Curso
Álgebra lineal para data science en R
4 h
21K
Los estudios estadísticos, tanto si implican la determinación de parámetros poblacionales como la predicción de variables dependientes, siempre conllevan cierta incertidumbre. La causa fundamental de esta incertidumbre es el proceso de muestreo. No es realista considerar a toda la población cuando se realiza un análisis estadístico. Por tanto, es necesario elegir una muestra representativa, ya sea para estimar un parámetro de la población, como la media, o para construir un modelo de regresión.
Para aprender o repasar estos conceptos básicos, consulta el curso introductorio a la estadística de DataCamp.
El valor real del parámetro poblacional no suele ser exactamente igual al valor estimado a partir de la muestra: esta diferencia es el error típico. Para tener en cuenta este error, es convencional estimar un valor esperado y luego especificar un intervalo que se espera que contenga el valor real.
Del mismo modo, los estudios de regresión también se basan en muestras aleatorias en lugar de en toda la población. La relación entre las variables dependientes e independientes, estimada por el estudio de regresión sobre la muestra, no es exactamente igual a la verdadera relación entre esas variables en toda la población. Por lo tanto, el valor predicho de un punto de datos individual no es exactamente igual a su valor real. Se espera que el valor verdadero se encuentre dentro de algún intervalo del valor predicho.
Este artículo explica el significado de ambos tipos de intervalos y los métodos matemáticos subyacentes que se utilizan para calcularlos. Analiza ejemplos prácticos de cuándo utilizar cada intervalo. Por último, ilustra con ejemplos prácticos cómo calcular intervalos de confianza y de predicción en el lenguaje de programación R.
Un intervalo de confianza es el intervalo que se espera -con cierto nivel de confianza- que contenga el valor verdadero de un parámetro poblacional, como la media poblacional.
Un parámetro poblacional es una propiedad numérica de toda la población. La media (de toda la población) es un ejemplo de parámetro poblacional. El valor real de los coeficientes de regresión entre dos variables es otro ejemplo de parámetro poblacional. La estadística inferencial consiste en estudiar los puntos de datos de una muestra aleatoria para estimar un parámetro poblacional.
Supongamos, hipotéticamente, que eres horticultor o agricultor de naranjas y quieres saber qué grosor adquieren los naranjos a los 100 días de vida. Es imposible estudiar todos los naranjos de 100 días. Así pues, seleccionas al azar unos cuantos árboles de 100 días y mides su circunferencia (grosor). La media de estas medidas te da la media muestral. Quieres utilizar esta media muestral para obtener la media poblacional.

Una población de naranjos. Creado con DALL-E.
La media muestral es una estimación puntual del parámetro poblacional (en este caso, el parámetro de interés es la media). Este curso de DataCamp sobre estadística inferencial trata estos conceptos con más detalle.
La media muestral es representativa de la media poblacional, pero no exactamente igual a ella. Se espera que la media poblacional se encuentre dentro de un intervalo determinado de la media muestral, que se denomina intervalo de confianza.
En el apartado anterior se explicaron los intervalos de confianza en estadística inferencial. La regresión también implica el uso de intervalos de confianza.
Como ejemplo, considera una variación del mismo ejemplo del naranjo:
Para ello, utiliza un análisis de regresión. El conjunto de datos sobre el que ejecutas la regresión se basa en una muestra de naranjos. Por tanto, la media estimada de la muestra (circunferencia media de los naranjos de 100 días) no será exactamente igual a la media de la población. El valor verdadero de la media poblacional se encuentra dentro de un intervalo de confianza de la media muestral estimada.
En secciones posteriores se muestran y explican las expresiones matemáticas del intervalo de confianza.
Un intervalo de predicción es el intervalo que se espera -con cierto nivel de confianza- que contenga el valor verdadero de un punto de datos individual, basándose en una predicción realizada mediante un análisis de regresión.
Considera otra variación del ejemplo de regresión mencionado anteriormente:
Utiliza la misma fórmula de regresión que antes. El valor estimado (es decir, el valor esperado) de la circunferencia individual es el mismo que la circunferencia media estimada. Sin embargo, debes tener en cuenta la mayor variabilidad de los puntos de datos individuales, porque estás prediciendo un valor individual (y no una media). Por tanto, el intervalo de predicción es mayor que el intervalo de confianza.
Más adelante en el artículo, verás las fórmulas de estos intervalos y aprenderás a utilizar R para calcularlos.
Los dos conceptos -intervalos de predicción e intervalos de confianza- están estrechamente relacionados. Un mismo análisis puede implicar a menudo el uso de ambos tipos de intervalos. Por tanto, es útil compararlos cara a cara.
Cuando necesitas conocer un parámetro poblacional, como la media, utilizas una muestra para estimar dicho parámetro. Como el tamaño de la muestra suele ser mucho menor que el de la población, la estimación del parámetro de la muestra es imperfecta. El intervalo de confianza es el rango (de la estimación muestral) que se espera que contenga el parámetro poblacional.
Los coeficientes de regresión también se consideran parámetros poblacionales. Como se estiman a partir de una muestra (y no de toda la población), estos parámetros contienen cierto error. Así, los coeficientes de regresión también pueden expresarse con un intervalo de confianza.
Además, puedes utilizar la regresión para predecir cualquiera de las dos cosas:
El primero utiliza un intervalo de confianza, y el segundo, un intervalo de predicción. En el apartado siguiente se explica esta diferencia con más detalle.
Como ya se ha explicado, el intervalo de confianza es proporcional a la desviación típica e inversamente proporcional al tamaño de la muestra. El intervalo de confianza de la media de la población, 𝛍, se expresa como:
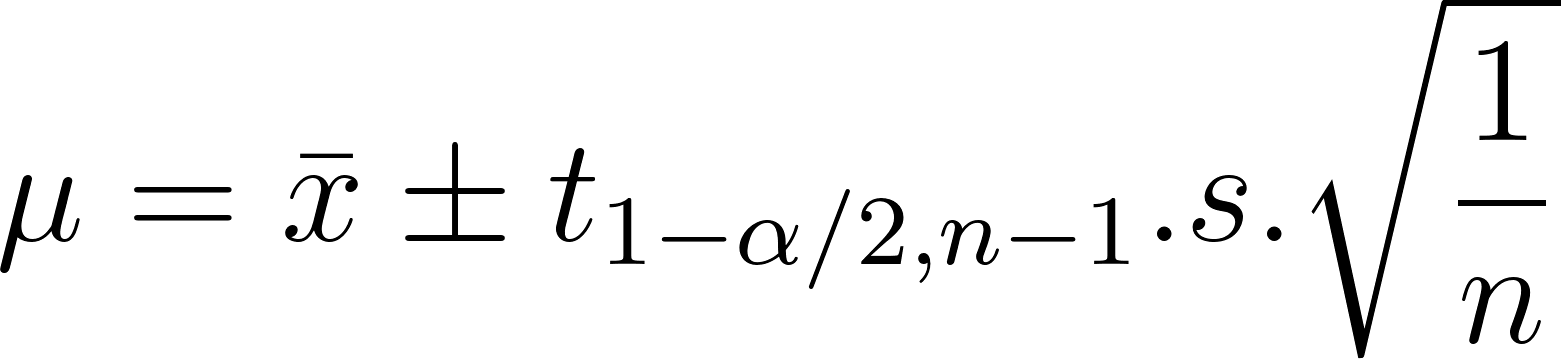
En la expresión anterior:
Por tanto, el rango de 𝛍 es:
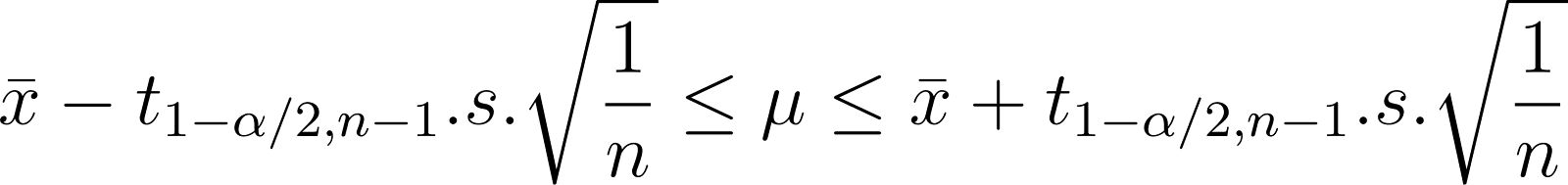
Observa también que el tamaño del intervalo es proporcional al valor t. Si quieres un grado de confianza (certeza) extremadamente alto de que el valor real se encuentra dentro del intervalo dado, ese intervalo tiene que ser muy grande. Cuanto menor sea el grado de confianza, más estrecho será el intervalo. Pero un grado de confianza muy bajo no es muy útil. Así que, en la práctica, es habitual elegir niveles de confianza del 90%, 95%, 99%, etc.
Si tienes un nivel de confianza del 95%, te lleva a un nivel de significación del 5%. Suponiendo un intervalo de dos caras, tienes que encontrar el valor crítico t al 2,5% (0,025).
Conceptualmente, todos los intervalos se expresan del siguiente modo:
![]()
Observa que, en todos los casos, cuanto mayor es el error, más amplio es el intervalo. Este error se calcula de forma diferente según el caso de uso. Para la inferencia, el error es la desviación típica. Para la regresión, el error se muestra en las secciones siguientes.
Cuando predices el valor medio de la variable dependiente, estimas su rango utilizando el intervalo de confianza. Por ejemplo, quieres predecir un intervalo para el peso medio de los perros de 2 años en función de su edad. Esto se llama intervalo de confianza de la respuesta media. También se considera un parámetro poblacional porque es una propiedad de toda la población. El intervalo se expresa como
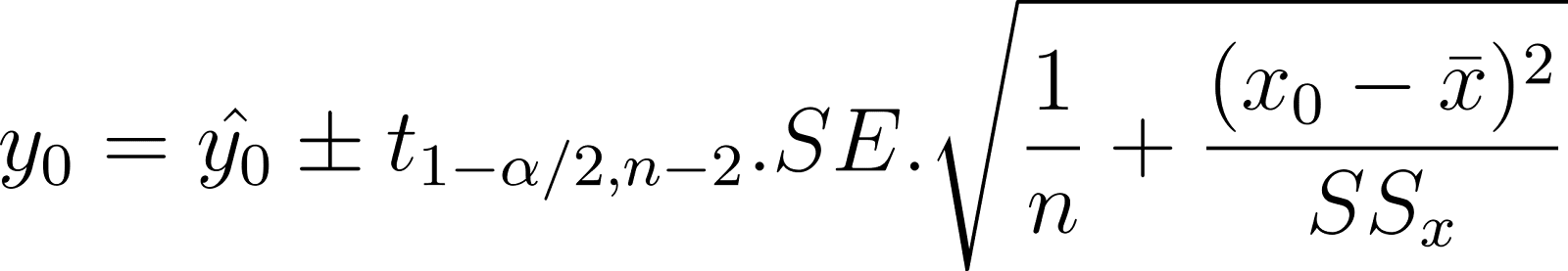
En la expresión anterior:
![]()
![]()
En la expresión anterior, el término sumatorio también se denomina suma de cuadrados de los residuos. El residuo es la diferencia entre el valor real de y y el valor predicho de y.
Utilizando el MSE en lugar del SE, el intervalo de confianza de la respuesta media también puede escribirse como:
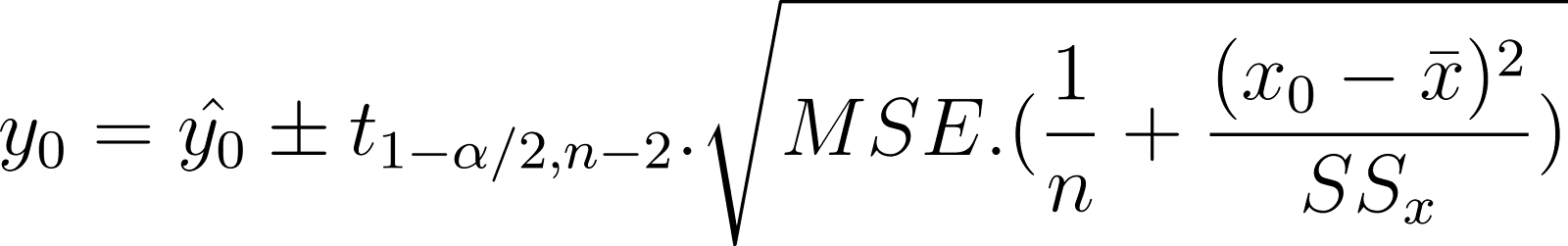
Compara la expresión anterior con la relación conceptual mostrada anteriormente.
![]()
Observa que el error tiene en cuenta
Para predecir el valor exacto de un punto de datos individual (no la media), estima su rango utilizando el intervalo de predicción. Por ejemplo, quieres predecir el intervalo del peso real de un perro concreto de 2 años en función de su edad. Esto se denomina intervalo de predicción, y se expresa como:
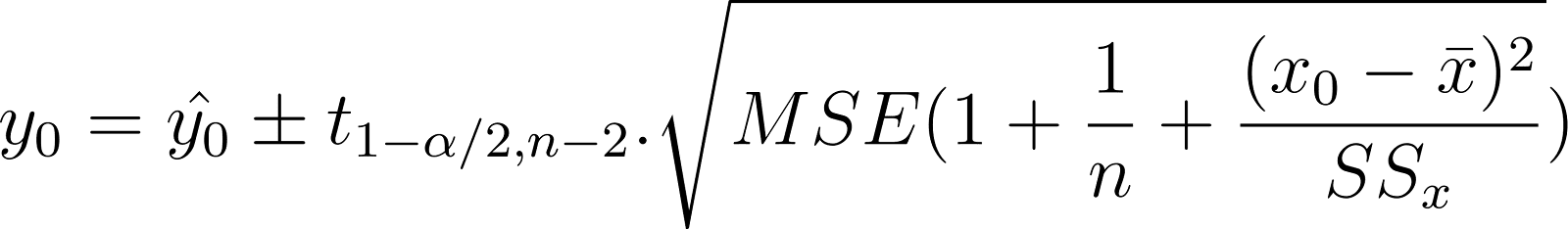
Compáralo con el intervalo de confianza mostrado anteriormente:
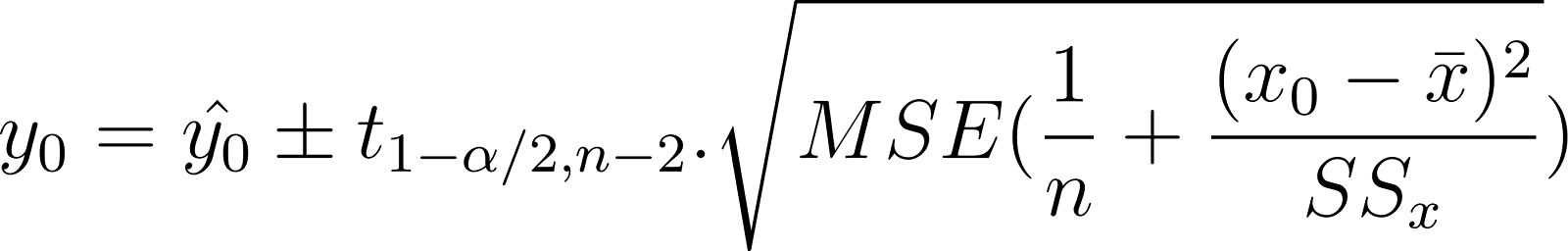
Observa que ambas expresiones son bastante similares. La única diferencia es el término de error adicional en el intervalo de predicción. El intervalo de predicción tiene un término MSE adicional dentro de la raíz cuadrada que el intervalo de confianza. Esto es para tener en cuenta la variabilidad de los valores y, que quieres predecir. Esto hace que el intervalo de predicción sea más amplio que el intervalo de confianza.
El esquema siguiente muestra los intervalos de confianza y predicción en relación con la estimación puntual (valor predicho).
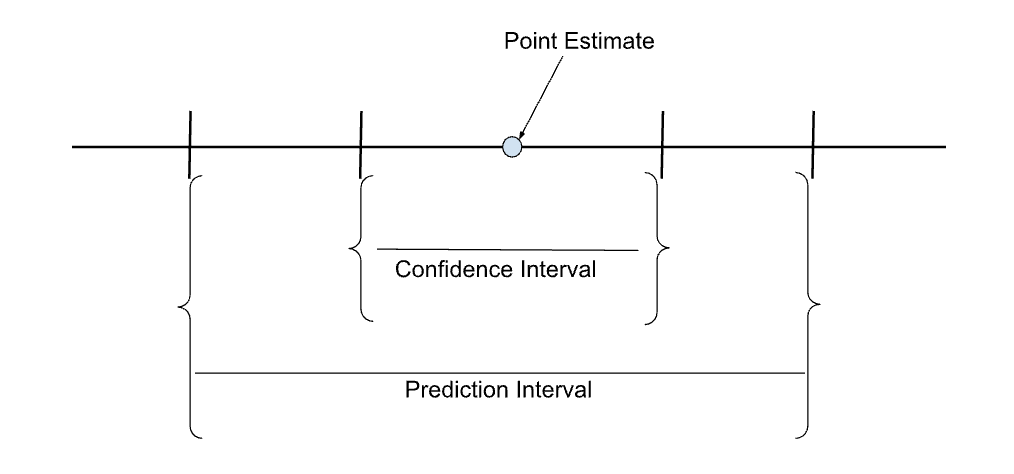
Comparar los intervalos de confianza y predicción de una estimación puntual. Imagen del autor.
El esquema siguiente muestra los intervalos de confianza y de predicción en relación con la regresión; observa también que los intervalos son más estrechos en la región de la media.
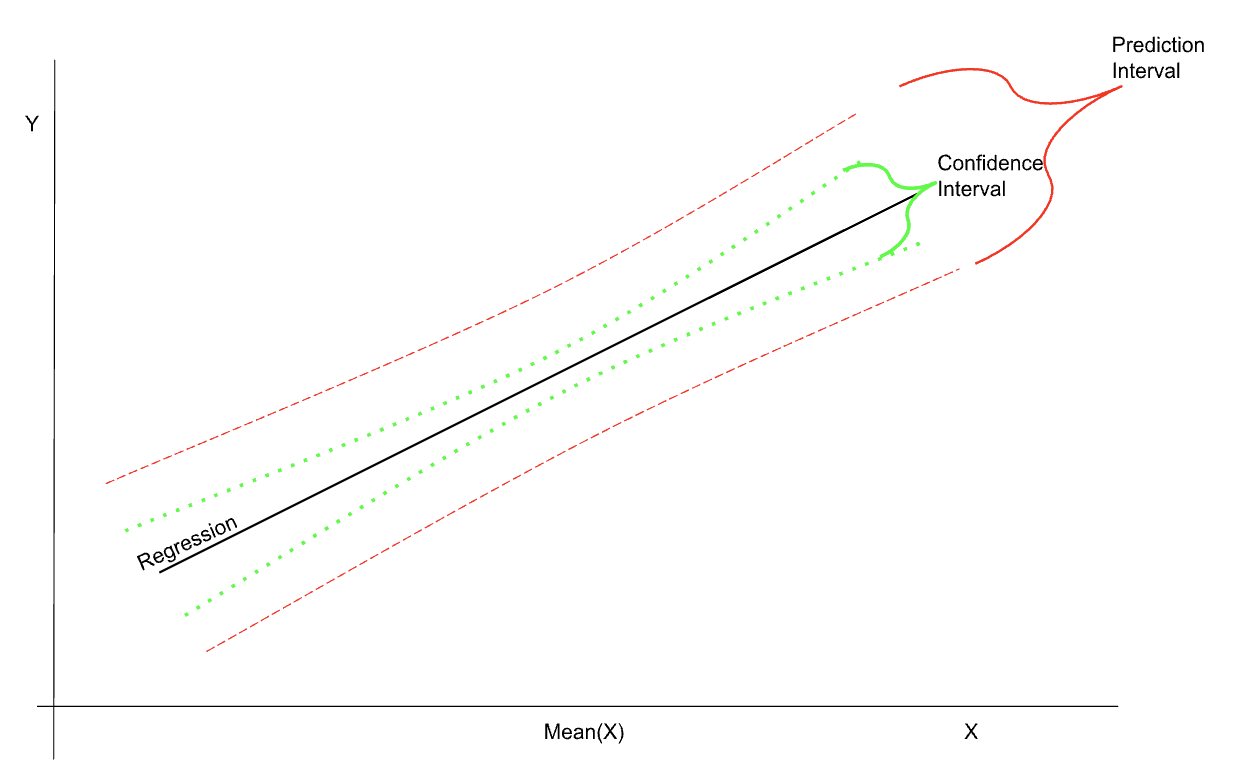
Ilustración de los intervalos de confianza y predicción en regresión. Imagen del autor.
En los apartados anteriores se han tratado los fundamentos de los intervalos de confianza y de predicción, sus usos y las fórmulas utilizadas para calcularlos. En este apartado se dan ejemplos prácticos de cuándo utilizar intervalos de confianza y de predicción.
Un intervalo de confianza se utiliza cuando se estima un parámetro poblacional. Para estimar el parámetro poblacional, puedes
Algunos ejemplos de uso del intervalo de confianza son:
Los intervalos de predicción se utilizan siempre que predices el valor esperado de un punto de datos individual basándote en observaciones de (y análisis de regresión sobre) una muestra aleatoria.
Algunos ejemplos prácticos son:
Los intervalos de confianza y los intervalos de predicción se utilizan a menudo en el mismo contexto, por lo que es importante entender en qué se diferencian.
Esta tabla resume las diferencias basándose en el debate de las secciones anteriores:
|
Intervalo de confianza |
Intervalo de predicción |
|
Se utiliza para determinar los parámetros de la población basándose en las estadísticas de la muestra |
No se utiliza para determinar parámetros de población basados en muestras |
|
Se utiliza para predecir la respuesta media (valor medio de la variable dependiente para una determinada variable independiente) a partir de regresiones. |
Se utiliza para predecir el valor futuro (de un punto de datos individual para una variable independiente dada) basándose en regresiones. |
|
Suele ser más estrecho para un análisis determinado |
Suele ser más amplio para un análisis determinado |
Esta sección muestra ejemplos prácticos del uso del lenguaje de programación R para estimar intervalos de confianza y de predicción. R es un lenguaje diseñado para aplicaciones estadísticas, y viene con conjuntos de datos y funciones estadísticas incorporadas.
Para aprender más sobre regresiones utilizando R, sigue el tutorial de DataCamp sobre regresiones lineales en R.
Los ejemplos siguientes utilizan el conjunto de datos incorporado de Orange. Este conjunto de datos registra la circunferencia (en milímetros) y la edad (en días) de los naranjos. Naturalmente, cabe esperar que cuanto más viejo sea el árbol, mayor será su circunferencia.
Los ejemplos siguientes muestran cómo estimar intervalos de confianza para estadísticas de resumen y análisis de regresión.
Para obtener el intervalo de confianza de la media, ejecuta la prueba T estándar utilizando la función t.test() en el conjunto de datos:
t.test(Orange$circumference)El resultado es como el del ejemplo siguiente:
t = 11.923, df = 34, p-value = 1.076e-13
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
96.10926 135.60502
sample estimates:
mean of x
115.8571 Te da la estimación media y el intervalo de confianza del 95%. Por defecto, la función Prueba T utiliza un nivel de confianza del 95%. Utiliza el parámetro conf.level para especificar un intervalo de confianza diferente, como el 99%.
> t.test(Orange$circumference, conf.level = 0.99)Este comando produce el siguiente resultado:
t = 11.923, df = 34, p-value = 1.076e-13
alternative hypothesis: true mean is not equal to 0
99 percent confidence interval:
89.34458 142.36970
sample estimates:
mean of x
115.8571 Observa que la media estimada es la misma en ambos casos. Sin embargo, el intervalo debe ser más amplio para tener un mayor nivel de confianza. Basándome en los datos, tengo un 99% de seguridad de que la media está entre 89,3 y 142,4, pero sólo un 95% de seguridad de que está entre 96,1 y 135,6. Para un parámetro estimado a partir de una muestra dada, cuanto más estrecho sea el intervalo de confianza, menor será el nivel de confianza.
En los análisis de regresión, necesitas los intervalos de confianza para los coeficientes de regresión y los valores predichos.
Para conocer en profundidad cómo hacer regresiones en R, sigue el curso de DataCamp sobre Inferencia para la Regresión Lineal en R.
Los coeficientes de regresión se estiman analizando una muestra aleatoria. Por tanto, no son los verdaderos coeficientes de toda la población. Las estimaciones de los parámetros de regresión llevan asociados algunos errores. Además de sus valores estimados, es útil dar un intervalo de confianza para los parámetros.
Utiliza la función lm() para construir un modelo lineal basado en el conjunto de datos Naranjos para predecir la circunferencia (en mm) de los naranjos dada su edad (en días):-
model_orange <- lm(circumference ~ age, data = Orange)Comprueba los coeficientes de este modelo lineal:
model_orangeEste comando muestra los parámetros del modelo (intercepto y pendiente) como se indica a continuación:
Coefficients: (Intercept) age
17.3997 0.1068 Utiliza la función confint() para calcular los intervalos de confianza del 95%:
confint(model_orange, level = 0.95)Ahora puedes ver los intervalos de confianza del 95% de la pendiente y el intercepto estimados por el modelo:
2.5 % 97.5 %
(Intercept) -0.14328303 34.9425835
age 0.08993141 0.1236092Utiliza el modelo de regresión creado anteriormente para predecir la circunferencia media esperada de los árboles de 900 días. Utiliza el parámetro interval para especificar un intervalo de confianza.
predict(model_orange, data.frame(age = 900), interval = "confidence", level = 0.95) La salida incluye la predicción (fit) y el intervalo de confianza (lwr y upr para los límites inferior y superior), como se muestra a continuación:
fit lwr upr
1 113.4929 105.3211 121.6647Utiliza el mismo modelo anterior para predecir la circunferencia específica de un naranjo individual de 900 días. Utiliza el parámetro interval para especificar que quieres el intervalo de predicción.
> predict(model, data.frame(age = 900), interval = "prediction", level = 0.95) El resultado se parece al ejemplo siguiente:
fit lwr upr
1 113.4929 64.5118 162.4741Observa que, en ambos casos, el valor predicho de la circunferencia es el mismo: 113,49. Sin embargo, el intervalo de predicción es mucho más amplio que el intervalo de confianza. El intervalo de confianza de la predicción es el rango que se espera que contenga la circunferencia media de los árboles de 900 días. El intervalo de predicción es el rango esperado de la circunferencia de un árbol individual de 900 días. Esto se debe a que puede haber una variación considerablemente mayor en los árboles individuales, que se suaviza al considerar el valor medio.
Los intervalos estadísticos se utilizan habitualmente en campos de la estadística aplicada, como el análisis de datos, la farmacia, la econometría, etc. Para los que no tienen formación académica en estadística, es fácil confundir los intervalos de confianza y los intervalos de predicción.
A continuación se exponen algunos errores comunes:
Este artículo ofrece una visión general de los intervalos de confianza y los intervalos de predicción. También explica la diferencia entre estos conceptos de apariencia similar y ofrece ejemplos prácticos de cuándo utilizar cada tipo de intervalo. El artículo también mostraba cómo calcular la predicción y los intervalos de confianza utilizando el lenguaje de programación R.
Para aprender a aplicar fórmulas estadísticas utilizando Python, consulta el curso DataCamp sobre estadística en Python. Por último, si te estás preparando para entrevistas de trabajo relacionadas con la estadística, consulta el curso de DataCamp sobre preguntas para entrevistas de estadística en Python.
¡Aprende más sobre estadística y ciencia de datos con estos cursos!
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Łukasz Deryło
Tutorial
Eladio Montero Porras
Tutorial
Vidhi Chugh
Tutorial
Zoumana Keita
Tutorial
DataCamp Team
