
Program
Pengembangan Model Bahasa Besar
16 Hr
DeepSeek V4 Flash adalah model yang lebih kecil, lebih cepat, dan lebih hemat biaya dalam seri pratinjau DeepSeek V4. Model ini dirancang untuk beban kerja inferensi praktis, dengan parameter aktif lebih rendah daripada DeepSeek V4 Pro serta mendukung tugas dengan konteks panjang. Versi GGUF yang digunakan dalam panduan ini menyimpan bobot dense dalam FP8 dan bobot MoE dalam FP4, sehingga cocok untuk inferensi lokal melalui build khusus llama.cpp.
Dalam panduan ini, kita akan menjalankan DeepSeek V4 Flash secara lokal di RunPod menggunakan GPU RTX PRO 6000 dan build llama.cpp yang dimodifikasi. Anda akan mempelajari cara menyiapkan GPU pod, memasang dependensi yang diperlukan, mengompilasi llama.cpp dengan dukungan DeepSeek V4, mengunduh model GGUF FP4/FP8 dari Hugging Face, dan menyajikannya melalui antarmuka web llama.cpp berbasis browser.
Sebelum memulai, pastikan Anda memiliki:
Akun RunPod
Setidaknya $5 kredit RunPod
Dasar-dasar perintah terminal Linux
Akun Hugging Face
Token akses Hugging Face yang disimpan sebagai HF_TOKEN
Anda akan menggunakan token Hugging Face untuk mengunduh model dengan lebih cepat dan lebih andal.
Jika Anda ingin melihat bagaimana model ini dibandingkan dengan kompetitor proprietari dari OpenAI, saya sarankan membaca panduan perbandingan kami DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Pertama, buat pod GPU baru di RunPod.
Untuk panduan ini, kami menggunakan GPU RTX PRO 6000 karena menawarkan 96GB VRAM dengan biaya jauh lebih rendah dibanding H100. Ini menjadikannya opsi praktis untuk menjalankan model DeepSeek V4 Flash versi penuh pada satu GPU tanpa harus membayar harga premium H100.
Di dasbor RunPod, pilih pod RTX PRO 6000 GPU dan gunakan template PyTorch terbaru sebagai base image.
Sebelum men-deploy pod, edit pengaturan template dan konfigurasikan storage, exposed port, dan environment variable.
Gunakan pengaturan yang direkomendasikan berikut:
|
Pengaturan |
Nilai yang Direkomendasikan |
|
GPU |
RTX PRO 6000 |
|
Container Disk |
50 GB |
|
Volume Disk |
300 GB |
|
Exposed Port |
8910 |
|
Template |
Template PyTorch terbaru |
|
Environment Variable |
|
Exposed port 8910 penting karena ini adalah port yang akan Anda gunakan untuk mengakses Web UI llama.cpp dari browser.
Setelah pod dideploy, tunggu beberapa detik hingga dasbor RunPod menampilkan tautan JupyterLab.
Buka JupyterLab, lalu jalankan terminal. Untuk memastikan GPU tersedia, jalankan:
nvidia-smi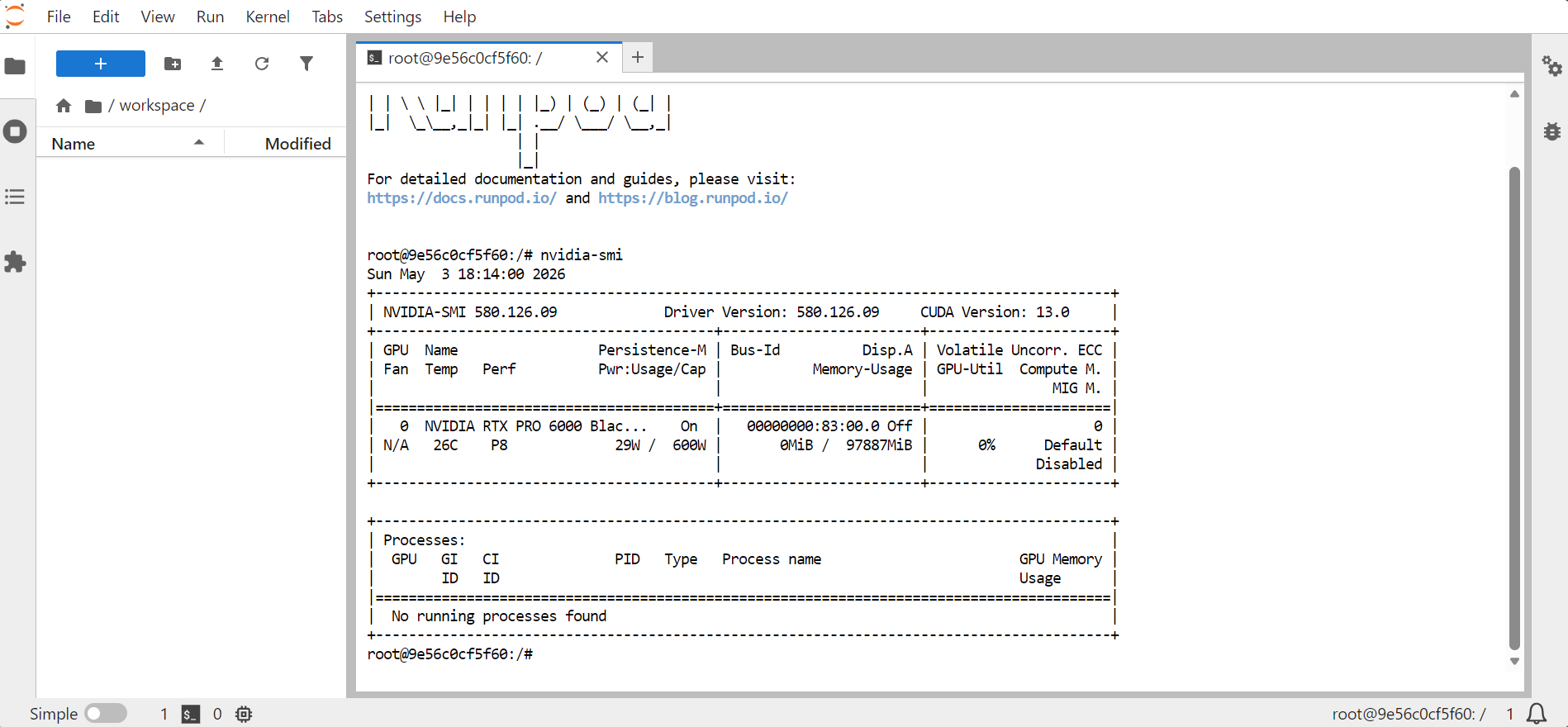
Perintah ini akan menampilkan informasi tentang GPU, memori, versi CUDA, dan versi driver.
Selanjutnya, pasang dependensi sistem yang diperlukan untuk membangun dan menjalankan llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvPaket-paket ini mencakup alat build, CMake, Git, Python, dan utilitas lain yang dibutuhkan untuk mengompilasi llama.cpp dari sumber.
DeepSeek V4 Flash masih sangat baru, jadi dukungan lokalnya belum semudah model-model yang lebih lama. Pada saat penulisan, belum ada rilis GGUF resmi yang banyak diadopsi dari penyedia komunitas besar seperti Unsloth untuk menjalankan model penuh melalui llama.cpp upstream standar.
Model resmi DeepSeek V4 Flash tersedia di Hugging Face, tetapi jalur GGUF lokal masih bergantung pada konversi komunitas dan dukungan runtime eksperimental. GGUF yang digunakan dalam panduan ini secara spesifik menyatakan bahwa llama.cpp upstream standar tidak dapat memuatnya dan memerlukan build yang masih dalam tahap pengerjaan dengan dukungan arsitektur DeepSeek V4 Flash, FP8 native, dan dukungan MXFP4.
Karena itu, setup ini menggunakan branch llama.cpp yang dimodifikasi oleh kontributor open-source, bukan versi upstream standar. Saat ini ini adalah jalur praktis untuk menguji GGUF DeepSeek V4 Flash versi penuh secara lokal.
Proyek llama.cpp upstream juga memiliki permintaan model terbuka untuk dukungan DeepSeek V4, yang menunjukkan bahwa dukungan resmi masih dalam pengerjaan dan belum sepenuhnya digabungkan ke proyek utama.
Pindah ke direktori workspace:
cd /workspaceKlon repositori yang dimodifikasi:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Sekarang konfigurasikan build menggunakan CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseIni mengaktifkan dukungan CUDA, sehingga model dapat menggunakan akselerasi GPU.
Bangun biner yang diperlukan:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitSetelah build selesai, salin biner ke folder proyek utama:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Terakhir, periksa apakah biner server berfungsi:
llama.cpp-deepseek-v4/llama-server --helpJika menu bantuan muncul, build berhasil.
Selanjutnya, pasang alat unduh Hugging Face. Di sinilah HF_TOKEN yang Anda tambahkan sebelumnya menjadi penting. Karena ini adalah file model berukuran besar, masuk dengan token Hugging Face meningkatkan keandalan unduhan dan memberi Anda akses ke metode unduhan yang lebih cepat.
Pasang paket yang diperlukan:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferAktifkan unduhan Hugging Face yang lebih cepat:
export HF_HUB_ENABLE_HF_TRANSFER=1Buat folder untuk model:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Unduh file model GGUF:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Dengan hf_transfer diaktifkan dan HF_TOKEN Anda sudah disetel di lingkungan RunPod, kecepatan unduhan model bisa sangat tinggi.
Dalam setup ini, kecepatan unduhan hampir mencapai 2 GB per detik, sehingga mengunduh file GGUF besar menjadi jauh lebih praktis. Kecepatan ini hanya mungkin jika token Hugging Face Anda dikonfigurasi dengan benar, dan pod dapat melakukan autentikasi dengan Hugging Face.

Setelah unduhan selesai, verifikasi file:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Anda akan melihat file serupa berikut:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufSekarang model sudah diunduh dan build llama.cpp yang dimodifikasi siap, langkah berikutnya adalah memulai server inferensi lokal sehingga Anda dapat mengakses DeepSeek V4 Flash melalui Web UI berbasis browser dan endpoint API.
Pindah ke direktori llama.cpp:
cd /workspace/llama.cpp-deepseek-v4Mulai server model:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfPerintah ini memuat model GGUF, mengekspos server pada 0.0.0.0:8910, menerapkan template chat Jinja, menggunakan --fit on untuk menyesuaikan model ke memori GPU dan sistem yang tersedia, menetapkan jendela konteks 32K, mengaktifkan batching yang ramah CUDA dan Flash Attention untuk inferensi lebih cepat, serta menyalakan metrik dan pencatatan performa agar Anda dapat memantau jalannya.
Model mungkin membutuhkan setidaknya satu menit untuk dimuat ke memori GPU dan CPU.

Saat server siap, Anda akan melihat pesan bahwa server “listening on http://0.0.0.0:8910”.

Ini berarti server model sedang berjalan dan siap menerima permintaan.
Kembali ke dasbor RunPod Anda. Cari exposed port 8910, lalu klik tautan port tersebut.
Ini akan membuka Web UI llama.cpp di browser Anda. Antarmukanya mirip dengan antarmuka chat gaya ChatGPT dasar.
Setelah halaman terbuka, model seharusnya sudah dimuat. Anda dapat mulai mengobrol langsung dari browser.
Setelah server berjalan, Anda dapat menguji model menggunakan berbagai jenis prompt.
Tujuannya adalah memeriksa seberapa baik performanya pada:
Gunakan prompt berikut:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
Dalam uji ini, model menghasilkan halaman HTML sekitar 2 menit, yang merupakan waktu yang wajar.
Untuk mempratinjau halaman yang dihasilkan, cari ikon mata di dekat keluaran kode di Web UI. Klik untuk membuka halaman web yang dirender.
Halaman berfungsi, tetapi kualitas visualnya kurang mengesankan. Tata letaknya fungsional, namun desain terasa dasar. Model yang lebih kecil terkadang menghasilkan tampilan frontend yang lebih rapi, jadi hasil ini kurang memuaskan untuk generasi UI.
Selanjutnya, uji kemampuan penulisan model.
Gunakan prompt ini:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Model menghasilkan laporan yang jelas dan terstruktur dengan baik. Ia menjelaskan gagasan utama secara sederhana dan menyertakan contoh yang berguna tentang penggunaan alat, perencanaan, memori, refleksi, dan otomasi bisnis.
Namun, keluaran terasa agak generik dan promosi di beberapa bagian, terutama mendekati kesimpulan. Ada juga beberapa masalah pemformatan dan ejaan, seperti penebalan yang tidak konsisten dan kesalahan kata seperti “Mainate Context.”
Sekarang uji kemampuan penalaran model dengan soal aljabar sederhana.
Gunakan prompt ini:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Model menyelesaikan soal dengan benar.
Ia mendefinisikan variabel dengan tepat, membentuk persamaan yang benar, melakukan substitusi nilai dengan benar, dan memeriksa jawaban akhir.
Jawaban tepatnya adalah:
Dalam desimal, kira-kira:
Nilai-nilai tersebut benar menjumlah hingga total $156.
Terakhir, uji apakah model dapat menghasilkan proyek pemrograman yang ramah pemula secara lengkap.
Gunakan prompt ini:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
Responsnya awalnya terlihat lengkap, dan struktur proyeknya masuk akal. Namun, kode yang dihasilkan memiliki beberapa masalah serius.
Keluaran mencakup:
Untuk proyek yang ramah pemula, ini masalah besar. Pemula seharusnya dapat menyalin, menjalankan, dan memahami kodenya dengan perbaikan minimal. Dalam kasus ini, proyek yang dihasilkan membutuhkan debugging signifikan sebelum dapat digunakan.
Setelah menguji DeepSeek V4 Flash pada generasi UI, penulisan, penalaran, dan generasi proyek, model menunjukkan hasil yang beragam.
Model berkinerja baik pada penalaran terstruktur dan penulisan penjelasan dasar. Ia juga mampu menghasilkan keluaran dengan cepat melalui Web UI llama.cpp.
Namun, model kewalahan pada desain frontend yang rapi dan generasi kode proyek lengkap yang andal. Keluaran proyek Python terlihat lengkap tetapi mengandung terlalu banyak kesalahan sintaks dan penamaan untuk berguna tanpa debugging manual.
|
Tugas |
Performa |
|
Generasi UI |
Rata-rata |
|
Penulisan dan penjelasan |
Baik |
|
Penalaran matematika |
Kuat |
|
Generasi proyek lengkap |
Lemah |
|
Kecepatan |
Baik |
|
Keandalan keseluruhan |
Campuran |
Menjalankan DeepSeek V4 Flash secara lokal terus terang merupakan mimpi buruk.
Saya pertama kali mencoba menjalankannya pada setup 4x H100 menggunakan konfigurasi sglang Docker Compose, tetapi tetap gagal. Saya kemudian mencoba menjalankannya dengan vLLM pada 4x H100 RunPod menggunakan Python, namun itu juga gagal. Error terus merujuk pada dukungan DeepSeek V4 di versi terbaru transformers, meskipun saya sudah menggunakan versi terbaru. Ini jelas menunjukkan bahwa dukungan framework yang tepat masih belum matang.
Bahkan halaman model resmi di Hugging Face tidak menyediakan contoh inferensi standar yang sederhana. Sebaliknya, halaman tersebut mengarahkan pengguna ke pendekatan torchrun khusus, yang jauh lebih berat dan membutuhkan lebih banyak upaya untuk disiapkan.
Saya juga menguji file GGUF yang disediakan komunitas, tetapi menemui masalah kompatibilitas llama.cpp. Biasanya, saya lebih suka menggunakan file GGUF Unsloth karena cepat, andal, dan mudah dijalankan, tetapi untuk DeepSeek V4 Flash, tidak ada jalur plug-and-play yang sederhana.
Setelah semua pengujian itu, metode yang ditunjukkan dalam panduan ini adalah cara termudah dan paling andal yang saya temukan untuk menjalankan model penuh secara lokal. Memang masih bergantung pada file GGUF komunitas dan build llama.cpp yang dimodifikasi, tetapi dibanding opsi lain, setup ini benar-benar berhasil.
Meski begitu, saya rasa DeepSeek V4 Flash belum layak dijalankan secara lokal saat ini. Proses setup terlalu menyulitkan, dukungan framework masih belum matang, dan kualitas output tidak sebanding dengan upaya yang diperlukan.
Jika Anda menginginkan pengalaman model lokal yang lebih mulus, saya merekomendasikan mencoba model seperti MiniMax M2.7 atau model terkuantisasi yang kuat seperti Qwen3.6-27B. Model-model ini lebih mudah dijalankan, didukung lebih baik di berbagai framework utama, lebih cepat dalam praktiknya, dan sering kali menghasilkan output berkualitas lebih tinggi dengan jauh lebih sedikit frustrasi saat setup.
Kursus LLM Teratas
Program
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
