
Curso
Introdução ao Databricks
3 h
40.1K
A Databricks é há muito tempo uma das favoritas entre a comunidade de engenharia de dados e agora está expandindo constantemente seus recursos para os domínios da inteligência artificial (IA) e do aprendizado de máquina (ML). Essa evolução significa que agora você pode treinar modelos, acompanhar experimentos, registrar modelos e implantá-los nos endpoints da Databricks, tudo na mesma plataforma unificada. Essa integração simplifica os fluxos de trabalho e torna o Databricks uma ferramenta poderosa para profissionais de dados e de IA.
Se você for novo na Databricks, considere fazer o curso Introdução à Databricks para aprender sobre a plataforma Databricks Lakehouse. Este curso ajudará você a entender como o Databricks pode modernizar as arquiteturas de dados e melhorar os processos de gerenciamento de dados.
Neste tutorial, orientarei você na implantação da versão distribuída do modelo DeepSeek R1 no Databricks. O DeepSeek R1 vem ganhando popularidade significativa, com muitas empresas optando por executá-lo em sua própria infraestrutura de nuvem em vez de enviar dados para servidores externos.
Este guia ajudará você a configurar uma conta Databricks, registrar o modelo DeepSeek R1, implantá-lo usando a interface do usuário e acessá-lo por meio do playground e localmente usando o comando CURL.
Para saber mais sobre o DeepSeek R1, incluindo seus recursos, processo de desenvolvimento, modelos destilados, preços e como ele se compara a outros modelos de IA, como as ofertas da OpenAI, confira o site DeepSeek-R1: Recursos, comparação, modelos destilados e muito mais blog.
Há duas maneiras fáceis de usar o Databricks. Você pode acessar o GCP, o AWS ou o Azure Marketplace e assinar o serviço da Databricks. Como alternativa, você pode se inscrever em uma conta autônoma da Databricks, que fornece alguns recursos de computação sem a necessidade de criar clusters de computação.
Aqui, descrevo as duas maneiras.
Se você já tiver acesso a uma GPU do AWS, esse método é altamente recomendado. É simples e não exige muito esforço.
Configurando o Databricks no marketplace da AWS.
Quando você terminar, ele criará um espaço de trabalho do Databricks para você com todos os tipos de opções. Todos os pagamentos serão feitos por meio do faturamento da AWS.
Ao clicar na guia "Compute", você pode criar o cluster de computação de sua escolha.
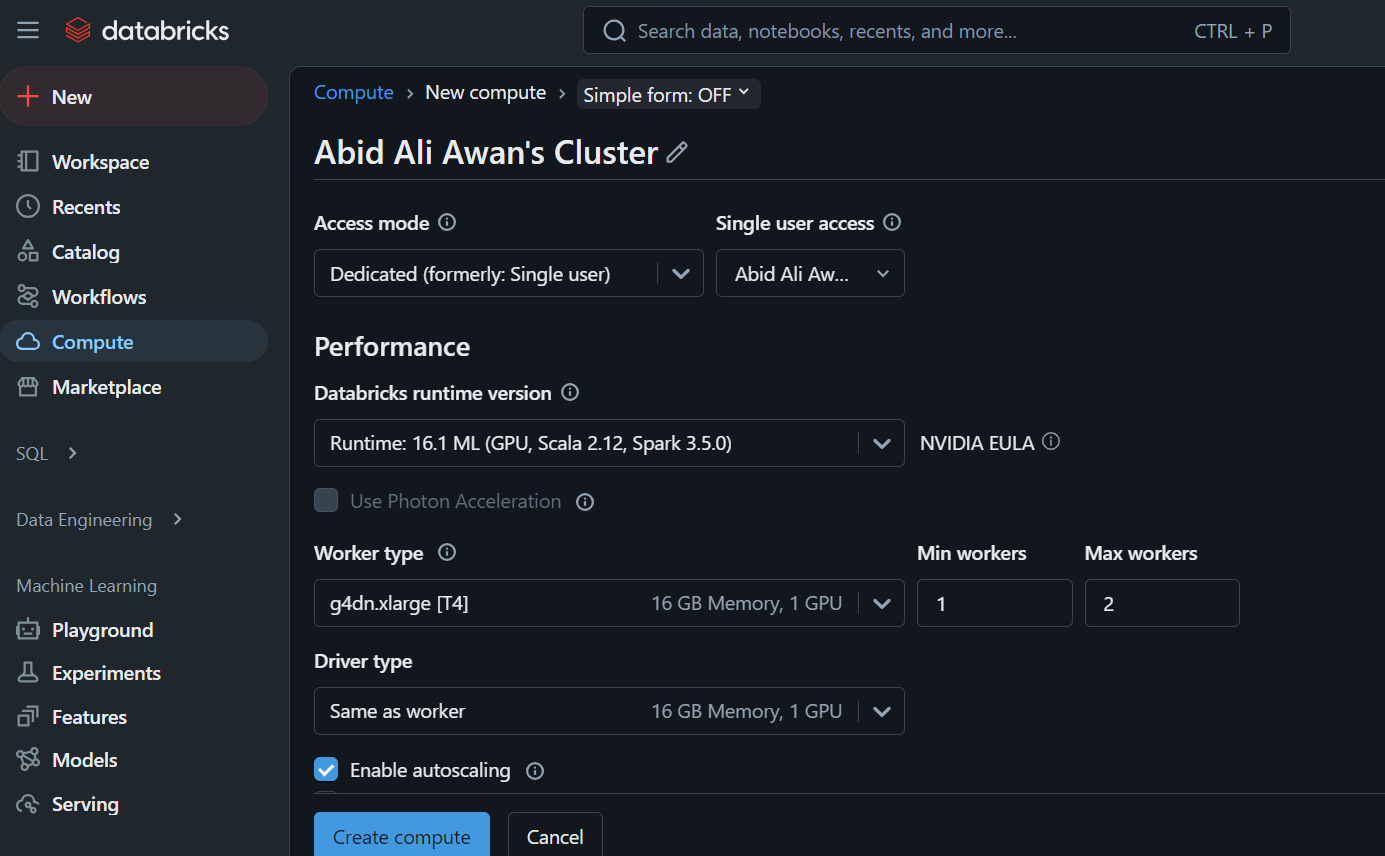
Esse cluster será usado posteriormente em um notebook e para implantar o modelo.
Se você preferir usar a versão autônoma do Databricks porque não tem acesso a uma GPU na nuvem ou por qualquer outro motivo, siga estas etapas:
O espaço de trabalho e tudo será configurado para você em poucos segundos.
Inscreva-se para obter a versão autônoma do Databricks.
Observe que há um problema: você não pode criar seu próprio cluster de computação ou cluster de GPU usando esse método. Você só pode registrar o modelo usando uma CPU em um notebook, o que pode ser um incômodo que você talvez queira evitar.
Se você estiver trabalhando com o DeepSeekR1 em uma configuração de produção ou pesquisa, usar uma CPU em vez de uma GPU pode ser frustrante devido ao impacto no desempenho, às limitações de memória e aos possíveis custos. Saiba mais na postagem do blog CPU vs. GPU.
A próxima etapa é registrar o modelo.
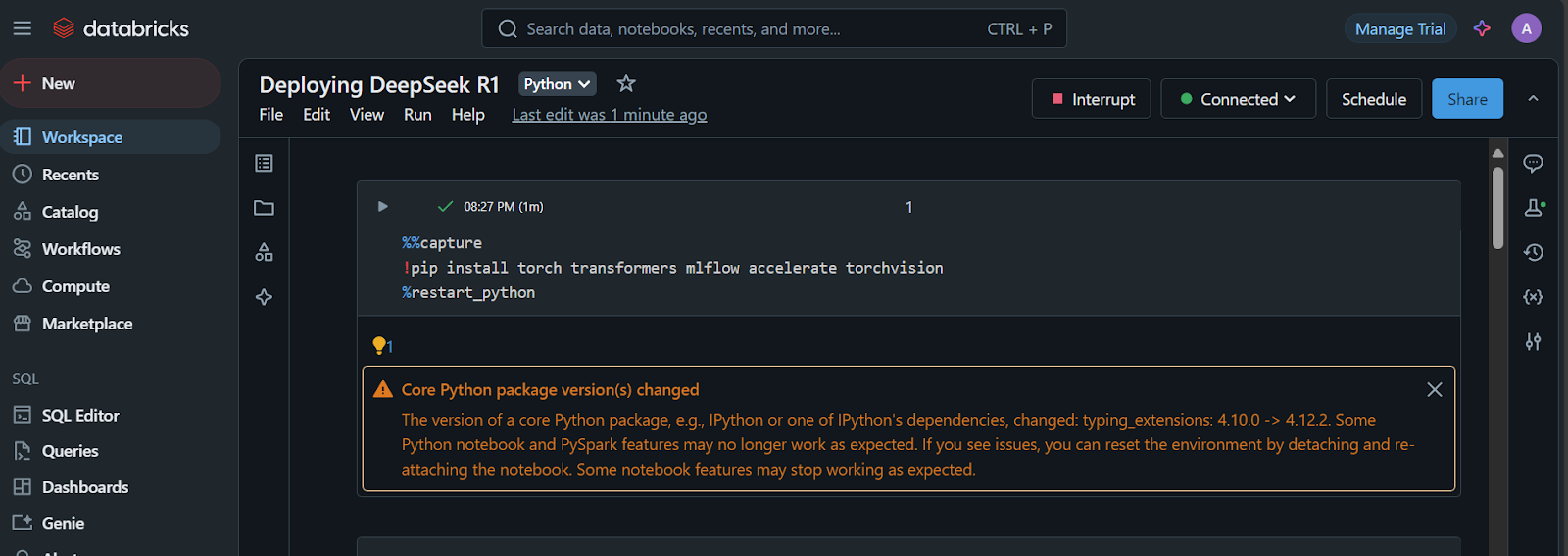
1. Instale os pacotes Python necessários:
%%capture
!pip install torch transformers mlflow accelerate torchvision
%restart_python2. Carregue os tokens, as configurações e o modelo do repositório Hugging Face:
import pandas as pd
import mlflow
import mlflow.transformers
import torch
from mlflow.models.signature import infer_signature
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig, pipeline
# Specify the model from HuggingFace transformers
model_name = "deepseek-ai/DeepSeek-R1-Distill-Llama-8B"
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
config=config,
torch_dtype=torch.float16
)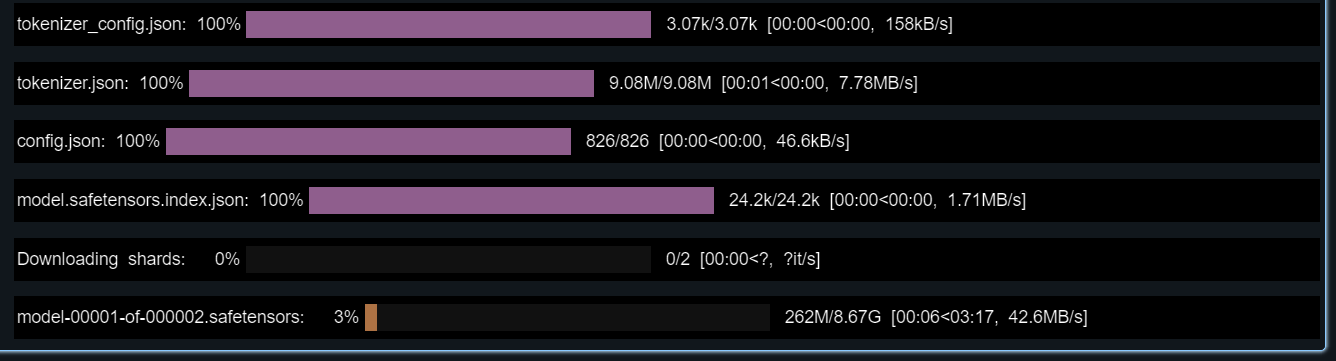
3. Teste o modelo carregado fornecendo a ele um prompt de amostra.
Também criaremos uma assinatura que será adicionada durante o registro do modelo:
text_generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
example_prompt = "How does a computer work?"
example_inputs = pd.DataFrame({"inputs": [example_prompt]})
example_outputs = text_generator(example_prompt, max_length=200)
signature = infer_signature(example_inputs, example_outputs)
print(example_outputs)O modelo deve estar funcionando perfeitamente!
A saída que ele mostrou para mim é:
[{'generated_text': "How does a computer work? What is the computer? What is the computer used for? What is the computer used for in real life?\n\nI need to answer this question, but I need to do it step by step. I need to start with the very basic level and build up from there. I need to make sure I understand each concept before moving on. I need to use a lot of examples to explain each idea. I need to write my thoughts as if I'm explaining them to someone else, but I need to make sure I understand how to structure the answer properly.\n\nOkay, let's start with the basic level. What is a computer? It's an electronic device, right? And it has a central processing unit (CPU) that does the processing. But I think the central processing unit is more efficient, so maybe it's the CPU. Then, it has memory and storage. I remember that memory is like RAM and storage is like ROM. But wait, I think"}]4. Configure o ambiente conda com a versão correta do Python e os pacotes Python necessários.
Isso nos ajudará a criar o contêiner que tem todas as ferramentas necessárias para executar o modelo:
conda_env = {
"name": "mlflow-env",
"channels": ["defaults", "conda-forge"],
"dependencies": [
"python=3.11",
"pip",
{
"pip": [
"mlflow",
"transformers",
"accelerate",
"torch",
"torchvision"
]
}
]
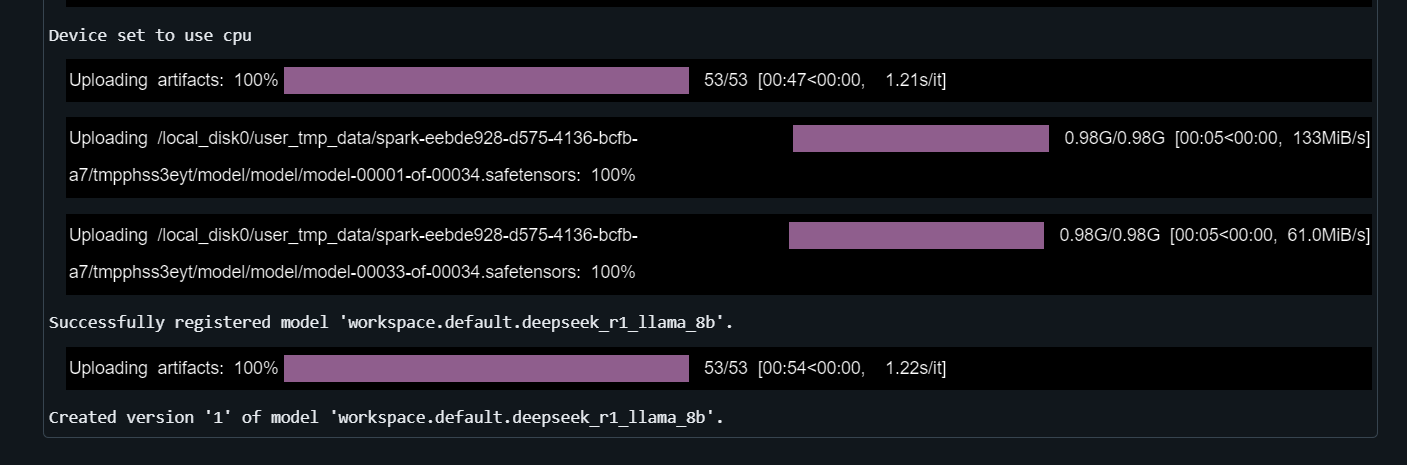
}5. Registre o modelo
Forneça à função mlflow.transformers.log_model o pipeline de geração de texto, o caminho do artefato, a assinatura, a entrada de exemplo, o nome do modelo e o ambiente conda:
with mlflow.start_run() as run:
mlflow.transformers.log_model(
transformers_model=text_generator,
artifact_path="deepseek_model",
signature=signature,
input_example=example_inputs,
registered_model_name="deepseek_r1_llama_8b",
conda_env=conda_env
)Você levará alguns minutos para registrar o modelo.
Saiba mais sobre o poder do Databricks Lakehouse e aprimore suas habilidades de engenharia de dados e aprendizado de máquina fazendo o curso Gerenciamento de dados no Databricks.
É hora de implantar o modelo!
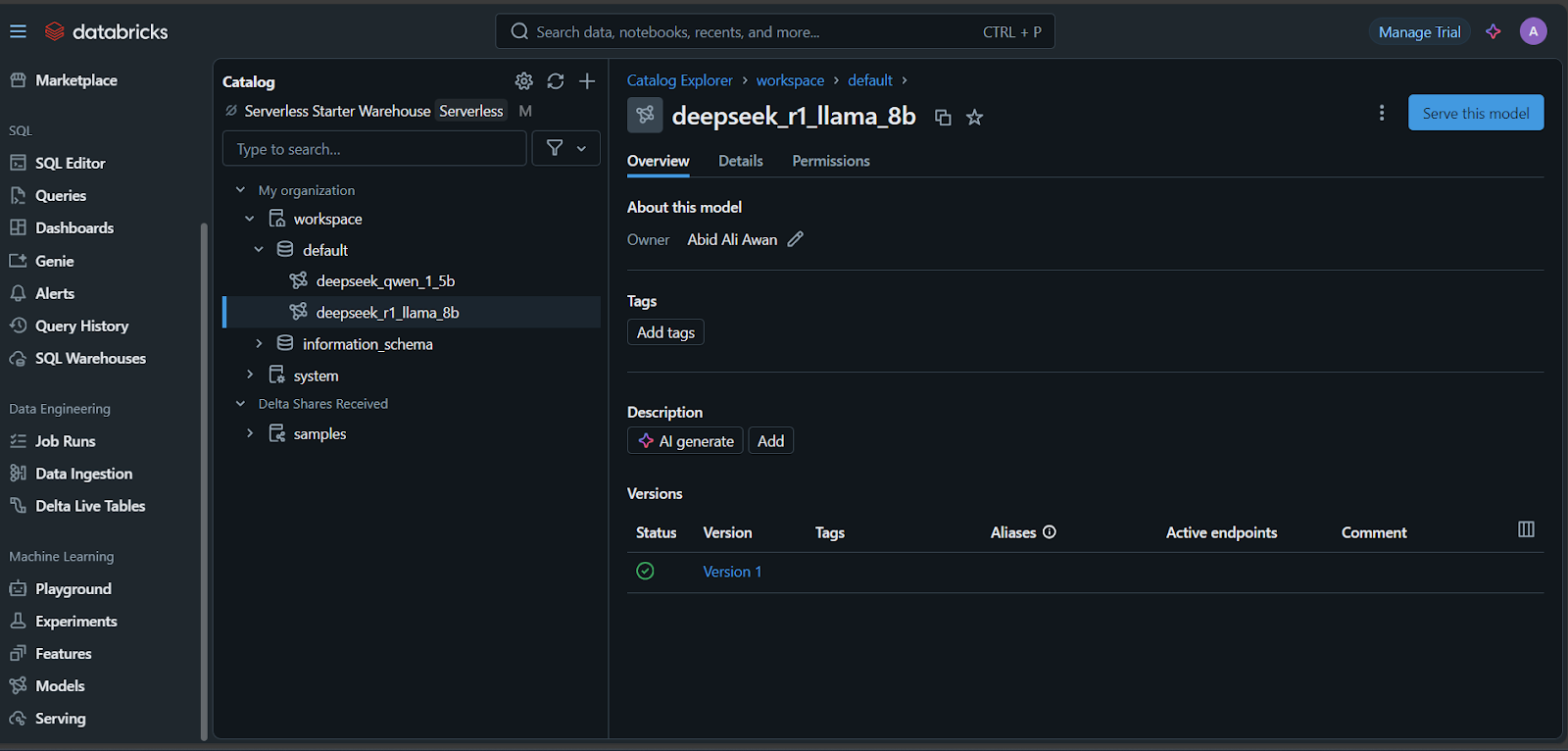
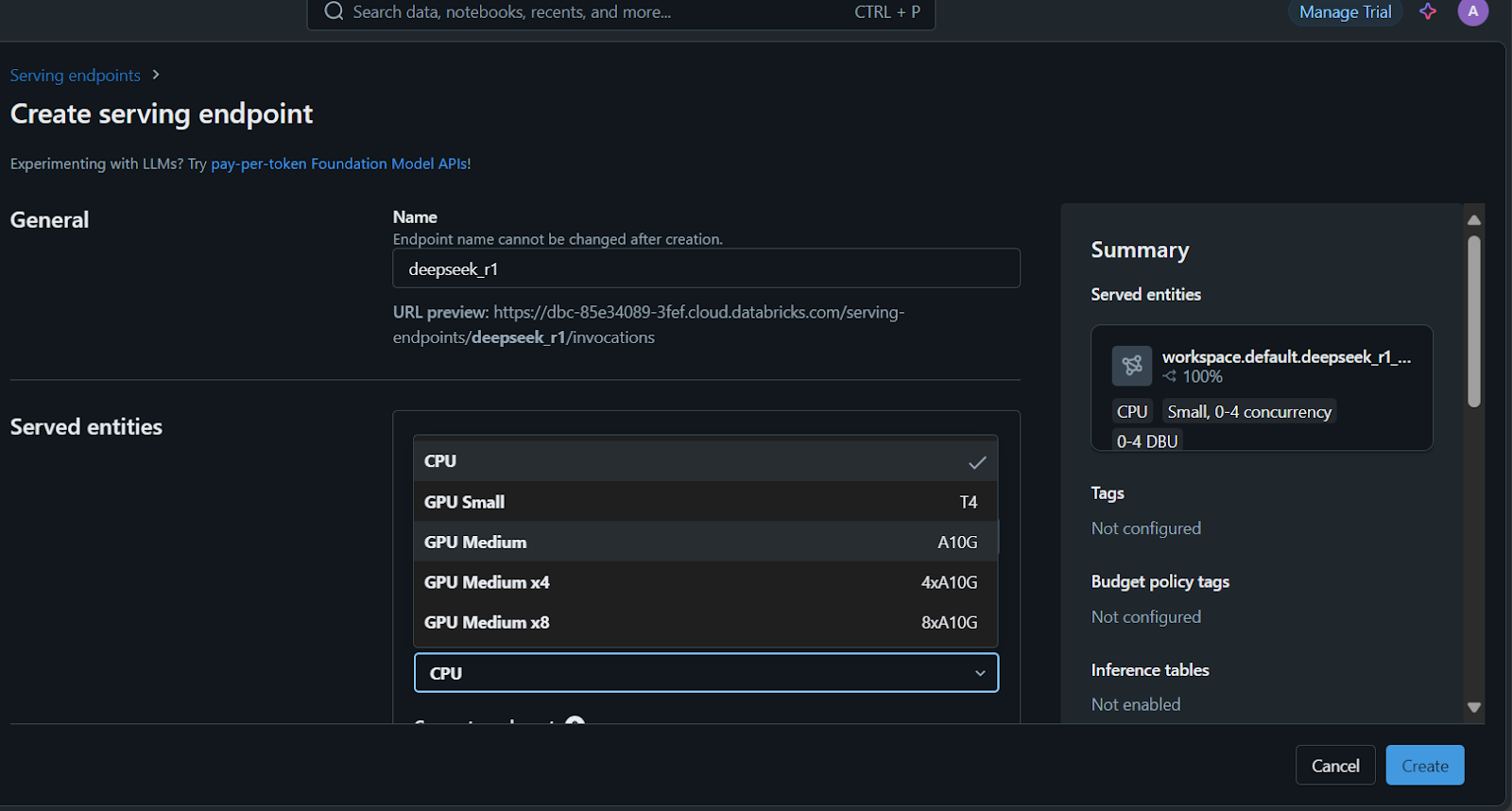
Você levará alguns minutos para configurar o endpoint de serviço. O status ficará verde quando a configuração for concluída e exibirá "Ready" (Pronto).
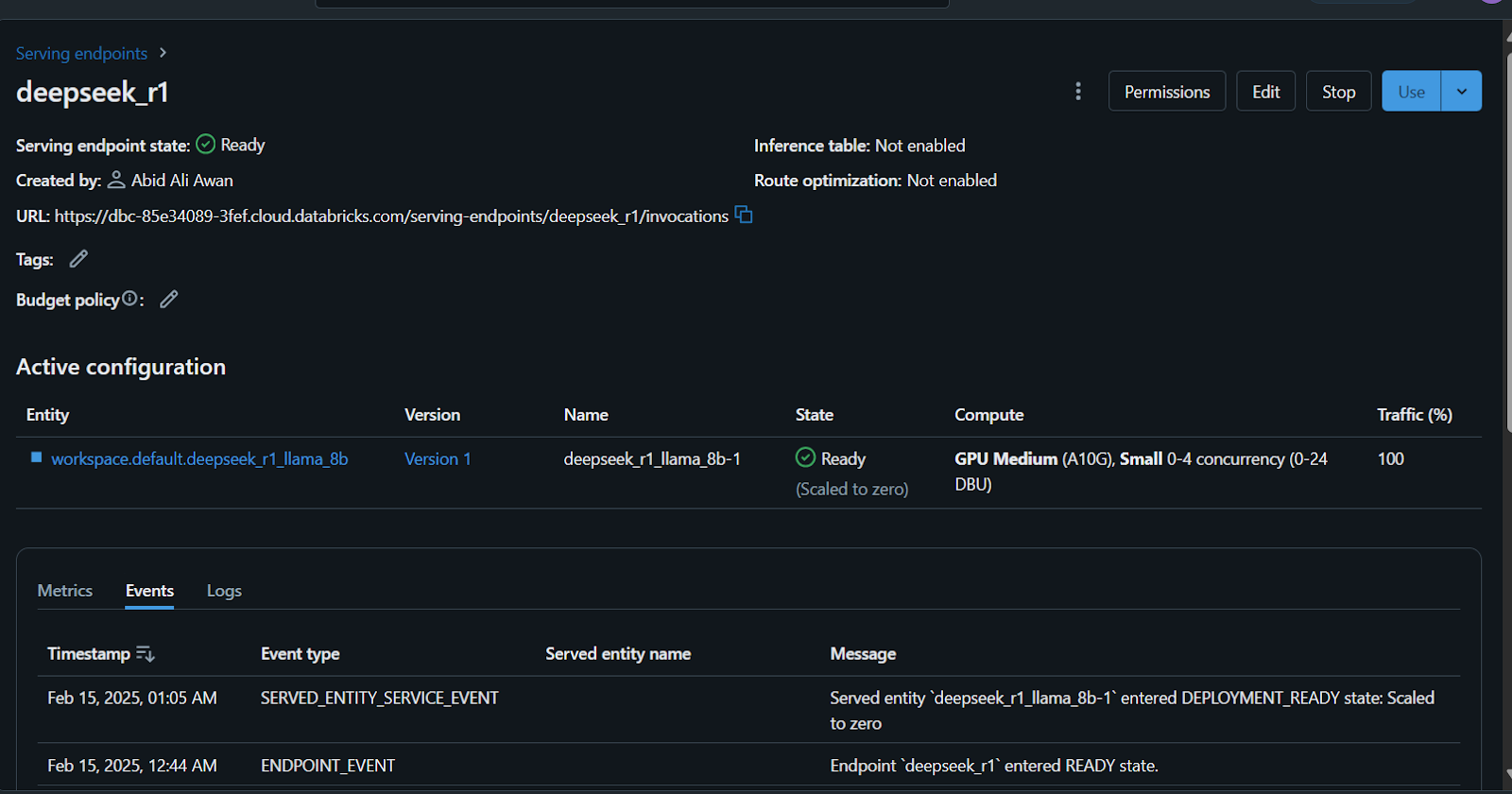
Além disso, você pode fazer o ajuste fino do DeepSeek R1 em um conjunto de dados personalizado antes de registrar o modelo. Siga o tutorial Fine-Tuning DeepSeek R1 para saber tudo o que você precisa saber sobre esse processo.
Há muitas maneiras de acessar ou usar esse modelo.
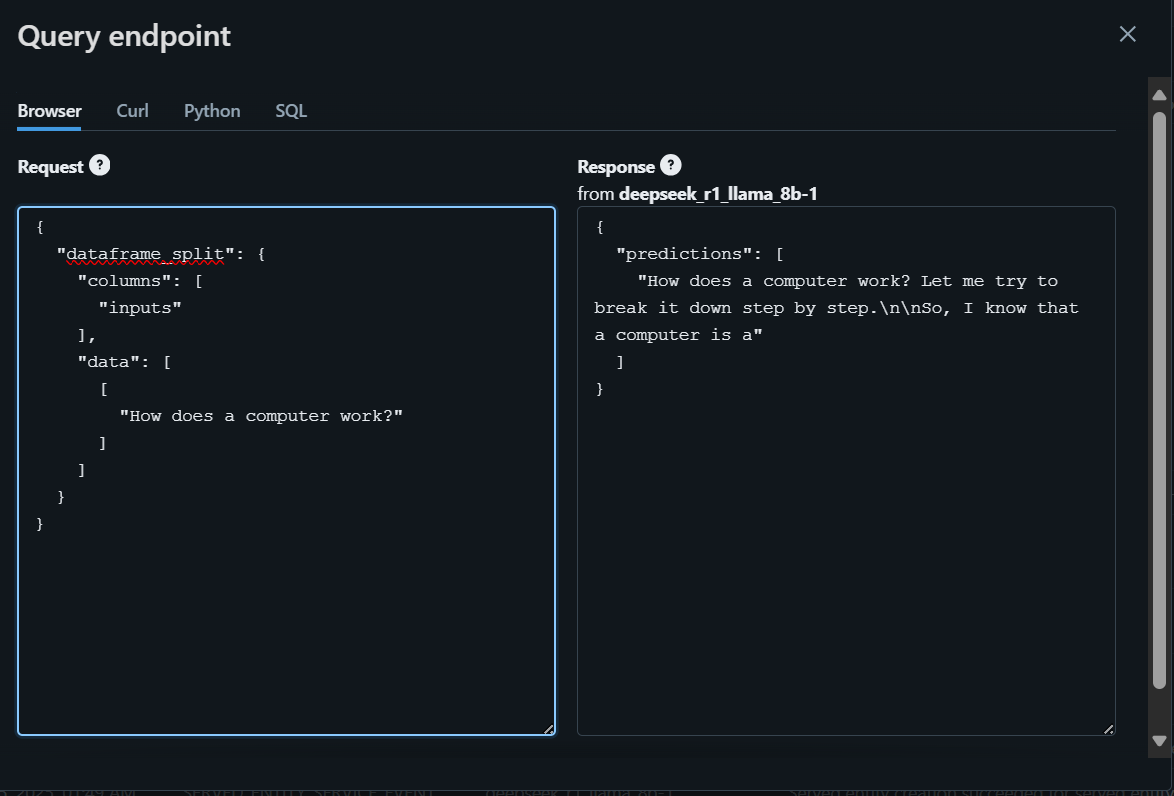
Para começar, escreveremos a pergunta usando o navegador e geraremos a resposta.
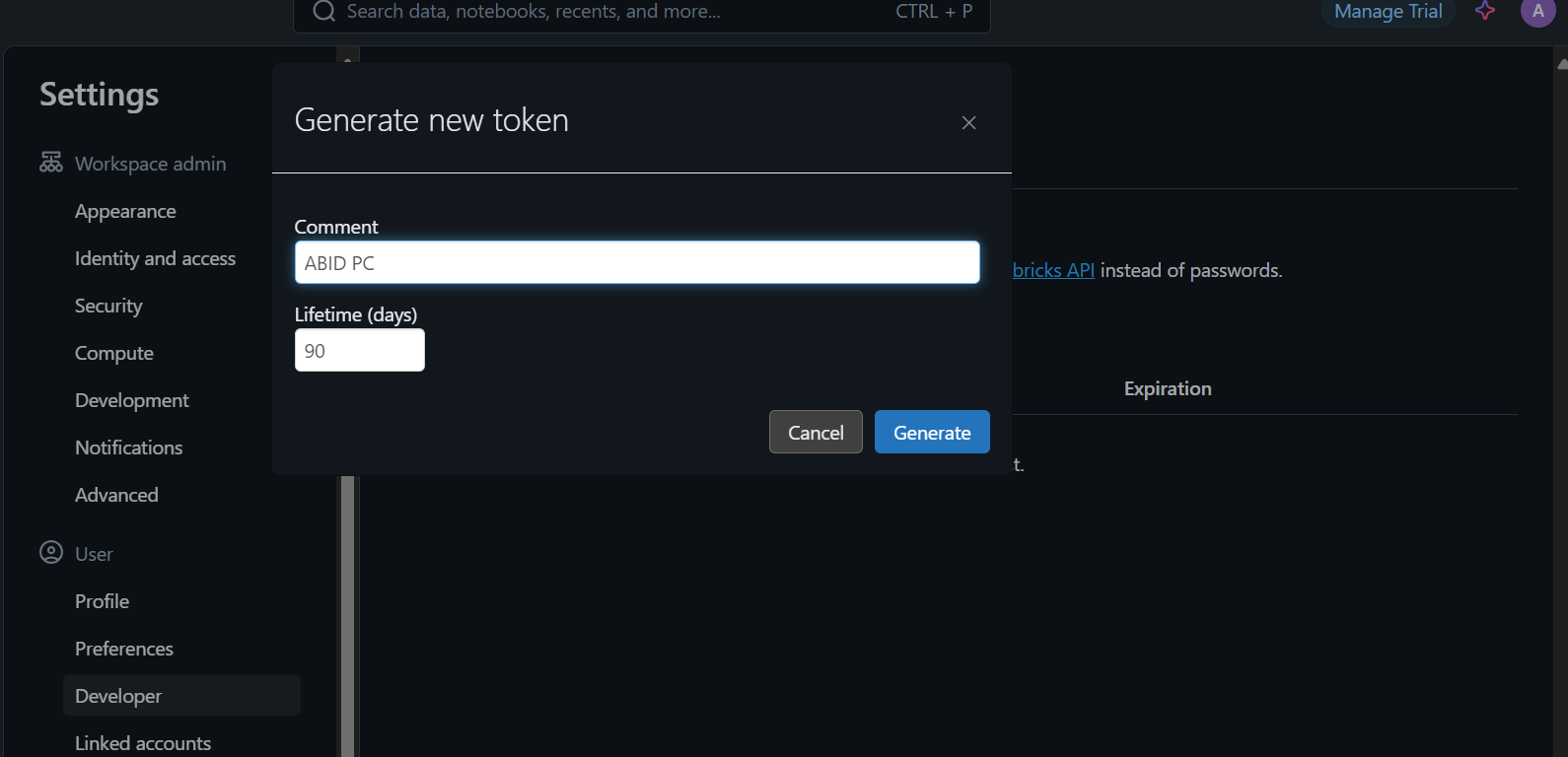
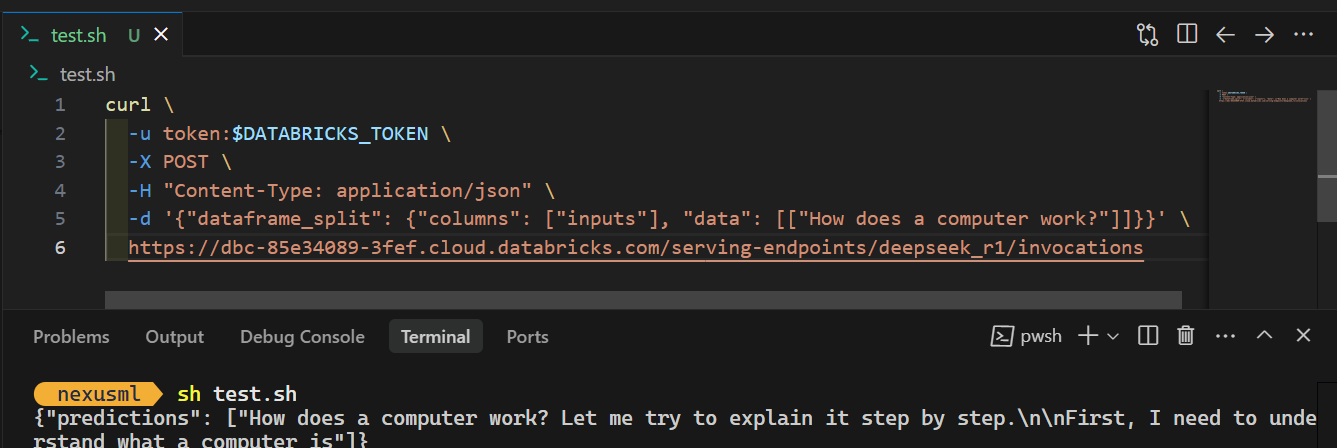
Para acessar o modelo localmente ou integrá-lo ao seu aplicativo, primeiro você precisa gerar uma chave de API da Databricks.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"dataframe_split": {"columns": ["inputs"], "data": [["How does a computer work?"]]}}' \
https://dbc-85e34089.cloud.databricks.com/serving-endpoints/deepseek_r1/invocationsQuando você executar o comando, a geração da resposta levará alguns segundos. É simples assim!
Confira o blog DeepSeek R1 vs V3 para saber mais sobre os melhores modelos de linguagem grande disponíveis no DeepSeek.
O registro e a implementação do modelo DeepSeek R1 no Databricks são simples. Você pode até mesmo registrar e implantar o modelo grande usando um cluster de CPU ou uma máquina de CPU local, tudo sem incorrer em custos. No entanto, a execução do modelo em uma CPU pode ser lenta e requer paciência, especialmente ao criar a imagem do docker.
Neste tutorial, abordamos passo a passo todo o processo de implantação do modelo. Começamos configurando o Databricks e registrando o modelo pré-treinado do DeepSeek Distilled R1 no Databricks Model Registry. Em seguida, usamos o painel do Databricks para implantar o modelo. Por fim, testamos o modelo implantado e demonstramos como usá-lo localmente com um simples comando CURL.
Se você não tem experiência com IA e modelos de linguagem grandes, recomendo que você faça o curso Introdução aos LLMs em Python. Isso ajudará você a construir uma base sólida, entender as principais terminologias e começar a trabalhar em modelos avançados como o DeepSeek R1!
Saiba mais sobre a Databricks com estes cursos!
Curso
Curso
Curso
blog
DataCamp Team
4 min
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita

