
Cours
Concepts Databricks
4 h
22K
Les API Databricks permettent une interaction programmatique avec Databricks, permettant aux utilisateurs d'automatiser les flux de travail, de gérer les clusters, d'exécuter des tâches et d'accéder aux données. Ces API prennent en charge l'authentification via des jetons d'accès personnels, OAuth ou Azure Active Directory.
Dans cet article, je vais vous guider à travers un voyage approfondi et pratique à travers l'API REST de Databricks. Que vous soyez novice en matière de Databricks ou que vous cherchiez à optimiser vos flux de travail existants, ce guide vous aidera à maîtriser les opérations clés, notamment l'authentification, la gestion des tâches et l'intégration avec des systèmes externes.
À la fin de cet article, vous disposerez d'un plan clair pour.. :
Si vous êtes totalement novice en matière de Databricks et que vous souhaitez l'assimiler rapidement, lisez notre article de blog, How to Learn Databricks : A Beginner's Guide to the Unified Data Platform, qui vous aidera à comprendre les principales fonctionnalités et applications de Databricks, et vous fournira également un parcours structuré pour commencer votre apprentissage.
L'API REST de Databricks offre de puissantes possibilités aux développeurs et aux ingénieurs de données, leur permettant de gérer les ressources de manière programmatique et de rationaliser les flux de travail. Voici comment l'API Databricks peut faire une grande différence :
L'API Databricks permet aux utilisateurs d'automatiser des tâches telles que la planification des travaux et la gestion des clusters. Cela permet de réduire les efforts manuels nécessaires à la gestion de ces processus et de libérer du temps pour des activités plus stratégiques. En automatisant les tâches répétitives, les organisations peuvent améliorer leur efficacité et réduire le risque d'erreur humaine, qui peut entraîner des erreurs coûteuses ou des temps d'arrêt.
L'API Databricks est conçue pour la flexibilité, permettant l'intégration avec des plateformes externes telles que des outils d'orchestration comme Apache Airflow ou Azure Data Factory.
Vous pouvez également utiliser l'API Databricks pour des systèmes de surveillance et d'alerte tels que Prometheus ou Datadog. L'API Databricks est également utilisée dans les pipelines d'ingestion de données à partir d'outils tels que Kafka ou les services de données RESTful. Ces intégrations permettent de mettre en place des flux de travail de bout en bout qui font le lien entre l'ingénierie des données et l'analyse à travers plusieurs systèmes.
L'API Databricks prend en charge la création et la gestion de milliers de pipelines automatisés. Il s'adapte sans effort à la gestion de milliers de tâches exécutées en parallèle et à la mise à l'échelle dynamique des clusters en fonction de la charge de travail. Cette évolutivité garantit que votre infrastructure s'adapte de manière transparente aux besoins de l'entreprise, même à l'échelle de l'entreprise.
L'API REST de Databricks offre un large éventail d'opérations pour gérer les travaux, les clusters, les fichiers et les autorisations d'accès. Ci-dessous, je vais explorer les opérations clés de l'API avec des exemples pratiques pour vous aider à construire et à automatiser des flux de travail robustes.
Les emplois sont l'épine dorsale des flux de travail automatisés dans Databricks. L'API vous permet de créer, de gérer et de contrôler les travaux de manière transparente.
Utilisez le point de terminaison POST /API/2.1/jobs/create pour définir un nouveau travail. Par exemple, la charge utile JSON suivante crée un nouveau job Databricks nommé My Job et exécute un notebook situé à l'adresse /path/to/notebook. La charge utile utilise alors un cluster existant avec l'ID cluster-id, ce qui évite de devoir en créer un nouveau. Si le travail échoue, la charge utile envoie une notification par courrier électronique à user@example.com.
{
"name": "My Job",
"existing_cluster_id": "cluster-id",
"notebook_task": {
"notebook_path": "/path/to/notebook"
},
"email_notifications": {
"on_failure": ["user@example.com"]
}
}Vous pouvez utiliser le point de terminaison GET /api/2.1/jobs/list pour récupérer une liste de tous les travaux dans votre espace de travail. Par exemple, l'exemple de commande suivant permet de dresser la liste de tous les travaux :
curl -n -X GET \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/listUtilisez le point de terminaison POST /api/2.1/jobs/run-now pour déclencher l'exécution immédiate d'un travail.
curl -n -X POST \
https://<databricks-instance>.cloud.databricks.com/api/2.1/jobs/run-now?job_id=123456789Bien que la dernière version de l'API ne dispose pas d'un point d'accès direct pour la suppression des travaux, vous pouvez gérer les travaux et leur cycle de vie à l'aide d'autres points d'accès. Utilisez le point de terminaison Supprimer un travail : POST /api/2.1/jobs/delete pour supprimer un travail et POST /api/2.1/jobs/runs/cancel pour annuler une exécution.
Utilisez GET /api/2.1/jobs/runs/get pour contrôler l'état d'un travail. Récupérez les journaux ou traitez les erreurs à l'aide du champ run_state.
Les grappes fournissent les ressources informatiques nécessaires à l'exécution des tâches. L'API simplifie la gestion du cycle de vie des clusters.
Créez un cluster avec POST /api/2.1/clusters/create. Par exemple, vous pouvez avoir ce qui suit dans le corps de la demande.
{
"cluster_name": "Example Cluster",
"spark_version": "12.2.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 4
}Ensuite, exécutez l'exemple de commande ci-dessous pour créer ce cluster.
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"cluster_name": "My Cluster", "spark_version": "7.3.x-scala2.12", "node_type_id": "i3.xlarge", "num_workers": 2}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/clusters/createUtilisez les API suivantes pour :
Démarrage de la grappe: POST /api/2.1/clusters/start
Redémarrez le cluster : POST /api/2.1/clusters/restart
Redimensionner le cluster : PATCH /api/2.1/clusters/edit
Mettez fin à la grappe : POST /api/2.1/clusters/delete
Considérez les meilleures pratiques suivantes pour :
DBFS permet le stockage et la récupération de fichiers dans les Databricks.
Vous pouvez utiliser l'API POST /api/2.1/dbfs/upload pour télécharger des fichiers vers DBFS par morceaux (multipart) ou lorsque vous traitez des fichiers volumineux (>1MB). L'API GET /api/2.1/dbfs/read est utilisée pour télécharger des fichiers.
Utilisez GET /api/2.1/dbfs/list pour explorer les répertoires et gérer les fichiers de manière programmatique. Pour les téléchargements de fichiers volumineux, utilisez les téléchargements par morceaux avec POST /api/2.1/dbfs/put et le paramètre overwrite.
L'API Secrets garantit un stockage et une récupération sécurisés des informations sensibles.
Utilisez le point de terminaison POST /api/2.1/secrets/create pour créer un nouveau secret afin de stocker des informations sensibles.
Par exemple, vous pouvez créer le corps de la demande en JSON comme suit :
{
"scope": "my-scope",
"key": "my-key",
"string_value": "my-secret-value"
}Créez ensuite le secret à l'aide de la commande suivante :
curl -n -X POST \
-H 'Content-Type: application/json' \
-d '{"scope": "my-scope", "key": "my-key", "string_value": "my-secret-value"}' \
https://<databricks-instance>.cloud.databricks.com/api/2.1/secrets/createUtilisez le point de terminaison GET /API/2.1/secrets/get pour récupérer des secrets pour des intégrations externes.
La plateforme Databricks permet un contrôle granulaire de l'accès aux travaux et aux ressources.
Utilisez le point de terminaison POST /api/2.1/permissions/jobs/update pour attribuer des rôles tels que propriétaires ou spectateurs. Par exemple, la charge utile suivante est utilisée pour mettre à jour les autorisations :
{
"access_control_list": [
{
"user_name": "user@example.com",
"permission_level": "CAN_MANAGE"
}
]
}Utilisez le contrôle d'accès basé sur les rôles (RBAC) intégré à Databricks pour gérer les autorisations entre les différents rôles au sein de votre organisation.
Lorsque vous travaillez avec l'API REST de Databricks, il est important de prendre en compte les limites de débit, de gérer les erreurs avec élégance et de relever les défis courants pour garantir des performances fiables et des opérations fluides. Dans cette section, j'aborderai les stratégies permettant d'optimiser l'utilisation de l'API et de résoudre les problèmes de manière efficace.
L'API Databricks applique des limites de taux pour garantir une utilisation équitable et maintenir la fiabilité du service.
Vous trouverez ci-dessous les problèmes courants que vous pouvez rencontrer avec les API de Databricks et la manière de les résoudre.
Si vous rencontrez des goulets d'étranglement au niveau des performances, vous devriez envisager les solutions suivantes :
L'API REST de Databricks est très polyvalente et prend en charge aussi bien les flux de travail simples, à un seul thread, que les traitements parallèles complexes. En exploitant des flux de travail avancés, vous pouvez optimiser l'efficacité et vous intégrer de manière transparente à des systèmes externes. Voyons comment mettre en œuvre ces fonctionnalités.
Notez que vous devez toujours configurer vos variables d'environnement à l'aide de :
DATABRICKS_HOST: Cette variable stocke l'URL de votre instance Databricks, qui est nécessaire pour construire les requêtes API.
DATABRICKS_TOKEN: Cette variable contient votre jeton d'accès, ce qui simplifie le processus d'inclusion dans les appels à l'API.
L'appel séquentiel d'un seul point de terminaison de l'API est efficace pour les petites tâches ou l'automatisation simple. Vous trouverez ci-dessous un exemple pratique utilisant la bibliothèque des requêtes en Python.
import requests
import os
# Set up environment variables
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
# API request to list jobs
url = f"{DATABRICKS_HOST}/api/2.1/jobs/list"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers)
if response.status_code == 200:
jobs = response.json().get("jobs", [])
for job in jobs:
print(f"Job ID: {job['job_id']}, Name: {job['settings']['name']}")
else:
print(f"Error: {response.status_code} - {response.text}")Le traitement en parallèle peut améliorer considérablement l'efficacité de l'ingestion de données à grande échelle ou de la gestion de points d'extrémité multiples. L'exemple ci-dessous montre comment utiliser Apache Spark pour distribuer des appels d'API de manière simultanée.
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
import requests
# Initialize Spark session
spark = SparkSession.builder.appName("ParallelAPI").getOrCreate()
# Sample data for parallel calls
data = [{"job_id": 123}, {"job_id": 456}, {"job_id": 789}]
df = spark.createDataFrame(data)
# Define API call function
def fetch_job_details(job_id):
url = f"{DATABRICKS_HOST}/api/2.1/jobs/get"
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}
response = requests.get(url, headers=headers, params={"job_id": job_id})
if response.status_code == 200:
return response.json().get("settings", {}).get("name", "Unknown")
return f"Error: {response.status_code}"
# Register UDF
fetch_job_details_udf = udf(fetch_job_details)
# Apply UDF to DataFrame
results_df = df.withColumn("job_name", fetch_job_details_udf("job_id"))
results_df.show()Tenez compte des conseils suivants pour trouver des compromis en matière d'évolutivité et de coûts.
L'intégration de Databricks avec des orchestrateurs externes comme Airflow ou Dagster vous permet de gérer des flux de travail complexes et d'automatiser l'exécution des tâches sur différents systèmes. L'exemple ci-dessous montre comment utiliser Airflow pour déclencher un travail Databricks.
from airflow import DAG
from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator
from datetime import datetime
# Define default arguments for the DAG
default_args = {
"owner": "airflow", # Owner of the DAG
"depends_on_past": False, # Do not depend on past DAG runs
"retries": 1, # Number of retry attempts in case of failure
}
# Define the DAG
with DAG(
dag_id="databricks_job_trigger", # Unique DAG ID
default_args=default_args, # Apply default arguments
schedule_interval=None, # Manually triggered DAG (no schedule)
start_date=datetime(2023, 1, 1), # DAG start date
) as dag:
# Task to trigger a Databricks job
run_job = DatabricksRunNowOperator(
task_id="run_databricks_job", # Unique task ID
databricks_conn_id="databricks_default", # Connection ID for Databricks
job_id=12345, # Replace with the actual Databricks job ID
)
# Set task dependencies (if needed)
run_jobPour les pipelines CI/CD, des outils comme l'intégration de Git avec Databricks peuvent automatiser le déploiement du code et des ressources dans différents environnements. Cela permet de s'assurer que les changements sont testés et validés avant d'être déployés en production.
# Example of using Databricks REST API in a CI/CD pipeline
import requests
def deploy_to_production():
# Assuming you have a personal access token
token = "your_token_here"
headers = {"Authorization": f"Bearer {token}"}
# Update job or cluster configurations as needed
url = "https://your-databricks-instance.cloud.databricks.com/api/2.1/jobs/update"
payload = {"job_id": "123456789", "new_settings": {"key": "value"}}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
print("Deployment successful.")
else:
print(f"Deployment failed. Status code: {response.status_code}")Maintenant que nous avons vu les différentes applications de l'API Databricks, permettez-moi de vous présenter un exemple de pipeline automatisé. Ce pipeline va ingérer des données à partir d'une API externe, transformer les données dans Databricks, puis écrire les résultats dans un tableau Databricks. Ce scénario est un flux de travail de bout en bout typique des tâches modernes d'ingénierie des données. Si vous avez besoin de rafraîchir vos connaissances sur les principales fonctionnalités de Databricks, y compris l'ingestion de données, je vous recommande de consulter notre tutoriel sur les 7 concepts incontournables pour tout spécialiste des données.
Pour interagir avec l'API REST de Databricks, vous devez vous authentifier à l'aide d'un jeton d'accès personnel (PAT). Suivez les étapes suivantes pour générer le PAT.
Espace de travail Databricks. Image par l'auteur.
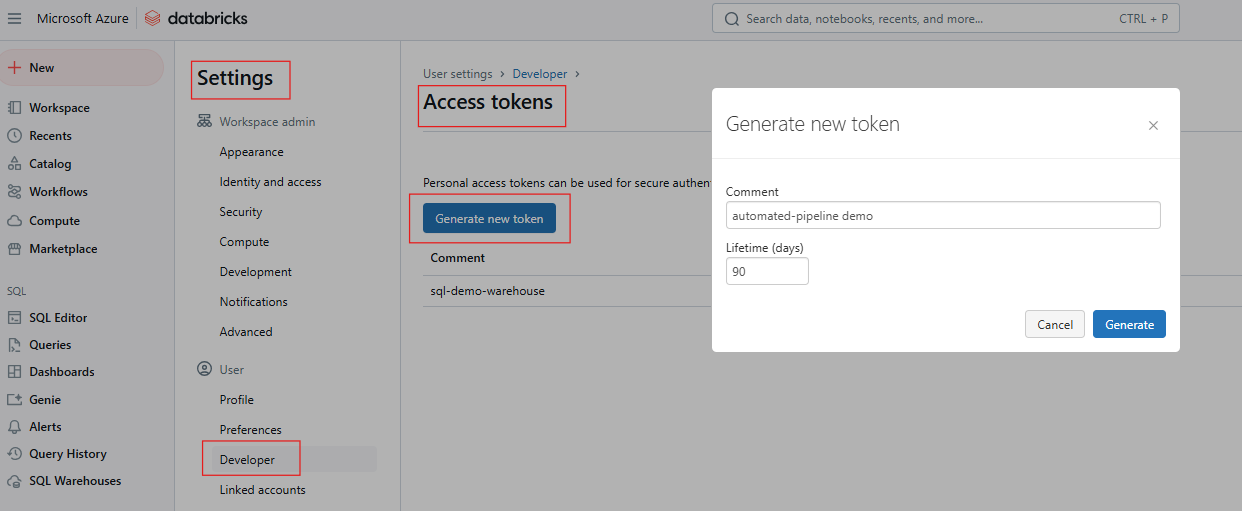
Générer un jeton d'accès dans Databricks. Image par l'auteur.
Si vous avez besoin de rafraîchir vos connaissances sur Databricks SQL, je vous recommande de lire notre tutoriel Databricks SQL pour apprendre à configurer SQL Warehouse à partir de l'interface web de Databricks.
Configurez les variables d'environnement en utilisant l'une des méthodes suivantes :
export DATABRICKS_HOST=https://<your-databricks-instance>
export DATABRICKS_TOKEN=<your-access-token>import os
import requests
DATABRICKS_HOST = os.getenv("DATABRICKS_HOST")
DATABRICKS_TOKEN = os.getenv("DATABRICKS_TOKEN")
headers = {"Authorization": f"Bearer {DATABRICKS_TOKEN}"}Un travail Databricks peut consister en plusieurs tâches, chacune effectuant une étape du pipeline. Pour cet exemple, considérez ce qui suit :
L'exemple suivant utilise le point de terminaison POST /api/2.1/jobs/create pour créer le travail.
{
"name": "Multi-Step Pipeline",
"tasks": [
{
"task_key": "fetch_data",
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/fetch_data"
}
},
{
"task_key": "transform_data",
"depends_on": [{"task_key": "fetch_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/transform_data"
}
},
{
"task_key": "write_results",
"depends_on": [{"task_key": "transform_data"}],
"existing_cluster_id": "your-cluster-id",
"notebook_task": {
"notebook_path": "/Users/example_user/write_results"
}
}
]
}Déclenchez le travail en utilisant POST /api/2.1/jobs/run-now
curl -n -X POST \
https://$DATABRICKS_HOST/api/2.1/jobs/run-now?job_id=your_job_idSurveillez l'état d'avancement des travaux à l'aide du site GET /api/2.1/jobs/runs/get et du site run_id.
response = requests.get(f"{DATABRICKS_HOST}/api/2.1/jobs/runs/get", headers=headers, params={"run_id": run_id})
print(response.json())Accédez aux journaux de sortie ou aux résultats des tâches en utilisant GET /api/2.1/jobs/runs/get-output.
Pour la journalisation, configurez les journaux de travail pour qu'ils soient écrits dans DBFS ou dans un outil de surveillance tel que Datadog ou Splunk. Incluez également un enregistrement détaillé dans le carnet de notes de chaque tâche pour une meilleure traçabilité.
De même, mettez en place des blocs "try-except" dans les carnets de notes afin d'attraper et d'enregistrer les exceptions. Utilisez l'API Databricks Jobs pour récupérer les journaux des travaux afin de déboguer les échecs. L'exemple ci-dessous illustre la gestion des erreurs dans un bloc-notes.
try:
# Code to fetch data from API
response = requests.get(api_url)
# Process data
except Exception as e:
print(f"An error occurred: {e}")
# Log error and exitVous pouvez également intégrer des notifications par e-mail ou Slack à l'aide de l'API Databricks Alerts ou d'outils tiers.
La mise en œuvre des meilleures pratiques dans les Databricks permet de renforcer considérablement la sécurité, de réduire les coûts et d'améliorer la fiabilité globale du système. Vous trouverez ci-dessous les stratégies clés que vous devez prendre en compte lors de l'utilisation de l'API Databricks et les domaines critiques.
Évitez de stocker des jetons simples dans des codes ou des carnets. Au lieu de cela, utilisez Databricks Secret pour stocker des informations sensibles telles que des clés API ou des informations d'identification en toute sécurité à l'aide de l'API Databricks Secrets. Cela permet de s'assurer que les données sensibles ne sont pas exposées en texte clair dans le code ou les carnets. Utilisez toujours des variables d'environnement pour transmettre des jetons ou des secrets à des scripts, mais veillez à ce que ces variables soient gérées de manière sécurisée et ne soient pas enregistrées dans le système de contrôle des versions.
Utilisez le contrôle d'accès basé sur les rôles (RBAC) pour définir les autorisations au niveau de l'espace de travail, du cluster et du travail et limiter l'accès aux API sensibles aux seuls utilisateurs ou comptes de service nécessaires.
Pour une gestion efficace des coûts, envisagez d'utiliser des grappes à nœud unique pour les tâches continues et à faible charge. Cependant, ils peuvent être rentables s'ils ne sont pas pleinement utilisés. En outre, des grappes d'emplois éphémères sont automatiquement créées et supprimées pour les emplois, ce qui garantit que les ressources ne sont pas inutilisées.
En raison de la tarification dynamique des ressources du cloud, la programmation en dehors des heures de pointe peut réduire considérablement les coûts. Utilisez l'API "Jobs" pour définir des programmes de travail pendant des fenêtres temporelles rentables.
Enfin, surveillez l'utilisation de la grappe en vérifiant régulièrement son taux d'utilisation afin de vous assurer que les ressources ne sont pas gaspillées. Configurez les clusters pour qu'ils s'arrêtent automatiquement après un temps d'inactivité spécifié afin d'éviter les coûts inutiles.
Pour les tests automatisés et les définitions de tâches, utilisez des tests unitaires pour mettre en œuvre des tests unitaires pour la logique des tâches afin de détecter rapidement les erreurs. Surveillez les exécutions de tâches et consignez les mesures de performances pour exploiter l'API des tâches afin de suivre les exécutions de tâches de manière programmatique et d'analyser les données d'exécution historiques :
L'utilisation de l'API REST de Databricks permet aux équipes d'automatiser les flux de travail, d'optimiser les coûts et de s'intégrer de manière transparente aux systèmes externes, transformant ainsi la manière dont les pipelines de données et les analyses sont gérés. Je vous encourage à commencer par tester un appel API de base, tel que la création d'un emploi, afin de vous familiariser avec la plateforme. Vous pouvez également explorer d'autres sujets avancés comme Unity Catalog pour une gouvernance fine ou vous plonger dans des cas d'utilisation de streaming en temps réel.
Je vous recommande également de consulter les documents officiels de l'API REST de Databricks pour répondre aux questions en suspens, et d'explorer les dépôts GitHub sur la CLI Databricks et le SDK Databricks pour Python afin d'en savoir plus sur le développement rationalisé.
Si vous souhaitez explorer les concepts fondamentaux de Databricks, je vous recommande vivement de suivre notre cours Introduction à Databricks. Ce cours vous apprend à connaître Databricks en tant que solution d'entreposage de données pour la Business Intelligence. Je vous recommande également de consulter notre article de blog sur les certifications Databricks en 2024 pour savoir comment obtenir les certifications Databricks, explorer les avantages professionnels et choisir la bonne certification en fonction de vos objectifs de carrière.
Apprenez le cloud avec DataCamp
Cours
Cours
Cours