
Track
AI Fundamentals
10 hr
Alibaba has just released Qwen2.5-Max, its most advanced AI model yet. This is not a reasoning model like DeepSeek R1 or OpenAI’s o1, meaning you can’t see its thinking process.
It’s better to think of Qwen2.5-Max as a generalist model and a competitor to GPT-4o, Claude 3.5 Sonnet, or DeepSeek V3.
In this blog, I’ll go over what Qwen2.5-Max is, how it was developed, how it stacks up against the competition, and how you can access it.
We keep our readers updated on the latest in AI by sending out The Median, our free Friday newsletter that breaks down the week’s key stories. Subscribe and stay sharp in just a few minutes a week:
Qwen2.5-Max is Alibaba’s most powerful AI model to date, designed to compete with top-tier models like GPT-4o, Claude 3.5 Sonnet, and DeepSeek V3.
Alibaba, one of China’s largest tech companies, is best known for its e-commerce platforms, but it has also built a strong presence in cloud computing and artificial intelligence. The Qwen series is part of its broader AI ecosystem, ranging from smaller open-weight models to large-scale proprietary systems.

Unlike some previous Qwen models, Qwen2.5-Max is not open-source, meaning its weights are not publicly available.
Trained on 20 trillion tokens, Qwen2.5-Max has a vast knowledge base and strong general AI capabilities. However, it is not a reasoning model like DeepSeek R1 or OpenAI’s o1, meaning it doesn’t explicitly show its thought process. However, given Alibaba’s ongoing AI expansion, we may see a dedicated reasoning model in the future—possibly with Qwen 3.
Qwen2.5-Max uses a Mixture-of-Experts (MoE) architecture, a technique also employed by DeepSeek V3. This approach allows the model to scale up while keeping computational costs manageable. Let’s break down its key components in a way that’s easy to understand.
Unlike traditional AI models that use all their parameters for every task, MoE models like Qwen2.5-Max and DeepSeek V3 activate only the most relevant parts of the model at any given time.
You can think of it like a team of specialists: if you ask a complex question about physics, only the experts in physics respond, while the rest of the team stays inactive. This selective activation means the model can handle large-scale processing more efficiently without requiring extreme amounts of computing power.
This method makes Qwen2.5-Max both powerful and scalable, allowing it to compete with dense models like GPT-4o and Claude 3.5 Sonnet while being more resource-efficient—a dense model is one in which all parameters are activated for every input.
Qwen2.5-Max was trained on 20 trillion tokens, covering a vast range of topics, languages, and contexts.
To put 20 trillion tokens into perspective, that’s roughly 15 trillion words—an amount so vast it’s hard to grasp. For comparison, George Orwell’s 1984 contains about 89,000 words, meaning Qwen2.5-Max has been trained on the equivalent of 168 million copies of 1984.
However, raw training data alone doesn’t guarantee a high-quality AI model, so Alibaba further refined it with:
Qwen2.5-Max has been tested against other leading AI models to measure its capabilities across various tasks. These benchmarks evaluate both instruct models (which are fine-tuned for tasks like chat and coding) and base models (which serve as the raw foundation before fine-tuning). Understanding this distinction helps clarify what the numbers really mean.
Instruct models are fine-tuned for real-world applications, including conversation, coding, and general knowledge tasks. Qwen2.5-Max is compared here to models like GPT-4o, Claude 3.5 Sonnet, Llama 3.1 405B, and DeepSeek V3.
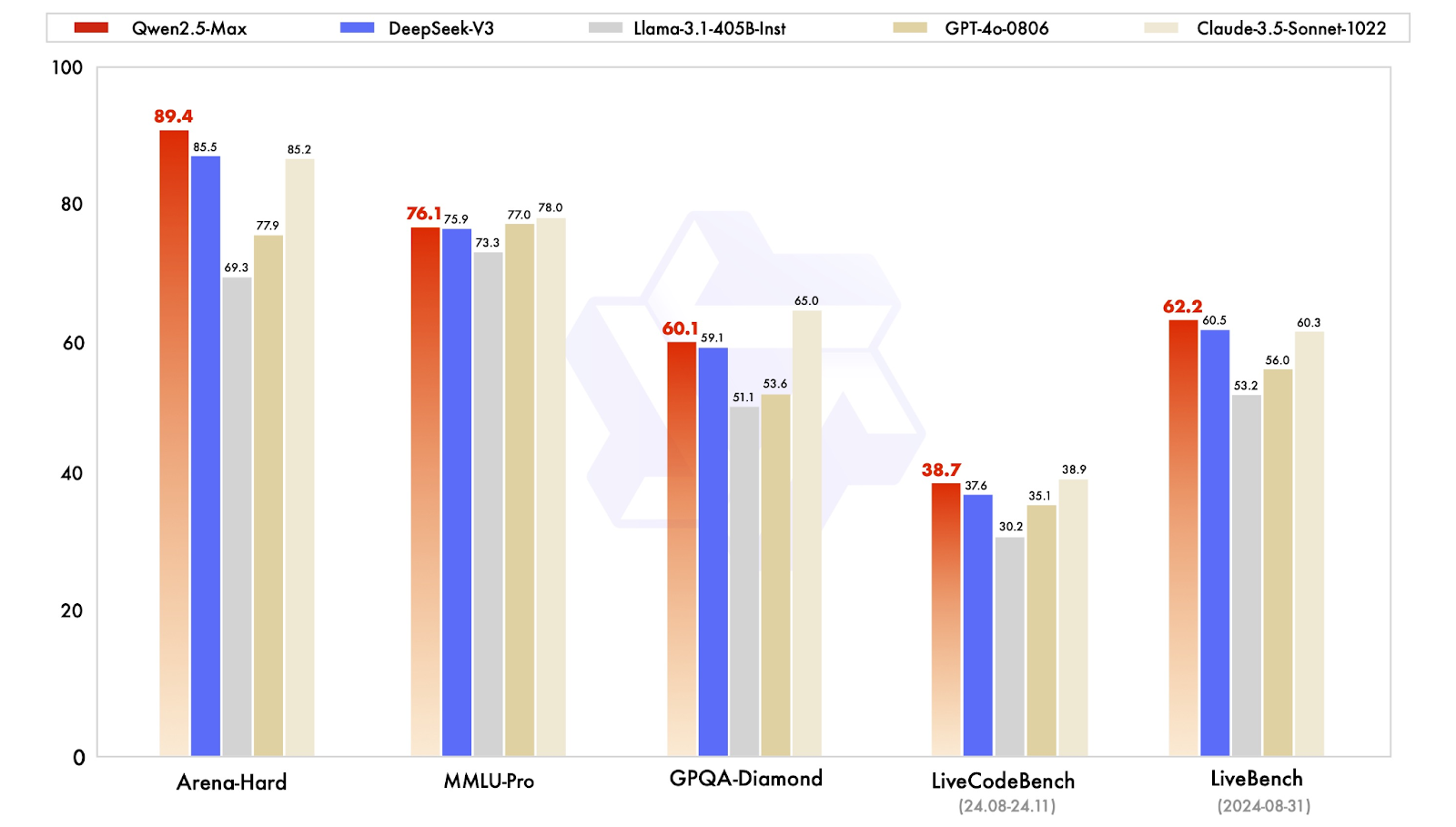
Comparison of the instruct models. Source: QwenLM
Let’s quickly break down the results:
Overall, Qwen2.5-Max proves to be a well-rounded AI model, excelling in preference-based tasks and general AI capabilities while maintaining competitive knowledge and coding abilities.
Since GPT-4o and Claude 3.5 Sonnet are proprietary models with no publicly available base versions, the comparison is limited to open-weight models like Qwen2.5-Max, DeepSeek V3, LLaMA 3.1-405B, and Qwen 2.5-72B. This provides a clearer picture of how Qwen2.5-Max stands against leading large-scale open models.
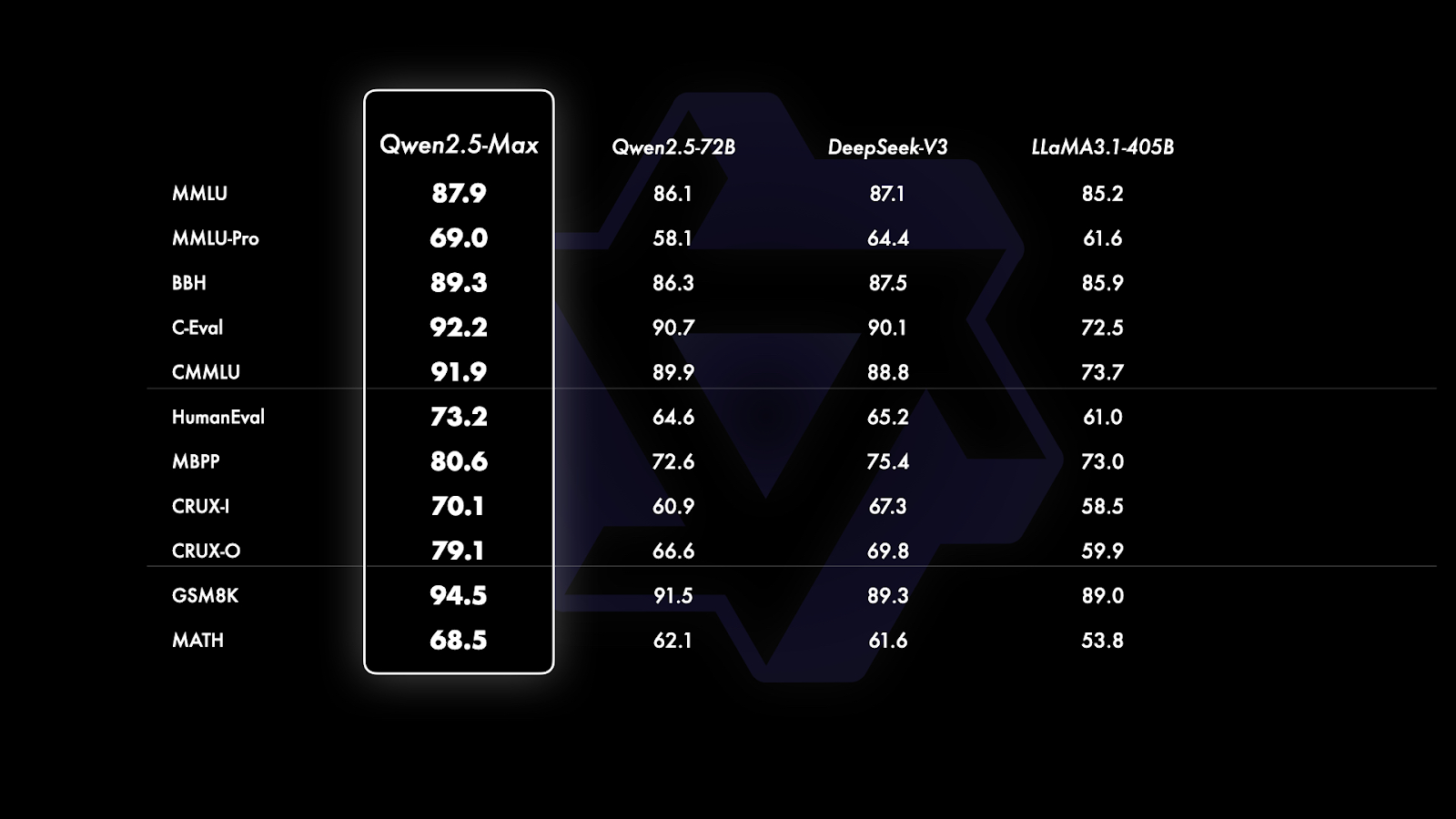
Comparison of the base models. Source: QwenLM
If you look closely at the graph above, it’s divided into three sections based on the type of benchmarks being evaluated:
Accessing Qwen2.5-Max is straightforward, and you can try it for free without any complicated setup.
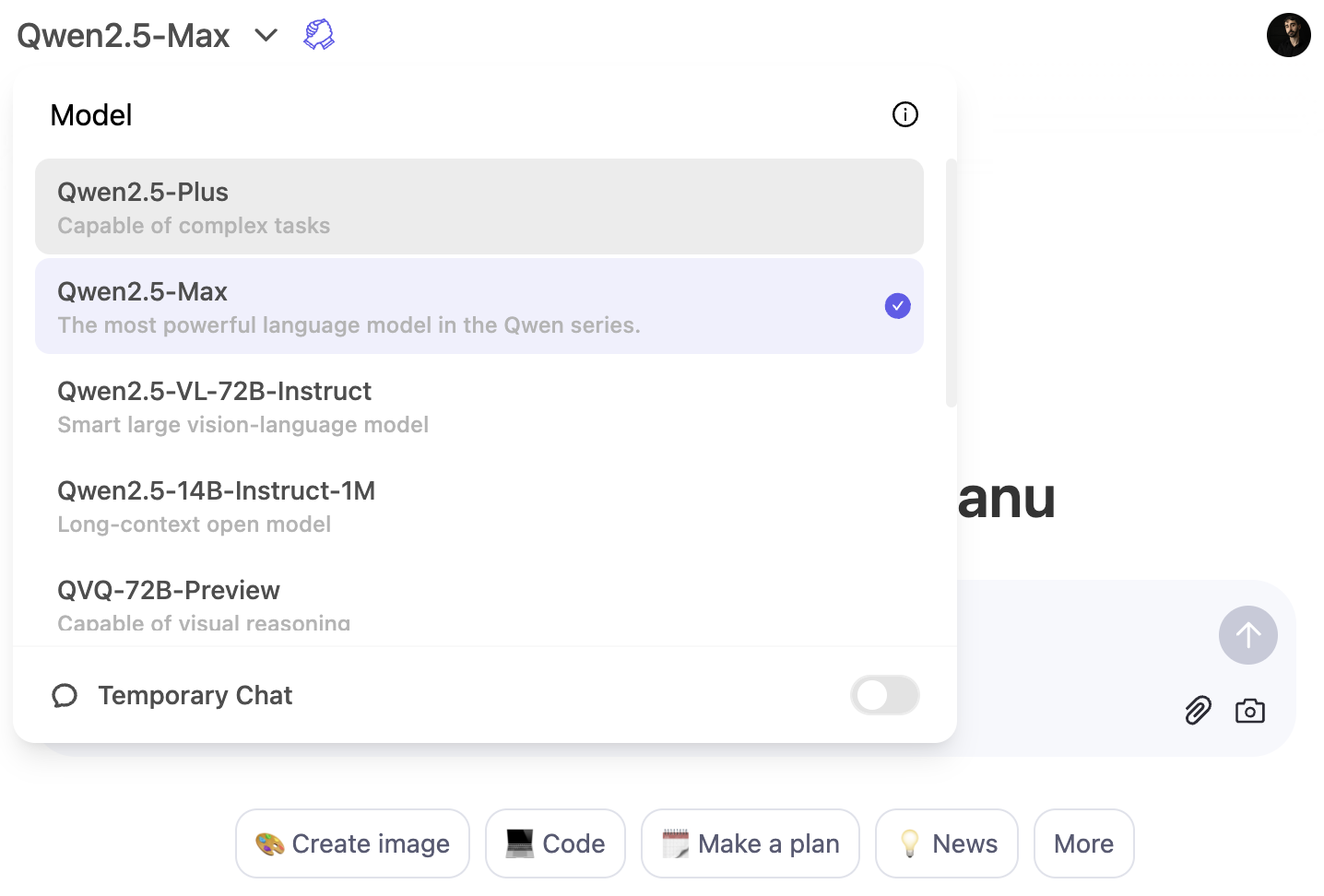
The quickest way to experience Qwen2.5-Max is through the Qwen Chat platform. This is a web-based interface that allows you to interact with the model directly in your browser—just like you’d use ChatGPT in your browser.
To use the Qwen2.5-Max model, click the model dropdown menu and select Qwen2.5-Max:
For developers, Qwen2.5-Max is available through the Alibaba Cloud Model Studio API. To use it, you’ll need to sign up for an Alibaba Cloud account, activate the Model Studio service, and generate an API key.
Since the API follows OpenAI’s format, integration should be straightforward if you’re already familiar with OpenAI models. For detailed setup instructions, visit the official Qwen2.5-Max blog.
Qwen2.5-Max is Alibaba’s most capable AI model yet, built to compete with top-tier models like GPT-4o, Claude 3.5 Sonnet, and DeepSeek V3.
Unlike some previous Qwen models, Qwen2.5-Max is not open-source, but it is available to test through Qwen Chat or via API access on Alibaba Cloud.
Given Alibaba’s continued investment in AI, it wouldn’t be surprising to see a reasoning-focused model in the future—possibly with Qwen 3.
If you want to read more AI news, I recommend these articles:
Learn AI with these courses!
Track
Track
Course
blog
Alex Olteanu
8 min
blog
Alex Olteanu
6 min
blog
Alex Olteanu
8 min
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt



