
Curso
Introducción a Databricks
3 h
40.1K
Databricks ha sido durante mucho tiempo un favorito entre la comunidad de ingeniería de datos, y ahora está ampliando constantemente sus capacidades en los ámbitos de la inteligencia artificial (IA) y el aprendizaje automático (AM). Esta evolución significa que ahora puedes entrenar modelos, hacer un seguimiento de los experimentos, registrar modelos y desplegarlos en los puntos finales de Databricks, todo ello dentro de la misma plataforma unificada. Esta integración simplifica los flujos de trabajo y convierte a Databricks en una potente herramienta para los profesionales de los datos y la IA.
Si eres nuevo en Databricks, considera la posibilidad de realizar el curso Introducción a Databricks para conocer la plataforma Databricks Lakehouse. Este curso te ayudará a comprender cómo Databricks puede modernizar las arquitecturas de datos y mejorar los procesos de gestión de datos.
En este tutorial, te guiaré en el despliegue de la versión distribuida del modelo DeepSeek R1 en Databricks. DeepSeek R1 ha ido ganando mucha popularidad, y muchas empresas han optado por ejecutarlo en su propia infraestructura en la nube, en lugar de enviar los datos a servidores externos.
Esta guía te ayudará a configurar una cuenta Databricks, registrar el modelo DeepSeek R1, desplegarlo mediante la interfaz de usuario y acceder a él a través del patio de recreo y localmente mediante el comando CURL.
Para saber más sobre DeepSeek R1, incluidas sus características, proceso de desarrollo, modelos destilados, precio y cómo se compara con otros modelos de IA como las ofertas de OpenAI, consulta DeepSeek-R1: Características, comparación, modelos destilados y más blog.
Hay dos formas sencillas de utilizar Databricks. Puedes ir a GCP, AWS o Azure Marketplace y suscribirte al servicio Databricks. Como alternativa, puedes contratar una cuenta Databricks independiente, que te proporciona algunos recursos informáticos sin necesidad de crear ningún clúster informático.
Aquí expongo las dos formas.
Si ya tienes acceso a una GPU de AWS, este método es muy recomendable. Es sencillo y no requiere demasiadas complicaciones.
Configurar Databricks en el mercado de AWS.
Una vez que hayas terminado, te creará un espacio de trabajo Databricks con todo tipo de opciones. Todos los pagos se realizarán a través de la facturación de AWS.
Cuando hagas clic en la pestaña "Computación", podrás crear el clúster de computación que elijas.
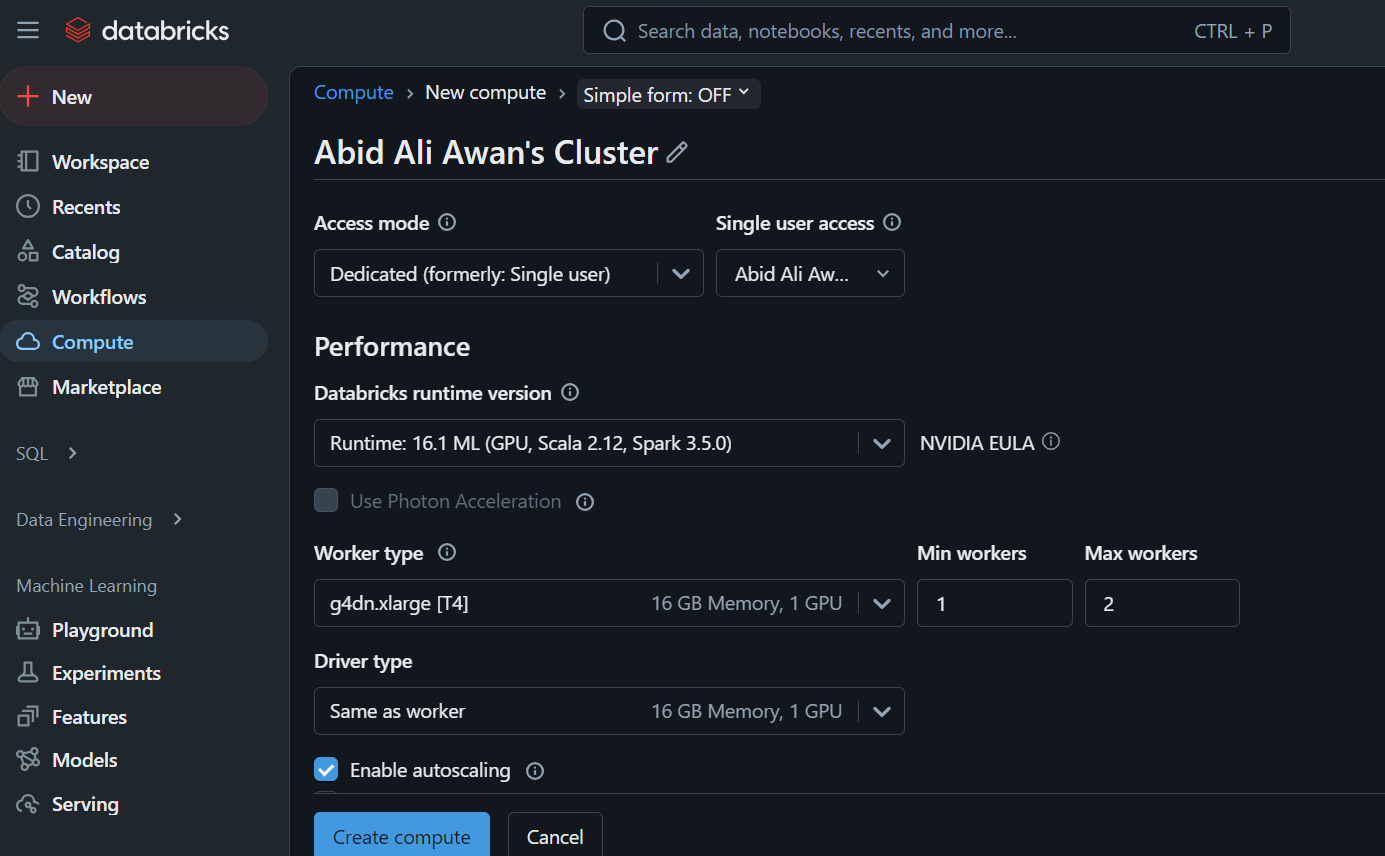
Este clúster se utilizará más adelante en un cuaderno y para desplegar el modelo.
Si prefieres utilizar la versión autónoma de Databricks porque no tienes acceso a una GPU en la nube o por cualquier otra razón, sigue estos pasos:
El espacio de trabajo y todo se configurará para ti en unos segundos.
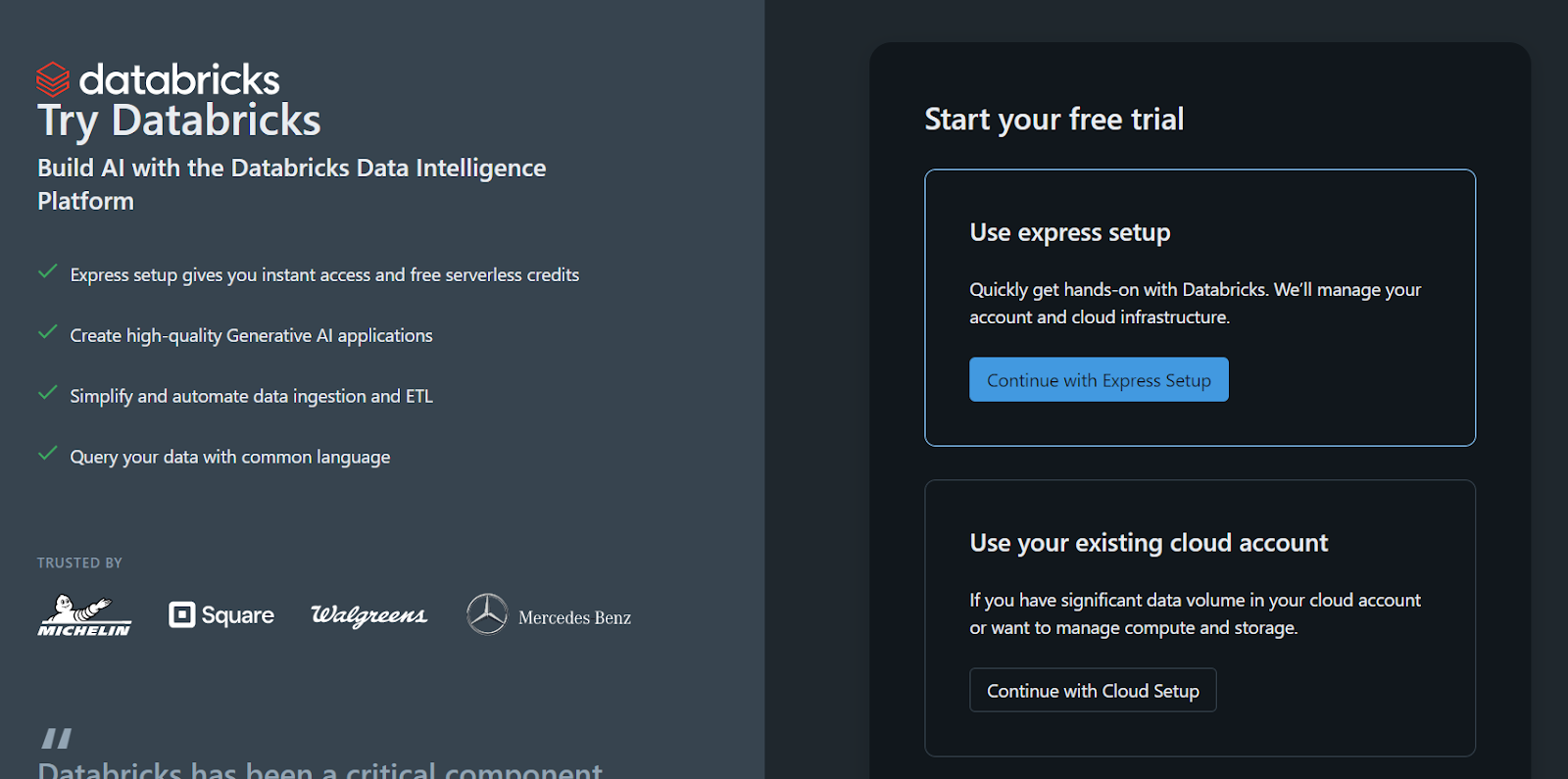
Inscríbete en la versión independiente de Databricks.
Ten en cuenta que hay una trampa: no puedes crear tu propio clúster de cálculo o clúster de GPU utilizando este método. Sólo puedes registrar el modelo utilizando una CPU en un portátil, lo que puede ser una molestia que quizá quieras evitar.
Si trabajas con DeepSeekR1 en un entorno de producción o investigación, utilizar una CPU en lugar de una GPU puede ser frustrante debido a la merma de rendimiento, las limitaciones de memoria y los costes potenciales. Más información en la entrada del blog CPU vs GPU.
El siguiente paso es registrar el modelo.
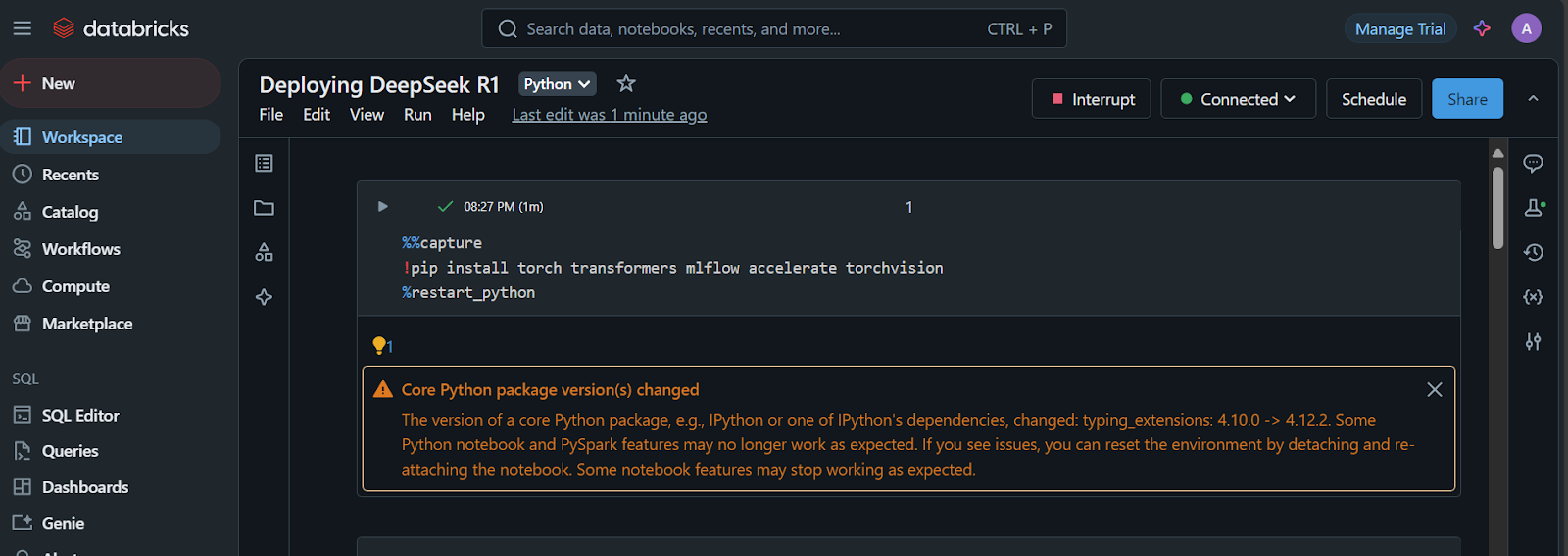
1. Instala los paquetes de Python necesarios:
%%capture
!pip install torch transformers mlflow accelerate torchvision
%restart_python2. Carga los tokens, las configuraciones y el modelo del repositorio Cara Abrazada:
import pandas as pd
import mlflow
import mlflow.transformers
import torch
from mlflow.models.signature import infer_signature
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig, pipeline
# Specify the model from HuggingFace transformers
model_name = "deepseek-ai/DeepSeek-R1-Distill-Llama-8B"
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
config=config,
torch_dtype=torch.float16
)
3. Prueba el modelo cargado proporcionándole un ejemplo de consulta.
También crearemos una firma que añadiremos durante el registro del modelo:
text_generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
example_prompt = "How does a computer work?"
example_inputs = pd.DataFrame({"inputs": [example_prompt]})
example_outputs = text_generator(example_prompt, max_length=200)
signature = infer_signature(example_inputs, example_outputs)
print(example_outputs)¡El modelo debería funcionar perfectamente!
El resultado que me ha mostrado es:
[{'generated_text': "How does a computer work? What is the computer? What is the computer used for? What is the computer used for in real life?\n\nI need to answer this question, but I need to do it step by step. I need to start with the very basic level and build up from there. I need to make sure I understand each concept before moving on. I need to use a lot of examples to explain each idea. I need to write my thoughts as if I'm explaining them to someone else, but I need to make sure I understand how to structure the answer properly.\n\nOkay, let's start with the basic level. What is a computer? It's an electronic device, right? And it has a central processing unit (CPU) that does the processing. But I think the central processing unit is more efficient, so maybe it's the CPU. Then, it has memory and storage. I remember that memory is like RAM and storage is like ROM. But wait, I think"}]4. Configura el entorno conda con la versión correcta de Python y los paquetes de Python necesarios.
Esto nos ayudará a crear el contenedor que tiene todas las herramientas necesarias para ejecutar el modelo:
conda_env = {
"name": "mlflow-env",
"channels": ["defaults", "conda-forge"],
"dependencies": [
"python=3.11",
"pip",
{
"pip": [
"mlflow",
"transformers",
"accelerate",
"torch",
"torchvision"
]
}
]
}5. Registra el modelo
Proporciona a la función mlflow.transformers.log_model el canal de generación de texto, la ruta del artefacto, la firma, la entrada de ejemplo, el nombre del modelo y el entorno conda:
with mlflow.start_run() as run:
mlflow.transformers.log_model(
transformers_model=text_generator,
artifact_path="deepseek_model",
signature=signature,
input_example=example_inputs,
registered_model_name="deepseek_r1_llama_8b",
conda_env=conda_env
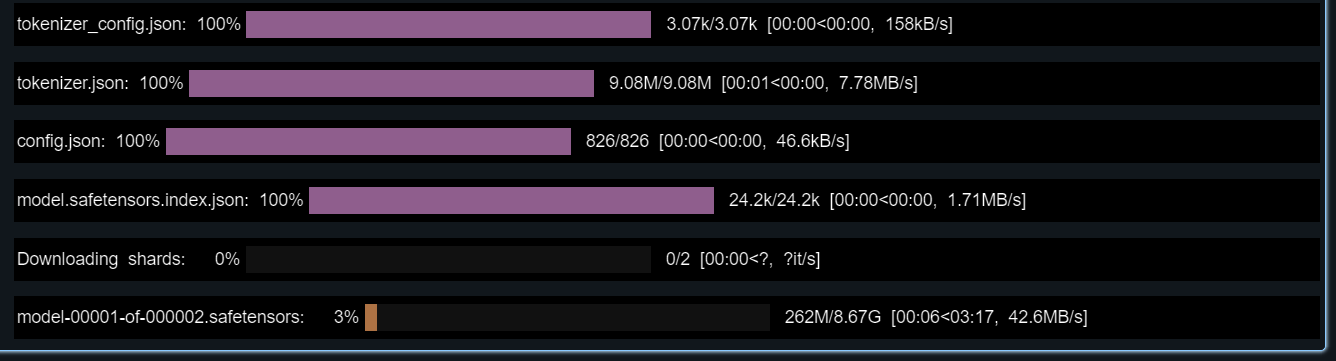
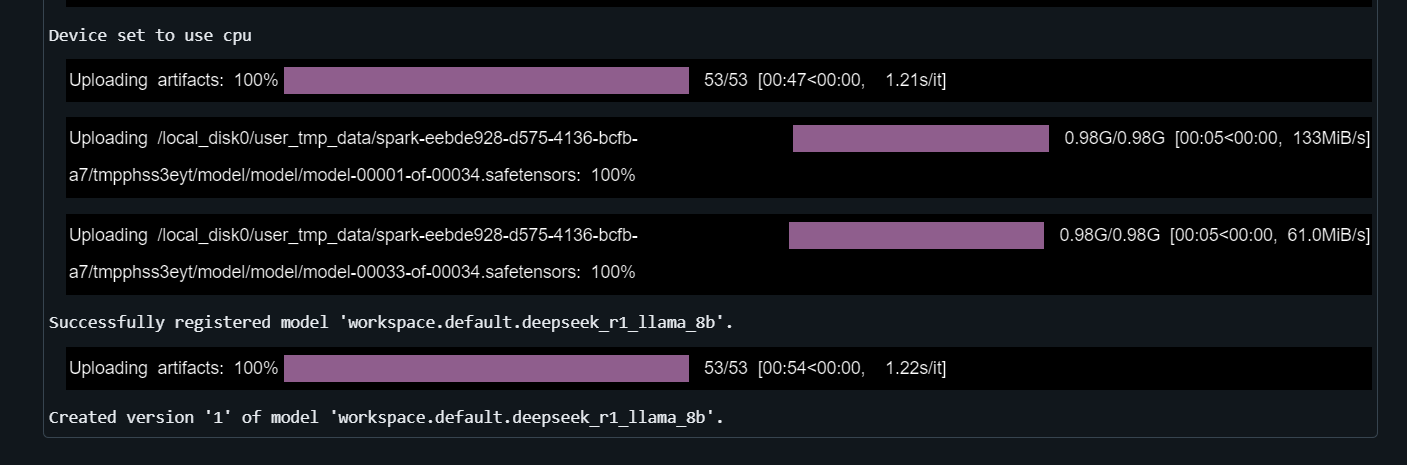
)El registro del modelo tardará unos minutos.
Conoce la potencia de Databricks Lakehouse y mejora tus conocimientos de ingeniería de datos y aprendizaje automático realizando el curso Gestión de datos en Databricks.
¡Es hora de desplegar el modelo!
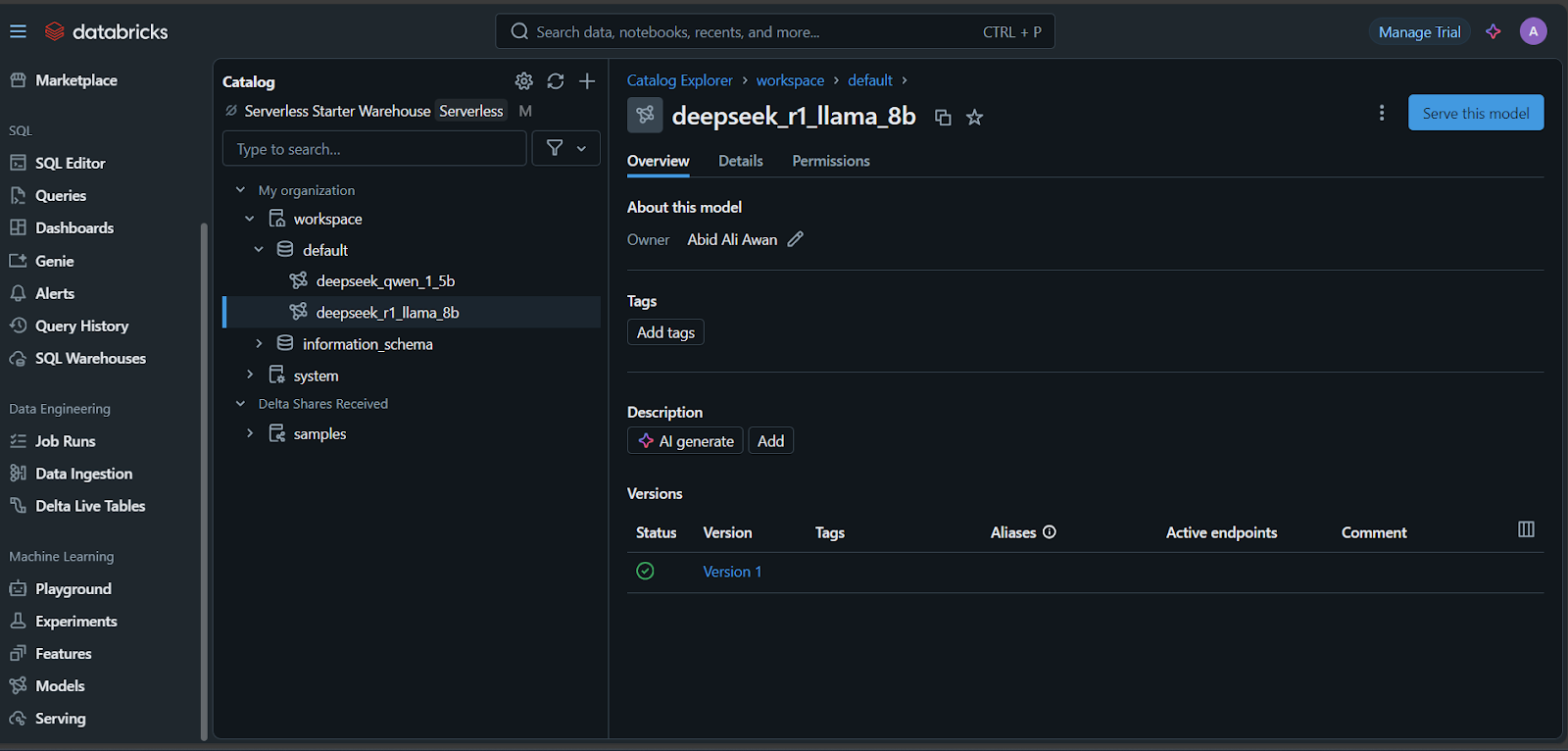
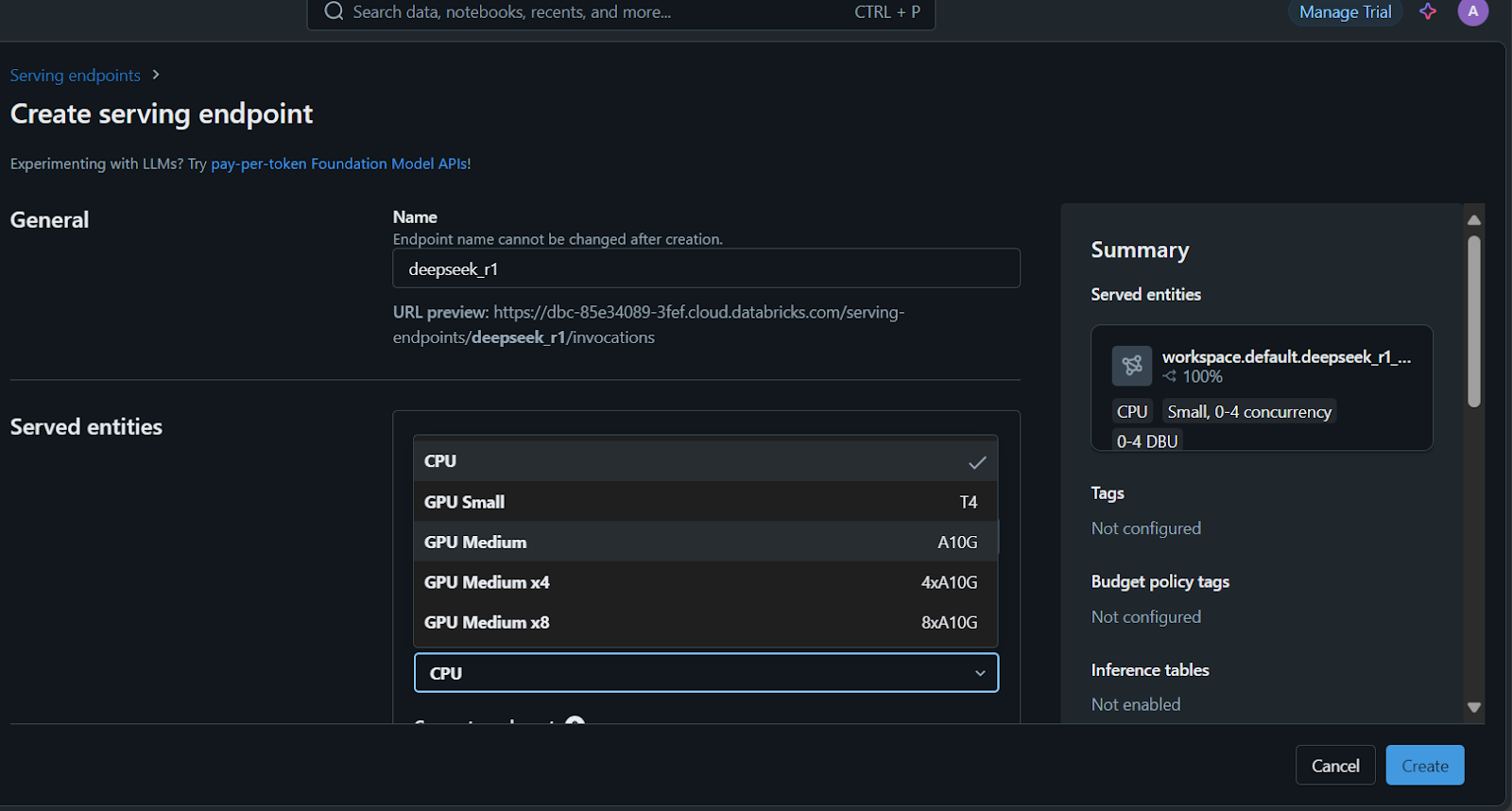
Tardarás unos minutos en configurar el punto final de servicio. El estado se volverá verde una vez completada la configuración y mostrará "Listo".
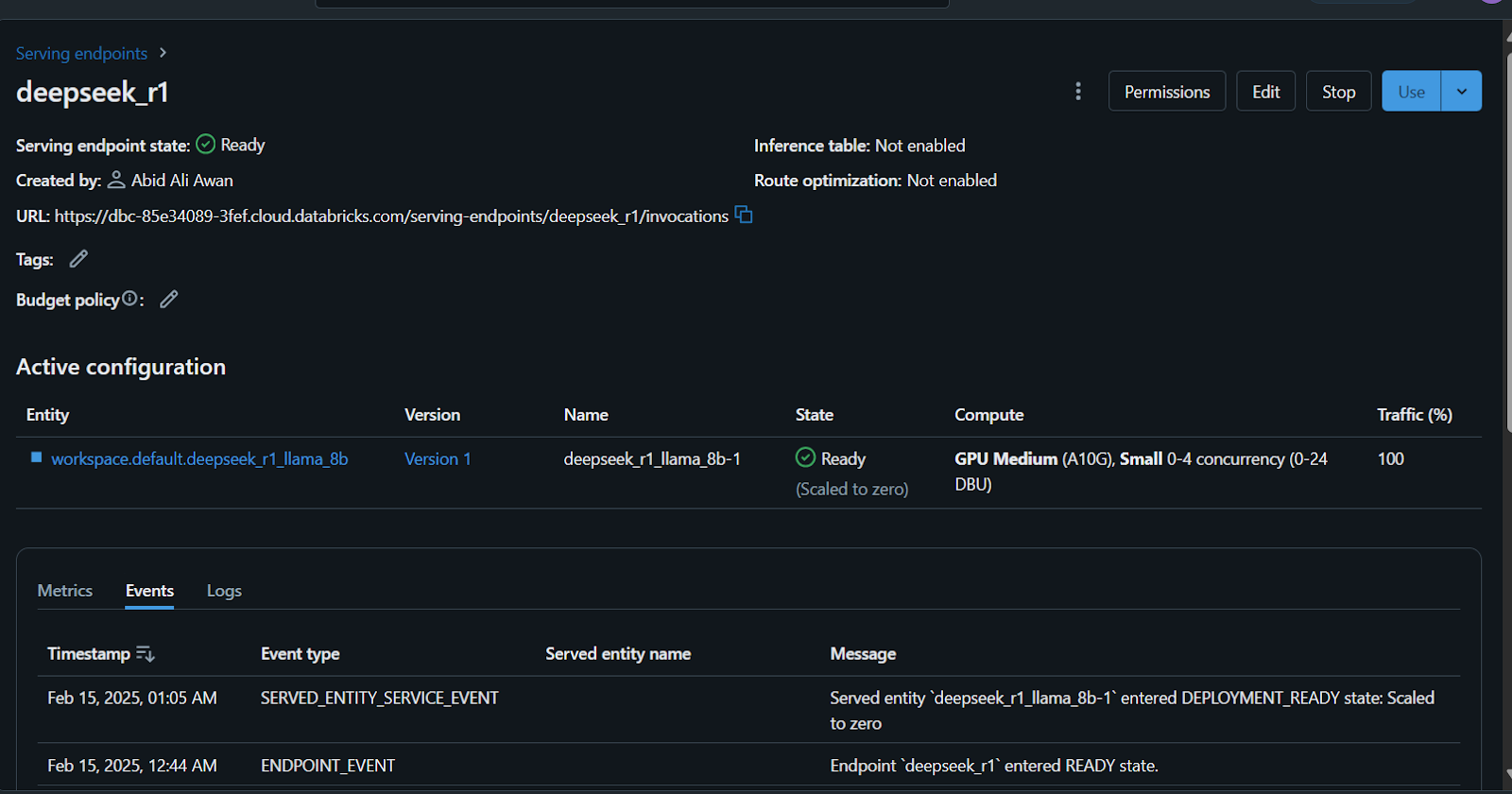
Además, puedes afinar el DeepSeek R1 en un conjunto de datos personalizado antes de registrar el modelo. Sigue el tutorial Ajuste fino de DeepSeek R1 para aprender todo lo que necesitas saber sobre este proceso.
Hay muchas formas de acceder o utilizar este modelo.
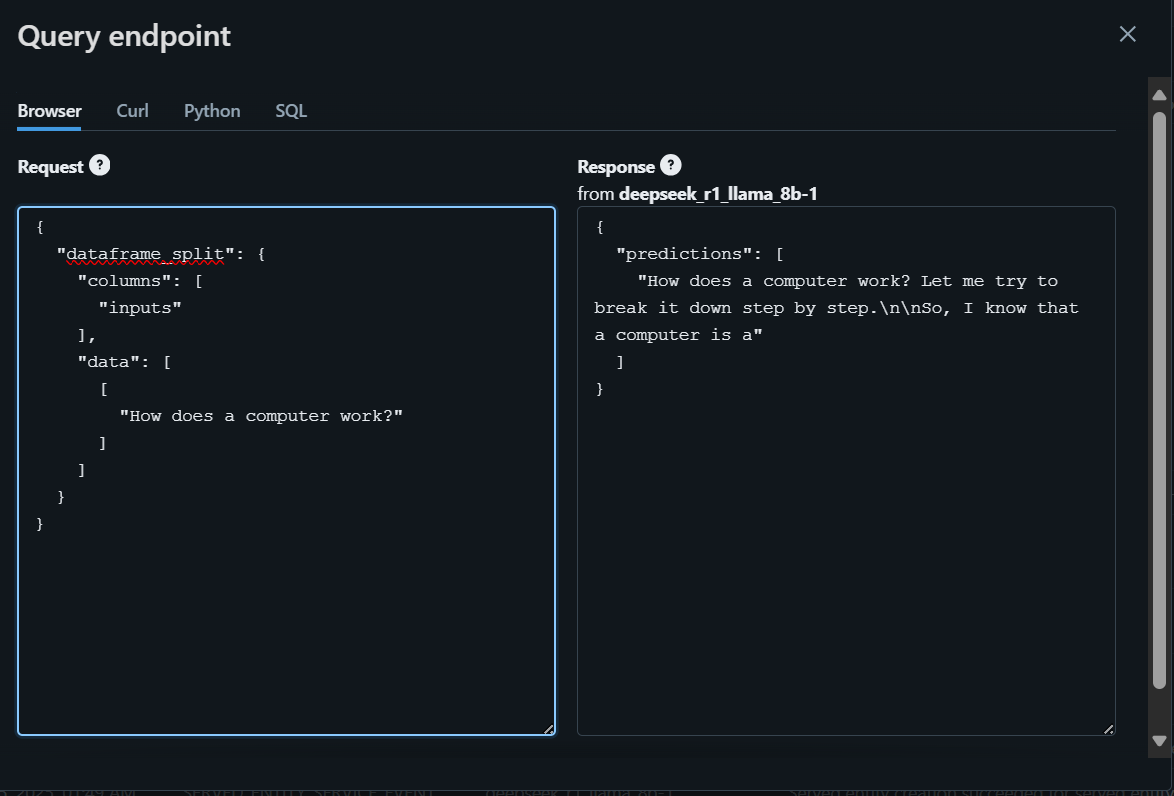
Para empezar, escribiremos la pregunta utilizando el navegador y generaremos la respuesta.
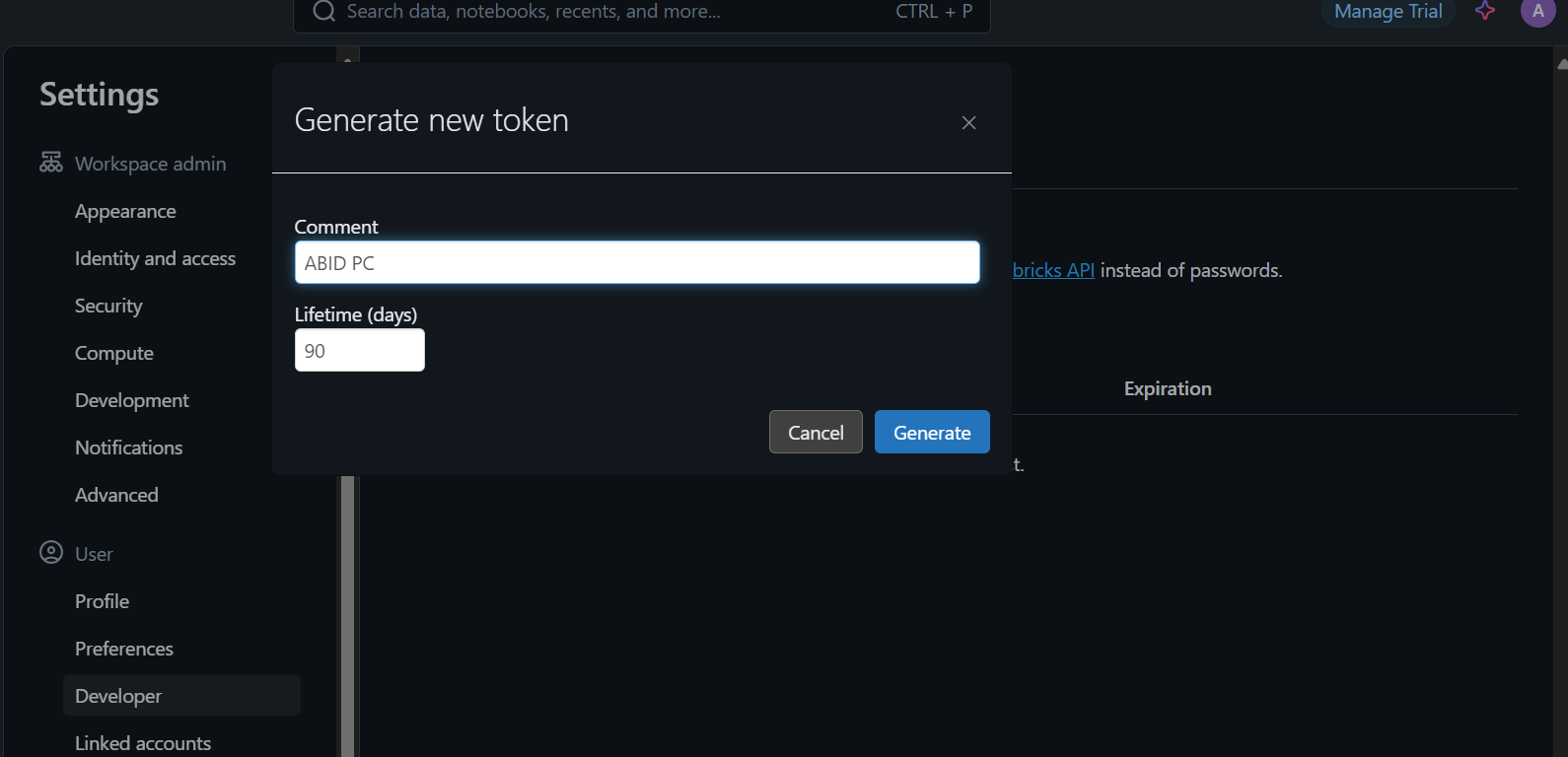
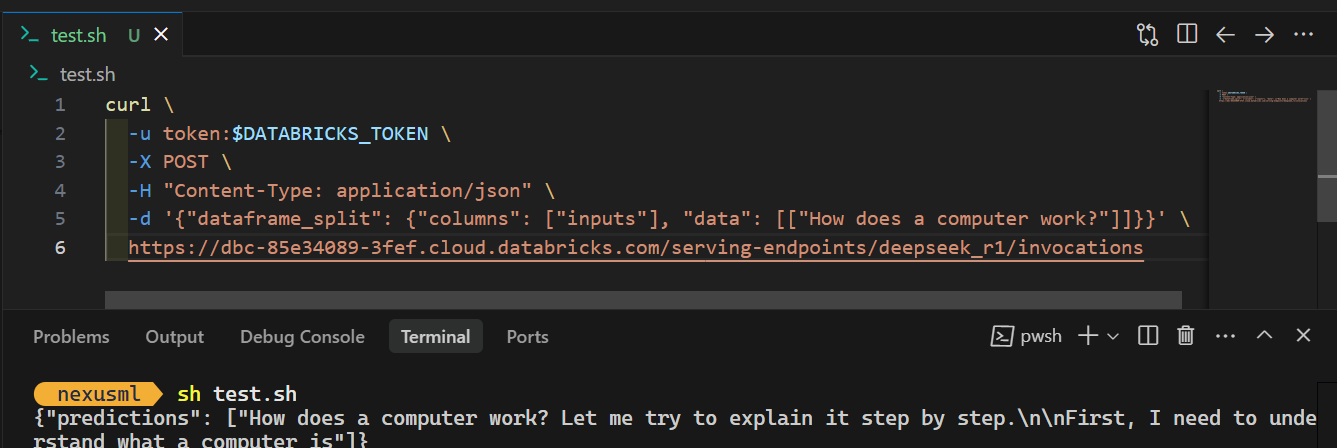
Para acceder al modelo localmente o integrarlo en tu aplicación, primero tienes que generar una clave API Databricks.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"dataframe_split": {"columns": ["inputs"], "data": [["How does a computer work?"]]}}' \
https://dbc-85e34089.cloud.databricks.com/serving-endpoints/deepseek_r1/invocationsCuando ejecutes el comando, la generación de la respuesta tardará unos segundos. ¡Así de sencillo!
Consulta el blog DeepSeek R1 vs V3 para conocer los mejores modelos lingüísticos de gran tamaño disponibles en DeepSeek.
Registrar e implantar el modelo DeepSeek R1 en Databricks es muy sencillo. Incluso puedes registrar y desplegar el modelo grande utilizando un clúster de CPU o una máquina CPU local, todo ello sin incurrir en ningún coste. Sin embargo, ejecutar el modelo en una CPU puede ser lento y requiere paciencia, especialmente cuando se construye la imagen docker.
En este tutorial, cubrimos paso a paso todo el proceso de despliegue del modelo. Empezamos configurando Databricks y registrando el modelo preentrenado DeepSeek Distilled R1 en el Registro de Modelos de Databricks. A continuación, utilizamos el panel de control de Databricks para desplegar el modelo. Por último, probamos el modelo desplegado y demostramos cómo utilizarlo localmente con un simple comando CURL.
Si eres nuevo en la IA y los grandes modelos lingüísticos, te recomiendo que sigas el curso Introducción a los LLM en Python. Esto te ayudará a construir una base sólida, comprender terminologías clave y empezar a trabajar con modelos avanzados como DeepSeek R1.
¡Aprende más sobre Databricks con estos cursos!
Curso
Curso
Curso
blog
Gus Frazer
14 min
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Natassha Selvaraj