
Track
Developing Large Language Models
16 hr
In this tutorial, we'll explore how to fine-tune the Llama 3 8B model using the LlaMA-Factory WebUI on the Wikipedia Q&A dataset. We'll begin by introducing the LlaMA-Factory WebUI, followed by setting it up within the Google Colab environment. Once configured, we'll walk through the process of fine-tuning the Llama 3 8B model on the dataset and then evaluate the model's performance through the chat interface.
As we progress, you'll also learn how to load custom datasets, merge models, and export them to Hugging Face. Finally, we'll cover how to deploy the fine-tuned model, making it accessible via the OpenAI API.
You can gain actionable knowledge on popular AI topics like ChatGPT, large language models, generative AI, and more by taking the AI Fundamentals skill track.

Image by Author | Canva
hiyouga/LLaMA-Factory is an open-source project that lets you fine-tune over 100 large language models (LLMs) through a WebUI interface. It provides a comprehensive set of tools and scripts for fine-tuning, chatbot, serving, and benchmarking LLMs.
LLaMA-Factory is designed specifically for beginners and non-technical professionals who wish to fine-tune open-source LLMs on their custom datasets without learning complex concepts of AI. Users simply need to select a model, add their dataset, and adjust a few parameters to initiate the training process.
Once training is complete, the same web application can be used to test the model, after which it can be exported to Hugging Face or saved locally. This provides a fast and efficient way to fine-tune LLMs locally.
In this section, we will learn how to install and launch LlaMA-Factory WebUI in Google Colab and Microsoft Windows.
Google Colab provides access to free GPUs, so if your laptop does not have GPU or CUDA installed. I recommended that you get started with a Colab notebook.
%cd /content/
%rm -rf LLaMA-Factory
!git clone https://github.com/hiyouga/LLaMA-Factory.git
%cd LLaMA-Factory
%ls
%pip install -e .[torch,bitsandbytes]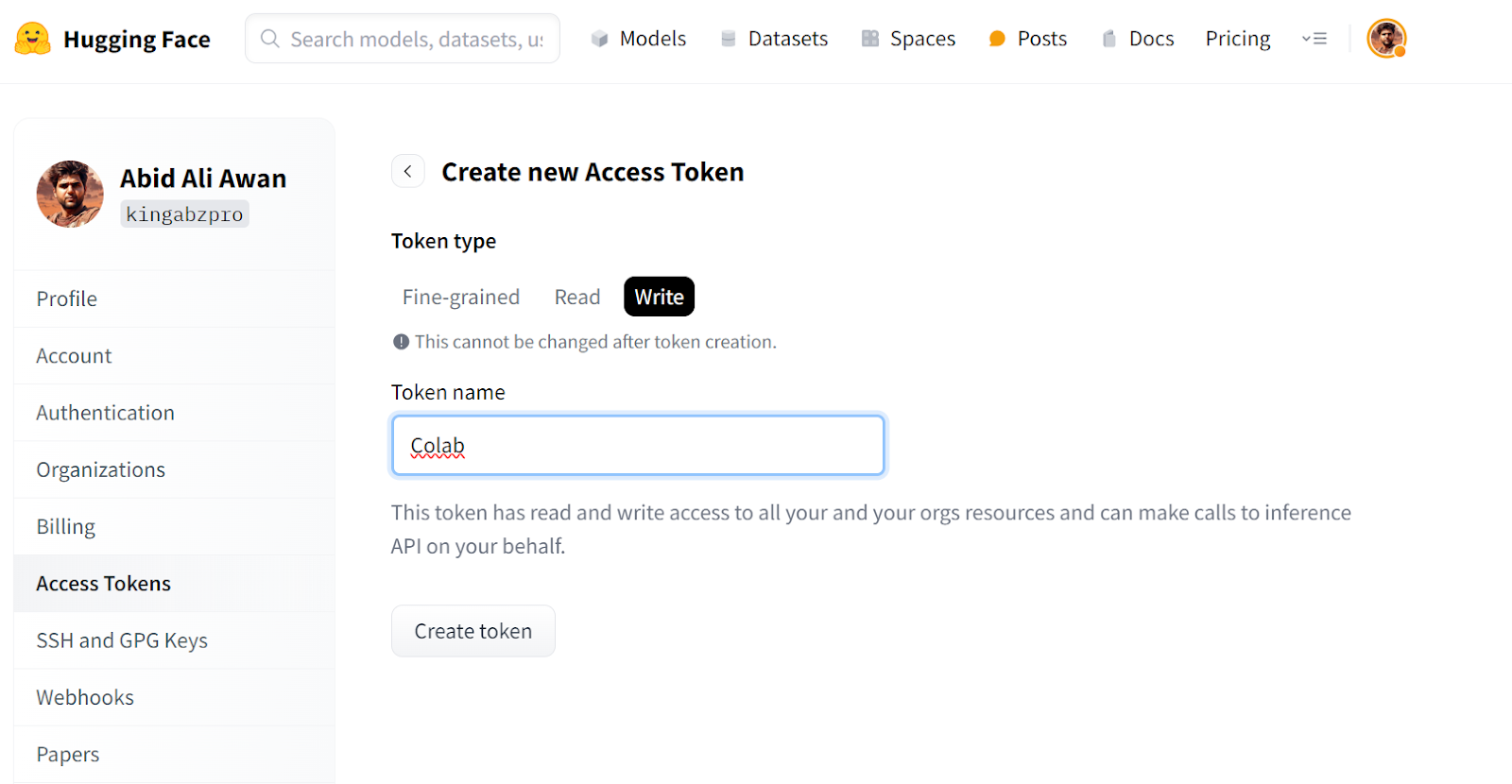
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get("HUGGINGFACE_TOKEN")
login(token = hf_token)llamafactory-cli. We are setting the GRADIO_SHARE=1 so that we can generate a public link to access the web app. %cd /content/LLaMA-Factory/
!GRADIO_SHARE=1 llamafactory-cli webui
The LLAMA-Factory WebUI looks simple but has plenty of options and tabs. We will explore these in the next section.
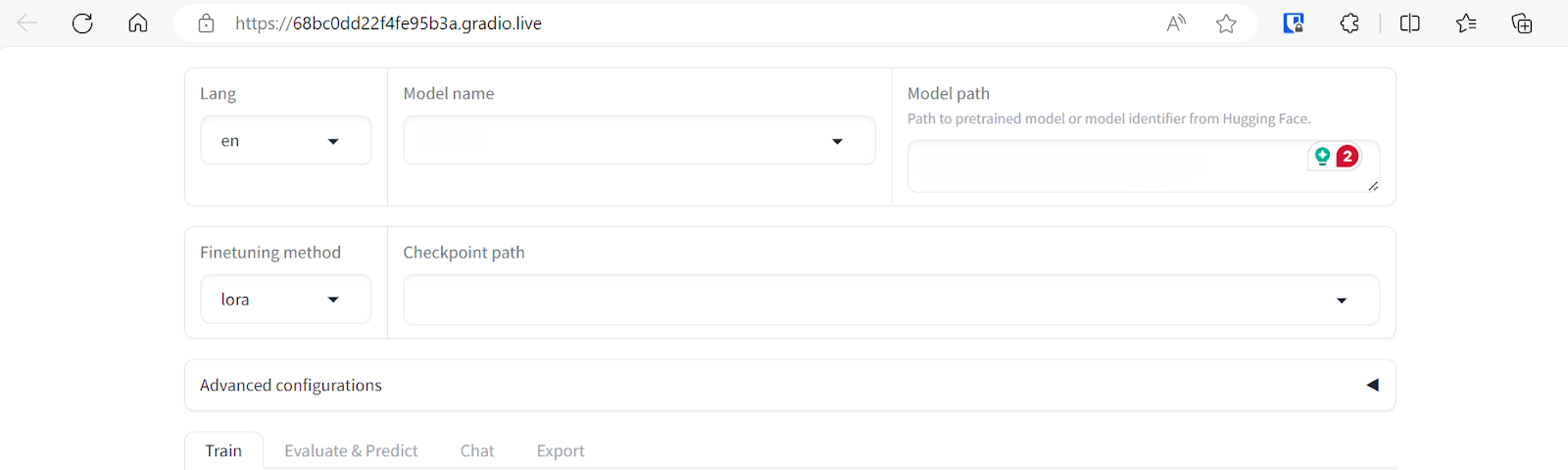
If you are facing issues launching your own LlaMA-Factory WebUI, please refer to the Google Colab notebook.
If you want to run LlaMA-Factory WebUI locally on Windows, you need to install a pre-built version of the bitsandbytes library. It supports CUDA 11.1 to 12.2, so please select the appropriate release version based on your CUDA version.
$ git clone https://github.com/hiyouga/LLaMA-Factory.git
$ cd LLaMA-Factory
$ pip install -e .[torch,bitsandbytes]
$ pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl$ llamafactory-cli webui$ huggingface-cli loginThere will be no coding in this section. We will select the model and dataset for fine-tuning, change some parameters, and press some buttons for faster training.
To understand the theory behind fine-tuning large language models, check out this comprehensive guide: Fine-Tuning Large Language Models.
We will be fine-tuning the unsloth/llama-3-8b-bnb-4bit model on the Microsoft/wiki_qa dataset. The dataset contains multiple columns, as shown below, but we will use the “question” and “answer” columns for model fine-tuning.
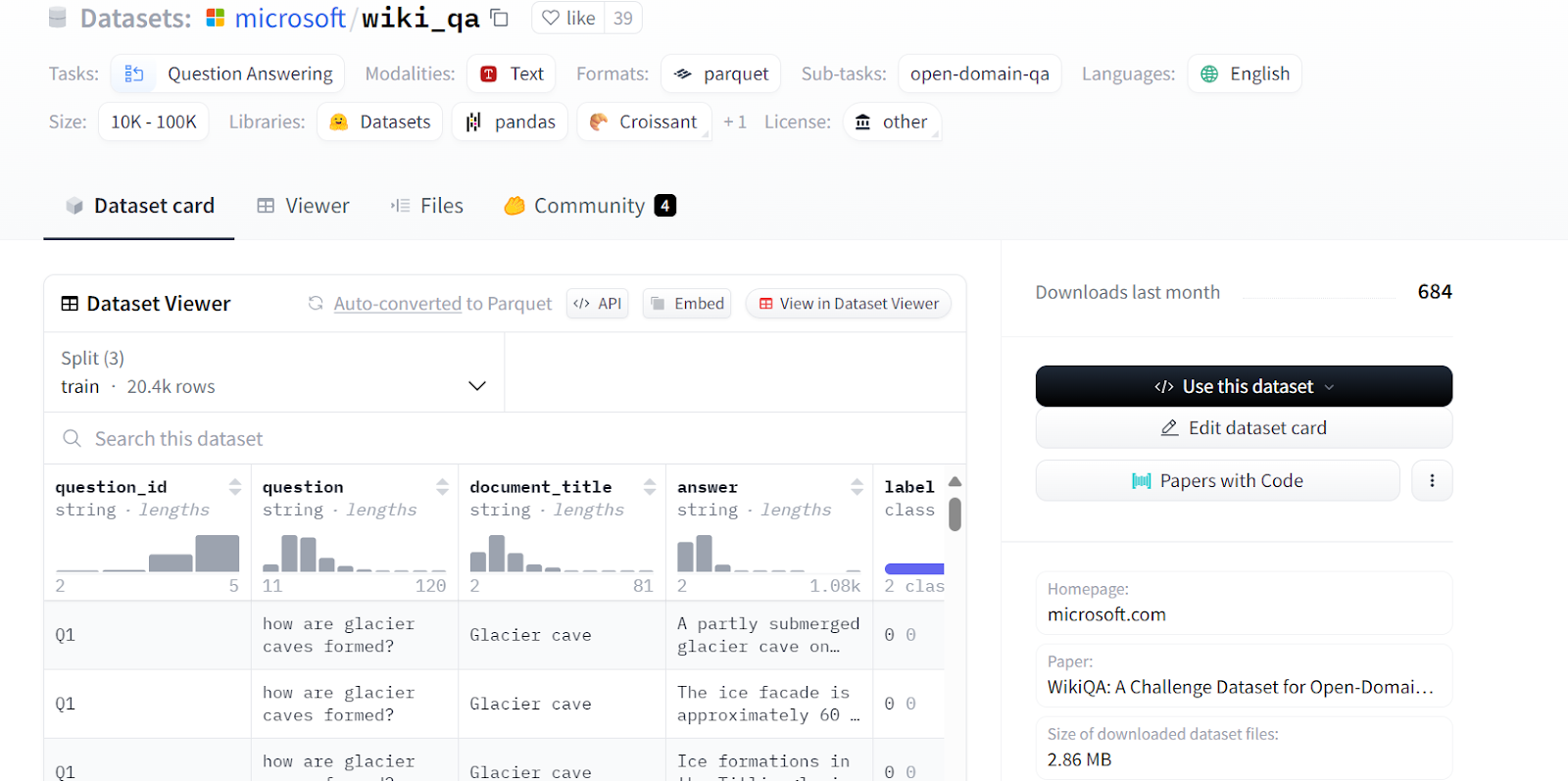
Source: microsoft/wiki_qa | Wiki Question Answering corpus from Microsoft
We cannot load the full LLaMA-3-8B instruction model in the free version of Google Colab. Instead, we will load the 4-bit quantized version of the same model provided by Unsloth.
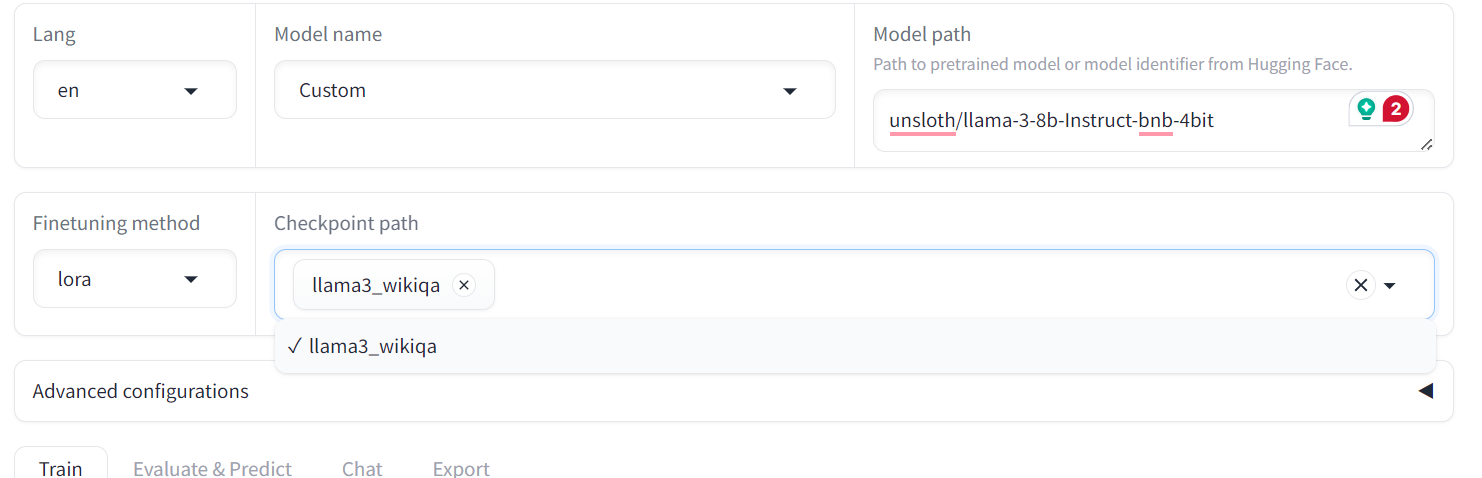
To do this, select the model name "Custom" and paste the repository link "unsloth/llama-3-8b-bnb-4bit" into the model path.
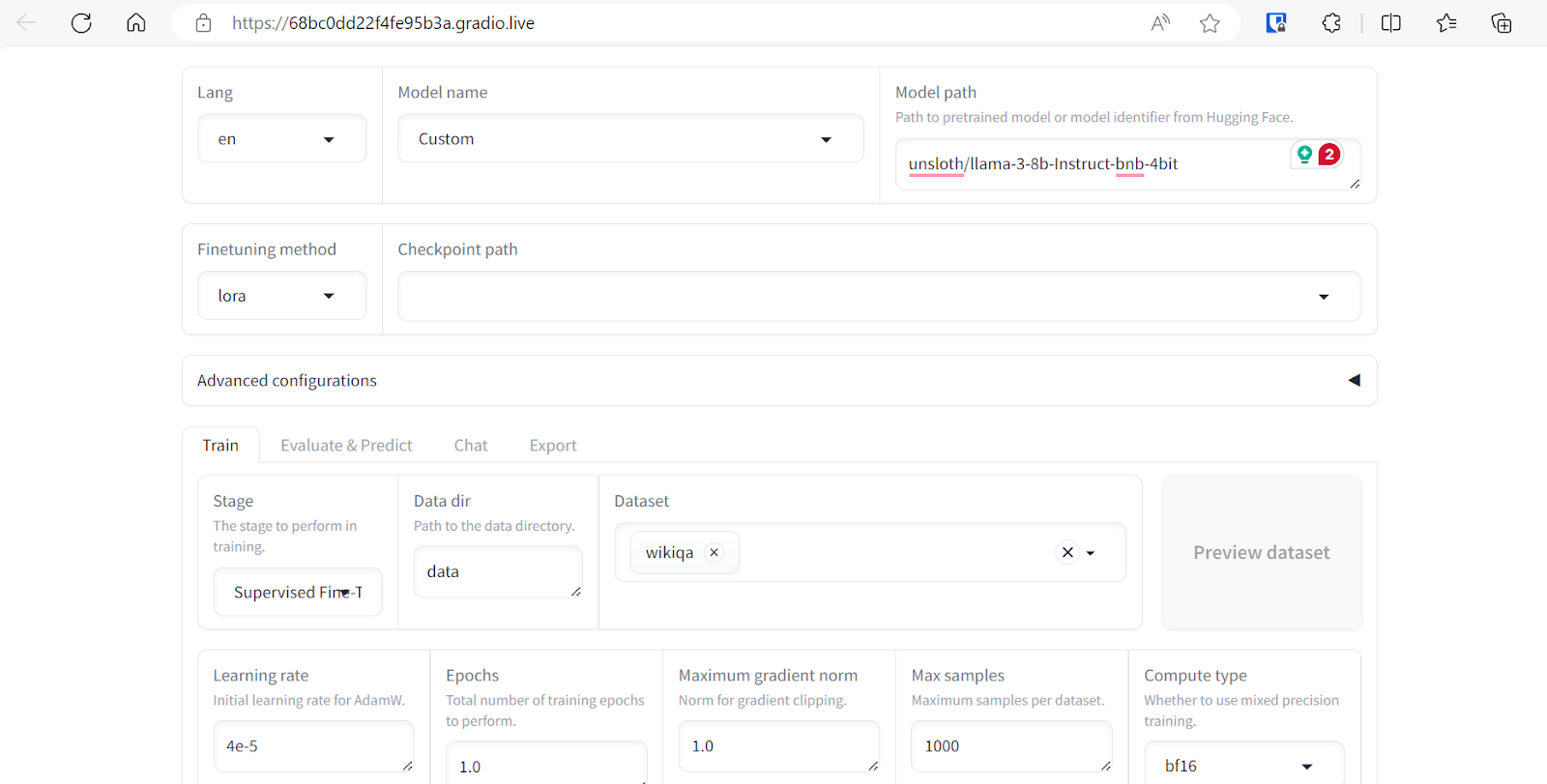
We can select multiple datasets to fine-tune our model. However, for this tutorial, we will only use the “Wikiqa” dataset, which you can easily select from a predefined dataset, as shown above.
Adjust the model training arguments by scrolling down the page. We will set the following parameters:
The rest of the arguments will be kept with their default values. These values can be changed to modify the behavior of the fine-tuned model.
We also have the option to change LoRa rank and other LoRa-related configurations. For this tutorial, we are keeping all the other settings at their default values.
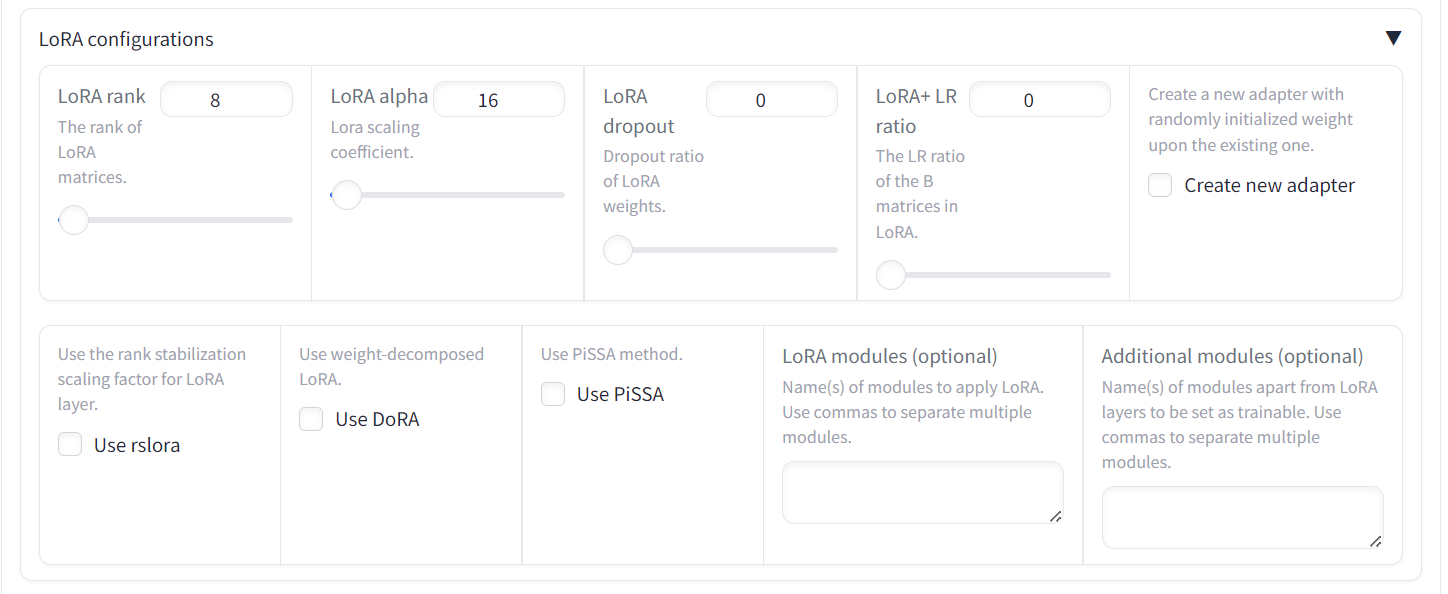
Scroll further down the page to see the training configuration. Please provide the output directory and configuration path and press the “Start” button. The loss graph will take some time to show as the LlaMA-Factor will first download the model and dataset and then load both, which can take at least 5 minutes.
Once the model is fully loaded and the training starts, you will begin to see visualizations on the loss graph. As we can observe, the loss is gradually decreasing with the number of steps, which is great.
When the training is complete, you will see the finish message at the bottom left. As we can observe, the loss has gradually reduced and plateaued after 45 steps.
If you are a data scientist or developer, you will find it easy to fine-tune your model using the Python language.
We have a detailed guide for technical individuals who want to train LlaMA-3 here: Fine-Tuning Llama 3 and Using It Locally: A Step-by-Step Guide.
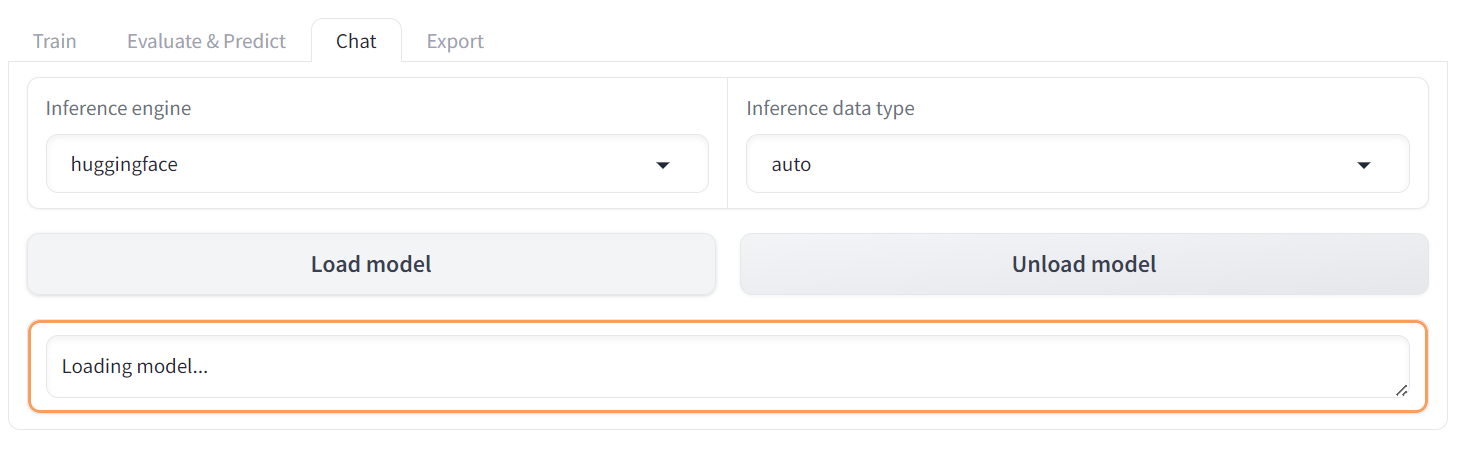
To evaluate the fine-tuned model, we have to switch the menu from “Train” to “Chat”. Then, go to the “Checkpoint path” and load the saved fine-tuned adopter.
After that, click on the “Load model” button and wait a few seconds until the model is successfully loaded.
Scroll down to see the chat input box and write a general question on the mountain range.
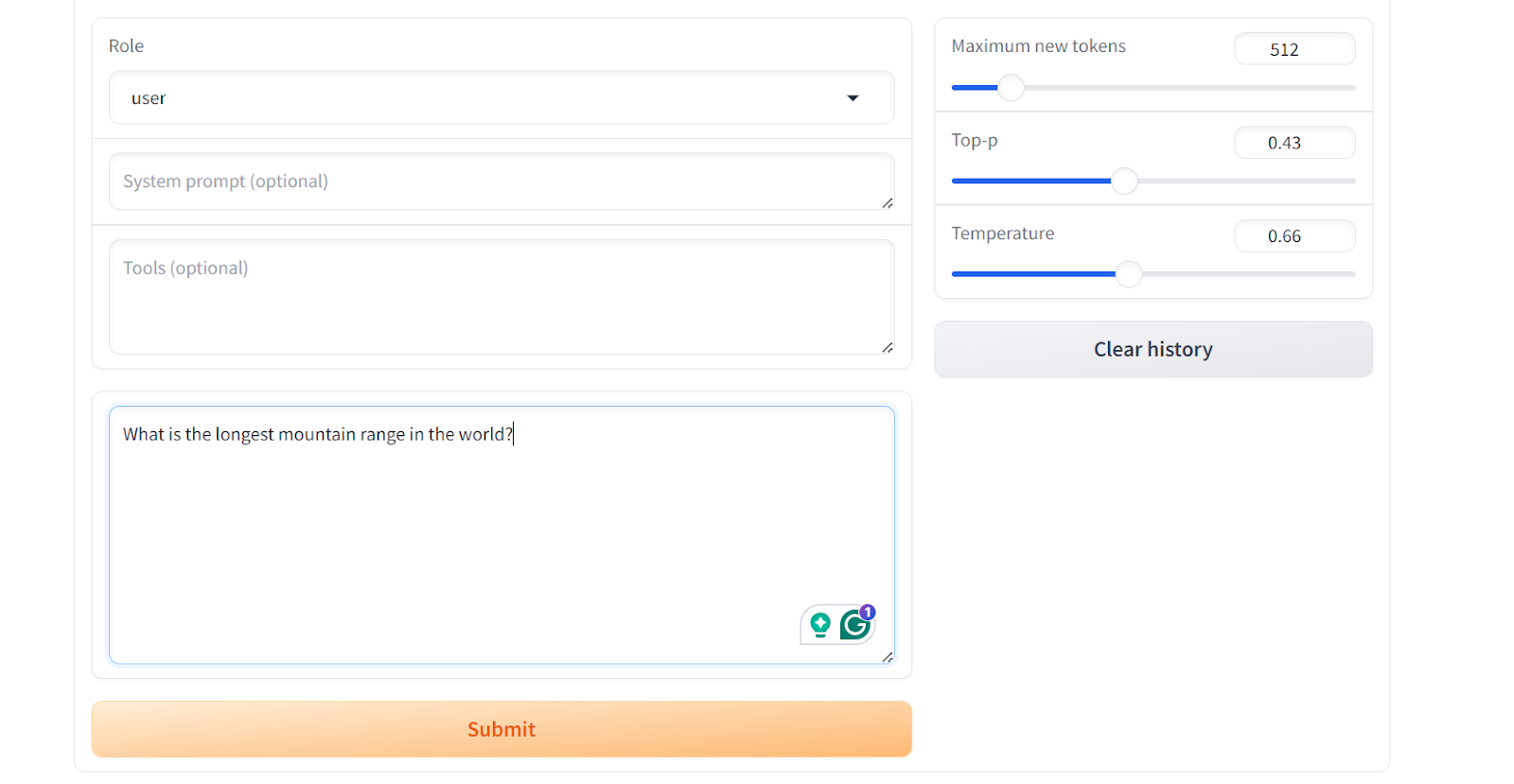
As a result, you will get a simple and straightforward answer, similar to the "wiki_qa" dataset.
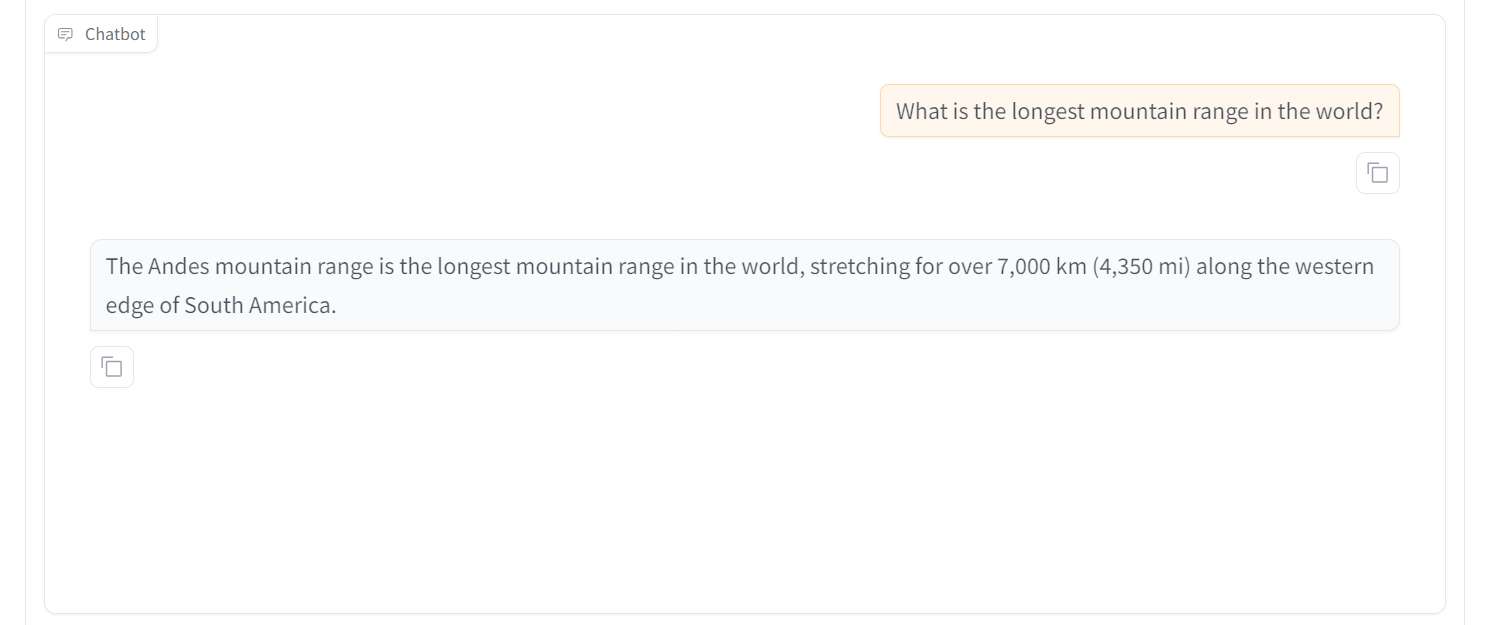
Let’s try to ask another question. We can see that the model is performing exceptionally. Within 30 minutes, we have fine-tuned the model, which would have taken more than 4 hours using the Transformer library. This is amazing.
Sometimes, fine-tuning is not the solution to all of the LLM’s problems. That's why you should read the RAG vs Fine-Tuning: A Comprehensive Tutorial with Practical Examples and learn what works best for you.
Beyond fine-tuning and testing models, the LLaMA-Factory ecosystem offers several core features, including using custom data for fine-tuning, merging and exporting models, and deploying the fine-tuned models using VLLM.
To add a custom dataset, simply modify the data/dataset_info.json file, and it will become accessible in the LLaMA-Factory WebUI.
For detailed information about the required format of dataset files and how to modify dataset_info.json file, please refer to the data/README.md documentation.
You can choose to use datasets from the Hugging Face or ModelScope hubs, or you can load the dataset from your local disk.
Preview of the data/dataset_info.json file
We can easily merge the fine-tuned LoRA adapter with the full model and export it to the Hugging Face Hub by clicking on the “Export” tab.
Adjust the maximum shard size, set the export directory path, and specify the Hugging Face Hub repository ID and export device. The process will take a few minutes to merge the model and upload all the model files to the Hugging Face Hub.
Note: The free version of Colab offers only 12GB of RAM, while merging the LoRA of an 8 billion parameters model requires at least 16GB of RAM. Therefore, this operation cannot be performed in the free version of Colab.
Merging and Experoint the fine-tuned model to Hugging Face Hub
LlaMA-Factory comes with the vLLM framework for model serving and deployment. By typing the following command, we can serve the Llama-3-8B-Instruct model and access it through OpenAI Python API or RestAPI.
$ API_PORT=8000 llamafactory-cli api examples/inference/llama3_vllm.yamlYou can even modify the file or create your own .yaml file to serve your fine-tuned model in production. All you have to do is provide the path to the model folder locally or on Huggin Face Hub.
Source: hiyouga/LLaMA-Factory (github.com)
If you are looking for a similar low-code solution that allows you to fine-tune LLMs, specifically the proprietary GPT-4o model, we have a comprehensive guide for you. Check out our step-by-step tutorial here: Fine-Tuning OpenAI's GPT-4: A Step-by-Step Guide.
The LLaMA-Factory WebUI simplifies the process for both beginners and experts. All you need to do is adjust a few parameters to fine-tune the model on a custom dataset. Using the same user interface, you can test the model and export it to Hugging Face or save it locally. This allows you to deploy the model in production later using the LLaMA-Factory CLI api command. It's that straightforward.
Instead of writing hundreds of lines of code and troubleshooting fine-tuning issues, you can achieve similar results with just a few clicks.
In this tutorial, we learned about the LLaMA-Factory WebUI, and how to fine-tune the LLaMA-3-8B-Instruct model on a Wikipedia Q&A dataset using this framework. Additionally, we tested the fine-tuned model using the built-in chatbot menu and explored the additional features that LLaMA-Factory offers.
Learn how to fine-tune the LLMs using Python by signing up for free for the upcoming Webinar Fine-Tuning Your Own Llama 3 Model.
Top DataCamp LLM Courses
Track
Course
Course
blog
Abid Ali Awan
8 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
code-along
Maxime Labonne

