
Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.1K
L'exécution d'un modèle à un trillion de paramètres tel que Kimi K2.5 nécessite généralement un cluster multi-GPU de grande envergure et un budget d'infrastructure adapté, souvent supérieur à 40 dollars de l'heure. Cependant, avec les outils d'optimisation adéquats, il est possible d'utiliser ce modèle de pointe sans engager des dépenses excessives.
Dans ce tutoriel, je vais vous expliquer comment exécuter Kimi K2.5 localement à l'aide d'un seul GPU NVIDIA H200 sur RunPod. En utilisant llama.cpp pour une inférence efficace et en le connectant à l'interface CLI Kimi, vous pouvez contourner les infrastructures d'entreprise complexes et commencer immédiatement à développer des logiciels de haut niveau.
Kimi K2.5 est un modèle linguistique open source de pointe, conçu pour le raisonnement avancé, le codage et la génération de textes de haute qualité. Développé par Moonshot AI, il s'agit d'un modèle à l'échelle d'un trillion de paramètres conçu pour le raisonnement avancé, la génération de code de haute qualité et les tâches de rédaction générales complexes.
Dans la pratique, il semble équivalent à Claude Opus 4.5 pour de nombreux flux de travail, en particulier la programmation, le raisonnement structuré et la génération de textes longs.
L'un des principaux avantages de Kimi K2.5 est qu'il est entièrement open source. Cela signifie que n'importe qui peut télécharger les poids et exécuter le modèle par lui-même sans avoir recours à des API payantes ou à des plateformes fermées. Le compromis, bien sûr, réside dans l'échelle.
Cette section décrit la configuration matérielle, la mémoire et les prérequis GPU nécessaires pour exécuter Kimi K2.5 localement, y compris les performances attendues sur un seul GPU H200.
Espace disque
Mémoire (RAM + VRAM)
Exigences en matière de GPU
Pilotes GPU et CUDA
Nous allons maintenant configurer un pod GPU sur RunPod et le préparer pour l'exécution de Kimi K2.5.
Commencez par créer un nouveau pod dans RunPod et sélectionnez le GPU NVIDIA H200. Pour l'image du conteneur, veuillez sélectionner ledernier modèle PyTorch d' , disponible à l'adresse, car il inclut déjà la plupart des dépendances CUDA et d'apprentissage profond dont nous avons besoin. Après avoir sélectionné le modèle, veuillez cliquer surModifier l' pour ajuster les paramètres par défaut du pod.
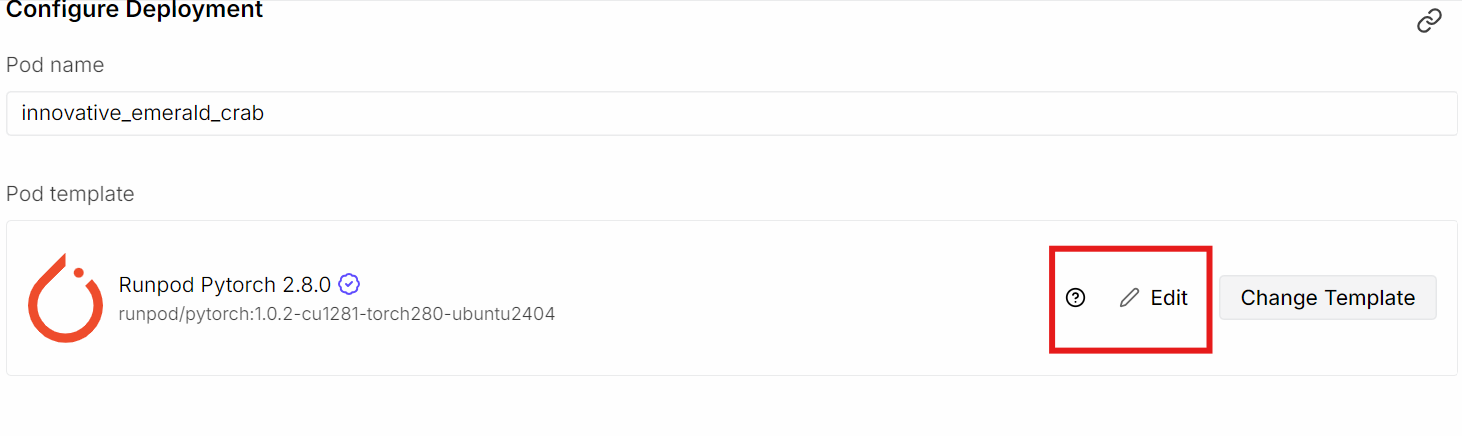
Veuillez mettre à jour la configuration du stockage comme suit :
Ensuite, veuillez exposer un port supplémentaire :
Nous exposons le port 8080 afin de pouvoir accéder au serveur llama.cpp et à l'interface utilisateur Web directement depuis le navigateur, que ce soit localement ou à distance, une fois que le serveur est opérationnel.
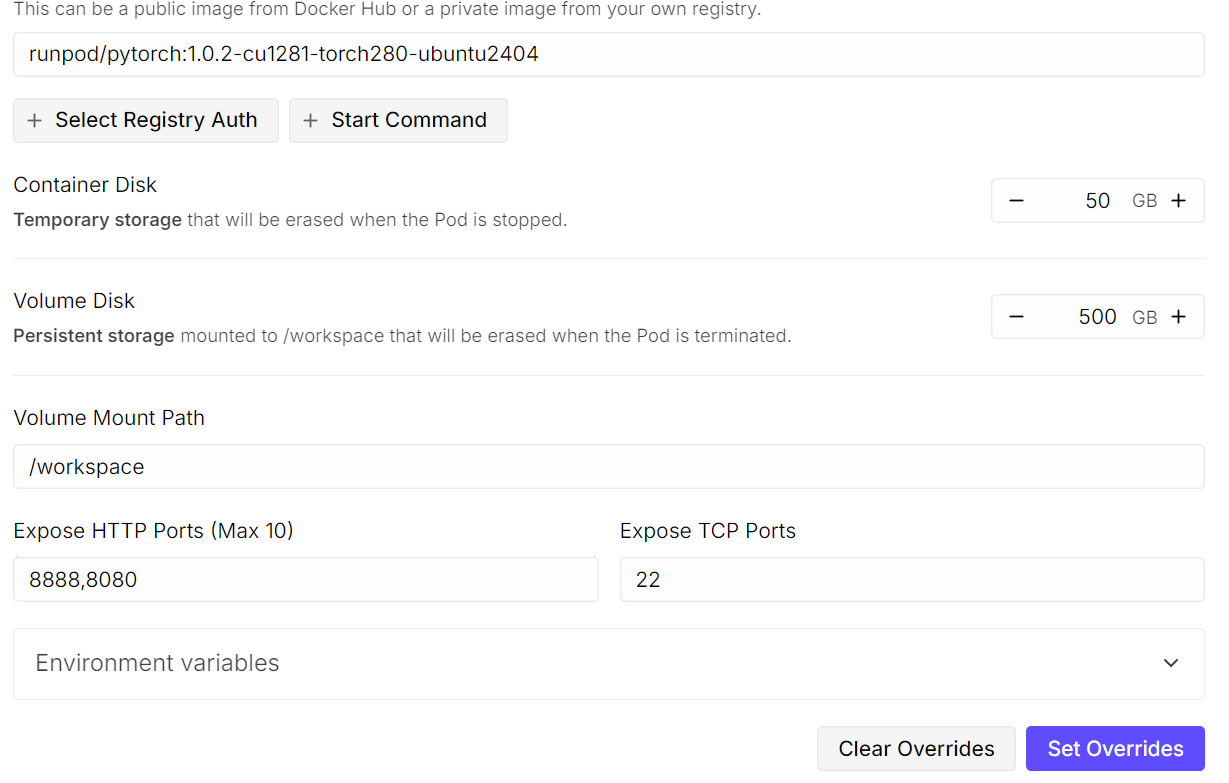
Après avoir enregistré ces paramètres, veuillez déployer le pod. Même avec un seul GPU, l'exécution d'un modèle tel que Kimi K2.5 est coûteuse, mais RunPod propose des options nettement plus rentables que les fournisseurs de cloud traditionnels.
Une fois le pod prêt, veuillez lancer l'interface Jupyter Lab. Depuis Jupyter Lab, veuillez ouvrir une session Terminal.
L'utilisation du terminal dans Jupyter est pratique, car elle permet d'ouvrir plusieurs sessions de terminal instantanément sans avoir à gérer des connexions SSH distinctes.
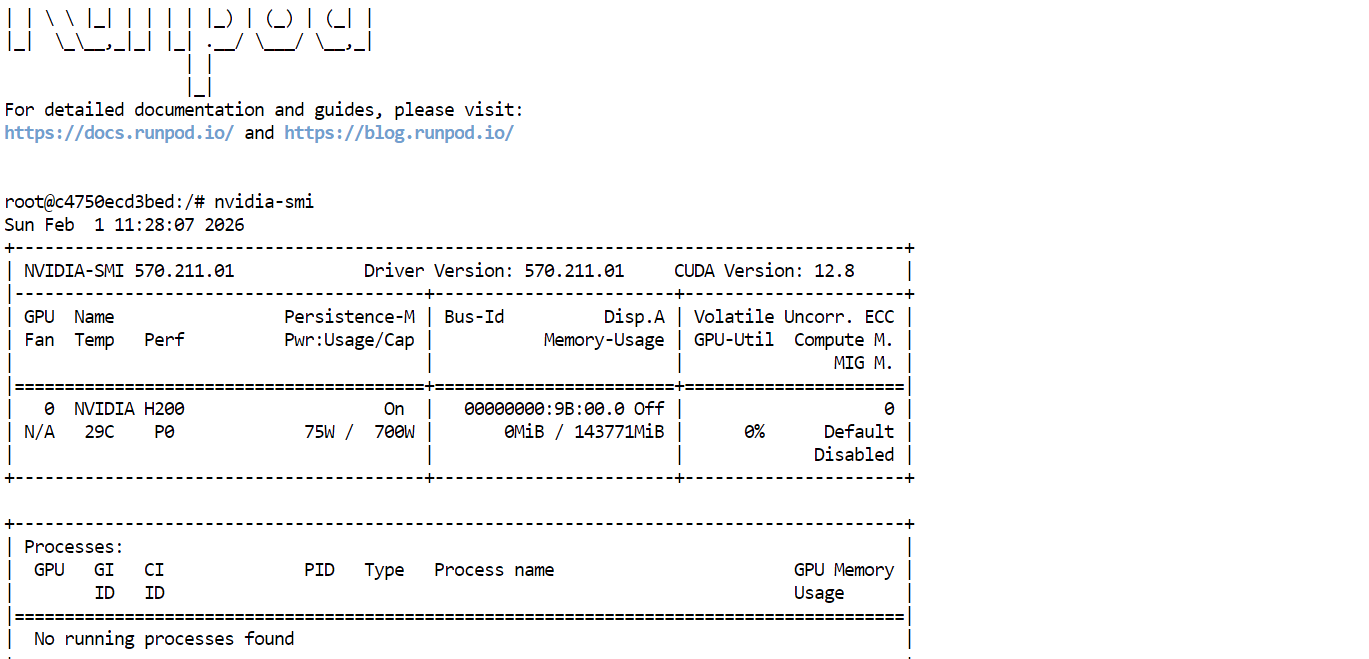
Veuillez d'abord vérifier que les pilotes GPU et CUDA sont correctement installés en exécutant :
nvidia-smiSi tout est correctement configuré, vous devriez voir le GPU H200 répertorié avec environ 144 Go de VRAM disponible.
Ensuite, veuillez installer les paquets Linux requis pour compiler llama.cpp à partir du code source :
sudo apt-get update
sudo apt-get install -y build-essential cmake curl git libcurl4-openssl-devNous allons maintenant compiler llama.cpp à partir du code source, car cette méthode est rapide, légère et nous offre les meilleures performances sur le GPU H200.
llama.cpp est un moteur d'inférence open source en C et C++ conçu pour exécuter des modèles linguistiques de grande taille. Il comprend un serveur HTTP intégré appelé llama-server, qui fournit des points de terminaison REST et une interface utilisateur Web pour interagir avec le modèle depuis votre navigateur.
Il prend également en charge les noyaux CUDA personnalisés et l'inférence hybride CPU + GPU, ce qui est utile lorsque les modèles ne tiennent pas entièrement dans la mémoire VRAM.
Tout d'abord, veuillez cloner le dépôt officiel llama.cpp :
git clone https://github.com/ggml-org/llama.cppEnsuite, veuillez configurer la compilation avec la prise en charge CUDA activée. Nous visons explicitement l'architecture CUDA 90, qui est requise pour les GPU NVIDIA H200 :
cmake /workspace/llama.cpp -B /workspace/llama.cpp/build \
-DGGML_CUDA=ON \
-DBUILD_SHARED_LIBS=OFF \
-DCMAKE_CUDA_ARCHITECTURES=90Veuillez maintenant compiler le binaire llama-server. Ce serveur sera utilisé ultérieurement pour exécuter Kimi K2.5 et exposer un point de terminaison HTTP et une interface utilisateur Web :
cmake --build /workspace/llama.cpp/build -j --clean-first --target llama-serverUne fois la compilation terminée, veuillez copier le fichier binaire à un emplacement approprié :
cp /workspace/llama.cpp/build/bin/llama-server /workspace/llama.cpp/llama-serverEnfin, veuillez vérifier que le binaire existe et qu'il a été compilé avec succès :
ls -la /workspace/llama.cpp | sed -n '1,60p'Nous allons maintenant télécharger le modèle Kimi K2.5 GGUF à partir de Hugging Face en utilisant Xet, qui permet des téléchargements nettement plus rapides pour les fichiers de modèles volumineux.
Tout d'abord, veuillez installer les outils de transfert Hugging Face et Xet requis :
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferActivez le backend de transfert à haut débit :
export HF_HUB_ENABLE_HF_TRANSFER=1Ensuite, veuillez télécharger le modèle quantifié 1,8 bits (UD-TQ1_0) depuis Hugging Face et l'enregistrer localement.
Nous utilisons ce quant car il offre le meilleur équilibre entre la qualité du modèle et la faisabilité matérielle, permettant à Kimi K2.5 de fonctionner sur un seul GPU H200 en déchargeant une partie du modèle vers la mémoire RAM du système tout en conservant une vitesse d'inférence utilisable.
hf download unsloth/Kimi-K2.5-GGUF \
--local-dir /workspace/models/Kimi-K2.5-GGUF \
--include "UD-TQ1_0/*"Même sans vous connecter à l'aide d'un jeton d'accès Hugging Face, vous devriez bénéficier d'une vitesse de téléchargement de 800 Mo par seconde ou plus sur RunPod.

Dans notre cas, le téléchargement complet a été effectué en environ 6 minutes. Le temps de téléchargement réel peut varier en fonction de la bande passante du réseau et des performances du disque.

Maintenant que le modèle est téléchargé et que llama.cpp est compilé avec le support CUDA, nous pouvons lancer Kimi K2.5 localement à l'aide du serveur HTTP llama.cpp.
Veuillez exécuter la commande suivante pour démarrer l' llama-server:
/workspace/llama.cpp/llama-server \
--model "/workspace/models/Kimi-K2.5-GGUF/UD-TQ1_0/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf" \
--alias "Kimi-K2.5" \
--host 0.0.0.0 \
--port 8080 \
--threads 32 \
--threads-batch 32 \
--ctx-size 20000\
--temp 0.8 \
--top-p 0.95 \
--min_p 0.01 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024\
--ubatch-size 256Fonctionnalité de chaque argument :
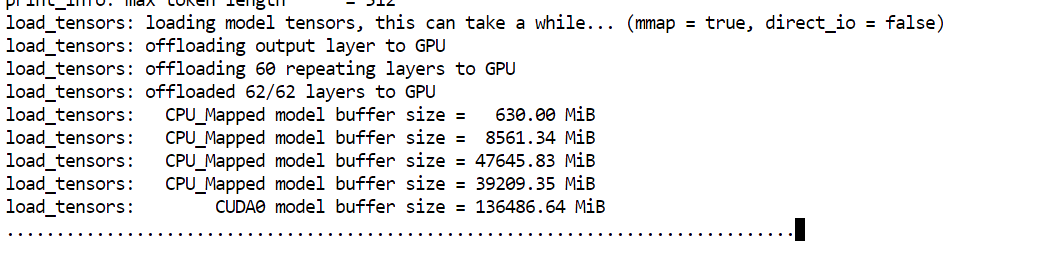
--model: Chemin d'accès au fichier modèle GGUF à charger--alias: Nom convivial utilisé pour identifier le modèle dans le serveur et l'interface utilisateur.--host: Interface réseau à laquelle le serveur doit se connecter (0.0.0.0 autorise l'accès externe)--port: Port HTTP utilisé pour exposer le serveur llama.cpp et l'interface utilisateur Web.--threads: Nombre de threads CPU utilisés pour l'inférence et le prétraitement--threads-batch: Threads CPU utilisés pour le traitement par lots des invites--ctx-size: Fenêtre contextuelle maximale taille de la fenêtre contextuelle en jetons--temp: Contrôle le caractère aléatoire des résultats générés--top-p: Seuil d'échantillonnage du noyau pour la sélection des jetons--min_p: Filtre les jetons à très faible probabilité--fit: Équilibre automatiquement les poids des modèles entre la mémoire VRAM et la mémoire RAM du système.--prio: Définit une priorité de processus plus élevée pour les charges de travail d'inférence.--jinja: Permet la création de modèles d'invites basés sur Jinja.--flash-attn: Active Flash Attention lorsqu'elle est prise en charge par le GPU--batch-size: Nombre de jetons traités par lot GPU--ubatch-size: Taille des micro-lots pour équilibrer l'utilisation de la mémoire et le débitAu démarrage, vous constaterez que le modèle charge environ 136 Go dans la mémoire du GPU, les poids restants étant transférés vers la mémoire RAM du système.
Remarque : Si le serveur llama.cpp ne détecte pas le GPU et démarre sur le CPU, veuillez redémarrer le pod. Si le problème persiste, veuillez supprimer la compilation existante et recompiler llama.cpp en activant la prise en charge CUDA.
Une fois le chargement terminé, le serveur affiche une URL d'accès. Veuillez ouvrir l'interface utilisateur Web dans votre navigateur à l'adresse suivante :
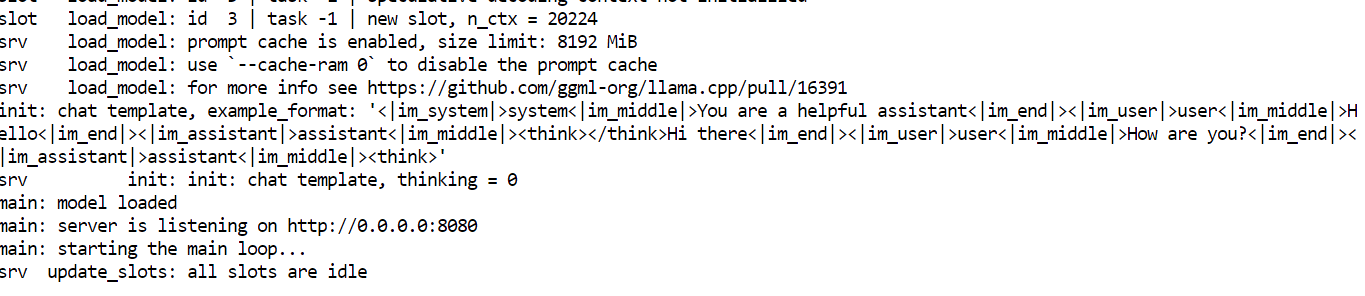
Remarque : Si vous rencontrez une erreur lors de l'exécution de nvidia-smi, il est probable que le processus se soit interrompu en raison d'une pression sur la mémoire. Veuillez redémarrer le pod. Tous les fichiers de modèle sont conservés sur le disque persistant.
Une fois que le serveur llama.cpp est opérationnel, vous pouvez y accéder via l'interface utilisateur Web exposée sur le port 8080. interface utilisateur Web accessible sur le port 8080.
Pour l'ouvrir, veuillez vous rendre sur le tableau de bord RunPod, sélectionner votre pod de course et cliquer sur le lien affiché à côté du port 8080. Cela ouvre l'interface utilisateur Web llama.cpp directement dans votre navigateur.
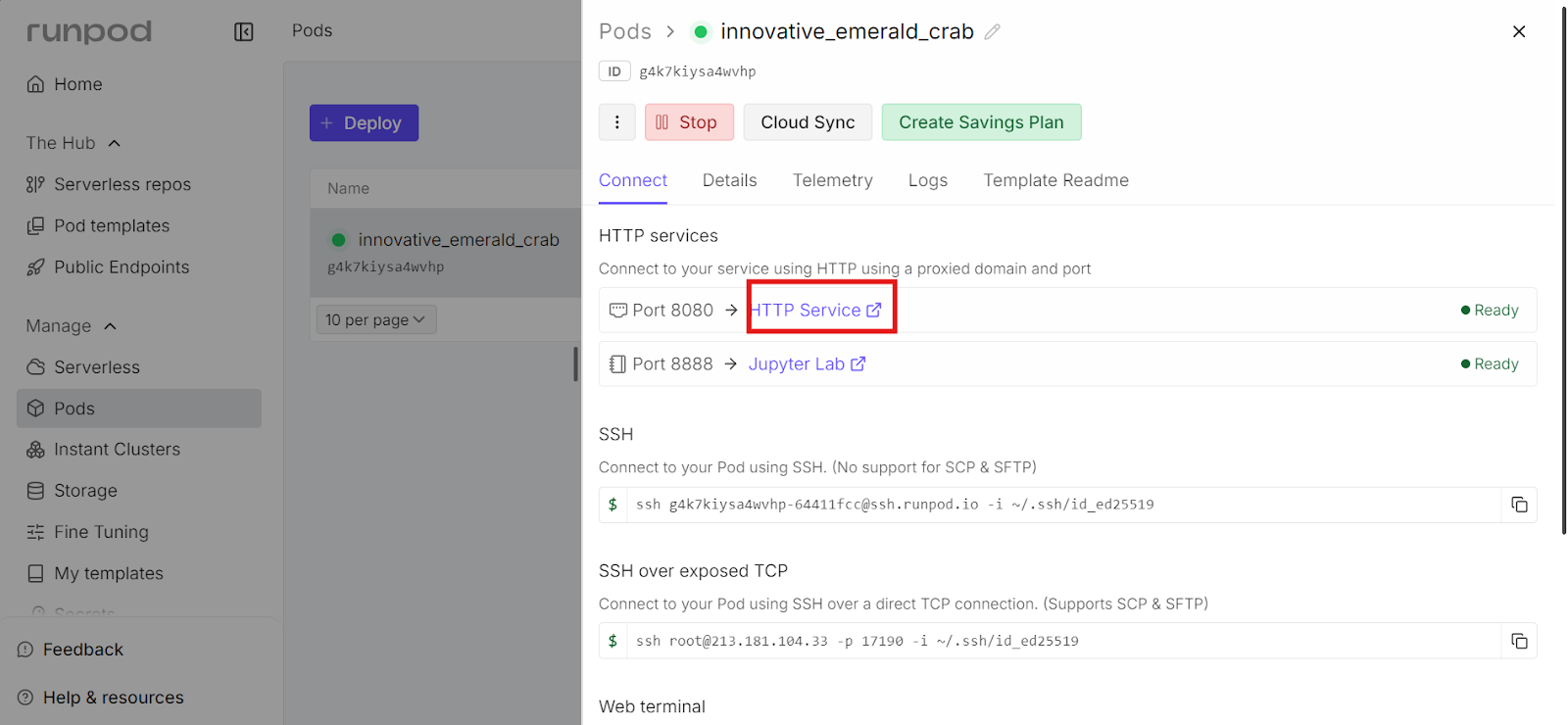
L'interface utilisateur Web offre une interface simple de type chat, similaire à chatGPT, mais fonctionnant entièrement sur votre propre instance RunPod. L'URL est accessible au public. Vous pouvez partager ce lien avec vos collègues ou collaborateurs si nécessaire.
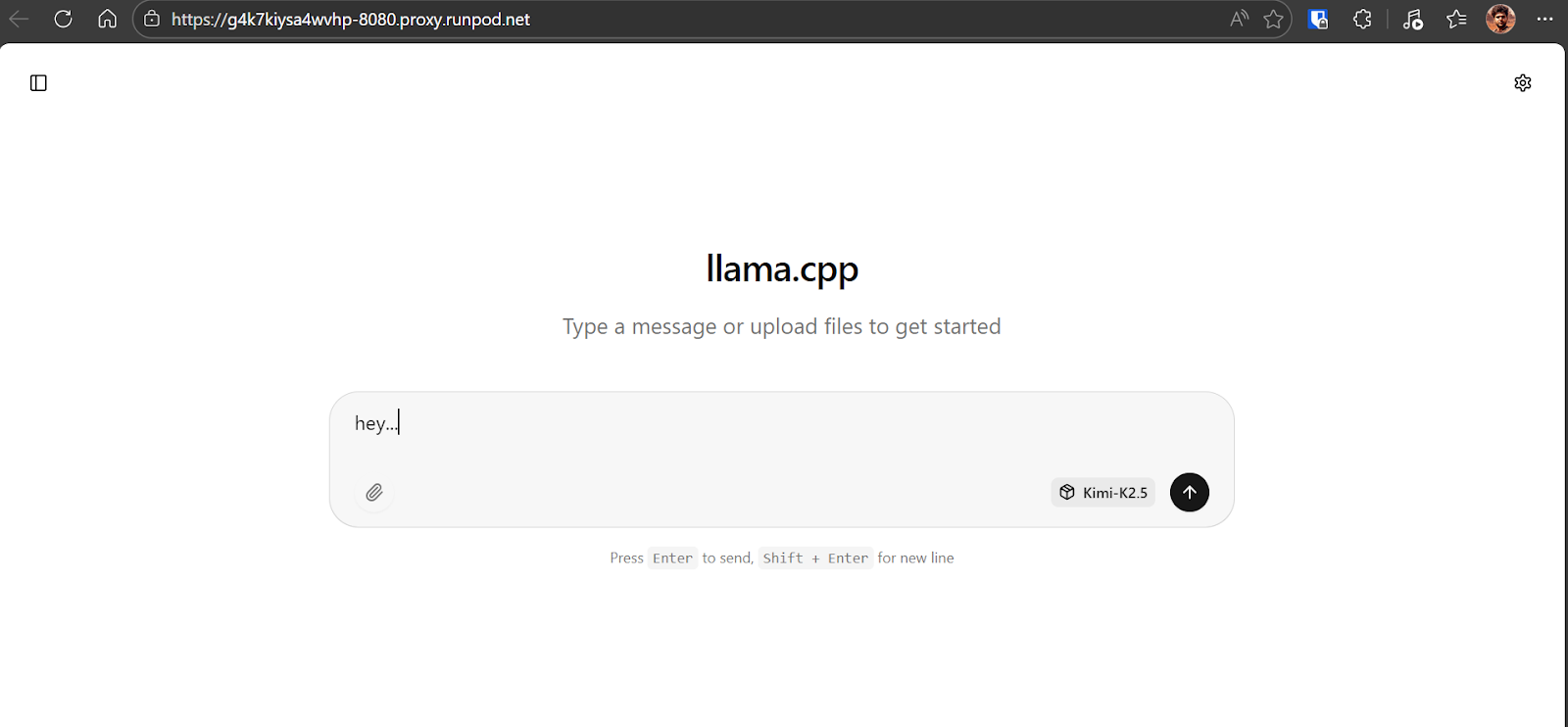
Commencez par envoyer une simple commande au modèle Kimi K2.5 afin de vérifier que tout fonctionne correctement. Dans notre cas, le modèle répond à environ 6 à 7 jetons par seconde, ce qui est conforme aux attentes pour le quant 1,8 bits fonctionnant sur un seul GPU H200 avec déchargement partiel de la RAM. Il s'agit d'une base de référence solide qui confirme que le modèle utilise correctement le GPU.
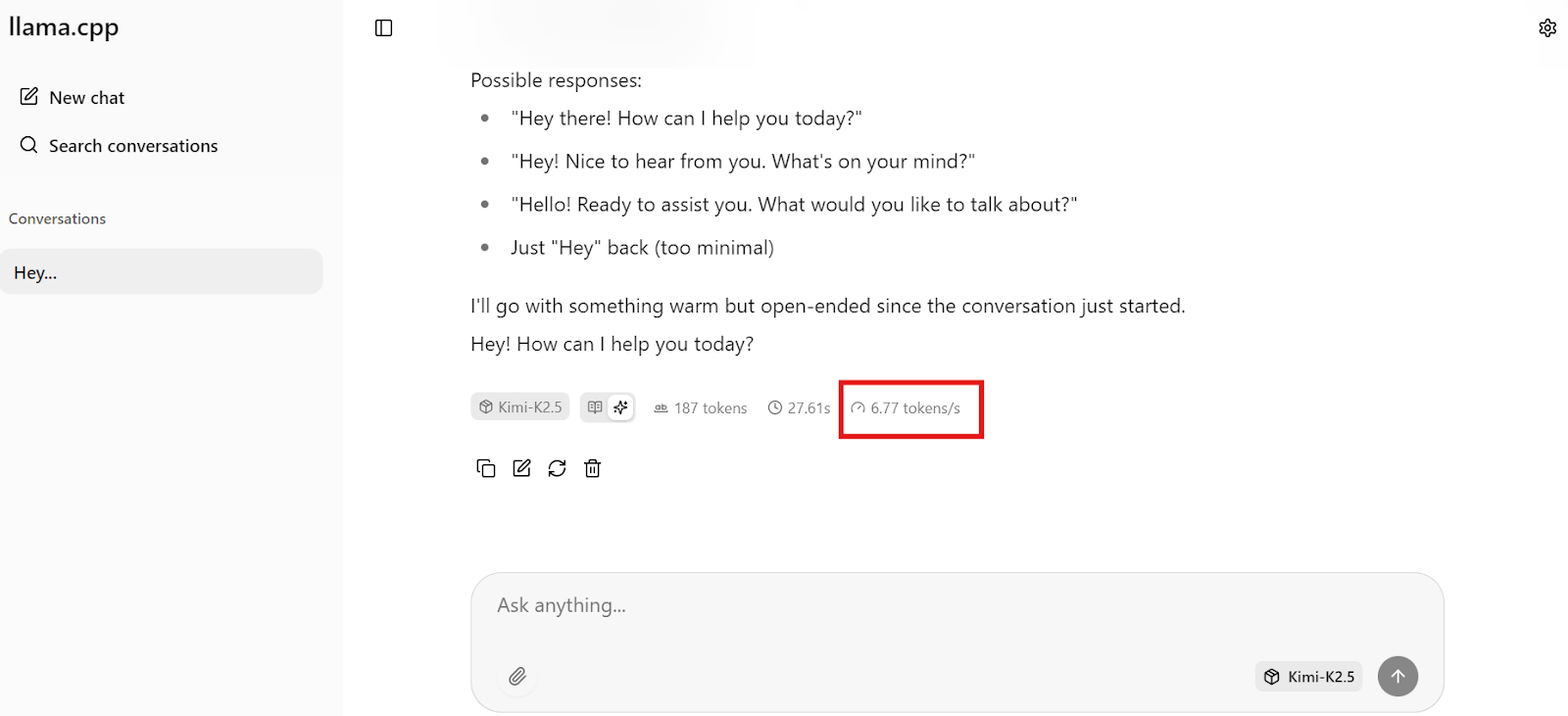
Remarque : L'interface utilisateur Web llama.cpp ne sépare pas clairement le raisonnement du résultat final, vous pouvez donc voir les deux mélangés en raison de problèmes de modèle.
Kimi CLI est un agent de codage et de raisonnement basé sur un terminal développé par Moonshot AI. Il est conçu pour faciliter les tâches de codage, les flux de travail shell et les modifications au niveau du projet directement à partir de votre ligne de commande. Contrairement à une simple interface de chat, Kimi CLI peut fonctionner dans votre répertoire de travail, ce qui le rend particulièrement adapté aux processus de développement réels.
Pour l'inférence locale, l'avantage principal de Kimi CLI réside dans le fait qu'il prend en charge les API compatibles avec OpenAI. Cela nous permet de le diriger directement vers notre serveur local llama-server, permettant ainsi à Kimi K2.5 de fonctionner entièrement sur notre propre matériel sans dépendre d'aucun service API hébergé ou payant.
Veuillez commencer par exécuter le script d'installation officiel :
curl -LsSf https://code.kimi.com/install.sh | bashEnsuite, veuillez ajouter le binaire à votre PATH afin que le commande kimi soit disponible dans votre terminal :
export PATH="/root/.local/bin:$PATH"Veuillez vérifier que l'installation s'est déroulée avec succès :
kimi --versionVous devriez obtenir un résultat similaire à kimi, version 1.5.
Veuillez créer le répertoire de configuration utilisé par Kimi CLI :
mkdir -p ~/.kimiVeuillez maintenant créer le fichier de configuration. Cela indique à Kimi CLI de traiter votreserveur local llama.cpp comme un fournisseur compatible avec OpenAI fonctionnant à l'adresse http://127.0.0.1:8080/v1. Il enregistre également une entrée de modèle local qui correspond à l'alias que vous avez spécifié lors du lancement de llama-server.
cat << 'EOF' > ~/.kimi/config.toml
[providers.local_llama]
type = "openai_legacy"
base_url = "http://127.0.0.1:8080/v1"
api_key = "sk-no-key-required"
[models.kimi_k25_local]
provider = "local_llama"
model = "Kimi-K2.5"
max_context_size = 20000
EOFVeuillez vous assurer que la valeur de l'model correspond exactement à l'--alias utilisé lors du démarrage de llama-server. Le champ « api_key » est un espace réservé et n'est pas obligatoire pour l'inférence locale.
Dans cette section, nous utiliserons Kimi CLI connecté à notre serveur local Kimi K2.5 pour créer en une seule fois un jeu Snake entièrement jouable à l'aide du codage vibe.
Tout d'abord, veuillez créer un nouveau répertoire de projet et vous y rendre :
mkdir -p /workspace/snake-game
cd /workspace/snake-gameEnsuite, veuillez lancer l'interface CLI Kimi :
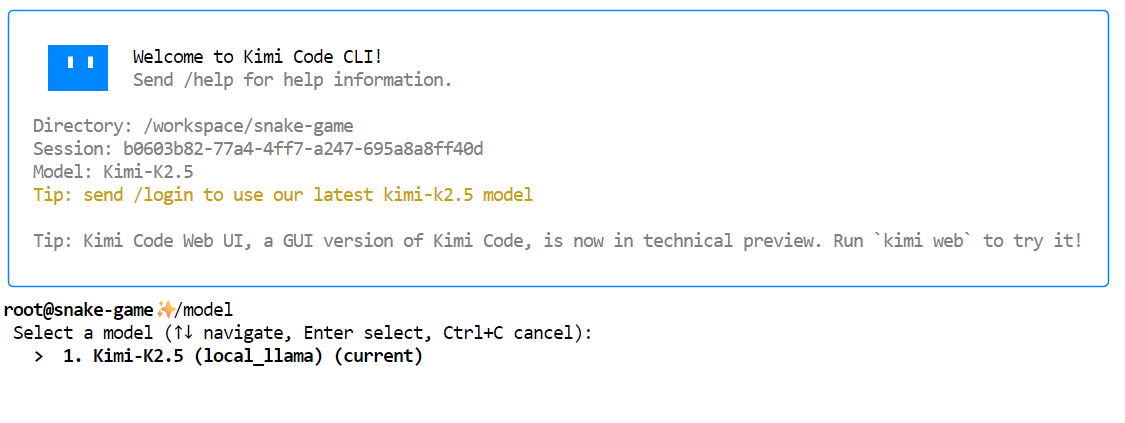
kimiUne fois Kimi CLI lancé, veuillez saisir /model et sélectionner le modèle local Kimi K2.5 que nous avons configuré précédemment. Veuillez consulter le site . Le modèleKimi-K2.5 est répertorié comme disponible.
 Veuillez maintenant demander à Kimi de générer le jeu. Veuillez utiliser une instruction simple et directe telle que celle-ci :
Veuillez maintenant demander à Kimi de générer le jeu. Veuillez utiliser une instruction simple et directe telle que celle-ci :
"Create a simple Snake game as a single self-contained file named index.html."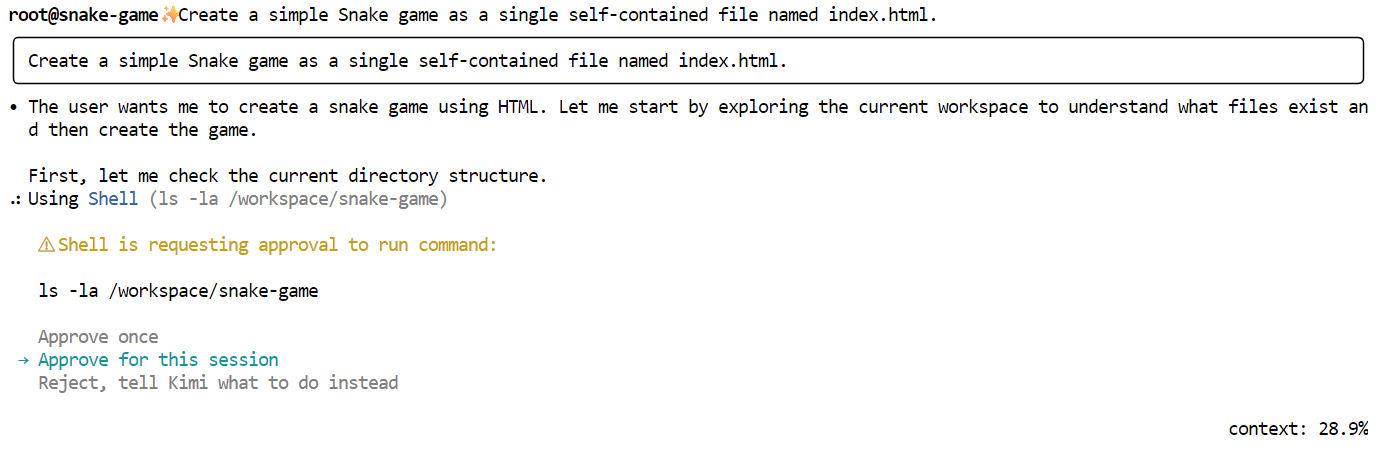
Kimi commencera par vous présenter un plan et vous demandera votre accord. Veuillez lire attentivement et approuver la demande.

Une fois approuvé, Kimi générera le fichier d' index.html s complet, comprenant HTML, CSS et JavaScript, le tout en un seul endroit.
Une fois le fichier généré, veuillez le télécharger ou le copier localement et l'ouvrir dans votre navigateur. Le jeu démarre immédiatement.
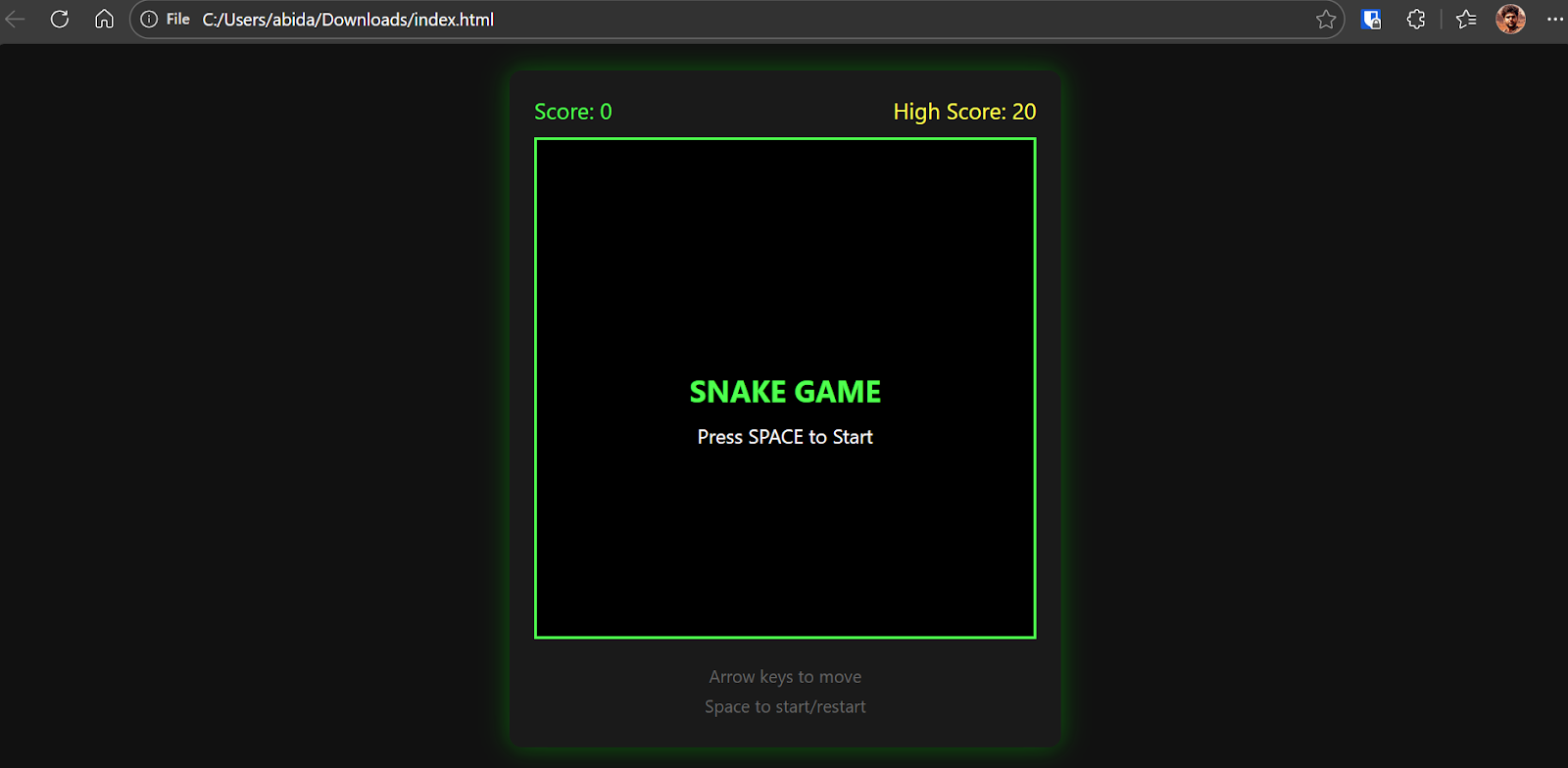
Le résultat est un jeu Snake entièrement fonctionnel, avec des mouvements fluides, des graphismes épurés et des fonctionnalités de jeu classiques.
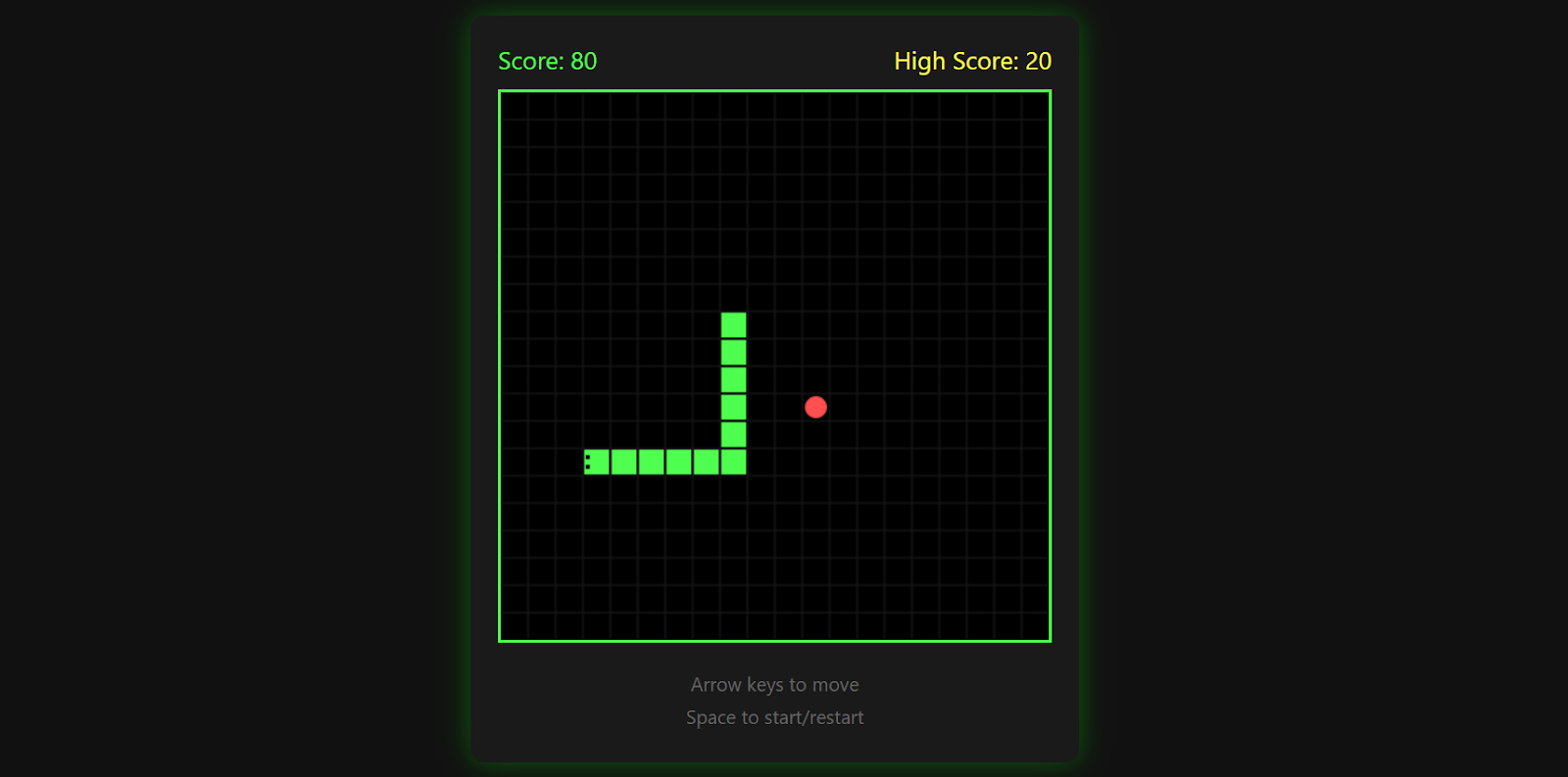
Le jeu enregistre votre meilleur score, se termine lorsque vous heurtez un mur et vous permet de recommencer en appuyant à nouveau sur la barre d'espace.
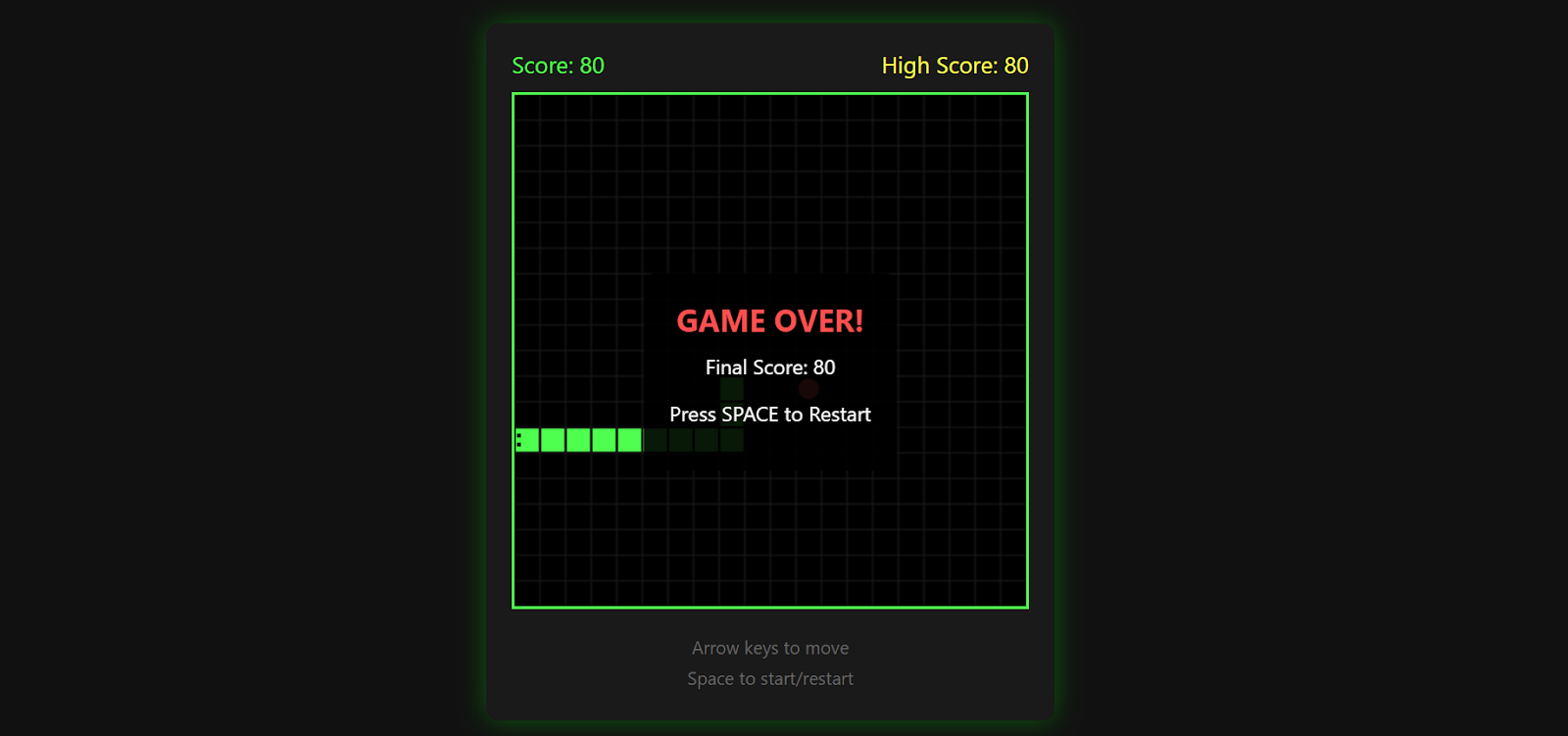
Il est remarquablement abouti pour une seule invite et constitue une excellente démonstration de ce que Kimi K2.5 peut générer lorsqu'il est associé à Kimi CLI et à une configuration d'inférence locale.
Pour être tout à fait honnête, j'ai trouvé que créer un jeu entièrement fonctionnel en une seule fois était plus frustrant que prévu.
Bien que Kimi K2.5 soit clairement performant, le modèle a souvent des difficultés à déterminer quand cesser d'itérer sur une tâche. Dans la pratique, cela conduit souvent à surcharger le problème.
Par exemple, lorsqu'on lui demande de créer un jeu Snake dans Pygame, il peut revenir à une implémentation HTML, et lorsqu'on lui demande du HTML, il peut revenir à une approche basée sur Python.
Ces allers-retours impliquent que vous devez souvent intervenir à plusieurs reprises pour que le modèle reste conforme à votre intention.
Une grande partie de ce comportement est due à l'de quantification 1,8 bits. Bien que les modes 1 bit et sub-2 bits permettent d'exécuter un modèle extrêmement volumineux sur un matériel limité, ils présentent certains inconvénients.
Le modèle est toujours en mesure de générer des réponses cohérentes, mais il rencontre davantage de difficultés avec la terminaison des tâches, le raisonnement à long terme, la planification structurée et l'appel de fonctions. Ce sont précisément les domaines qui revêtent le plus d'importance pour les flux de travail de type agent et les tâches de codage en plusieurs étapes.
De manière réaliste, Kimi K2.5 commence à se démarquer avec des précisions d' splus élevées, telles que 4 bits ou plus. À ce niveau, la planification s'améliore considérablement et le modèle se comporte de manière plus prévisible.
L'inconvénient est évident. Une précision plus élevée nécessite une quantité de RAM et de VRAM considérablement plus importante, ce qui la rend inaccessible pour de nombreuses configurations locales. D'un point de vue purement axé sur le rapport taille/performances à faible précision, les modèles tels que GLM 4.7 offrent actuellement une expérience plus fluide pour de nombreux utilisateurs.
Cela dit, si l'on fait abstraction des contraintes matérielles et que l'on utilise Kimi K2.5 avec une précision plus élevée ou via une API hébergée, le modèle est véritablement remarquable. Sa profondeur de raisonnement, la qualité de sa génération de code et sa gestion de contextes longs sont suffisamment solides pour qu'il puisse remplacer les modèles propriétaires dans de nombreux flux de travail.
En effet, lorsqu'elle est utilisée via l' API Kimi AI, elle est suffisamment performante pour justifier le passage à celle-ci de l'ensemble du flux de travail de codage d'ambiance.
Pour approfondir les concepts abordés ici, je vous recommande les ressources suivantes :
Meilleurs cours DataCamp
Cours
Cours
Cours