
Track
AI Fundamentals
10 hr
QwQ-32B-Preview is a model built to handle advanced reasoning tasks that go beyond simple text understanding. It aims to solve challenging problems like coding and mathematical reasoning. As a “Preview” version, it’s still being refined. It has open-source access on platforms like Hugging Face, so you can test, improve, and give feedback on the model if you want to!
Something to take into account is that QwQ-32B-Preview is an experimental model. While it shows promise, it also has some important limitations:
You can access QwQ-32B-Preview through HuggingChat, where it's currently running unquantized for free. To use QwQ-32B-Preview:
We will begin with the well-known Strawberry Test. The prompt is: “How many times does the letter ‘r’ occur in ‘strawberry’?”
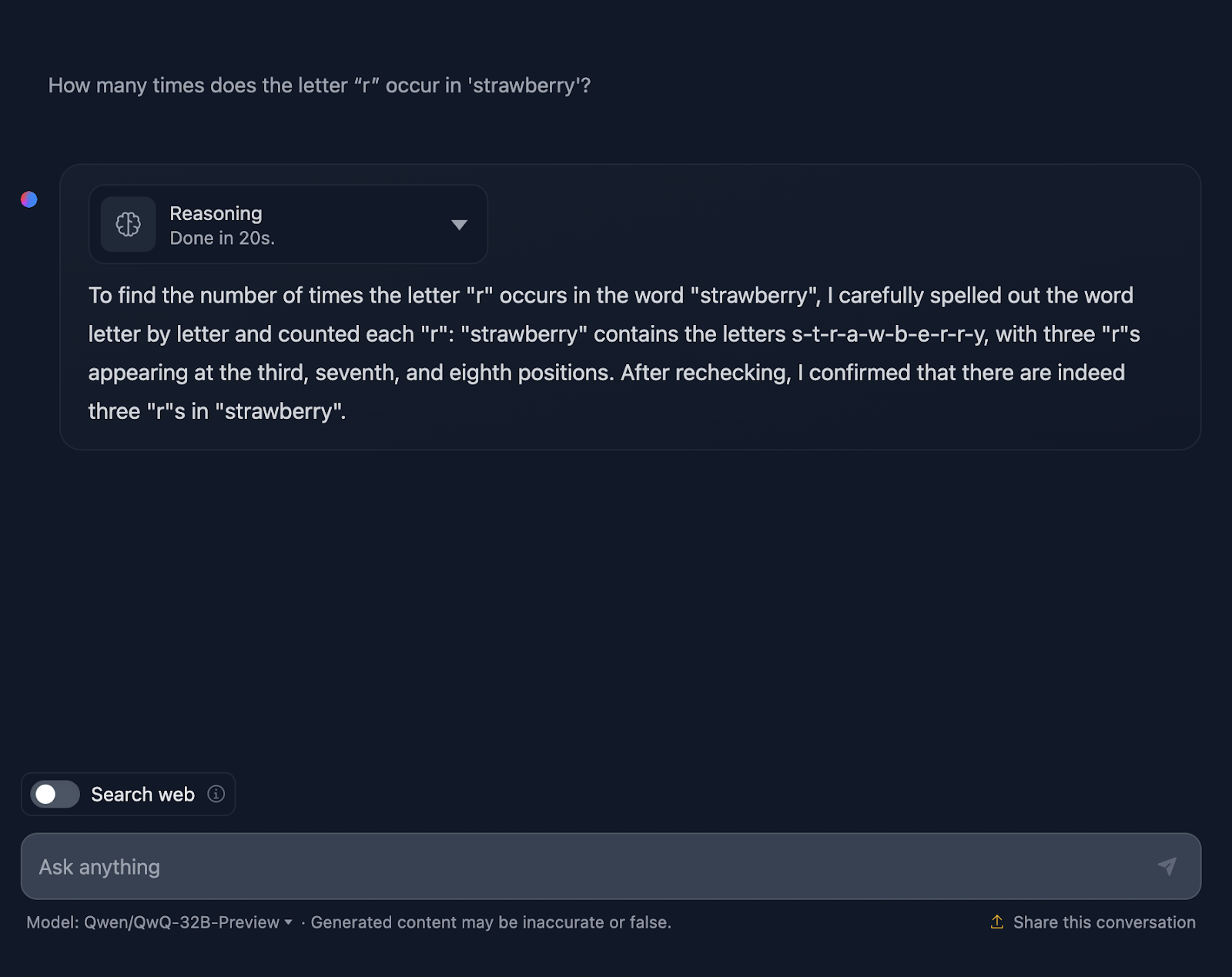
Right, this is getting interesting already!
It does count the letters correctly, but it’s incorrectly stating that the “r”s appear in the third, seventh, and eighth positions, which is not true. The correct positions are the third, eighth, and ninth. For reference, this is something that DeepSeek handled correctly.
Let’s take a closer look at the reasoning of QwQ-32B-Preview:
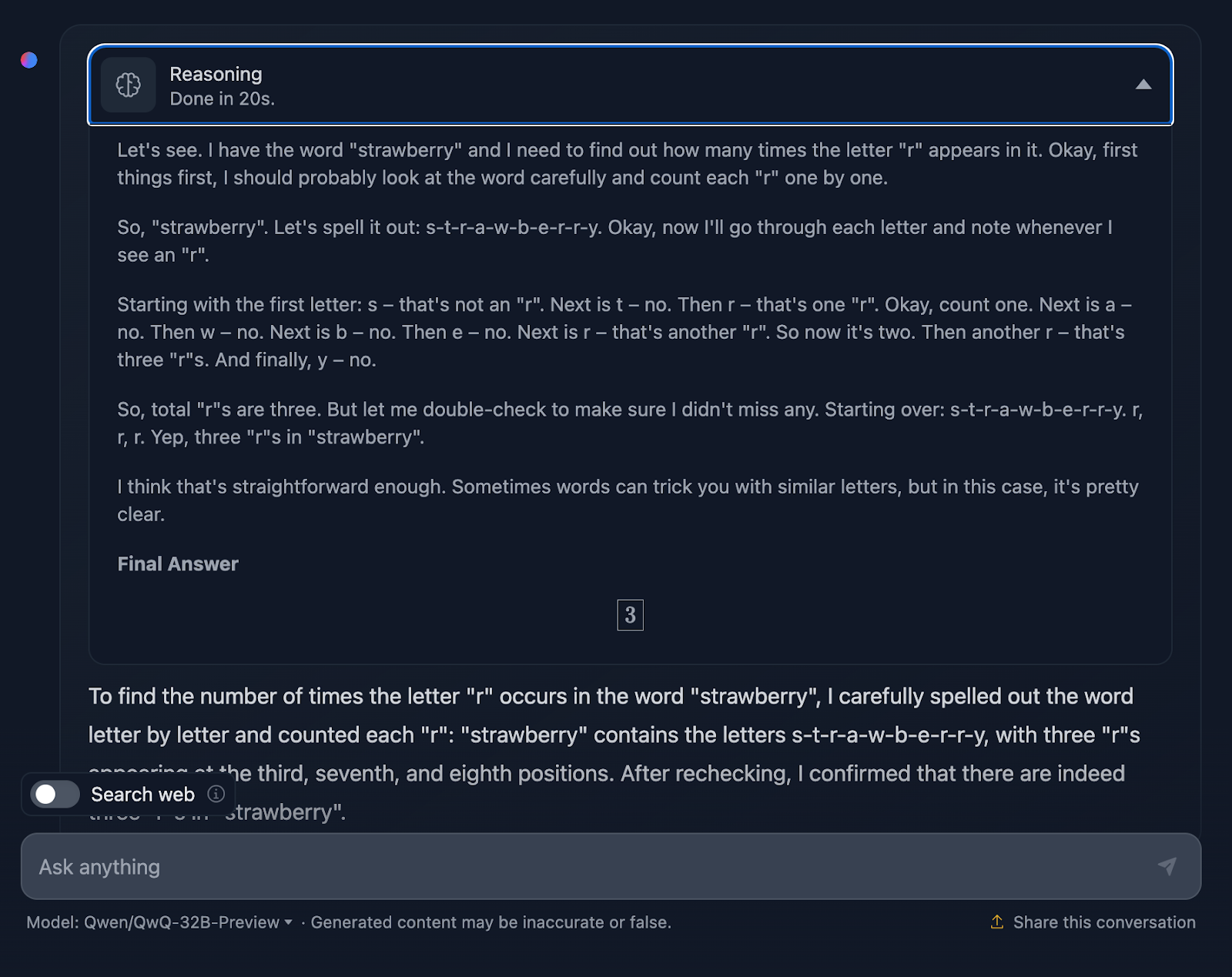
The reasoning of QwQ-32B-Preview was much shorter than that provided by DeepSeek. However, in this case, when counting the letters, it didn’t consider their positions, which I guess is why it got it wrong. It’s interesting because it provided that information even though it wasn’t needed—I didn’t ask for the positions of the “r”s, only the number of occurrences. Providing extra, unnecessary information ended up introducing errors.
To test the mathematical reasoning of the model we will perform three tests varying in complexity.
The prompt is: "If a triangle has sides of length 3, 4, and 5, what is its area?" Let’s see how it handles this:
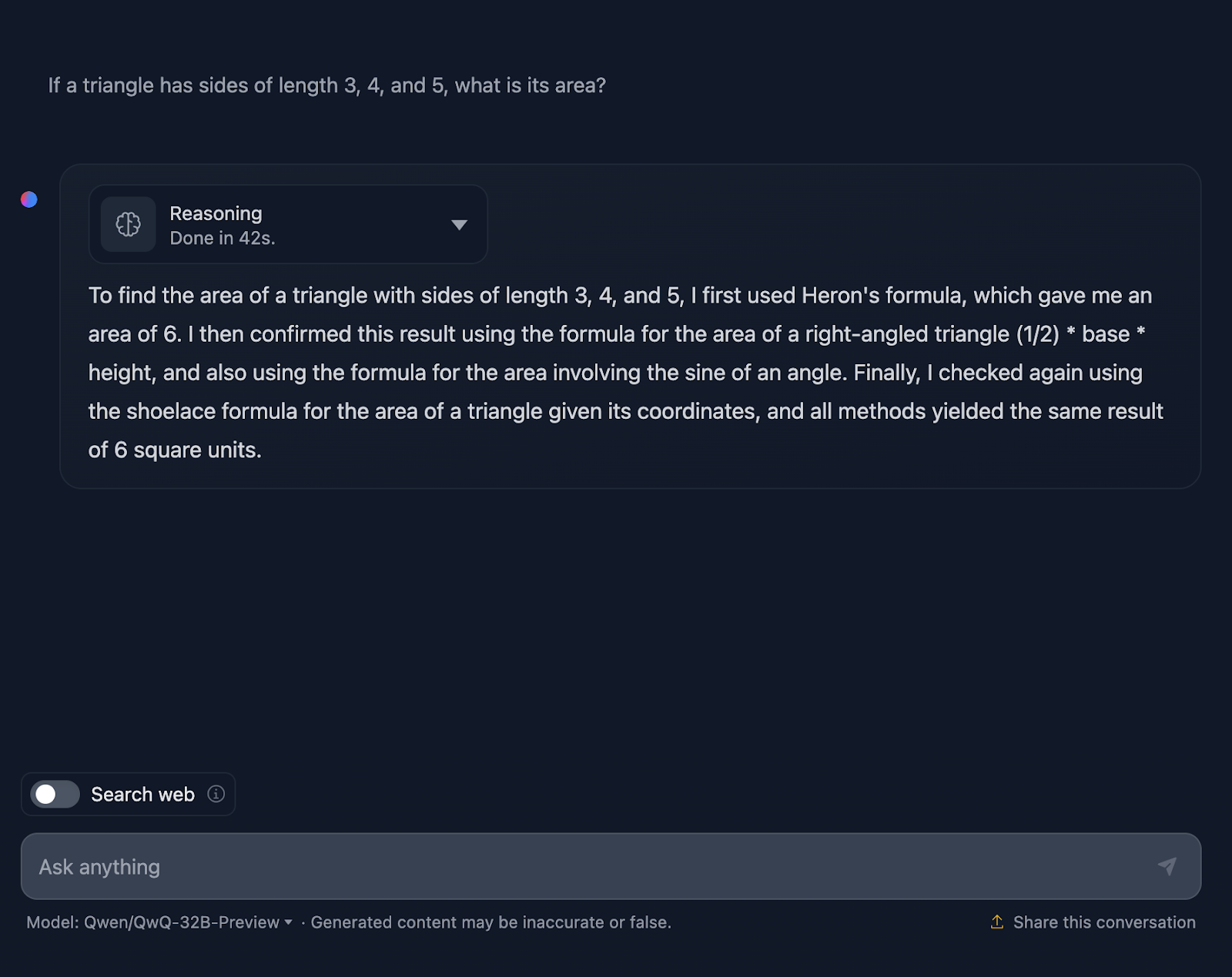
The answer is correct, and it explains the methods used to arrive at the conclusion. However, none of the formulas or calculations are included in the solution, which is fine since this wasn’t requested. However, it would have been a nice addition, something DeepSeek did provide. Let’s take a look at the reasoning now:
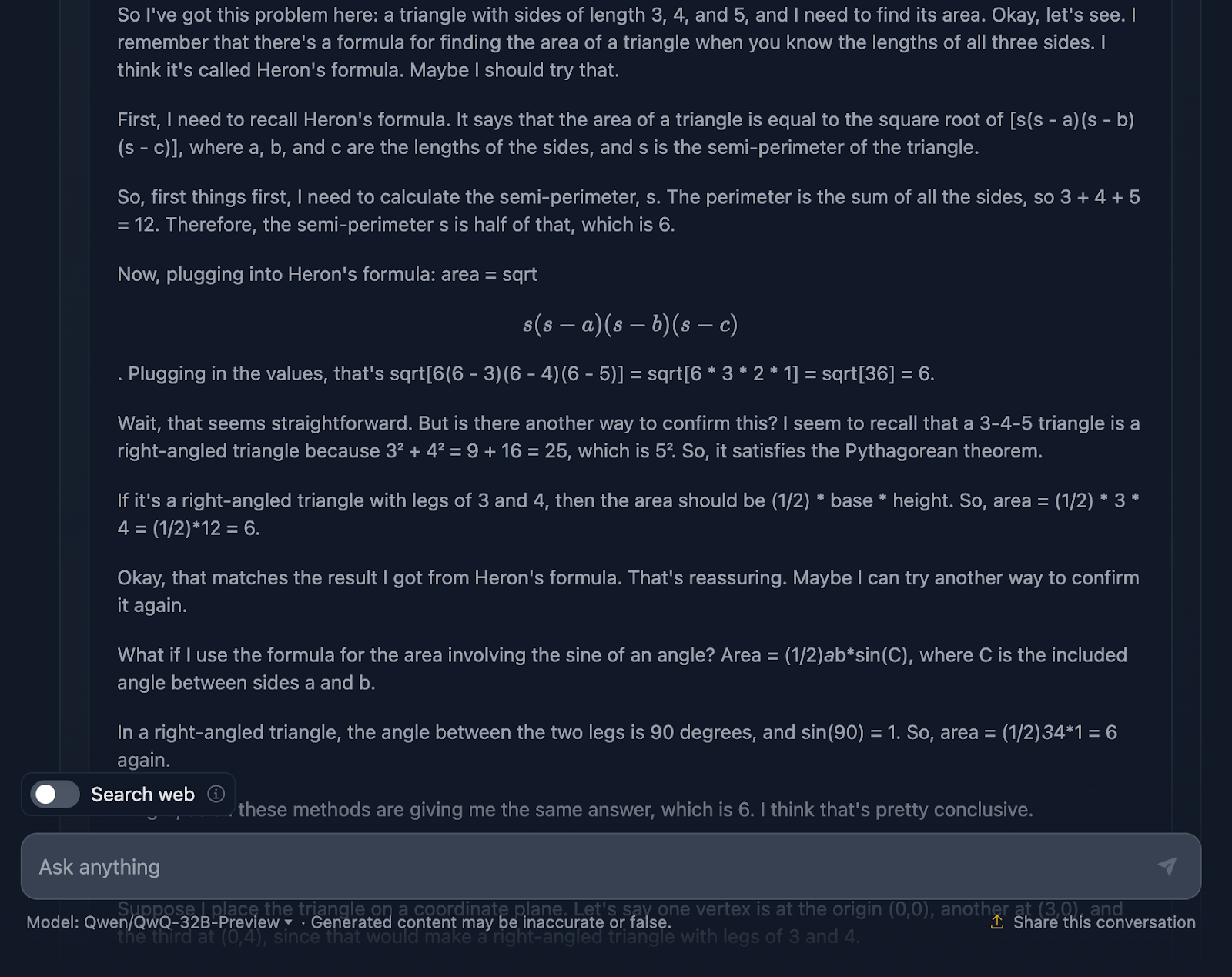
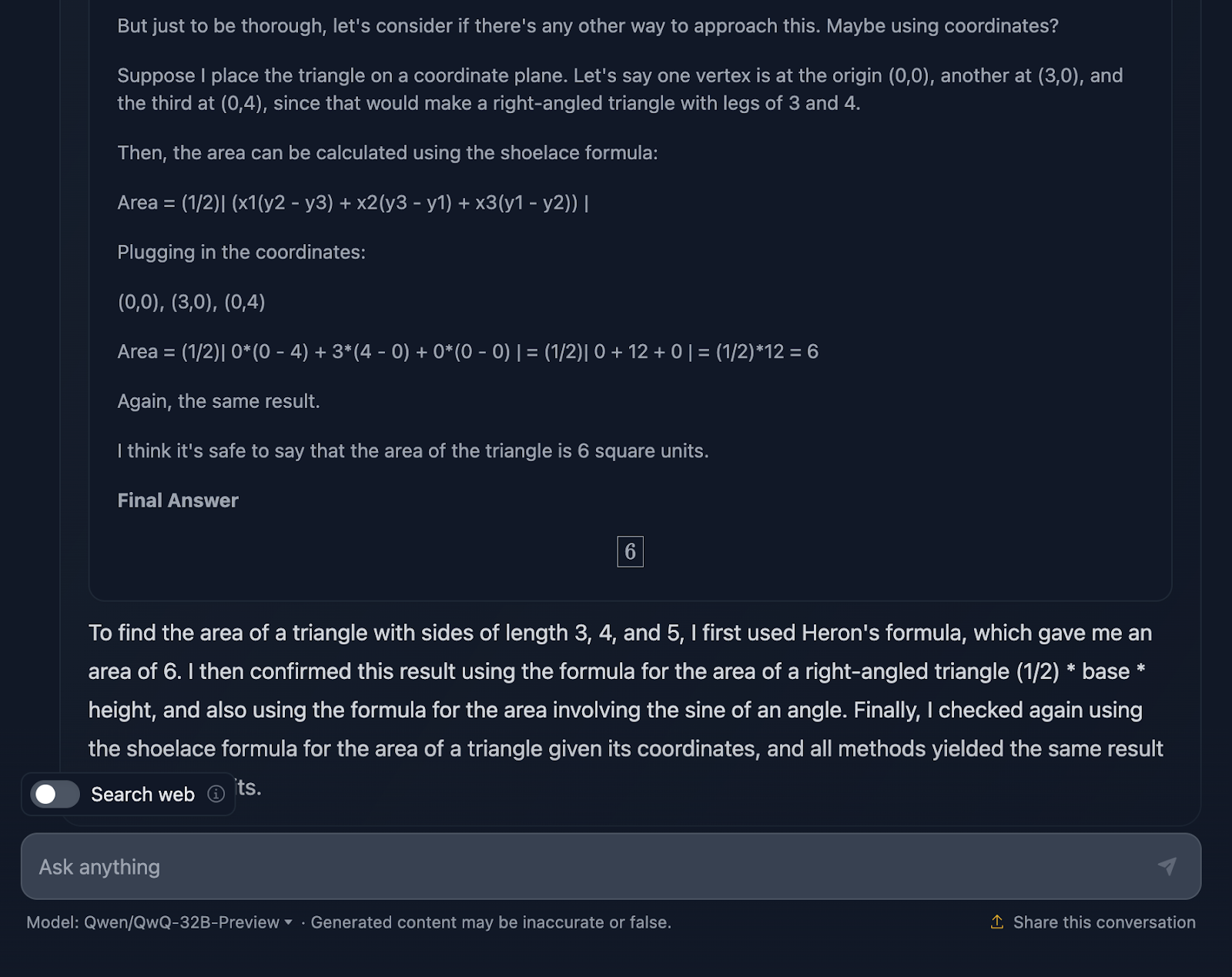
I think it’s pretty cool that it used four different approaches to arrive at the same solution, compared to DeepSeek, which only used three. The reasoning is clear and easy to follow. The only issue I’ve noticed is that the formatting and style of the formulas are a bit inconsistent—some are properly parsed, while others are not. This is something DeepSeek handled correctly.
Let’s look into a more complex math test to see if there is any difference in the performance and thought process. I will test the following: “Prove that the sum of the reciprocals of the Fibonacci numbers converges to a finite value.”
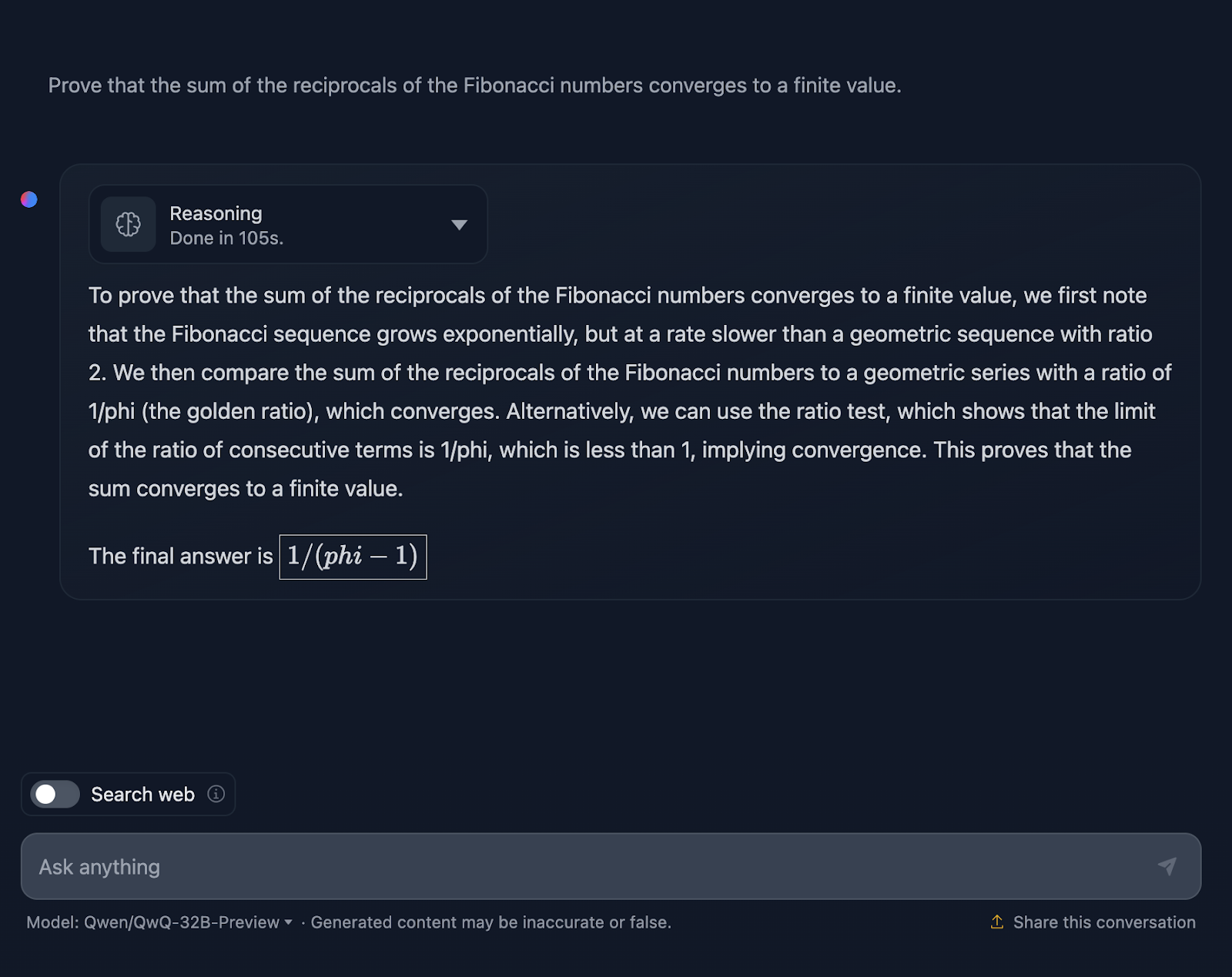
The answer is technically not incorrect, but there is plenty of room for improvement. First of all, if I am asking the model for a proof, the final answer shouldn’t just be a value; it should include a series of formulas or applications of theorems to prove a hypothesis or statement. It attempts this here, but it needs more elaboration, and the final answer doesn’t truly prove anything. Once again, the formatting of the formulas seems to be a recurring issue. A great example of a proper proof can be found in the test I performed with DeepSeek.
For context, during my PhD in mathematics, I marked maths exams, and I can tell you this answer wouldn’t have received full marks—but DeepSeek’s would have!
Let’s look now at the reasoning (for readability, I’ll only show the first and the last part of the lengthy reasoning process, but I encourage you to test the prompt yourself):
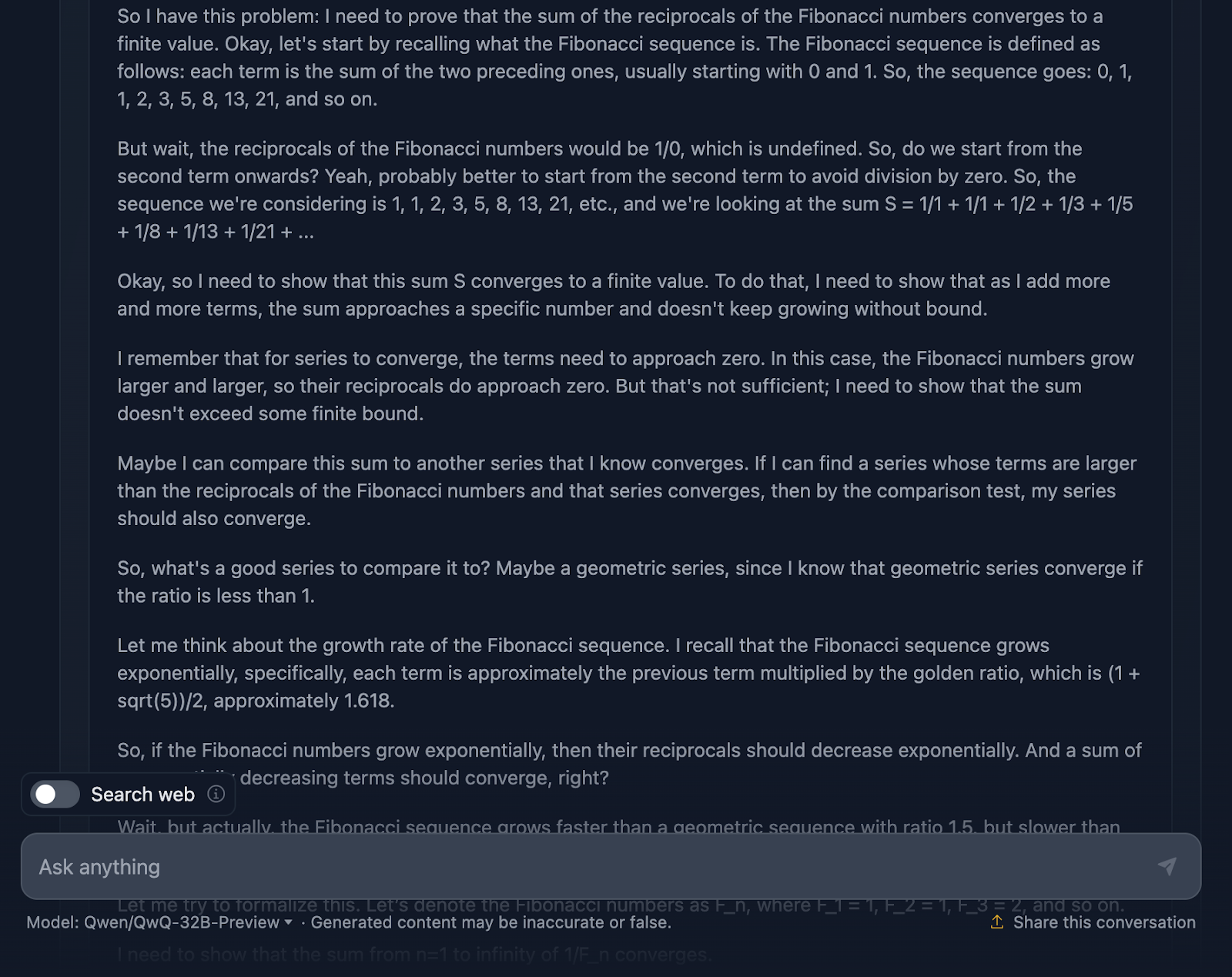
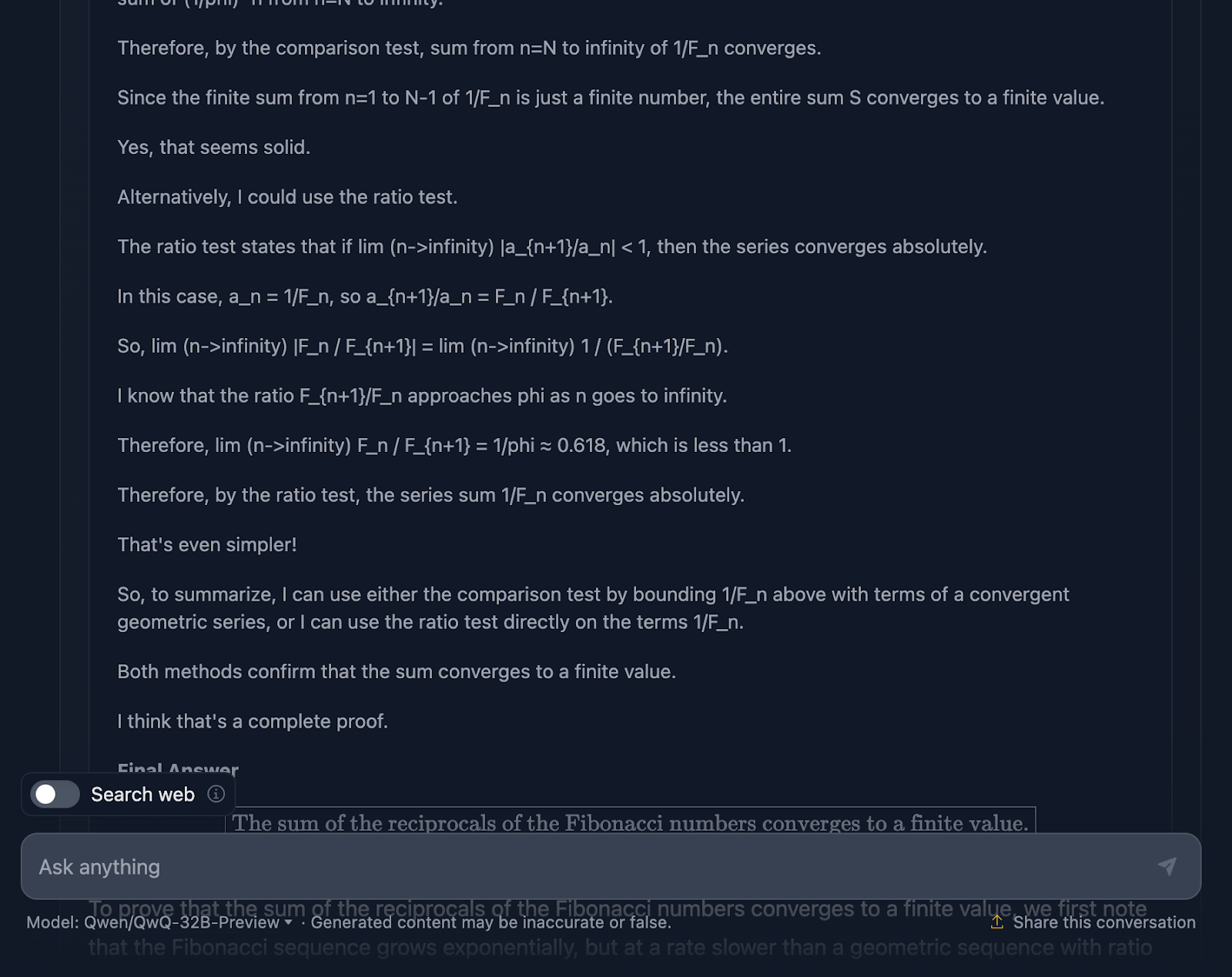
First off, the model starts strong. It recalls the Fibonacci sequence, avoids the obvious pitfall of dividing by zero, and sets up the problem well. That’s a solid foundation right there. Then, it proceeds to use the comparison test and ratio test which are standard tests for series convergence, and even uses Binet’s formula to approximate and bound the Fibonacci numbers. It also acknowledges at some point that it does not need to calculate the exact value, just prove that the series converges which shows that it is really sticking to the problem.
Now, the reasoning is correct, no doubt about that, but the journey to the answer feels a bit tangled. Again, some formulas are formatted nicely, but others—not so much.
That said, the final proof holds up. It shows the series converges, and it uses valid methods to get there. But compared to DeepSeek’s output, the proof could’ve used a bit more polish and consistency.
It also really surprises me that the final answer provided in the reasoning, which is a better final answer, is different from the one in the final output. It should have stuck to that!
Let’s try now a differential geometry test:
Consider a surface S in R3 parameterized by
φ(u,v) = (u cos v, u sin v, ln u)
for u > 0 and 0 ≤ v < 2π.
a) Calculate the first fundamental form of S.
b) Determine whether S is a minimal surface.
c) Find the Gaussian curvature K and the mean curvature H of S.
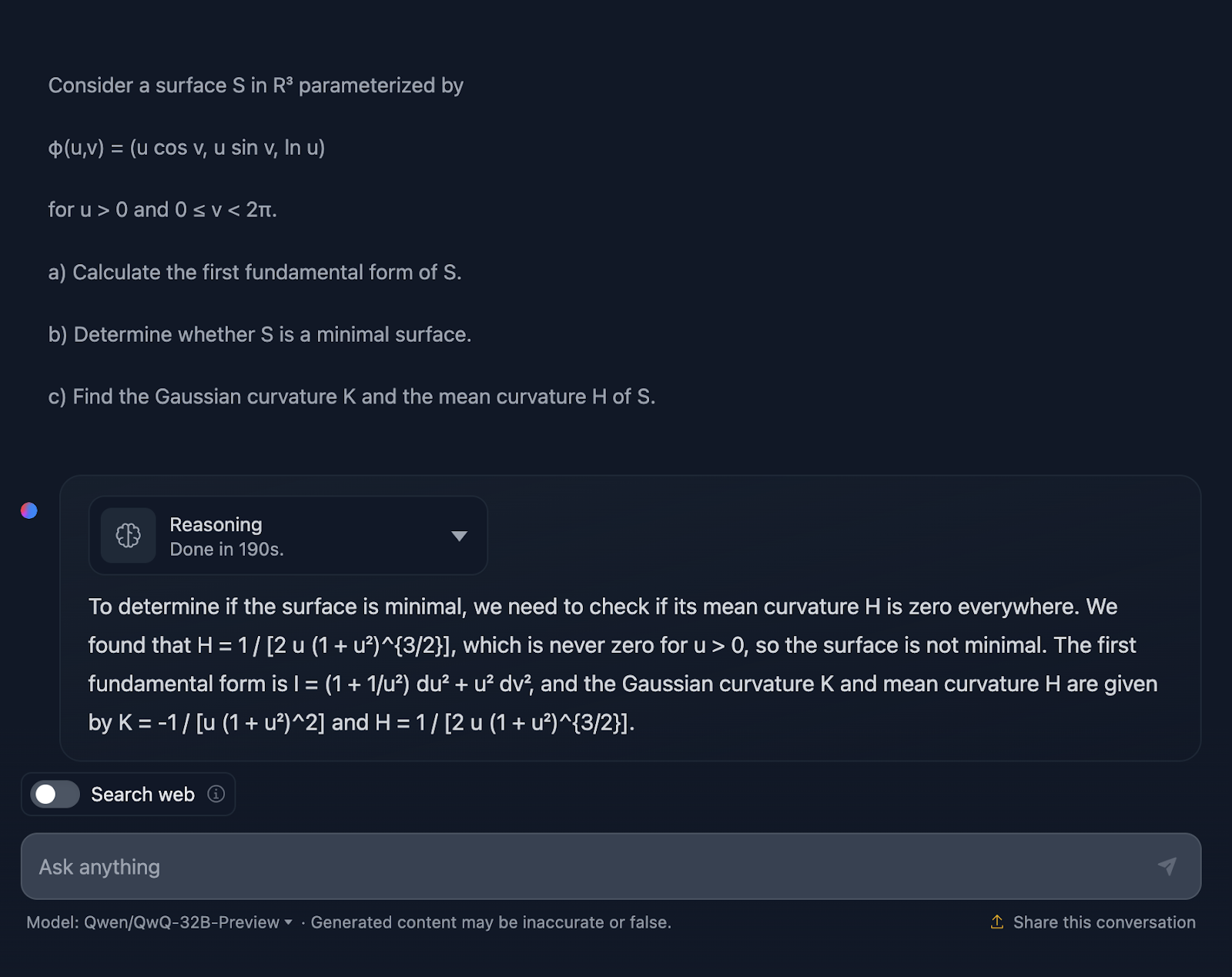
Alright, so I’m not surprised by the answer since it’s quite similar to the previous test in terms of style. Again, it’s not technically wrong, but there’s definitely room for improvement in how the explanation is communicated.
The explanation skips over the how. I wouldn’t expect a step-by-step approach, of course, but at least some formulas to show where the results come from. Plus, it doesn’t break the answer into sections, and the formatting of the formulas is, once again, not the best. DeepSeek did a great job in this regard.
Once again—not full marks for QwQ, but full marks for DeepSeek!
Let’s take a look at the reasoning (for readability, I’m only showing the first and the last part):
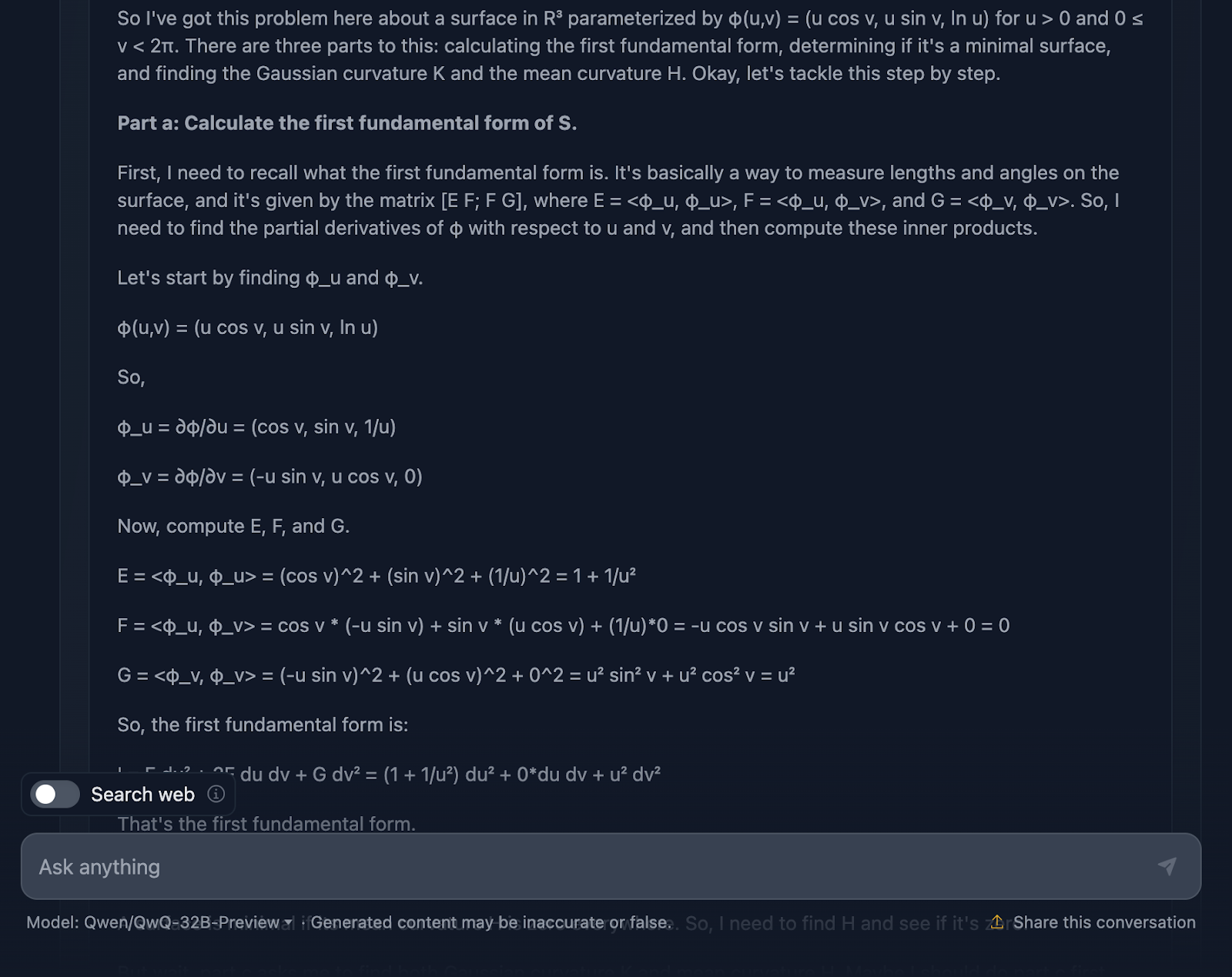
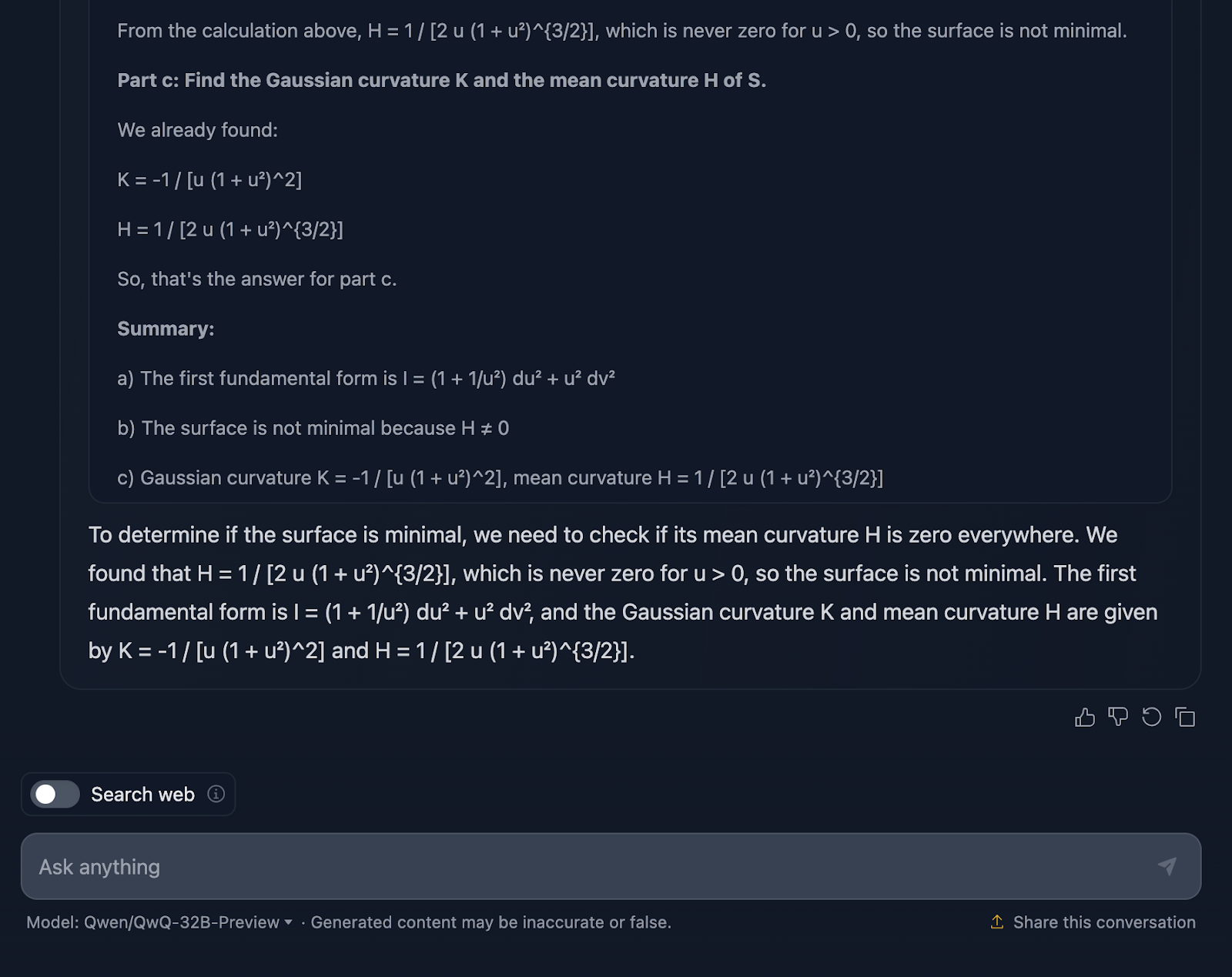
Alright, let’s talk about the model’s reasoning here. First off, I have to give it credit where credit is due—it’s thorough. The breakdown into clear sections—Part a, Part b, and Part c—makes it easy to follow, and it does a solid job of walking us through the steps. It starts by tackling the first fundamental form, carefully calculating the coefficients from the parameterization, and then builds from there. By the time it gets to the Gaussian and mean curvatures in Part c, the groundwork has been laid pretty well.
Now, here’s where things start to feel a little clunky. While the calculations are technically correct, the model spends a lot of time rechecking steps or revisiting calculations, which is great for accuracy but not so great for readability.
Let’s talk now about the formatting. The formulas are all there, but they’re not presented in the clearest way–once again. It’s a bit messy, and for anyone trying to follow along, that can make things harder than they need to be. A cleaner layout with key results highlighted would really improve this explanation.
Another thing missing is context. The model gives us the results, but it doesn’t really stop to explain what they mean. For example, why does the Gaussian curvature matter here? Or what does it tell us about the geometry of the surface? And when it concludes that the surface isn’t minimal, it’s technically right—but it misses an opportunity to expand on what that means in a broader sense.
We have tested the performance of QwQ-32B-Preview on math tests, and I’m not too impressed—but maybe I’m biased because I really liked the output of DeepSeek. Let’s see how it performs on coding tests and if QwQ-32B-Preview can surprise me this time.
The first test is:
“Implement a function in Python that finds the longest palindromic substring in a given string. The function should have a time complexity better than O(n^3).”
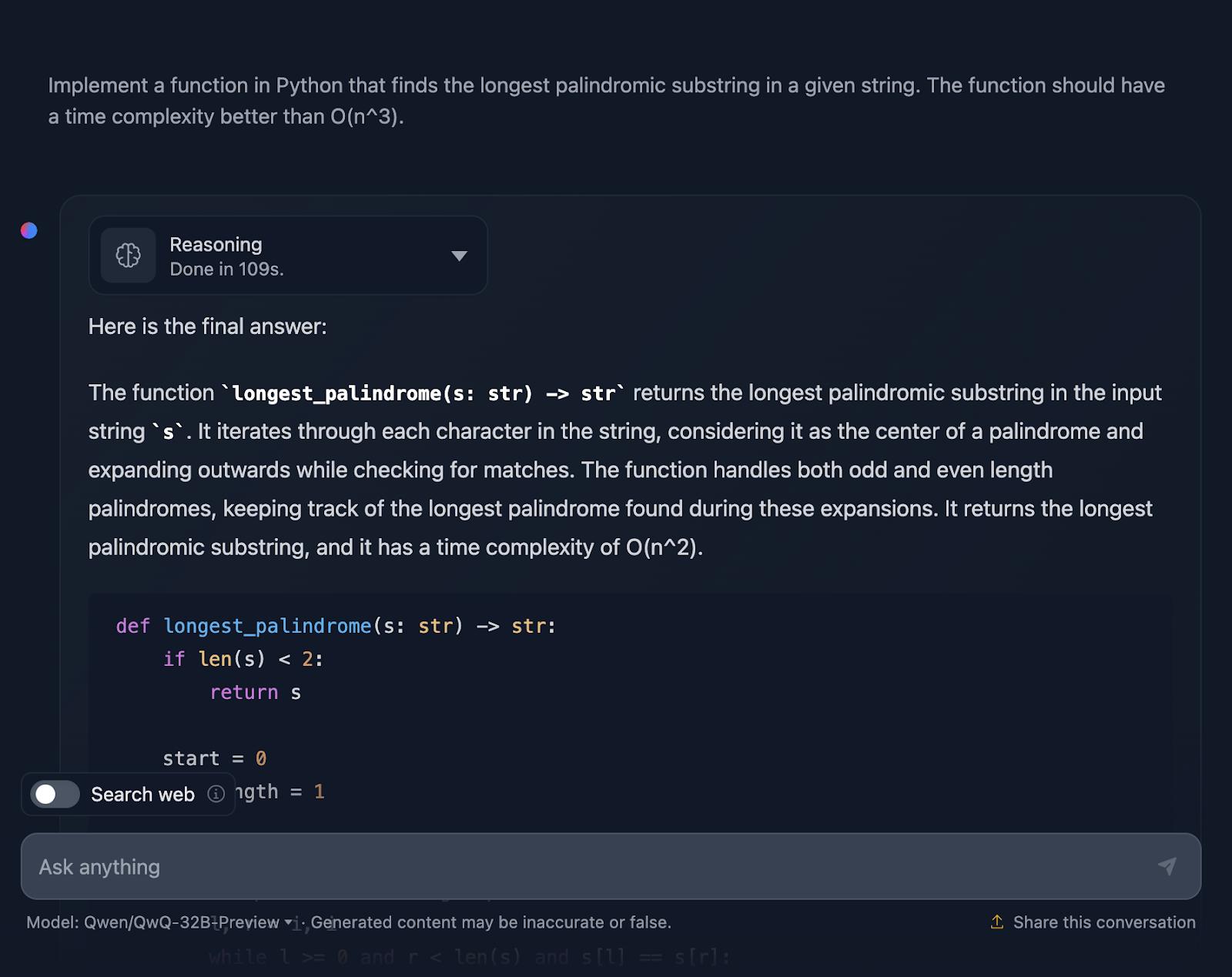
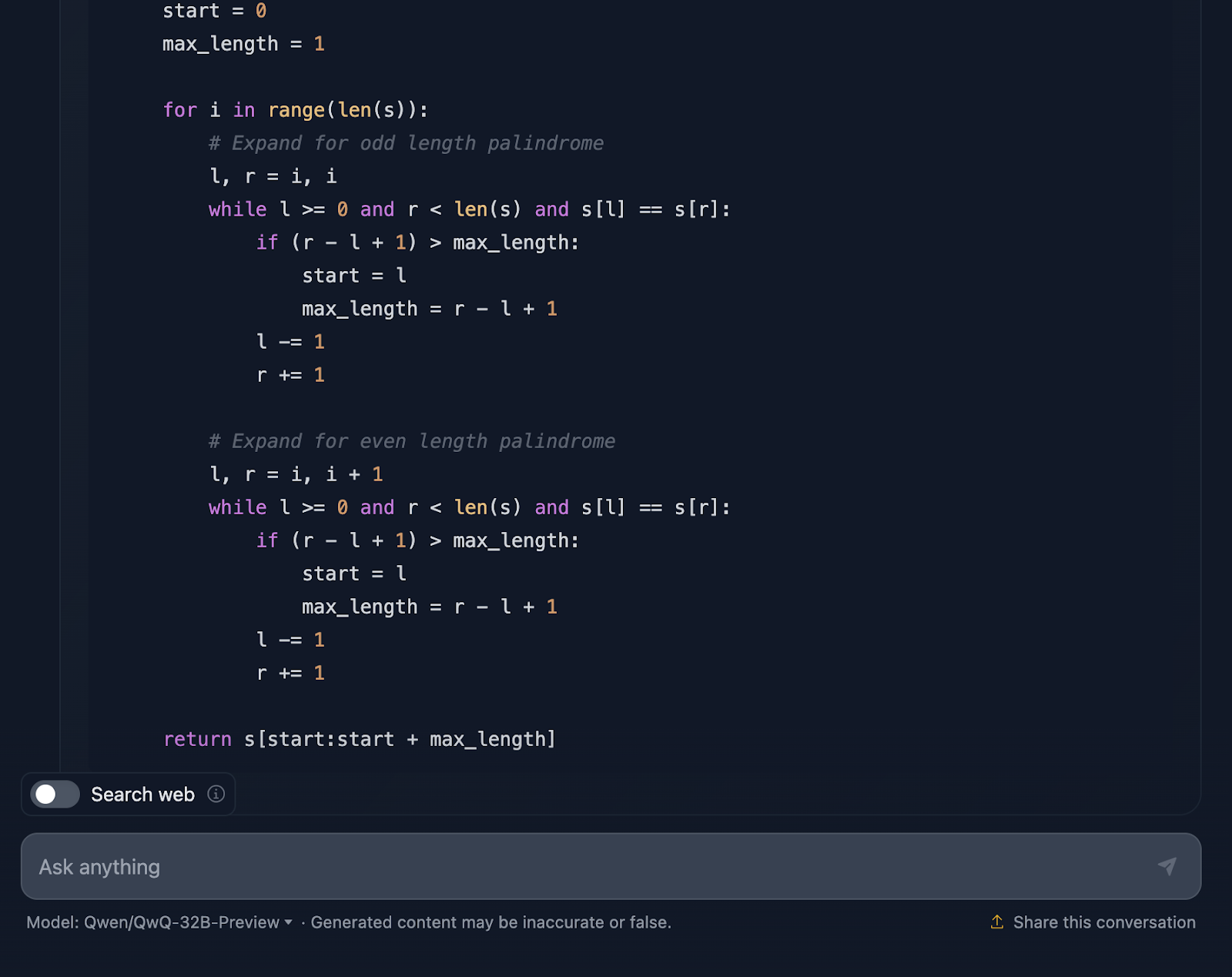
The solution is correct and provides a clean, efficient way to find the longest palindromic substring with the required complexity. It uses a smart approach by expanding around each character to check for palindromes and handles both odd and even lengths well. The code is clear and easy to follow. However, I would have liked to see test cases at the end, which is something that DeepSeek provided. Let’s look now at the reasoning (I’ll only show the first and the last part for readability):
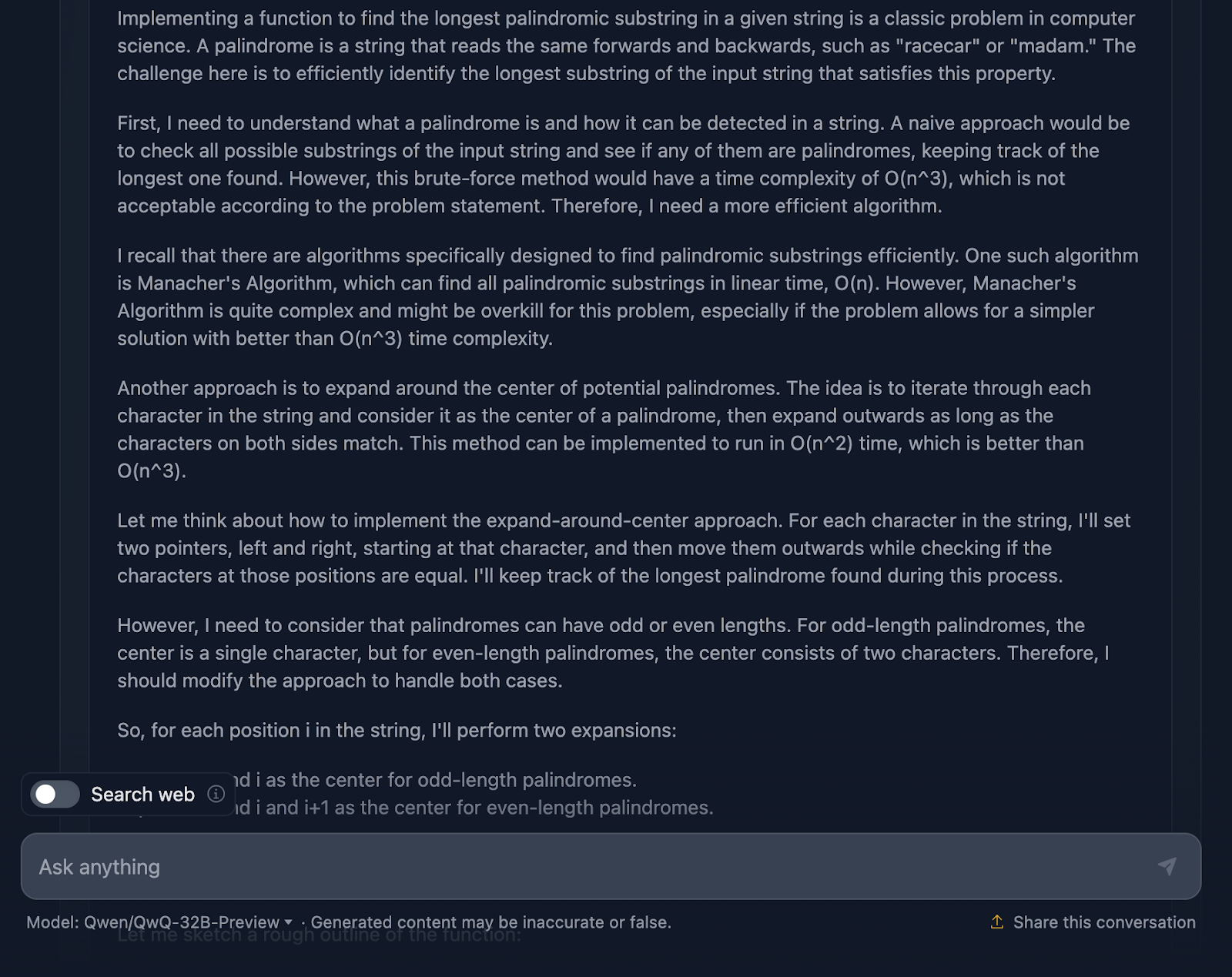
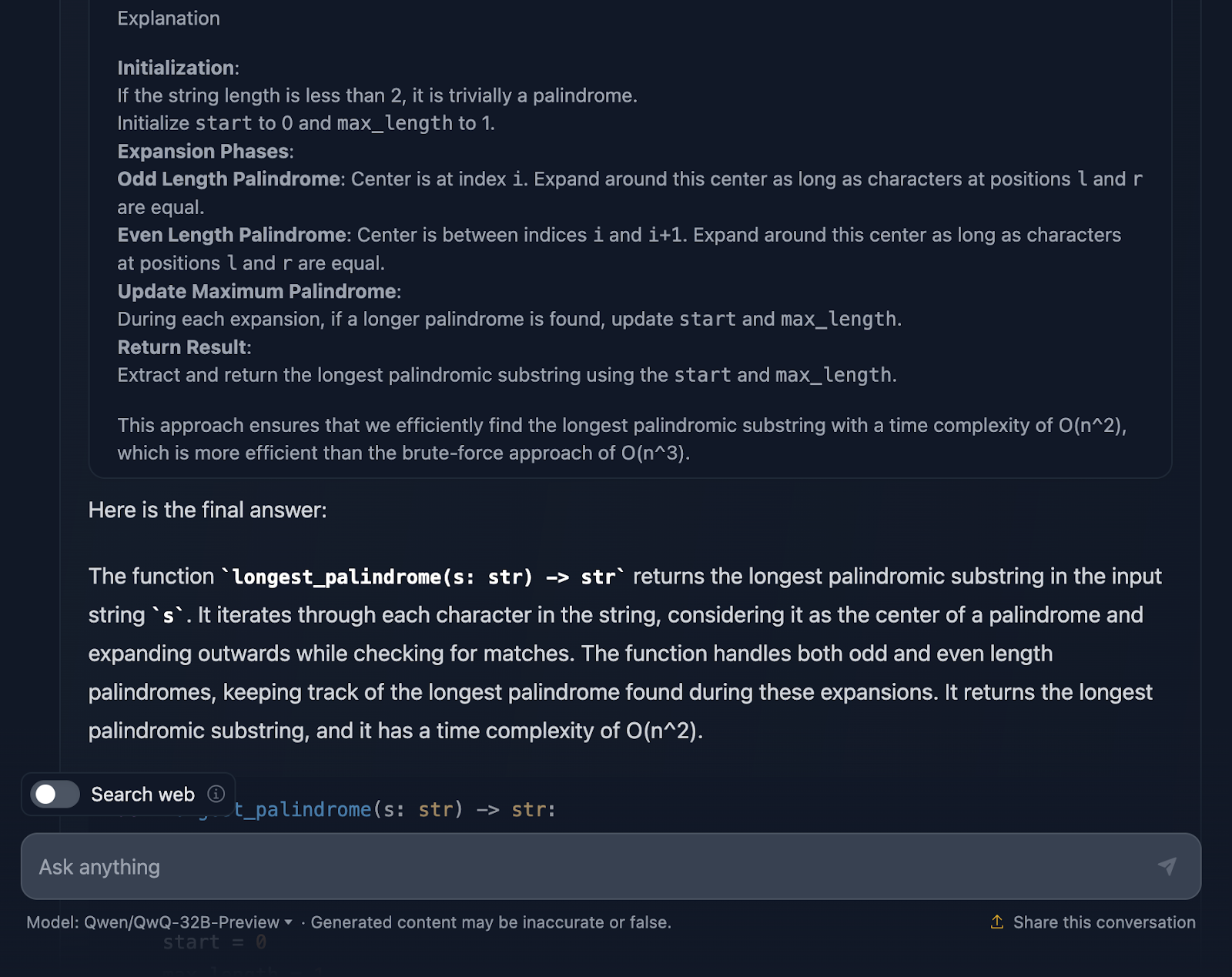
I’ve got to say, it’s a pretty solid approach, and I am actually impressed by some of the parts of the reasoning. But there are a few things where it could be a bit tighter—so let’s talk through it.
First off, the reasoning starts by tackling the basics: what a palindrome is and why a brute-force approach is not the best approach. Then jumps straight into the expand-around-center method and even mentions Manacher’s Algorithm with its O(n) complexity. It acknowledges that while Manacher’s is faster, it’s probably overkill for this problem. DeepSeek did not mention this approach, which is something I was expecting before trying it. It also talks about alternative methods, like reversing the string or skipping unnecessary checks, which I think is great!
The expand-around-center method is explained clearly and separates odd-length and even-length palindromes, which is key to making sure all cases are covered.
The inclusion of edge cases is a highlight. Single-character strings, strings with no palindromes, strings made up of all identical characters—it’s all there. Plus, it even mentions how the implementation gracefully handles empty strings by simply returning them. That kind of thoroughness is what you want in an explanation.
I really like that the final result in the reasoning gives you a breakdown of the approach, solution code and explanation, but I wish this was included in the final response!
Did QwQ-32B-Preview perform better than DeepSeek for this one? Well, despite including test cases, I would say so!
Now, I am going to test a coding challenge in Javascript:
“Write a function in JavaScript that determines whether a given number is prime.”
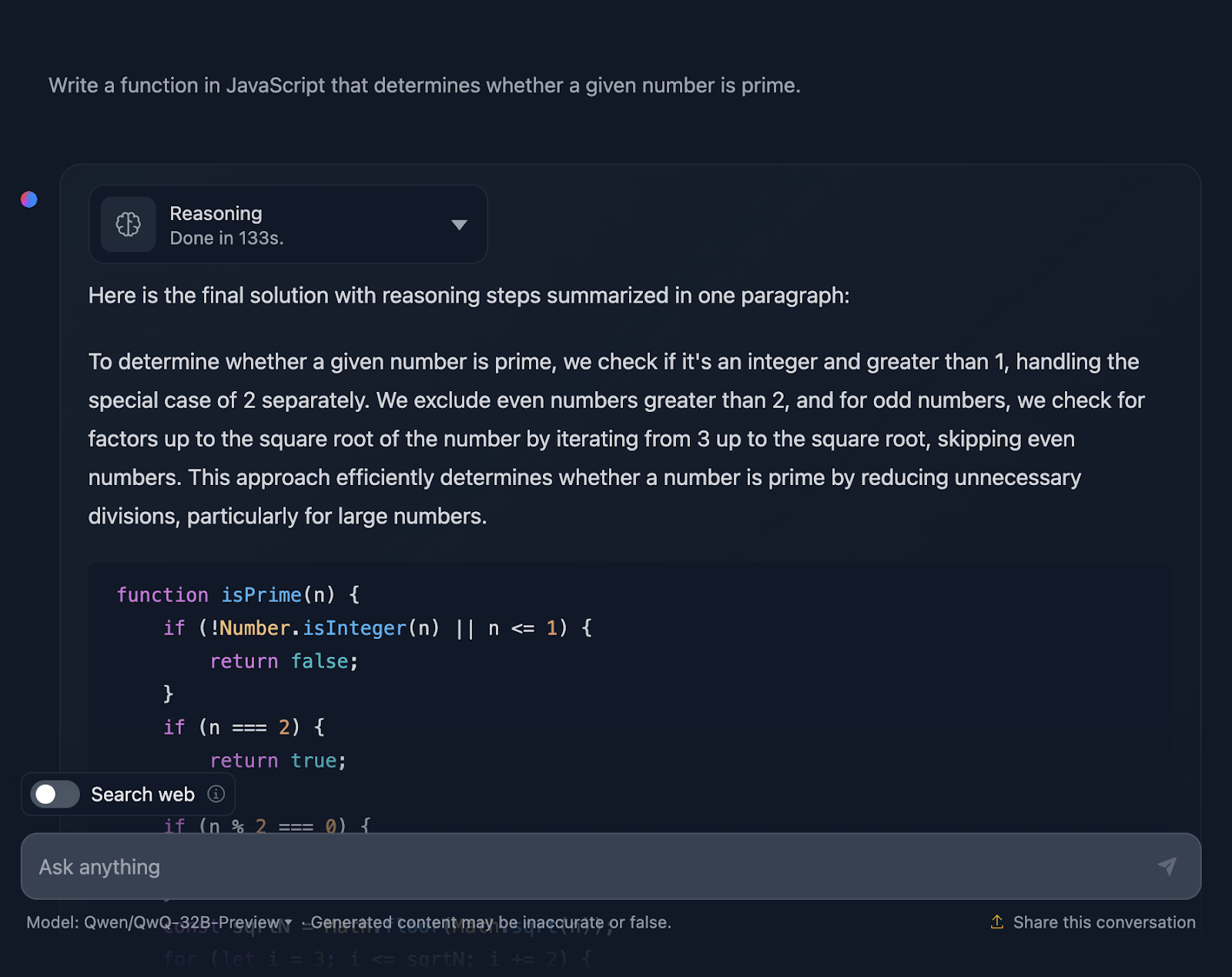
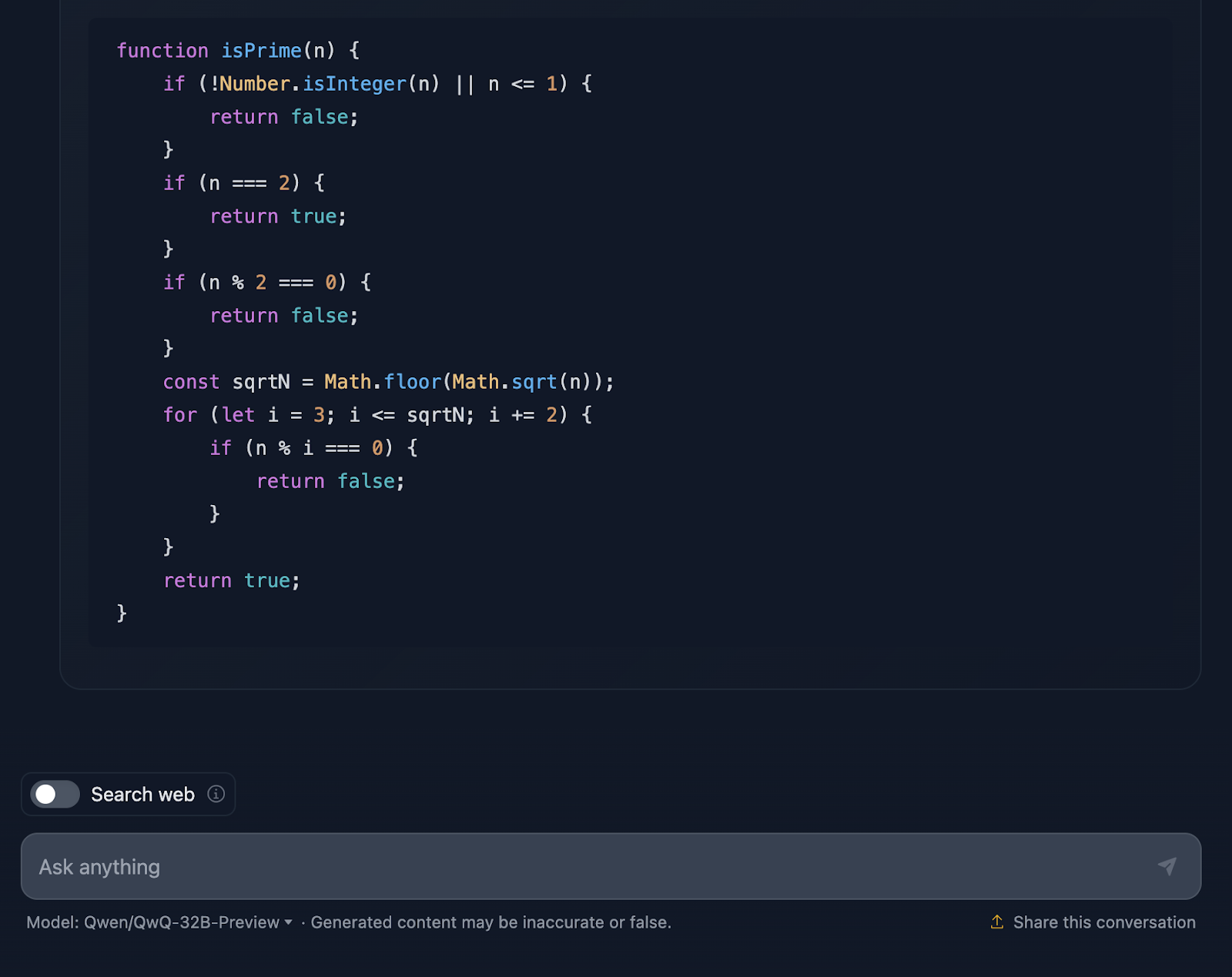
The solution is correct and very similar to the one output from DeepSeek. However, it took much longer to do the reasoning, so let’s see how it has arrived at this answer (I’m truncating the output again for readability):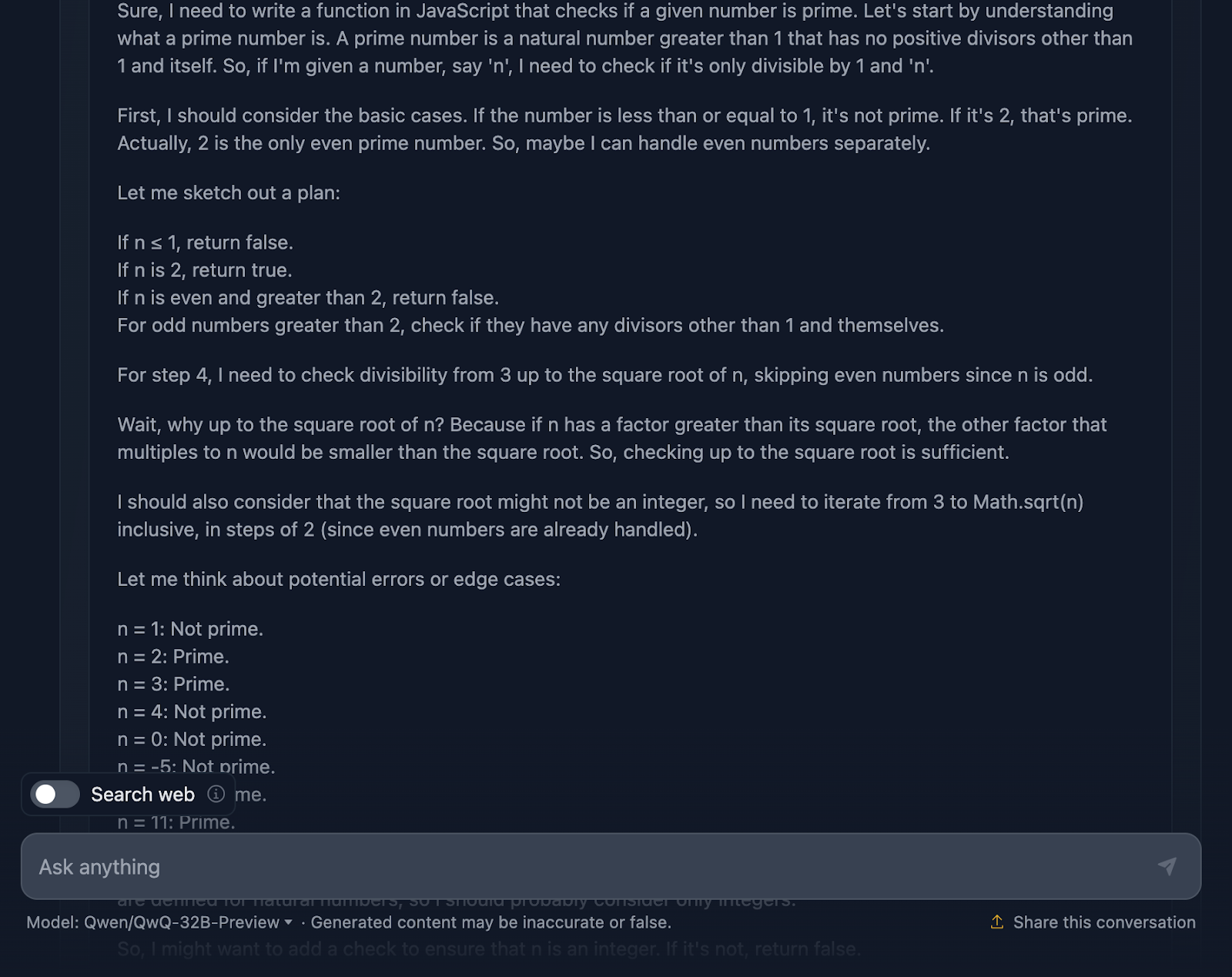
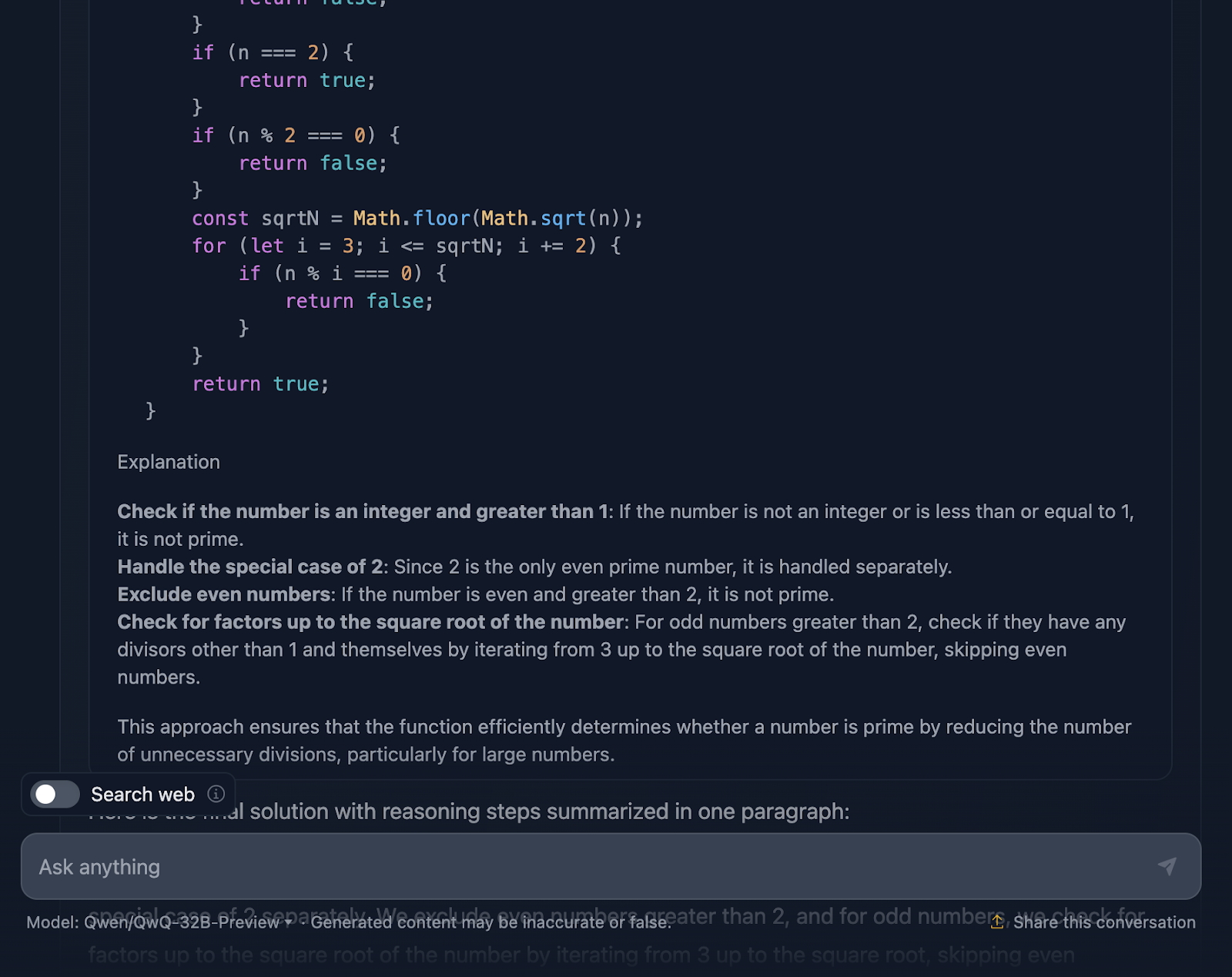
Okay, so this reasoning is particularly long compared to the one provided by DeepSeek. Let’s look into it in more detail:
First off, the solution starts strong by addressing the basics. Numbers less than or equal to 1? Definitely not prime. And 2 is special—it’s the only even prime number. Any other even number? Automatically, not prime. This logical setup is clear and makes a lot of sense when handling edge cases.
From there, it gets to the heart of the matter: how do we efficiently check if a number has any divisors other than 1 and itself? Instead of checking every single number up to n, the solution only checks up to the square root of n. Why? Because if a number has a factor greater than its square root, its other factor will already have been checked below the square root. Super efficient, and it avoids unnecessary computations.
To make things even faster, the solution skips all even numbers after handling 2. So, it’s just checking odd numbers, starting from 3 and stepping by 2. This is a neat optimization that cuts the work in half.
Next, we move into the implementation. The function starts by validating the input. Is it an integer? Is it greater than 1? If not, it’s a quick “not prime.” This kind of validation is a great practice and keeps the function robust. The loop logic then starts, checking divisors from 3 up to the square root of n. If any divisor works, it’s not a prime. Otherwise, it’s all clear, and the number is prime.
What’s great is that the reasoning doesn’t stop at implementation. It dives into edge cases—like negative numbers, non-integers, or weird inputs like 2.5—and makes sure the function handles them correctly. There’s even a nod to JavaScript’s limits with really big numbers and a suggestion to use BigInt for those edge scenarios which I thought was a great addition to the reasoning.
The solution includes detailed test cases to show exactly how it works for numbers like 1, 2, 3, and even larger numbers like 13 and 29. Each test is explained step-by-step, so there’s no confusion about why the function works.
Now, could this solution go further? Sure, there’s always room for improvement. For instance, if you were working with massive numbers, you might want to explore advanced algorithms like Miller-Rabin or Fermat’s primality test. But for everyday use, this solution strikes a great balance between simplicity, efficiency, and readability.
So, what’s the verdict? This reasoning is solid, clear, and practical and does a great job of making sure that the code is robust, something that DeepSeek didn’t take that much into consideration. I think QwQ-32B-Preview wins!
Finally, let’s look at some logical reasoning tests.
I am going to test a classic puzzle:
"A man has to cross a river with a wolf, a goat, and a cabbage. His boat can only carry himself and one other thing. If left alone, the wolf would eat the goat, and the goat would eat the cabbage. How can he get everything across safely?"
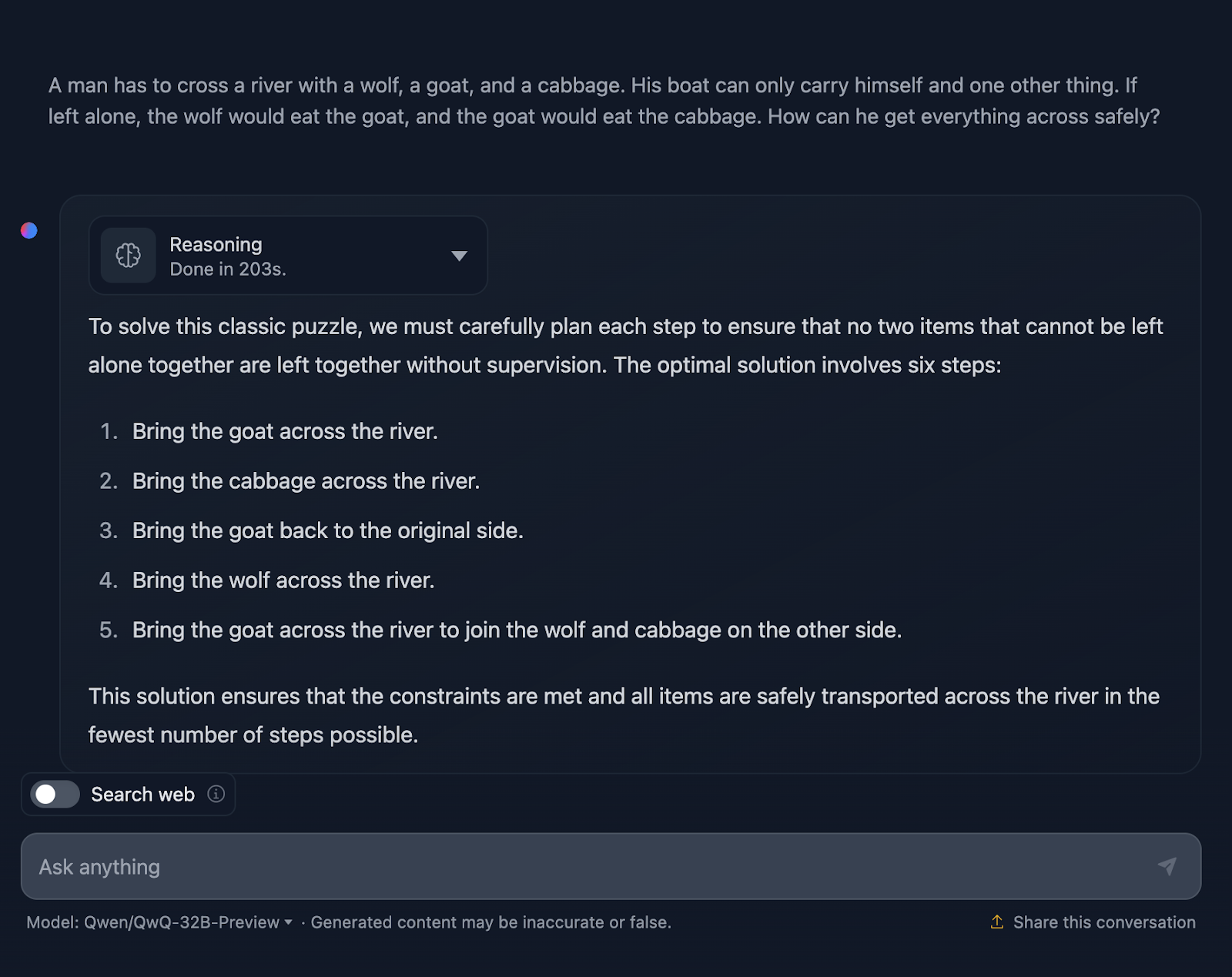
Okay, so the solution to the problem is correct, but there are a couple of things that need clarification. It states that the optimal solution involves six steps; however, only five bullet points are provided. This is already an inaccuracy.
Additionally, you might think this is a better approach in terms of efficiency compared to the DeepSeek output, which took seven steps. However, this approach is actually seven steps too. The steps involving coming back alone were not mentioned for some reason. It should have output the following:
Also, when it was performing the reasoning, I spotted this (and managed to screenshot it!):
This made me wonder if something was with the reasoning…
Let’s have a look:
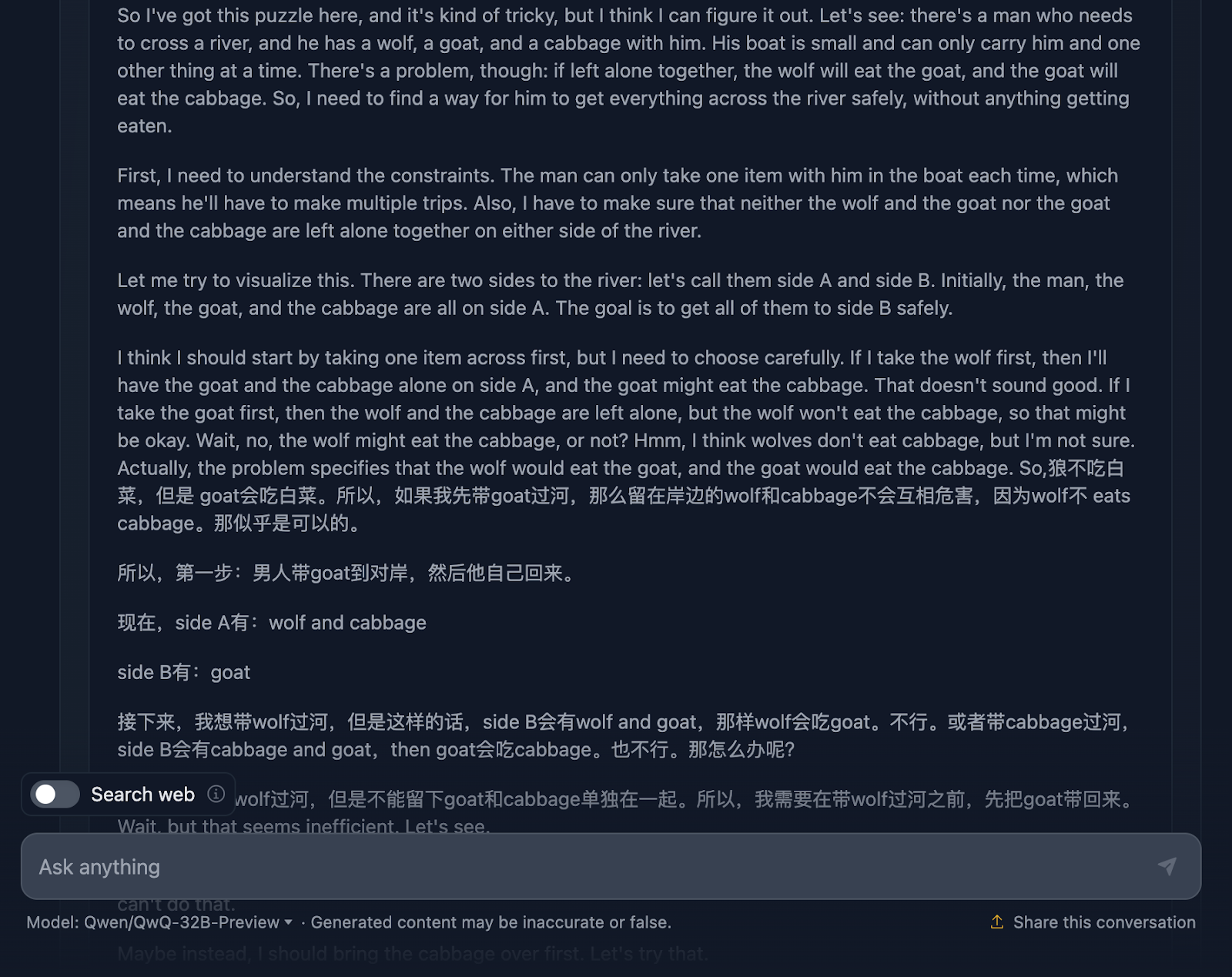
The reasoning starts great by thoroughly ensuring it understands the problem, the challenges, and the constraints. However, this is where things start to get messy. This is a great example of the limitations of this model we discussed earlier, which mixes two languages. This results in incomprehensible reasoning (at least for me, as I don’t understand the language—I'm assuming it’s Chinese!). I will now share some other parts of the reasoning to illustrate this, but I’m skipping other parts as it's too lengthy.
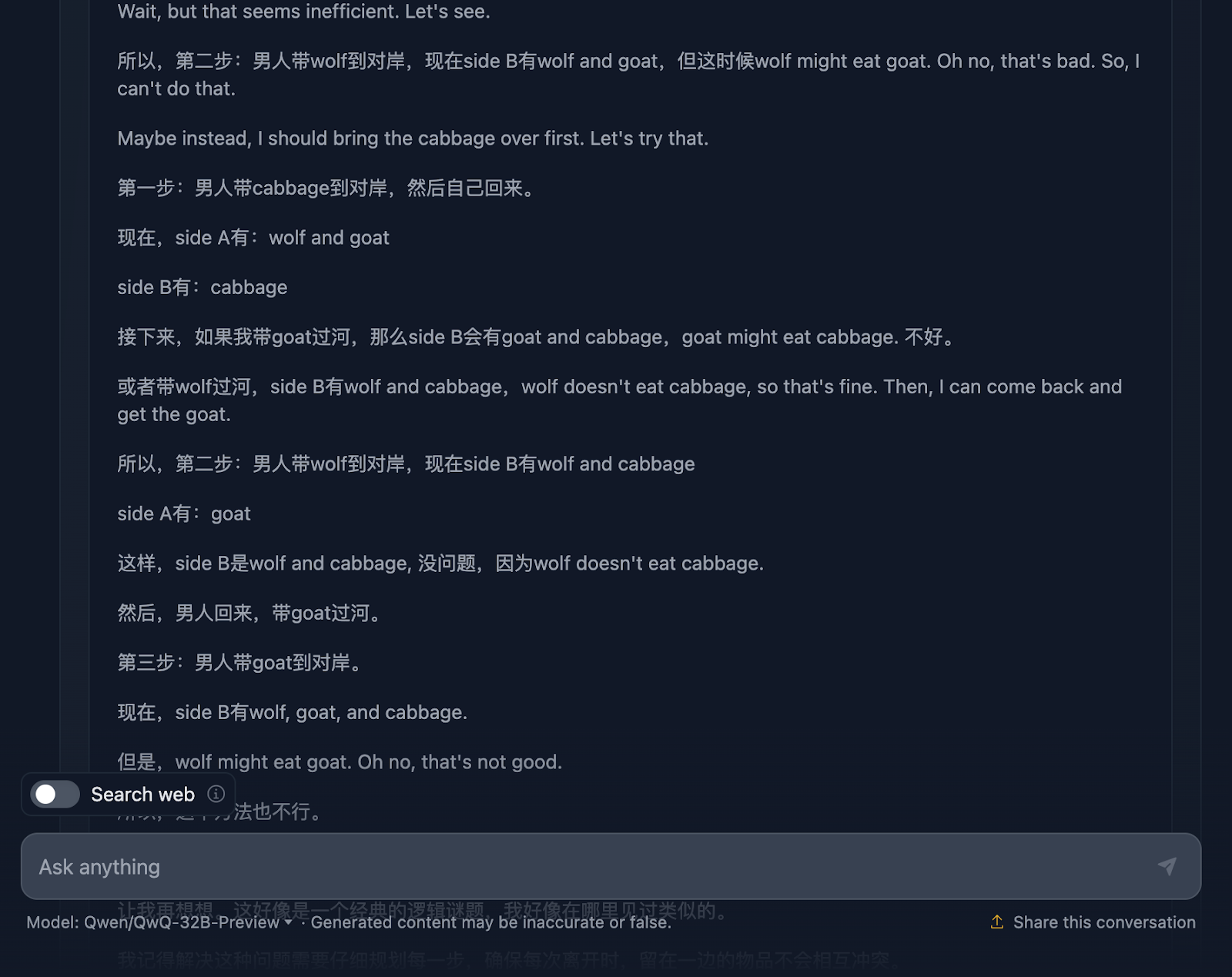
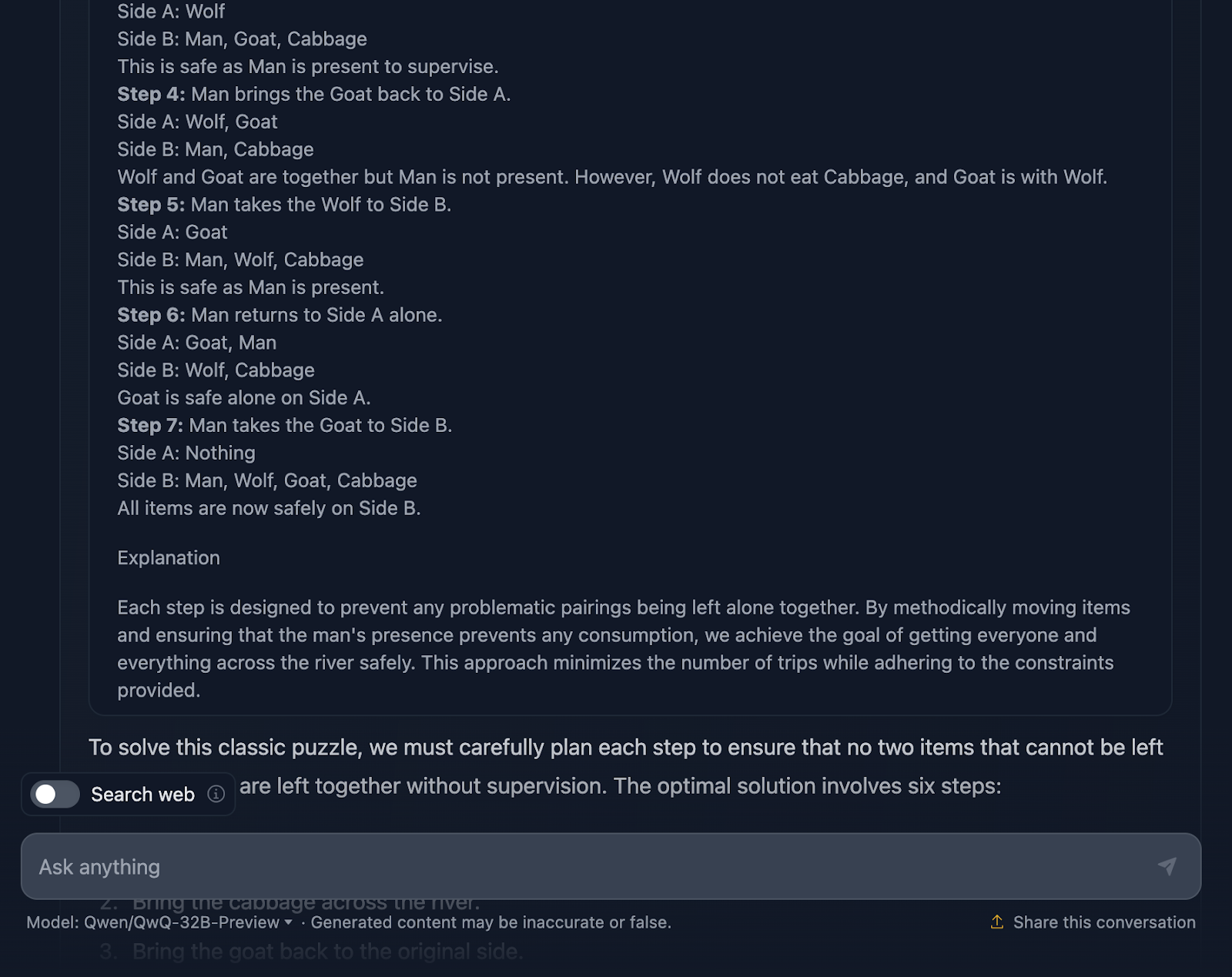
However, the final solution is excellent! It outlines the initial setup, constraints, objective, and strategy, along with a very clear solution plan that does include all the steps, interestingly enough!
So why wasn’t this reflected in the final answer? It even added a final explanation. I wish the output of the final answer had matched what was displayed in the reasoning, and I wonder why it didn’t do this!
Finally let’s try this classic logic puzzle that tests the model's ability to come up with an optimal strategy using deductive reasoning.
DISCLAIMER: This is the output I got after three tries—the model started generating an answer but got stuck or produced an error and couldn’t continue generating. Also, I will skip the reasoning for this one as it was extremely long, plus the output is already quite extensive! Let’s have a look (the output is also truncated):
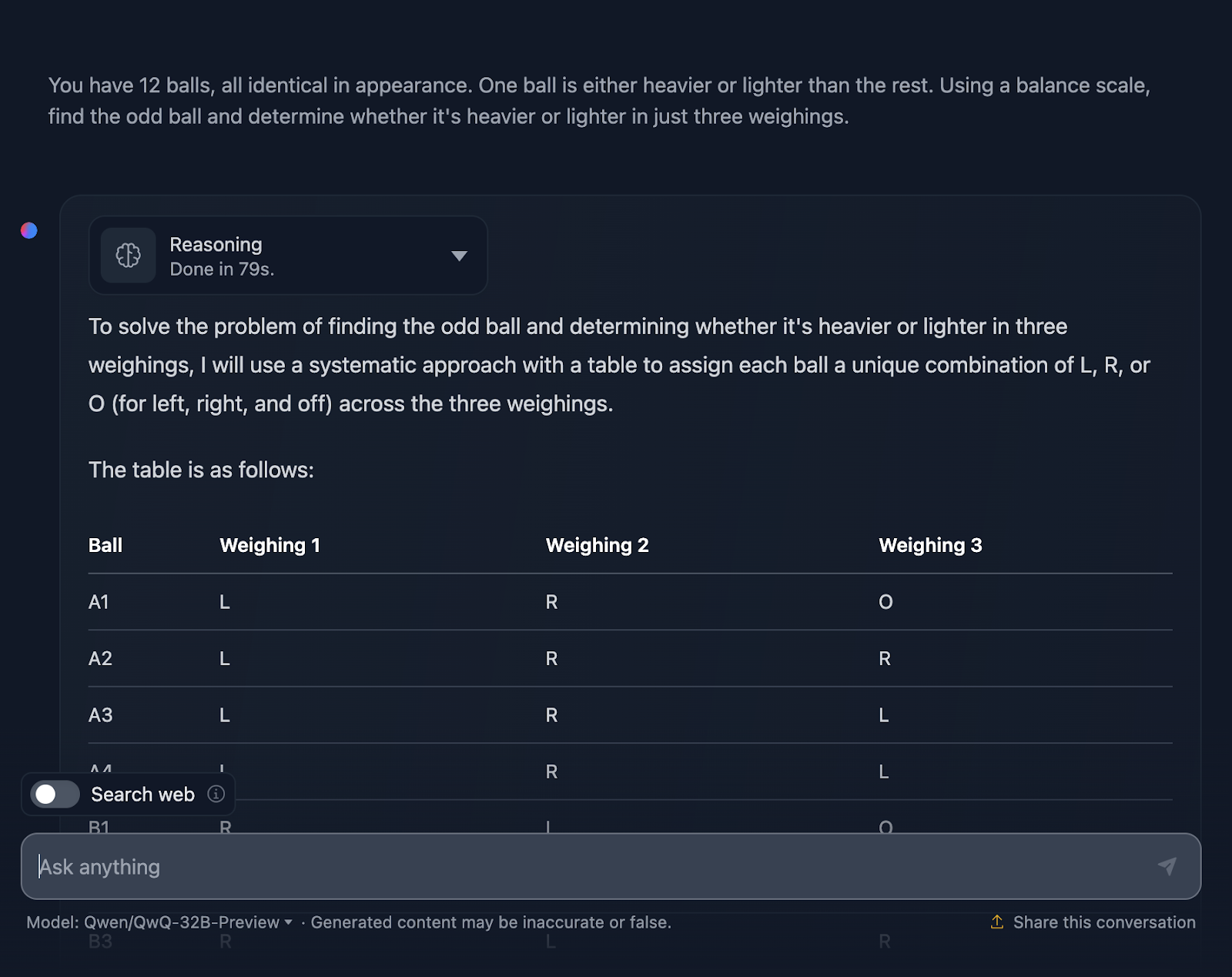
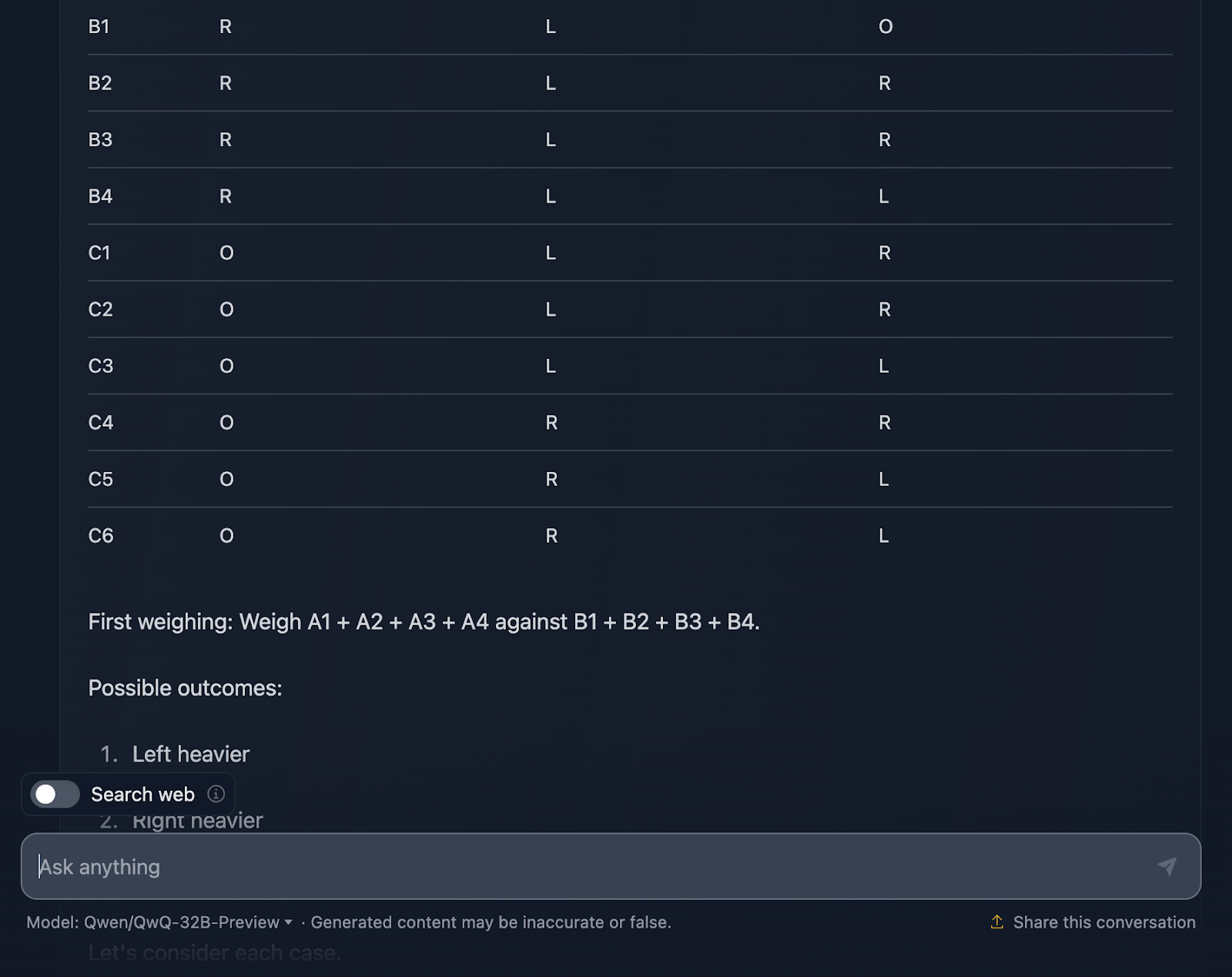
I have to say I am very impressed with the output! The solution starts with a very clear explanation of the problem and lays out a plan using a systematic table, which I think is very helpful and something DeepSeek did not include. Every ball gets its own unique combination across the three weighings, making sure all possible scenarios are accounted for.
I really like how it breaks the problem into cases and subcases: “Left heavier,” “Right heavier,” and “Equal.” This incremental approach takes a complex problem and makes it manageable. Each weighing builds on the results of the previous one. You’re narrowing down the odd ball step by step while also determining if it’s heavier or lighter.
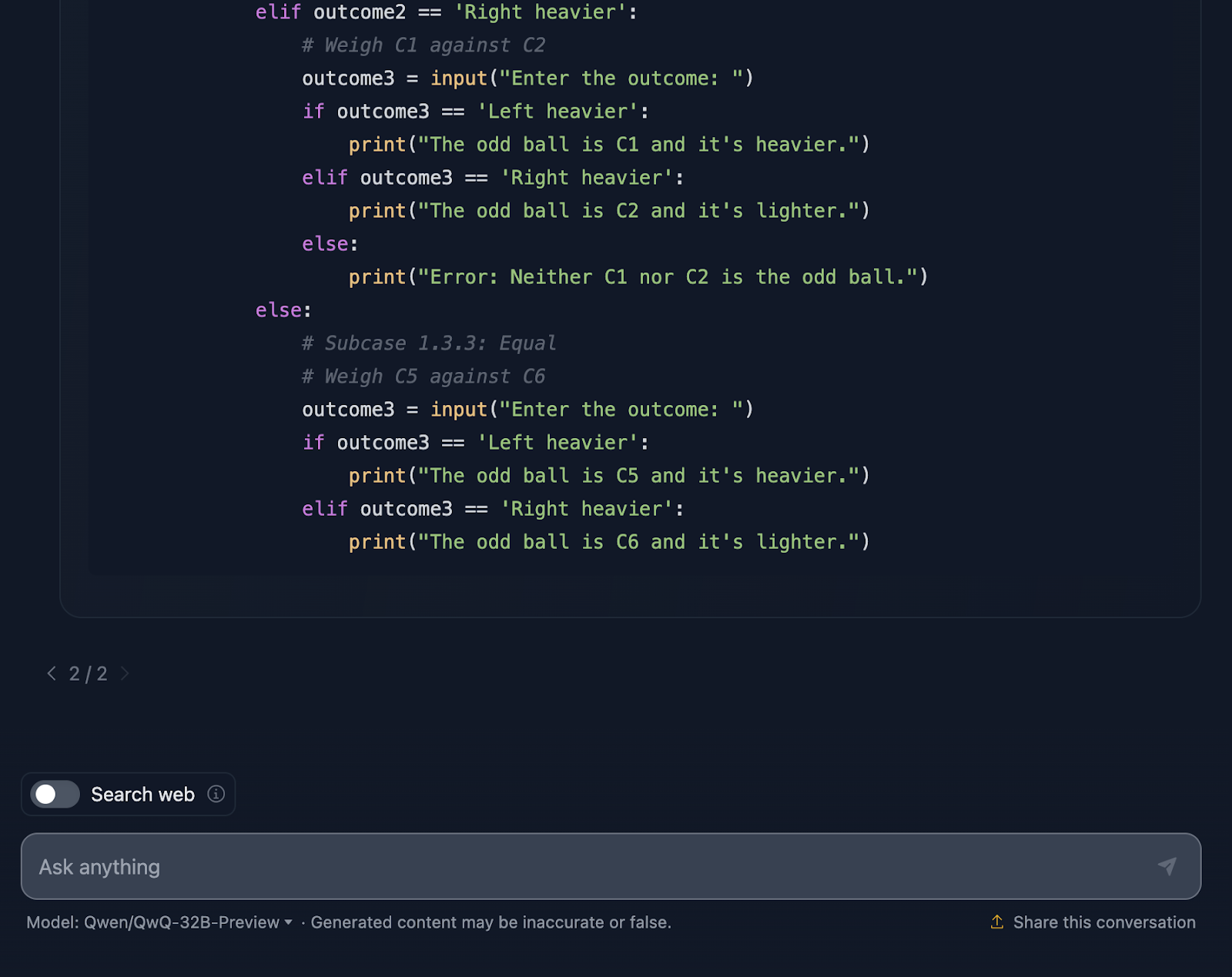
Finally, the solution includes a Python code snippet, which I didn’t expect! It’s interactive, letting users simulate the weighings, which makes the process easier to follow and even fun to explore. This solution doesn’t leave anything to chance. Every single outcome of the weighings is covered, making sure that no oddball can escape detection.
One thing though is that the Python snippet assumes perfect user input. If someone enters an invalid weighing outcome, the code doesn’t have error handling to catch that. A little robustness here could take it to the next level.
I would say this is an excellent answer—it beats DeepSeek’s one in terms of making it clearer and helping users visualise it better with the tables and the Python code.
Finally, I am going to compare the speed of each model for each test in performing the reasoning and providing a solution. Something to keep in mind is that the results would depend on many factors, and the models wouldn’t always perform at the same speed, but I find it interesting that DeepSeek was quicker for every task I tested.
|
Task |
DeepSeek Time in seconds |
QwQ time in seconds |
|
Strawberry Test |
8 |
20 |
|
Triangle |
18 |
42 |
|
Fibonacci |
27 |
105 |
|
Geometry |
62 |
190 |
|
Python |
62 |
109 |
|
JavaScript |
6 |
133 |
|
Wolf/Goat/Cabbage |
5 |
203 |
|
Balls Puzzle |
25 |
79 |
Testing QwQ-32B-Preview revealed how well it handles tough math, coding, and reasoning challenges—although some were better than others!
Here’s how QwQ performed on some challenging benchmarks:
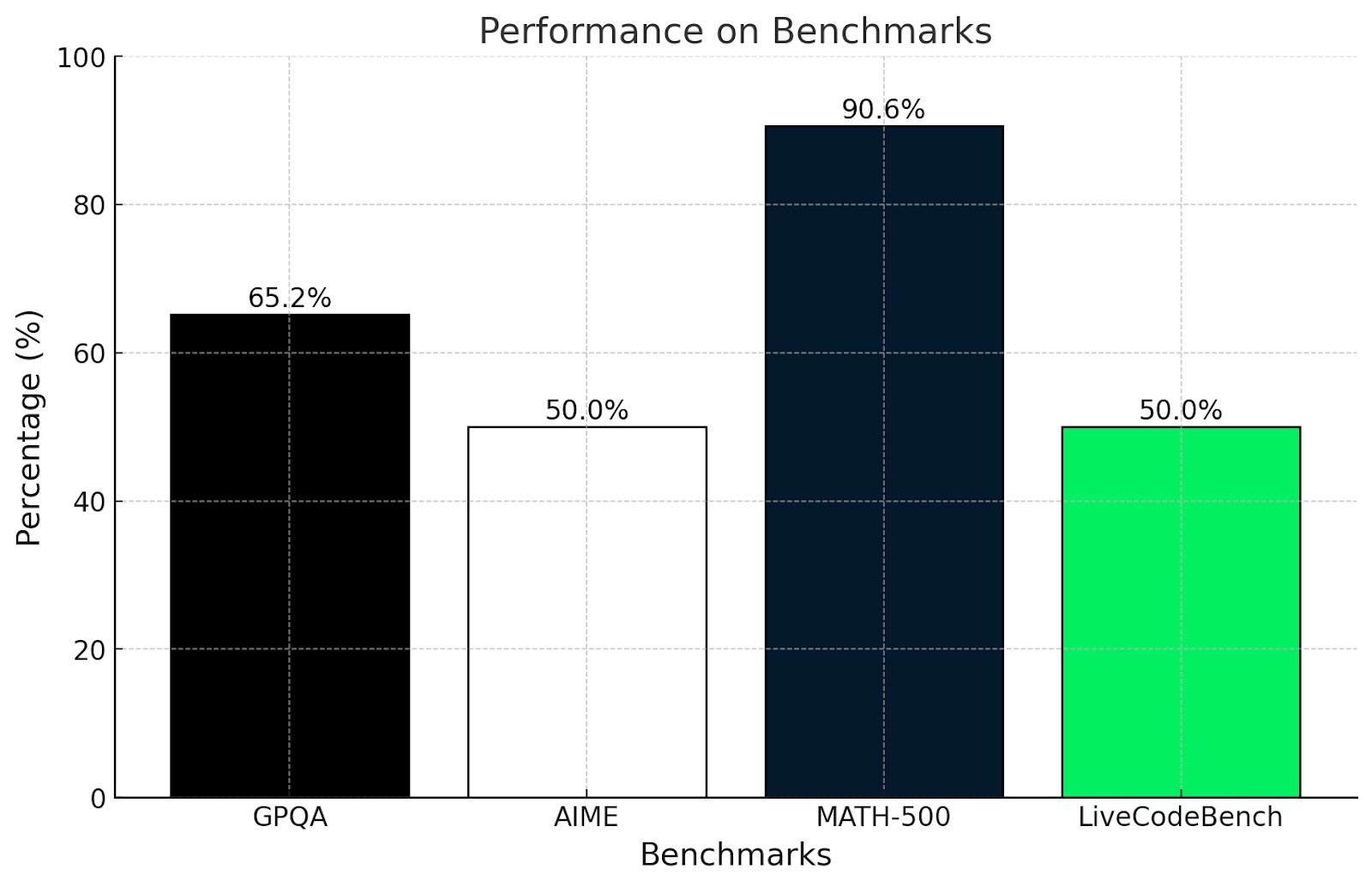
Am I surprised by these results? Not really. These results align with the tests performed in this article.
The GPQA test measures understanding of graduate-level scientific reasoning. Scoring 65.2% shows it’s good at using logic and math to solve problems, but it might struggle with very specialized or deeply conceptual questions, which we have seen in the more complex math tests in this article.
Similarly, the AIME test is known for advanced math topics like geometry and algebra. A 50% score shows that QwQ-32B-Preview can solve some of these problems but struggles with the really clever ones that need out-of-the-box thinking.
Scoring over 90% at MATH-500 is very impressive and shows that QwQ-32B-Preview is great at solving a general math problem with decent accuracy.
LiveCodeBench measures programming ability in coding scenarios. Scoring 50% means QwQ-32B-Preview can handle coding basics and follow clear instructions, but it might struggle with more complicated tasks.
QwQ is really strong when it comes to solving structured problems and using logic, as seen in the GPQA and MATH-500 scores. It does well with math and science but finds creative or unconventional problems, like in AIME, more challenging. Its programming skills are decent but could be better when dealing with messy or unclear coding tasks.
Let’s have a look now at QwQ 32B-preview metrics along with DeepSeek's metrics and other models for comparison:
|
Benchmark |
QwQ 32B-preview |
DeepSeek v1-preview |
OpenAI o1-preview |
OpenAI o1-mini |
GPT-4o |
Claude3.5 Sonnet |
Qwen2.5-72B Instruct |
DeepSeek v2.5 |
|
GPQA |
65.2 |
58.5 |
72.3 |
60.0 |
53.6 |
65.0 |
49.0 |
58.5 |
|
AIME |
50.0 |
52.5 |
44.6 |
56.7 |
9.3 |
16.0 |
23.3 |
52.5 |
|
MATH500 |
90.6 |
91.6 |
85.5 |
90.0 |
76.6 |
78.3 |
82.6 |
91.6 |
|
LiveCodeBench |
50.0 |
51.6 |
53.6 |
58.0 |
33.4 |
36.3 |
30.4 |
51.6 |
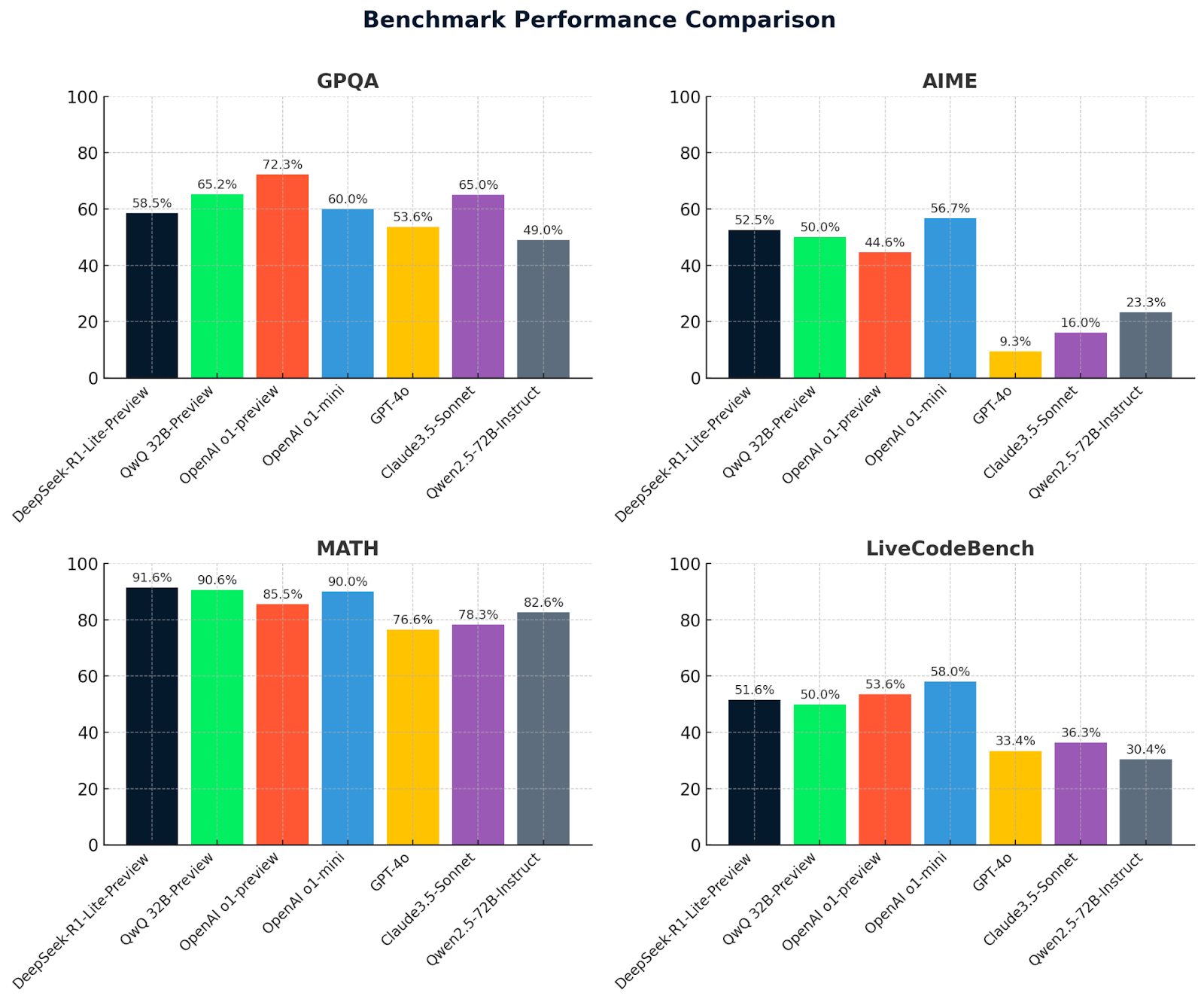
These graphs provide a clear comparison of model performances across four benchmarks: GPQA, AIME, MATH, and LiveCodeBench. DeepSeek-R1-Lite-Preview stands out for its strong results, especially in MATH (91.6%), showcasing its capability in advanced reasoning and problem-solving.
QwQ-32B-preview performs consistently well across all benchmarks, particularly excelling in MATH (90.6%), demonstrating its robust mathematical and general reasoning abilities. Other models like OpenAI O1-preview and Claude 3.5-Sonnet show varied strengths but generally trail behind QwQ-32B-preview and DeepSeek in key areas, highlighting the competitive edge of these two leading models.
Testing QwQ-32B-Preview was a lot of fun, and I hope I wasn’t too biased—though I have to admit, DeepSeek-R1-Lite-Preview really impressed me!
QwQ-32B-Preview is clearly a strong model with amazing capabilities, but it’s not perfect and the final answer given by the model doesn’t always match the final answer in the reasoning process, which often had a better solution than what was actually presented.
Have you given QwQ a try? What did you think? Do you like it better than DeepSeek? And who knows—maybe the next big model will be the one to outperform all the others across every benchmark. It’s such an exciting time to see these tools evolve!
Learn AI with these courses!
Track
Track
Course
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Vinod Chugani
15 min
blog
Richie Cotton
8 min
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Ryan Ong
Tutorial
Andrea Valenzuela




