
Course
Working with the OpenAI API
3 hr
141.6K
OpenAI announced its latest large language model, GPT-4o, the successor to GPT-4 Turbo. Read on to discover its capabilities, performance, and how you might want to use it.
GPT-4o is OpenAI’s latest LLM. The 'o' in GPT-4o stands for "omni"—Latin for "every"—referring to the fact that this new model can accept prompts that are a mixture of text, audio, images, and video. Previously, the ChatGPT interface used separate models for different content types.
For example, when speaking to ChatGPT via Voice Mode, your speech would be converted to text using Whisper, a text response would be generated using GPT-4 Turbo, and that text response would be converted to speech with TTS.

A comparison of how GPT-4 Turbo and GPT-4o process speech input
Similarly, working with images in ChatGPT involved a mix of GPT-4 Turbo and DALL-E 3.
Having a single model for different content media promises increased speed and quality of results, a simpler interface, and some new use cases.
GPT-4o Mini is a leaner, faster version of GPT-4o, designed to handle tasks with a greater focus on speed and efficiency. It's derived from the larger GPT-4o model through a process called distillation.
While it retains much of the original model’s ability to process multimodal inputs—text, audio, and images—GPT-4o mini is optimized for lightweight applications where faster response times are crucial.
It’s particularly useful for developers needing a cost-effective solution for coding, debugging, and real-time interactions that don’t require the full computational power of GPT-4o.
You can read more details in this article about GPT-4o mini.
The all-in-one model approach means that GPT-4o overcomes several limitations of the previous voice interaction capabilities.
With the previous OpenAI system of combining Whisper, GPT-4 Turbo, and TTS in a pipeline, the reasoning engine, GPT-4, only had access to the spoken words. This method meant that things like tone of voice, background noises, and knowledge of voices from multiple speakers were simply discarded. As such, GPT-4 Turbo couldn’t really express responses with different emotions or styles of speech.
By having a single model that can reason about text and audio, this rich audio information can be used to provide higher-quality responses with a greater variety of speaking styles.
In the following example provided by OpenAI, GPT-4o provides sarcastic output.
One step in the LLM workflow is when the prompt text is converted into tokens. These are units of text that the model can understand.
In English, a token is typically one word or piece of punctuation, although some words can be broken down into multiple tokens. On average, three English words take up about four tokens.
If language can be represented in the model with fewer tokens, fewer calculations need to be made, and the speed of generating text is increased.
Further, since OpenAI charges for its API per token input or output, fewer tokens mean a lower price to the API users.
GPT-4o has an improved tokenization model that results in fewer tokens being needed per text. The improvement is mostly noticeable in languages that don't use the Roman alphabet.
For example, Indian languages, in particular, have benefitted, with Hindi, Marathi, Tamil, Telugu, and Gujarati all showing reductions in tokens by 2.9 to 4.4 times. Arabic showed a 2x token reduction, and East Asian languages like Chinese, Japanese, Korean, and Vietnamese showed token reductions between 1.4x and 1.7x.
With OpenAI's existing pricing strategy for ChatGPT, users have to pay to access the best model: GPT-4 Turbo has only been available on the Plus and Enterprise paid plans.
This is changing, with OpenAI promising to make GPT-4o available on the free plan as well. Plus users will get five times as many messages as users on the free plan.
The rollout will be gradual, with red team (testers who try to break the model to find problems) access beginning immediately and further users gaining access over time.
While this isn’t necessarily an update exclusive to GPT-4o, OpenAI also announced the release of the ChatGPT desktop app. The updates in latency and multimodality mentioned above, alongside the release of the app, mean that the way we work with ChatGPT is likely going to change. For example, OpenAI showed a demo of an augmented coding workflow using voice and the ChatGPT desktop app. Scroll down in the use-cases section to see that example in action!
Details of how GPT-4o works are still scant. The only detail that OpenAI provided in its announcement is that GPT-4o is a single neural network that was trained on text, vision, and audio input.
This new approach differs from the previous technique of having separate models trained on different data types.
However, GPT-4o isn't the first model to take a multi-modal approach. In 2022, TenCent Lab created SkillNet, a model that combined LLM transformer features with computer vision techniques to improve the ability to recognize Chinese characters.
In 2023, a team from ETH Zurich, MIT, and Stanford University created WhisBERT, a variation on the BERT series of large language models. While not the first, GPT-4o is considerably more ambitious and powerful than either of these earlier attempts.
How radical the changes are to GPT-4o's architecture compared to GPT-4 Turbo depends on whether you ask OpenAI's engineering or marketing teams. In April, a bot named "im-also-a-good-gpt2-chatbot" appeared on LMSYS's Chatbot Arena, a leaderboard for the best generative AIs. That mysterious AI has now been revealed to be GPT-4o.
The "gpt2" part of the name is important. Not to be confused with GPT-2, a predecessor of GPT-3.5 and GPT-4, the "2" suffix was widely regarded to mean a completely new architecture for the GPT series of models.
Evidently, someone in OpenAI's research or engineering team thinks that combining text, vision, and audio content types into a single model is a big enough change to warrant the first version number bump in six years.
On the other hand, the marketing team has opted for a relatively modest naming change, continuing the "GPT-4" convention.
OpenAI released benchmark figures of GPT-4o compared to several other high-end models.
Of these, only three models really matter for comparison. GPT 4 Turbo, Claude 3 Opus, and Gemini Pro 1.5 have spent the last few months angling for the top spot on the LMSYS Chatbot Arena leaderboard.
Llama 3 400B may be a contender in the future, but it isn't finished yet. Thus here, we only present the results for these three models and GPT-4o.
The results of six benchmarks were used.
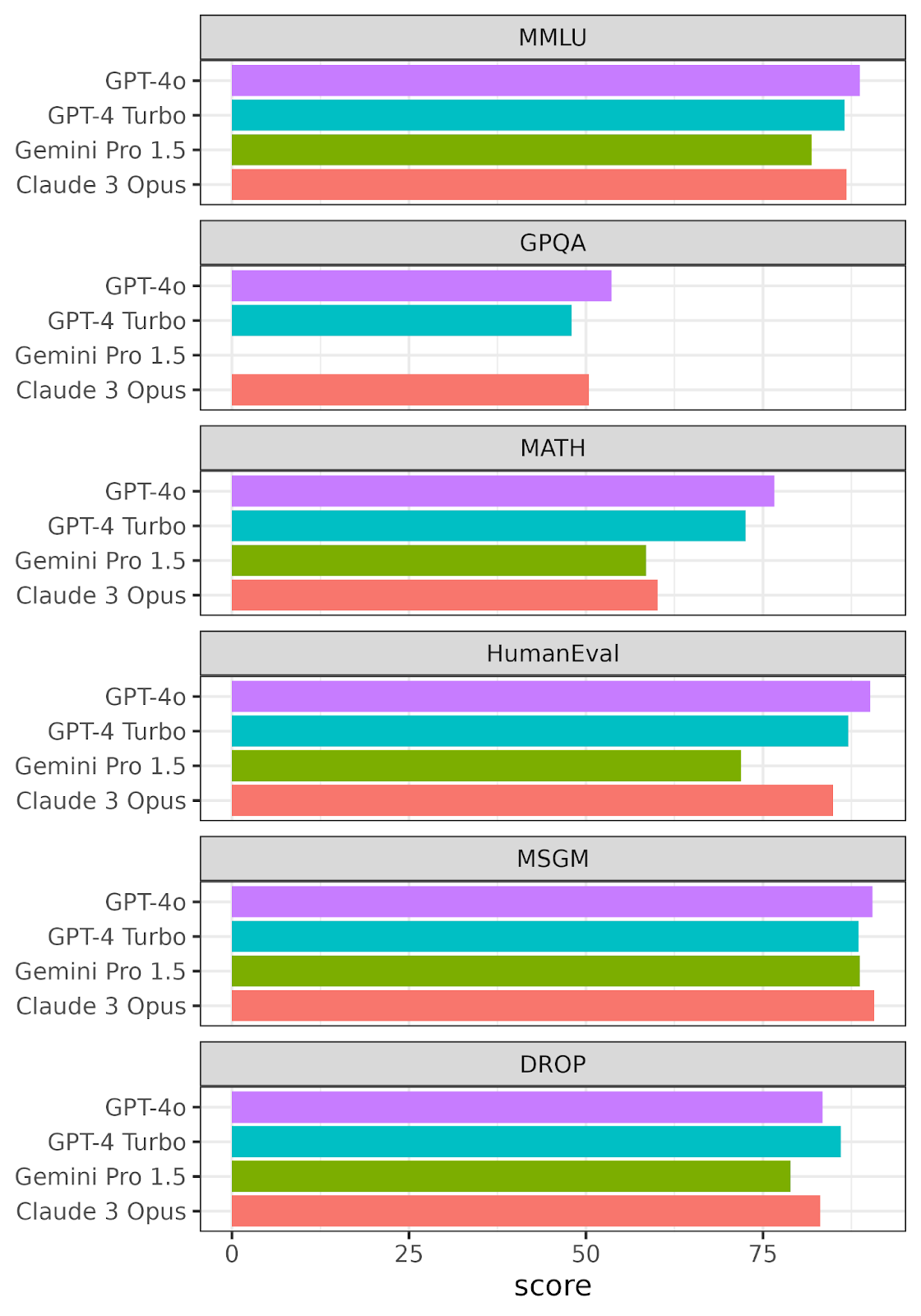
Performance of GPT-4o, GPT-4 Turbo, Gemini Pro 1.5, and Claude 3 Opus against six LLM benchmarks. Scores for each benchmark range from 0 to 100. Recreated from data provided by OpenAI. No data was provided for Gemini Pro 1.5 for the GPQA benchmark.
GPT-4o gets the top score in four of the benchmarks, though it is beaten by Claude 3 Opus in the MSGM benchmark and by GPT-4 Turbo in the DROP benchmark. Overall, this performance is impressive, and it shows promise for the new approach of multimodal training.
If you look closely at the GPT-4o numbers compared to GPT-4 Turbo, you'll see that the performance increases are only a few percentage points.
It's an impressive boost for one year later, but it's far from the dramatic jumps in performance from GPT-1 to GPT-2 or GPT-2 to GPT-3.
Being 10% better at reasoning about text year-on-year is likely to be the new normal. The low-hanging fruit has been picked, and it's just difficult to continue with big leaps in text reasoning.
On the other hand, what these LLM benchmarks don't capture is AI's performance on multi-modal problems. The concept is so new that we don't have any good ways of measuring how good a model is across text, audio and vision.
Overall, GPT-4o's performance is impressive, and it shows promise for the new approach of multimodal training.
Recent GPT models and their derivatives, like GitHub Copilot, are already capable of providing code assistance, including writing code and explaining and fixing errors. The multi-modal capabilities of GPT-4o allow for some interesting opportunities.
In a promotional video hosted by OpenAI CTO Mira Murati, two OpenAI researchers, Mark Chen and Barret Zoph, demonstrated using GPT-4o to work with some Python code.
The code is shared with GPT as text, and the voice interaction feature is used to get GPT to explain the code. Later, after running the code, GPT-4o's vision capability is used to explain the plot.
Overall, showing ChatGPT your screen and speaking a question is a potentially simpler workflow than saving a plot as an image file, uploading it to ChatGPT, then typing a question.
GPT-4o's ability to understand video input from a camera and verbally describe the scene could be a must-have feature for visually impaired people. It's essentially the audio description feature that TVs have, but for real life.
I’ve had access to some of GPT-4o’s new features since just after the announcement (sadly, no voice chat yet), and I’ve been impressed with many of its outputs. Responses seem faster and more consistent, and it seems to understand my requests better than it did previously. That’s not to say it’s been perfect, though.
Here are some examples of the interactions I had with ChatGPT-4o:
First, using voice chat, I asked if it had any ideas about how to analyze the performance of the soccer team I support, the mighty Leeds United. As well as providing several options, it gave me some example Python code:
import pandas as pd
# Sample data for Leeds United's match results
data = {
'Match': ['Match1', 'Match2', 'Match3', 'Match4', 'Match5'],
'Result': ['Win', 'Draw', 'Loss', 'Win', 'Win'],
'Goals Scored': [2, 1, 0, 3, 2]
}
# Create a DataFrame
df = pd.DataFrame(data)
# Summarize match results
summary = df['Result'].value_counts()
total_goals = df['Goals Scored'].sum()
average_goals = df['Goals Scored'].mean()
# Display summary
print("Match Results Summary:")
print(summary)
print("\nTotal Goals Scored:", total_goals)
print("Average Goals Per Match:", round(average_goals, 2))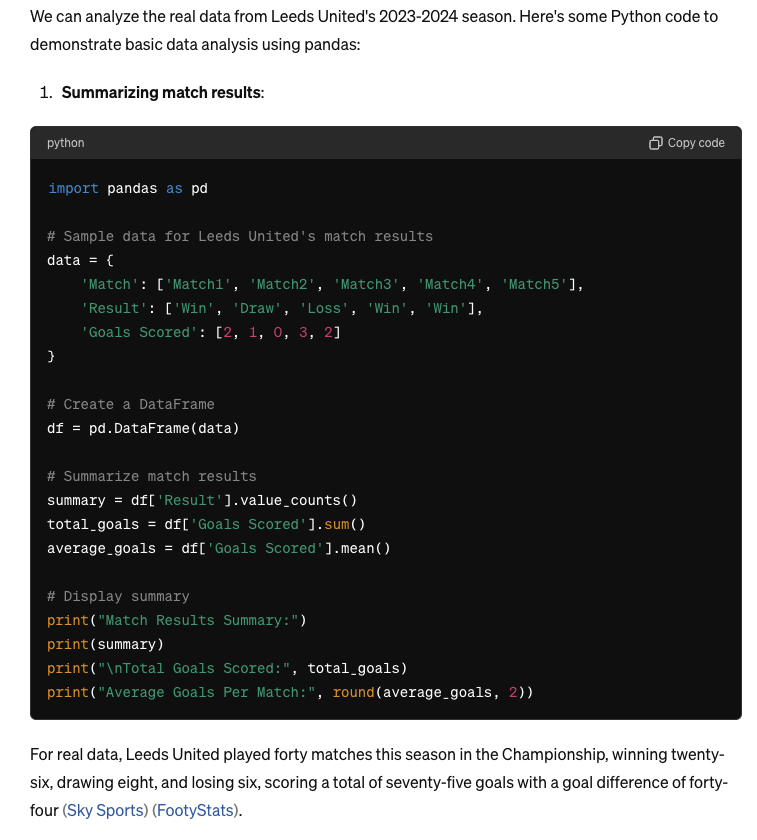
However, when I probed this train of thought in more detail, things got a little off. I first asked for some real data to use - it searched the web and found two good sources, but it reported the stats wrong. Leeds played 46 games in the regular season, scoring 81 with a goal difference of plus 38, as opposed to the 40 games played it outlined in its response.
I then asked ChatGPT to visualize the goals scored against each team:
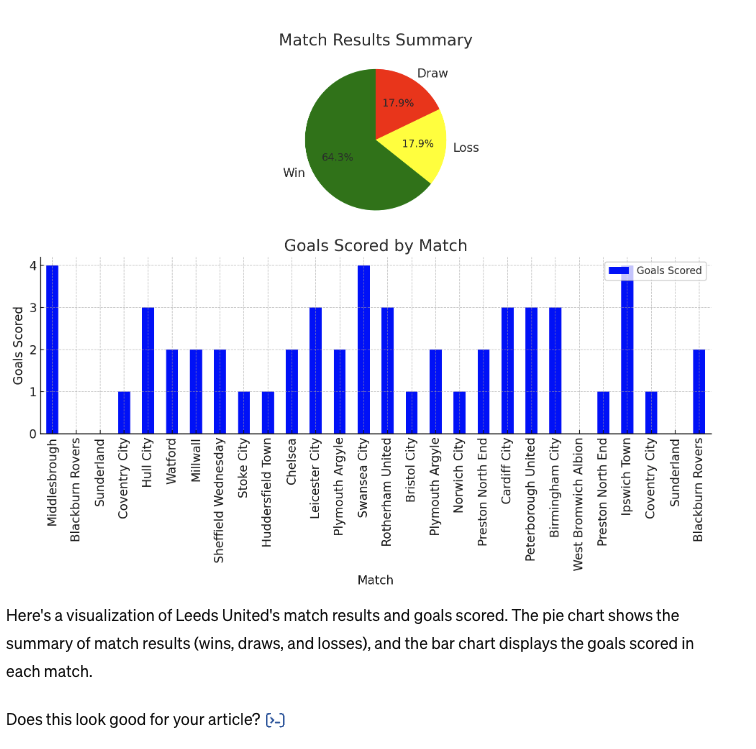
Again, it’s half-completed the task here. It has created a visualization as requested, which looks fine on the surface. But in reality, a lot of the data is made up and inaccurate (teams appearing twice, goals not counted, and teams not in the same division as Leeds).
In fairness, I imagine performance would have been better had I provided a full dataset myself, but I wish it would say that rather than confidently make up answers.
Next, I asked GPT-4o to analyze a picture of one of my plants. I still don’t have access to the integrated vision feature, so I had to take a picture and ask ChatGPT what plant it was:

This isn’t a bad effort, although it’s not quite accurate. While it is a bonsai tree, it’s an Ilex crenata rather than a Carmona retusa. Still, the two look pretty similar so it’s an easy mistake to make and I appreciated the extra context on how to take care of the plant.
Finally, I wanted to test out the image abilities of the new model. I first showed it a picture of my tortoise, Darwin, and asked it to tell me about my friend:

Again, this is close but not perfect. Darwin is actually a Horsefield tortoise rather than a Hermann’s, but they do look very similar. I then asked ChatGPT-4o to take the original image and recreate it in the style of Hokusai. Here’s the result:

A pretty good effort, although there isn’t much actual resemblance to the original image, but I guess that’s fair enough. It did take a little while to generate this one too.
Overall, though, I was impressed with the responsiveness of the new model and how well it understood my requests. It’s far from flawless, and it still confidently hallucinates at times, but I can’t wait to get hands-on with the improved speech and integrated vision.
Regulation for generative AI is still in its early stages; the EU AI Act is the only notable legal framework in place so far. That means that companies creating AI need to make some of their own decisions about what constitutes safe AI.
OpenAI has a preparedness framework that it uses to determine whether or not a new model is fit to release to the public.
The framework tests four areas of concern.
Each area of concern is graded Low, Medium, High, or Critical, and the model's score is the highest of the grades across the four categories.
OpenAI promises not to release a model that is of critical concern, though this is a relatively low safety bar: under its definitions, a critical concern corresponds to something that would upend human civilization. GPT-4o comfortably avoids this, scoring Medium concern.
As with all generative AIs, the model doesn't always behave as intended. Computer vision is not perfect, and so interpretations of an image or video are not guaranteed to work.
Likewise, transcriptions of speech are rarely 100% correct, particularly if the speaker has a strong accent or technical words are used.
OpenAI provided a video of some outtakes where GPT-4o did not work as intended.
Notably, translation between two non-English languages was one of the cases where it failed. Other problems included unsuitable tone of voice (being condescending) and speaking the wrong language.
Learn to Build AI Tools with OpenAI Today!
Course
Course
Course
blog
Ryan Ong
8 min
blog
Abid Ali Awan
9 min
blog
Richie Cotton
8 min
blog
Richie Cotton
7 min
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Arunn Thevapalan



