
Cours
Supervised Learning in R: Regression
4 h
46.4K
La régression linéaire est un outil puissant dans l'analyse et la science des données. Elle est utilisée pour quantifier la relation entre une variable dépendante et une ou plusieurs variables indépendantes. Si vous êtes familiarisé avec la régression linéaire, vous connaissez peut-être aussi la mesure courante d'adéquation appelée r-carré, qui indique la proportion de la variance de la variable dépendante qui est expliquée par la ou les variables indépendantes. Cependant, vous êtes peut-être moins familier avec le r-carré ajusté, qui est souvent utilisé avec des modèles plus complexes comportant plusieurs prédicteurs.
Cet article vous permettra de mieux comprendre le r-carré ajusté, son importance dans l'évaluation des modèles, ses principales différences avec le r-carré et ses applications dans les scénarios de régression multiple, afin que vous puissiez maîtriser pleinement ces statistiques de modèle. Pour commencer, je vous recommande vivement de suivre le cours Introduction à la régression avec statsmodels en Python de DataCamp et notre cours Introduction à la régression en R pour apprendre à connaître les modèles de régression et à interpréter les différentes mesures de performance, notamment le r-carré ajusté.
Le R au carré mesure la proportion de la variance de la variable dépendante expliquée par la ou les variables indépendantes du modèle. Le r-carré ajusté explique également la variance, mais il comporte un élément supplémentaire : Comme son nom l'indique, ilajuste la valeur du r-carré en pénalisant l'inclusion de variables non pertinentes, c'est-à-dire fortement colinéaires. Pour ce faire, il prend en compte à la fois le nombre de prédicteurs et la taille de l'échantillon.
Pour trouver le r-carré ajusté, il faut d'abord trouver le r-carré. Bien qu'il existe différentes façons de trouver la valeur r-carré, la formule ci-dessous est l'une des plus courantes :
Ici, le r-carré est calculé comme un moins le quotient de la somme des carrés des résidus sur la somme totale des carrés.
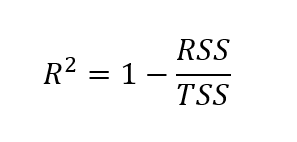
Où ?
Après avoir trouvé la valeur du r-carré, nous pouvons trouver le r-carré ajusté. Pour ce faire, nous insérons notre valeur de r-carré dans la formule ci-dessous.
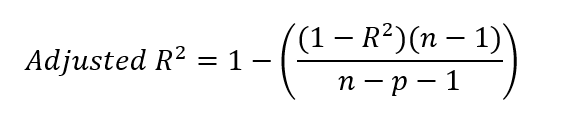
Où ?
Pour s'exercer, on peut prendre un exemple. Imaginez le scénario suivant : Nous disposons d'un ensemble de données comprenant 30 observations. Nous créons un modèle de régression linéaire multiple avec cinq prédicteurs. Nous découvrons un r-carré de 0,8. Voici comment nous pouvons utiliser cette information pour trouver le r-carré ajusté :

Vous vous interrogez peut-être sur la présence de -1 dans l'équation, tant au numérateur qu'au dénominateur. Pour clarifier, n-1 au numérateur tient compte des degrés de liberté, en corrigeant l'utilisation de la moyenne de l'échantillon lors du calcul de la variance. En effet, lors du calcul de la variance, nous utilisons généralement la moyenne de l'échantillon comme estimation de la moyenne de la population. La moyenne de l'échantillon n'étant pas la véritable moyenne de la population, la variance a tendance à être sous-estimée. Pour corriger ce biais, nous réduisons les degrés de liberté de 1.
Au dénominateur, n-p-1 tient compte du nombre de prédicteurs p dans le modèle, où p est le nombre de variables indépendantes. L'ajout de -1 au dénominateur corrige l'estimation de l'ordonnée à l'origine du modèle, qui utilise également un degré de liberté. Nous devons nous rappeler que, dans un modèle de régression, nous estimons à la fois les coefficients de pente des prédicteurs et l'ordonnée à l'origine pour tenir compte de toute la complexité.
Bien que le r-carré et le r-carré ajusté évaluent tous deux la performance du modèle de régression, il existe une différence essentielle entre les deux mesures. La valeur du carré r augmente toujours ou reste la même lorsque des prédicteurs sont ajoutés au modèle, même si ces prédicteurs n'améliorent pas de manière significative le pouvoir explicatif du modèle. Ce problème peut donner une impression trompeuse de l'efficacité du modèle.
Le r-carré ajusté ajuste la valeur du r-carré pour tenir compte du nombre de variables indépendantes dans le modèle. La valeur ajustée du r-carré peut diminuer si un nouveau prédicteur n'améliore pas l'adéquation du modèle, ce qui en fait une mesure plus fiable de la précision du modèle. C'est pourquoi le r-carré ajusté peut être utilisé comme un outil par les analystes de données pour les aider à décider quels prédicteurs inclure.
Pour construire des modèles fiables, il est important de savoir quand utiliser le r-carré ajusté plutôt que le r-carré. Vous trouverez ci-dessous des scénarios dans lesquels l'utilisation du r-carré ajusté pour évaluer les modèles est appropriée.
En général, bien que le r-carré ajusté soit préféré au r-carré dans les modèles de régression multiple parce qu'il tient compte du nombre de prédicteurs et pénalise l'ajout de variables non pertinentes, il existe certains scénarios dans lesquels l'utilisation du r-carré peut encore être appropriée :
Prenons un exemple où les nuances entre le r-carré et le r-carré ajusté entrent en jeu. Supposons que nous disposions de ces deux modèles de régression :
Nous pourrions dire que le modèle 1 semble expliquer une plus grande partie de la variance globale des données parce qu'il a une valeur r-carré plus élevée. Mais nous devons également considérer que le modèle 2 pourrait expliquer une plus grande partie de la véritable relation sous-jacente entre les variables parce qu'il prend en compte des prédicteurs non pertinents. Le r-carré ajusté plus élevé du modèle 2 suggère qu'il fournit un ajustement plus fiable en pénalisant la complexité inutile, et qu'il pourrait également être moins enclin à l'overfitting. Personnellement, et en l'absence d'autres informations, je choisirais le modèle 2.
Explorons des exemples pratiques de calcul du r-carré ajusté dans R et Python. Nous utiliserons le jeu de données "Fish Market" de Kaggle, qui permet d'estimer le poids d'un poisson en fonction de son espèce et de ses mesures physiques. Pour simplifier, nous arrondirons le résultat à cinq décimales.
Téléchargez le jeu de données et enregistrez-le dans votre répertoire de travail. Utilisez le code suivant pour ajuster un modèle linéaire afin de prédire le poids du poisson en fonction de différentes variables, notamment Length1, Height, Width, et Length3, qui désignent respectivement la longueur verticale du poisson, sa hauteur, sa largeur diagonale et sa longueur transversale.
# Load the dataset
data <- read.csv("data/Fish.csv")
# Remove rows with missing values
data <- na.omit(data)
# Model 1: Using 4 predictors ('Length1', 'Height', 'Width', 'Length3')
model1 <- lm(Weight ~ Length1 + Height + Width + Length3, data = data)Nous vérifions maintenant les valeurs de r-carré et de r-carré ajusté, et nous constatons ce qui suit. Le r-carré ajusté est très proche de la valeur du r-carré, juste un peu plus lent.
r_squared_model1 <- round(summary(model1)$r.squared, 4)
r_squared_model1 <- round(summary(model1)$adj.r.squared, 4)0.88527
0.88229Que se passe-t-il si nous essayons maintenant de créer un autre modèle en ajoutant un autre prédicteur ? Cette fois, nous créons un deuxième modèle et ajoutons Length2, qui fait référence à la longueur diagonale du poisson. De la même manière que précédemment, nous pouvons vérifier les valeurs de r-carré et de r-carré ajusté de notre nouveau modèle.
# Model 2: Adding one more predictor ('Length2')
model2 <- lm(Weight ~ Length1 + Height + Width + Length3 + Length2, data = data)r_squared_model2 <- round(summary(model1)$r.squared, 4)
r_squared_model2 <- round(summary(model1)$adj.r.squared, 4)0.88529
0.88154Pour le modèle 2, on constate que la valeur du r-carré n'a pratiquement pas augmenté par rapport au modèle 1. Nous constatons également que la valeur ajustée du r-carré a diminué, et que la diminution du r-carré ajusté a été plus importante que l'augmentation de la valeur du r-carré. Cela nous indique que le prédicteur que nous avons ajouté n'était pas bon.
Quand on y pense, Length2, qui se réfère à la longueur de la diagonale du poisson, était probablement fortement corrélé avec les autres variables du modèle ou avec une combinaison linéaire des autres variables du modèle. En particulier, nous nous attendons à ce que la longueur de la diagonale du poisson soit fortement corrélée avec la longueur du poisson et la longueur transversale du poisson. Nous constatons donc que notre nouvelle variable n'a pas apporté d'informations nouvelles et pertinentes.
Dans un souci d'exhaustivité, nous pouvons également montrer comment trouver le r-carré ajusté à la main. Nous utilisons la valeur r-squared et les paramètres du modèle, et nous suivons la formule que nous avons montrée précédemment.
# Save R-squared as a variable
r_squared_model2 <- summary(model2)$r.squared
# Get the number of observations (n) for both models
n <- nrow(data) # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 <- length(coef(model1)) - 1
p_model2 <- length(coef(model2)) - 1
# Adjusted r-squared formula for Model 1
adjusted_r_squared_model1 <- 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted r-squared formula for Model 2
adjusted_r_squared_model2 <- 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared values for both models
cat("R-Squared for Model 1:", r_squared_model1, "\n")
cat("R-Squared for Model 2:", r_squared_model2, "\n")
# Print the Adjusted R-Squared values for both models
cat("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1, "\n")
cat("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2, "\n")Le code suivant montre une implémentation du même exemple en Python.
# Import requied libraries
import pandas as pd
import statsmodels.api as sm
# Load the dataset
data = pd.read_csv('data/Fish.csv')
# Drop rows with missing values if any exist
data = data.dropna()
# Define predictors for Model 1 (4 variables)
X1 = data[['Length1', 'Height', 'Width', 'Length3']]
# Add a constant (intercept)
X1 = sm.add_constant(X1)
# Define the target variable 'Weight'
y = data['Weight']
# Fit Model 1
model1 = sm.OLS(y, X1).fit()
# Define predictors for Model 2 (5 variables)
X2 = data[['Length1', 'Height', 'Width', 'Length3', 'Length2']]
# Add a constant (intercept)
X2 = sm.add_constant(X2)
# Fit Model 2
model2 = sm.OLS(y, X2).fit()
# Save r-squared as a variable
r_squared_model1 = model1.rsquared # R-Squared for Model 1
r_squared_model2 = model2.rsquared # R-Squared for Model 2
# Get the number of observations
n = X1.shape[0] # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 = X1.shape[1] - 1 # Number of predictors for Model 1
p_model2 = X2.shape[1] - 1 # Number of predictors for Model 2
# Adjusted R-Squared formula for Model 1
adjusted_r_squared_model1 = 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted R-Squared formula for Model 2
adjusted_r_squared_model2 = 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared for both models
print("R-Squared for Model 1:", r_squared_model1)
print("R-Squared for Model 2:", r_squared_model2)
# Print the Adjusted R-Squared values for both models
print("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1)
print("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2)Nous pouvons également utiliser des fonctions dans Python pour trouver les valeurs r-carré et r-carré ajusté des modèles de régression :
# Model 1
print("Model 1 R-Squared:", model1.rsquared)
print("Model 1 Adjusted R-Squared:", model1.rsquared_adj)
# Model 2
print("Model 2 R-Squared:", model2.rsquared)
print("Model 2 Adjusted R-Squared:", model2.rsquared_adj)Si vous avez rencontré des difficultés avec les sections de code ci-dessus, consultez nos tutoriels Essentials of Linear Regression in Python et How to Do Linear Regression in R pour apprendre le guide étape par étape de la mise en œuvre et de l'interprétation des différentes métriques du modèle de régression. Si Excel est votre outil d'analyse préféré, consultez notre tutoriel sur la régression linéaire dans Excel ( ) : Un guide complet pour les débutants pour apprendre à mettre en œuvre et à visualiser les modèles de régression linéaire dans Excel.
Lorsque nous examinons le r-carré ajusté, nous devons prendre le temps de clarifier nos termes. Certains termes semblent similaires mais ont des objectifs différents. J'ai créé ici un tableau qui compare des notions similaires mais distinctes : r-carré, r-carré ajusté et r-carré prédit.
| Métrique | Mesures | Cas d'utilisation | Points forts | Limitations |
|---|---|---|---|---|
| R au carré | Proportion de la variance expliquée par le modèle | Comprendre comment le modèle s'adapte aux données d'apprentissage | Simple à interpréter et permettant d'obtenir rapidement l'adéquation du modèle | Trompeuse lors de la comparaison de modèles avec différents prédicteurs, vulnérable à l'ajustement excessif |
| R-carré ajusté | Proportion de la variance expliquée, ajustée en fonction du nombre de prédicteurs | Comparaison de modèles avec différents nombres de prédicteurs | Pénalise l'ajout de variables non pertinentes, empêche l'ajustement excessif | N'indique pas la performance prédictive sur de nouvelles données |
| R-carré prédit | Dans quelle mesure le modèle prédit-il les nouvelles données ? | Évaluation de la performance du modèle sur des données inédites | Indique dans quelle mesure le modèle se généralise à de nouvelles données | Nécessité d'une validation croisée ou d'un ensemble de données de réserve, coûteux sur le plan informatique |
Enfin, examinons quelques erreurs courantes, car il existe des malentendus fréquents sur son utilisation dans la régression.
Le r-carré ajusté est une mesure importante pour évaluer la performance des modèles de régression, en particulier lorsqu'il s'agit de variables indépendantes multiples. Par rapport à la métrique r-carré, elle fournit une mesure plus réaliste et plus fiable de la précision du modèle lorsque plusieurs prédicteurs sont impliqués.
Si vous êtes curieux de savoir comment R et Python trouvent les coefficients des modèles de régression linéaire, consultez les tutoriels suivants : Tutoriel sur l'équation normale pour la régression linéaire et Décomposition QR dans l'apprentissage automatique : Un guide détaillé.
Apprenez avec DataCamp
Cours
Cours
Cours
Tutoriel
Allan Ouko
Tutoriel
DataCamp Team
Tutoriel
Aditya Sharma
Tutoriel
Allan Ouko
Tutoriel
Sejal Jaiswal
Tutoriel
Kurtis Pykes
