
programa
Fundamentos de la IA
10 h
El mecanismo de atención se encuentra en el centro de modelos transformadores. Todas las arquitecturas de modelos populares, como GPT, LLaMAy Mixture of Experts (MoE), dependen de él para conectar tokens y construir significado.
Pero la atención es cara. Tu cálculo implica multiplicaciones de matrices grandes y, lo que es más importante, un movimiento masivo de datos entre la memoria de la GPU y las unidades de cálculo. A medida que aumenta la longitud de las secuencias, el ancho de banda de la memoria se convierte en el verdadero cuello de botella.
Por lo tanto, optimizar la atención tiene un impacto desmesurado en el rendimiento de los LLM, y ahí es precisamente donde entra en juego Flash Attention. En este artículo, te explicaré qué es Flash Attention, cómo funciona y cómo utilizarlo con PyTorch y Hugging Face Transformers.
Si estás buscando una forma de iniciarte en los LLM, te recomiendo que realices nuestro curso introductorio sobre conceptos de LLM.
Flash Attention es un mecanismo de atención optimizado mecanismo de atención, lo que lo hace mucho más rápido y eficiente en cuanto a memoria en las GPU.
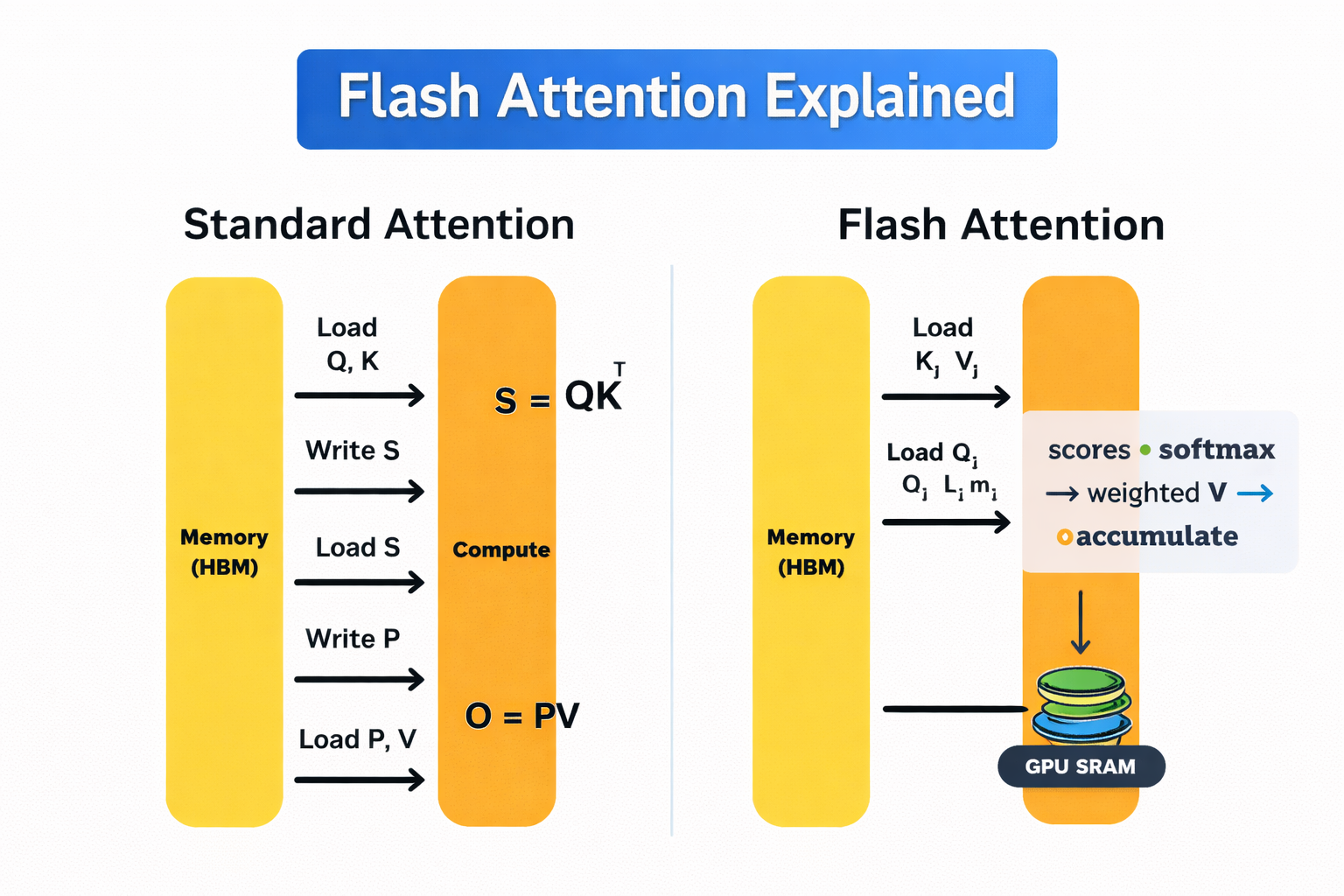
Atención estándar frente a atención instantánea
Las GPU tienen dos tipos principales de memoria. La memoria de gran ancho de banda (HBM) es grande, pero relativamente lenta. La SRAM integrada en el chip es extremadamente rápida, pero tiene un tamaño muy limitado.
La autoatención estándar transfiere constantemente datos entre estos dos. Ese ir y venir es caro, y se convierte en un coste significativo a medida que aumenta la longitud de la secuencia.
Flash Attention evita esto calculando la atención en pequeños mosaicos que caben por completo en la SRAM rápida. Cadamosaico se procesa de extremo a extremo con un, aplicando softmax de forma incremental, por lo que no es necesario volver a escribir los resultados intermedios en HBM. Por lo tanto, la matriz de atención completa nunca se almacena en la memoria.
A diferencia de los métodos de atención dispersa o lineal, Flash Attention no es una aproximación. Produce exactamente el mismo resultado matemático que la autoatención estándar, solo que se ejecuta de una manera más eficiente en cuanto a memoria.
Flash Attention logra su eficiencia rediseñando la forma en que calcula la atención en la GPU. Sigue un mecanismo sencillo: realizar todo el trabajo posible en la memoria rápida integrada en el chip y evitar movimientos innecesarios hacia la memoria lenta.
Una forma útil de pensar en esto es mediante una analogía con la cocina. La SRAM integrada en la GPU es como una pequeña y rápida encimera de cocina. Es donde realmente preparas y cocinas. La memoria de alto ancho de banda (HBM) de la GPU es como una gran tienda de comestibles en tu calle. Puede almacenar todo lo que necesitas, pero ir y venir lleva tiempo.
En pocas palabras, la atención estándar sigue acudiendo a la tienda de comestibles después de cada paso. Por el contrario, Flash Attention planifica la cocina para que todo quepa en la encimera mientras cocinas. Veamos esto con más detalle:
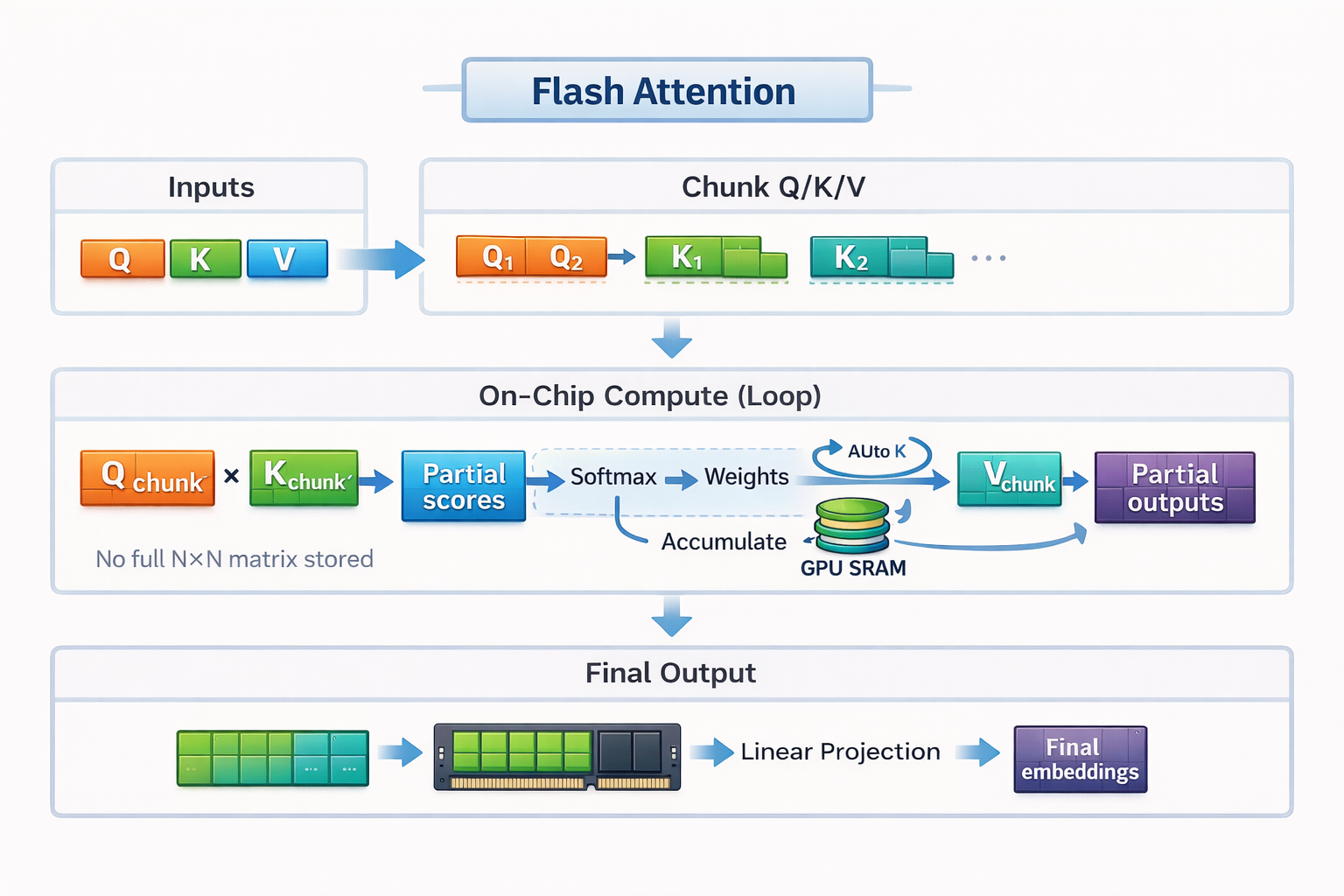
Mecanismo de funcionamiento de Flash Attention
Flash Attention se basa en dos ideas clave: mosaico y recalculación.
Siguiendo con nuestro ejemplo culinario, el mosaico es la forma en que Flash Attention adapta el cálculo de la atención al pequeño mostrador.
En lugar de cargar toda la secuencia y crear una matriz de atención completa, Flash Attention divide las entradas en pequeños bloques o mosaicos. Cada mosaico cabe completamente en la rápida SRAM de la GPU. Flash Attention calcula la atención una casilla a la vez, de principio a fin, antes de pasar a la siguiente casilla.
Siguiendo con la analogía de la cocina, no puedes colocar los ingredientes para un banquete completo en una encimera pequeña. Así que preparas y cocinas en pequeñas cantidades. Cortas algunas verduras, las cocinas, despejas el espacio y luego pasas a la siguiente tanda. Al trabajar de esta manera, evitas tener que ir y venir constantemente al supermercado.
Esta ejecución bloque por bloque permite a Flash Attention mantener los datos locales, rápidos y eficientes, sin necesidad de materializar la matriz de atención completa en una memoria lenta.
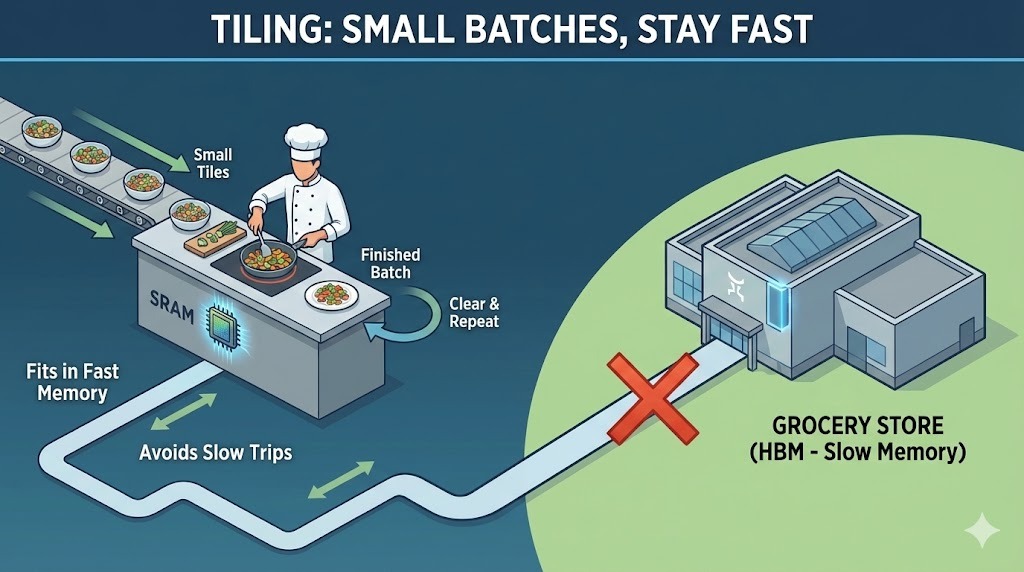
Atención a los mosaicos en Flash
Durante el entrenamiento, la atención estándar almacena grandes resultados intermedios para que puedan reutilizarse durante la pasada hacia atrás. Ese almacenamiento tiene un alto coste en términos de memoria. Flash Attention adopta un enfoque diferente. En lugar de almacenar estos intermedios, vuelve a calcular pequeñas partes de las puntuaciones de atención cada vez que son necesarias.
En la cocina, esto es como cortar cebollas. Podrías ir andando a la tienda de comestibles para guardar las cebollas picadas y luego volver más tarde a recogerlas. O bien, puedes desecharlas y simplemente volver a picar una cebolla fresca cuando llegue el momento de cocinar. Sorprendentemente, la segunda opción es más rápida porque evita movimientos frecuentes o más largos.
En las GPU modernas, el recálculo sigue la misma lógica, ya que el cálculo adicional es barato en comparación con los movimientos de memoria. Al volver a calcular los valores pequeños en lugar de almacenarlos y cargarlos, Flash Attention reduce significativamente el tráfico de memoria y mantiene la eficiencia del entrenamiento.
Juntos, el mosaico y el recálculo permiten a Flash Attention mantener el cálculo de la atención en el contador, minimizar los viajes al supermercado y aprovechar al máximo las ventajas del hardware moderno de las GPU.
Flash Attention 2 (FA2), lanzado en 2023, es una importante actualización con respecto a la primera generación. Mantiene la misma idea central de conciencia IO y atención precisa, pero mejora la eficiencia en varias dimensiones que son importantes en las cargas de trabajo del mundo real.
La primera versión de Flash Attention paralelizó el cálculo entre el tamaño del lote y los cabezales de atención. Eso funcionó bien para configuraciones de entrenamiento con lotes grandes. Sin embargo, no era tan adecuado para la inferencia, donde los tamaños de los lotes suelen ser pequeños y las longitudes de las secuencias son largas.
FA2 añade paralelismo en toda la dimensión de la longitud de la secuencia. Esto permite que más partes del cálculo de atención se ejecuten simultáneamente, incluso cuando el tamaño del lote es pequeño. Al distribuir el trabajo entre los tokens de la secuencia, la versión 2 mantiene ocupadas simultáneamente más unidades de cálculo de la GPU.
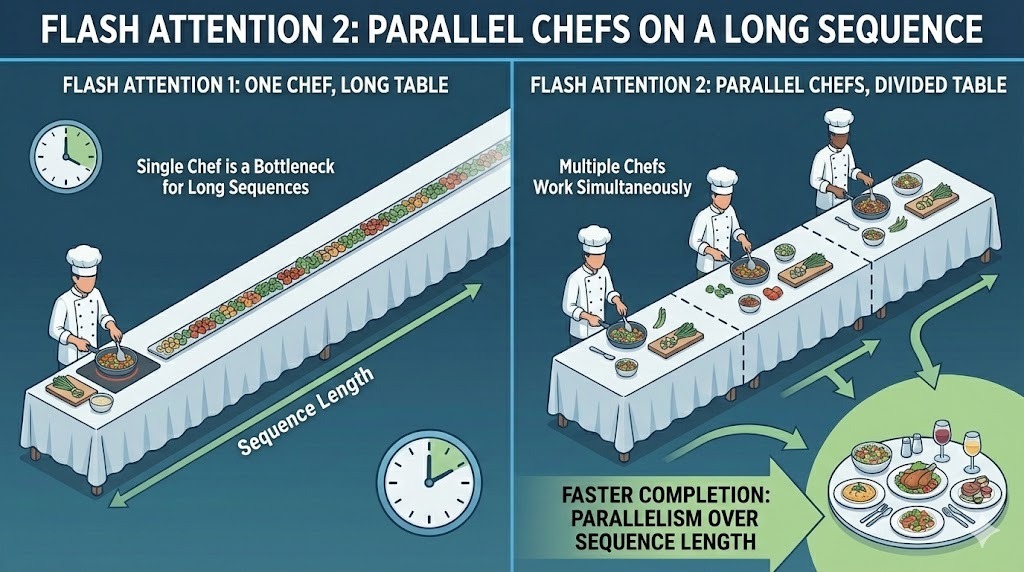
Paralelismo entre lotes en Flash Attention 2
La ventaja práctica es un mayor rendimiento y un mejor aprovechamiento del hardware en escenarios de inferencia comunes, donde lo habitual son las indicaciones largas y los lotes pequeños.
Las GPU son extremadamente eficaces en la multiplicación de matrices. Un hardware especializado denominado Tensor Cores puede ejecutar operaciones de multiplicación de matrices generales (GEMM) a una velocidad muy alta.
El problema es que la atención no es solo una multiplicación de matrices: implica operaciones como escalado, enmascaramiento y softmax, que se ejecutan en núcleos GPU estándar y son mucho más lentas en comparación.
FA2 redujo este desequilibrio. Reestructura el cálculo para minimizar las operaciones de coma flotante no matriciales, especialmente las relacionadas con el reescalado de las puntuaciones de atención. La mayor parte del tiempo de ejecución se dedica a operaciones matriciales grandes y eficientes que los núcleos Tensor pueden acelerar.
Flash Attention v1 se optimizó en torno a dimensiones de cabeza de 64 o 128, que coincidían con modelos como BERT y GPT-3. A medida que evolucionaban las arquitecturas de los modelos, las dimensiones de los cabezales aumentaban para admitir tamaños de incrustación más grandes y una mayor capacidad de los modelos.
FA2 amplió la compatibilidad a dimensiones de cabezal de hasta 256. Esto lo hizo compatible con arquitecturas más nuevas que se basan en cabezales de atención más amplios.
Flash Attention 3 (FA3) es el estándar actual del sector que impulsa modelos de última generación como GPT-5.2. Se basa en la misma base de atención exacta y consciente de la E/S que las versiones anteriores, pero está diseñado específicamente para las GPU NVIDIA H100 (Hopper).
El cambio clave es que FA3 está diseñado para aprovechar las nuevas características de hardware asíncrono de Hopper, lo que permite que el movimiento de la memoria y el cálculo se superpongan de forma mucho más agresiva que antes.
En versiones anteriores, todos los subprocesos de la GPU, conocidos como warps, seguían la misma ruta de ejecución. FA3 cambia este modelo mediante la especialización en warp. Asigna una de dos funciones distintas a cada urdimbre:
Esta separación permite que la transferencia de datos y el cálculo se realicen al mismo tiempo. Mientras los warps productores obtienen los siguientes bloques de datos, los warps consumidores se mantienen ocupados calculando los bloques actuales, lo que mejora significativamente la latencia.
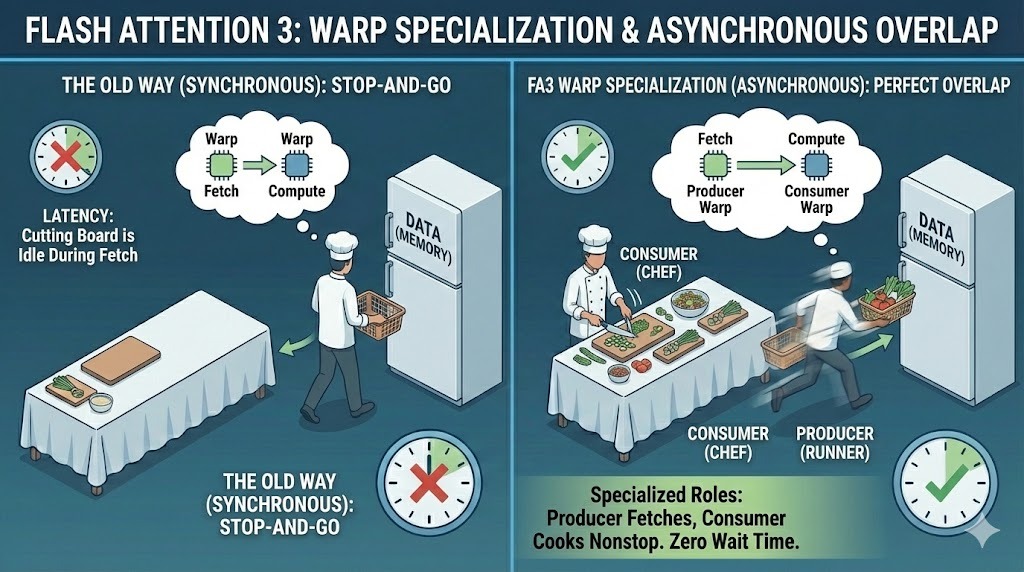
Especialización en Flash Attention 3
Flash Attention 3 también introduce compatibilidad nativa con FP8, o precisión de coma flotante de 8 bits. Las versiones anteriores se basaban principalmente en FP16 o BF16, que ya reducían el uso de memoria en comparación con FP32, pero seguían consumiendo un ancho de banda significativo.
FP8 reduce el consumo de memoria aproximadamente a la mitad. Esta reducción se traduce directamente en un mayor rendimiento y una menor presión sobre la memoria. En las GPU Hopper, FP8 cuenta con aceleración por hardware, lo que significa que FA3 puede procesar más operaciones de atención por segundo sin sacrificar la precisión a nivel del modelo.
Esta capacidad es una de las principales razones por las que modelos grandes como Gemini 3 pueden manejar ventanas de contexto masivas ventanas de contexto mientras prestan servicio a millones de usuarios de manera eficiente.
Una última característica del diseño del FA3 es el uso del acelerador de memoria tensorial (TMA) del H100. El TMA es un hardware especializado que gestiona copias de memoria de forma asíncrona, sin ocupar los núcleos de cálculo principales.
Flash Attention 3 utiliza TMA para mover bloques de datos en segundo plano mientras el cálculo continúa sin interrupciones. Al superponer estrechamente el movimiento de la memoria con las matemáticas, FA3 es capaz de extraer cerca del 75 % del rendimiento máximo teórico del hardware.
Flash Attention 4 (FA4) representa el siguiente paso experimental en la optimización de la atención. Está diseñado para las próximas GPU Blackwell B200 de NVIDIA y explora las posibilidades que se abren cuando se crean núcleos de atención para una clase de hardware completamente nueva.
A medida que los tamaños de los modelos continúan creciendo y los entrenamientos avanzan hacia la escala de billones de parámetros, incluso Flash Attention 3 acabará alcanzando sus límites. FA4 es un primer intento de eliminar esos límites llevando la utilización del hardware más allá de cualquier núcleo anterior.
En esta etapa, Flash Attention 4 es una tecnología en fase de investigación y preproducción. Es muy prometedor, pero aún no se utiliza en modelos implementados o de producción.
Uno de los principales hitos de Flash Attention 4 es el rendimiento. Es el primer núcleo de atención diseñado para superar 1 PFLOPS, o un cuatrillón de operaciones de coma flotante por segundo, en una sola GPU.
Se centra en un futuro en el que entrenar modelos con billones de parámetros llevaría una cantidad de tiempo impracticable. A esa escala, incluso las pequeñas ineficiencias se acumulan y provocan retrasos importantes. FA4 tiene como objetivo hacer viables esos futuros entrenamientos extrayendo un rendimiento extremo de un solo chip.
Para alcanzar ese rendimiento, FA4 lleva la asincronía mucho más allá que las versiones anteriores. Amplía el modelo productor-consumidor a canalizaciones muy complejas y de múltiples etapas, en las que el movimiento de datos, el cálculo y la sincronización funcionan de forma independiente.
En lugar de una superposición relativamente simple entre la carga y el cálculo, FA4 gestiona una ejecución profundamente asíncrona en múltiples etapas. Las diferentes partes del núcleo avanzan a diferentes velocidades, coordinadas por una programación a nivel de hardware en lugar de un único flujo sincronizado.
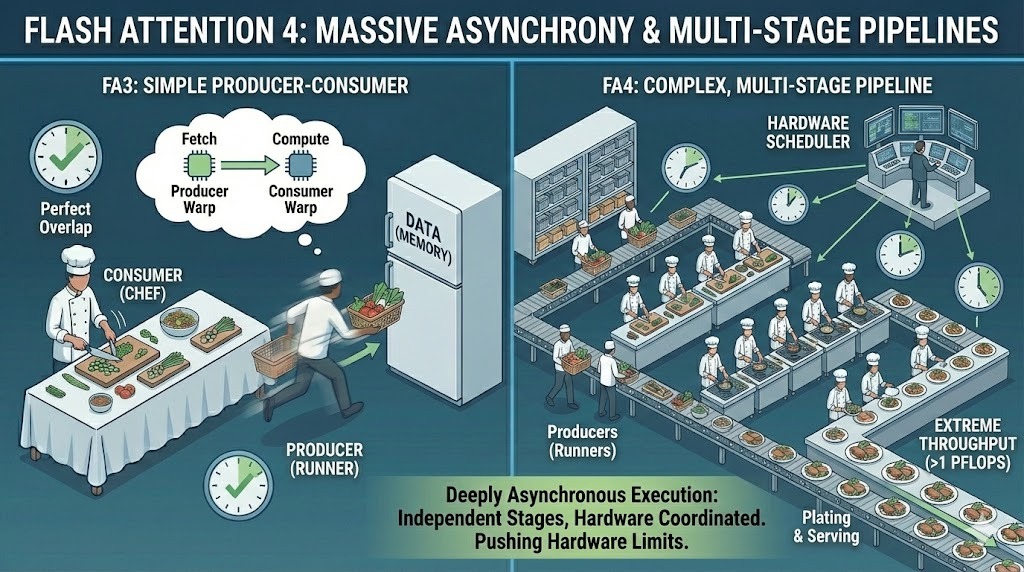
Asincronía masiva en Flash Attention 4
Esta complejidad es también la razón por la que FA4 sigue siendo experimental. Gestionar la precisión, la estabilidad y la integración a este nivel es todo un reto. La comunidad aún necesita más trabajo antes de que los equipos puedan utilizarla de forma fiable en grandes modelos de producción.
Veamos cómo se compara Flash Attention con el mecanismo de atención estándar en algunos ámbitos clave.
Las pruebas comparativas muestran sistemáticamente que todas las versiones de Flash Attention superan a la autoatención estándar, con ganancias que aumentan a medida que crece la longitud de la secuencia.
El artículo original sobre Flash Attention informa de una aceleración de entre 2 y 4 veces con respecto a la atención estándar optimizada. Flash Attention 2 mejora aún más este aspecto al aumentar el paralelismo y saturar mejor la GPU, lo que a menudo proporciona otra mejora de aproximadamente el doble en la práctica.
Flash Attention 3 mejora aún más el rendimiento en las GPU Hopper, especialmente con FP8, logrando una utilización del hardware mucho mayor que la que puede alcanzar la atención estándar.
La atención estándar materializa explícitamente la matriz de atención completa N × N, lo que conduce a un crecimiento cuadrático de la memoria con respecto a la longitud de la secuencia. A medida que N crece, el uso de memoria se dispara, saturando rápidamente la memoria de la GPU. Flash Attention evita almacenar esta matriz por completo.
Al calcular la atención en mosaicos y guardar los resultados intermedios en una memoria rápida integrada en el chip, se reduce el uso de memoria a una secuencia lineal en función de la longitud de la secuencia para dimensiones de cabeza fijas. Este cambio de escalado de memoria cuadrático a lineal elimina el mayor cuello de botella estructural en la atención estándar.
Esa reducción de memoria permite directamente ventanas de contexto más largas. Con la atención estándar, los modelos suelen dar errores de memoria insuficiente cuando las secuencias alcanzan unos pocos miles de tokens.
Flash Attention hace que los contextos de tokens de 4k y 8k sean prácticos en una sola GPU, e incluso desbloquea ventanas mucho más largas, como tokens de 16k o 32k, en ese único dispositivo cuando se combina con otras técnicas de ahorro de memoria.
No te confundas aquí: Las enormes ventanas de un millón de tokens logradas en algunos modelos fronterizos actuales como Gemini 3, se consiguen dividiendo la secuencia en grandes clústeres de GPU, ya que superan con creces la capacidad de memoria de cualquier dispositivo individual.
Hoy en día, utilizar Flash Attention es mucho más sencillo que antes. En la mayoría de los casos, no es necesario escribir kernels CUDA personalizados ni cambiar la arquitectura del modelo. El soporte ya está integrado en las herramientas más populares en la actualidad.
Desde PyTorch 2.0, Flash Attention está disponible directamente a través de torch.nn.functional.scaled_dot_product_attention. Cuando llamas a esta función, PyTorch selecciona automáticamente el backend de atención más rápido disponible para tu hardware.
En las GPU compatibles, ese backend es Flash Attention. Desde la perspectiva del usuario, a menudo parece un código de atención estándar, pero en realidad PyTorch envía un núcleo Flash Attention optimizado.
Si utilizas Hugging Face Transformers, habilitar Flash Attention suele ser un cambio de una sola línea. Al configurar attn_implementation="flash_attention_2" en la configuración del modelo, se indica a la biblioteca que utilice Flash Attention 2 siempre que sea posible.
Para muchos modelos de transformadores, esto es suficiente para obtener mejoras tanto en velocidad como en memoria sin tocar el resto del código de entrenamiento o inferencia.
Flash Attention 2 está diseñado para las GPU NVIDIA modernas y funciona mejor en las arquitecturas Ampere, Ada y Hopper, incluidas las A100, RTX 3090, RTX 4090 y H100. Estas GPU proporcionan el ancho de banda de memoria y las características arquitectónicas necesarias para aprovechar al máximo el mosaico y el paralelismo en FA2.
También cabe destacar que la versión original Flash Attention v1 también es compatible con GPU más antiguas. Las tarjetas basadas en Turing, como la T4 y la RTX 2080, pueden seguir utilizando Flash Attention v1, aunque las versiones más recientes requieren un hardware más actual para aprovechar al máximo sus mejoras de rendimiento.
En la práctica, si ya utilizas PyTorch 2.x o Hugging Face Transformers en una GPU NVIDIA moderna, Flash Attention suele estar a solo un cambio de configuración de distancia.
La atención estándar se topó con un gran obstáculo, ya que el crecimiento cuadrático de la memoria hacía que las secuencias largas fueran lentas, costosas o simplemente imposibles debido a fallos por falta de memoria. Flash Attention cambió eso al rediseñar la forma en que se ejecuta la atención.
Al reducir el uso de memoria de cuadrático a lineal con respecto a la longitud de la secuencia, Flash Attention hace que el modelado de contexto largo sea práctico. Las ventanas de contexto que antes sobrecargaban las GPU con unos pocos miles de tokens ahora se amplían a 4k, 8k e incluso más de 32k tokens en el mismo hardware.
Si trabajas con transformadores a gran escala y no utilizas Flash Attention, es casi seguro que estás desperdiciando rendimiento.
¿Deseas crear tus propios modelos que puedan utilizar Flash Attention? Realiza nuestro curso sobre modelos de transformadores con PyTorch.
Cursos de IA
programa
Curso
Curso
blog
Natassha Selvaraj
15 min
blog
Bhavishya Pandit
7 min
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Arjun Sarkar
Tutorial
Abid Ali Awan

