp/llama-serverPor fim, veja se o binário tá aí e foi compilado direitinho:
ls -la /workspace/llama.cpp | sed -n '1,60p'Agora vamos baixar o modelo Kimi K2.5 GGUF do Hugging Face usando o Xet, que faz downloads bem mais rápidos de arquivos grandes de modelos.
Primeiro, instale as ferramentas de transferência Hugging Face e Xet necessárias:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferAtive o backend de transferência de alta velocidade:
export HF_HUB_ENABLE_HF_TRANSFER=1Depois, baixa o modelo quantizado de 1,8 bits (UD-TQ1_0) do Hugging Face e guarda-o localmente.
Usamos essa quantificação porque ela oferece o melhor equilíbrio entre a qualidade do modelo e a viabilidade do hardware, permitindo que o Kimi K2.5 seja executado em uma única GPU H200, transferindo parte do modelo para a RAM do sistema e, ao mesmo tempo, mantendo uma velocidade de inferência utilizável.
hf download unsloth/Kimi-K2.5-GGUF \
--local-dir /workspace/models/Kimi-K2.5-GGUF \
--include "UD-TQ1_0/*"Mesmo sem fazer login usando um token de acesso do Hugging Face, você deve ver velocidades de download de 800 MB por segundo ou mais no RunPod.

No nosso caso, o download completo ficou pronto em cerca de 6 minutos. O tempo real de download pode variar dependendo da largura de banda da rede e do desempenho do disco.

Agora que o modelo foi baixado e o llama.cpp foi compilado com suporte a CUDA, podemos iniciar o Kimi K2.5 localmente usando o servidor HTTP llama.cpp.
Execute o seguinte comando para iniciar o llama-server:
/workspace/llama.cpp/llama-server \
--model "/workspace/models/Kimi-K2.5-GGUF/UD-TQ1_0/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf" \
--alias "Kimi-K2.5" \
--host 0.0.0.0 \
--port 8080 \
--threads 32 \
--threads-batch 32 \
--ctx-size 20000\
--temp 0.8 \
--top-p 0.95 \
--min_p 0.01 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024\
--ubatch-size 256O que cada argumento faz:
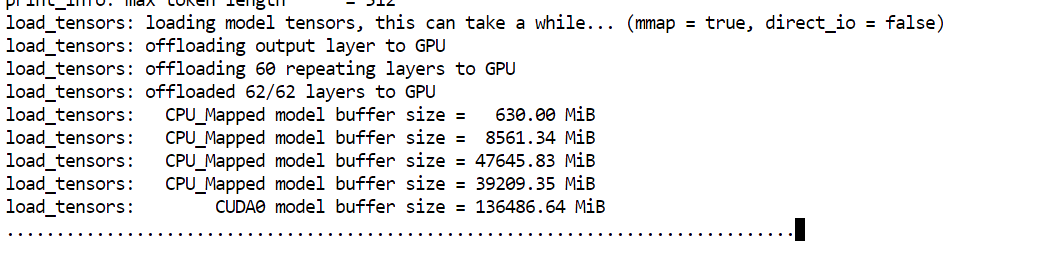
--model: Caminho para o arquivo do modelo GGUF a ser carregado--alias: Nome amigável usado para identificar o modelo no servidor e na interface do usuário--host: Interface de rede à qual o servidor deve se conectar (0.0.0.0 permite acesso externo)--port: Porta HTTP usada para expor o servidor llama.cpp e a interface do usuário da Web--threads: Número de threads da CPU usados para inferência e pré-processamento--threads-batch: Threads da CPU usados para processamento rápido em lote--ctx-size: Janela de contexto janela de contexto em tokens--temp: Controla a aleatoriedade da saída gerada--top-p: Limite de amostragem do núcleo para seleção de tokens--min_p: Filtra tokens com probabilidade muito baixa--fit: Equilibra automaticamente os pesos do modelo entre a VRAM e a RAM do sistema.--prio: Define uma prioridade de processo mais alta para cargas de trabalho de inferência--jinja: Permite a criação de modelos de prompt baseados em Jinja--flash-attn: Ativa atenção instantânea quando compatível com a GPU--batch-size: Número de tokens processados por lote de GPU--ubatch-size: Tamanho do micro-lote para equilibrar o uso da memória e a taxa de transferênciaDurante a inicialização, você vai ver o modelo carregar cerca de 136 GB na memória da GPU, com os pesos restantes descarregados na RAM do sistema.
Observação: Se o servidor llama.cpp não detectar a GPU e iniciar na CPU, reinicie o pod. Se o problema continuar, dá uma olhada na compilação atual e tenta compilar o llama.cpp de novo com o suporte CUDA ativado.
Quando o carregamento terminar, o servidor vai mostrar um URL de acesso. Abra a interface do usuário da Web no seu navegador em:
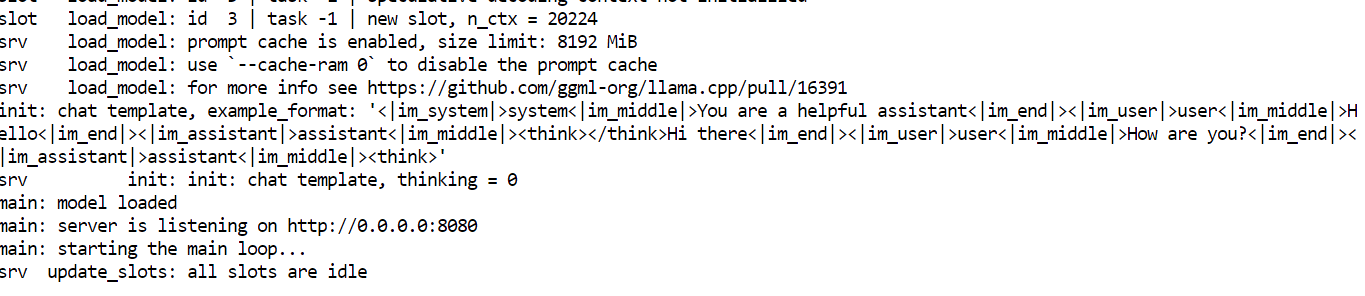
Observação: Se você vir um erro ao rodar nvidia-smi, o processo provavelmente travou por causa da pressão na memória. Reinicie o pod. Todos os arquivos de modelo ficam no disco persistente.
Quando o servidor llama.cpp estiver funcionando, você pode acessá-lo pela interface do usuário da Web na porta 8080.
Para abrir, vá até o painel do RunPod, escolha o seu pod em execução e clique no link que aparece ao lado da porta 8080. Isso abre a interface do usuário da Web llama.cpp diretamente no seu navegador.
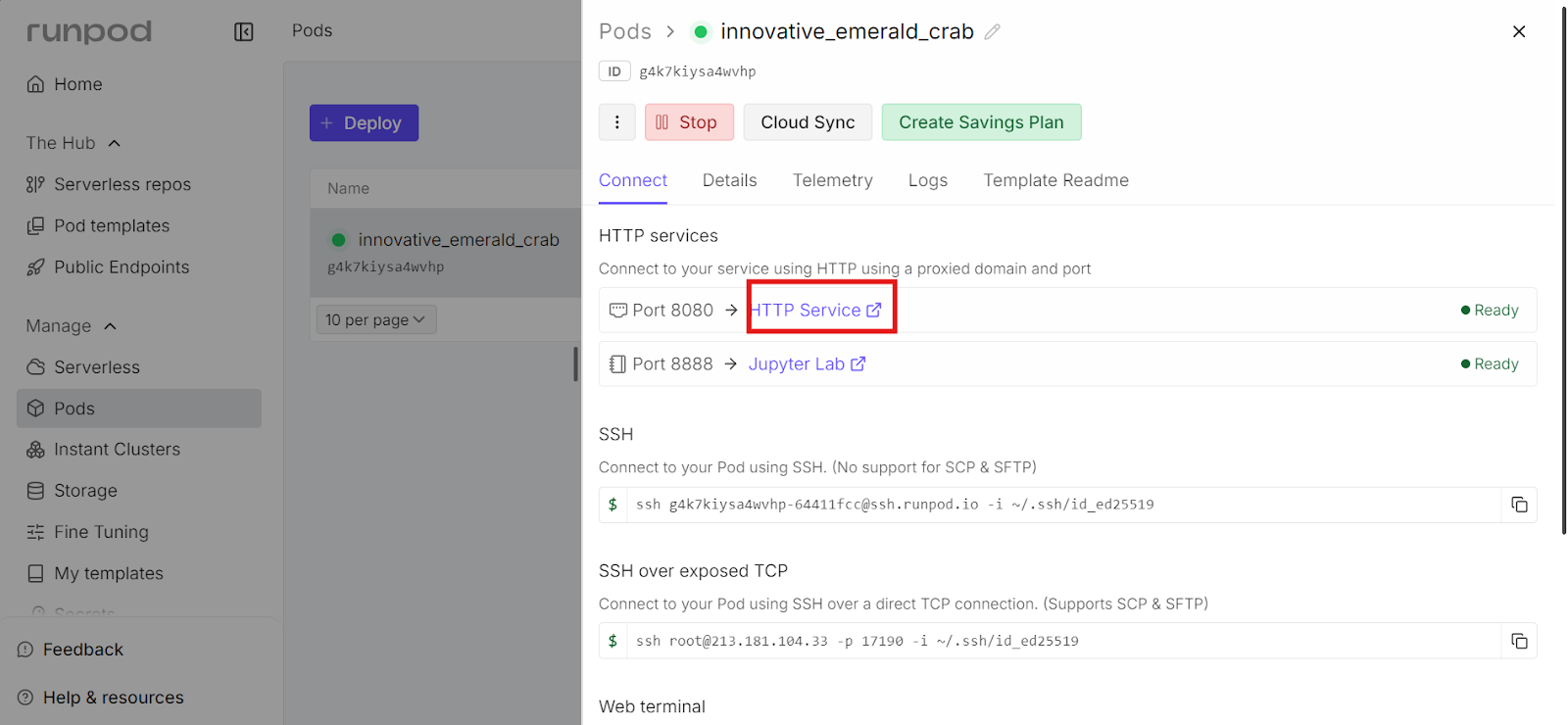
A interface do usuário da Web oferece uma interface simples no estilo chat, parecida com o chatGPT, mas rodando totalmente na sua própria instância do RunPod. A URL está disponível para todo mundo. Você pode compartilhar esse link com colegas de equipe ou colaboradores, se precisar.
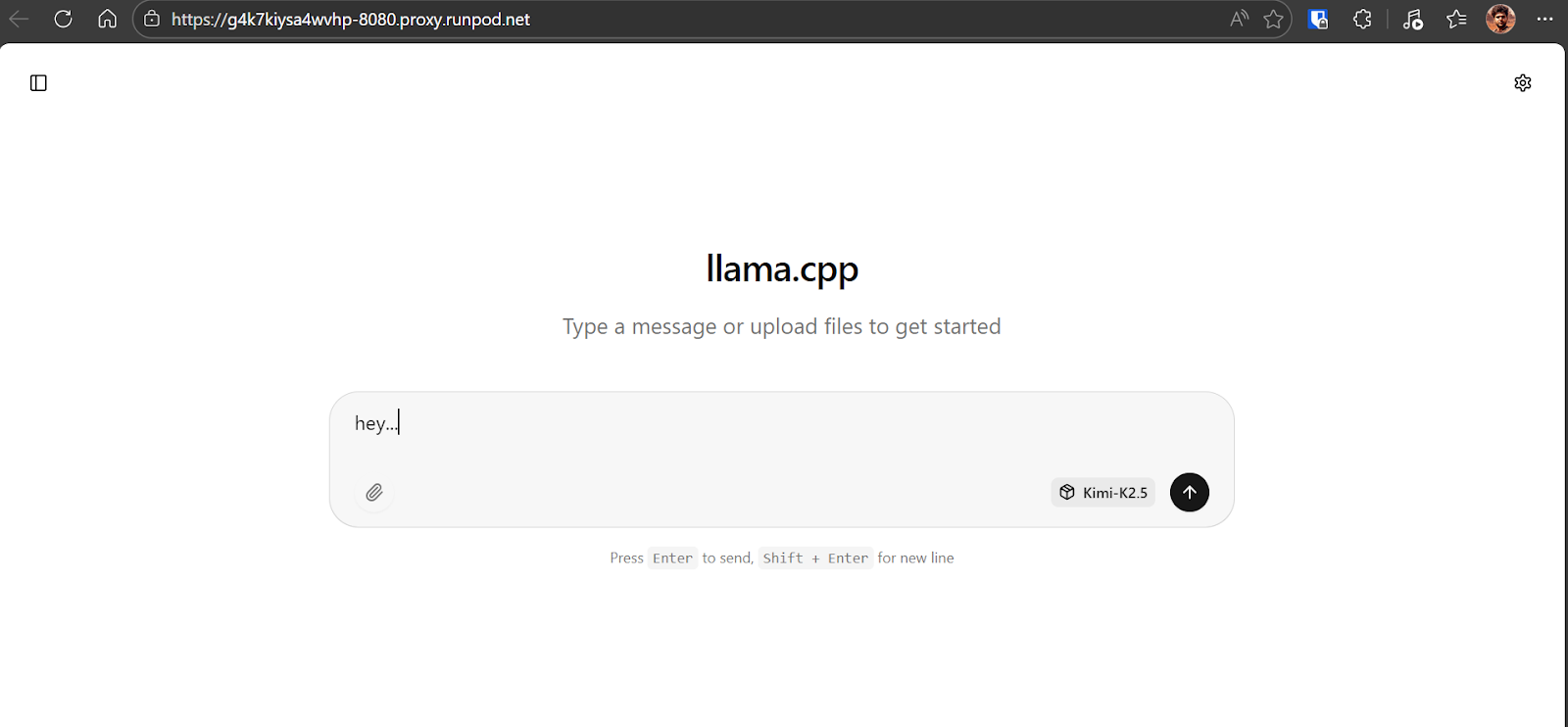
Comece enviando um comando simples para o modelo Kimi K2.5 para verificar se tudo está funcionando corretamente. No nosso caso, o modelo responde a cerca de 6 a 7 tokens por segundo, o que é esperado para a quantização de 1,8 bits rodando em uma única GPU H200 com descarregamento parcial da RAM. Essa é uma base sólida e confirma que o modelo está usando a GPU da maneira certa.
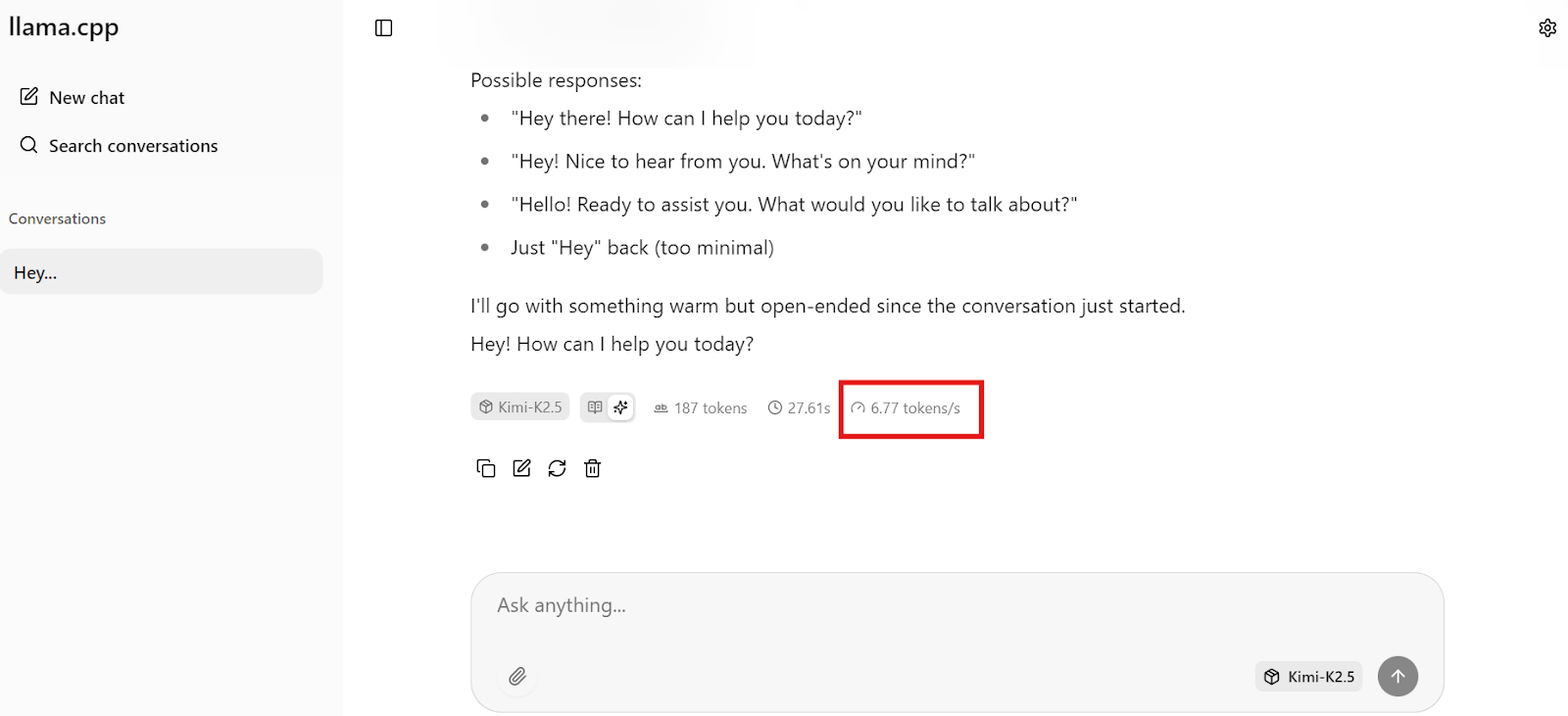
Observação: A interface do usuário da Web llama.cpp não separa claramente o raciocínio da saída final, então você pode ver os dois misturados por causa de problemas com o modelo.
Kimi CLI é um agente de codificação e raciocínio baseado em terminal desenvolvido pela Moonshot AI. Ele foi feito pra ajudar nas tarefas de codificação, fluxos de trabalho do shell e mudanças no nível do projeto direto da sua linha de comando. Diferente de uma interface de chat simples, o Kimi CLI pode funcionar dentro do seu diretório de trabalho, o que o torna ideal para fluxos de trabalho de desenvolvimento reais.
Para inferência local, a principal vantagem do Kimi CLI é que ele suporta APIs compatíveis com OpenAI. Isso permite que a gente aponte diretamente para o nosso llama-server rodando localmente, fazendo com que o Kimi K2.5 funcione totalmente no nosso próprio hardware, sem depender de nenhum serviço de API hospedado ou pago.
Comece executando o script de instalação oficial:
curl -LsSf https://code.kimi.com/install.sh | bashDepois, coloca o binário no teu PATH pra que o comando kimi esteja disponível no seu terminal:
export PATH="/root/.local/bin:$PATH"Confirme se a instalação deu certo:
kimi --versionVocê deve ver uma saída parecida com kimi, version 1.5.
Crie o diretório de configuração usado pelo Kimi CLI:
mkdir -p ~/.kimiAgora, crie o arquivo de configuração. Isso diz ao Kimi CLI para tratar seuservidor local llama.cpp como um provedor compatível com OpenAI rodando em http://127.0.0.1:8080/v1. Ele também registra uma entrada de modelo local que combina com o alias que você especificou ao iniciar o llama-server.
cat << 'EOF' > ~/.kimi/config.toml
[providers.local_llama]
type = "openai_legacy"
base_url = "http://127.0.0.1:8080/v1"
api_key = "sk-no-key-required"
[models.kimi_k25_local]
provider = "local_llama"
model = "Kimi-K2.5"
max_context_size = 20000
EOFCertifique-se de que o valor de model corresponda exatamente ao --alias usado ao iniciar llama-server. O campo “ api_key ” é um espaço reservado e não é necessário para a inferência local.
Nesta seção, vamos usar o Kimi CLI conectado ao nosso servidor Kimi K2.5 local para criar um jogo Snake totalmente jogável usando a codificação vibe.
Primeiro, crie um novo diretório de projeto e entre nele:
mkdir -p /workspace/snake-game
cd /workspace/snake-gameDepois, abra o Kimi CLI:
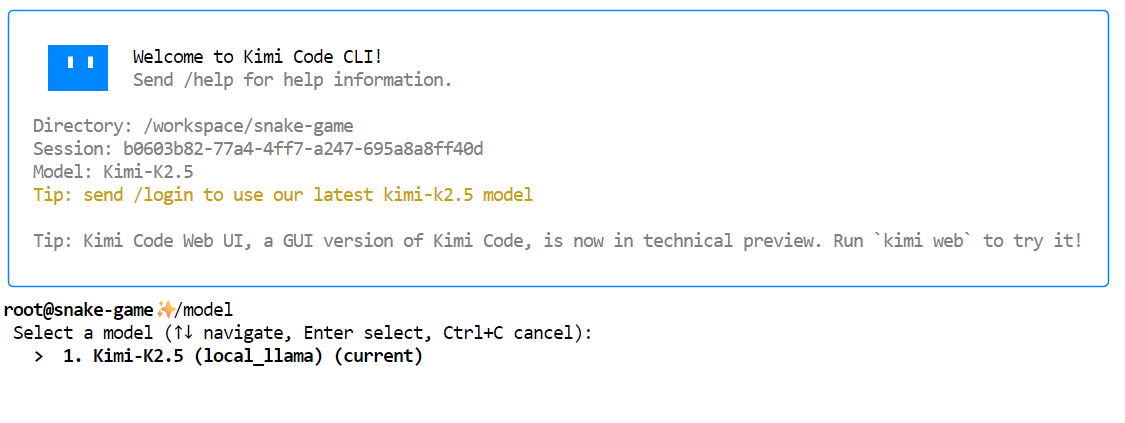
kimiAssim que o Kimi CLI começar, digite /model e escolha o modelo local Kimi K2.5 que a gente configurou antes. Você deve vero Kimi-K2.5 listado como um modelo disponível.
 Agora, peça ao Kimi para gerar o jogo. Use uma instrução simples e direta como esta:
Agora, peça ao Kimi para gerar o jogo. Use uma instrução simples e direta como esta:
"Create a simple Snake game as a single self-contained file named index.html."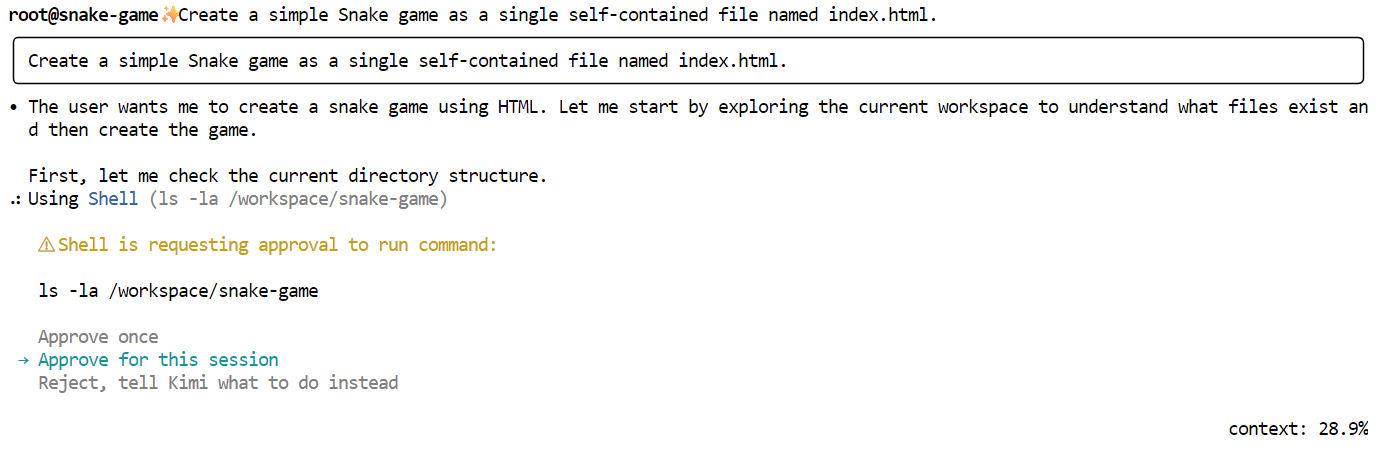
Kimi vai primeiro apresentar um plano e pedir a sua aprovação. Dá uma olhada e aprova o pedido.

Depois de aprovado, o Kimi vai criar o arquivo completo index.html, incluindo HTML, CSS e JavaScript, tudo num só lugar.
Depois que o arquivo estiver pronto, baixa ou copia ele no seu computador e abre no seu navegador. O jogo começa na hora.
O resultado é um jogo Snake totalmente funcional, com movimentos suaves, visuais limpos e recursos clássicos de jogabilidade.
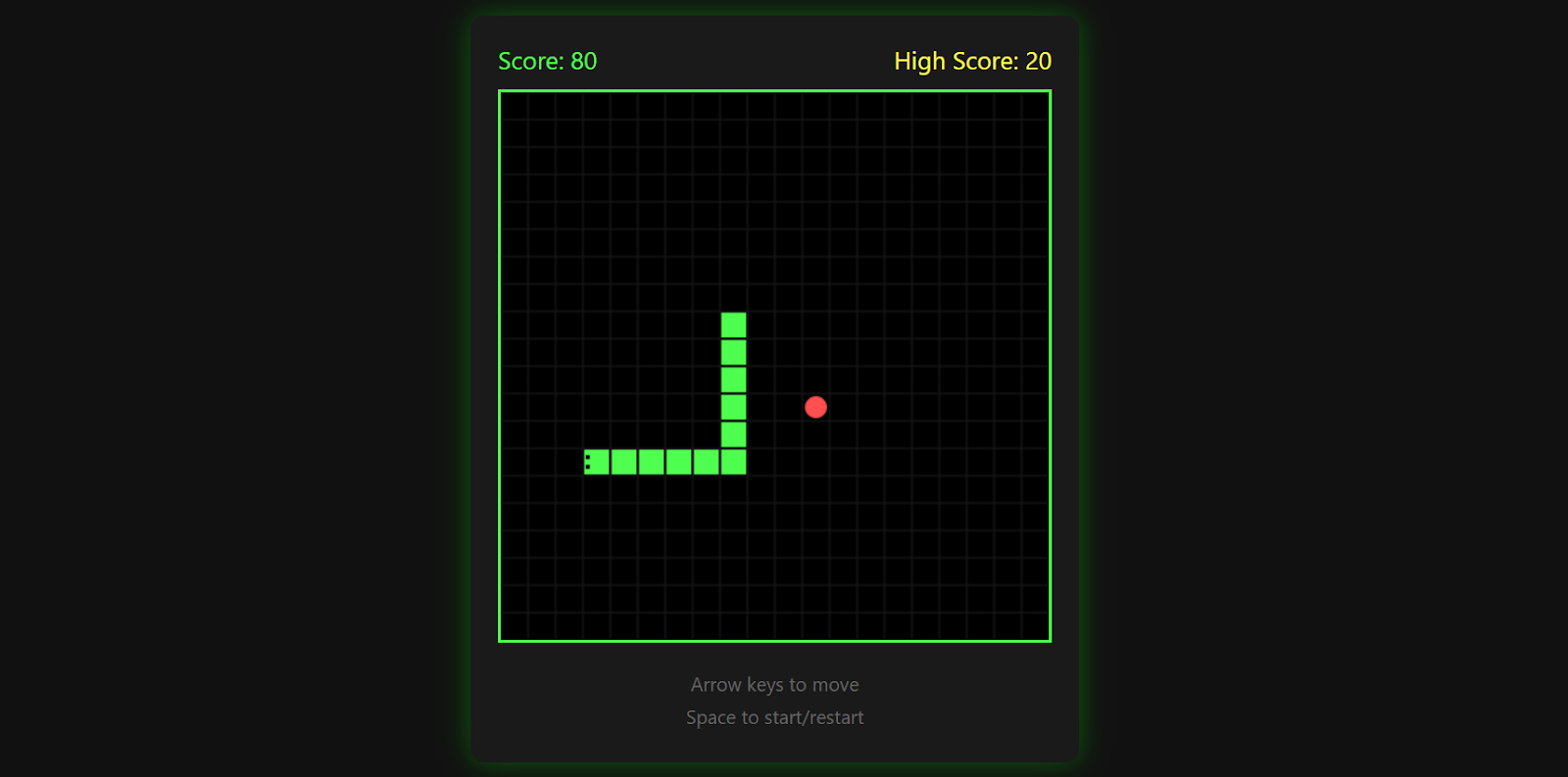
O jogo registra sua pontuação mais alta, termina quando você bate em uma parede e permite que você reinicie pressionando a barra de espaço novamente.
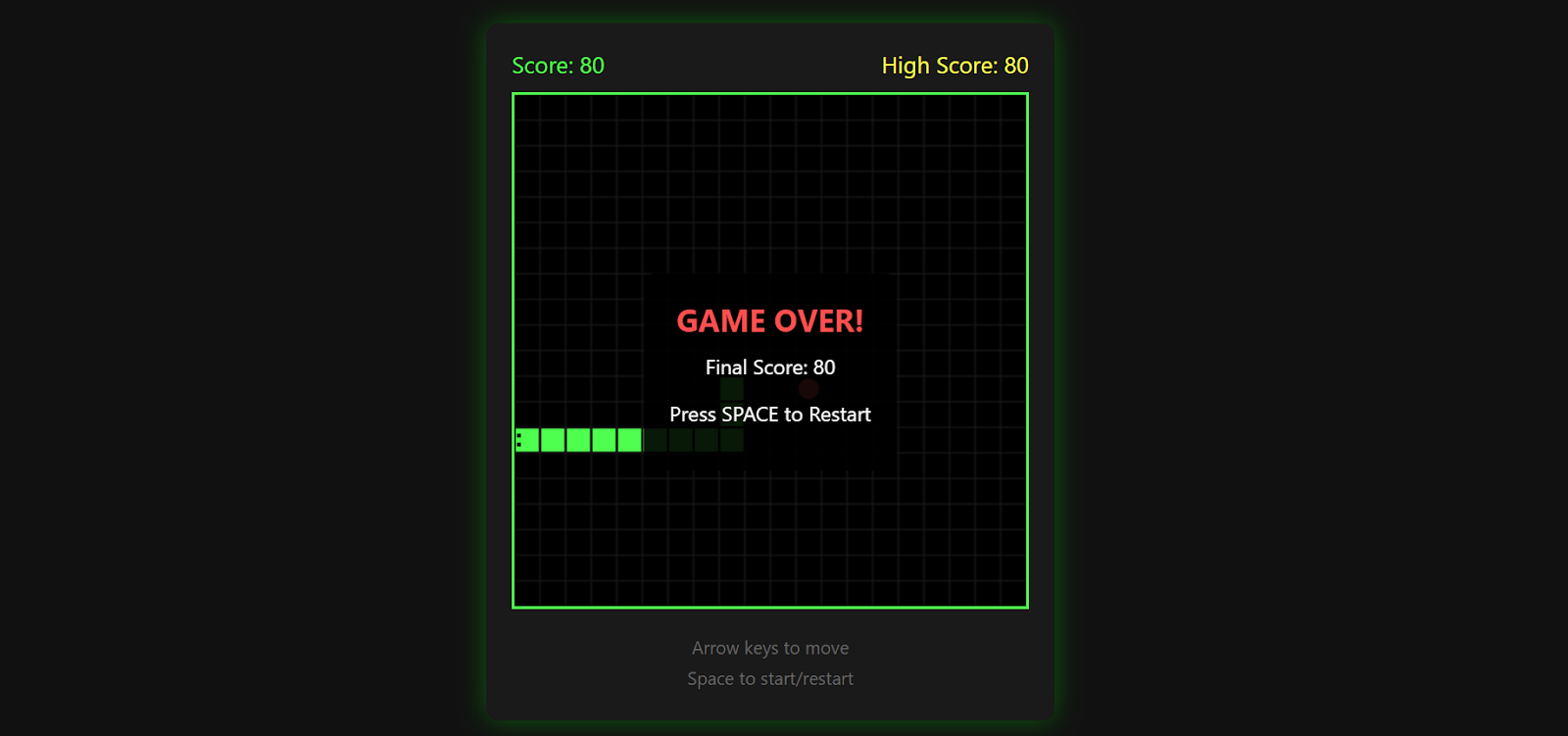
É surpreendentemente refinado para um único prompt e uma ótima demonstração do que o Kimi K2.5 pode gerar quando combinado com o Kimi CLI e uma configuração de inferência local.
Pra ser sincero, achei que criar um jogo totalmente funcional em uma única tentativa foi mais frustrante do que esperava.
Embora o Kimi K2.5 seja claramente capaz, o modelo muitas vezes tem dificuldade em decidir quando parar de iterar uma tarefa. Na prática, isso acaba complicando demais o problema.
Por exemplo, quando pedem pra criar um jogo Snake no Pygame, ele pode voltar pra uma implementação HTML, e quando pedem HTML, ele pode voltar pra uma abordagem baseada em Python.
Essa alternância significa que muitas vezes você precisa intervir várias vezes para manter o modelo alinhado com sua intenção.
Grande parte desse comportamento vem da quantização de 1,8 bits. Embora os modos de 1 bit e sub-2 bits permitam executar um modelo extremamente grande em hardware limitado, eles têm suas desvantagens.
O modelo ainda consegue dar respostas coerentes, mas tem mais dificuldade com encerramento de tarefas, raciocínio de longo prazo, planejamento estruturado e chamada de funções. Essas são exatamente as áreas mais importantes para fluxos de trabalho do tipo agente e tarefas de codificação em várias etapas.
Na real, o Kimi K2.5 começa a se destacar em precisões mais altas, tipo 4 bits ou mais. Nesse nível, o planejamento melhora bastante e o modelo fica mais previsível.
A desvantagem é óbvia. Uma precisão maior precisa de muito mais RAM e VRAM, o que deixa isso fora do alcance de muitas configurações locais. Do ponto de vista do tamanho em relação ao desempenho em baixa precisão, modelos como o GLM 4.7 oferecem atualmente uma experiência mais suave para muitos usuários.
Dito isso, se você ignorar as limitações de hardware e rodar o Kimi K2.5 com maior precisão ou por meio de uma API hospedada, o modelo é realmente impressionante. A profundidade do seu raciocínio, a qualidade da geração de código e o tratamento de contextos longos são tão bons que ele pode substituir modelos proprietários em muitos fluxos de trabalho.
Na verdade, quando usada por meio da API Kimi AI, ela é boa o suficiente pra justificar a mudança de todo o fluxo de trabalho de codificação de vibração pra ela.
Pra continuar aprendendo mais sobre os conceitos que falamos aqui, recomendo esses recursos:
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial



