
Kurs
Einführung in Databricks
3 Std.
40.2K
Databricks ist seit langem ein Favorit in der Data-Engineering-Community und erweitert seine Fähigkeiten nun stetig in den Bereich der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML). Diese Entwicklung bedeutet, dass du jetzt Modelle trainieren, Lernpfade verfolgen, Modelle registrieren und sie an Databricks-Endpunkten einsetzen kannst - und das alles innerhalb derselben einheitlichen Plattform. Diese Integration vereinfacht Arbeitsabläufe und macht Databricks zu einem leistungsstarken Werkzeug für Daten- und KI-Experten.
Wenn du neu bei Databricks bist, solltest du den Kurs Einführung in Databricks besuchen, um mehr über die Databricks Lakehouse-Plattform zu erfahren. Dieser Kurs hilft dir zu verstehen, wie Databricks Datenarchitekturen modernisieren und Datenmanagementprozesse verbessern kann.
In diesem Tutorial zeige ich dir, wie du die verteilte Version des DeepSeek R1-Modells auf Databricks einsetzt. DeepSeek R1 erfreut sich zunehmender Beliebtheit. Viele Unternehmen entscheiden sich dafür, es auf ihrer eigenen Cloud-Infrastruktur zu betreiben, anstatt Daten an externe Server zu senden.
Diese Anleitung hilft dir dabei, ein Databricks-Konto einzurichten, das DeepSeek R1-Modell zu registrieren, es über die Benutzeroberfläche einzusetzen und über die Spielwiese und lokal mit dem CURL-Befehl darauf zuzugreifen.
Um mehr über DeepSeek R1 zu erfahren, einschließlich der Funktionen, des Entwicklungsprozesses, der destillierten Modelle, der Preise und wie es im Vergleich zu anderen KI-Modellen wie den Angeboten von OpenAI abschneidet, besuche die Website DeepSeek-R1: Eigenschaften, Vergleich, destillierte Modelle & mehr blog.
Es gibt zwei einfache Möglichkeiten, Databricks zu nutzen. Du kannst entweder zu GCP, AWS oder dem Azure Marketplace gehen und den Databricks-Dienst abonnieren. Alternativ kannst du dich für ein eigenständiges Databricks-Konto anmelden, das dir einige Rechenressourcen zur Verfügung stellt, ohne dass du ein Rechencluster erstellen musst.
Hier beschreibe ich die beiden Möglichkeiten.
Wenn du bereits Zugang zu einer AWS GPU hast, ist diese Methode sehr empfehlenswert. Es ist einfach und erfordert nicht allzu viel Aufwand.
Einrichten von Databricks auf dem AWS-Marktplatz.
Sobald du damit fertig bist, wird ein Databricks-Arbeitsbereich mit allen möglichen Optionen für dich erstellt. Alle Zahlungen werden über die AWS-Abrechnung abgewickelt.
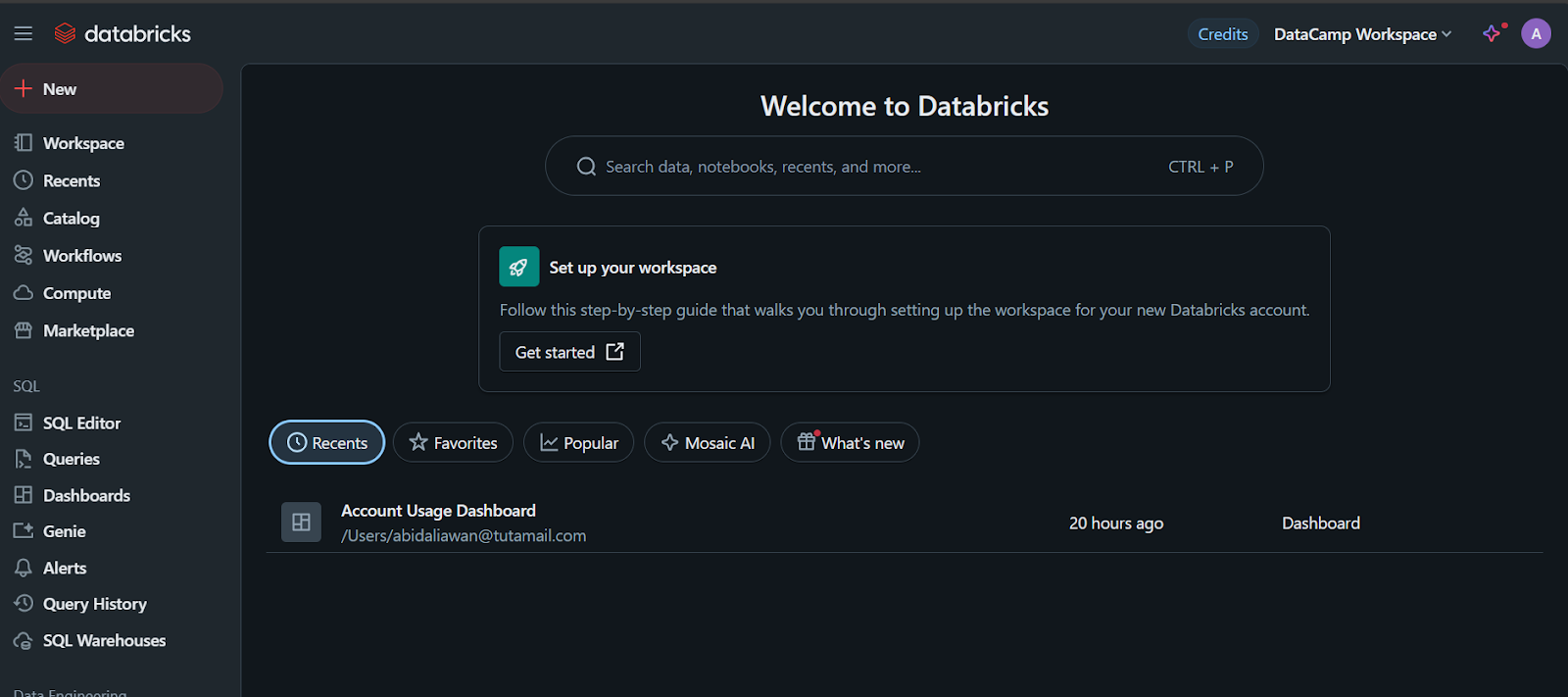
Wenn du auf den Reiter "Compute" klickst, kannst du den Compute-Cluster deiner Wahl erstellen.
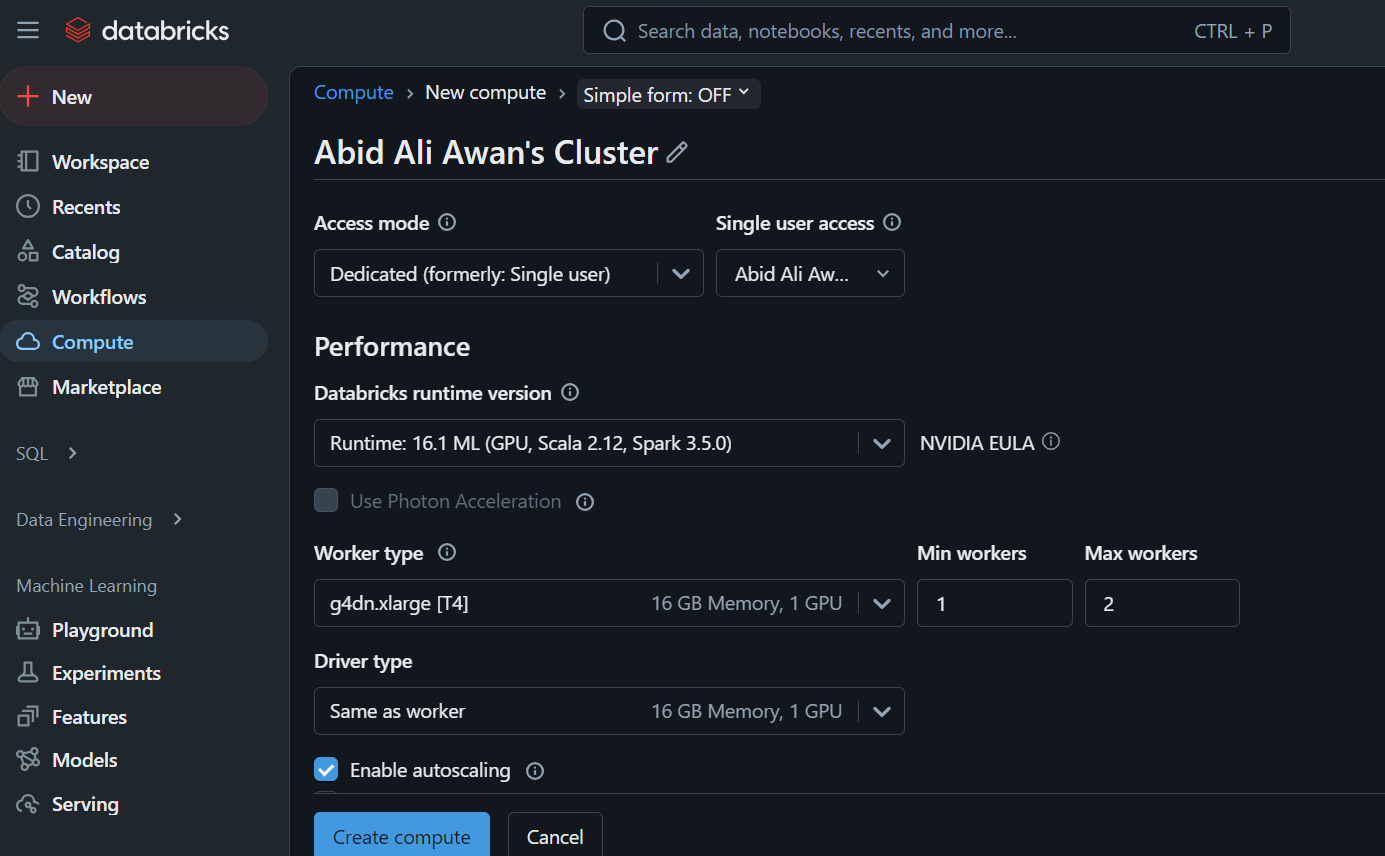
Dieser Cluster wird später in einem Notebook und zum Einsatz des Modells verwendet.
Wenn du lieber die Einzelplatzversion von Databricks verwendest, weil du keinen Zugang zu einem Cloud-GPU hast oder aus einem anderen Grund, befolge diese Schritte:
Der Arbeitsbereich und alles andere wird innerhalb weniger Sekunden für dich eingerichtet.
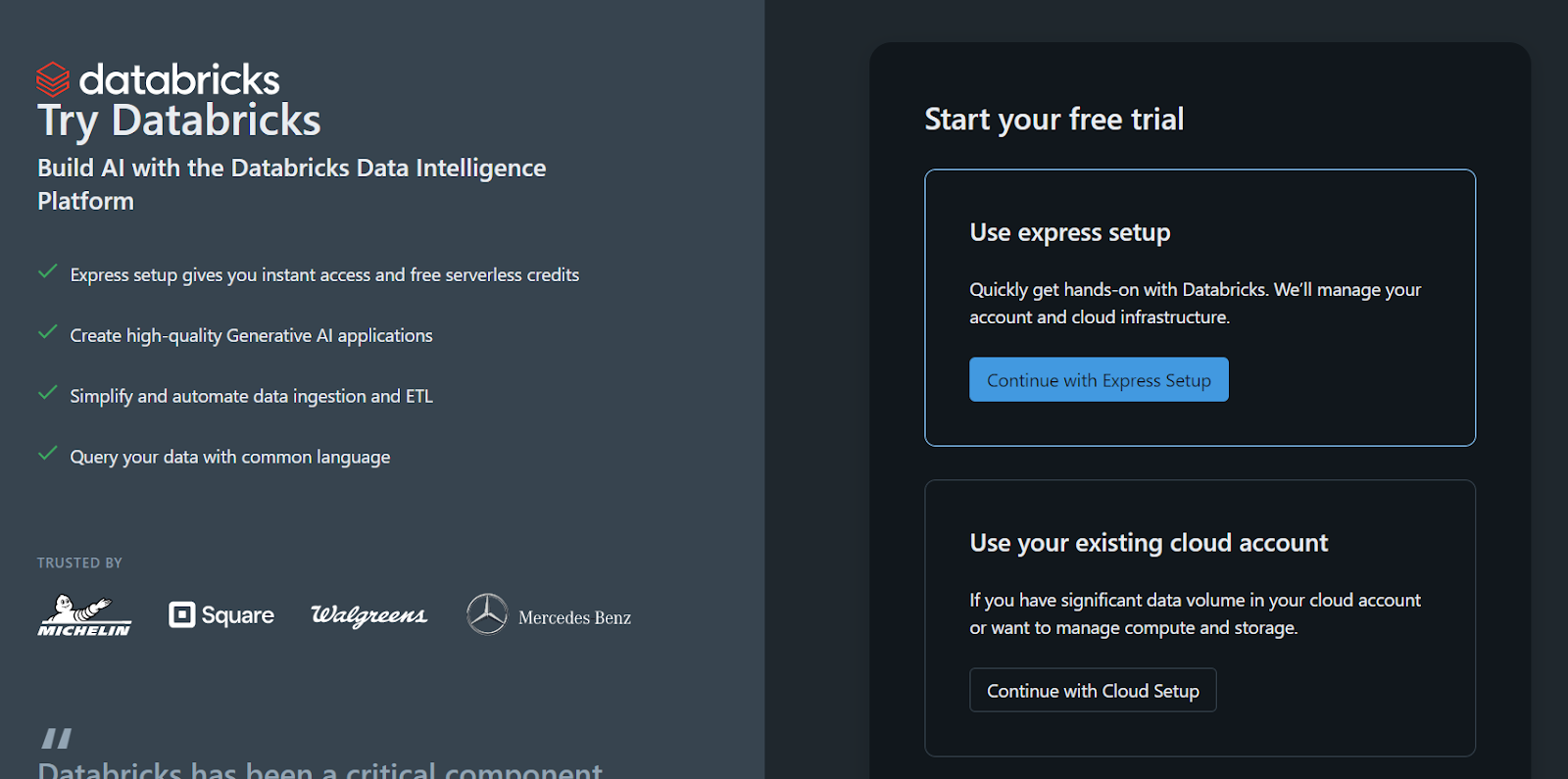
Melde dich für die Einzelplatzversion von Databricks an.
Bitte beachte, dass es einen Haken gibt: Du kannst mit dieser Methode keinen eigenen Compute-Cluster oder GPU-Cluster erstellen. Du kannst das Modell nur mit einer CPU in einem Notebook registrieren, was ein Problem sein kann, das du vielleicht vermeiden möchtest.
Wenn du mit DeepSeekR1 in einer Produktions- oder Forschungsumgebung arbeitest, kann die Verwendung einer CPU anstelle eines Grafikprozessors aufgrund der Leistungseinbußen, der Speicherbeschränkungen und der möglichen Kosten frustrierend sein. Erfahre mehr im Blogbeitrag CPU vs. GPU.
Der nächste Schritt ist die Registrierung des Modells.
1. Installiere die erforderlichen Python-Pakete:
%%capture
!pip install torch transformers mlflow accelerate torchvision
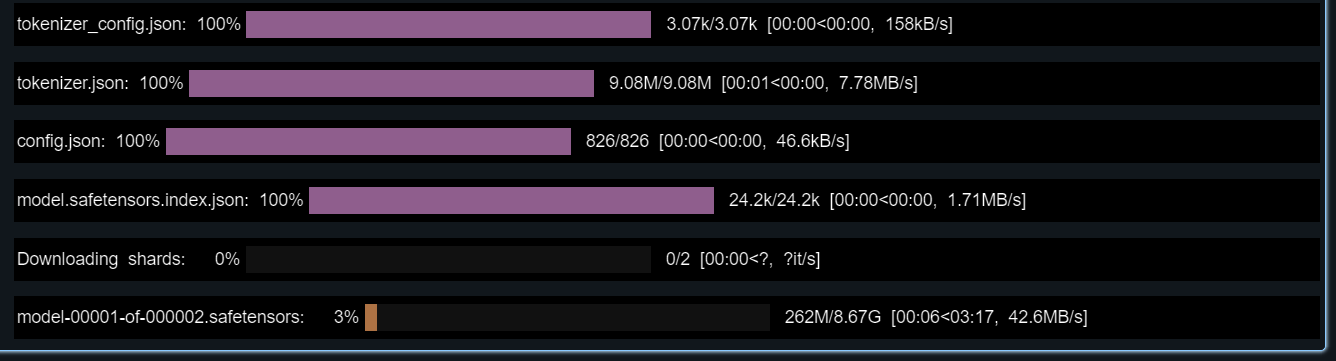
%restart_python2. Lade die Token, Konfigurationen und das Modell aus dem Hugging Face Repository:
import pandas as pd
import mlflow
import mlflow.transformers
import torch
from mlflow.models.signature import infer_signature
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig, pipeline
# Specify the model from HuggingFace transformers
model_name = "deepseek-ai/DeepSeek-R1-Distill-Llama-8B"
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
config=config,
torch_dtype=torch.float16
)
3. Teste das geladene Modell, indem du es mit einer Probeaufforderung versiehst.
Wir werden auch eine Signatur erstellen, die wir bei der Modellregistrierung hinzufügen werden:
text_generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
example_prompt = "How does a computer work?"
example_inputs = pd.DataFrame({"inputs": [example_prompt]})
example_outputs = text_generator(example_prompt, max_length=200)
signature = infer_signature(example_inputs, example_outputs)
print(example_outputs)Das Modell sollte perfekt funktionieren!
Die Ausgabe, die mir angezeigt wird, ist:
[{'generated_text': "How does a computer work? What is the computer? What is the computer used for? What is the computer used for in real life?\n\nI need to answer this question, but I need to do it step by step. I need to start with the very basic level and build up from there. I need to make sure I understand each concept before moving on. I need to use a lot of examples to explain each idea. I need to write my thoughts as if I'm explaining them to someone else, but I need to make sure I understand how to structure the answer properly.\n\nOkay, let's start with the basic level. What is a computer? It's an electronic device, right? And it has a central processing unit (CPU) that does the processing. But I think the central processing unit is more efficient, so maybe it's the CPU. Then, it has memory and storage. I remember that memory is like RAM and storage is like ROM. But wait, I think"}]4. Richte die Umgebung conda mit der richtigen Python-Version und den erforderlichen Python-Paketen ein.
Das hilft uns dabei, einen Container zu erstellen, der alle notwendigen Werkzeuge enthält, um das Modell auszuführen:
conda_env = {
"name": "mlflow-env",
"channels": ["defaults", "conda-forge"],
"dependencies": [
"python=3.11",
"pip",
{
"pip": [
"mlflow",
"transformers",
"accelerate",
"torch",
"torchvision"
]
}
]
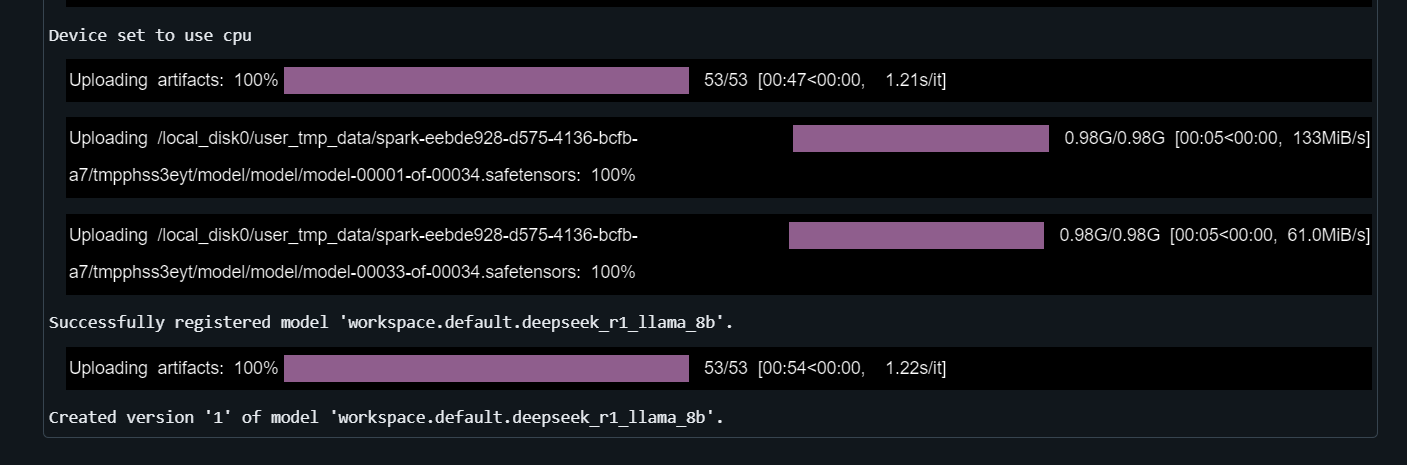
}5. Das Modell registrieren
Gib der Funktion mlflow.transformers.log_model die Textgenerierungspipeline, den Artefaktpfad, die Signatur, die Beispieleingabe, den Modellnamen und die conda Umgebung an:
with mlflow.start_run() as run:
mlflow.transformers.log_model(
transformers_model=text_generator,
artifact_path="deepseek_model",
signature=signature,
input_example=example_inputs,
registered_model_name="deepseek_r1_llama_8b",
conda_env=conda_env
)Es dauert ein paar Minuten, bis das Modell registriert ist.
Lerne die Leistungsfähigkeit von Databricks Lakehouse kennen und verbessere deine Fähigkeiten in den Bereichen Data Engineering und maschinelles Lernen, indem du den Kurs Data Management in Databricks belegst.
Es ist an der Zeit, das Modell einzusetzen!
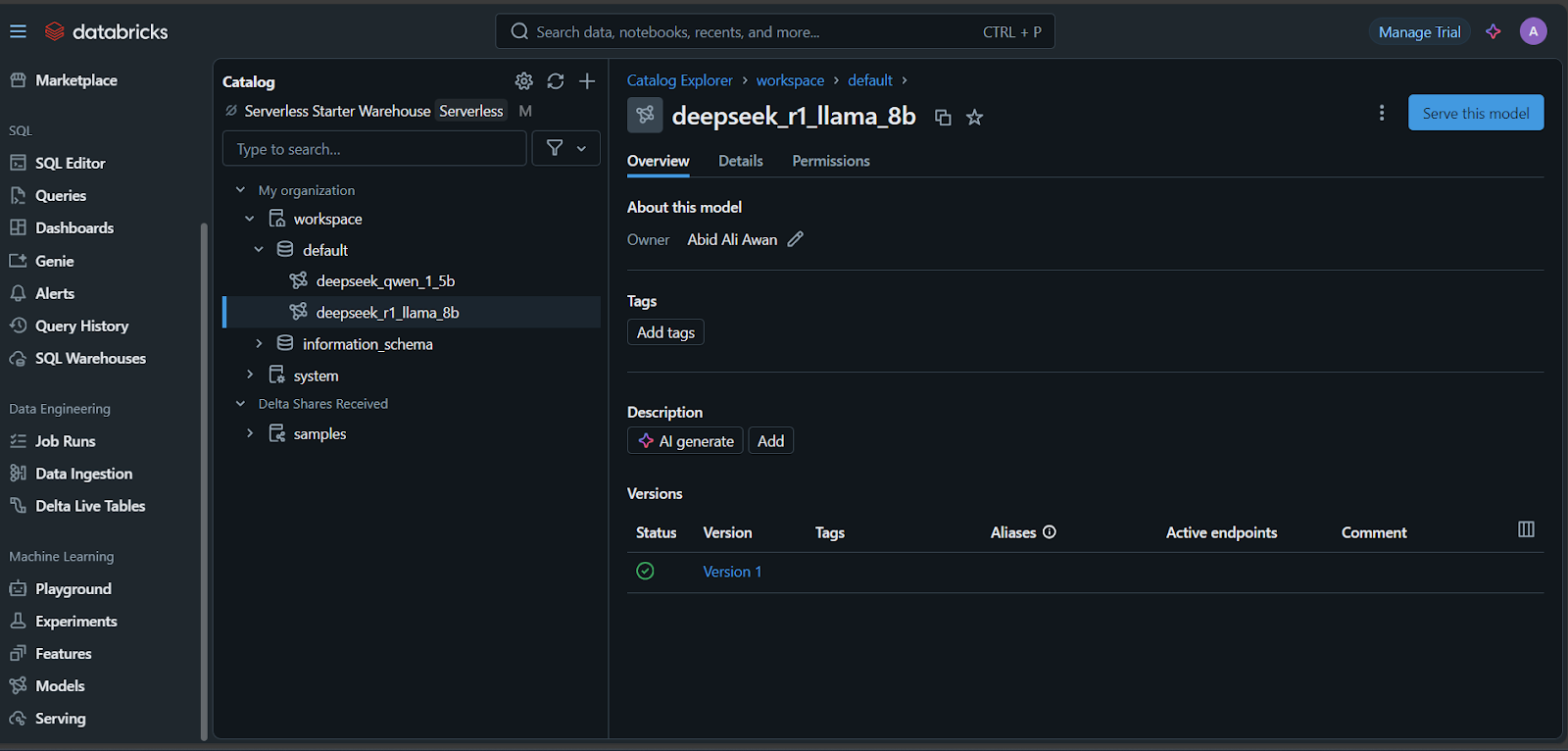
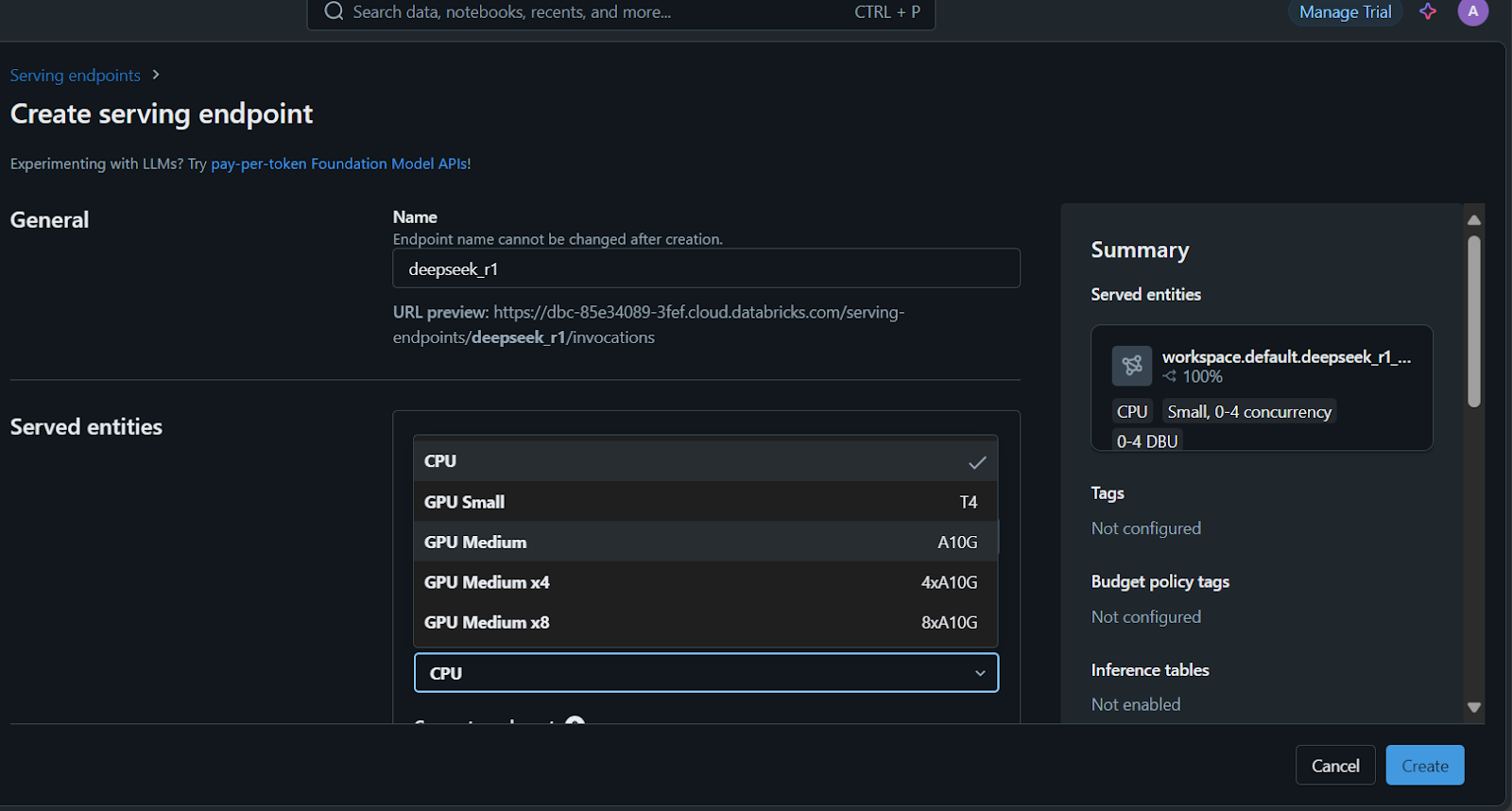
Es dauert ein paar Minuten, bis der Serving-Endpunkt eingerichtet ist. Sobald die Einrichtung abgeschlossen ist, wird der Status grün und zeigt "Bereit" an.
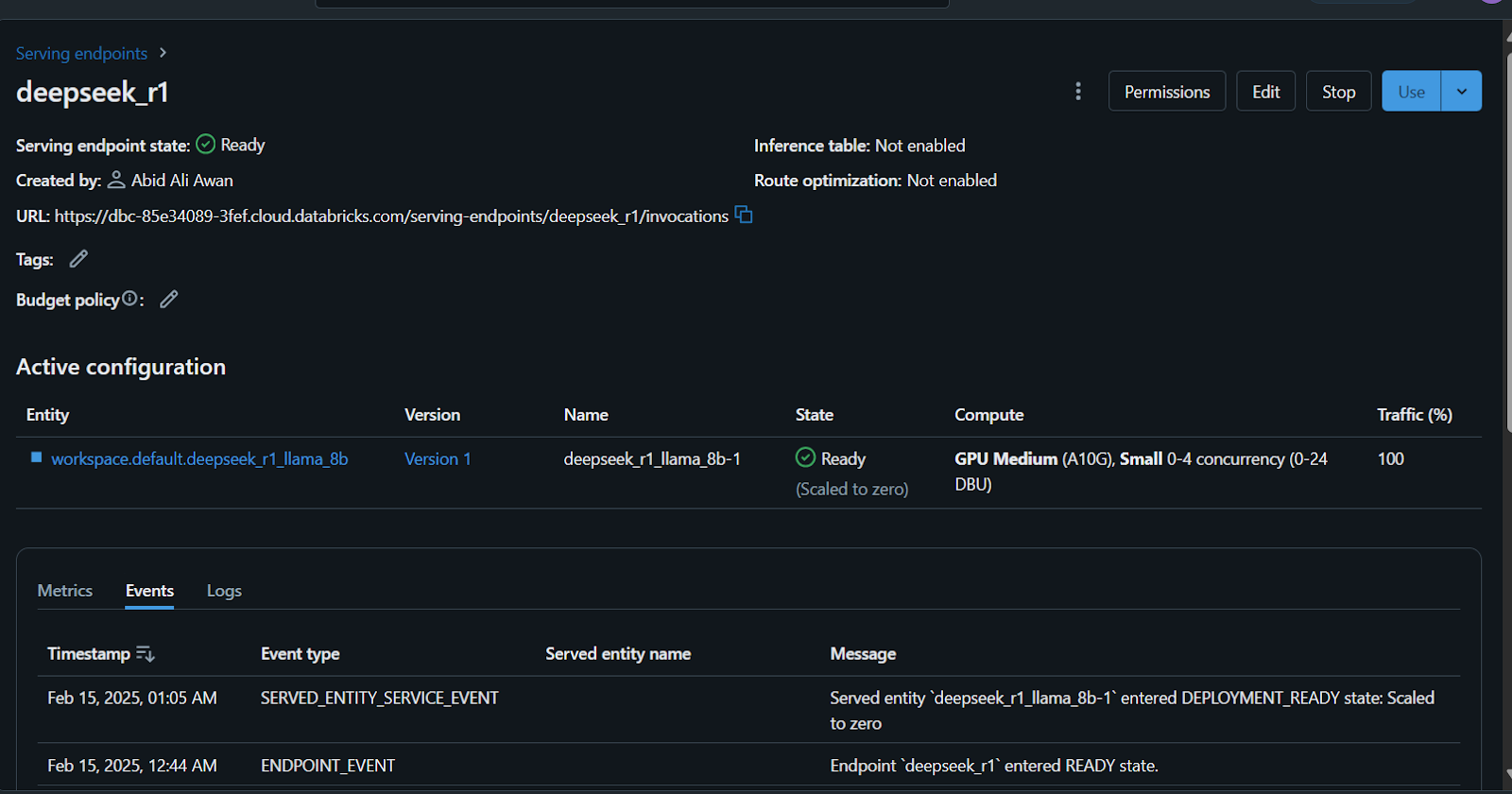
Außerdem kannst du den DeepSeek R1 auf einem benutzerdefinierten Datensatz feinabstimmen, bevor du das Modell registrierst. Folge dem Tutorial zum Feintuning von DeepSeek R1, um alles zu erfahren, was du über diesen Prozess wissen musst.
Es gibt viele Möglichkeiten, auf dieses Modell zuzugreifen oder es zu nutzen.
Um loszulegen, werden wir die Frage mit dem Browser schreiben und die Antwort generieren.
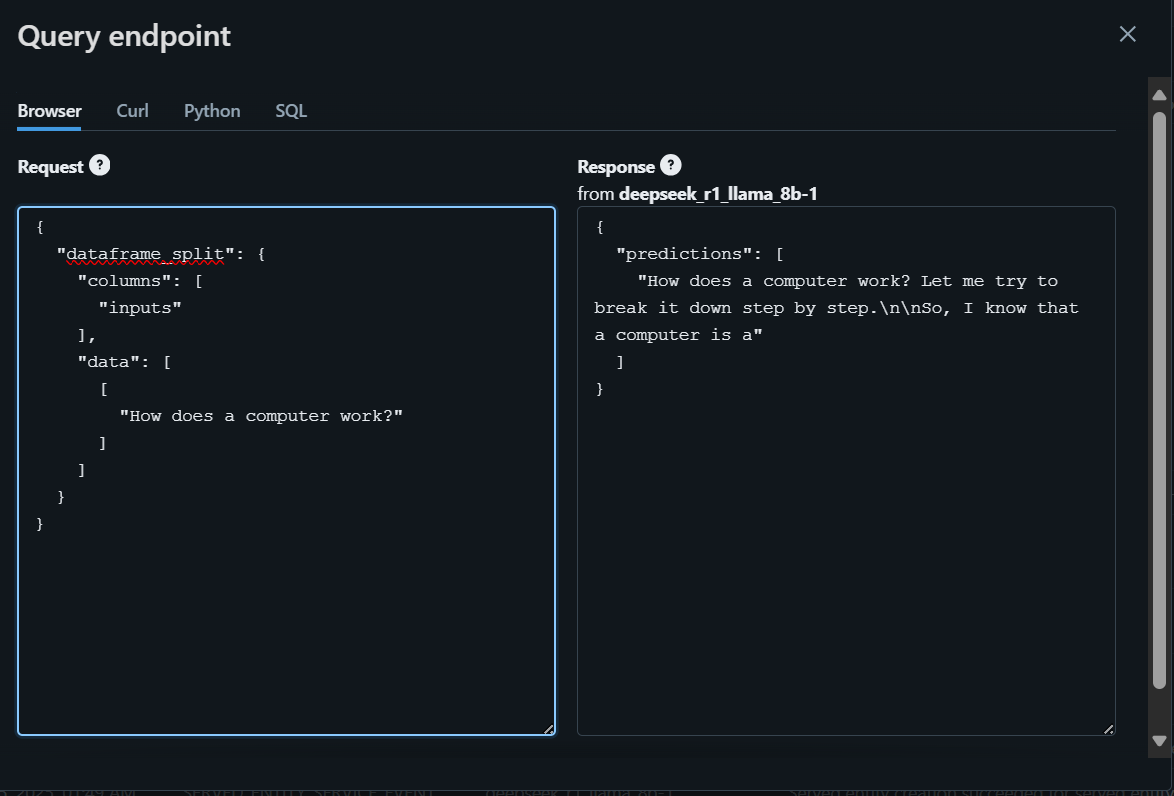
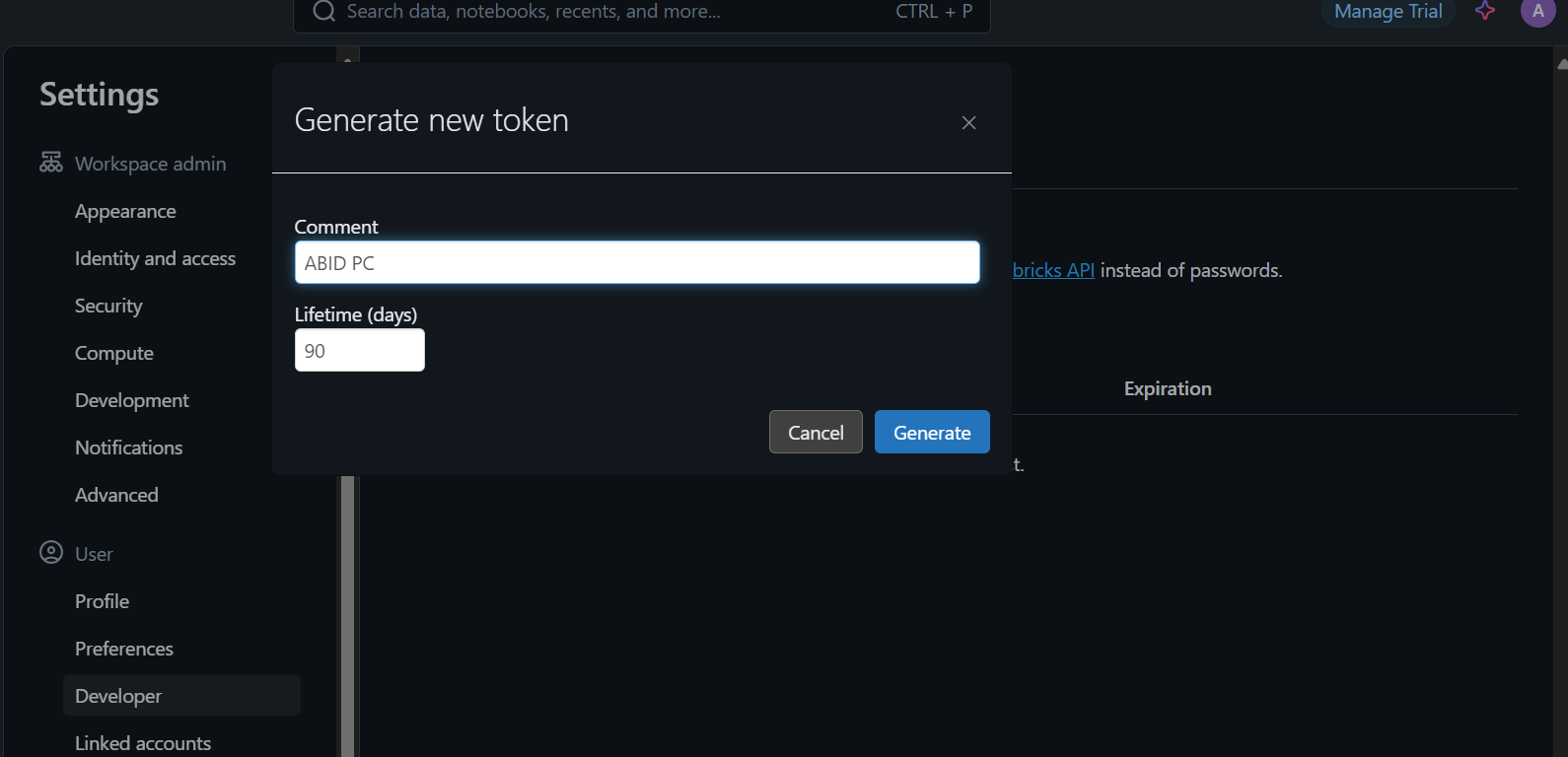
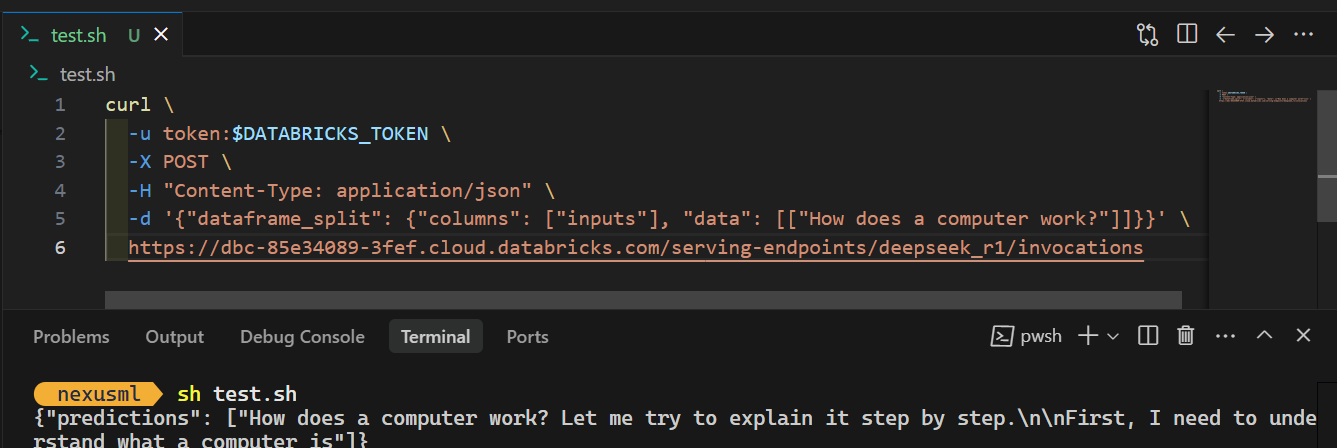
Um auf das Modell lokal zuzugreifen oder es in deine Anwendung zu integrieren, musst du zunächst einen Databricks-API-Schlüssel generieren.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"dataframe_split": {"columns": ["inputs"], "data": [["How does a computer work?"]]}}' \
https://dbc-85e34089.cloud.databricks.com/serving-endpoints/deepseek_r1/invocationsWenn du den Befehl ausführst, dauert es ein paar Sekunden, bis du die Antwort erhältst. So einfach ist das!
Schau dir den DeepSeek R1 vs V3 Blog an, um mehr über die besten großen Sprachmodelle von DeepSeek zu erfahren.
Die Registrierung und Bereitstellung des DeepSeek R1-Modells auf Databricks ist ganz einfach. Du kannst das große Modell sogar mit einem CPU-Cluster oder einer lokalen CPU-Maschine registrieren und einsetzen, ohne dass dir Kosten entstehen. Die Ausführung des Modells auf einer CPU kann jedoch langsam sein und erfordert Geduld, vor allem beim Erstellen des Docker-Images.
In diesem Lernprogramm haben wir den gesamten Prozess der Modellbereitstellung Schritt für Schritt behandelt. Wir begannen mit der Einrichtung von Databricks und der Registrierung des vortrainierten DeepSeek Distilled R1-Modells in der Databricks Model Registry. Dann haben wir das Databricks-Dashboard verwendet, um das Modell einzusetzen. Schließlich haben wir das eingesetzte Modell getestet und gezeigt, wie man es mit einem einfachen CURL-Befehl lokal nutzen kann.
Wenn du neu im Bereich KI und große Sprachmodelle bist, empfehle ich dir den Kurs "Einführung in LLMs in Python ". Dies wird dir helfen, eine solide Grundlage zu schaffen, die wichtigsten Begriffe zu verstehen und mit der Arbeit an fortgeschrittenen Modellen wie DeepSeek R1 zu beginnen!
Lerne mehr über Databricks mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
