
Course
Image Processing in Python
4 hr
55.9K
Images are everywhere. We live in a time when images and videos contain lots of information that is sometimes difficult to obtain. This is why image analysis, also known as computer vision, has become a highly valuable skill applicable in many use cases.
This guide introduces the interesting field of computer vision. It explains the fundamentals of this scientific discipline, its main applications, and how machine learning and deep learning are revolutionizing computer vision, opening the gate to new, revolutionary possibilities.
In simple terms, computer vision is a branch of AI that studies how computers can see and understand the content of digital images and videos.
The ultimate goal of computer vision is to replicate human vision capabilities in machines. However, while humans use retinas, optic nerves, and dedicated parts of their brains to collect and process visual information, this process is completely different in machines. Instead, to teach machines how to see, we rely on a variety of technological components, including:
Sight is a key sense that many of us use for a variety of tasks each day. Against this backdrop, we shouldn’t be surprised by the many real-world applications of computer vision available today.
Below, you can find a non-exhaustive list of the most prominent applications of computer vision.
Many popular computer vision applications involve recognizing things in images. A great example is self-driving cars. Manufacturers of autonomous cars use multiple cameras to acquire images from the environment so that their self-driving cars can detect objects, lane markings, and traffic signs to safely drive. How does object detection work in practice? We highly recommend you read our tutorial on Object Detection with YOLO algorithm.
Used for security and surveillance, facial recognition analyzes key features to identify people. This is done by training neural networks on vast biometrics databases that allow models to identify unique facial features in humans. Read our separate tutorial to discover how to perform Face Detection with Python.
Tools like Google Translate allow users to point a smartphone camera at a sign in another language and almost immediately obtain a translation of the sign in their preferred language.
Not only can computer vision applications understand images, but we're also at the point where they can create realistic images using generative AI. This is the case of DALL-E, a genAI model that creates images from text descriptions, or Sora, which does the same but with videos. Another example is deep fakes. A deep fake is software that is used to depict people in fake videos they did not actually appear in. By understanding what makes up a human face, deep fakes can generate new faces.
Curious about other applications of computer vision? Check out our dedicated article to learn about 19 Computer Vision Projects From Beginner to Advanced.
The unique applications of computer vision we have today wouldn’t be possible without AI, in particular, deep learning models. To understand why, we first need to understand what a digital image is –the most basic unit of information in computer vision.
A digital image is made up of hundreds, if not thousands of pixels, which contain information about color and intensity. In grayscale images, each pixel's intensity can be represented by a number between 0 and 255.

Greyscale images. Source: DataCamp
By contrast, colored images are generally stored in the RGB system. RGB stands for Red, Green, and Blue. Each image can be thought of as being represented by three rasters, one for each color channel. This means that you need three times the amount of data to store a color image compared to a grayscale one.
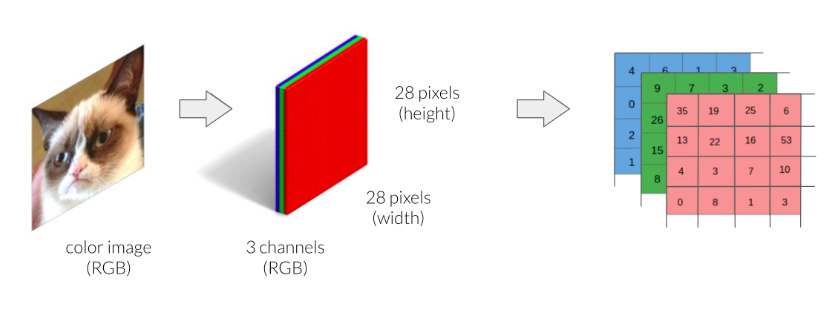
Colored images. Source: DataCamp
So, digital images can be seen as a bunch of numbers. Not long ago, we lacked the powerful tools required to process and extract information from images. This changed at the beginning of the 2010s when deep learning researchers managed to develop novel neural networks that were particularly well-suited for computer vision tasks.
Today, thanks to advancements in deep learning and progress in GPUs, cloud computing, and great availability of image data, data practitioners can train powerful neural networks capable of complex tasks in computer vision.
Following the generative AI boom, state-of-the-art vision language models (VLM) can understand and process both visual and textual data, enabling new tasks like image captioning, visual question answering, and text-to-image generation.
Curious about neural networks? Check our Introduction to Deep Learning with Python Course to get started today.
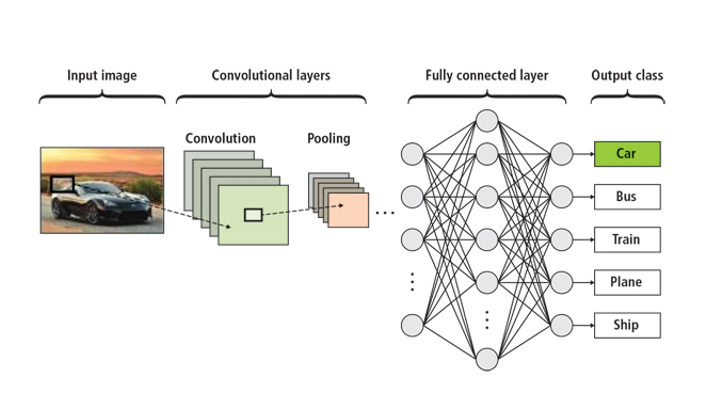
Neural network for computer vision. Source: NVIDIA
A common misconception among newcomers in the field is the difference between machine vision and computer vision.
Machine vision refers to the use of cameras, sensors, as well as algorithms, to help computers and robots analyze images and make informed decisions during the manufacturing process. The applications of machine vision encompass tasks like automatic inspection, quality control, and robot guidance.
The term is often used in manufacturing and industrial settings, hence its scope is application-specific and narrower compared to computer vision, which has a broader range of applications across various industries. Equally, in terms of complexity, computer vision often involves more complex processing and interpretation compared to machine vision.
You can see the differences between machine vision vs computer vision in the table below:
|
Aspect |
Machine Vision |
Computer Vision |
|
Definition |
Use of cameras, sensors, and algorithms to analyze images and make decisions, often in industrial settings. |
A field of AI focused on enabling computers to interpret and understand digital images and videos. |
|
Primary Use Cases |
Quality control, defect detection, assembly line monitoring, and robot guidance. |
Object detection, facial recognition, image generation, autonomous vehicles, and medical imaging. |
|
Complexity |
Generally simpler and specific to the task at hand. |
Involves complex processing, often using AI and deep learning models. |
|
Scope |
Narrow, application-specific (primarily manufacturing and industrial automation). |
Broad, encompassing multiple industries like healthcare, retail, automotive, and entertainment. |
|
Technology Focus |
Cameras, lighting, and hardware for capturing and analyzing images in controlled environments. |
Algorithms, neural networks, and large datasets for advanced image understanding. |
|
Examples |
Automated inspection of circuit boards, guiding robotic arms in factories. |
Training self-driving cars, creating deep fakes, or identifying diseases in medical scans. |
Computer vision is one of the most exciting and in-demand disciplines in AI. If you are willing to get started in the field, DataCamp is here to help. We work hard to offer data practitioners valuable, up-to-date courses and dedicated materials.
We highly recommend you start with our Image Processing in Python Skill Track. This track covers the fundamentals, from image pre-processing to deep learning. You'll begin with image enhancement and restoration and move on to biomedical images to analyze more complex image types, like MRI scans and X-rays. The track concludes with a course on convolutional neural nets, where you'll learn to build powerful deep-learning image classifiers.
For technical resources, consider the following:
We hope you enjoyed this user-friendly introduction to computer vision. The field is full of excitement, with new computer vision applications reaching the market every day. If you want to become a computer vision specialist, the Image Processing in Python Skill Track is the ideal place to get started.
Top DataCamp Courses
Course
Course
Course
blog
Abid Ali Awan
8 min
blog
Bex Tuychiev
15 min
blog
Zoumana Keita
14 min
Tutorial
Amberle McKee
Tutorial
Sayak Paul
Tutorial
Arunn Thevapalan

