
Cursus
Développer des applications d'IA
21 h
L'époque où nous nous contentions de grands modèles de langage qui ne peuvent traiter que du texte. Nous exigeons aujourd'hui multimodaux capables de comprendre et d'interagir avec du texte, des images et des vidéos.
Entrez Modèles de vision Llama 3.2 11B & 90BLlama est le premier modèle multimodal open-source de Meta AI, capable de traiter à la fois des textes et des images.
Dans ce guide pratique, je vais vous guider à travers le processus de création d'un assistant de support client multimodal avec l'aide de Llama 3.2 et de Gradio. À la fin de ce tutoriel, vous disposerez d'une application web entièrement fonctionnelle capable d'analyser les descriptions textuelles et les images téléchargées afin de générer des solutions utiles, à l'instar d'un assistant de support technique !
Si vous avez besoin d'une introduction rapide à Llama 3.2 avant de commencer, je vous recommande de lire ce Guide Llama 3.2.
Dans cette démonstration pratique, nous utiliserons le modèle Llama3.2-11B-Vision (multimodal). Avant de commencer à coder, assurons-nous que nous disposons de toutes les dépendances nécessaires.
Nous avons besoin de quelques bibliothèques pour que tout fonctionne. Les principaux sont les suivants :
Exécutez les commandes suivantes pour installer les dépendances nécessaires :
!pip3 install -U transformers bitsandbytes accelerate peft -q
!pip3 install gradio -qChargeons maintenant le modèle et le processeur du Llama 3.2. Nous utiliserons Hugging Facepour charger le modèle et le processeur, en s'assurant que le modèle tourne sur le GPU s'il est disponible, ou par défaut sur le CPU dans le cas contraire. Comme il s'agit d'un modèle à 11B paramètres, il fonctionne bien sur un GPU A100 dans Google Colab.
Dans le bloc de code ci-dessous :
tie_weight(), qui garantit que les poids des couches d'intégration d'entrée et de sortie sont identiques. Cela réduit la consommation de mémoire et peut améliorer les performances.import torch
from PIL import Image
import gradio as gr
from transformers import MllamaForConditionalGeneration, AutoProcessor
def load_model():
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
device = "cuda" if torch.cuda.is_available() else "cpu" # Check if GPU is available
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto", # Automatically map to available device
offload_folder="offload", # Offload to disk if necessary
)
model.tie_weights() # Tying weights for efficiency
processor = AutoProcessor.from_pretrained(model_id)
print(f"Model loaded on: {device}")
return model, processorGradio est une bibliothèque Python légère qui nous permet de construire rapidement des apps d'apprentissage automatique avec des interfaces web. Au lieu d'écrire du HTML ou du JavaScript complexe, nous pouvons définir les composants de notre application (comme des zones de texte, des boutons ou des images) directement en Python.
Voici à quoi ressemble l'interface utilisateur de base de Gradio :
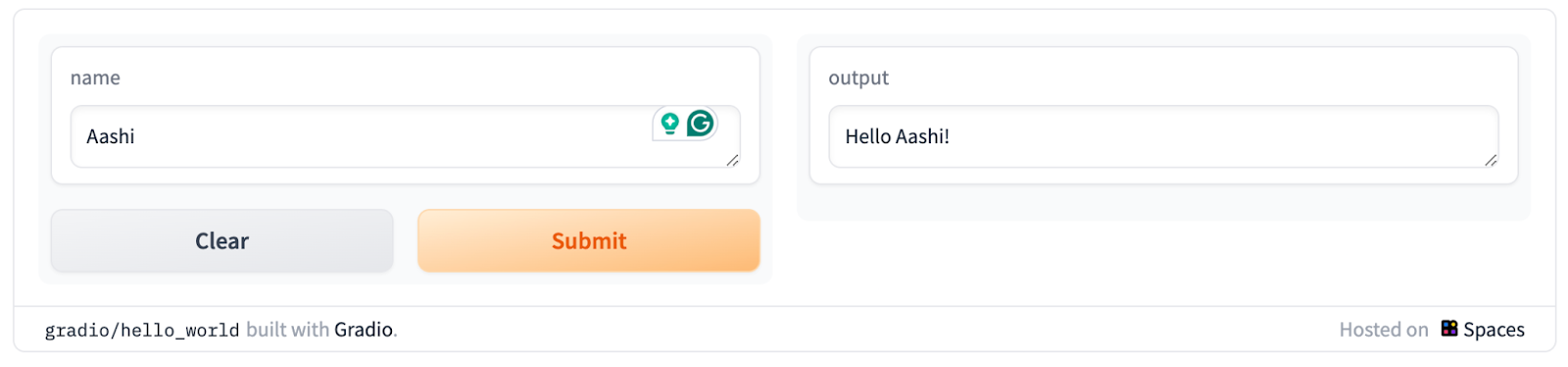
Gradio présente quelques avantages :
Pour cette démo, Gradio permet aux utilisateurs de saisir facilement du texte et des images et de voir le résultat (l'analyse du texte et de l'image, dans ce cas) en temps réel. Il est parfait pour présenter la puissance de modèles tels que Llama 3.2 dans un environnement convivial.
Maintenant que nous avons configuré nos importations et notre modèle, passons à la partie principale de l'application, à savoir le traitement des entrées (texte et image) et la génération de la réponse.
Nous commençons par définir une fonction qui prend en compte le texte de l'utilisateur et, éventuellement, une image. Cette fonction utilise ensuite le modèle Llama 3.2 pour générer une réponse.
def process_ticket(text, image=None):
model, processor = load_model()
try:
if image:
# Resize the image for consistency
image = image.convert("RGB").resize((224, 224))
prompt = f"<|image|><|begin_of_text|>{text}"
# Process both the image and text input
inputs = processor(images=[image], text=prompt, return_tensors="pt").to(model.device)
else:
prompt = f"<|begin_of_text|>{text}"
# Process text-only input
inputs = processor(text=prompt, return_tensors="pt").to(model.device)
# Generate response (restrict token length for faster output)
outputs = model.generate(**inputs, max_new_tokens=200)
# Decode the response from tokens to text
response = processor.decode(outputs[0], skip_special_tokens=True)
return response
except Exception as e:
print(f"Error processing ticket: {e}")
return "An error occurred while processing your request."Cette fonction gère deux types d'entrées dans la boucle :
Une fois le type d'entrée identifié, il est transmis à un processeur issu de la bibliothèque de transformateurs pour traiter l'entrée. Ensuite, le modèle génère une sortie dans la plage de max_new_tokens.
L'interface Gradio relie le tout et nous permet d'exécuter des tests dans un format basé sur le web. Cette interface permet aux utilisateurs de soumettre un texte et des images d'un problème auquel ils sont confrontés et de voir la solution générée par l'IA.
Jetons un coup d'œil au code et expliquons-le.
def create_interface():
text_input = gr.Textbox(
label="Describe your issue",
placeholder="Describe the problem you're experiencing",
lines=4,
)
image_input = gr.Image(label="Upload a Screenshot (Optional)", type="pil")
# Output element
output = gr.Textbox(label="Suggested Solution", lines=5)
# Create the Gradio interface
interface = gr.Interface(
fn=process_ticket, # Function to process inputs
inputs=[text_input, image_input], # User inputs (text and image)
outputs=output, # AI-generated output
title="Multimodal Customer Support Assistant",
description="Submit a description of your issue, along with an optional screenshot, and get AI-powered suggestions.",
)
# Launch the interface with debug mode
interface.launch(debug=True)Dans le code ci-dessus, nous :
text_input pour le texteimage_input pour l'imagedebug = True pour déboguer les erreurs. Une fois que le code fonctionne correctement, repassez à False.L'interface finale se présentera comme suit :
L'application Gradio, notre assistant multimodal d'assistance à la clientèle, est prête ! Pour obtenir la réponse souhaitée, essayez de modifier le paramètre max_new_tokens ou de jouer un peu avec l'invite.
Outre la démo que nous avons créée dans ce tutoriel, il existe quelques autres cas d'utilisation qui nécessitent un minimum d'effort. Il s'agit notamment de
Pour chaque cas d'utilisation, il y a quelques conseils que chaque développeur peut utiliser lors du développement d'une application comme celle que nous avons déjà construite. Voici quelques bonnes pratiques qu'un développeur peut adopter lorsqu'il travaille avec des modèles tels que llama3.2.
Les tâches multimodales pouvant être gourmandes en ressources, il est essentiel de réduire le temps de latence. Envisagez d'optimiser le modèle pour obtenir des réponses plus rapides en utilisant la mise en cache, l'élagage du modèle ou en limitant le nombre de jetons générés.
Il est important de mettre en place des mécanismes pour gérer les erreurs. Dans les cas où le modèle ne parvient pas à générer une réponse significative (par exemple, en raison de la mauvaise qualité de l'image), nous pouvons fournir des réponses de repli ou des messages d'erreur. Nous pouvons même opter pour un retour d'information humain qui, en retour, permet d'améliorer le modèle.
Le cursus des performances de l'appli, comme les temps de réponse et les données d'interaction avec l'utilisateur, peut permettre d'optimiser l'interface et même d'améliorer l'expérience utilisateur. En notant le temps de performance, nous pouvons essayer d'optimiser la latence du modèle en utilisant des bibliothèques comme bits and bytes.
Dans ce guide, nous avons appris à combiner les capacités multimodales de Llama 3.2 et l'interface intuitive de Gradio. De l'assistance à la clientèle à l'éducation en passant par la création de contenu, les applications potentielles sont vastes et variées.
En adhérant aux meilleures pratiques telles que la gestion de la latence, la gestion des erreurs et le contrôle des performances, nous pouvons nous assurer que nos applications Llama 3.2 et Gradio sont robustes, efficaces et conviviales.
Pour en savoir plus, je vous recommande ces tutoriels :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours