
Cours
Introduction aux LLM en Python
3 h
33.6K
DeepSeek a bouleversé le paysage de l'IA, contestant la domination d'OpenAI en lançant une nouvelle série de modèles de raisonnement avancés. Le plus beau ? Ces modèles sont totalement libres d'utilisation, sans aucune restriction, ce qui les rend accessibles à tous.
Dans ce tutoriel, nous allons affiner le modèle DeepSeek-R1-Distill-Llama-8B sur le Medical Chain-of-Thought Dataset de Hugging Face. Ce modèle distillé DeepSeek-R1 a été créé en affinant le modèle Llama 3.1 8B sur les données générées par DeepSeek-R1. Il présente des capacités de raisonnement similaires à celles du modèle original.
Si vous êtes novice en matière de LLM et de mise au point, je vous recommande vivement de suivre le cours d'introduction aux LLM en Python. Introduction aux LLM en Python .

Image par l'auteur
L'entreprise chinoise DeepSeek AI a mis en libre accès ses modèles de raisonnement de première génération, DeepSeek-R1 et DeepSeek-R1-Zero, qui rivalisent avec le modèle o1 d'OpenAI en termes de performances sur des tâches de raisonnement telles que les mathématiques, le codage et la logique. Vous pouvez lire notre guide complet de DeepSeek R1 pour en savoir plus.
DeepSeek-R1-Zero est le premier modèle open-source formé uniquement à l'aide d'outils d'apprentissage par renforcement à grande échelle. apprentissage par renforcement (RL) à grande échelle au lieu d'un réglage fin supervisé (SFT) en tant qu'étape initiale. Cette approche permet au modèle d'explorer de manière indépendante chaîne de pensée (CoT), de résoudre des problèmes complexes et d'affiner ses résultats de manière itérative. Cependant, il comporte des difficultés telles que des étapes de raisonnement répétitives, une mauvaise lisibilité et des mélanges de langues qui peuvent nuire à sa clarté et à sa facilité d'utilisation.
DeepSeek-R1 a été introduit pour surmonter les limites de DeepSeek-R1-Zero en incorporant des données de départ à froid avant l'apprentissage par renforcement, fournissant une base solide pour les tâches de raisonnement et de non-raisonnement.
Cette formation en plusieurs étapes permet au modèle d'atteindre des performances de pointe, comparables à celles d'OpenAI-o1, dans les domaines des mathématiques, du code et du raisonnement, tout en améliorant la lisibilité et la cohérence de ses résultats.
Outre les grands modèles linguistiques dont le fonctionnement nécessite une puissance de calcul et une mémoire considérables, DeepSeek a également introduit des modèles distillés. Ces modèles plus petits et plus efficaces ont démontré qu'ils pouvaient encore atteindre des performances de raisonnement remarquables.
Comprenant de 1,5 à 70 milliards de paramètres, ces modèles conservent de fortes capacités de raisonnement, DeepSeek-R1-Distill-Qwen-32B surpassant OpenAI-o1-mini sur de nombreux points de référence.
Les modèles plus petits héritent des schémas de raisonnement des modèles plus grands, ce qui démontre l'efficacité du processus de distillation.
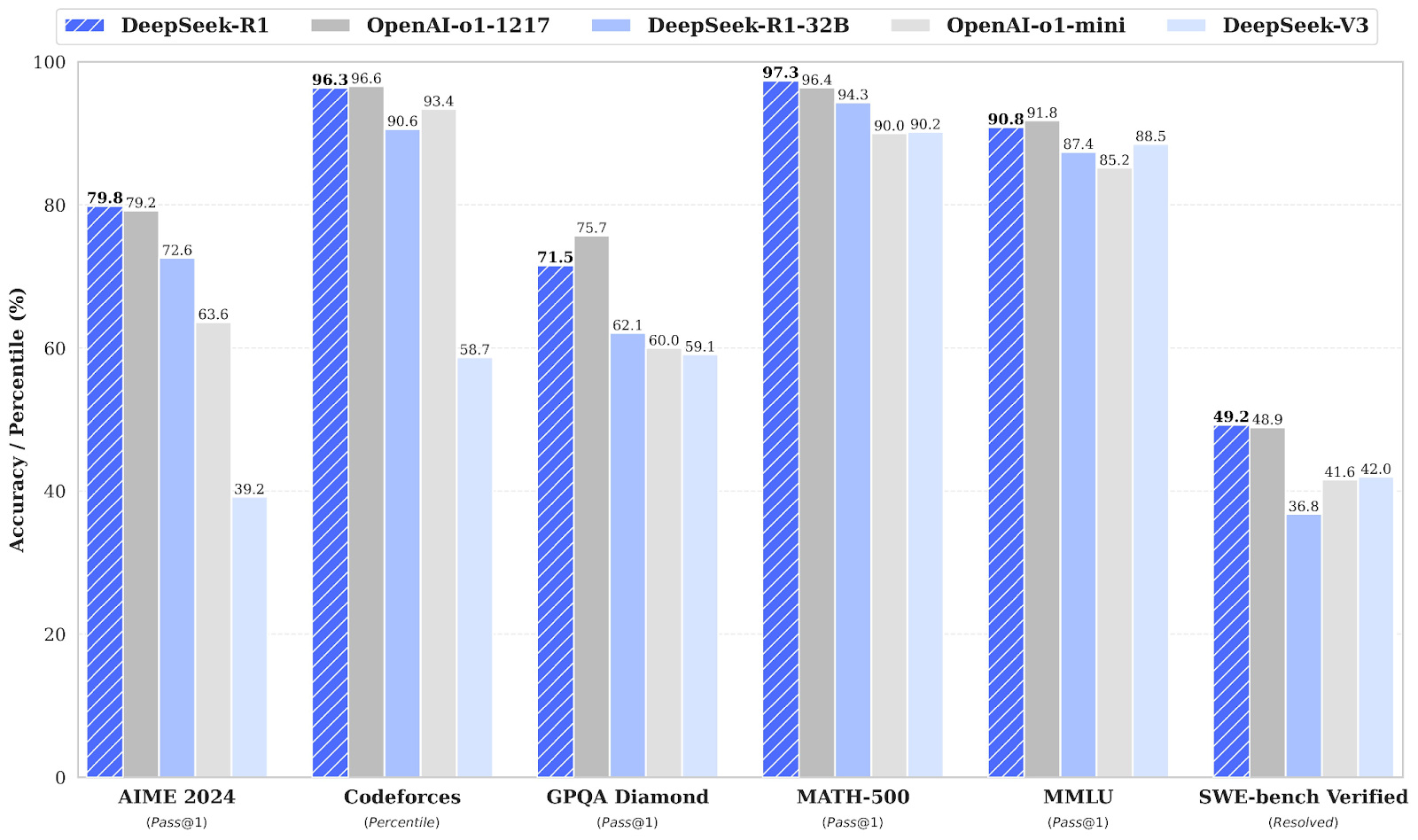
Source : deepseek-ai/DeepSeek-R1
Lisez le site DeepSeek-R1 : Caractéristiques, comparaison avec o1, modèles distillés et plus encore blog pour en savoir plus sur ses principales caractéristiques, son processus de développement, ses modèles distillés, son accès, son prix et sa comparaison avec OpenAI o1.
Pour affiner le modèle DeepSeek R1, vous pouvez suivre les étapes ci-dessous :
Pour ce projet, nous utilisons Kaggle comme IDE Cloud car il offre un accès gratuit aux GPU, qui sont souvent plus puissants que ceux disponibles dans Google Colab. Pour commencer, lancez un nouveau carnet Kaggle et ajoutez votre jeton Hugging Face et votre jeton Poids et biais comme secrets.
Vous pouvez ajouter des secrets en naviguant vers l'onglet Add-ons dans l'interface du carnet Kaggle et en sélectionnant l'option Secrets.
Après avoir configuré les secrets, installez le paquetage Python unsloth. Unsloth est un framework open-source conçu pour rendre le réglage fin des grands modèles de langage (LLM) 2 fois plus rapide et plus efficace en termes de mémoire.
Lisez notre Guide du déshabillage : Optimisez et accélérez la mise au point du LLM pour découvrir les principales caractéristiques d'Unsloth, ses diverses fonctions et la manière d'optimiser votre flux de travail de mise au point.
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.gitConnectez-vous à l'interface de programmation de Hugging Face à l'aide de l'API de Hugging Face que nous avons extraite en toute sécurité de Kaggle Secrets.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Connectez-vous à Weights & Biases (wandb) à l'aide de votre clé API et créez un nouveau projet pour suivre les expériences et les progrès de la mise au point.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)Pour ce projet, nous chargeons la version Unsloth de DeepSeek-R1-Distill-Llama-8B. En outre, nous chargerons le modèle en quantification 4 bits afin d'optimiser l'utilisation de la mémoire et les performances.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
token = hf_token,
)Pour créer un style d'invite pour le modèle, nous définirons une invite système et inclurons des espaces réservés pour la génération de questions et de réponses. Le message guide le modèle pour qu'il réfléchisse étape par étape et fournisse une réponse logique et précise.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""Dans cet exemple, nous fournirons une question médicale au site prompt_style, nous la convertirons en jetons, puis nous transmettrons les jetons au modèle pour la génération de réponses.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])Même sans ajustement, notre modèle a réussi à générer une chaîne de pensée et à fournir un raisonnement avant de fournir la réponse finale. Le processus de raisonnement est encapsulé dans les balises <think></think>.
Alors, pourquoi avons-nous encore besoin d'un réglage fin ? Le processus de raisonnement, bien que détaillé, était long et peu concis. En outre, la réponse finale a été présentée sous forme de points, ce qui s'écarte de la structure et du style de l'ensemble de données que nous voulons affiner.
<think>
Okay, so I have this medical question to answer. Let me try to break it down. The patient is a 61-year-old woman with a history of involuntary urine loss during activities like coughing or sneezing, but she doesn't leak at night. She's had a gynecological exam and a Q-tip test. I need to figure out what cystometry would show regarding her residual volume and detrusor contractions.
First, I should recall what I know about urinary incontinence. Involuntary urine loss during activities like coughing or sneezing makes me think of stress urinary incontinence. Stress incontinence typically happens when the urethral sphincter isn't strong enough to resist increased abdominal pressure from activities like coughing, laughing, or sneezing. This usually affects women, especially after childbirth when the pelvic muscles and ligaments are weakened.
The Q-tip test is a common diagnostic tool for stress urinary incontinence. The test involves inserting a Q-tip catheter, which is a small balloon catheter, into the urethra. The catheter is connected to a pressure gauge. The patient is asked to cough, and the pressure reading is taken. If the pressure is above normal (like above 100 mmHg), it suggests that the urethral sphincter isn't closing properly, which is a sign of stress incontinence.
So, based on the history and the Q-tip test, the diagnosis is likely stress urinary incontinence. Now, moving on to what cystometry would show. Cystometry, also known as a filling cystometry, is a diagnostic procedure where a catheter is inserted into the bladder, and the bladder is filled with a liquid to measure how much it can hold (residual volume) and how it responds to being filled (like during a cough or sneeze). This helps in assessing the capacity and compliance of the bladder.
In a patient with stress incontinence, the bladder's capacity might be normal, but the sphincter's function is impaired. So, during the cystometry, the residual volume might be within normal limits because the bladder isn't overfilled. However, when the patient is asked to cough or perform a Valsalva maneuver, the detrusor muscle (the smooth muscle layer of the bladder) might not contract effectively, leading to an increase in intra-abdominal pressure, which might cause leakage.
Wait, but detrusor contractions are usually associated with voiding. In stress incontinence, the issue isn't with the detrusor contractions but with the sphincter's inability to prevent leakage. So, during cystometry, the detrusor contractions would be normal because they are part of the normal voiding process. However, the problem is that the sphincter doesn't close properly, leading to leakage.
So, putting it all together, the residual volume might be normal, but the detrusor contractions would be normal as well. The key finding would be the impaired sphincter function leading to incontinence, which is typically demonstrated during the Q-tip test and clinical history. Therefore, the cystometry would likely show normal residual volume and normal detrusor contractions, but the underlying issue is the sphincter's inability to prevent leakage.
</think>
Based on the provided information, the cystometry findings in this 61-year-old woman with stress urinary incontinence would likely demonstrate the following:
1. **Residual Volume**: The residual volume would be within normal limits. This is because the bladder's capacity is typically normal in cases of stress incontinence, where the primary issue lies with the sphincter function rather than the bladder's capacity.
2. **Detrusor Contractions**: The detrusor contractions would also be normal. These contractions are part of the normal voiding process and are not impaired in stress urinary incontinence. The issue is not with the detrusor muscle but with the sphincter's inability to prevent leakage.
In summary, the key findings of the cystometry would be normal residual volume and normal detrusor contractions, highlighting the sphincteric defect as the underlying cause of the incontinence.<|end▁of▁sentence|>Nous allons légèrement modifier le style de l'invite pour le traitement de l'ensemble de données en ajoutant le troisième espace réservé pour la colonne de la chaîne de pensée complexe.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Écrivez la fonction Python qui créera une colonne "texte" dans l'ensemble de données, qui se compose du style de l'invite de train. Remplissez les espaces réservés avec des questions, des chaînes de texte et des réponses.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}Nous chargerons les 500 premiers échantillons de la base de données FreedomIntelligence/medical-o1-reasoning-SFT qui est disponible sur le hub Hugging Face. Ensuite, nous mettrons en correspondance la colonne text à l'aide de la fonction formatting_prompts_func.
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT","en", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]Comme vous pouvez le constater, la colonne de texte comporte une invite du système, des instructions, une chaîne de pensée et la réponse.
"Below is an instruction that describes a task, paired with an input that provides further context. \nWrite a response that appropriately completes the request. \nBefore answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.\n\n### Instruction:\nYou are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning. \nPlease answer the following medical question. \n\n### Question:\nA 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?\n\n### Response:\n<think>\nOkay, let's think about this step by step. There's a 61-year-old woman here who's been dealing with involuntary urine leakages whenever she's doing something that ups her abdominal pressure like coughing or sneezing. This sounds a lot like stress urinary incontinence to me. Now, it's interesting that she doesn't have any issues at night; she isn't experiencing leakage while sleeping. This likely means her bladder's ability to hold urine is fine when she isn't under physical stress. Hmm, that's a clue that we're dealing with something related to pressure rather than a bladder muscle problem. \n\nThe fact that she underwent a Q-tip test is intriguing too. This test is usually done to assess urethral mobility. In stress incontinence, a Q-tip might move significantly, showing urethral hypermobility. This kind of movement often means there's a weakness in the support structures that should help keep the urethra closed during increases in abdominal pressure. So, that's aligning well with stress incontinence.\n\nNow, let's think about what would happen during cystometry. Since stress incontinence isn't usually about sudden bladder contractions, I wouldn't expect to see involuntary detrusor contractions during this test. Her bladder isn't spasming or anything; it's more about the support structure failing under stress. Plus, she likely empties her bladder completely because stress incontinence doesn't typically involve incomplete emptying. So, her residual volume should be pretty normal. \n\nAll in all, it seems like if they do a cystometry on her, it will likely show a normal residual volume and no involuntary contractions. Yup, I think that makes sense given her symptoms and the typical presentations of stress urinary incontinence.\n</think>\nCystometry in this case of stress urinary incontinence would most likely reveal a normal post-void residual volume, as stress incontinence typically does not involve issues with bladder emptying. Additionally, since stress urinary incontinence is primarily related to physical exertion and not an overactive bladder, you would not expect to see any involuntary detrusor contractions during the test.<|end▁of▁sentence|>"À l'aide des modules cibles, nous établirons le modèle en y ajoutant l'adoptant de rang inférieur.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)Ensuite, nous mettrons en place les arguments de formation et le formateur en fournissant le modèle, les tokenizers, l'ensemble de données et d'autres paramètres de formation importants qui optimiseront notre processus de réglage fin.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)Exécutez la commande suivante pour démarrer la formation.
trainer_stats = trainer.train()Le processus de formation a duré 44 minutes. La perte d'apprentissage s'est progressivement réduite, ce qui est un bon signe d'amélioration des performances du modèle.
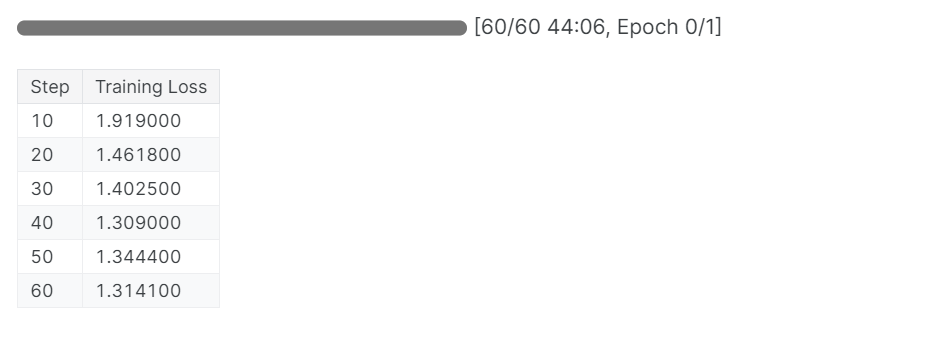
Vous pouvez consulter le rapport d'évaluation du modèle de remplissage sur le tableau de bord des poids et mesures en vous connectant au site web et en consultant le projet.
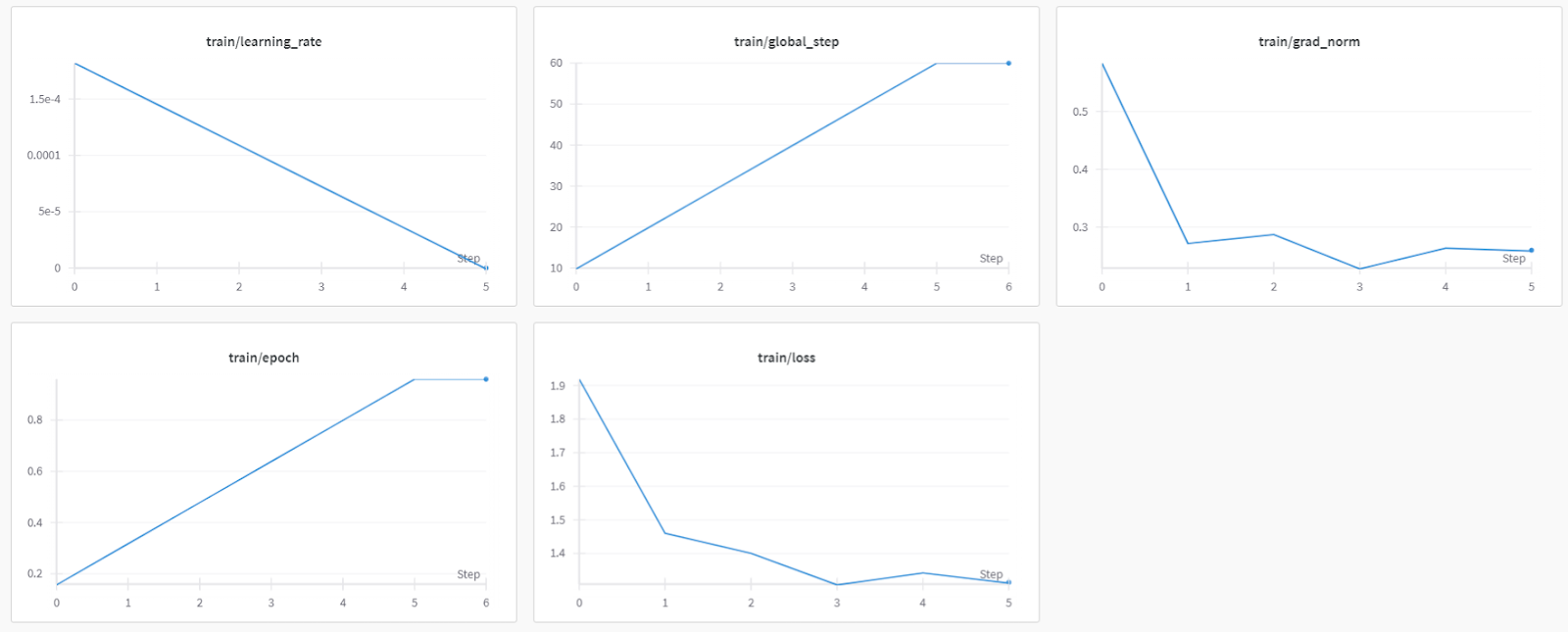
Si vous rencontrez des problèmes lors de l'exécution du code ci-dessus, veuillez vous référer à la section Réglage fin de DeepSeek R1 (Modèle de raisonnement) Carnet Kaggle.
Pour comparer les résultats, nous poserons au modèle affiné la même question que précédemment pour voir ce qui a changé.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
C'est beaucoup mieux et plus précis. La chaîne de pensée était directe et la réponse était simple et tenait en un seul paragraphe. La mise au point a été couronnée de succès.
<think>
Okay, so let's think about this. We have a 61-year-old woman who's been dealing with involuntary urine loss during things like coughing or sneezing, but she's not leaking at night. That suggests she might have some kind of problem with her pelvic floor muscles or maybe her bladder.
Now, she's got a gynecological exam and a Q-tip test. Let's break that down. The Q-tip test is usually used to check for urethral obstruction. If it's positive, that means there's something blocking the urethra, like a urethral stricture or something else.
Given that she's had a positive Q-tip test, it's likely there's a urethral obstruction. That would mean her urethra is narrow, maybe due to a stricture or some kind of narrowing. So, her bladder can't empty properly during activities like coughing because the urethral obstruction is making it hard.
Now, let's think about what happens when her bladder can't empty. If there's a urethral obstruction, the bladder is forced to hold more urine, increasing the residual volume. That's because her bladder doesn't empty completely. So, her residual volume is probably increased.
Also, if her bladder can't empty properly, she might have increased detrusor contractions. These contractions are usually stronger to push the urine out. So, we expect her detrusor contractions to be increased.
Putting it all together, if she has a urethral obstruction and a positive Q-tip test, we'd expect her cystometry results to show increased residual volume and increased detrusor contractions. That makes sense because of the obstruction and how her bladder is trying to compensate by contracting more.
</think>
Based on the findings of the gynecological exam and the positive Q-tip test, it is most likely that the cystometry would reveal increased residual volume and increased detrusor contractions. The positive Q-tip test indicates urethral obstruction, which would force the bladder to retain more urine, thereby increasing the residual volume. Additionally, the obstruction can lead to increased detrusor contractions as the bladder tries to compensate by contracting more to expel the urine.<|end▁of▁sentence|>
Maintenant, sauvegardons localement l'adoptant, le modèle complet et le tokenizer afin de pouvoir les utiliser dans d'autres projets.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)
Nous pousserons également l'adopteur, le tokenizer et le modèle vers Hugging Face Hub afin que la communauté de l'IA puisse tirer parti de ce modèle en l'intégrant dans leurs systèmes.
new_model_online = "kingabzpro/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method = "merged_16bit")
Source : kingabzpro/DeepSeek-R1-Medical-COT - Hugging Face
La prochaine étape de votre parcours d'apprentissage consiste à servir et à déployer votre modèle dans le cloud. Vous pouvez suivre le guide Comment déployer des LLM avec BentoML qui fournit un processus étape par étape pour déployer de grands modèles de langage de manière efficace et rentable à l'aide de BentoML et d'outils tels que vLLM.
Si vous préférez utiliser le modèle localement, vous pouvez le convertir au format GGUF et l'exécuter sur votre machine. Pour cela, consultez la page Améliorer le fonctionnement de Llama 3.2 et l'utiliser localement qui fournit des instructions détaillées pour une utilisation locale.
Les choses évoluent rapidement dans le domaine de l'IA. La communauté des logiciels libres prend aujourd'hui le relais, remettant en cause la domination des modèles propriétaires qui ont régi le paysage de l'IA au cours des trois dernières années.
Les grands modèles de langage (LLM) open-source sont de plus en plus performants, rapides et efficaces. Il est donc plus facile que jamais de les affiner avec des ressources de calcul et de mémoire réduites.
Dans ce tutoriel, nous avons exploré le modèle de raisonnement DeepSeek R1 et appris à affiner sa version distillée pour les tâches de questions-réponses médicales. Un modèle de raisonnement affiné améliore non seulement les performances, mais permet également son application dans des domaines critiques tels que la médecine, les services d'urgence et les soins de santé.
Pour contrer le lancement de DeepSeek R1, OpenAI a introduit deux outils puissants : o3 d'OpenAI, un modèle de raisonnement plus avancé, et l'agent d'IA Operator d'OpenAI, alimenté par le nouveau modèle Computer-Using Agent (CUA), qui peut naviguer de manière autonome sur des sites web et effectuer des tâches.
Les meilleurs cours de DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min