
Curso
Supervised Learning in R: Regression
4 h
46.4K
La regresión lineal es una poderosa herramienta en el análisis y la ciencia de datos. Se utiliza para cuantificar la relación entre una variable dependiente y una o varias variables independientes. Si estás familiarizado con la regresión lineal, puede que también estés familiarizado con la medida común de bondad de ajuste denominada r-cuadrado, que indica la proporción de la varianza de la variable dependiente que se explica por la(s) variable(s) independiente(s). Sin embargo, puede que estés menos familiarizado con la r-cuadrado ajustada, que suele utilizarse con modelos más complejos con múltiples predictores.
Este artículo te proporcionará una comprensión exhaustiva de la r-cuadrado ajustada, su importancia en la evaluación de modelos, sus diferencias clave con la r-cuadrado y sus aplicaciones en escenarios de regresión múltiple, para que puedas tener un dominio completo de estas estadísticas de modelos. Para empezar, recomiendo encarecidamente seguir el curso Introducción a la regresión con modelos estadísticos en Python de DataCamp y nuestro curso Introducción a la regresión en R para aprender sobre los modelos de regresión y cómo interpretar las distintas métricas de rendimiento, incluida la r-cuadrado ajustada.
La R-cuadrado mide la proporción de varianza de la variable dependiente explicada por la variable o variables independientes del modelo. La r-cuadrado ajustada también explica la varianza, pero tiene una consideración adicional: Como su nombre indica, ajusta el valor r-cuadrado penalizando la inclusión de variables irrelevantes, es decir, altamente colineales. Para ello, tiene en cuenta tanto el número de predictores como el tamaño de la muestra.
Para hallar la r-cuadrado ajustada, primero tenemos que hallar la r-cuadrado. Aunque hay distintas formas de hallar el valor r-cuadrado, la fórmula que aparece a continuación es una de las más habituales:
Aquí, la r-cuadrado se calcula como uno menos el cociente de la suma de cuadrados residuales sobre la suma total de cuadrados.
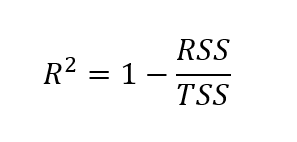
Dónde:
Tras hallar el valor de r-cuadrado, podemos hallar el r-cuadrado ajustado. Para ello, introducimos nuestro valor r-cuadrado en la fórmula siguiente.
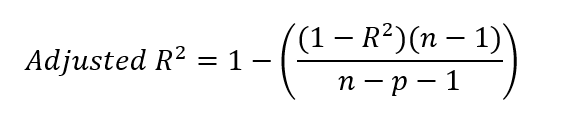
Dónde:
Para practicar, podemos poner un ejemplo. Considera este escenario: Tenemos un conjunto de datos con 30 observaciones. Creamos un modelo de regresión lineal múltiple con cinco predictores. Descubrimos un r-cuadrado de 0,8. Así es como podemos tomar esta información para hallar la r-cuadrado ajustada:

Quizá te preguntes por el -1 de la ecuación, tanto en el numerador como en el denominador. Para aclararlo, n-1 en el numerador tiene en cuenta los grados de libertad, corrigiendo el uso de la media muestral al calcular la varianza. Esto se debe a que, al calcular la varianza, solemos utilizar la media muestral como estimación de la media poblacional. Como la media de la muestra no es la verdadera media de la población, la varianza tiende a subestimarse. Para corregir este sesgo, reducimos los grados de libertad en 1.
En el denominador, n-p-1 ajusta el número de predictores p del modelo, donde p es el número de variables independientes. El -1 adicional en el denominador corrige la estimación del intercepto del modelo, que también consume un grado de libertad. Debemos recordar que, en un modelo de regresión, estimamos tanto los coeficientes de pendiente de los predictores como el intercepto para tener en cuenta toda la complejidad.
Aunque tanto la r-cuadrado como la r-cuadrado ajustada evalúan el rendimiento del modelo de regresión, existe una diferencia clave entre ambas métricas. El valor r-cuadrado siempre aumenta o permanece igual cuando se añaden más predictores al modelo, aunque esos predictores no mejoren significativamente el poder explicativo del modelo. Esta cuestión puede crear una impresión engañosa sobre la eficacia del modelo.
La r-cuadrado ajustada ajusta el valor de la r-cuadrado para tener en cuenta el número de variables independientes del modelo. El valor r-cuadrado ajustado puede disminuir si un nuevo predictor no mejora el ajuste del modelo, lo que lo convierte en una medida más fiable de la precisión del modelo. Por esta razón, el r-cuadrado ajustado puede ser utilizado como herramienta por los analistas de datos para ayudarles a decidir qué predictores incluir.
Saber cuándo utilizar r-cuadrado ajustado en lugar de r-cuadrado es importante para construir modelos fiables. A continuación se exponen supuestos en los que resulta adecuado utilizar la r-cuadrado ajustada para evaluar los modelos.
En general, aunque la r-cuadrado ajustada es preferible a la r-cuadrado en los modelos de regresión múltiple porque tiene en cuenta el número de predictores y penaliza la adición de variables irrelevantes, hay algunos supuestos en los que utilizar la r-cuadrado puede seguir siendo adecuado:
Consideremos un ejemplo en el que entrarían en juego los matices entre r-cuadrado y r-cuadrado ajustado. Supongamos que tenemos estos dos modelos de regresión:
Podríamos decir que el modelo 1 parece explicar más de la varianza global de los datos porque tiene un valor r-cuadrado más alto. Pero también tenemos que considerar que el modelo 2 podría explicar más de la verdadera relación subyacente entre las variables porque tiene en cuenta predictores irrelevantes. La mayor r-cuadrado ajustada del modelo 2 sugiere que proporciona un ajuste más fiable al penalizar la complejidad innecesaria, y también podría ser menos propenso al sobreajuste. Personalmente, y a falta de otra información, elegiría el modelo 2.
Exploremos ejemplos prácticos de cálculo de la r-cuadrado ajustada en R y Python. Utilizaremos el conjunto de datos "Pescadería" de Kaggle, que sirve para estimar el peso de un pez en función de su especie y sus medidas físicas. Para simplificar, redondearemos el resultado a cinco decimales.
Descarga el conjunto de datos y guárdalo en tu directorio de trabajo. Utiliza el código siguiente para ajustar un modelo lineal que prediga el peso del pez en función de algunas variables diferentes, como Length1, Height, Width, y Length3, que se refieren a la longitud vertical del pez, la altura del pez, la anchura diagonal del pez y la longitud transversal del pez, respectivamente.
# Load the dataset
data <- read.csv("data/Fish.csv")
# Remove rows with missing values
data <- na.omit(data)
# Model 1: Using 4 predictors ('Length1', 'Height', 'Width', 'Length3')
model1 <- lm(Weight ~ Length1 + Height + Width + Length3, data = data)Ahora, comprobamos los valores r-cuadrado y r-cuadrado ajustado, y vemos lo siguiente. El r-cuadrado ajustado es muy parecido al valor r-cuadrado, sólo que ligeramente más lento.
r_squared_model1 <- round(summary(model1)$r.squared, 4)
r_squared_model1 <- round(summary(model1)$adj.r.squared, 4)0.88527
0.88229¿Y si ahora intentamos crear otro modelo añadiendo otro predictor? Esta vez, creamos un segundo modelo y añadimos Length2, que se refiere a la longitud diagonal del pez. Del mismo modo que antes, podemos comprobar los valores r-cuadrado y r-cuadrado ajustado de nuestro nuevo modelo.
# Model 2: Adding one more predictor ('Length2')
model2 <- lm(Weight ~ Length1 + Height + Width + Length3 + Length2, data = data)r_squared_model2 <- round(summary(model1)$r.squared, 4)
r_squared_model2 <- round(summary(model1)$adj.r.squared, 4)0.88529
0.88154Para el modelo 2, podemos ver que el valor r-cuadrado apenas aumentó en comparación con el modelo 1. Además, vemos que el valor r-cuadrado ajustado disminuyó, y la disminución del r-cuadrado ajustado fue mayor que el aumento del valor r-cuadrado. Esto nos dice que el predictor que añadimos no era bueno.
Si lo pensamos bien, Length2, que se refiere a la longitud diagonal del pez, probablemente estaba muy correlacionada con las demás variables del modelo o con una combinación lineal de las demás variables del modelo. En concreto, esperamos que la longitud diagonal del pez esté muy correlacionada con la longitud del pez y la longitud transversal del pez. Así que vemos que nuestra nueva variable no añadía información nueva y relevante.
En aras de la exhaustividad, también podemos demostrar cómo hallar el r-cuadrado ajustado a mano. Utilizamos el valor r-cuadrado y los parámetros del modelo, y seguimos la fórmula que hemos mostrado antes.
# Save R-squared as a variable
r_squared_model2 <- summary(model2)$r.squared
# Get the number of observations (n) for both models
n <- nrow(data) # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 <- length(coef(model1)) - 1
p_model2 <- length(coef(model2)) - 1
# Adjusted r-squared formula for Model 1
adjusted_r_squared_model1 <- 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted r-squared formula for Model 2
adjusted_r_squared_model2 <- 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared values for both models
cat("R-Squared for Model 1:", r_squared_model1, "\n")
cat("R-Squared for Model 2:", r_squared_model2, "\n")
# Print the Adjusted R-Squared values for both models
cat("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1, "\n")
cat("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2, "\n")El código siguiente muestra una implementación del mismo ejemplo en Python.
# Import requied libraries
import pandas as pd
import statsmodels.api as sm
# Load the dataset
data = pd.read_csv('data/Fish.csv')
# Drop rows with missing values if any exist
data = data.dropna()
# Define predictors for Model 1 (4 variables)
X1 = data[['Length1', 'Height', 'Width', 'Length3']]
# Add a constant (intercept)
X1 = sm.add_constant(X1)
# Define the target variable 'Weight'
y = data['Weight']
# Fit Model 1
model1 = sm.OLS(y, X1).fit()
# Define predictors for Model 2 (5 variables)
X2 = data[['Length1', 'Height', 'Width', 'Length3', 'Length2']]
# Add a constant (intercept)
X2 = sm.add_constant(X2)
# Fit Model 2
model2 = sm.OLS(y, X2).fit()
# Save r-squared as a variable
r_squared_model1 = model1.rsquared # R-Squared for Model 1
r_squared_model2 = model2.rsquared # R-Squared for Model 2
# Get the number of observations
n = X1.shape[0] # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 = X1.shape[1] - 1 # Number of predictors for Model 1
p_model2 = X2.shape[1] - 1 # Number of predictors for Model 2
# Adjusted R-Squared formula for Model 1
adjusted_r_squared_model1 = 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted R-Squared formula for Model 2
adjusted_r_squared_model2 = 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared for both models
print("R-Squared for Model 1:", r_squared_model1)
print("R-Squared for Model 2:", r_squared_model2)
# Print the Adjusted R-Squared values for both models
print("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1)
print("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2)También podemos utilizar funciones en Python para hallar los valores r-cuadrado y r-cuadrado ajustado de los modelos de regresión:
# Model 1
print("Model 1 R-Squared:", model1.rsquared)
print("Model 1 Adjusted R-Squared:", model1.rsquared_adj)
# Model 2
print("Model 2 R-Squared:", model2.rsquared)
print("Model 2 Adjusted R-Squared:", model2.rsquared_adj)Si has tenido algún problema con las secciones de código anteriores, consulta nuestros tutoriales Fundamentos de la regresión lineal en Python y Cómo hacer regresión lineal en R para aprender la guía paso a paso para implementar e interpretar diferentes métricas del modelo de regresión. Si Excel es tu herramienta de análisis preferida, consulta nuestro tutorial sobre Regresión lineal en Excel: Una guía completa para principiantes para aprender a implementar y visualizar modelos de regresión lineal en Excel.
Al considerar la r-cuadrado ajustada, deberíamos tomarnos un tiempo para mantener claros nuestros términos. Hay algunos términos que parecen similares pero tienen finalidades diferentes. Aquí he creado una tabla que compara algunas ideas parecidas pero distintas: r-cuadrado, r-cuadrado ajustado y r-cuadrado predicho.
| Métrica | Medidas | Caso práctico | Puntos fuertes | Limitaciones |
|---|---|---|---|---|
| R-cuadrado | Proporción de varianza explicada por el modelo | Comprender lo bien que se ajusta el modelo a los datos de entrenamiento | Fácil de interpretar y proporciona rápidamente el ajuste del modelo | Engañoso al comparar modelos con diferentes predictores, vulnerable al sobreajuste |
| R-cuadrado ajustado | Proporción de varianza explicada, ajustada al número de predictores | Comparación de modelos con diferente número de predictores | Penaliza la adición de variables irrelevantes, evita el sobreajuste | No indica el rendimiento predictivo de los nuevos datos |
| R-cuadrado previsto | Cómo de bien predice el modelo los nuevos datos | Evaluar el rendimiento del modelo con datos no vistos | Indica lo bien que generaliza el modelo a nuevos datos | Requiere validación cruzada o un conjunto de datos de reserva, caro desde el punto de vista informático |
Por último, veamos algunos errores comunes, porque hay algunos malentendidos habituales sobre su uso en la regresión.
La r-cuadrado ajustada es una métrica importante para evaluar el rendimiento de los modelos de regresión, sobre todo cuando se trata de múltiples variables independientes. En comparación con la métrica r-cuadrado, proporciona una medida más realista y fiable de la precisión del modelo cuando intervienen múltiples predictores.
Si tienes curiosidad por saber cómo R y Python encuentran los coeficientes de los modelos de regresión lineal, consulta los siguientes tutoriales: Tutorial de Ecuación Normal para Regresión Lineal y Descomposición QR en Aprendizaje Automático: Guía detallada.
Aprende con DataCamp
Curso
Curso
Curso
blog
Arun Nanda
15 min
Tutorial
Zoumana Keita
Tutorial
Eladio Montero Porras
Tutorial
Kurtis Pykes
Tutorial
Vidhi Chugh
Tutorial
Abid Ali Awan
