
Cursus
Développer des LLM
16 h
Récemment, le domaine des grands modèles linguistiques (LLM) a connu une évolution rapide. Les nouveaux LLM sont conçus pour être plus petits et plus intelligents, ce qui les rend moins chers et plus faciles à utiliser que les grands modèles.
Avec la sortie de Llama 3.2, nous avons désormais accès à des modèles plus petits, tels que les variantes 1B et 3B. Bien que ces petits modèles ne puissent pas atteindre la précision des grands modèles dans les tâches générales, ils peuvent être affinés pour obtenir des performances exceptionnelles dans des domaines spécifiques, tels que la classification des émotions dans les interactions avec l'assistance à la clientèle. Cette capacité leur permet de remplacer potentiellement les modèles traditionnels dans ces domaines.
Dans ce tutoriel, nous allons explorer les capacités de vision et les modèles légers de Llama 3.2. Nous apprendrons à accéder au modèle Llama 3.2 3B, à l'affiner sur un ensemble de données d'assistance à la clientèle, puis à le fusionner et à l'exporter vers le hub Hugging Face. Enfin, nous convertirons le modèle au format GGUF et l'utiliserons localement à l'aide de l'application Jan.
Si vous êtes novice en matière d'IA, il est fortement recommandé de suivre le cours Fondamentaux de l'IA pour apprendre les bases du ChatGPT, des grands modèles de langage, de l'IA générative, etc.

Image par l'auteur
La famille des modèles open-source Llama 3.2 comporte deux variantes : le modèleléger et le modèlevision . Les modèles de vision excellent dans le raisonnement sur les images et le rapprochement de la vision et du langage, tandis que les modèles légers sont performants dans la génération de textes multilingues et l'appel d'outils pour les appareils périphériques.
Le modèle léger se décline en deux variantes plus petites : 1B et 3B. Ces modèles sont efficaces pour la génération de textes multilingues et les tâches d'appel d'outils. Ils sont petits, ce qui signifie qu'ils peuvent fonctionner sur un appareil afin de garantir que les données ne quittent jamais l'appareil et de fournir une génération de texte à grande vitesse à un faible coût informatique.
Pour créer ces modèles légers et efficaces, Llama 3.2 utilise des techniques d'élagage et de distillation des connaissances. L'élagage réduit la taille du modèle tout en conservant les performances, et la distillation des connaissances utilise les grands réseaux pour partager les connaissances avec les plus petits, améliorant ainsi leurs performances.
Le modèle 3B est plus performant que d'autres modèles tels que Gemma 2 (2.6B) et Phi 3.5-mini dans des tâches telles que le suivi des instructions, le résumé, la réécriture de messages et l'utilisation d'outils.
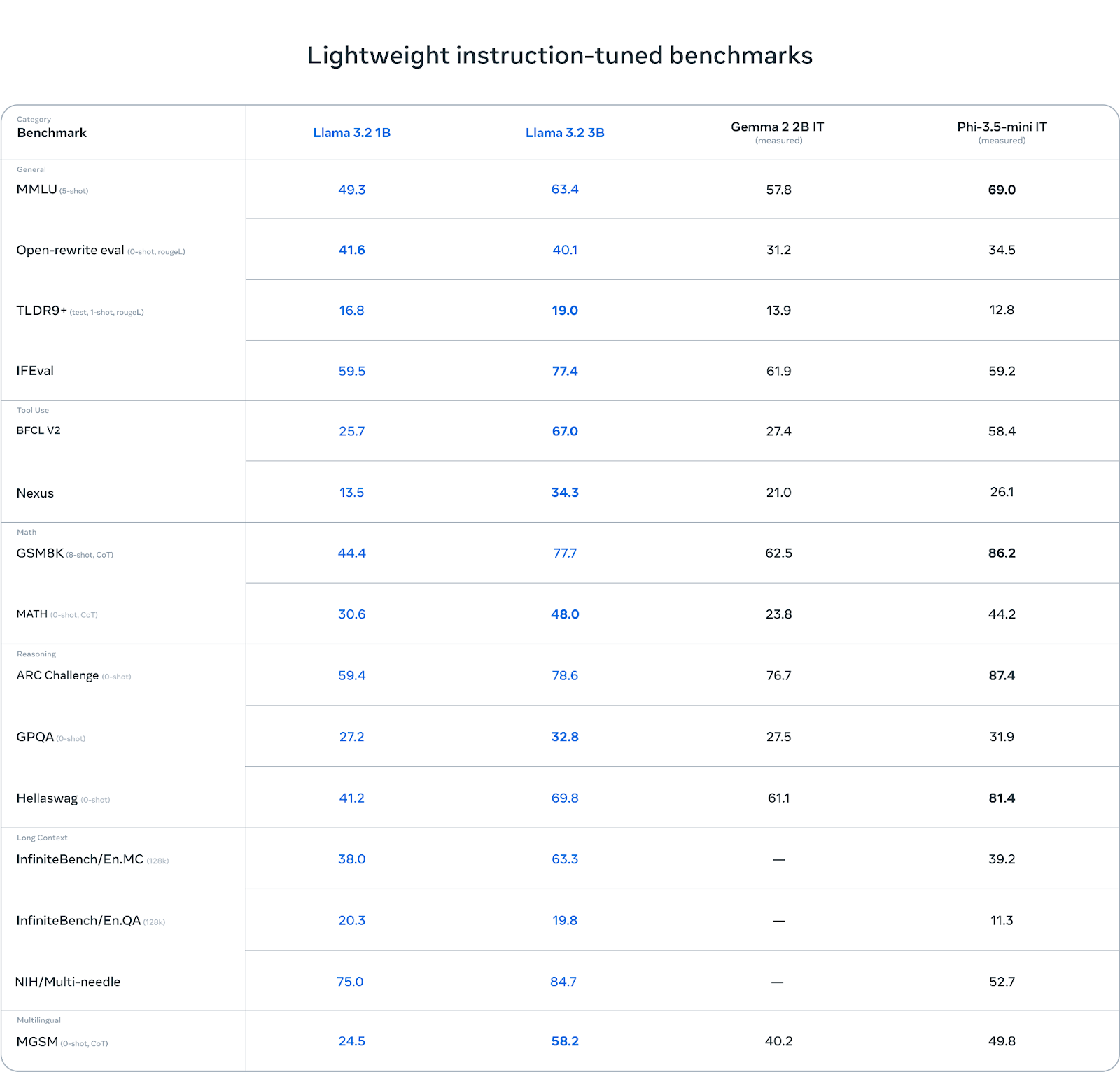
Source : Llama 3.2 : Révolutionner l'IA et la vision grâce à des modèles ouverts et personnalisables
Les modèles vision se déclinent en deux variantes : 11B et 90B. Ces modèles sont conçus pour soutenir le raisonnement par l'image. Le 11B et le 90B peuvent comprendre et interpréter des documents, des tableaux et des graphiques et effectuer des tâches telles que le sous-titrage d'images et la mise à la terre visuelle. Ces capacités de vision avancées ont été rendues possibles par l'intégration d'encodeurs d'images pré-entraînés avec des modèles de langage utilisant des poids adaptatifs constitués de couches d'attention croisée.
Par rapport à Claude 3 Haiku et GPT-4o miniles modèles de vision du Llama 3.2 ont excellé dans la reconnaissance d'images et dans diverses tâches de compréhension visuelle, ce qui en fait des outils robustes pour les applications multimodales de l'IA.
Source : Llama 3.2 : Révolutionner l'IA et la vision grâce à des modèles ouverts et personnalisables
Vous pouvez en savoir plus sur les cas d'utilisation de Llama 3.2, les benchmarks, Llama Guard 3 et l'architecture du modèle en lisant notre dernier blog, Llama 3.2 Guide : Comment ça marche, les cas d'utilisation et plus encore.
Même si le modèle Llama 3.2 est librement accessible et open source, vous devez accepter les termes et conditions et remplir le formulaire sur le site web.
Pour accéder au dernier modèle Llama 3.2 sur la plateforme Kaggle :
Source : Télécharger Llama
Source : Meta | Llama 3.2 | Kaggle
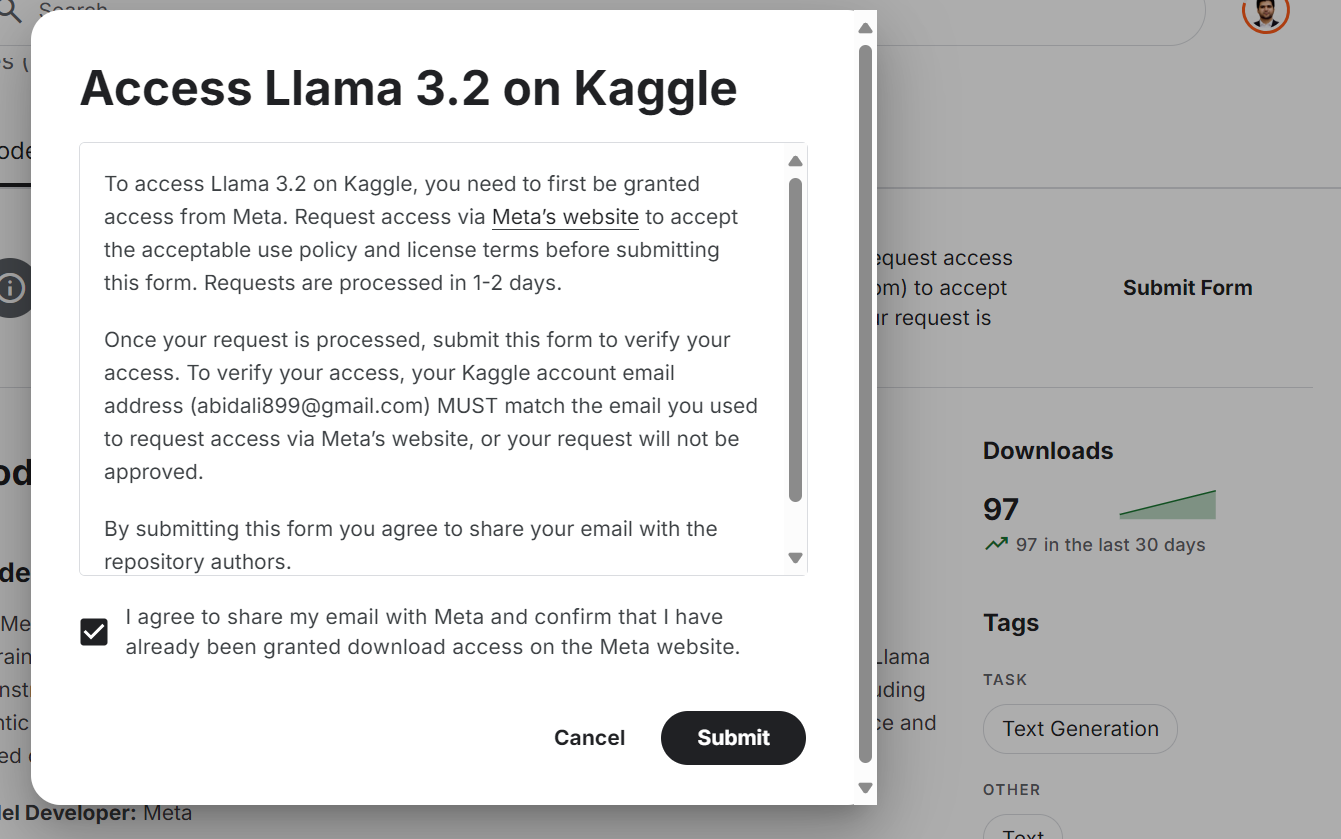
Source : Meta | Llama 3.2 | Kaggle
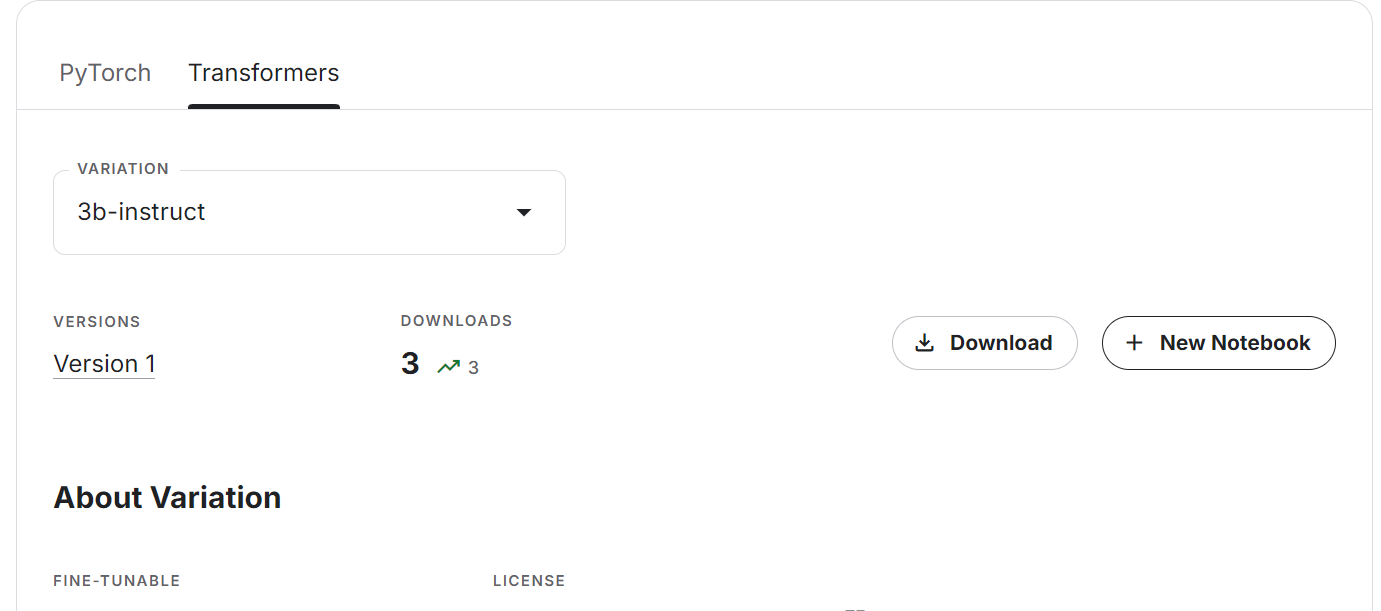
%%capture
%pip install -U transformers acceleratefrom transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, TextStreamer
import torch
base_model = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)pad_token_id pour éviter de recevoir des messages d'avertissement.if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
if model.config.pad_token_id is None:
model.config.pad_token_id = model.config.eos_token_idpipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)messages = [{"role": "user", "content": "Who is Vincent van Gogh?"}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])La réponse est assez précise.

from IPython.display import Markdown, display
messages = [
{
"role": "system",
"content": "You are a skilled Python developer specializing in database management and optimization.",
},
{
"role": "user",
"content": "I'm experiencing a sorting issue in my database. Could you please provide Python code to help resolve this problem?",
},
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
outputs = pipe(prompt, max_new_tokens=512, do_sample=True)
display(
Markdown(
outputs[0]["generated_text"].split(
"<|start_header_id|>assistant<|end_header_id|>"
)[1]
)
)Le résultat est très précis. Le modèle donne d'assez bons résultats bien qu'il n'ait que 3 milliards de paramètres.
Si vous rencontrez des difficultés pour accéder aux modèles légers du Llama 3.2, veuillez consulter le carnet de notes, Accès aux modèles légers du Llama 3.2.
L'accès au modèle Vision est simple et vous n'avez pas à vous soucier de la mémoire du GPU, car nous utiliserons plusieurs GPU dans ce guide.
Source : Meta | Llama 3.2 Vision | Kaggle
Source : Meta | Llama 3.2 Vision | Kaggle
%%capture
%pip install -U transformers accelerateimport torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
base_model = "/kaggle/input/llama-3.2-vision/transformers/11b-vision-instruct/1"
processor = AutoProcessor.from_pretrained(base_model)
model = MllamaForConditionalGeneration.from_pretrained(
base_model,
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16,
device_map="auto",
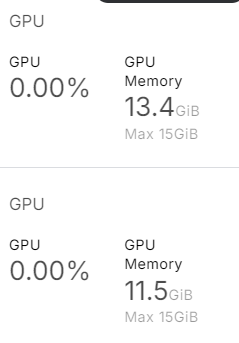
)Comme nous pouvons le voir, il utilise près de 25 Go de mémoire GPU. Il sera impossible de l'exécuter sur un ordinateur portable ou sur la version gratuite de Google Colab.
import requests
from PIL import Image
url = "https://media.datacamp.com/cms/google/ad_4nxcz-j3ir2begccslzay07rqfj5ttakp2emttn0x6nkygls5ywl0unospj2s0-mrwpdtmqjl1fagh6pvkkjekqey_kwzl6qnodf143yt66znq0epflvx6clfoqw41oeoymhpz6qrlb5ajer4aeniogbmtwtd.png"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Describe the tutorial feature image."}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=120)
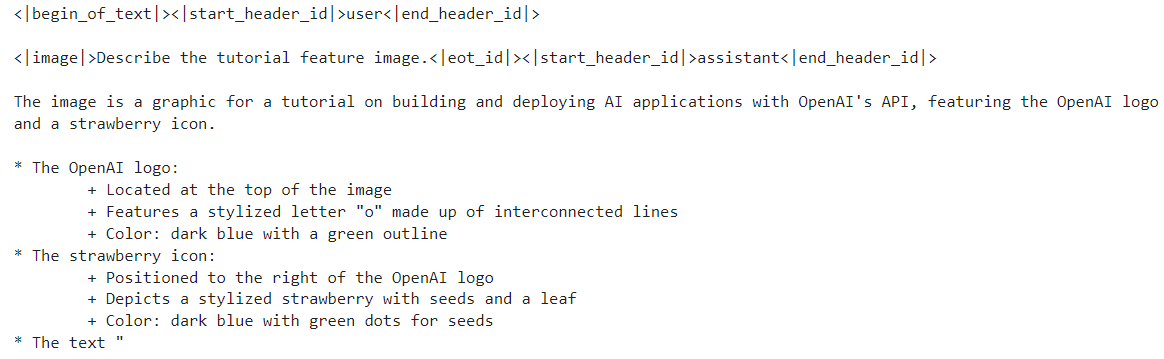
print(processor.decode(output[0]))Nous obtenons ainsi une description détaillée de l'image. Il est assez précis.
Si vous rencontrez des problèmes lors de l'exécution du code ci-dessus, veuillez vous référer à la section Accès aux modèles de vision Llama 3.2 Carnet de notes Kaggle.
Dans cette section, nous allons apprendre à affiner le modèle Llama 3.2 3B Instruct à l'aide de la bibliothèque Transformers sur l'ensemble de données d'assistance à la clientèle. Nous utiliserons Kaggle pour accéder à des GPU gratuits et obtenir une RAM supérieure à celle de Colab.
Lancez le nouveau notebook sur Kaggle et définissez les variables d'environnement. Nous utiliserons l'API Hugging Face pour enregistrer le modèle et Weights & Biases pour suivre ses performances.
Installez et mettez à jour tous les paquets Python nécessaires.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandbChargez les paquets et fonctions Python que nous utiliserons tout au long du processus de mise au point et d'évaluation.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_formatConnectez-vous à Hugging Face CLI en utilisant la clé d'API.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Connectez-vous à Weights & Biases en utilisant la clé API et instanciez le nouveau projet.
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama 3.2 on Customer Support Dataset',
job_type="training",
anonymous="allow"
)Définissez les variables pour le mode de base, le jeu de données et le nom du nouveau modèle. Nous les utiliserons à plusieurs endroits dans ce projet, il est donc préférable de les définir dès le départ pour éviter toute confusion.
base_model = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
new_model = "llama-3.2-3b-it-Ecommerce-ChatBot"
dataset_name = "bitext/Bitext-customer-support-llm-chatbot-training-dataset"Définissez le type de données et la mise en œuvre de l'attention.
# Set torch dtype and attention implementation
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
else:
torch_dtype = torch.float16
attn_implementation = "eager"Chargez le modèle et le tokenizer en fournissant le répertoire du modèle local. Même si notre modèle est petit, le chargement du modèle complet et sa mise au point prendront un certain temps. Au lieu de cela, nous chargerons le modèle avec une quantification sur 4 bits.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)Nous chargerons le Bitext-customer-support-llm-chatbot du hub Hugging Face. Il s'agit d'un ensemble de données synthétiques hybrides que nous utiliserons pour créer notre propre chatbot personnalisé d'assistance à la clientèle.
Nous chargerons, mélangerons et sélectionnerons seulement 1000 échantillons. Nous affinons le modèle sur un petit sous-ensemble afin de réduire le temps d'apprentissage, mais vous pouvez toujours sélectionner le modèle complet.
Ensuite, nous créerons la colonne "texte" à l'aide des instructions du système, des demandes de l'utilisateur et des réponses de l'assistant. Ensuite, nous convertirons la réponse JSON au format chat.
#Importing the dataset
dataset = load_dataset(dataset_name, split="train")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
instruction = """You are a top-rated customer service agent named John.
Be polite to customers and answer all their questions.
"""
def format_chat_template(row):
row_json = [{"role": "system", "content": instruction },
{"role": "user", "content": row["instruction"]},
{"role": "assistant", "content": row["response"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= 4,
)
Comme vous pouvez le constater, nous avons combiné la demande du client et la réponse de l'assistant sous la forme d'un chat.
dataset['text'][3]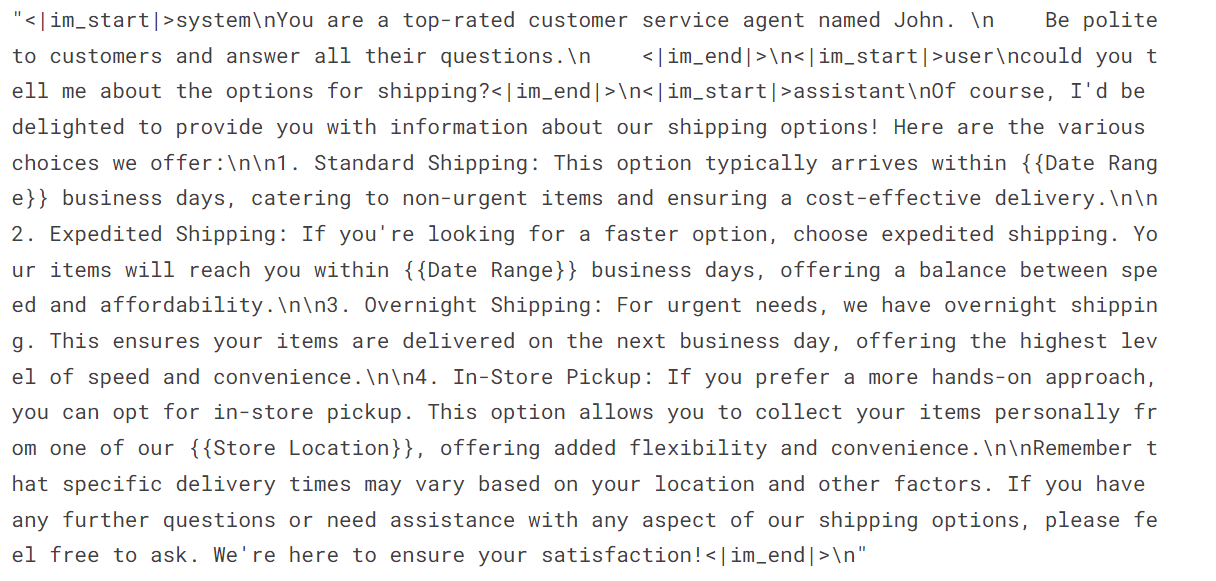
Extraire le nom du modèle linéaire du modèle.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)Utilisez le nom du module linéaire pour créer l'adoptant LoRA. Nous nous contenterons d'affiner l'adoption de LoRA et laisserons le reste du modèle pour économiser de la mémoire et accélérer le temps de formation.
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = get_peft_model(model, peft_config)Nous configurons les hyperparamètres du modèle pour l'exécuter dans l'environnement Kaggle. Vous pouvez comprendre chaque hyperparamètre en vous référant à la section Réglage fin du lama 2 et en le modifiant pour optimiser l'entraînement sur votre système.
#Hyperparamter
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)Nous allons maintenant mettre en place un formateur de réglage fin supervisé (SFT) et fournir un ensemble de données de formation et d'évaluation, une configuration LoRA, un argument de formation, un tokenizer et un modèle.
# Setting sft parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Lancez le processus de formation et surveillez les mesures de perte de formation et de validation.
trainer.train()La perte de formation s'est progressivement réduite. Ce qui est bon signe.
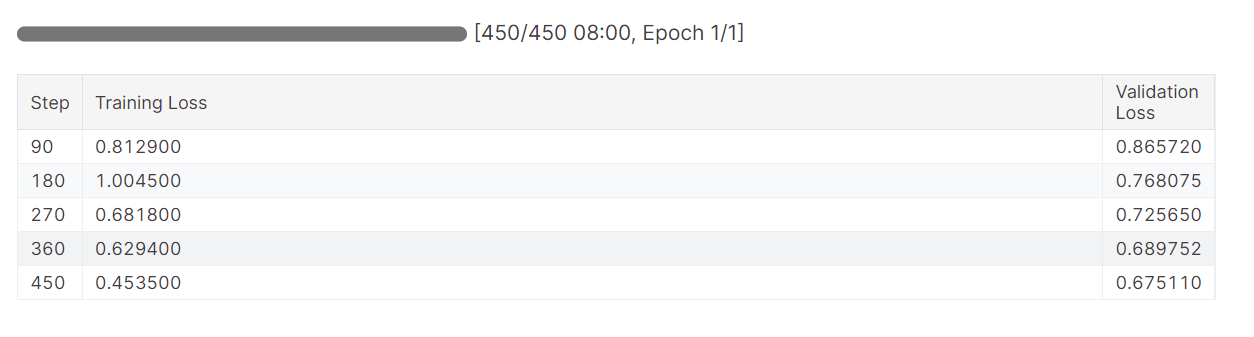
L'historique détaillé de l'exécution est généré à la fin de l'exécution de l'analyse des poids et des biais.
wandb.finish()
Vous pouvez toujours consulter le tableau de bord Pondérations et Biais pour examiner en détail les métriques du modèle.
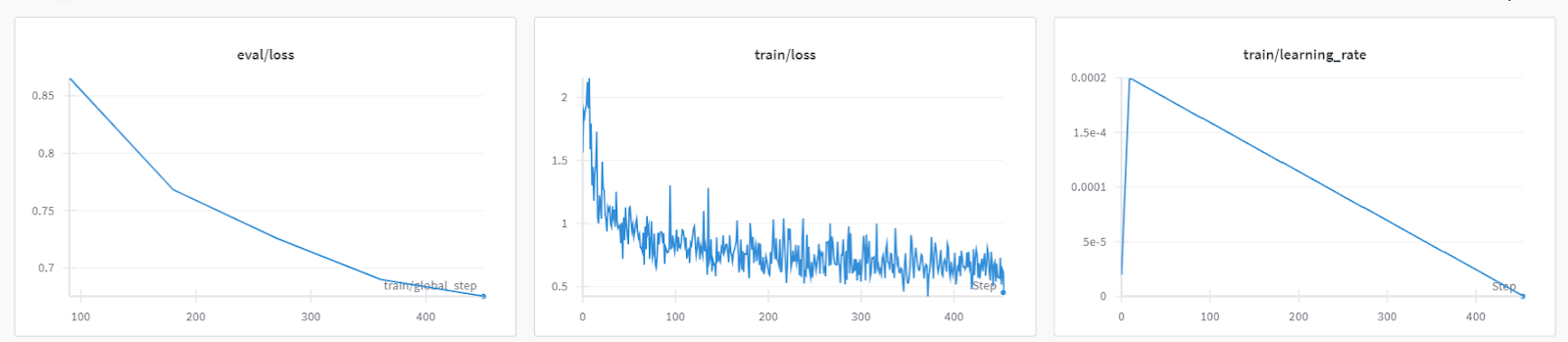
Pour tester le modèle affiné, nous lui fournirons l'exemple d'invite de l'ensemble de données.
messages = [{"role": "system", "content": instruction},
{"role": "user", "content": "I bought the same item twice, cancel order {{Order Number}}"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=150, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])Le modèle affiné a adopté le style et fourni une réponse précise.

Enregistrez le modèle affiné localement et envoyez-le également vers le hub Hugging Face. La fonction push_to_hub créera un nouveau référentiel de modèles et poussera les fichiers de modèles vers votre référentiel Hugging Face.
# Save the fine-tuned model
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)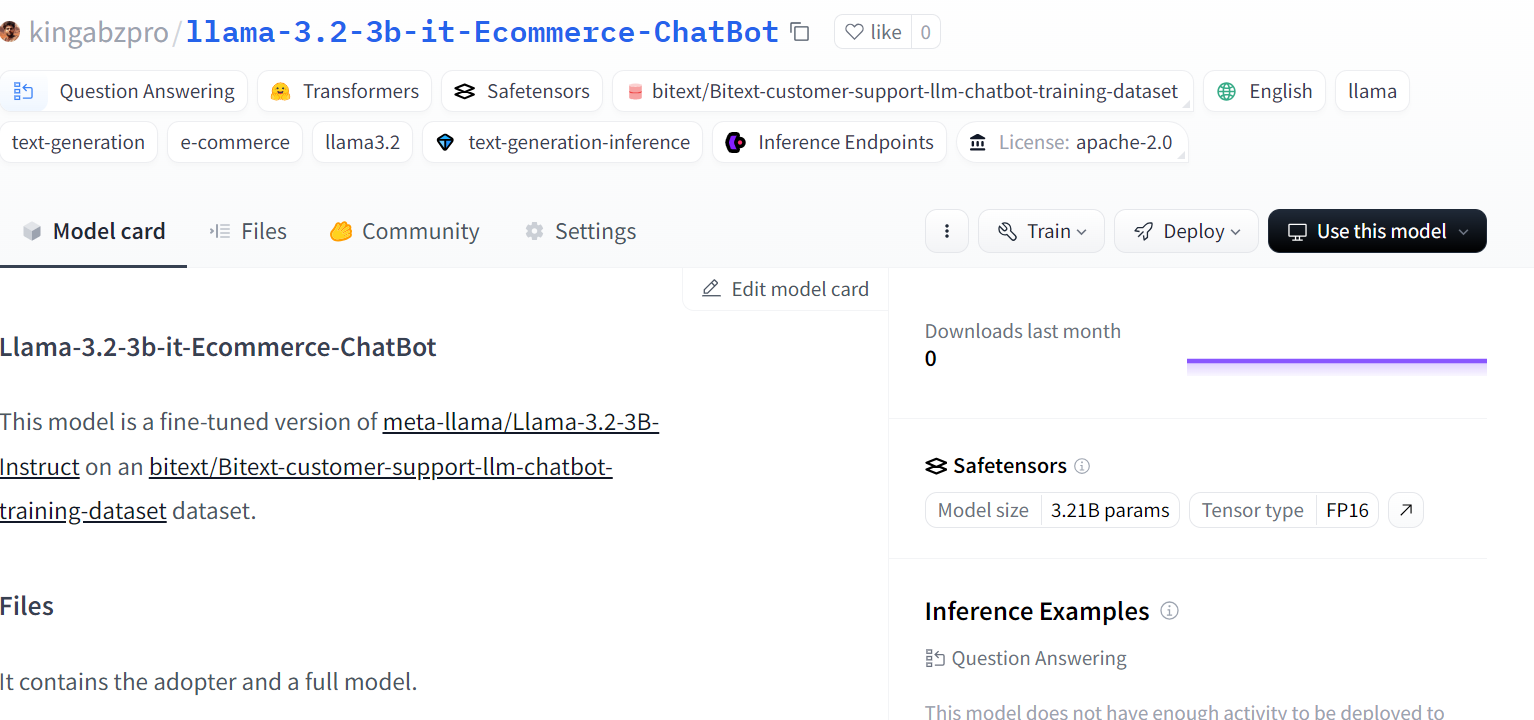
Source : kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot
Pour affiner les grands modèles de Llama 3, vous pouvez consulter les documents suivants Mise au point de Llama 3.1 pour la classification de texte pour le tutoriel sur la classification de texte. Ce tutoriel est très populaire et vous aidera à trouver les LLM sur la tâche complète.
Cliquez sur le bouton "Enregistrer la version" en haut à droite, sélectionnez l'option d'enregistrement rapide et modifiez l'option d'enregistrement de sortie pour enregistrer le fichier de modèle et l'ensemble du code.
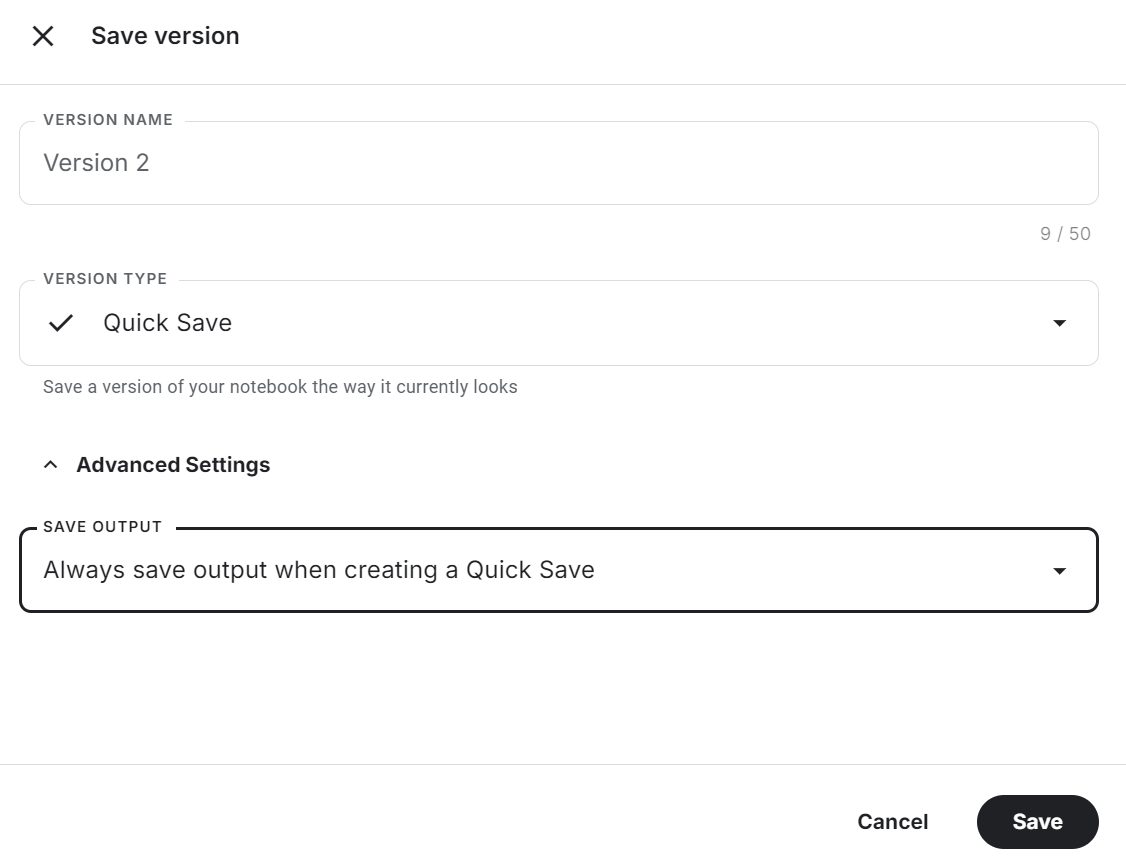
Consultez la page Ajustez Llama 3.2 sur le support client Notebook Kaggle pour la source du code, les résultats et la sortie.
Il s'agit d'un guide fortement axé sur le code. Si vous recherchez un guide sans code ou à faible code pour affiner les LLM, consultez le guide du débutant de l'interface WebUI de LlaMA-Factory à l'adresse: Réglage fin des LLM.
Nous allons créer un nouveau carnet et ajouter le carnet précédemment enregistré pour accéder à l'adaptateur LoRA ajusté afin d'éviter tout problème de mémoire.
Assurez-vous que vous avez également ajouté le modèle de base "Llama 3.2 3B Instruct".
Installez et mettez à jour tous les paquets Python nécessaires.
%%capture
%pip install -U bitsandbytes
%pip install transformers==4.44.2
%pip install -U accelerate
%pip install -U peft
%pip install -U trlConnectez-vous à l'interface de programmation de Hugging Face pour envoyer le modèle fusionné au hub de Hugging Face.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Fournissez l'emplacement au modèle de base et affinez LoRA. Nous les utiliserons pour charger le modèle de base et le fusionner avec l'adaptateur.
# Model
base_model_url = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
new_model_url = "/kaggle/input/fine-tune-llama-3-2-on-customer-support/llama-3.2-3b-it-Ecommerce-ChatBot/"Chargez le tokenizer et le modèle complet.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model_url)
base_model_reload= AutoModelForCausalLM.from_pretrained(
base_model_url,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto",
)Appliquer le format de chat au modèle et au tokenizer. Ensuite, fusionnez le modèle de base avec l'adaptateur LoRA.
# Merge adapter with base model
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
model = PeftModel.from_pretrained(base_model_reload, new_model_url)
model = model.merge_and_unload()Pour vérifier si le modèle a été fusionné avec succès, fournissez-lui l'invite d'échantillons et générez le repos.
instruction = """You are a top-rated customer service agent named John.
Be polite to customers and answer all their questions.
"""
messages = [{"role": "system", "content": instruction},
{"role": "user", "content": "I have to see what payment payment modalities are accepted"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=150, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])Comme nous pouvons le constater, notre modèle perfectionné fonctionne parfaitement.

Enregistrez localement le tokenizer et le modèle.
new_model = "llama-3.2-3b-it-Ecommerce-ChatBot"
model.save_pretrained(new_model)
tokenizer.save_pretrained(new_model)Transférez le tokenizer et le modèle fusionné dans le référentiel de modèles Hugging Face.
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)Après quelques minutes, vous pouvez visualiser tous les fichiers de modèles avec les fichiers de métadonnées dans votre référentiel Hugging Face.
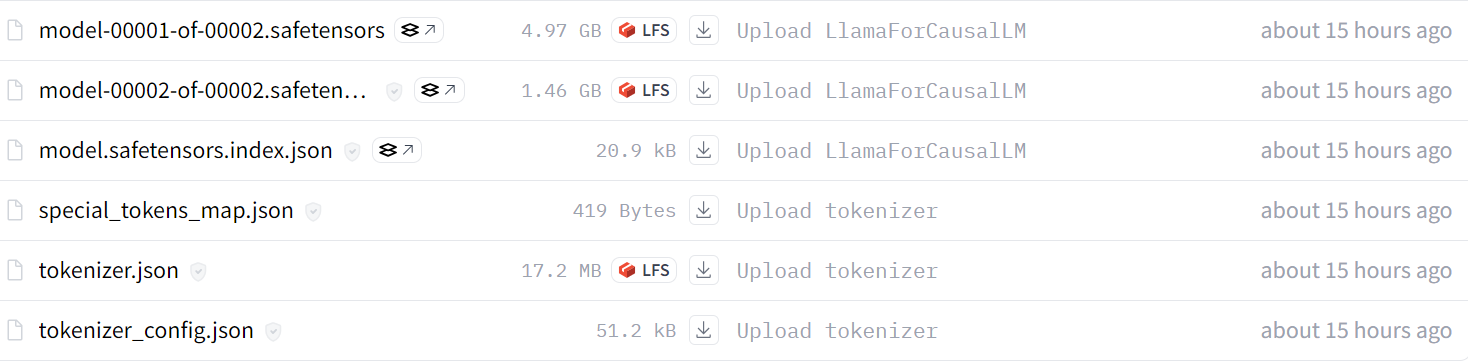
Source : kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot
Vous pouvez également consulter le code source dans la section Fusion et exportation du lama 3.2 affiné Kaggle notebook pour en savoir plus sur la fusion et le téléchargement de votre modèle dans le hub Hugging Face.
La prochaine étape de ce projet consiste à convertir le modèle complet au format GGUF et à le quantifier. Ensuite, vous pouvez l'utiliser localement à l'aide de votre application de chat préférée comme Jan, Msty ou GPT4ALL. Suivez le Ajuster le lama 3 et l'utiliser localement pour apprendre à convertir tous les LLM au format GGUF et à les utiliser localement sur votre ordinateur portable.
Pour utiliser le modèle affiné localement, nous devons d'abord le convertir au format GGUF. Pourquoi ? Parce qu'il s'agit d'un format llama.cpp et qu'il est accepté par toutes les applications de chatbot de bureau.
La conversion du modèle fusionné au format llama.ccp est assez facile. Il suffit de se rendre sur le site GGUF My Repo Hugging Face Hub. Connectez-vous avec votre compte Hugging Face. Tapez le lien du dépôt de modèle affiné "kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot" et appuyez sur le bouton "Submit".
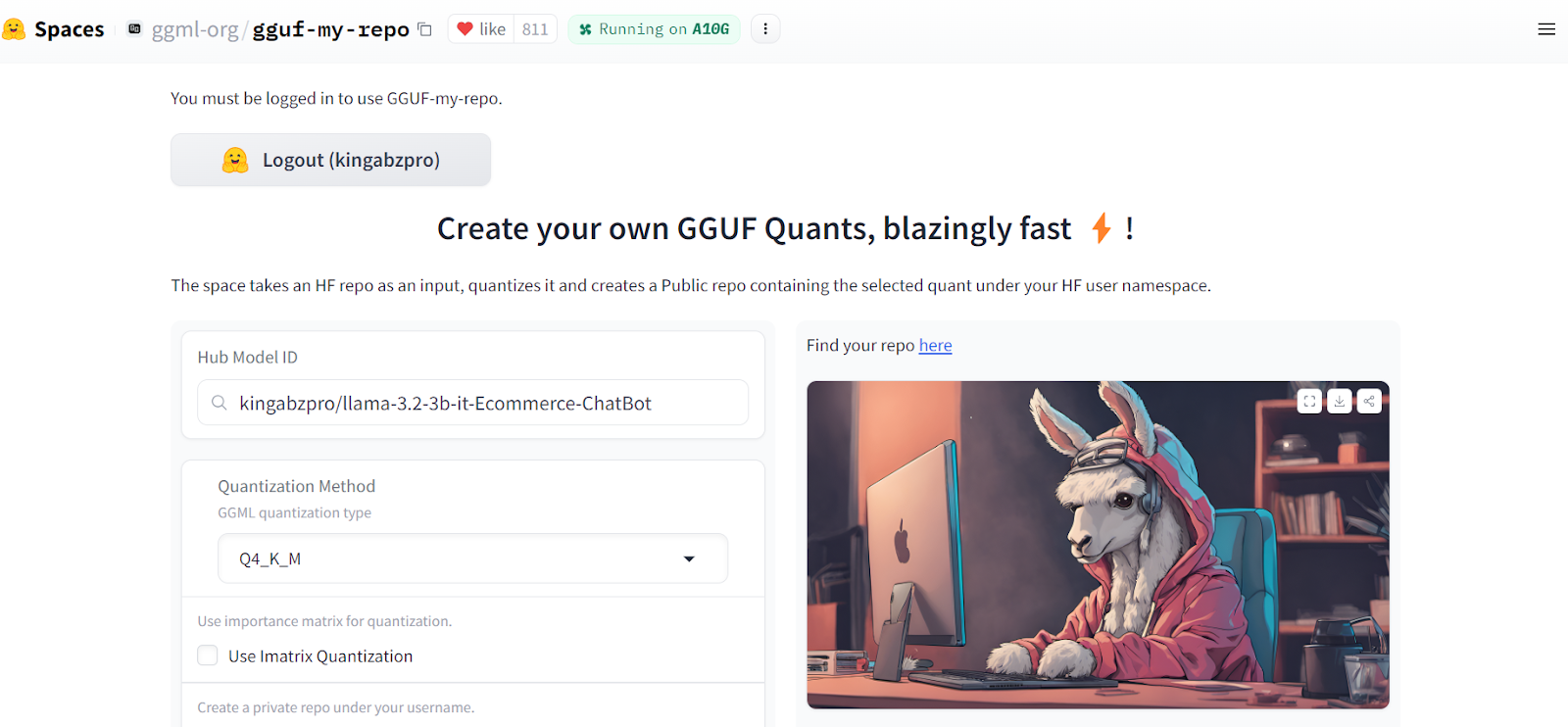
Source : GGUF My Repo
En quelques secondes, la version quantifiée du modèle sera créée dans un nouveau référentiel Hugging Face.
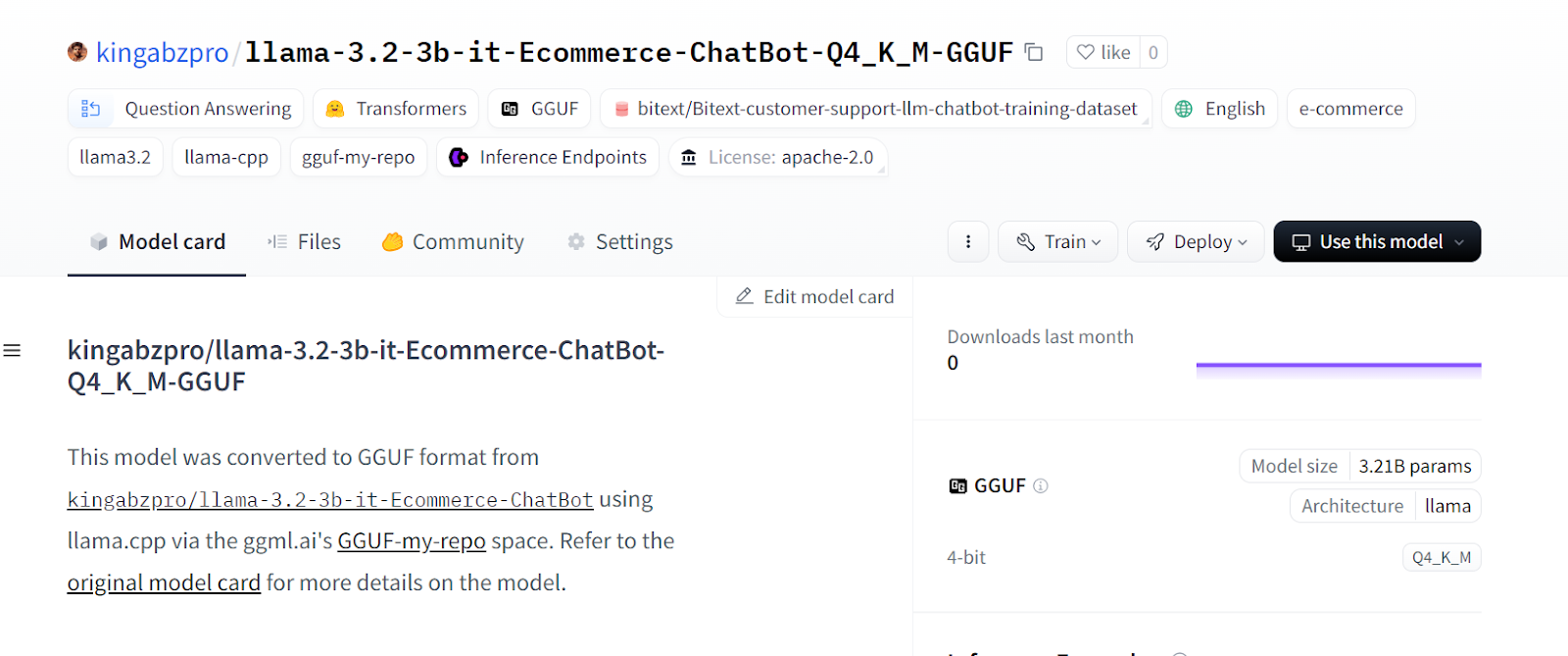
Source : kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot-Q4_K_M-GGUF
Cliquez sur l'onglet "Fichiers" et téléchargez uniquement le fichier GGUF.
Source : llama-3.2-3b-it-ecommerce-chatbot-q4_k_m.gguf
Nous utiliserons le Jan pour utiliser localement notre modèle affiné. Rendez-vous sur le site officiel, jan.ai, pour télécharger et installer l'application.
Source : Jan
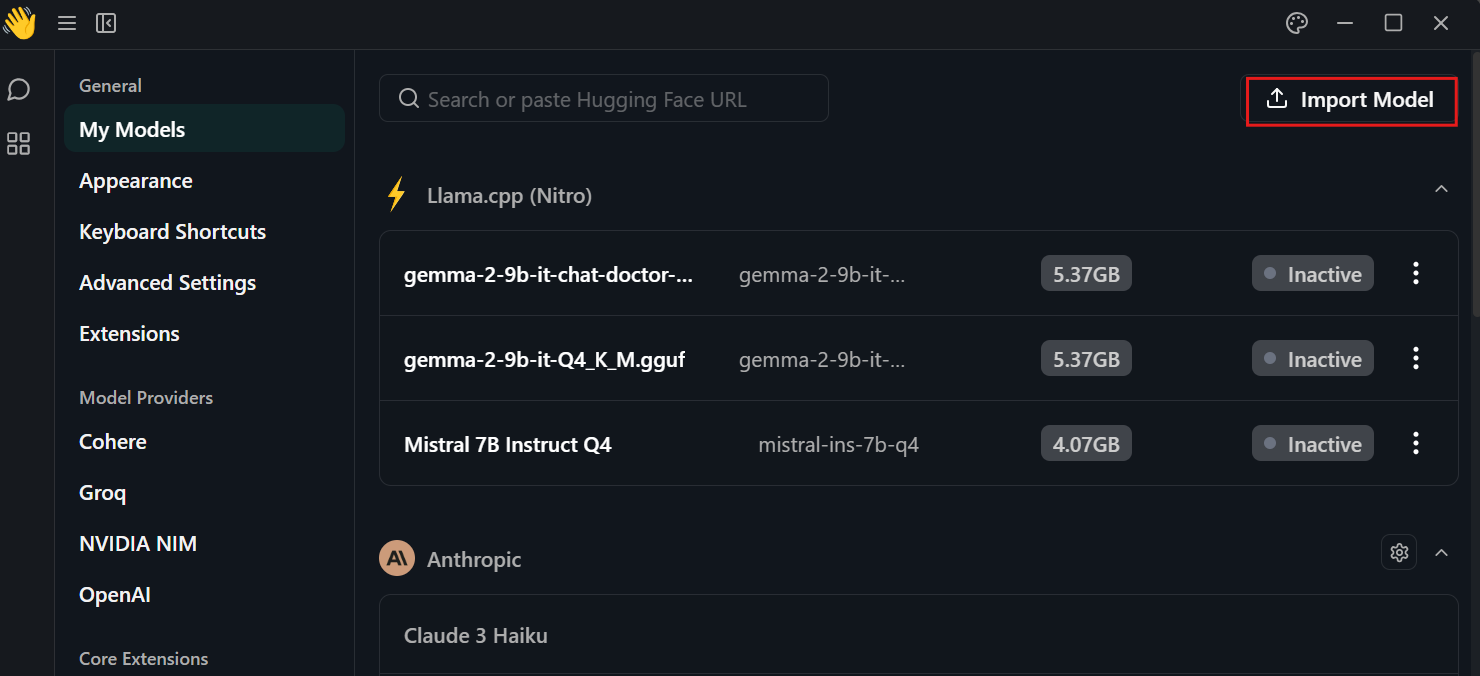
Cliquez sur le paramètre, sélectionnez le menu "Mes modèles" et appuyez sur le bouton "Importer un modèle". Ensuite, fournissez-lui le répertoire local du modèle.
Allez dans le menu "chat" et sélectionnez le modèle affiné, comme indiqué ci-dessous.
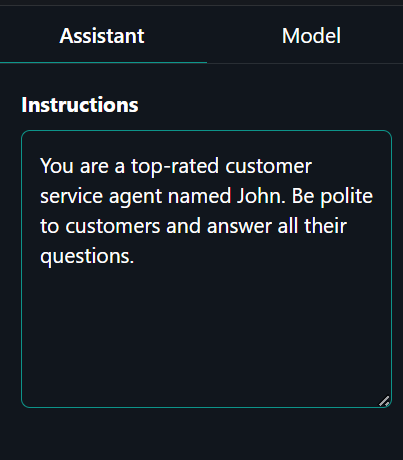
Cliquez sur l'onglet "Assistant" dans le panneau de droite et tapez l'invite du système.
Invite du système : "Vous êtes un agent du service clientèle de premier ordre nommé John. Soyez poli avec les clients et répondez à toutes leurs questions".
Cliquez sur l'onglet "Modèle", juste à côté de l'onglet "Assistant" et changez le stop token en "<|eot_id|>"
C'est tout. Tout ce que vous avez à faire, c'est de demander au service d'assistance à la clientèle de l'IA de vous expliquer le problème auquel vous êtes confronté.
Prompt : "Comment commander plusieurs articles auprès du même fournisseur ?
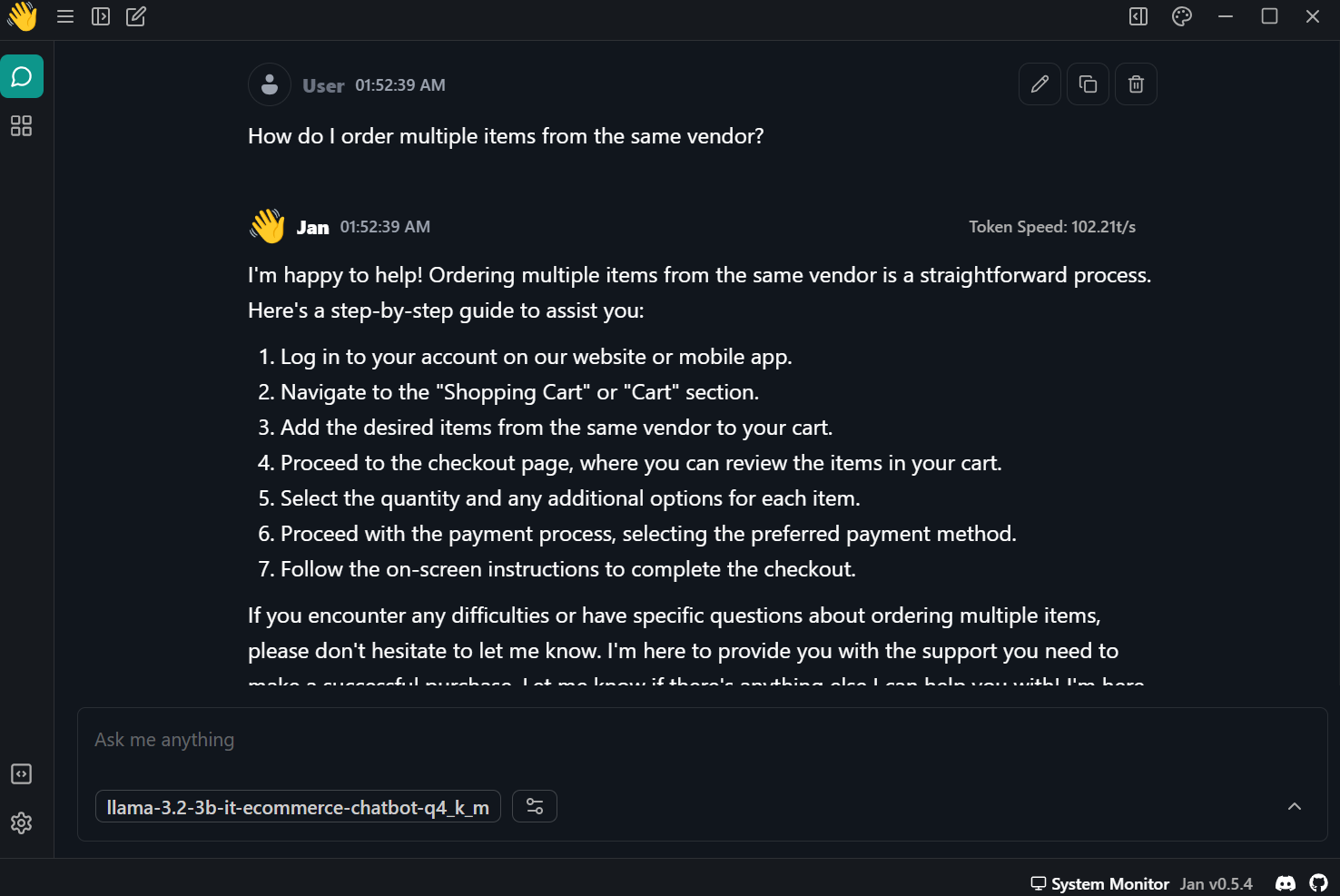
La réponse a été précise et très rapide - près de 102 jetons par seconde.
Le réglage fin des petits LLM nous permet de réduire les coûts et d'améliorer le temps d'inférence. Avec suffisamment de données, vous pouvez améliorer les performances du modèle pour certaines tâches proches de celles du GPT-4-mini. En bref, l'avenir de l'IA passe par l'utilisation de plusieurs LLM plus petits dans une grille avec une relation maître-esclave.
Le modèle principal recevra l'invite initiale et décidera du modèle spécialisé à utiliser pour générer les réponses. Cela permettra de réduire le temps de calcul, d'améliorer les résultats et de réduire les coûts de fonctionnement.
Dans ce tutoriel, nous avons appris à connaître Llama 3.2 et à y accéder dans Kaggle. Nous avons également appris à affiner le modèle léger Llama 3.2 sur l'ensemble de données d'assistance à la clientèle afin qu'il apprenne à répondre dans un certain style et à fournir des informations précises spécifiques au domaine. Nous avons ensuite fusionné l'adaptateur LoRA avec le modèle de base et poussé le modèle complet vers le Hugging Face Hub. Enfin, nous avons converti le modèle fusionné au format GGUF et l'avons utilisé localement sur l'ordinateur portable avec l'application Jan chatbot.
Prenez notre Travailler avec Hugging Face pour apprendre à utiliser l'outil et à affiner les modèles.
Principaux cours de LLM
Cursus
Cursus
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach