
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
DeepSeek V4 Flash é o modelo menor, mais rápido e mais econômico da série de prévia do DeepSeek V4. Ele foi projetado para cargas de inferência práticas, com menos parâmetros ativos que o DeepSeek V4 Pro e suporte a tarefas de longo contexto. A versão GGUF usada neste guia armazena pesos densos em FP8 e pesos de MoE em FP4, o que a torna adequada para inferência local por meio de uma build personalizada do llama.cpp.
Neste guia, vamos executar o DeepSeek V4 Flash localmente no RunPod usando uma GPU RTX PRO 6000 e uma build modificada do llama.cpp. Você vai aprender a configurar o pod de GPU, instalar as dependências necessárias, compilar o llama.cpp com suporte ao DeepSeek V4, baixar o modelo GGUF FP4/FP8 do Hugging Face e servi-lo pela interface Web do llama.cpp no navegador.
Antes de começar, verifique se você tem:
Uma conta no RunPod
Ao menos US$ 5 de crédito no RunPod
Noções básicas de comandos no terminal Linux
Uma conta no Hugging Face
Um token de acesso do Hugging Face salvo como HF_TOKEN
Você usará o token do Hugging Face para baixar o modelo com mais rapidez e estabilidade.
Se quiser ver como o modelo se compara aos concorrentes proprietários da OpenAI, recomendo ler nosso guia de comparação DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Primeiro, crie um novo pod de GPU no RunPod.
Para este guia, estamos usando a GPU RTX PRO 6000 porque ela oferece 96 GB de VRAM a um custo muito menor que uma H100. Isso a torna uma opção prática para executar o modelo completo DeepSeek V4 Flash em uma única GPU sem pagar os preços premium da H100.
No painel do RunPod, selecione um pod com RTX PRO 6000 e use o template mais recente do PyTorch como imagem base.
Antes de fazer o deploy do pod, edite as configurações do template e ajuste o armazenamento, a porta exposta e as variáveis de ambiente.
Use a seguinte configuração recomendada:
|
Configuração |
Valor recomendado |
|
GPU |
RTX PRO 6000 |
|
Container Disk |
50 GB |
|
Volume Disk |
300 GB |
|
Exposed Port |
8910 |
|
Template |
Template mais recente do PyTorch |
|
Variável de ambiente |
|
A porta exposta 8910 é importante porque é por ela que você acessará a interface Web do llama.cpp no navegador.
Quando o pod for criado, aguarde alguns segundos até o painel do RunPod exibir o link para o JupyterLab.
Abra o JupyterLab e inicie um terminal. Para confirmar que a GPU está disponível, execute:
nvidia-smi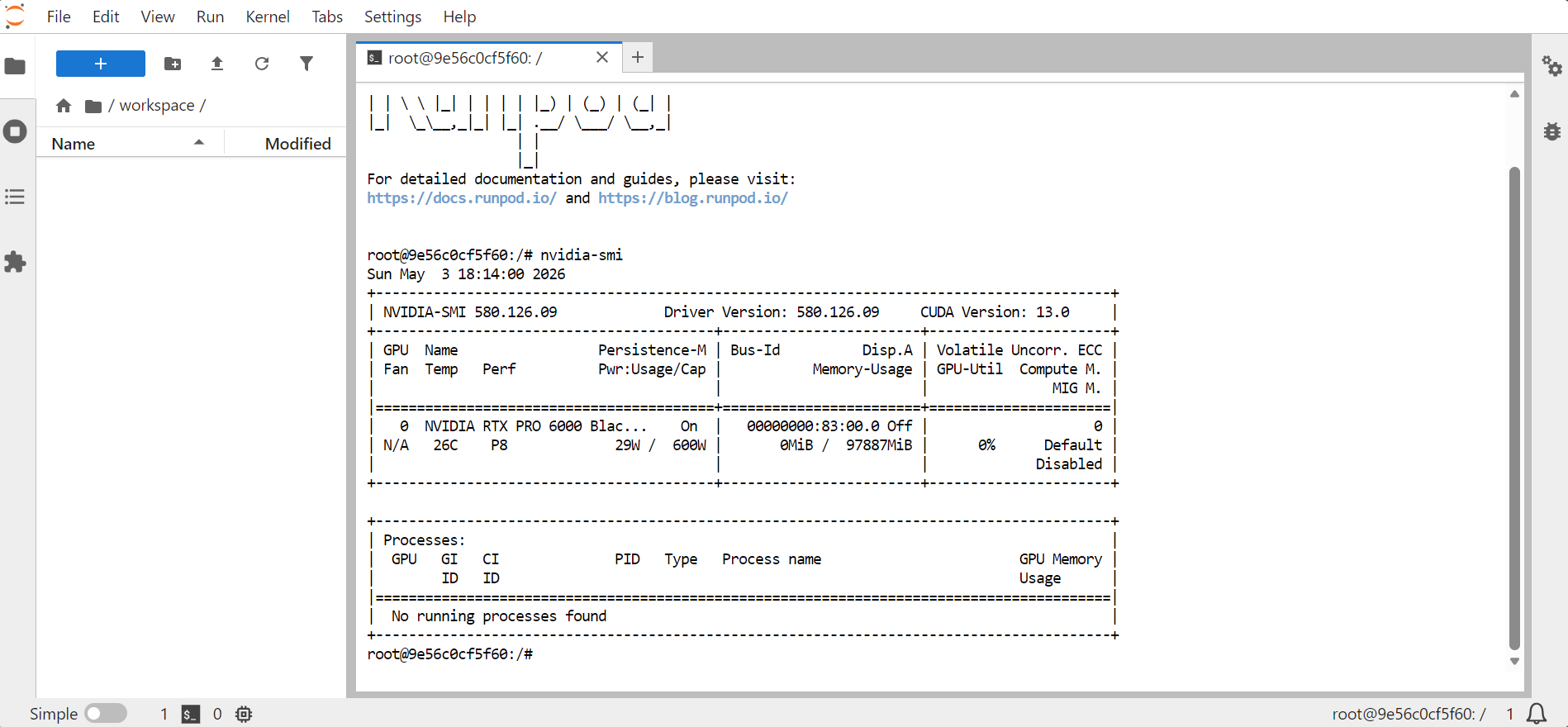
Isso deve exibir informações sobre a GPU, a memória, a versão do CUDA e a versão do driver.
Em seguida, instale as dependências do sistema necessárias para compilar e executar o llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvEsses pacotes incluem ferramentas de build, CMake, Git, Python e outras utilidades necessárias para compilar o llama.cpp a partir do código-fonte.
O DeepSeek V4 Flash ainda é muito novo, então o suporte local não é tão simples quanto em modelos mais antigos. No momento da escrita, não há um release GGUF oficial amplamente adotado por grandes mantenedores da comunidade, como o Unsloth, para executar o modelo completo no llama.cpp upstream padrão.
O modelo oficial DeepSeek V4 Flash está disponível no Hugging Face, mas a rota GGUF local ainda depende de conversões da comunidade e suporte experimental no runtime. O GGUF usado neste guia afirma especificamente que o llama.cpp upstream padrão não consegue carregá-lo e requer uma build em andamento com suporte à arquitetura do DeepSeek V4 Flash, FP8 nativo e suporte a MXFP4.
Por isso, esta configuração usa um branch modificado do llama.cpp de um colaborador open source, em vez da versão upstream padrão. Atualmente, esse é o caminho prático para testar o GGUF completo do DeepSeek V4 Flash localmente.
O projeto llama.cpp upstream também tem uma solicitação aberta para suporte ao DeepSeek V4, o que mostra que o suporte oficial ainda está em andamento e não foi totalmente incorporado ao projeto principal.
Vá para o diretório de trabalho:
cd /workspaceClone o repositório modificado:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Agora configure o build com o CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseIsso ativa o suporte a CUDA, permitindo que o modelo use aceleração de GPU.
Compile os binários necessários:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitApós a compilação, copie os binários para a pasta principal do projeto:
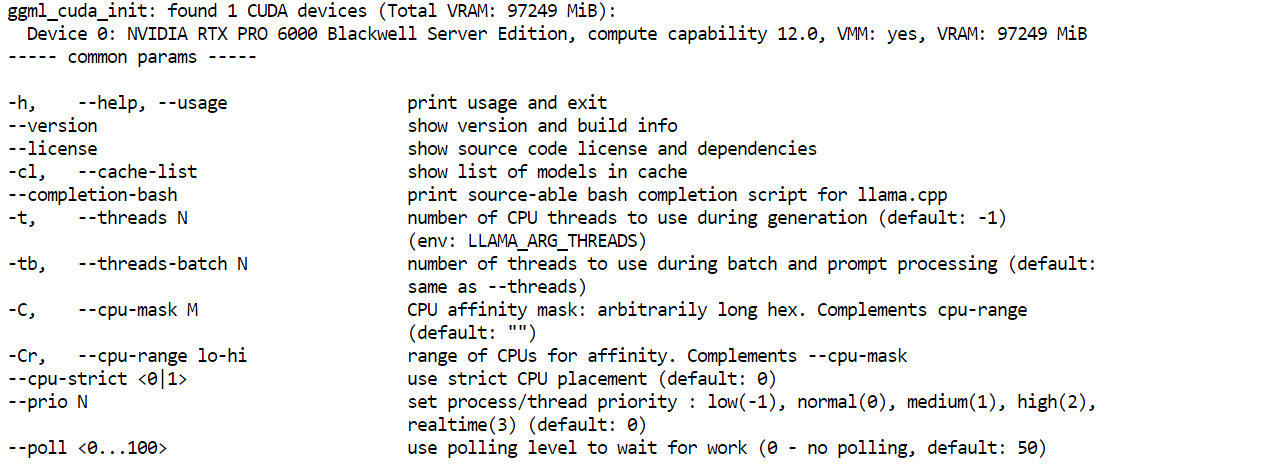
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Por fim, verifique se o binário do servidor funciona:
llama.cpp-deepseek-v4/llama-server --helpSe o menu de ajuda aparecer, a build foi concluída com sucesso.
Em seguida, instale as ferramentas de download do Hugging Face. É aqui que o HF_TOKEN que você adicionou antes se torna importante. Como este é um arquivo de modelo grande, entrar com seu token do Hugging Face melhora a confiabilidade do download e libera métodos mais rápidos.
Instale os pacotes necessários:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferHabilite downloads mais rápidos do Hugging Face:
export HF_HUB_ENABLE_HF_TRANSFER=1Crie uma pasta para o modelo:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Baixe o arquivo do modelo GGUF:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Com o hf_transfer habilitado e seu HF_TOKEN já definido no ambiente do RunPod, o download do modelo pode atingir velocidades muito altas.
Nesta configuração, o download chegou a quase 2 GB por segundo, o que torna muito mais viável baixar um arquivo GGUF grande. Essa velocidade só é possível quando seu token do Hugging Face está configurado corretamente e o pod pode se autenticar com o Hugging Face.

Quando o download terminar, verifique o arquivo:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Você deve ver um arquivo semelhante a este:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufAgora que o modelo foi baixado e a build modificada do llama.cpp está pronta, o próximo passo é iniciar o servidor de inferência local para acessar o DeepSeek V4 Flash pela interface Web no navegador e pelo endpoint de API.
Acesse o diretório do llama.cpp:
cd /workspace/llama.cpp-deepseek-v4Inicie o servidor do modelo:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfEsse comando carrega o modelo GGUF, expõe o servidor em 0.0.0.0:8910, aplica o template de chat Jinja, usa --fit on para ajustar o modelo à memória disponível da GPU e do sistema, define uma janela de contexto de 32K, habilita batching otimizado para CUDA e Flash Attention para inferência mais rápida, além de ativar métricas e logs de performance para você monitorar a execução.
O modelo pode levar pelo menos um minuto para ser carregado na memória da GPU e da CPU.

Quando o servidor estiver pronto, você verá a mensagem informando que está “listening on http://0.0.0.0:8910”.

Isso significa que o servidor do modelo está ativo e pronto para receber requisições.
Volte ao seu painel do RunPod. Procure a porta exposta 8910 e clique no link da porta.
Isso vai abrir a interface Web do llama.cpp no seu navegador. A interface é semelhante a um chat básico no estilo do ChatGPT.
Quando a página abrir, o modelo já deve estar carregado. Você pode começar a conversar com ele diretamente pelo navegador.
Depois que o servidor estiver em execução, você pode testar o modelo com diferentes tipos de prompts.
O objetivo é verificar o desempenho em:
Use o seguinte prompt:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
Neste teste, o modelo gerou a página HTML em cerca de 2 minutos, um tempo razoável.
Para pré-visualizar a página gerada, procure o ícone de olho perto do output de código na interface Web. Clique para abrir a página renderizada.
A página funcionou, mas a qualidade visual não impressionou. O layout era funcional, porém o design ficou básico. Modelos menores às vezes geram frontends mais caprichados, então o resultado foi aquém do esperado para geração de UI.
Agora teste a capacidade de escrita do modelo.
Use este prompt:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
O modelo produziu um texto claro e bem estruturado. Explicou as ideias principais de forma simples e incluiu exemplos úteis de uso de ferramentas, planejamento, memória, reflexão e automação de processos de negócios.
No entanto, a saída soou um pouco genérica e promocional em alguns trechos, especialmente na conclusão. Também houve alguns problemas de formatação e ortografia, como negrito inconsistente e erros de digitação como “Mainate Context”.
Agora teste a capacidade de raciocínio do modelo com um problema simples de álgebra.
Use este prompt:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
O modelo resolveu o problema corretamente.
Ele definiu as variáveis, criou as equações certas, fez as substituições corretamente e conferiu a resposta final.
A resposta exata foi:
Em decimais, aproximadamente:
Os valores somam corretamente o total de US$ 156.
Por fim, teste se o modelo consegue gerar um projeto de código completo para iniciantes.
Use este prompt:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
A resposta parecia completa à primeira vista, e a estrutura do projeto fazia sentido. Porém, o código gerado tinha vários problemas graves.
A saída incluía:
Para um projeto voltado a iniciantes, isso é um grande problema. Um iniciante deveria conseguir copiar, executar e entender o código com correções mínimas. Neste caso, o projeto gerado exigiria bastante depuração antes de poder ser usado.
Após testar o DeepSeek V4 Flash em geração de UI, redação, raciocínio e geração de projeto, o modelo apresentou resultados mistos.
Ele foi bem em raciocínio estruturado e escrita explicativa básica. Também conseguiu gerar respostas rapidamente pela interface Web do llama.cpp.
Por outro lado, teve dificuldade com design frontend mais polido e com geração de código de projeto completo de forma confiável. O projeto em Python parecia completo, mas trouxe erros demais de sintaxe e nomenclatura para ser útil sem depuração manual.
|
Tarefa |
Desempenho |
|
Geração de UI |
Mediano |
|
Redação e explicação |
Bom |
|
Raciocínio matemático |
Forte |
|
Geração de projeto completo |
Fraco |
|
Velocidade |
Boa |
|
Confiabilidade geral |
Mista |
Executar o DeepSeek V4 Flash localmente foi, sinceramente, um pesadelo.
Primeiro tentei rodá-lo em um setup com 4x H100 usando uma configuração do sglang com Docker Compose, mas falhou. Depois tentei executar com o vLLM em 4x H100 no RunPod usando Python, e também falhou. O erro apontava para suporte ao DeepSeek V4 na versão mais recente do transformers, embora eu já estivesse usando a versão mais nova. Ficou claro que o suporte adequado nos frameworks ainda não está maduro.
Mesmo a página oficial do modelo no Hugging Face não fornece um exemplo simples e padrão de inferência. Em vez disso, direciona os usuários para uma abordagem personalizada com torchrun, que é bem mais pesada e trabalhosa de configurar.
Também testei arquivos GGUF fornecidos pela comunidade, mas esbarrei em problemas de compatibilidade com o llama.cpp. Normalmente, eu prefiro usar arquivos GGUF do Unsloth porque são rápidos, confiáveis e fáceis de rodar, mas para o DeepSeek V4 Flash não havia um caminho simples de plug and play.
Depois de todos esses testes, o método mostrado neste guia foi o jeito mais fácil e confiável que encontrei para executar o modelo completo localmente. Ele ainda depende de um arquivo GGUF da comunidade e de uma build modificada do llama.cpp, mas, comparado às outras opções, essa configuração funcionou de verdade.
Dito isso, eu não acho que vale a pena rodar o DeepSeek V4 Flash localmente agora. A configuração é muito trabalhosa, o suporte nos frameworks ainda é imaturo e a qualidade das saídas não justifica o esforço.
Se você quer uma experiência local mais tranquila, eu recomendaria testar modelos como o MiniMax M2.7 ou modelos bem quantizados como Qwen3.6-27B. Eles são mais fáceis de rodar, têm melhor suporte nos principais frameworks, são mais rápidos na prática e muitas vezes geram resultados de maior qualidade com muito menos frustração na configuração.
Principais cursos de LLM
Programa
Curso
Curso
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita


