
Cours
Traitement d’images en Python
4 h
55.9K
Les images sont partout. Nous vivons à une époque où les images et les vidéos contiennent de nombreuses informations parfois difficiles à obtenir. C'est pourquoi l'analyse d'images, également connue sous le nom de vision par ordinateur, est devenue une compétence très précieuse applicable dans de nombreux cas d'utilisation.
Ce guide présente le domaine intéressant de la vision par ordinateur. Il explique les fondements de cette discipline scientifique, ses principales applications, et comment l'apprentissage automatique et l'apprentissage profond révolutionnent la vision par ordinateur, ouvrant la voie à de nouvelles possibilités révolutionnaires.
En termes simples, la vision par ordinateur est une branche de l'intelligence artificielle qui étudie la manière dont les ordinateurs peuvent voir et comprendre le contenu des images numériques et des vidéos.
L'objectif ultime de la vision par ordinateur est de reproduire les capacités de vision humaine dans des machines. Cependant, alors que les humains utilisent des rétines, des nerfs optiques et des parties dédiées de leur cerveau pour collecter et traiter les informations visuelles, ce processus est complètement différent chez les machines. Pour apprendre aux machines à voir, nous nous appuyons sur une série de composants technologiques, notamment :
La vue est un sens essentiel que beaucoup d'entre nous utilisent pour toute une série de tâches quotidiennes. Dans ce contexte, nous ne devrions pas être surpris par les nombreuses applications réelles de la vision par ordinateur disponibles aujourd'hui.
Vous trouverez ci-dessous une liste non exhaustive des principales applications de la vision par ordinateur.
De nombreuses applications populaires de vision par ordinateur impliquent la reconnaissance d'objets dans les images. Les voitures autonomes en sont un bon exemple. Les fabricants de voitures autonomes utilisent plusieurs caméras pour acquérir des images de l'environnement afin que leurs voitures autonomes puissent détecter les objets, le marquage des voies et les panneaux de signalisation pour conduire en toute sécurité. Comment fonctionne la détection d'objets dans la pratique ? Nous vous recommandons vivement de lire notre tutoriel sur la détection d'objets avec l' algorithme YOLO.
Utilisée à des fins de sécurité et de surveillance, la reconnaissance faciale analyse les caractéristiques clés pour identifier les personnes. Pour ce faire, les réseaux neuronaux sont entraînés sur de vastes bases de données biométriques qui permettent aux modèles d'identifier des caractéristiques faciales uniques chez l'homme. Lisez notre tutoriel séparé pour découvrir comment effectuer une détection de visage avec Python.
Des outils tels que Google Translate permettent aux utilisateurs de pointer l'appareil photo de leur smartphone sur un panneau dans une autre langue et d'obtenir presque immédiatement une traduction du panneau dans leur langue préférée.
Non seulement les applications de vision par ordinateur peuvent comprendre les images, mais nous en sommes également au point où elles peuvent créer des images réalistes à l'aide de l'IA générative. C'est le cas de DALL-E, un modèle de genAI qui crée des images à partir de descriptions textuelles, ou de Sora, qui fait la même chose mais avec des vidéos. Un autre exemple est celui des "deep fakes". Un deep fake est un logiciel utilisé pour représenter des personnes dans de fausses vidéos dans lesquelles elles n'apparaissent pas réellement. En comprenant ce qui compose un visage humain, les deep fakes peuvent générer de nouveaux visages.
Curieux de découvrir d'autres applications de la vision par ordinateur ? Consultez notre article dédié pour découvrir 19 projets de vision par ordinateur, du débutant à l'expert.
Les applications uniques de vision par ordinateur dont nous disposons aujourd'hui ne seraient pas possibles sans l'IA, en particulier les modèles d'apprentissage profond. Pour comprendre pourquoi, il faut d'abord comprendre ce qu'est une image numérique, l'unité d'information la plus élémentaire dans le domaine de la vision par ordinateur.
Une image numérique est composée de centaines, voire de milliers de pixels, qui contiennent des informations sur la couleur et l'intensité. Dans les images en niveaux de gris, l'intensité de chaque pixel peut être représentée par un nombre compris entre 0 et 255.

Images en niveaux de gris. Source : DataCamp
En revanche, les images colorées sont généralement stockées dans le système RVB. RVB signifie rouge, vert et bleu. On peut considérer que chaque image est représentée par trois trames, une pour chaque canal de couleur. Cela signifie que vous avez besoin de trois fois plus de données pour stocker une image en couleur qu'une image en niveaux de gris.
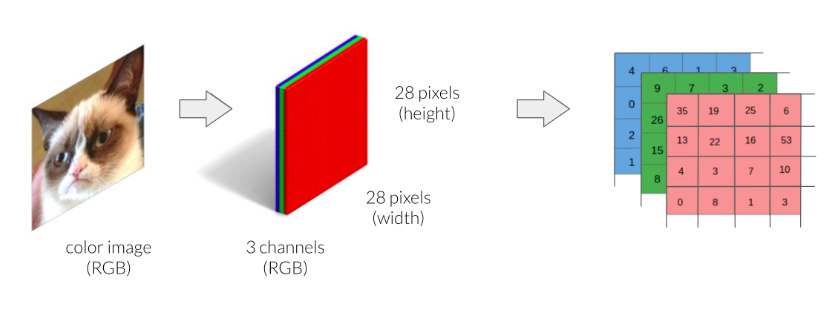
Images en couleur. Source : DataCamp
Les images numériques peuvent donc être considérées comme un ensemble de nombres. Il n'y a pas si longtemps, nous ne disposions pas des outils puissants nécessaires au traitement et à l'extraction d'informations à partir d'images. Cette situation a changé au début des années 2010, lorsque les chercheurs en apprentissage profond ont réussi à mettre au point de nouveaux réseaux neuronaux particulièrement bien adaptés aux tâches de vision par ordinateur.
Aujourd'hui, grâce aux avancées du deep learning et aux progrès des GPU, du cloud computing et à la grande disponibilité des données d'images, les praticiens des données peuvent entraîner de puissants réseaux neuronaux capables d'effectuer des tâches complexes en vision par ordinateur.
Suite à l'essor de l'IA générative, les modèles de langage visuel (VLM) de pointe peuvent comprendre et traiter des données visuelles et textuelles, ce qui permet de nouvelles tâches telles que le sous-titrage d'images, la réponse à des questions visuelles et la génération de texte à partir d'images.
Les réseaux neuronaux vous intéressent ? Consultez notre cours d'introduction à l'apprentissage profond avec Python pour commencer dès aujourd'hui.
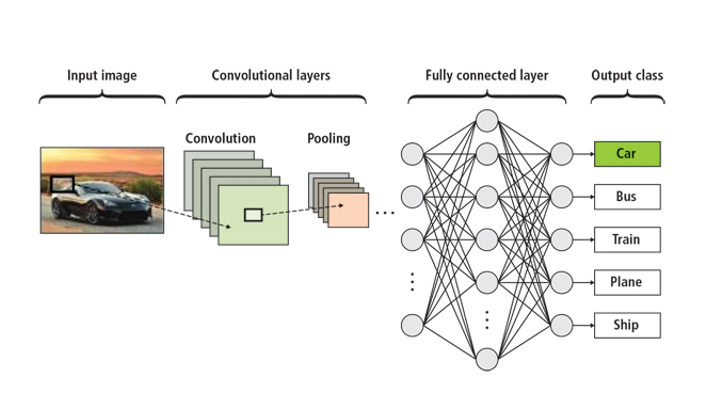
Réseau de neurones pour la vision par ordinateur. Source : NVIDIA
Les nouveaux venus dans le domaine se méprennent souvent sur la différence entre la vision industrielle et la vision par ordinateur.
La vision industrielle fait référence à l'utilisation de caméras, de capteurs et d'algorithmes pour aider les ordinateurs et les robots à analyser les images et à prendre des décisions éclairées au cours du processus de fabrication. Les applications de la vision industrielle englobent des tâches telles que l'inspection automatique, le contrôle de la qualité et le guidage des robots.
Ce terme est souvent utilisé dans le domaine de la fabrication et de l'industrie, et son champ d'application est donc spécifique et plus étroit que celui de la vision par ordinateur, qui a un éventail plus large d'applications dans diverses industries. De même, en termes de complexité, la vision par ordinateur implique souvent un traitement et une interprétation plus complexes que la vision industrielle.
Vous pouvez voir les différences entre la vision industrielle et la vision par ordinateur dans le tableau ci-dessous :
|
Aspect |
Vision industrielle |
Vision par ordinateur |
|
Définition |
Utilisation de caméras, de capteurs et d'algorithmes pour analyser des images et prendre des décisions, souvent dans un cadre industriel. |
Un domaine de l'IA visant à permettre aux ordinateurs d'interpréter et de comprendre les images et les vidéos numériques. |
|
Principaux cas d'utilisation |
Contrôle de la qualité, détection des défauts, surveillance de la chaîne de montage et guidage des robots. |
Détection d'objets, reconnaissance faciale, génération d'images, véhicules autonomes et imagerie médicale. |
|
Complexité |
Généralement plus simple et spécifique à la tâche à accomplir. |
Implique un traitement complexe, utilisant souvent l'IA et des modèles d'apprentissage profond. |
|
Champ d'application |
Étroite, spécifique à une application (principalement la fabrication et l'automatisation industrielle). |
Large, englobant de multiples industries telles que les soins de santé, le commerce de détail, l'automobile et le divertissement. |
|
Focus sur la technologie |
Caméras, éclairage et matériel pour la capture et l'analyse d'images dans des environnements contrôlés. |
Algorithmes, réseaux neuronaux et grands ensembles de données pour une compréhension avancée des images. |
|
Exemples |
Inspection automatisée des cartes de circuits imprimés, guidage des bras robotisés dans les usines. |
La formation des voitures autonomes, la création de "deep fakes" ou l'identification de maladies dans les scanners médicaux. |
La vision par ordinateur est l'une des disciplines les plus passionnantes et les plus demandées de l'IA. Si vous souhaitez vous lancer dans le domaine, DataCamp est là pour vous aider. Nous nous efforçons d'offrir aux praticiens des données des cours de qualité, actualisés, et du matériel spécialisé.
Nous vous recommandons vivement de commencer par notre cursus de traitement d'images en Python. Ce cursus couvre les fondamentaux, du prétraitement des images à l'apprentissage profond. Vous commencerez par l'amélioration et la restauration d'images et passerez aux images biomédicales pour analyser des types d'images plus complexes, comme les IRM et les radiographies. Le cursus se termine par un cours sur les réseaux neuronaux convolutifs, où vous apprendrez à construire de puissants classificateurs d'images à apprentissage profond.
En ce qui concerne les ressources techniques, considérez les éléments suivants :
Nous espérons que vous avez apprécié cette introduction conviviale à la vision par ordinateur. Le domaine est en pleine effervescence, avec de nouvelles applications de vision par ordinateur qui arrivent sur le marché tous les jours. Si vous souhaitez devenir un spécialiste de la vision par ordinateur, le cursus de compétences Traitement d'images en Python est idéal pour commencer.
Les meilleurs cours de DataCamp
Cours
Cours
Cours