
Kurs
Agentische Systeme mit LangChain entwerfen
3 Std.
12.1K
Um ein Modell mit einer Billion Parametern wie Kimi K2.5 zu betreiben, braucht man normalerweise einen riesigen Multi-GPU-Cluster und ein entsprechendes Budget für die Infrastruktur, das oft über 40 Dollar pro Stunde liegt. Mit den richtigen Optimierungstools kannst du dieses hochmoderne Modell aber nutzen, ohne dein Budget zu sprengen.
In diesem Tutorial zeige ich dir, wie du Kimi K2.5 lokal mit einer einzelnen NVIDIA H200 GPU auf RunPod laufen lassen kannst. Durch die Nutzung von llama.cpp für effiziente Inferenz und die Verbindung mit der Kimi-CLI kannst du komplexe Unternehmensinfrastrukturen umgehen und sofort mit der Entwicklung hochwertiger Software beginnen.
Kimi K2.5 ist ein topaktuelles Open-Source-Sprachmodell, das für anspruchsvolles Denken, Programmieren und hochwertige Textgenerierung entwickelt wurde. Entwickelt von Moonshot AI, ist es ein Modell mit einer Billion Parametern, das für fortgeschrittenes Denken, hochwertige Codegenerierung und anspruchsvolle allgemeine Schreibaufgaben entwickelt wurde.
In der Praxis fühlt es sich bei vielen Arbeitsabläufen, vor allem beim Programmieren, beim strukturierten Denken und beim Erstellen langer Texte, genauso gut an wie Claude Opus 4.5.
Einer der größten Vorteile von Kimi K2.5 ist, dass es komplett Open Source ist. Das heißt, jeder kann die Gewichte runterladen und das Modell selbst ausprobieren, ohne auf kostenpflichtige APIs oder geschlossene Plattformen angewiesen zu sein. Der Kompromiss ist natürlich die Größe.
Hier geht's um die Hardware, den Speicher und die GPU, die du brauchst, um Kimi K2.5 lokal zu nutzen, und wie die Leistung auf einer einzelnen H200-GPU so ungefähr aussieht.
Festplattenspeicher
Speicher (RAM + VRAM)
GPU-Anforderungen
GPU-Treiber und CUDA
Wir richten jetzt einen GPU-Pod auf RunPod ein und machen ihn bereit für die Ausführung von Kimi K2.5.
Mach mal so: Erstell erst mal einen neuen Pod in RunPod und wähl die NVIDIA H200 GPUaus . Für das Container-Image nimmst du am besten dieneueste PyTorch-Vorlage „ “, weil sie schon die meisten CUDA- und Deep-Learning-Abhängigkeiten hat, die wir brauchen. Nachdem du die Vorlage ausgewählt hast, klick auf„ “ und dann auf „Edit“, um die Standardeinstellungen des Pods anzupassen.
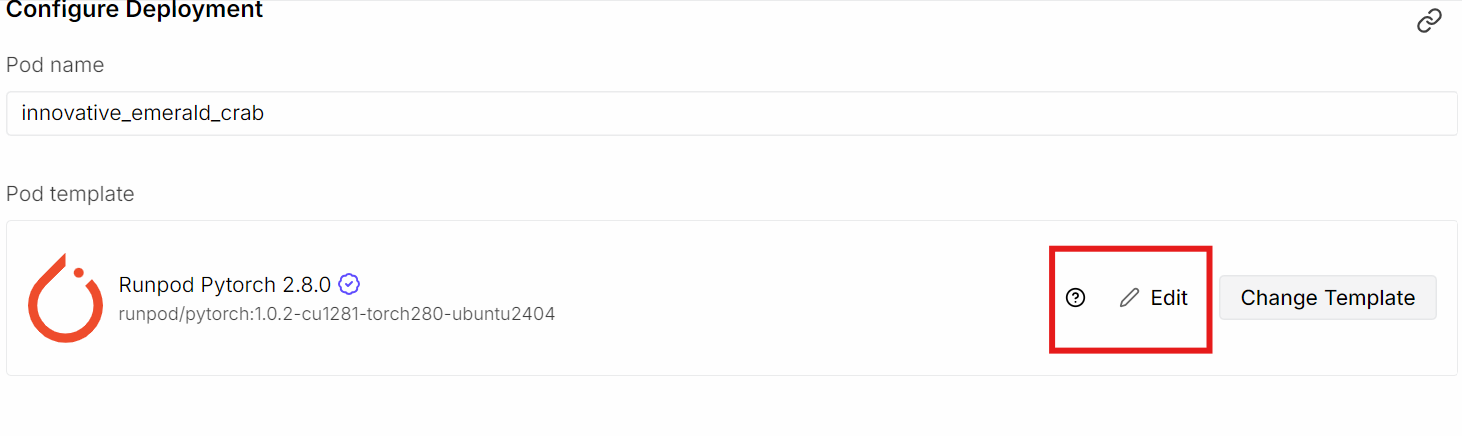
Aktualisiere die Speicherkonfiguration wie folgt:
Als Nächstes machst du einen weiteren Port zugänglich:
Wir machen Port 8080 zugänglich, damit wir direkt über den Browser auf den Server llama.cpp und die Web-Benutzeroberfläche zugreifen können, egal ob lokal oder aus der Ferne, sobald der Server läuft.
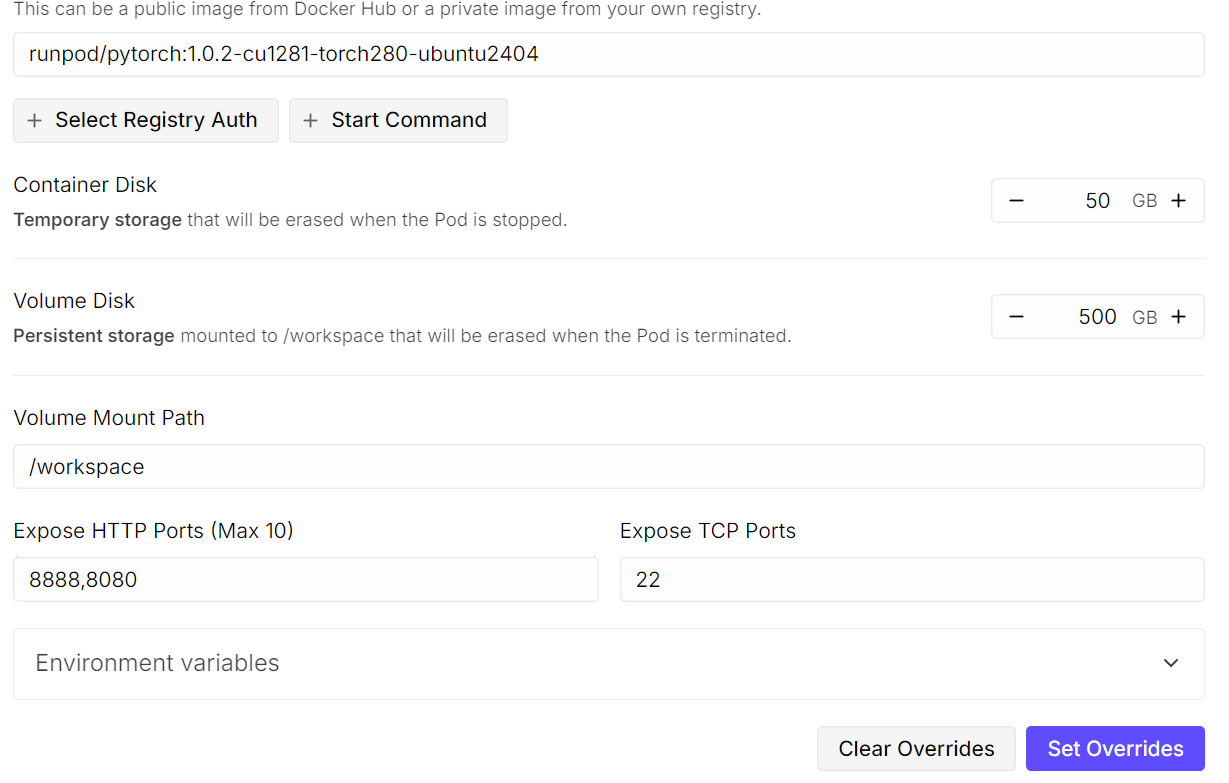
Speicher einfach diese Einstellungen und starte dann den Pod. Selbst mit einer einzigen GPU ist die Ausführung eines Modells wie Kimi K2.5 teuer, aber RunPod bietet im Vergleich zu herkömmlichen Cloud-Anbietern deutlich kostengünstigere Optionen.
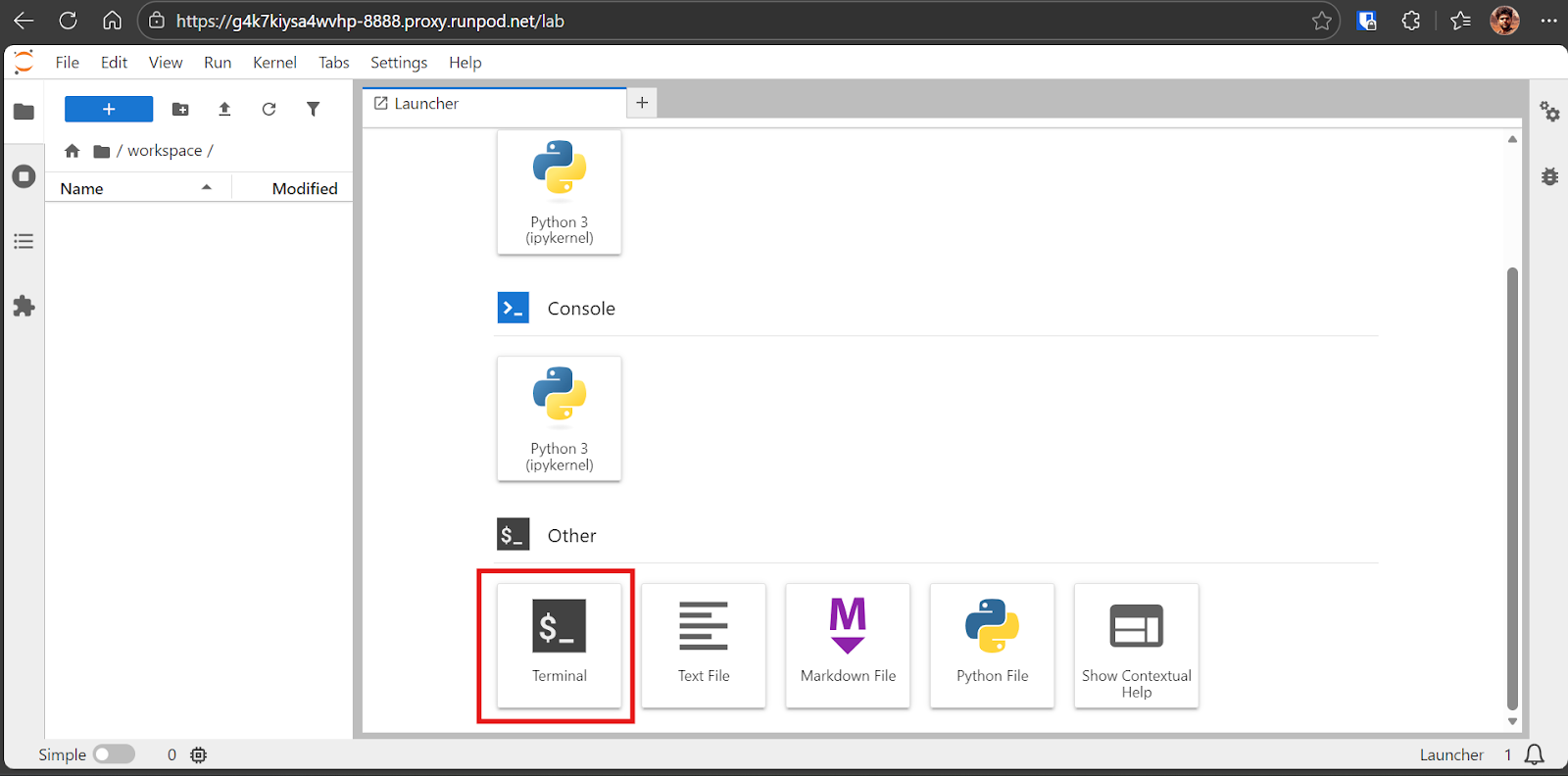
Sobald der Pod fertig ist, starte die Jupyter Lab-Oberfläche. Öffne in Jupyter Lab eine Terminal-Sitzung.
Das Terminal in Jupyter ist echt praktisch, weil du mehrere Terminal-Sessions auf einmal öffnen kannst, ohne separate SSH-Verbindungen verwalten zu müssen.
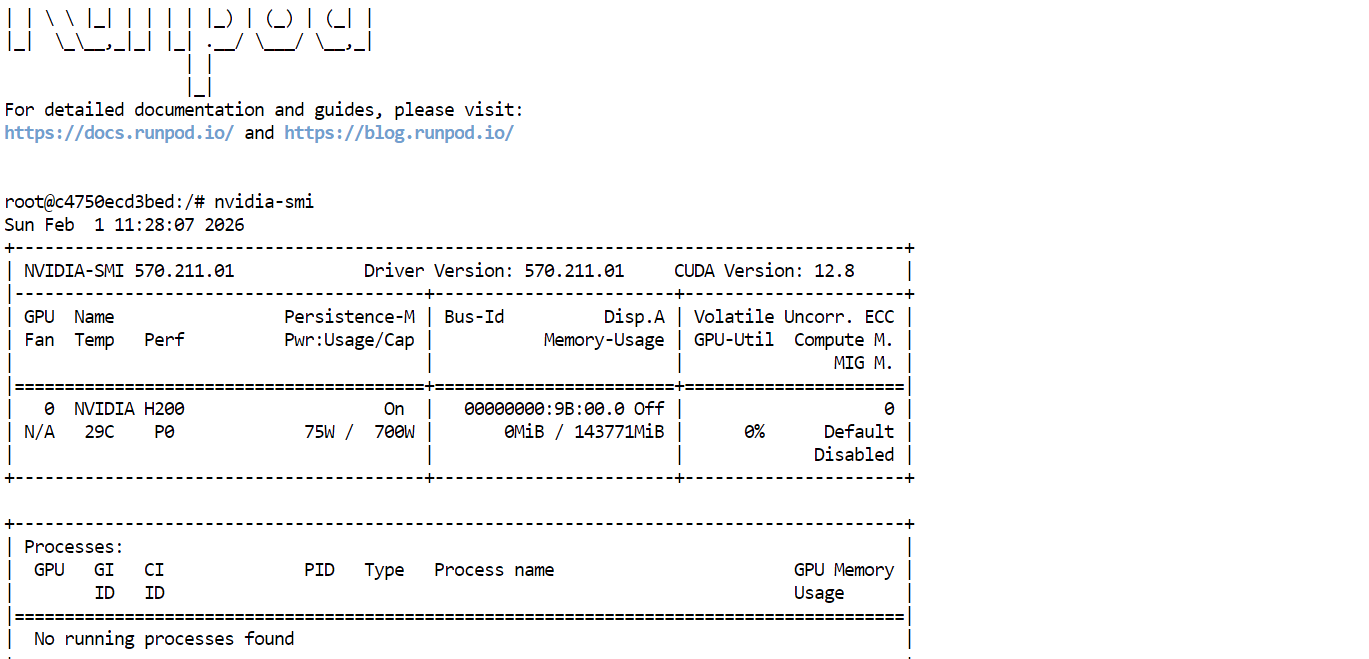
Überprüfe zuerst, ob die GPU-Treiber und CUDA richtig installiert sind, indem du Folgendes ausführst:
nvidia-smiWenn alles richtig eingerichtet ist, solltest du die H200-GPU mit ungefähr 144 GB verfügbarem VRAM.
Als Nächstes installierst du die Linux-Pakete, die du brauchst, um llama.cpp aus dem Quellcode zu erstellen:
sudo apt-get update
sudo apt-get install -y build-essential cmake curl git libcurl4-openssl-devWir werden jetzt llama.cpp aus dem Quellcode erstellen, weil es schnell und leicht ist und uns die beste Leistung auf der H200-GPU bringt.
llama.cpp ist eine Open-Source-Inferenz-Engine in C und C++, die für die Ausführung großer Sprachmodelle entwickelt wurde. Es hat einen eingebauten HTTP-Server namens llama-server, der REST-Endpunkte und eine Web-Benutzeroberfläche bietet, damit du über deinen Browser mit dem Modell interagieren kannst.
Es unterstützt auch benutzerdefinierte CUDA-Kerne und hybride CPU- und GPU-Inferenz, was nützlich ist, wenn Modelle nicht vollständig in den VRAM passen.
Klon zuerst das offizielle Repository llama.cpp:
git clone https://github.com/ggml-org/llama.cppAls Nächstes stellst du den Build mit aktivierter CUDA-Unterstützung ein. Wir konzentrieren uns ganz auf die CUDA-Architektur 90, die für NVIDIA H200-GPUs gebraucht wird:
cmake /workspace/llama.cpp -B /workspace/llama.cpp/build \
-DGGML_CUDA=ON \
-DBUILD_SHARED_LIBS=OFF \
-DCMAKE_CUDA_ARCHITECTURES=90Jetzt kompiliere die Binärdatei von llama-server. Dieser Server wird später für Kimi K2.5 genutzt werden und einen HTTP-Endpunkt sowie eine Web-Benutzeroberfläche bereitstellen:
cmake --build /workspace/llama.cpp/build -j --clean-first --target llama-serverSobald der Build fertig ist, kopier die Binärdatei an einen geeigneten Ort:
cp /workspace/llama.cpp/build/bin/llama-server /workspace/llama.cpp/llama-serverÜberprüfe zum Schluss, ob die Binärdatei da ist und erfolgreich erstellt wurde:
ls -la /workspace/llama.cpp | sed -n '1,60p'Wir laden jetzt das Kimi K2.5 GGUF-Modell von Hugging Face mit Xetherunterladen, das das Herunterladen großer Modelldateien deutlich beschleunigt.
Installiere zuerst die benötigten Hugging Face- und Xet-Transfer-Tools:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferAktiviere das Backend für die schnelle Übertragung:
export HF_HUB_ENABLE_HF_TRANSFER=1Als Nächstes lädst du das 1,8-Bit-quantisierte Modell (UD-TQ1_0) von Hugging Face runter und speicherst es auf deinem Rechner.
Wir nutzen dieses Quant, weil es die beste Balance zwischen Modellqualität und Hardware-Machbarkeit bietet. So kann Kimi K2.5 auf einer einzigen H200-GPU laufen, indem ein Teil des Modells auf den System-RAM ausgelagert wird, während die nutzbare Inferenzgeschwindigkeit erhalten bleibt.
hf download unsloth/Kimi-K2.5-GGUF \
--local-dir /workspace/models/Kimi-K2.5-GGUF \
--include "UD-TQ1_0/*"Auch ohne dich mit einem Hugging Face-Zugriffstoken anzumelden, solltest du Download-Geschwindigkeiten von 800 MB pro Sekunde oder mehr auf RunPod.

Bei uns hat der komplette Download ungefähr 6 Minutengedauert . Die tatsächliche Downloadzeit kann je nach Netzwerkbandbreite und Festplattenleistung variieren.

Jetzt, wo das Modell runtergeladen und llama.cpp mit CUDA-Unterstützung erstellt wurde, können wir Kimi K2.5 lokal über den HTTP-Server von llama.cpp starten.
Mach den folgenden Befehl, um „ llama-server “ zu starten:
/workspace/llama.cpp/llama-server \
--model "/workspace/models/Kimi-K2.5-GGUF/UD-TQ1_0/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf" \
--alias "Kimi-K2.5" \
--host 0.0.0.0 \
--port 8080 \
--threads 32 \
--threads-batch 32 \
--ctx-size 20000\
--temp 0.8 \
--top-p 0.95 \
--min_p 0.01 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024\
--ubatch-size 256Was jedes Argument macht:
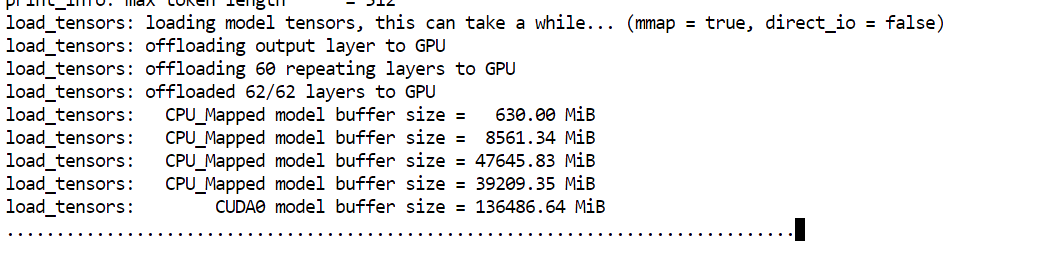
--model: Pfad zur GGUF-Modelldatei, die geladen werden soll--alias: Der Name, den du benutzt, um das Modell auf dem Server und in der Benutzeroberfläche zu erkennen.--host: Netzwerkschnittstelle, an die der Server gebunden werden soll (0.0.0.0 erlaubt externen Zugriff)--port: HTTP-Port, über den der Server llama.cpp und die Web-Benutzeroberfläche zugänglich gemacht werden--threads: Anzahl der CPU-Threads, die für die Inferenz und Vorverarbeitung genutzt werden--threads-batch: CPU-Threads, die für die Stapelverarbeitung von Eingabeaufforderungen verwendet werden--ctx-size: Maximales Kontextfenster in Tokens--temp: Steuert die Zufälligkeit der generierten Ausgabe--top-p: Schwellenwert für die Kernprobenahme bei der Tokenauswahl--min_p: Filtert Tokens mit sehr geringer Wahrscheinlichkeit raus--fit: Passt die Modellgewichte automatisch zwischen VRAM und System-RAM an.--prio: Setzt eine höhere Prozesspriorität für Inferenz-Workloads--jinja: Aktiviert Jinja-basierte Eingabeaufforderungsvorlagen--flash-attn: Aktiviert Blitzlicht, wenn die GPU das unterstützt--batch-size: Anzahl der pro GPU-Batch verarbeiteten Token--ubatch-size: Kleine Batch-Größe, um Speicherverbrauch und Durchsatz auszugleichenBeim Start siehst du, dass das Modell ungefähr 136 GB in den GPU-Speicher lädt, während die restlichen Gewichte auf den System-RAM ausgelagert werden.
Anmerkung: Wenn der Server „llama.cpp“ die GPU nicht erkennt und auf der CPU startet, starte den Pod neu. Wenn das Problem immer noch da ist, lösch einfach den aktuellen Build und baue llama.cpp mit aktivierter CUDA-Unterstützung neu.
Sobald das Laden fertig ist, zeigt der Server eine Zugriffs-URL an. Öffne die Web-Benutzeroberfläche in deinem Browser unter:
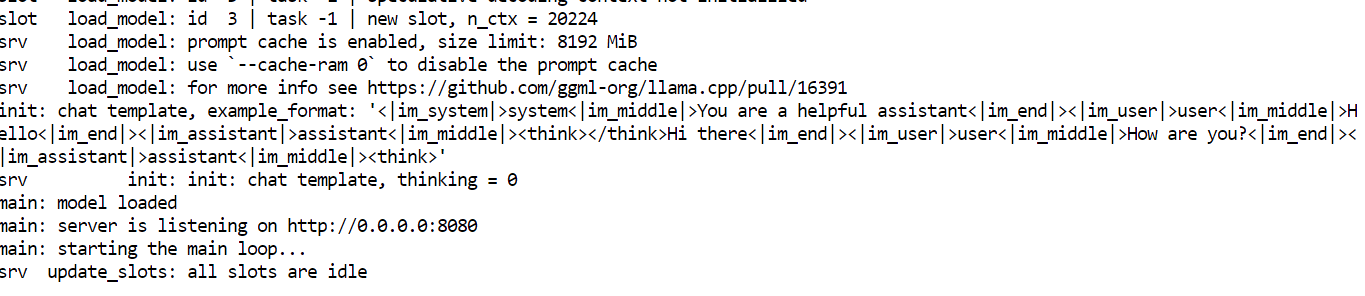
Anmerkung: Wenn du beim Ausführen von „ nvidia-smi “ einen Fehler siehst, ist der Prozess wahrscheinlich wegen zu wenig Speicher abgestürzt. Starte den Pod neu. Alle Modelldateien bleiben auf der persistenten Festplatte.
Sobald der Server „llama.cpp“ läuft, kannst du über die Web-Benutzeroberfläche auf Port 8080.
Um es zu öffnen, geh zum RunPod-Dashboard, wähle deinen Lauf-Pod aus und klick auf den Link neben Port 8080. Damit öffnest du die Web-Benutzeroberfläche von llama.cpp direkt in deinem Browser.
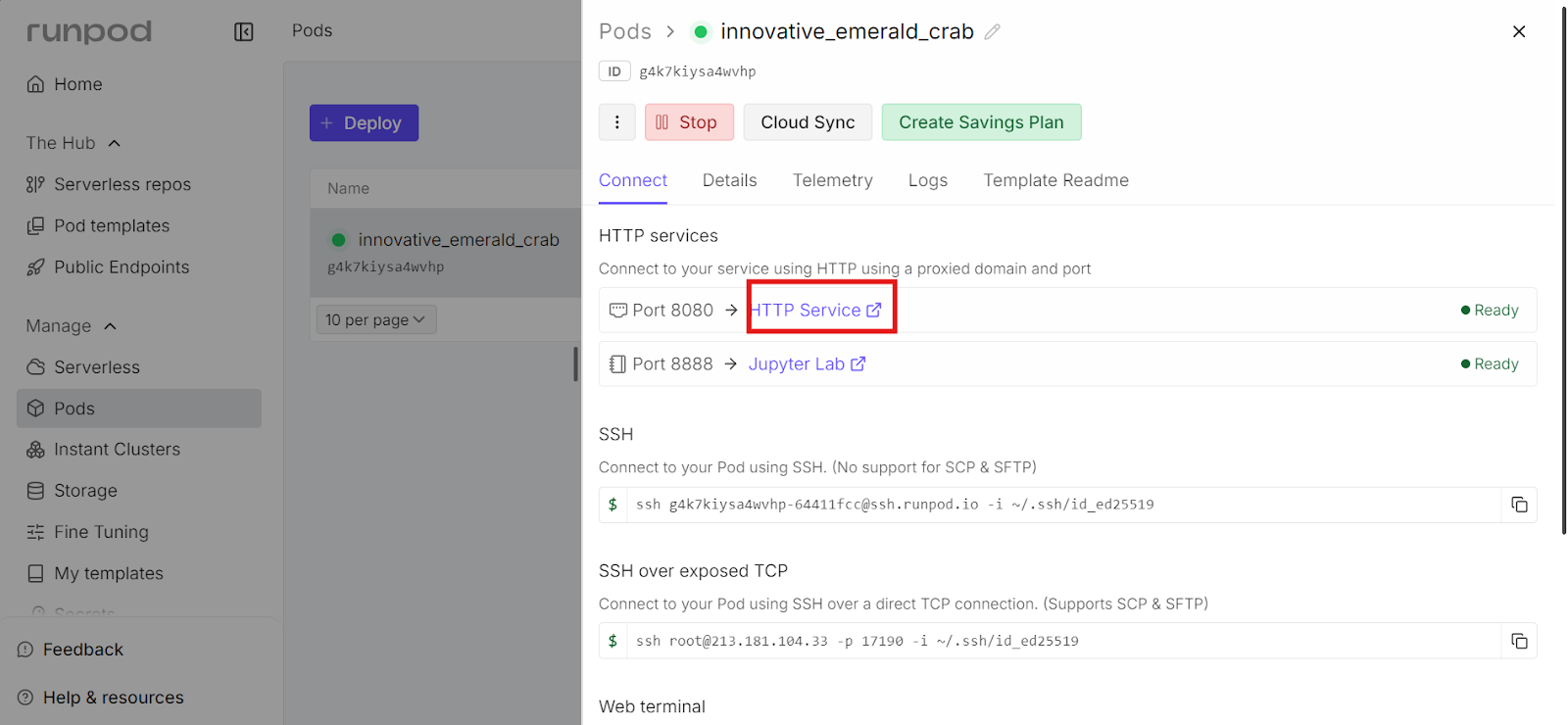
Die Web-Benutzeroberfläche bietet eine einfache Chat-ähnliche Oberfläche, ähnlich wie chatGPT, läuft aber komplett auf deiner eigenen RunPod-Instanz. Die URL ist öffentlich zugänglich. Du kannst diesen Link bei Bedarf mit deinen Teamkollegen oder Mitarbeitern teilen.
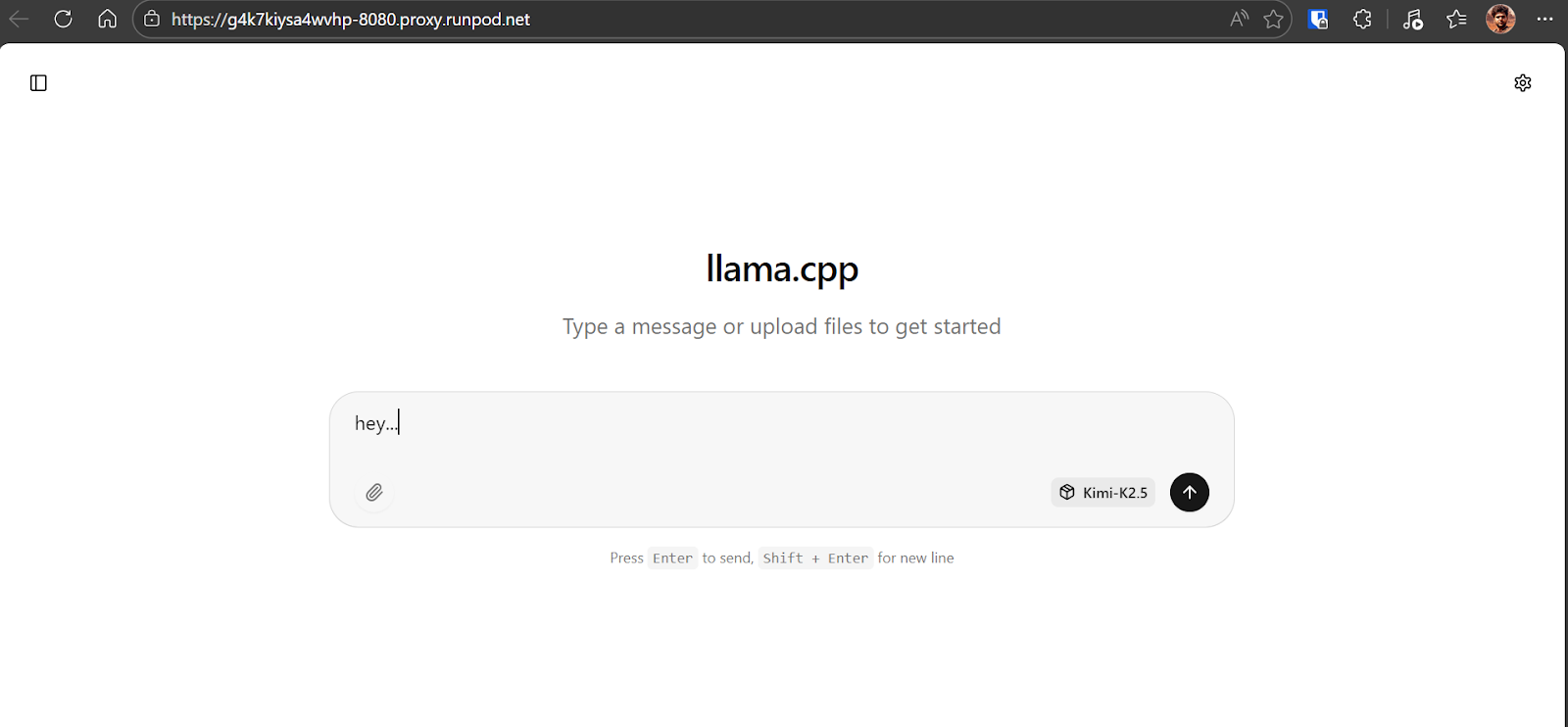
Schick erstmal eine einfache Eingabeanforderung an das Modell Kimi K2.5, um zu checken, ob alles richtig läuft. Bei uns reagiert das Modell mit etwa 6 bis 7 Tokens pro Sekunde, was für den 1,8-Bit-Quant auf einer einzelnen H200-GPU mit teilweiser RAM-Auslagerung zu erwarten ist. Das ist eine solide Basis und zeigt, dass das Modell die GPU richtig nutzt.
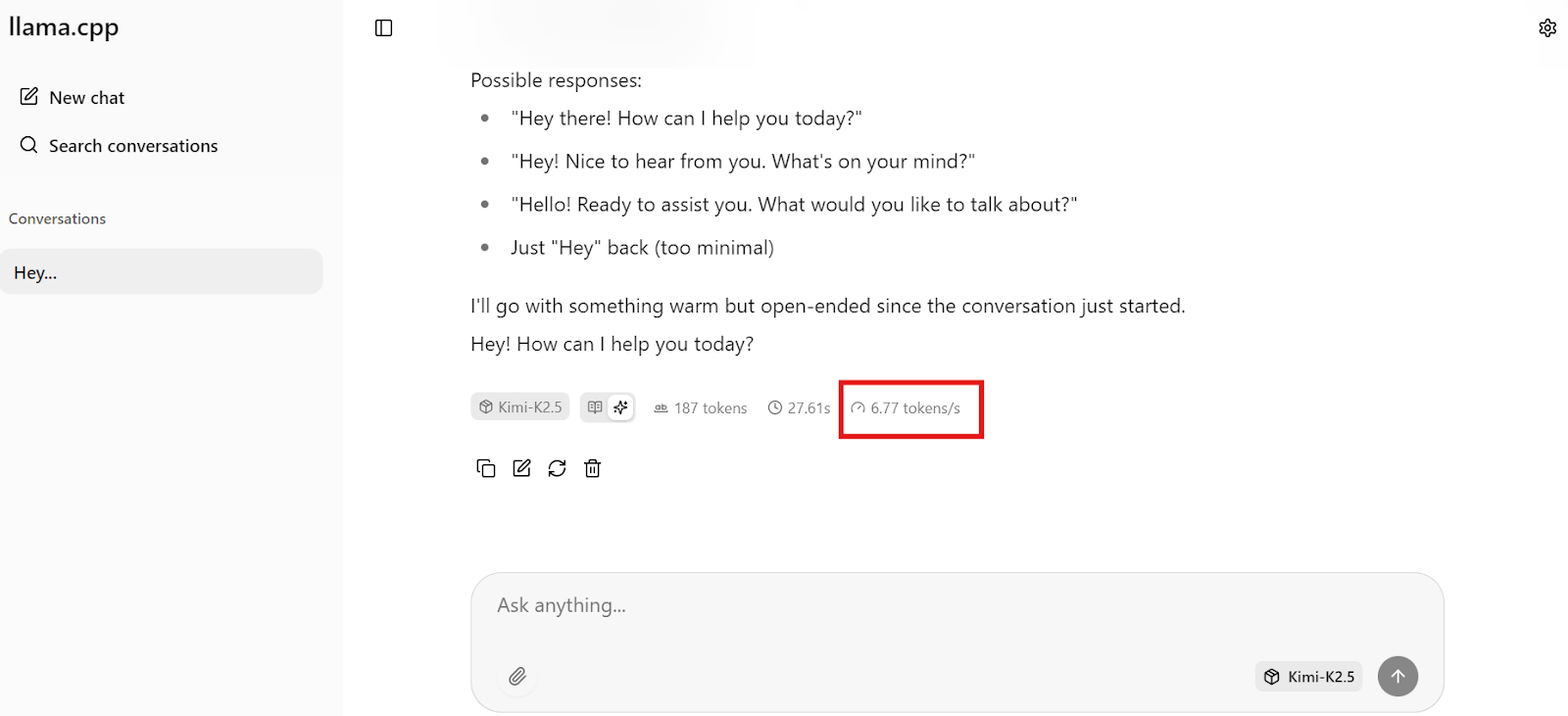
Anmerkung: Die Web-Benutzeroberfläche von llama.cpp trennt die Argumentation nicht klar von der endgültigen Ausgabe, sodass du aufgrund von Vorlagenproblemen möglicherweise beides gemischt siehst.
Kimi CLI ist ein Terminal-basierter Agent zum Codieren und Schlussfolgern, der von Moonshot AI entwickelt wurde. Es hilft dir bei Programmieraufgaben, shell-Workflows und Änderungen auf Projektebene direkt von deiner Befehlszeile aus. Anders als bei einer einfachen Chat-Oberfläche kannst du Kimi CLI direkt in deinem Arbeitsverzeichnis nutzen, was es super für echte Entwicklungsabläufe macht.
Für lokale Inferenz ist der Hauptvorteil von Kimi CLI, dass es OpenAI-kompatible APIsunterstützt :. Dadurch können wir direkt auf unsere lokal laufende llama-server verweisen, sodass Kimi K2.5 komplett auf unserer eigenen Hardware läuft, ohne dass wir auf gehostete oder kostenpflichtige API-Dienste angewiesen sind.
Mach's so: Starte das offizielle Installationsskript:
curl -LsSf https://code.kimi.com/install.sh | bashAls Nächstes fügst du die Binärdatei zu deinem PATH hinzu, damit das Befehl „kimi in deinem Terminal verfügbar ist:
export PATH="/root/.local/bin:$PATH"Schau mal, ob die Installation geklappt hat:
kimi --versionDu solltest eine Ausgabe sehen, die so ähnlich wie „ kimi, version 1.5 “ aussieht.
Mach das Konfigurationsverzeichnis, das von der Kimi-CLI benutzt wird:
mkdir -p ~/.kimiJetzt erstelle die Konfigurationsdatei. Dadurch wird die Kimi-CLI angewiesen, deine lokale llama.cpp-Server- -Datei als einen OpenAI-kompatiblen Anbieter zu behandeln, der unter http://127.0.0.1:8080/v1 läuft. Es registriert auch einen lokalen Modelleintrag, der mit dem Alias übereinstimmt, den du beim Starten von „ llama-server “ angegeben hast.
cat << 'EOF' > ~/.kimi/config.toml
[providers.local_llama]
type = "openai_legacy"
base_url = "http://127.0.0.1:8080/v1"
api_key = "sk-no-key-required"
[models.kimi_k25_local]
provider = "local_llama"
model = "Kimi-K2.5"
max_context_size = 20000
EOFStell sicher, dass der Wert von „ model “ genau mit dem Wert von „ --alias “ übereinstimmt, der beim Starten von „ llama-server “ verwendet wird. Das Feld „ api_key “ ist nur ein Platzhalter und wird für die lokale Inferenz nicht gebraucht.
In diesem Abschnitt nutzen wir die Kimi-CLI, die mit unserem lokalen Kimi-K2.5-Server verbunden ist, um mit Vibe-Coding ein voll spielbares Snake-Spiel zu erstellen.
Mach erst mal ein neues Projektverzeichnis und geh da rein:
mkdir -p /workspace/snake-game
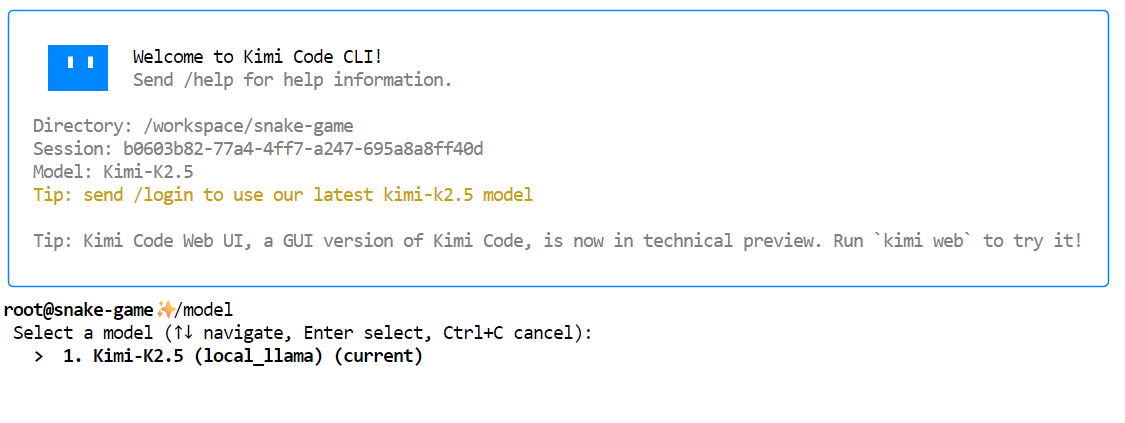
cd /workspace/snake-gameStarte dann die Kimi-CLI:
kimiSobald Kimi CLI gestartet ist, gib /modelein und wähle das lokale Kimi K2.5-Modell „ “ aus , das wir vorher eingerichtet haben. Du solltest„ “ Kimi-K2.5 als verfügbares Modell sehen.
 Jetzt sag Kimi, dass es das Spiel erstellen soll. Benutz einfach eine klare Anweisung wie die folgende:
Jetzt sag Kimi, dass es das Spiel erstellen soll. Benutz einfach eine klare Anweisung wie die folgende:
"Create a simple Snake game as a single self-contained file named index.html."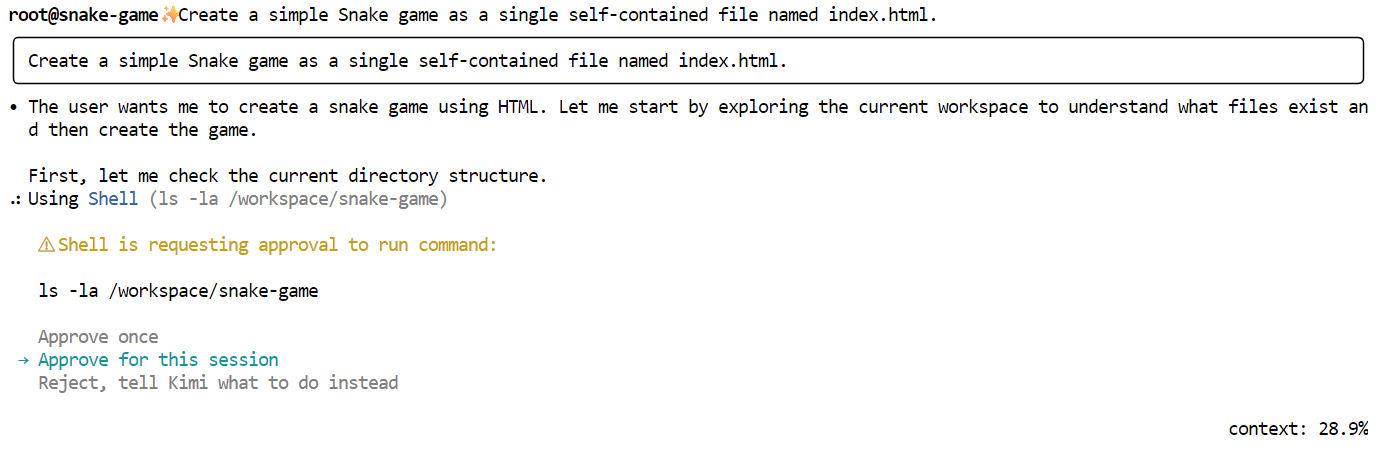
Kimi wird erst mal einen Plan machen und dich fragen, ob du damit einverstanden bist. Schau es dir an und gib den Antrag frei.

Nach der Freigabe erstellt Kimi die komplette Datei „ index.html “, einschließlich HTML, CSS und JavaScript, alles an einem Ort.
Sobald die Datei erstellt ist, kannst du sie runterladen oder lokal kopieren und in deinem Browser öffnen. Das Spiel startet sofort.
Das Ergebnis ist ein voll funktionsfähiges Snake-Spiel mit flüssigen Bewegungen, klarer Grafik und klassischen Spielfunktionen.
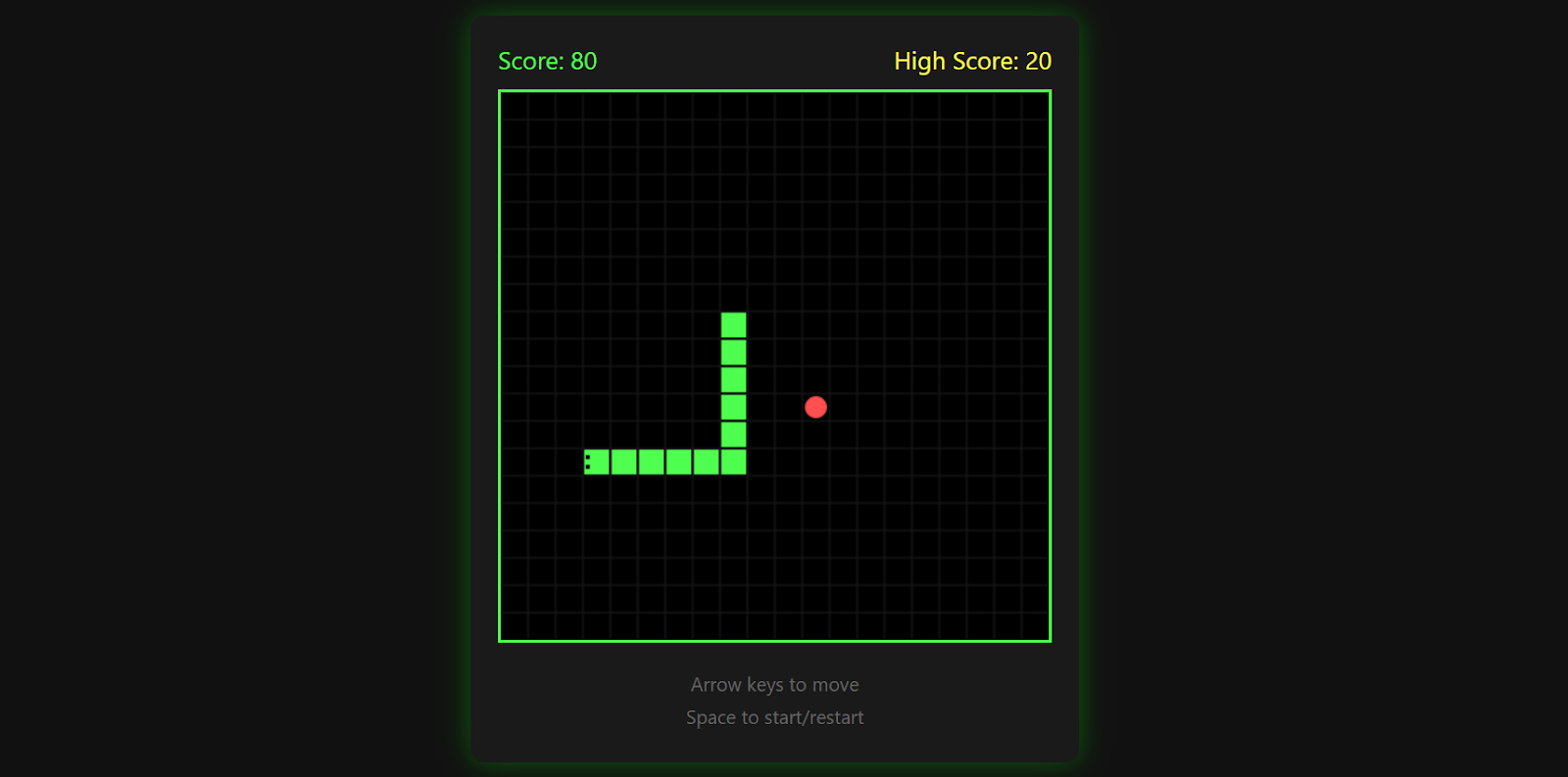
Das Spiel merkt sich deinen Highscore, hört auf, wenn du gegen eine Wand fährst, und du kannst durch nochmaliges Drücken der Leertaste neu starten.
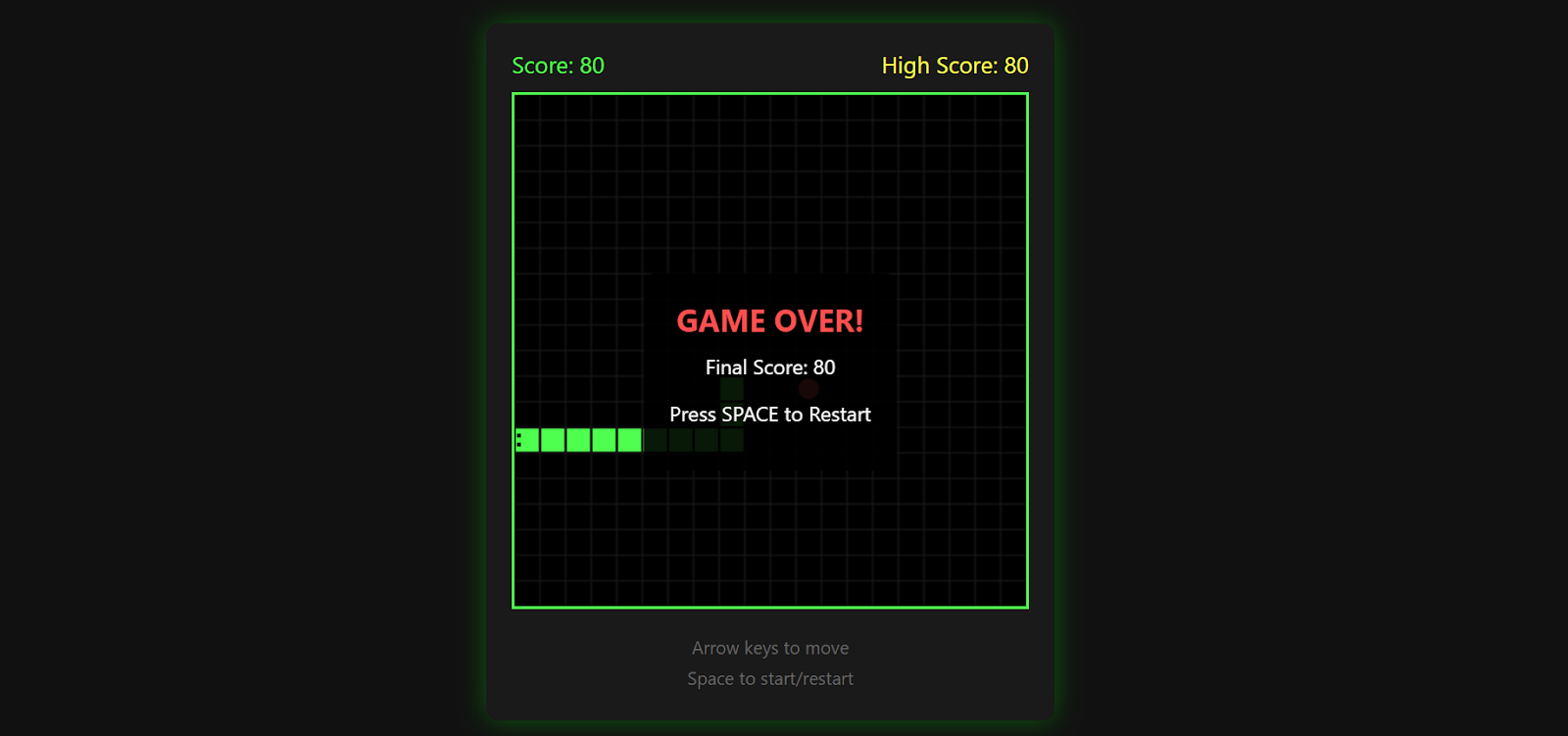
Für eine einzige Eingabeaufforderung ist das Ergebnis echt beeindruckend und zeigt super, was Kimi K2.5 zusammen mit Kimi CLI und einer lokalen Inferenzkonfiguration so alles kann.
Um ehrlich zu sein, fand ich es frustrierender als erwartet, ein voll funktionsfähiges Spiel in einem einzigen One-Shot-Prompt zu erstellen.
Kimi K2.5 kann echt gut, aber das Modell hat oft Probleme damit, zu entscheiden, wann es mit der Wiederholung einer Aufgabe aufhören soll. In der Praxis führt das oft dazu, dass man sich zu sehr mit dem Problem beschäftigt.
Wenn man zum Beispiel gebeten wird, ein Snake-Spiel in Pygame zu programmieren, kann es sein, dass man wieder auf eine HTML-Implementierung zurückgreift, und wenn man nach HTML gefragt wird, kann es sein, dass man wieder zu einem Python-basierten Ansatz zurückkehrt.
Dieses Hin und Her bedeutet, dass du oft mehrmals eingreifen musst, um das Modell an deine Absicht anzupassen.
Ein großer Teil dieses Verhaltens kommt von der 1,8-Bit-Quantisierungs. Die Modi „1-Bit“ und „Sub-2-Bit“ machen es zwar möglich, ein extrem großes Modell auf begrenzter Hardware auszuführen, bringen aber auch Nachteile mit sich.
Das Modell kann immer noch zusammenhängende Antworten liefern, hat aber mehr Probleme mit der Beendigung von Aufgaben, langfristigen Überlegungen, strukturierter Planung und Funktionsaufrufen. Genau diese Bereiche sind für agentenbasierte Arbeitsabläufe und mehrstufige Codierungsaufgaben am wichtigsten.
Realistisch gesehen zeigt Kimi K2.5 seine Stärken bei höheren Präzisionsn, wie zum Beispiel 4 Bit oder mehr. Auf dieser Stufe wird die Planung deutlich besser und das Modell verhält sich vorhersehbarer.
Der Nachteil ist klar. Höhere Präzision braucht deutlich mehr RAM und VRAM, was es für viele lokale Setups unmöglich macht. Wenn man nur die Größe und Leistung bei niedriger Genauigkeit betrachtet, bieten Modelle wie GLM 4.7 im Moment für viele Leute ein flüssigeres Erlebnis.
Wenn du aber die Hardware-Einschränkungen ignorierst und Kimi K2.5 mit höherer Genauigkeit oder über eine gehostete API laufen lässt, ist das Modell echt beeindruckend. Seine Argumentationstiefe, die Qualität der Codegenerierung und die Verarbeitung langer Kontexte sind so stark, dass es proprietäre Modelle in vielen Arbeitsabläufen ersetzen kann.
Tatsächlich, wenn man die Kimi AI APIgenug, um den ganzen Vibe-Coding-Workflow darauf umzustellen.
Um mehr über die hier behandelten Konzepte zu erfahren, empfehle ich dir diese Ressourcen:
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Moez Ali
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree