programa
Fundamentos de la IA
10 h
Alibaba acaba de lanzar Qwen2.5-Max, su modelo de IA más avanzado hasta la fecha. No se trata de un modelo de razonamiento como DeepSeek R1 o el o1 de OpenAI, lo que significa que no puedes ver su proceso de pensamiento.
Es mejor pensar en Qwen2.5-Max como un modelo generalista y competidor de GPT-4o, Claude 3.5 Sonnet o DeepSeek V3.
En este blog, repasaré qué es Qwen2.5-Max, cómo se desarrolló, cómo se compara con la competencia y cómo puedes acceder a él.
Qwen2.5-Max es el modelo de IA más potente de Alibaba hasta la fecha, diseñado para competir con modelos de primer nivel como GPT-4o, Claude 3.5 Sonnet y DeepSeek V3.
Alibaba, una de las mayores empresas tecnológicas de China, es más conocida por sus plataformas de comercio electrónico, pero también ha construido una fuerte presencia en computación en nube y inteligencia artificial. La serie Qwen forma parte de su ecosistema de IA más amplio, que abarca desde modelos más pequeños de peso abierto hasta sistemas propietarios a gran escala.

A diferencia de algunos modelos Qwen anteriores, Qwen2.5-Max no es de código abierto, lo que significa que sus pesos no están disponibles públicamente.
Entrenado con 20 billones de fichas, Qwen2.5-Max tiene una amplia base de conocimientos y una gran capacidad de IA general. Sin embargo, no es un modelo de razonamiento como DeepSeek R1 o el o1 de OpenAI, lo que significa que no muestra explícitamente su proceso de pensamiento. Sin embargo, dada la actual expansión de la IA de Alibaba, es posible que veamos un modelo de razonamiento dedicado en el futuro, posiblemente con Qwen 3.
Qwen2.5-Max utiliza una Mezcla de Expertos (MoE) una técnica que también emplea DeepSeek V3. Este planteamiento permite ampliar el modelo manteniendo unos costes computacionales manejables. Vamos a desglosar sus componentes clave de una forma fácil de entender.
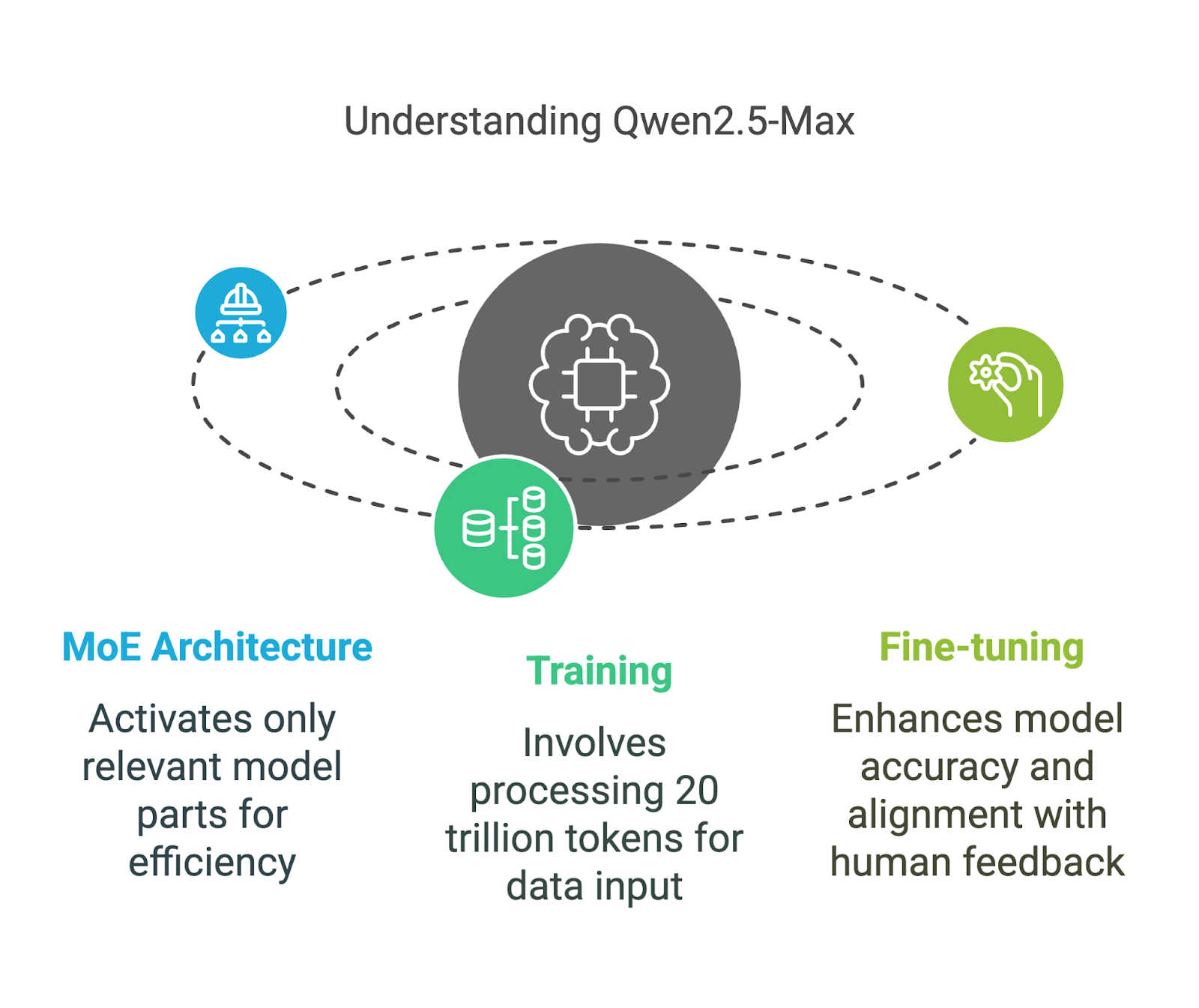
A diferencia de los modelos de IA tradicionales, que utilizan todos sus parámetros para cada tarea, los modelos MoE como Qwen2.5-Max y DeepSeek V3 sólo activan las partes más relevantes del modelo en cada momento.
Puedes pensar en ello como en un equipo de especialistas: si haces una pregunta compleja sobre física, sólo responden los expertos en física, mientras que el resto del equipo permanece inactivo. Esta activación selectiva significa que el modelo puede manejar el procesamiento a gran escala de forma más eficiente sin requerir cantidades extremas de potencia de cálculo.
Este método hace que Qwen2.5-Max sea potente y escalable, lo que le permite competir con modelos densos como GPT-4o y Claude 3.5 Sonnet, y al mismo tiempo consume menos recursos: un modelo denso es aquel en el que todos los parámetros se activan para cada entrada.
Qwen2.5-Max se entrenó con 20 billones de tokens, cubriendo una amplia gama de temas, idiomas y contextos.
Para poner 20 billones de tokens en perspectiva, eso equivale aproximadamente a 15 billones de palabras, una cantidad tan enorme que es difícil de comprender. A modo de comparación, la obra de George Orwell 1984 contiene unas 89.000 palabras, lo que significa que Qwen2.5-Max se ha entrenado en el equivalente a 168 millones de ejemplares de 1984.
Sin embargo, los datos de entrenamiento en bruto por sí solos no garantizan un modelo de IA de alta calidad, por lo que Alibaba lo perfeccionó aún más con:
Qwen2.5-Max se ha probado frente a otros modelos de IA líderes para medir sus capacidades en diversas tareas. Estas pruebas evalúan tanto los modelos instructores (que se ajustan para tareas como chatear y codificar) como los modelos base (que sirven de base bruta antes del ajuste). Comprender esta distinción ayuda a aclarar lo que significan realmente las cifras.
Los modelos de instrucción se ajustan a las aplicaciones del mundo real, como la conversación, la codificación y las tareas de conocimiento general. Qwen2.5-Max se compara aquí con modelos como GPT-4o, Claude 3.5 Sonnet, Llama 3.1 405By DeepSeek V3.
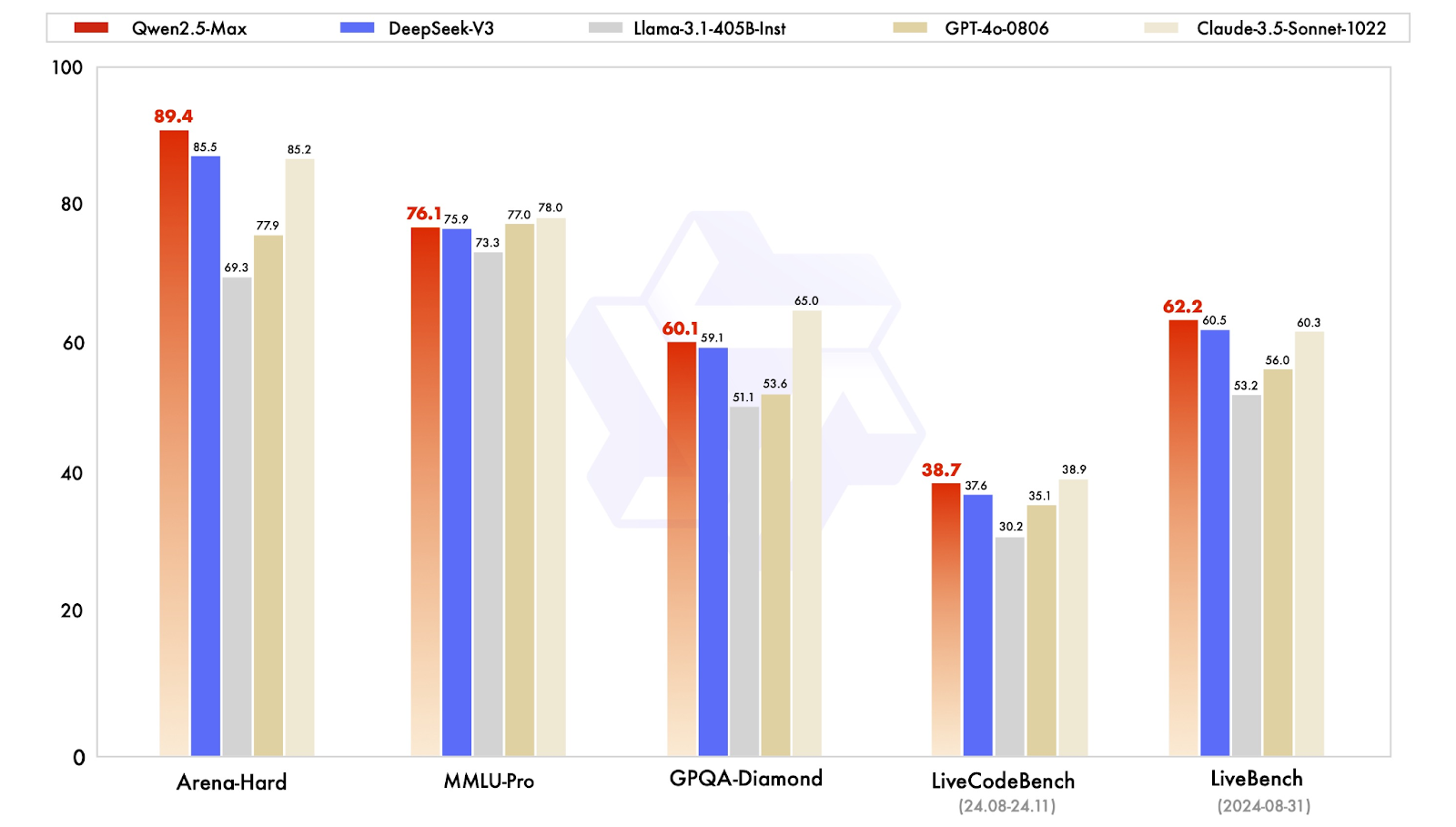
Comparación de los modelos instructores. Fuente: QwenLM
Desglosemos rápidamente los resultados:
En general, Qwen2.5-Max demuestra ser un modelo de IA completo, que destaca en tareas basadas en preferencias y en capacidades generales de IA, al tiempo que mantiene conocimientos competitivos y habilidades de codificación.
Desde GPT-4o y Claude 3.5 Sonnet son modelos propietarios sin versiones base disponibles públicamente, la comparación se limita a modelos de peso abierto como Qwen2.5-Max, DeepSeek V3, LLaMA 3.1-405B y Qwen 2.5-72B. Esto proporciona una imagen más clara de la posición de Qwen2.5-Max frente a los principales modelos abiertos a gran escala.
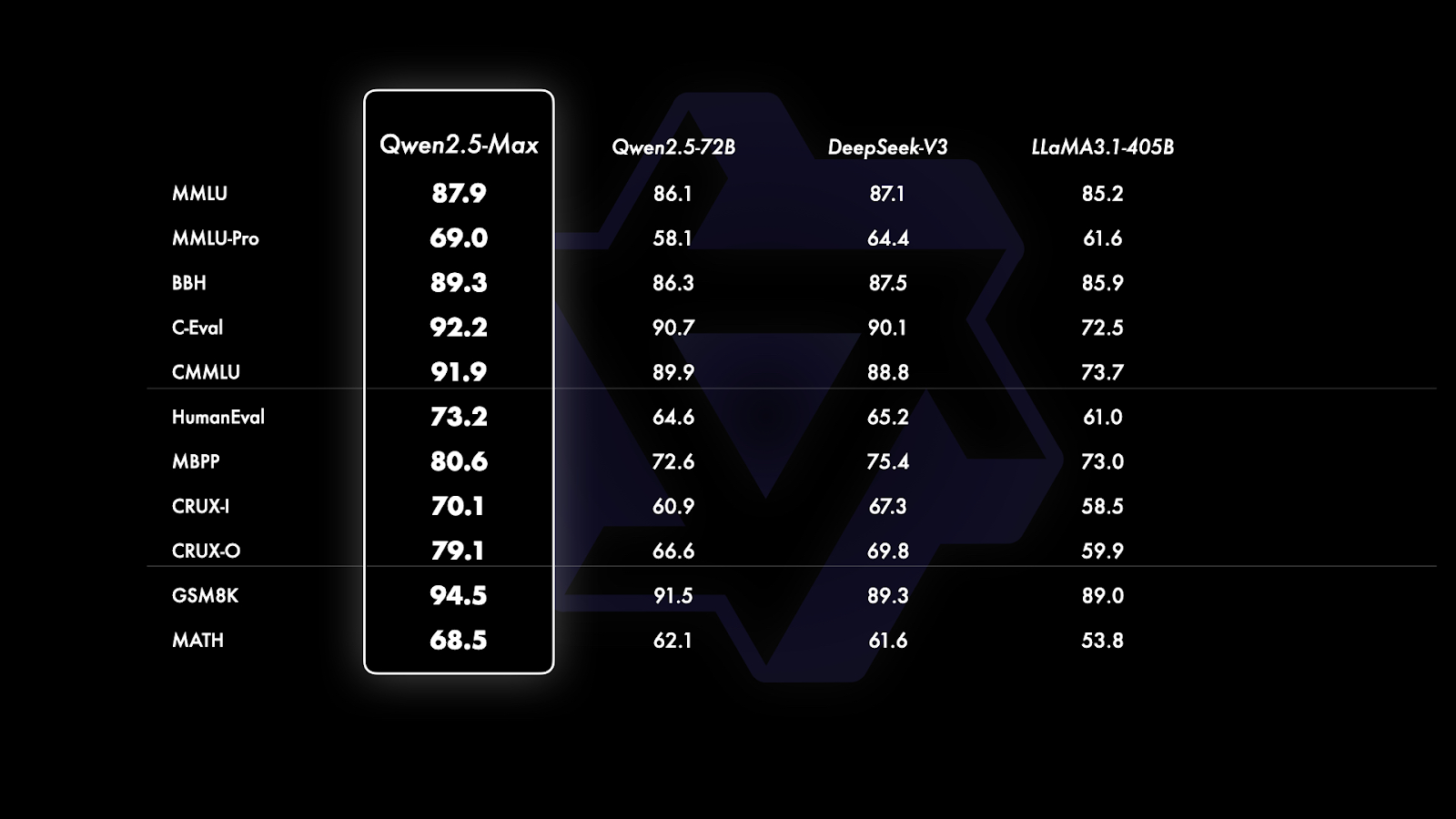
Comparación de los modelos base. Fuente: QwenLM
Si te fijas bien en el gráfico anterior, está dividido en tres secciones basadas en el tipo de puntos de referencia que se evalúan:
Acceder a Qwen2.5-Max es sencillo, y puedes probarlo gratis sin ninguna configuración complicada.
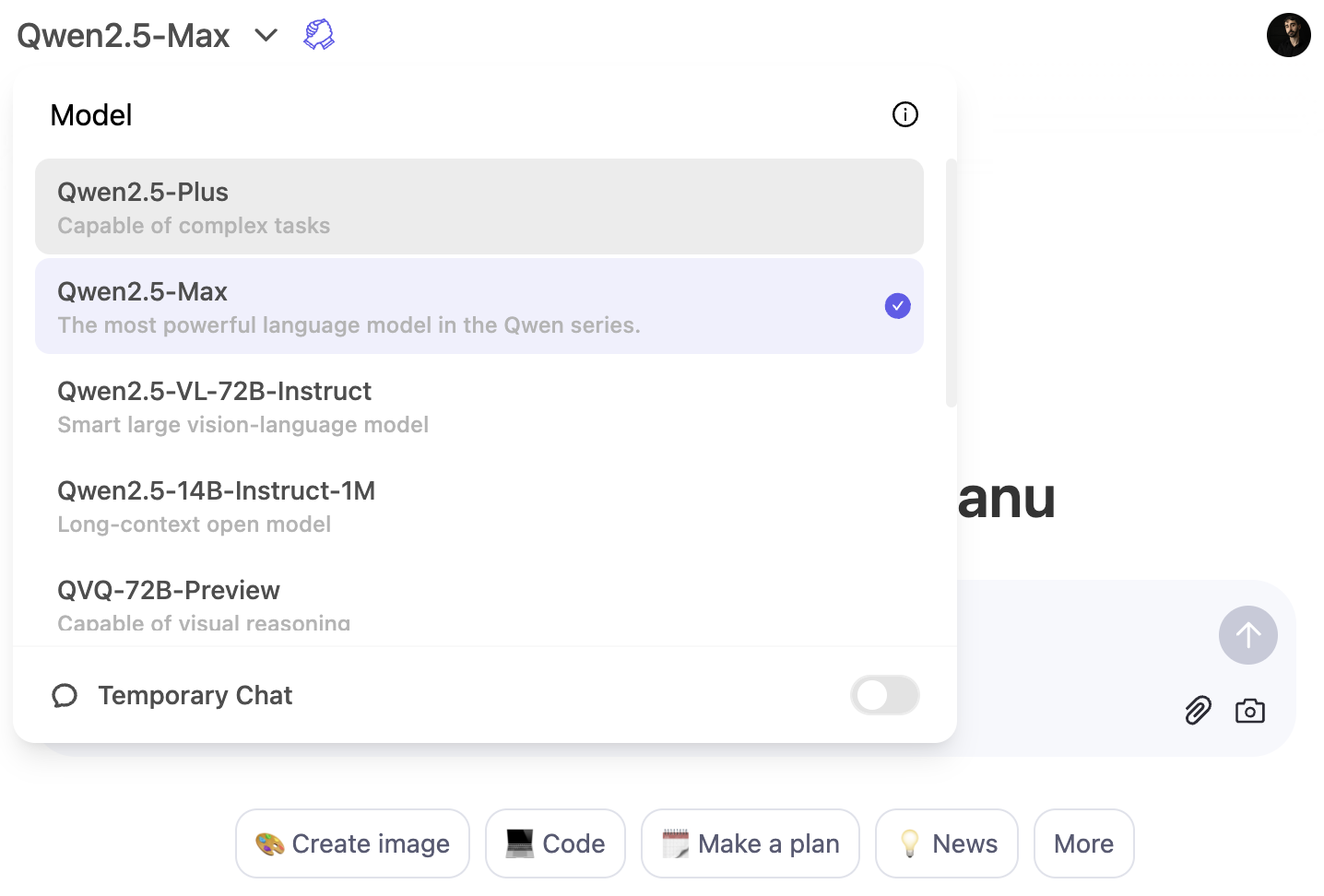
La forma más rápida de experimentar Qwen2.5-Max es a través del Chat Qwen de Qwen. Se trata de una interfaz basada en web que te permite interactuar con el modelo directamente en tu navegador, igual que usarías ChatGPT en tu navegador.
Para utilizar el modelo Qwen2,5-Max, haz clic en el menú desplegable del modelo y selecciona Qwen2,5-Max:
Para los desarrolladores, Qwen2.5-Max está disponible a través de la API Alibaba Cloud Model Studio. Para utilizarlo, tendrás que registrarte en una cuenta de Alibaba Cloud, activar el servicio Model Studio y generar una clave API.
Como la API sigue el formato de OpenAI, la integración debería ser sencilla si ya estás familiarizado con los modelos de OpenAI. Para obtener instrucciones detalladas de configuración, visita el blog oficial de Qwen2.5-Max.
Qwen2.5-Max es el modelo de IA más capaz de Alibaba hasta la fecha, creado para competir con modelos de primer nivel como GPT-4o, Claude 3.5 Sonnet y DeepSeek V3.
A diferencia de algunos modelos anteriores de Qwen, Qwen2.5-Max no es de código abierto, pero está disponible para probarlo a través del chat de Qwen o mediante el acceso a la API en Alibaba Cloud.
Dada la continua inversión de Alibaba en IA, no sería sorprendente ver un modelo centrado en el razonamiento en el futuro, posiblemente con Qwen 3.
Si quieres leer más noticias sobre IA, te recomiendo estos artículos:
Aprende IA con estos cursos
programa
programa
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
9 min
blog
Ryan Ong
8 min
blog
Josep Ferrer
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali

