
Cours
Déploiement MLOps et cycle de vie
4 h
12K
Llama Stack est un cadre conçu pour rationaliser le développement et le déploiement d'applications d'IA générative basées sur les modèles Llama de Meta. modèles Llama de Meta. Il y parvient en fournissant une collection d'API et de composants normalisés pour des tâches telles que l'inférence, la sécurité, la gestion de la mémoire et les capacités des agents.
Voici ses objectifs et ses avantages :
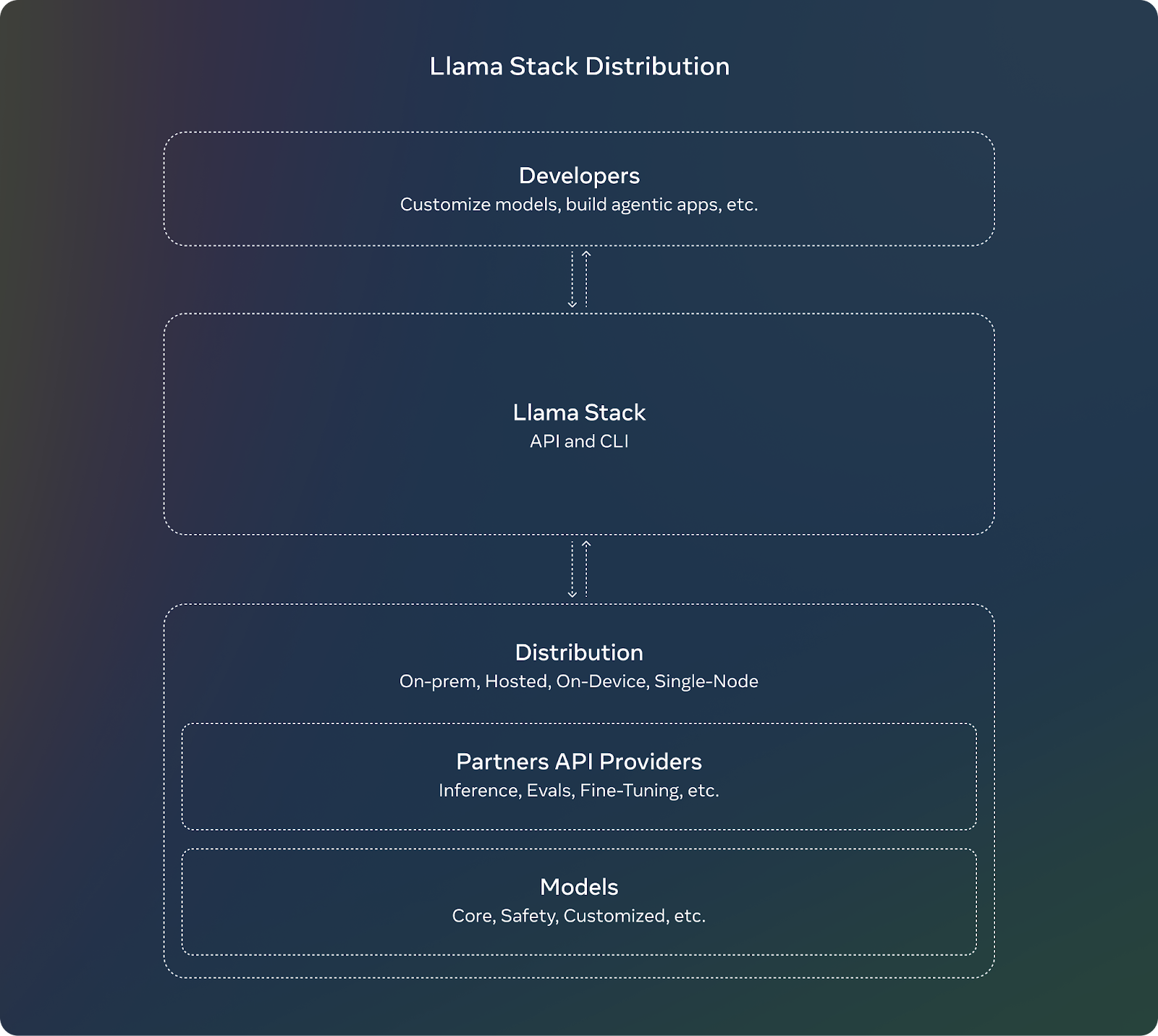
Source : Meta AI
Llama Stack est livré avec plusieurs API, chacune ciblant un ensemble spécifique de tâches dans la construction d'une application d'IA générative.
L'API Inférence gère la génération de texte ou d'invites multimodale variations du lama. Ses principales caractéristiques sont les suivantes :
L'API définit diverses configurations permettant aux développeurs de contrôler le comportement du modèle (par exemple, FP8 ou BF16 quantification) en fonction des exigences de leur application.
L'API de sécurité est conçue pour un déploiement responsable des modèles d'IA en modérant le contenu et en filtrant les résultats nuisibles ou potentiellement biaisés. Il peut être configuré pour définir des niveaux de violation (par exemple, INFO, WARN, ERROR) et pour renvoyer des messages exploitables aux utilisateurs.
L'API Mémoire permet de conserver les interactions passées et d'y faire référence, et de créer des conversations plus cohérentes qui tiennent compte du contexte. La variété des configurations de mémoire permet aux développeurs de choisir les types de stockage en fonction des besoins de l'application. Ses principales caractéristiques sont les suivantes :
L'API Agentic permet aux LLM d'utiliser des outils et des fonctions externes, ce qui leur permet d'effectuer des tâches telles que la recherche sur le web, l'exécution de code ou la récupération de mémoire. L'API permet aux développeurs de configurer agents avec des outils et des objectifs spécifiques. Il prend en charge les interactions à tours multiples où chaque tour se compose de plusieurs étapes. Ses principales caractéristiques sont les suivantes :
Voici les autres API que Llama Stack propose :
Nous mettrons en œuvre un exemple de projet sur Llama Stack afin de nous familiariser avec l'idée générale et les capacités de ce cadre.
Avant de commencer, sachez que
Commençons par configurer l'interface de ligne de commande (CLI) de Llama.
La pile Llama fournit une interface en ligne de commande (CLI) pour gérer les distributions, installer les modèles et configurer les environnements. Voici les étapes d'installation à suivre :
a. Créer et activer un environnement virtuel :
conda create -n llama_stack python=3.10
conda activate llama_stackb. Clonez le dépôt Llama Stack :
git clone <https://github.com/meta-llama/llama-stack.git>
cd llama-stackc. Installez les dépendances nécessaires :
pip install llama-stack
pip install -r requirements.txtLes conteneurs Docker simplifient le déploiement du serveur Llama Stack et des fournisseurs d'API d'agents. Des images Docker préconstruites sont disponibles pour faciliter l'installation :
docker pull llamastack/llamastack-local-gpu
llama stack build
llama stack configure llamastack-local-gpuCes commandes extraient l'image Docker, la construisent et configurent la pile.
Construisons un chatbot de base en utilisant les API de la Pile à Llamas. Voici les étapes à suivre :
Nous exécuterons le serveur sur le port 5000. Assurez-vous que le serveur fonctionne avant d'utiliser les API :
llama stack run local-gpu --port 5000Après avoir installé la pile Llama, vous pouvez utiliser du code client pour interagir avec ses API. Utilisez l'API Inference pour générer des réponses basées sur les données de l'utilisateur :
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url="<http://localhost:5000>")
user_input = "Hello! How are you?"
response = client.inference.chat_completion(
model="Llama3.1-8B-Instruct",
messages=[{"role": "user", "content": user_input}],
stream=False
)
print("Bot:", response.text)Note : Remplacez "Llama3.1-8B-Instruct" par le nom du modèle disponible dans votre installation.
Mettez en œuvre l'API de sécurité pour modérer les réponses et vous assurer qu'elles sont appropriées :
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": response.text}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
print("Unsafe content detected.")
else:
print("Bot:", response.text)Créez la conscience du contexte du chatbot en stockant et en récupérant l'historique des conversations :
### building a memory bank that can be used to store and retrieve context.
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)Nous pouvons ensuite combiner les API pour créer un chatbot robuste :
Voici le code complet après avoir suivi toutes les étapes :
import uuid
client = LlamaStackClient(base_url="<http://localhost:5000>")
### create a memory bank at the start
bank = client.memory.create_memory_bank(
name="chat_memory",
config=VectorMemoryBankConfig(
type="vector",
embedding_model="all-MiniLM-L6-v2",
chunk_size_in_tokens=512,
overlap_size_in_tokens=64,
)
)
def get_bot_response(user_input):
### retrieving conversation history
query_response = client.memory.query_documents(
bank_id=bank.bank_id,
query=[user_input],
params={"max_chunks": 10}
)
history = [chunk.content for chunk in query_response.chunks]
### preparing messages with history
messages = [{"role": "user", "content": user_input}]
if history:
messages.insert(0, {"role": "system", "content": "\\n".join(history)})
### generate response
response = client.inference.chat_completion(
model="llama-2-7b-chat",
messages=messages,
stream=False
)
bot_response = response.text
### safety check
safety_response = client.safety.run_shield(
messages=[{"role": "assistant", "content": bot_response}],
shield_type="llama_guard",
params={}
)
if safety_response.violation:
return "I'm sorry, but I can't assist with that request."
### memory storing
documents = [
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=user_input,
mime_type="text/plain"
),
MemoryBankDocument(
document_id=str(uuid.uuid4()),
content=bot_response,
mime_type="text/plain"
)
]
client.memory.insert_documents(
bank_id=bank.bank_id,
documents=documents
)
return bot_response
### putting all together
while True:
user_input = input("You: ")
if user_input.lower() == "bye":
break
bot_response = get_bot_response(user_input)
print("Bot:", bot_response)Pour voir quelques exemples et démarrer votre mise en œuvre d'applications utilisant Llama Stack, Meta a fourni le fichier llama-stack-apps dans lequel vous pouvez consulter des exemples d'applications. N'hésitez pas à consulter le cadre et à vous familiariser avec lui.
En tant que projet open-source, Llama Stack vit des contributions de la communauté. Les API évoluent rapidement et le projet est ouvert aux commentaires et à la participation des développeurs, ce qui contribuera à façonner l'avenir de la plateforme. Si vous testez Llama Stack, cela peut aider d'autres développeurs si vous partagez votre projet en tant qu'exemple, ou si vous contribuez à la documentation.
Tout au long de cet article, nous avons exploré comment démarrer avec Llama Stack à l'aide d'instructions pas à pas.
Au fur et à mesure que vous avancez dans le déploiement de vos applications d'IA, n'oubliez pas de garder un œil sur le dépôt de dépôt de Llama Stack pour obtenir les dernières mises à jour et améliorations.
Pour en savoir plus sur l'écosystème des lamas, consultez les ressources suivantes :
Apprenez l'IA avec ces cours !
Cours
Cours
Cours