
Cours
Introduction à Databricks
3 h
40.1K
Databricks est depuis longtemps l'un des favoris de la communauté de l'ingénierie des données, et il étend désormais régulièrement ses capacités aux domaines de l'intelligence artificielle (IA) et de l'apprentissage machine (ML). Cette évolution signifie que vous pouvez désormais former des modèles, faire le cursus des expériences, enregistrer des modèles et les déployer sur des points d'extrémité Databricks, le tout au sein d'une même plateforme unifiée. Cette intégration simplifie les flux de travail et fait de Databricks un outil puissant pour les professionnels des données et de l'IA.
Si vous ne connaissez pas Databricks, vous pouvez suivre le cours Introduction à Databricks pour découvrir la plate-forme Databricks Lakehouse. Ce cours vous aidera à comprendre comment Databricks peut moderniser les architectures de données et améliorer les processus de gestion des données.
Dans ce tutoriel, je vais vous aider à déployer la version distribuée du modèle DeepSeek R1 sur Databricks. DeepSeek R1 a gagné une popularité importante, de nombreuses entreprises choisissant de l'exécuter sur leur propre infrastructure cloud au lieu d'envoyer des données sur des serveurs externes.
Ce guide vous aidera à configurer un compte Databricks, à enregistrer le modèle DeepSeek R1, à le déployer à l'aide de l'interface utilisateur et à y accéder via le terrain de jeu et localement à l'aide de la commande CURL.
Pour en savoir plus sur DeepSeek R1, notamment sur ses caractéristiques, son processus de développement, ses modèles distillés, son prix et sa comparaison avec d'autres modèles d'IA tels que les offres d'OpenAI, consultez le site DeepSeek-R1 : Caractéristiques, comparaison, modèles distillés et plus encore blog.
Il y a deux façons simples d'utiliser Databricks. Vous pouvez vous rendre sur GCP, AWS ou Azure Marketplace et vous abonner au service Databricks. Vous pouvez également vous inscrire à un compte Databricks autonome, qui vous fournit des ressources informatiques sans qu'il soit nécessaire de créer des grappes de calcul.
Je vous présente ici les deux façons de procéder.
Si vous avez déjà accès à un GPU AWS, cette méthode est fortement recommandée. Elle est simple et ne demande pas trop d'efforts.
Mise en place de Databricks sur la place de marché AWS.
Une fois que vous avez terminé, il créera un espace de travail Databricks pour vous avec toutes sortes d'options. Tous les paiements seront effectués par le biais de la facturation AWS.
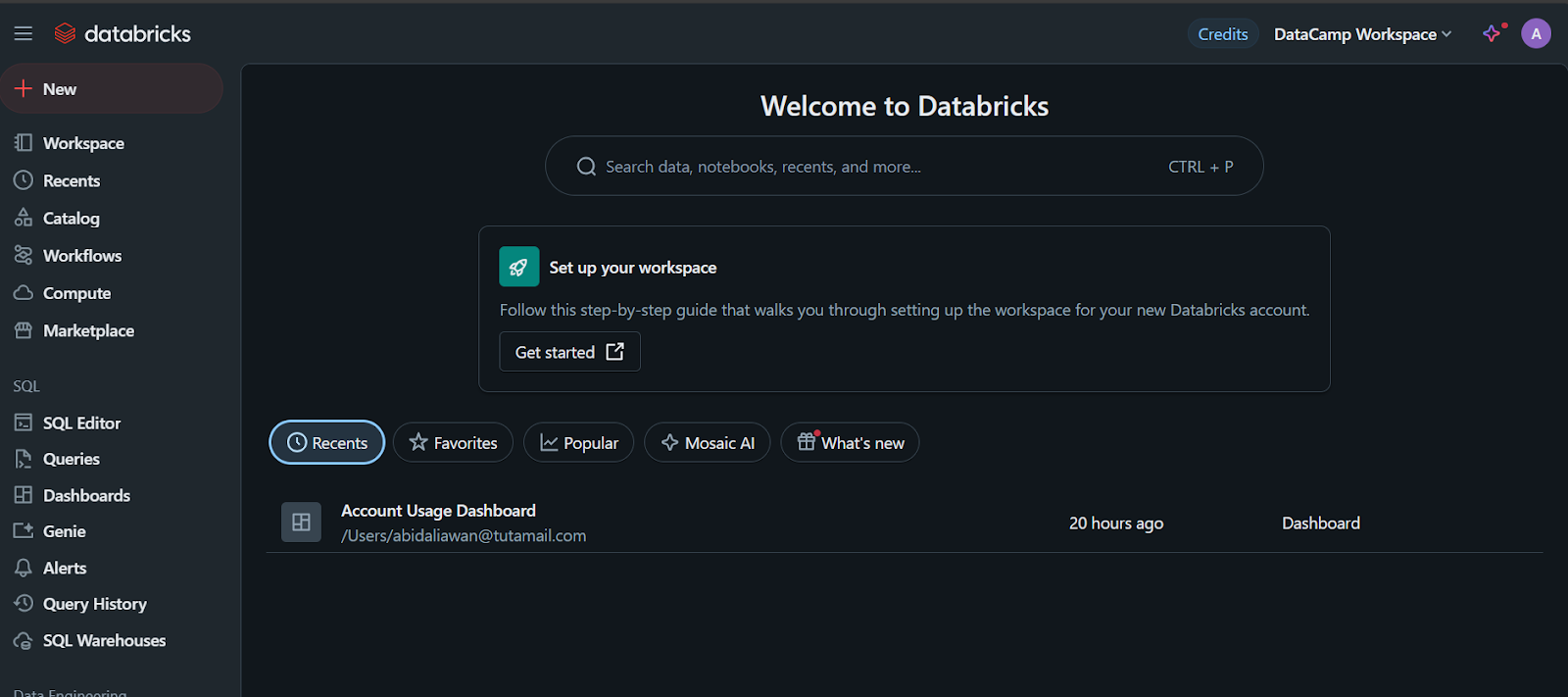
Lorsque vous cliquez sur l'onglet "Compute", vous pouvez créer le cluster de calcul de votre choix.
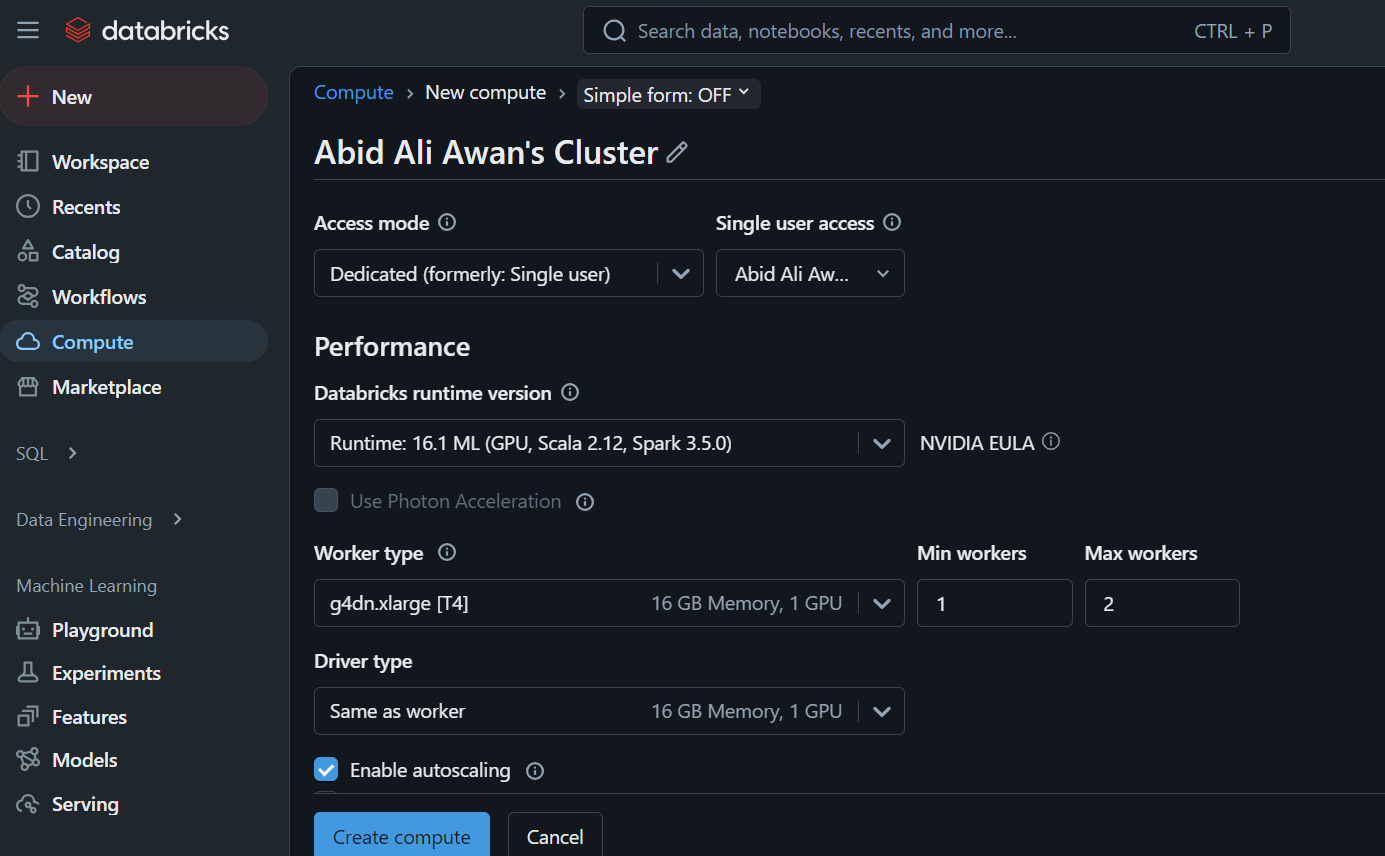
Cette grappe sera utilisée ultérieurement dans un carnet de notes et pour déployer le modèle.
Si vous préférez utiliser la version autonome de Databricks parce que vous n'avez pas accès à un GPU cloud ou pour toute autre raison, suivez ces étapes :
L'espace de travail et tout le reste seront mis en place en quelques secondes.
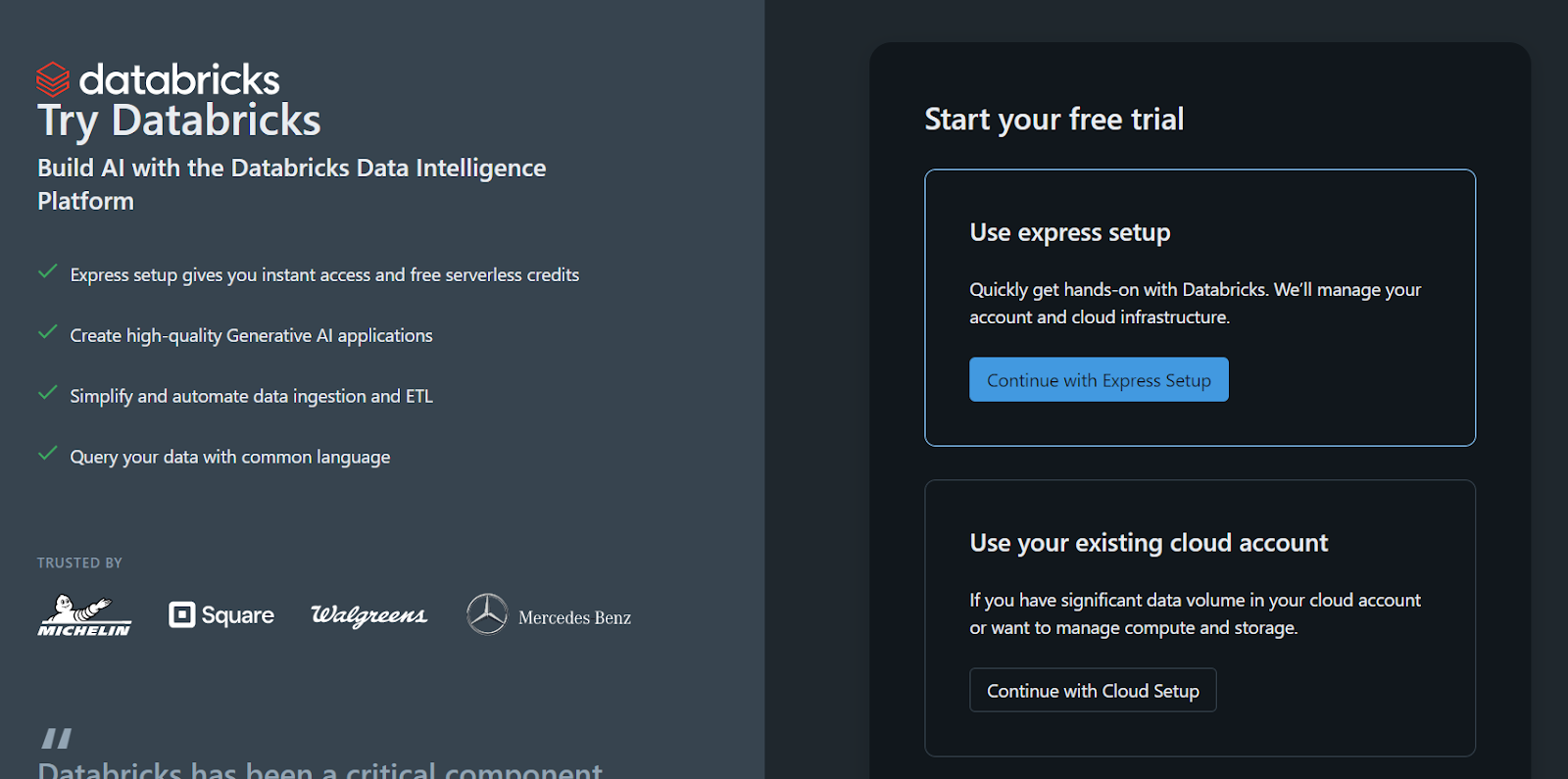
Inscrivez-vous à la version autonome de Databricks.
Veuillez noter qu'il y a un problème: vous ne pouvez pas créer votre propre cluster de calcul ou de GPU en utilisant cette méthode. Vous ne pouvez enregistrer le modèle qu'en utilisant une unité centrale dans un ordinateur portable, ce qui peut constituer un problème que vous souhaiteriez éviter.
Si vous travaillez avec DeepSeekR1 dans un environnement de production ou de recherche, l'utilisation d'un CPU au lieu d'un GPU peut être frustrante en raison du manque de performance, des limitations de mémoire et des coûts potentiels. Pour en savoir plus, consultez l'article de blog CPU vs GPU.
L'étape suivante consiste à enregistrer le modèle.
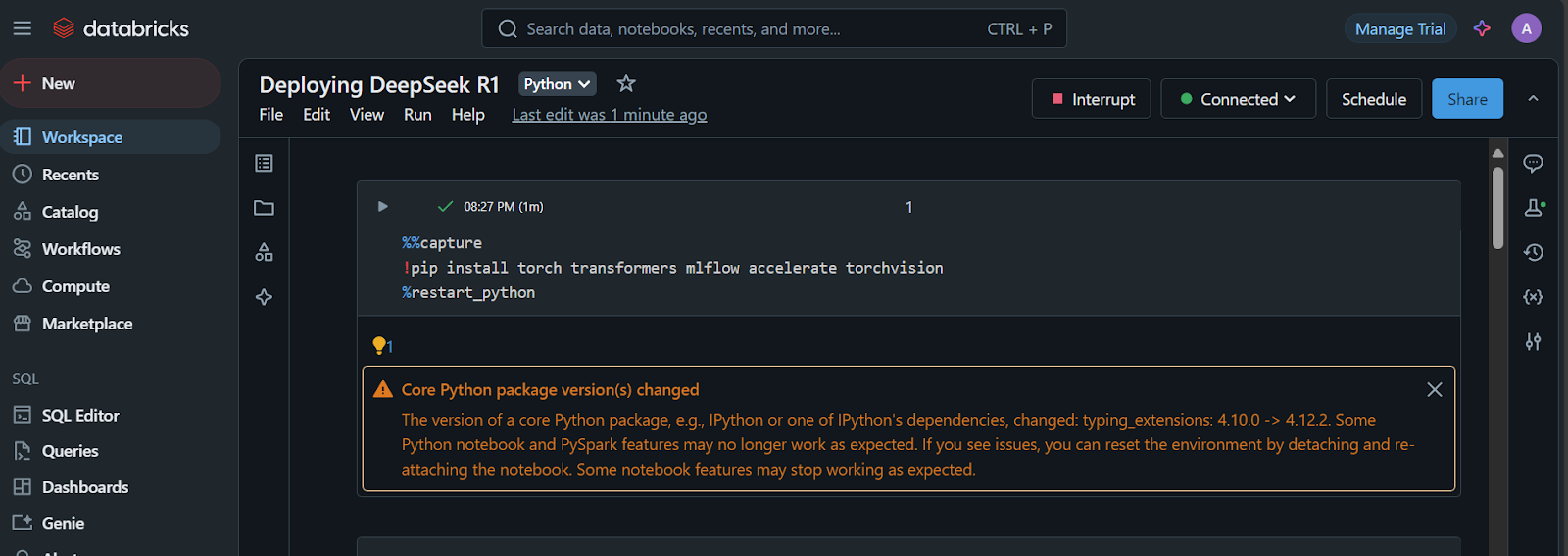
1. Installez les paquets Python requis :
%%capture
!pip install torch transformers mlflow accelerate torchvision
%restart_python2. Chargez les jetons, les configurations et le modèle à partir du référentiel Hugging Face :
import pandas as pd
import mlflow
import mlflow.transformers
import torch
from mlflow.models.signature import infer_signature
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig, pipeline
# Specify the model from HuggingFace transformers
model_name = "deepseek-ai/DeepSeek-R1-Distill-Llama-8B"
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
config=config,
torch_dtype=torch.float16
)
3. Testez le modèle chargé en lui fournissant un exemple d'invite.
Nous créerons également une signature que nous ajouterons lors de l'enregistrement du modèle :
text_generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
example_prompt = "How does a computer work?"
example_inputs = pd.DataFrame({"inputs": [example_prompt]})
example_outputs = text_generator(example_prompt, max_length=200)
signature = infer_signature(example_inputs, example_outputs)
print(example_outputs)Le modèle devrait fonctionner parfaitement !
La sortie qu'il a affichée pour moi est la suivante :
[{'generated_text': "How does a computer work? What is the computer? What is the computer used for? What is the computer used for in real life?\n\nI need to answer this question, but I need to do it step by step. I need to start with the very basic level and build up from there. I need to make sure I understand each concept before moving on. I need to use a lot of examples to explain each idea. I need to write my thoughts as if I'm explaining them to someone else, but I need to make sure I understand how to structure the answer properly.\n\nOkay, let's start with the basic level. What is a computer? It's an electronic device, right? And it has a central processing unit (CPU) that does the processing. But I think the central processing unit is more efficient, so maybe it's the CPU. Then, it has memory and storage. I remember that memory is like RAM and storage is like ROM. But wait, I think"}]4. Configurez l'environnement conda avec la bonne version de Python et les paquets Python requis.
Cela nous aidera à créer le conteneur qui contient tous les outils nécessaires à l'exécution du modèle :
conda_env = {
"name": "mlflow-env",
"channels": ["defaults", "conda-forge"],
"dependencies": [
"python=3.11",
"pip",
{
"pip": [
"mlflow",
"transformers",
"accelerate",
"torch",
"torchvision"
]
}
]
}5. Enregistrer le modèle
Fournissez à la fonction mlflow.transformers.log_model le pipeline de génération de texte, le chemin de l'artefact, la signature, l'exemple d'entrée, le nom du modèle et l'environnement conda:
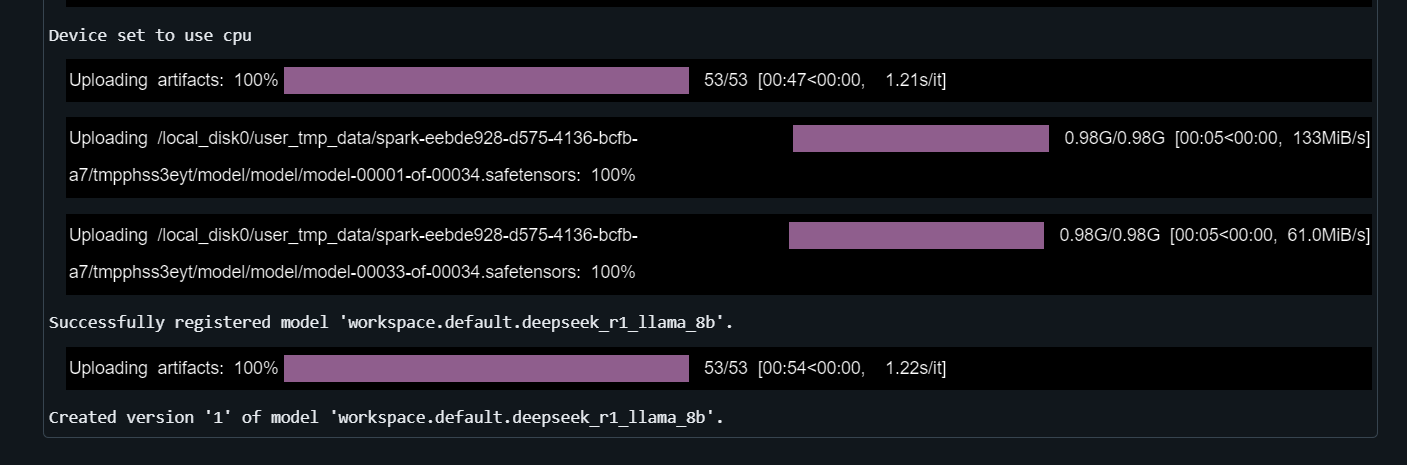
with mlflow.start_run() as run:
mlflow.transformers.log_model(
transformers_model=text_generator,
artifact_path="deepseek_model",
signature=signature,
input_example=example_inputs,
registered_model_name="deepseek_r1_llama_8b",
conda_env=conda_env
)L'enregistrement du modèle prendra quelques minutes.
Découvrez la puissance de Databricks Lakehouse et améliorez vos compétences en ingénierie des données et en apprentissage automatique en suivant le cours Data Management in Databricks.
Il est temps de déployer le modèle !
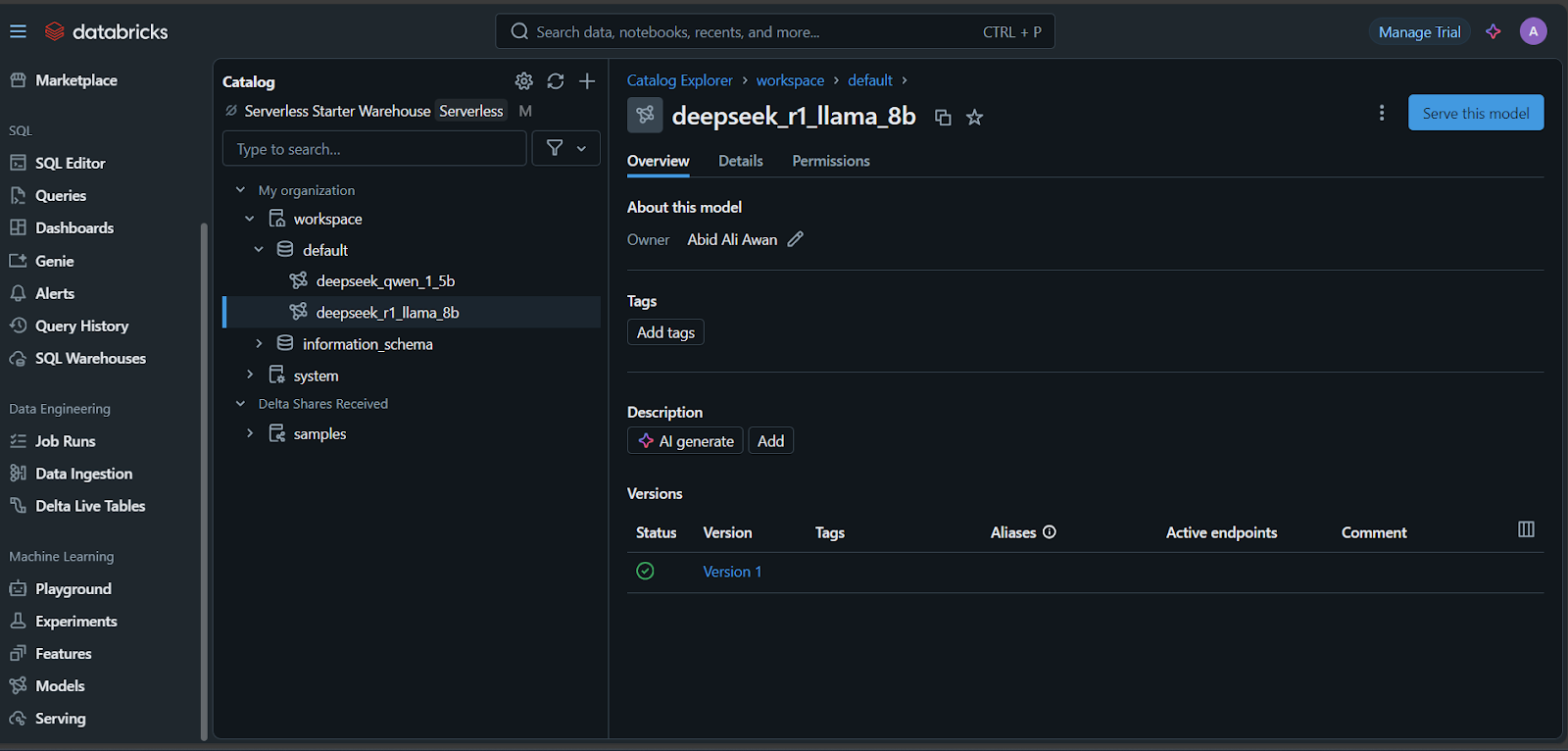
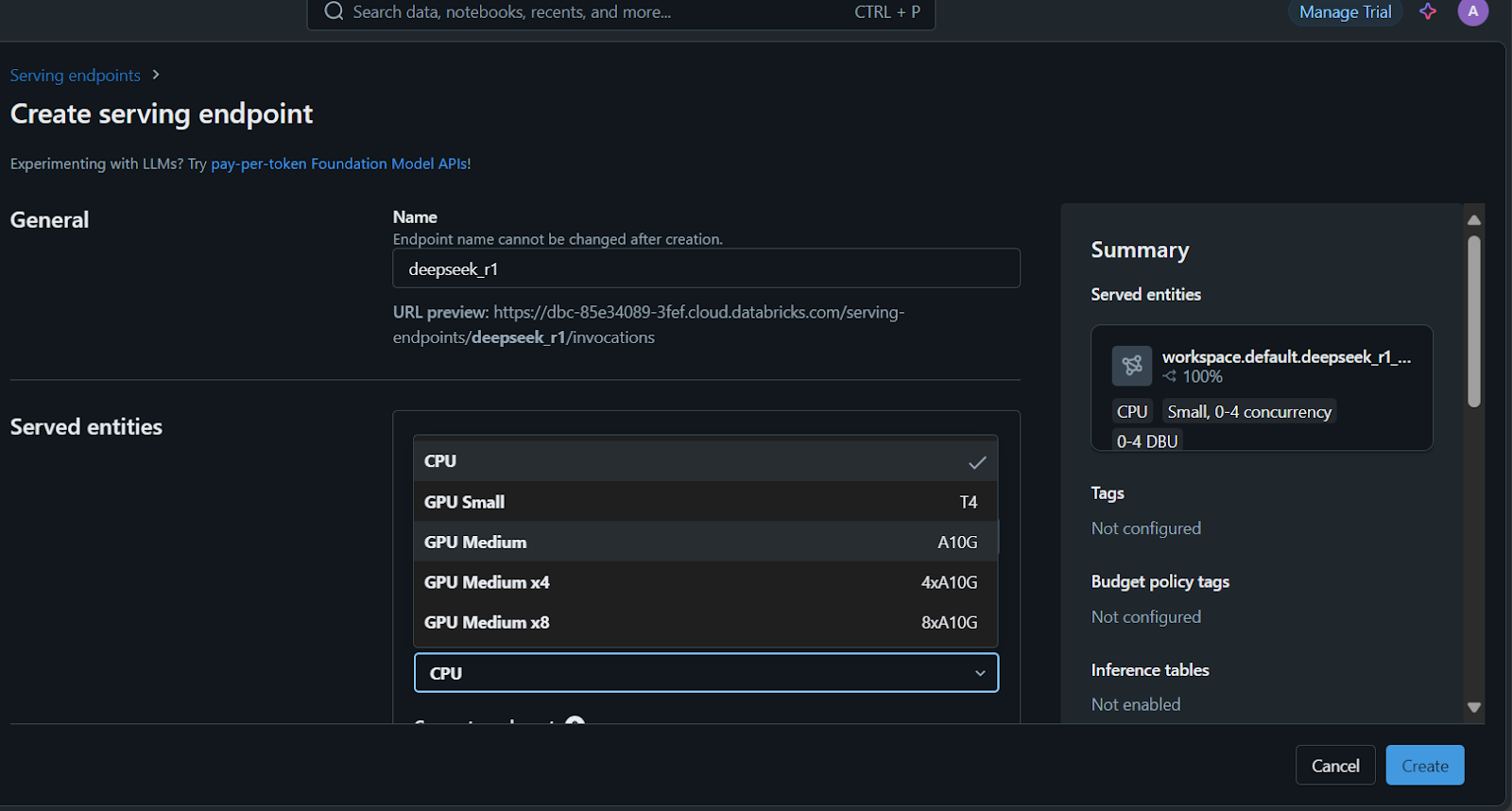
Quelques minutes seront nécessaires pour configurer le point d'accès au service. Une fois la configuration terminée, l'état devient vert et affiche "Ready".
En outre, vous pouvez affiner le DeepSeek R1 sur un ensemble de données personnalisé avant d'enregistrer le modèle. Suivez le tutoriel " Fine-Tuning DeepSeek R1" pour apprendre tout ce que vous devez savoir sur ce processus.
Il existe de nombreuses façons d'accéder à ce modèle ou de l'utiliser.
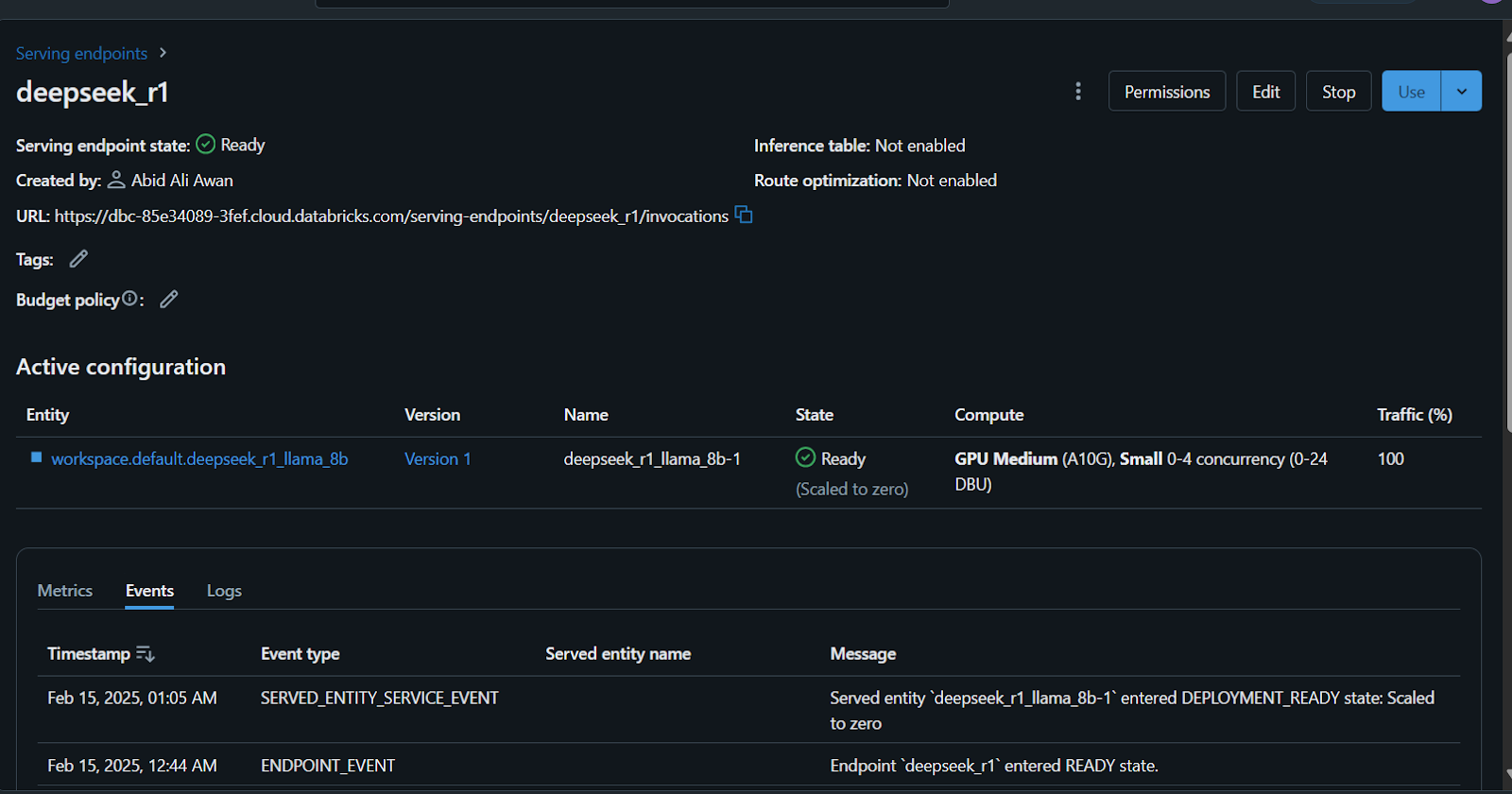
Pour commencer, nous allons rédiger la question à l'aide du navigateur et générer la réponse.
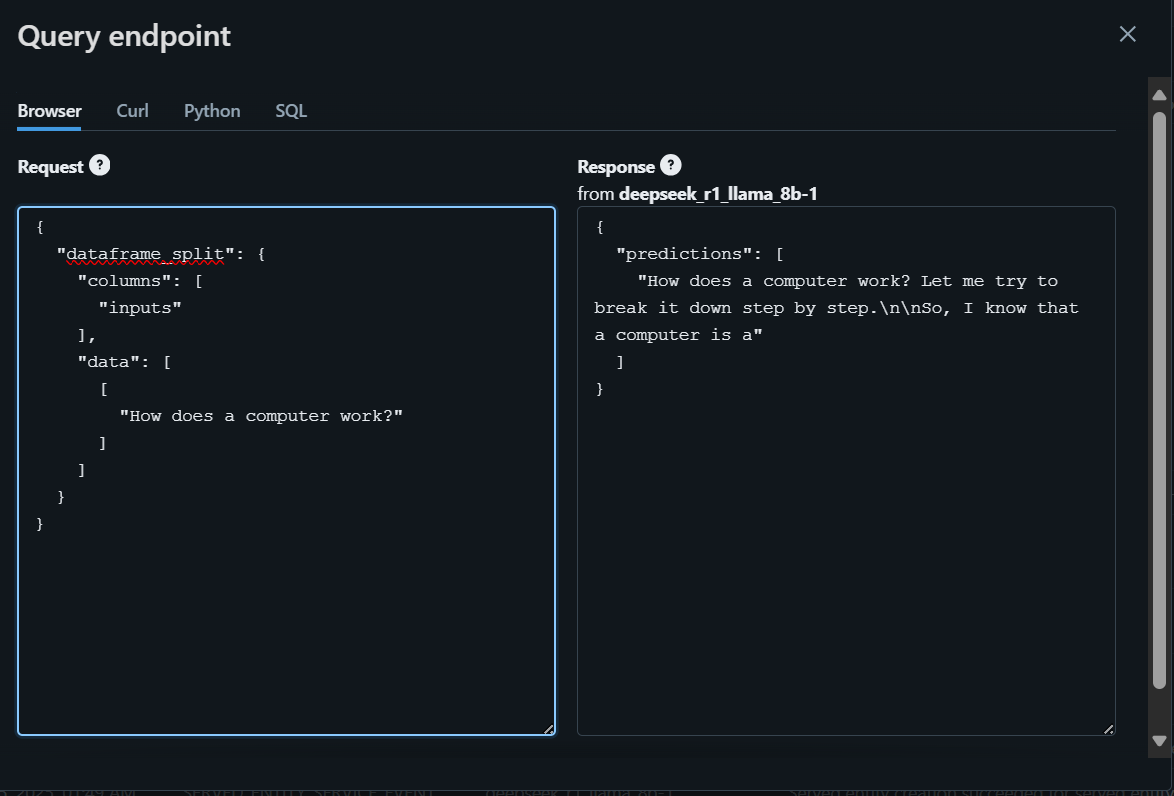
Pour accéder au modèle localement ou l'intégrer dans votre application, vous devez d'abord générer une clé API Databricks.
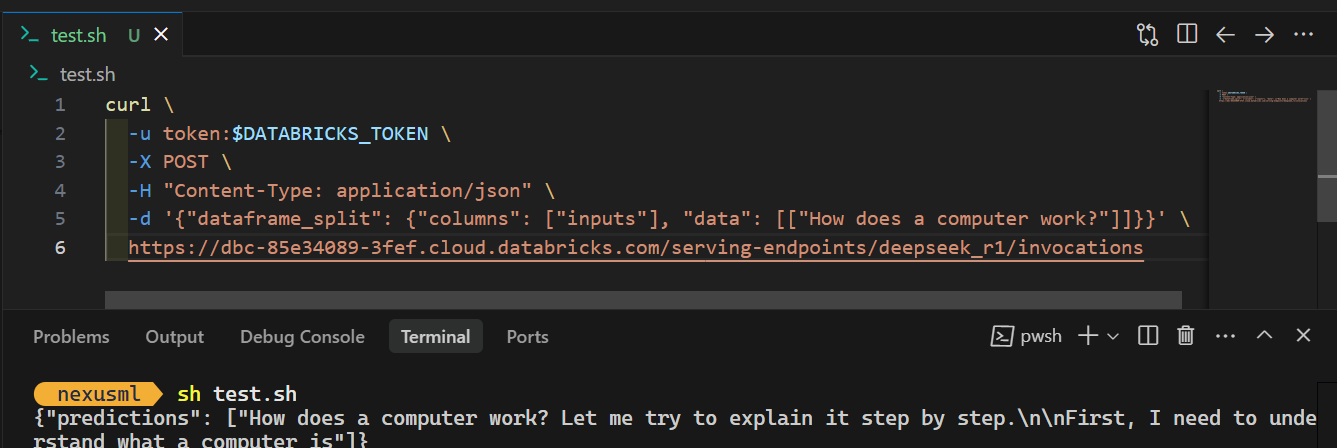
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"dataframe_split": {"columns": ["inputs"], "data": [["How does a computer work?"]]}}' \
https://dbc-85e34089.cloud.databricks.com/serving-endpoints/deepseek_r1/invocationsLorsque vous exécutez la commande, la génération de la réponse prend quelques secondes. C'est aussi simple que cela !
Consultez le blog DeepSeek R1 vs V3 pour en savoir plus sur les meilleurs modèles de langage disponibles chez DeepSeek.
L'enregistrement et le déploiement du modèle DeepSeek R1 sur Databricks sont simples. Vous pouvez même enregistrer et déployer le grand modèle à l'aide d'une grappe de CPU ou d'une machine CPU locale, le tout sans frais. Cependant, l'exécution du modèle sur une unité centrale peut être lente et nécessite de la patience, en particulier lors de la construction de l'image docker.
Dans ce tutoriel, nous avons couvert l'ensemble du processus de déploiement du modèle, étape par étape. Nous avons commencé par configurer Databricks et enregistrer le modèle DeepSeek Distilled R1 pré-entraîné dans le Databricks Model Registry. Ensuite, nous avons utilisé le tableau de bord Databricks pour déployer le modèle. Enfin, nous avons testé le modèle déployé et montré comment l'utiliser localement à l'aide d'une simple commande CURL.
Si vous êtes novice en matière d'IA et de grands modèles de langage, je vous recommande de suivre le cours Introduction aux LLM en Python, je vous recommande de suivre le cours Introduction aux modèles de langage en Python. Cela vous aidera à construire une base solide, à comprendre les terminologies clés et à commencer à travailler sur des modèles avancés comme DeepSeek R1 !
Apprenez-en plus sur Databricks avec ces cours !
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach