programa
Fundamentos de la IA
10 h
Según los ejemplos de Meta, los modelos pueden analizar gráficos incrustados en documentos y resumir las tendencias clave. También pueden interpretar mapas, determinar qué parte de una ruta de senderismo es la más empinada o calcular la distancia entre dos puntos.
Esta integración del razonamiento de texto e imagen ofrece una amplia gama de aplicaciones potenciales, entre las que se incluyen:
Los modelos de visión de Llama 3.2 son abiertos y personalizables. Los desarrolladores pueden afinar tanto las versiones pre-entrenadas como las alineadas de estos modelos utilizando el programa Meta Torchtune de Meta.
Además, estos modelos pueden desplegarse localmente a través de Torchchatreduciendo la dependencia de la nube y proporcionando una solución a los desarrolladores que desplegar sistemas de IA on-prem o en entornos con recursos limitados.
Los modelos de visión también están disponibles para su prueba a través de Meta AI, el asistente inteligente de Meta.
Para que los modelos de visión de Llama 3.2 puedan comprender tanto texto como imágenes, Meta integró un codificador de imágenes preentrenado codificador de imágenes en el modelo de lenguaje existente mediante adaptadores especiales. Estos adaptadores enlazan los datos de imagen con las partes de procesamiento de texto del modelo, permitiéndole manejar ambos tipos de entrada.
El proceso de entrenamiento comenzó con el modelo lingüístico Llama 3.1. En primer lugar, el equipo lo entrenó con grandes conjuntos de imágenes emparejadas con descripciones de texto para enseñar al modelo a conectarlas. Después, lo perfeccionaron utilizando datos más limpios y específicos para mejorar su capacidad de comprensión y razonamiento sobre el contenido visual.
En las etapas finales, Meta utilizó técnicas como ajuste fino y datos sintéticos para garantizar que el modelo diera respuestas útiles y se comportara con seguridad.
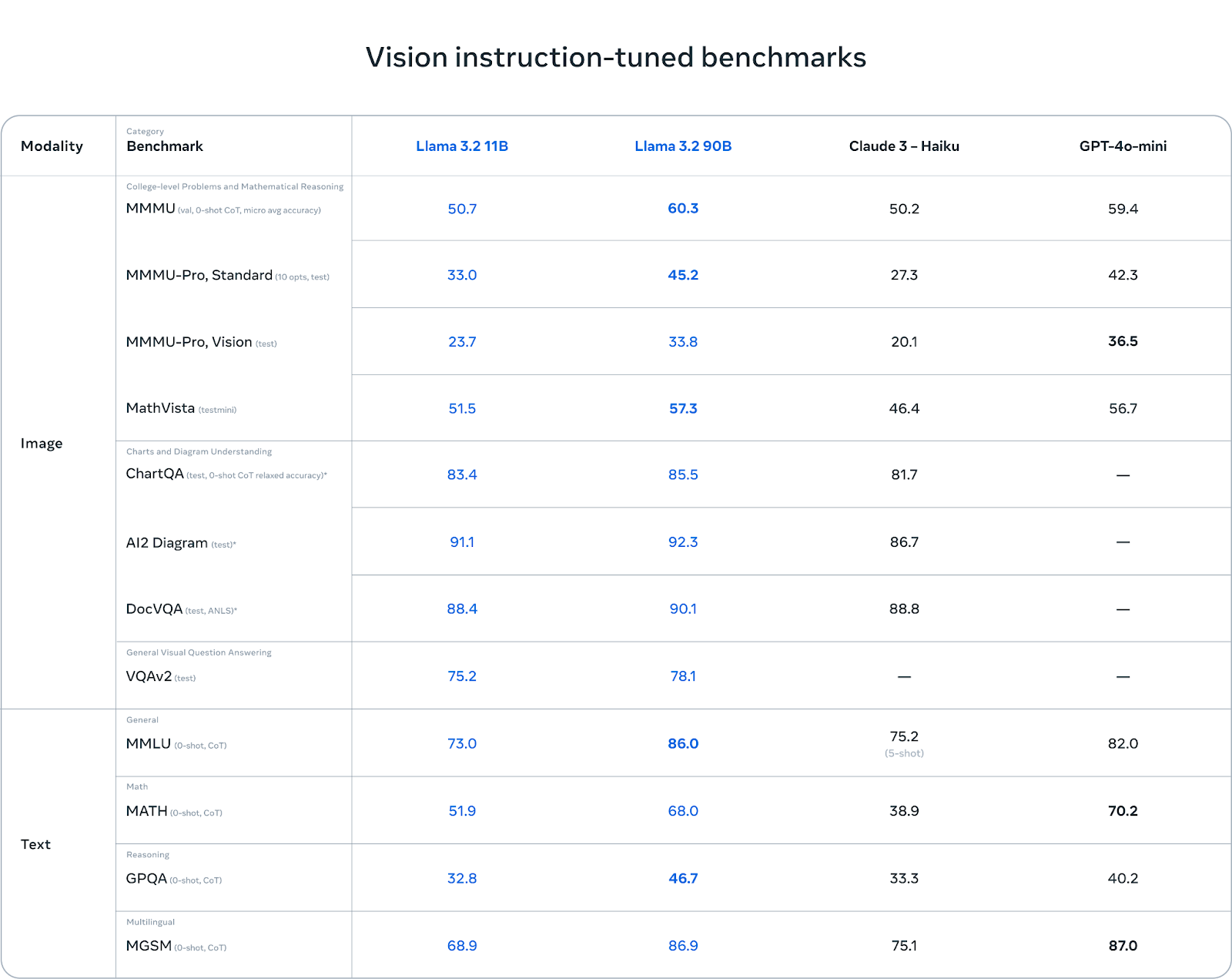
Los modelos de visión Llama 3.2 brillan en comprensión de gráficos y diagramas. En pruebas comparativas como AI2 Diagram (92,3) y DocVQA (90,1), Llama 3.2 supera a Claude 3 Haiku. Esto lo convierte en una opción excelente para tareas de comprensión de documentos, respuesta a preguntas visuales y extracción de datos de gráficos.
En las tareas multilingües (MGSM), Llama 3.2 también rinde bien, casi igualando a GPT-4o-mini con una puntuación de 86,9, lo que la convierte en una opción sólida para los desarrolladores que trabajan con varios idiomas.
Fuente: Meta AI
Aunque Llama 3.2 rinde bien en tareas basadas en la visión, se enfrenta a retos en otras áreas. En MMMU-Pro Vision, que pone a prueba el razonamiento matemático sobre datos visuales, GPT-4o-mini supera a Llama 3.2 con una puntuación de 36,5 frente al 33,8 de Llama.
Del mismo modo, en la prueba de referencia MATH, el rendimiento de GPT-4o-mini (70,2) supera significativamente a Llama 3.2 (51,9), lo que demuestra que Llama aún tiene margen de mejora en las tareas de razonamiento matemático.
Otro avance significativo de Llama 3.2 es la introducción de modelos ligeros diseñados para dispositivos edge y móviles. Estos modelos, con 1.000 y 3.000 millones de parámetros, están optimizados para funcionar en hardware más pequeño, manteniendo un compromiso razonable en cuanto al rendimiento.
Estos modelos están diseñados para funcionar en dispositivos móviles, proporcionando un procesamiento rápido y local sin necesidad de enviar datos a la nube. Ejecutar modelos localmente en dispositivos de borde ofrece dos ventajas principales:
Los modelos ligeros de Llama 3.2 están optimizados para los procesadores Arm y son compatibles con el hardware de Qualcomm y MediaTek, que alimentan muchos dispositivos móviles y de vanguardia en la actualidad.
Los modelos ligeros están diseñados para diversas aplicaciones prácticas en el dispositivo, como:
1. Resumiendo: Los usuarios pueden resumir grandes cantidades de texto, como correos electrónicos o notas de reuniones, directamente en su dispositivo sin depender de servicios en la nube.
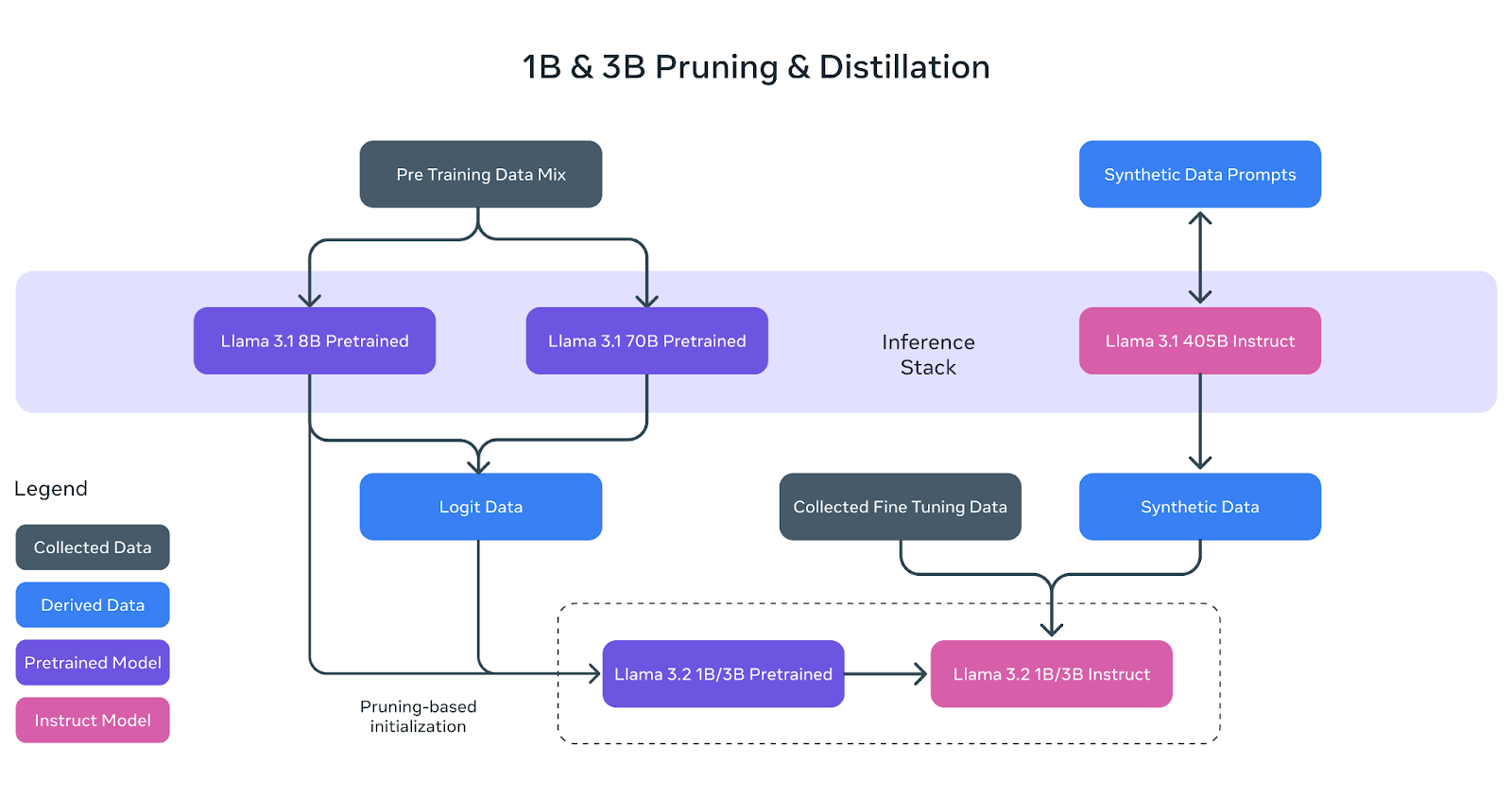
Los modelos ligeros Llama 3.2 (1B y 3B) se construyeron para adaptarse con eficacia a los dispositivos móviles y de borde, manteniendo un gran rendimiento. Para conseguirlo, Meta utilizó dos técnicas clave: la poda y la destilación.
Fuente: Meta AI
La poda ayuda a reducir el tamaño de los modelos Llama originales eliminando las partes menos críticas de la red y conservando al mismo tiempo todo el conocimiento posible. En el caso de los modelos 1B y 3B de Llama 3.2, este proceso comenzó con el modelo preentrenado más grande Llama 3.1 8B.
Mediante la poda sistemática, el equipo de Meta AI pudo crear versiones más pequeñas y eficientes del modelo sin una pérdida significativa de rendimiento. Esto se representa en el diagrama anterior, donde el modelo 8B preentrenado (recuadro morado) se poda y refina para convertirse en la base de los modelos Llama 3.2 1B/3B más pequeños.
La destilación es el proceso de transferencia de conocimientos de un modelo más grande y potente (el "maestro") a un modelo más pequeño (el "alumno"). En Llama 3.2, los logits (predicciones) de los modelos mayores Llama 3.1 8B y Llama 3.1 70B se utilizaron para enseñar los modelos más pequeños.
De este modo, los modelos 1B y 3B, más pequeños, podían aprender a realizar tareas con mayor eficacia, a pesar de su tamaño reducido. El diagrama anterior muestra cómo este proceso utiliza los datos logits de los modelos mayores para guiar a los modelos 1B y 3B durante el preentrenamiento.
Tras la poda y la destilación, los modelos 1B y 3B se sometieron a un post-entrenamiento, similar al de los modelos Llama anteriores. Esto implicó técnicas como el ajuste fino supervisado, el muestreo de rechazo y la optimización directa de las preferencias para alinear los resultados de los modelos con las expectativas de los usuarios.
También se generaron datos sintéticos para garantizar que los modelos pudieran manejar una amplia gama de tareas, como resumir, reescribir y seguir instrucciones.
Como se muestra en el diagrama, los modelos finales de instrucción Llama 3.2 1B/3B son el resultado de la poda, la destilación y un amplio post-entrenamiento.
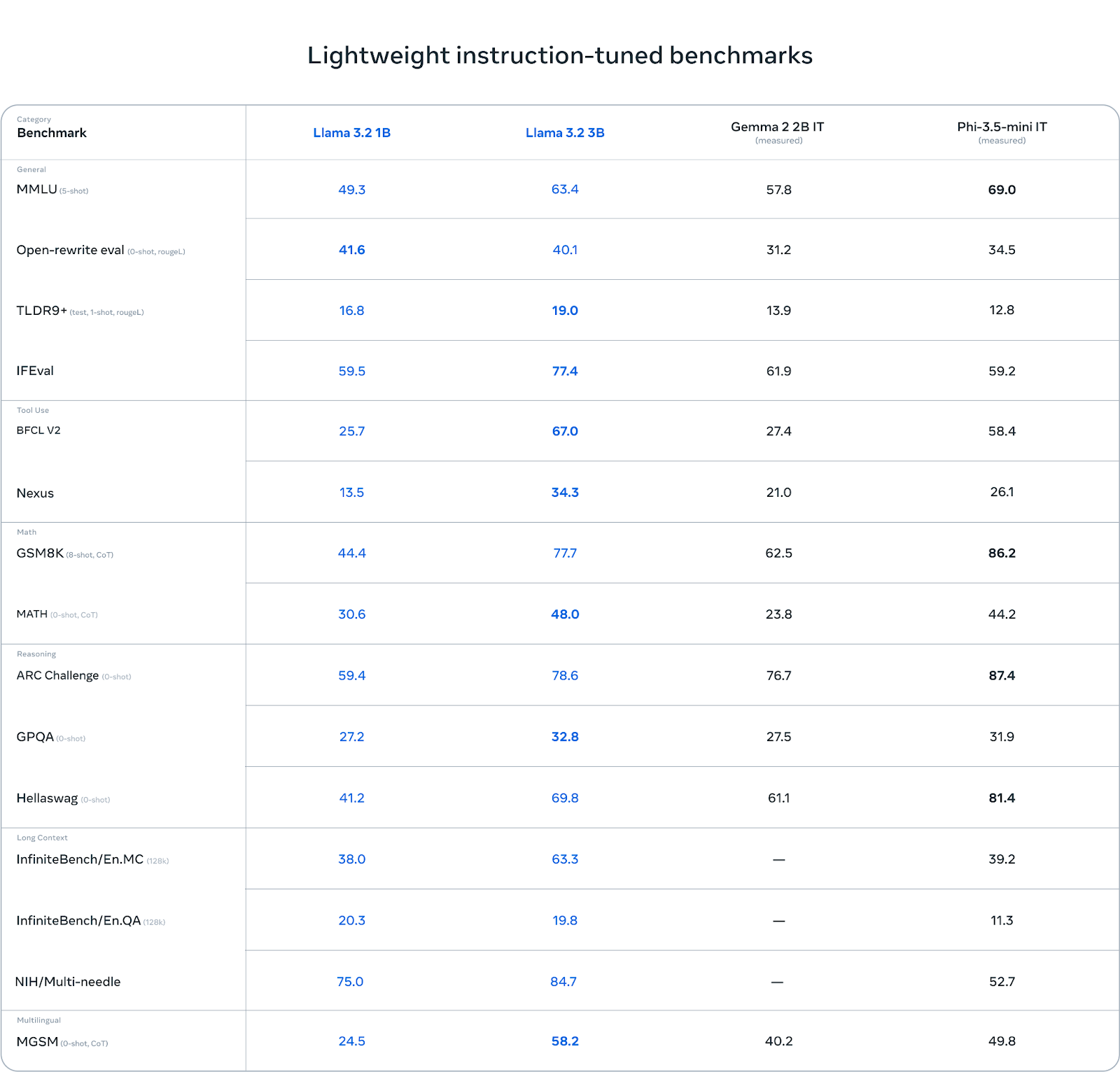
Llama 3.2 3B destaca en ciertas categorías, especialmente en tareas que implican razonamiento. Por ejemplo, en el Desafío ARC, obtiene una puntuación de 78,6, superando a Gemma (76,7) y quedando ligeramente por detrás de Phi-3,5-mini (87,4). Del mismo modo, obtiene buenos resultados en la prueba comparativa Hellawag, alcanzando 69,8, superando a Gemma y manteniéndose competitivo con Phi.
En tareas de uso de herramientas como BFCL V2, Llama 3.2 3B también brilla con una puntuación de 67,0, por delante de ambos competidores. Esto demuestra que el modelo 3B maneja con eficacia las tareas de seguimiento de instrucciones y las relacionadas con las herramientas.
Fuente: Meta AI
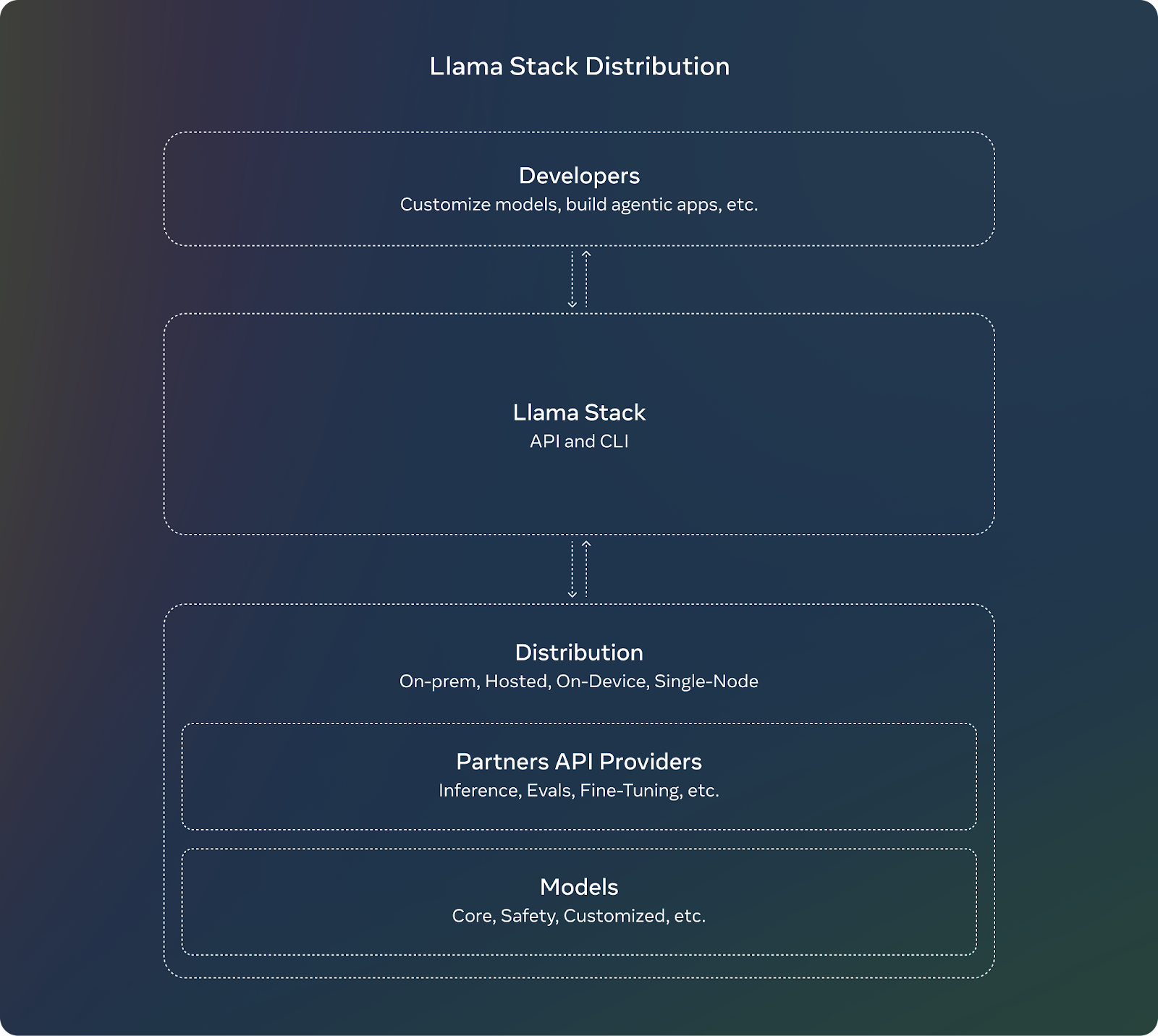
Para complementar el lanzamiento de Llama 3.2, Meta presenta la Pila Llama. Para los desarrolladores, utilizar la Pila Llama significa que no tienen que preocuparse de los complejos detalles de configurar o desplegar grandes modelos. Pueden centrarse en crear sus aplicaciones y confiar en que la Pila Llama se encargará de gran parte del trabajo pesado.
Estas son las características clave de la Pila Llama:
Fuente: Meta AI
Meta sigue centrándose en IA responsable con Llama 3.2. Llama Guard 3 se ha actualizado para incluir una versión con visión que admite las nuevas capacidades multimodales de Llama 3.2. Esto garantiza que las aplicaciones que utilicen las nuevas funciones de comprensión de imágenes sigan siendo seguras y cumplan las directrices éticas.
Además, Llama Guard 3 1B se ha optimizado para su despliegue en entornos con recursos más limitados, haciéndolo más pequeño y eficiente que las versiones anteriores.
Acceder y descargar los modelos Llama 3.2 es bastante sencillo. Meta ha puesto estos modelos a disposición en múltiples plataformas, incluyendo su propio sitio web y Hugging Face, una popular plataforma para alojar y compartir modelos de IA.
Puedes descargar los modelos Llama 3.2 directamente del sitio web oficial de Llama. Meta ofrece tanto los modelos más pequeños y ligeros (1B y 3B) como los modelos más grandes con visión (11B y 90B) para que los desarrolladores los utilicen.
Cara de abrazo es otra plataforma en la que están disponibles los modelos Llama 3.2. Proporciona un acceso fácil y lo utilizan habitualmente los desarrolladores de la comunidad de IA.
Los modelos Llama 3.2 están disponibles para su desarrollo inmediato en nuestro amplio ecosistema de plataformas asociadas, como AMD, AWS, Databricks, Dell, Google Cloud, Groq, IBM, Intel, Microsoft Azure, NVIDIA, Oracle Cloud y Snowflake, entre otras.
El lanzamiento de Meta de Llama 3.2 introduce los primeros modelos multimodales de la serie, centrándose en dos áreas clave: modelos habilitados para visión y modelos ligeros para dispositivos edge y móviles.
Los modelos multimodales 11B y 90B ahora pueden procesar tanto texto como imágenes, mientras que los modelos 1B y 3B están optimizados para un uso local eficiente en dispositivos más pequeños.
En este artículo he expuesto lo esencial: cómo funcionan estos modelos, sus aplicaciones prácticas y cómo puedes acceder a ellos.
Aprende IA con estos cursos
programa
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Ryan Ong
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita

