Track
Разработка больших языковых моделей
16 ч
DeepSeek V4 Flash — это более компактная, быстрая и экономичная модель из серии предварительного просмотра DeepSeek V4. Она предназначена для практических задач инференса, имеет меньше активных параметров, чем DeepSeek V4 Pro, и поддерживает задачи с длинным контекстом. Версия GGUF, используемая в этом руководстве, хранит плотные веса в FP8, а веса MoE — в FP4, что делает её подходящей для локального инференса через кастомную сборку llama.cpp.
В этом руководстве мы запустим DeepSeek V4 Flash локально на RunPod с использованием GPU RTX PRO 6000 и модифицированной сборки llama.cpp. Вы узнаете, как настроить GPU pod, установить необходимые зависимости, скомпилировать llama.cpp с поддержкой DeepSeek V4, скачать модель FP4/FP8 GGUF с Hugging Face и развернуть её через веб-интерфейс llama.cpp.
Перед началом убедитесь, что у вас есть:
Аккаунт RunPod
Не менее $5 на балансе RunPod
Базовые навыки работы с терминалом Linux
Аккаунт Hugging Face
Токен доступа Hugging Face, сохранённый как HF_TOKEN
Токен Hugging Face понадобится для более быстрого и надёжного скачивания модели.
Если хотите сравнить модель с закрытыми конкурентами от OpenAI, рекомендуем прочитать наш обзор DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Сначала создайте новый GPU pod в RunPod.
Для этого руководства мы используем GPU RTX PRO 6000, поскольку он предлагает 96 ГБ видеопамяти по куда более низкой цене, чем H100. Это практичный вариант, позволяющий запускать полноценную модель DeepSeek V4 Flash на одном GPU без премиальной стоимости H100.
В панели RunPod выберите pod с RTX PRO 6000 и используйте последнюю шаблонную сборку PyTorch как базовый образ.
Перед запуском pod отредактируйте настройки шаблона и укажите хранилище, открытый порт и переменные окружения.
Используйте следующую рекомендуемую конфигурацию:
|
Параметр |
Рекомендуемое значение |
|
GPU |
RTX PRO 6000 |
|
Container Disk |
50 GB |
|
Volume Disk |
300 GB |
|
Exposed Port |
8910 |
|
Template |
Latest PyTorch template |
|
Environment Variable |
|
Открытый порт 8910 важен, потому что через него вы будете заходить в веб-интерфейс llama.cpp из браузера.
После развертывания pod подождите несколько секунд, пока в панели RunPod не появится ссылка на JupyterLab.
Откройте JupyterLab и запустите терминал. Чтобы убедиться, что GPU доступен, выполните:
nvidia-smi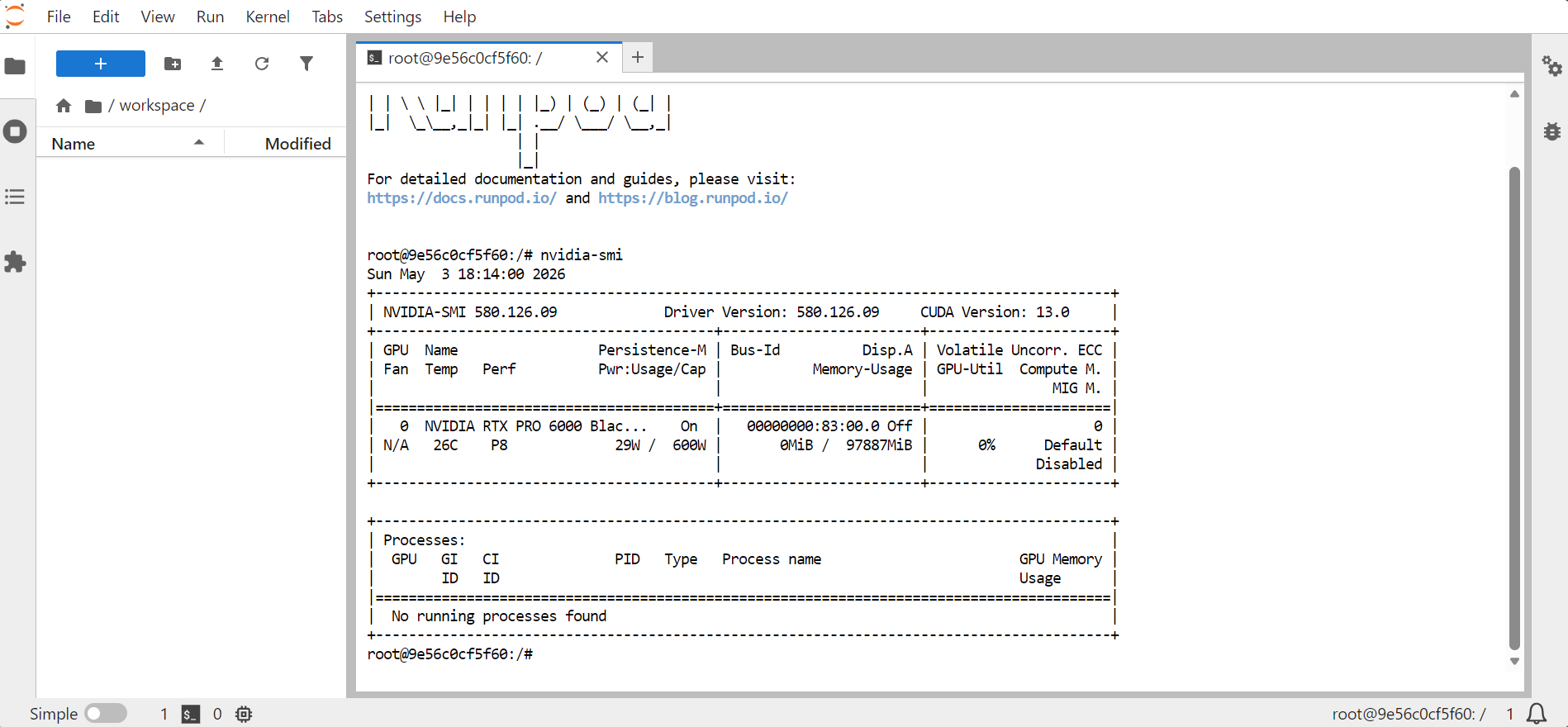
Вы должны увидеть информацию о GPU, памяти, версии CUDA и версии драйвера.
Далее установите системные зависимости, необходимые для сборки и запуска llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvЭти пакеты включают инструменты сборки, CMake, Git, Python и другие утилиты, необходимые для компиляции llama.cpp из исходников.
DeepSeek V4 Flash всё ещё совсем новая, поэтому локальная поддержка пока не так проста, как у более старых моделей. На момент написания нет широко используемого официального релиза GGUF от крупных участников сообщества, таких как Unsloth, для запуска полной модели через стандартный апстрим llama.cpp.
Официальная модель DeepSeek V4 Flash доступна на Hugging Face, но локальный путь через GGUF по‑прежнему зависит от конверсий сообщества и экспериментальной поддержки рантайма. В GGUF, используемом в этом руководстве, прямо указано, что стандартный апстрим llama.cpp не может его загрузить и требует сборку WIP с поддержкой архитектуры DeepSeek V4 Flash, нативного FP8 и MXFP4.
Поэтому мы используем модифицированную ветку llama.cpp от участника с открытым исходным кодом, а не стандартную апстрим-версию. На данный момент это практичный способ протестировать полный GGUF DeepSeek V4 Flash локально.
В апстрим-проекте llama.cpp также открыт запрос на поддержку DeepSeek V4, что показывает: официальная поддержка ещё в работе и не была полностью влита в основной проект.
Перейдите в рабочий каталог:
cd /workspaceКлонируйте модифицированный репозиторий:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Настройте сборку с помощью CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseЭто включает поддержку CUDA, чтобы модель могла использовать ускорение на GPU.
Соберите необходимые бинарные файлы:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitПосле завершения сборки скопируйте бинарники в корень проекта:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Наконец, проверьте, что серверный бинарник работает:
llama.cpp-deepseek-v4/llama-server --helpЕсли появилось меню справки, сборка прошла успешно.
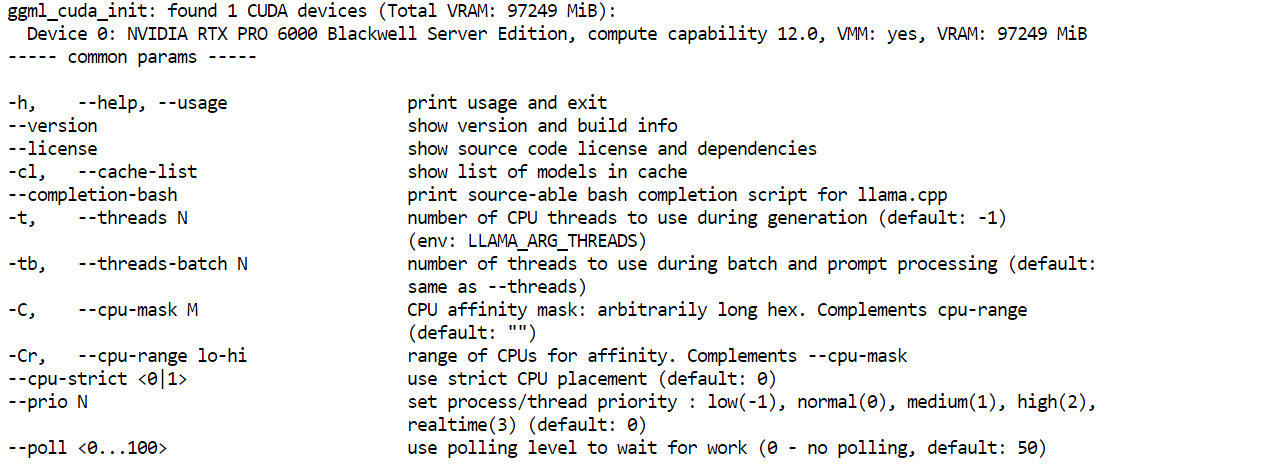
Далее установите инструменты загрузки Hugging Face. Здесь важен ваш HF_TOKEN, добавленный ранее. Поскольку это большой файл модели, вход с токеном Hugging Face повышает надёжность загрузки и даёт доступ к более быстрым методам скачивания.
Установите необходимые пакеты:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferВключите ускоренные загрузки Hugging Face:
export HF_HUB_ENABLE_HF_TRANSFER=1Создайте папку для модели:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Скачайте файл модели GGUF:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8С включённым hf_transfer и настроенным HF_TOKEN в окружении RunPod скорость загрузки модели может быть очень высокой.
В нашем случае скорость почти достигала 2 ГБ/с, что делает загрузку большого файла GGUF гораздо практичнее. Такая скорость возможна только при корректной настройке токена Hugging Face и успешной аутентификации pod на стороне Hugging Face.

После завершения загрузки проверьте файл:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Вы должны увидеть примерно такой файл:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufТеперь, когда модель загружена, а модифицированная сборка llama.cpp готова, запустим локальный сервер инференса, чтобы обращаться к DeepSeek V4 Flash через веб-интерфейс и API.
Перейдите в каталог llama.cpp:
cd /workspace/llama.cpp-deepseek-v4Запустите сервер модели:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfЭта команда загружает модель GGUF, открывает сервер на 0.0.0.0:8910, применяет чат‑шаблон Jinja, использует --fit on для размещения модели в доступной памяти GPU и системы, задаёт контекстное окно 32K, включает пакетную обработку, дружественную к CUDA, и Flash Attention для более быстрого инференса, а также включает метрики и логирование производительности для мониторинга запуска.
Загрузка модели в память GPU и CPU может занять не менее минуты.

Когда сервер будет готов, вы увидите сообщение о том, что он «listening on http://0.0.0.0:8910».

Это означает, что сервер модели запущен и готов принимать запросы.
Вернитесь в панель RunPod. Найдите открытый порт 8910 и кликните по ссылке порта.
Откроется веб-интерфейс llama.cpp в вашем браузере. Интерфейс похож на простой чат в стиле ChatGPT.
После загрузки страницы модель уже должна быть в памяти. Можете начинать общение прямо из браузера.
После запуска сервера вы можете протестировать модель на разных типах запросов.
Цель — проверить качество работы в задачах:
Используйте следующий промпт:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
В этом тесте модель сгенерировала HTML‑страницу примерно за 2 минуты — разумное время.
Чтобы просмотреть результат, найдите значок глаза рядом с выводом кода в веб‑интерфейсе. Нажмите на него, чтобы открыть отрисованную страницу.
Страница работала, но визуальное качество не впечатлило. Макет был рабочим, но дизайн — базовым. Модели поменьше иногда создают более отполированные фронтенд‑решения, поэтому результат для UI оказался средним.
Далее проверьте способности модели к письму.
Используйте такой промпт:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Модель выдала понятный и хорошо структурированный отчёт. Она просто объяснила ключевые идеи и привела полезные примеры использования инструментов, планирования, памяти, рефлексии и бизнес-автоматизации.
Однако местами текст казался немного общим и рекламным, особенно ближе к заключению. Также встречались форматные и орфографические огрехи — например, несогласованное выделение жирным и ошибки в словах вроде «Mainate Context».
Теперь проверьте способность модели к рассуждению на простой задаче по алгебре.
Используйте этот промпт:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Модель решила задачу верно.
Она корректно определила переменные, составила уравнения, подставила значения и проверила итог.
Точный ответ:
В десятичном виде это примерно:
Значения корректно суммируются до $156.
Наконец, проверьте, способна ли модель сгенерировать законченный учебный проект.
Используйте такой промпт:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
Сначала ответ выглядел полным, и структура проекта была логичной. Однако в коде оказалось несколько серьёзных проблем.
В частности, были:
Для учебного проекта это критично. Новичок должен иметь возможность скопировать, запустить и понять код с минимальными правками. В данном случае сгенерированный проект потребует значительной отладки, прежде чем им можно будет пользоваться.
По итогам тестов на генерацию UI, письмо, рассуждение и создание проекта модель показала смешанные результаты.
Она хорошо справилась со структурированным рассуждением и базовыми объяснениями. Также она быстро генерировала ответы через веб‑интерфейс llama.cpp.
Однако у неё возникли сложности с отполированным фронтенд‑дизайном и надёжной генерацией полного проекта. Вывод по Python выглядел законченным, но содержал слишком много синтаксических и номинативных ошибок, чтобы быть полезным без ручной отладки.
|
Задача |
Качество |
|
Генерация UI |
Средне |
|
Письмо и объяснения |
Хорошо |
|
Математическое рассуждение |
Сильно |
|
Полная генерация проекта |
Слабо |
|
Скорость |
Хорошо |
|
Общая надёжность |
Смешанная |
Запуск DeepSeek V4 Flash локально, честно говоря, оказался кошмаром.
Сначала я пытался запустить её на конфигурации 4× H100, используя sglang и конфигурацию Docker Compose, но всё равно получил сбой. Затем я попробовал запустить её с vLLM на 4× H100 в RunPod через Python, но и это не удалось. Ошибка указывала на поддержку DeepSeek V4 в последней версии transformers, хотя у меня уже стояла самая свежая. Стало ясно, что полноценной поддержки фреймворками пока нет.
Даже на официальной странице модели Hugging Face нет простого стандартного примера инференса. Вместо этого пользователей направляют к кастомному подходу на torchrun, который куда тяжелее и требует больше усилий при настройке.
Я также пробовал GGUF‑файлы от сообщества, но столкнулся с проблемами совместимости с llama.cpp. Обычно я предпочитаю GGUF от Unsloth — они быстрые, надёжные и простые в запуске, — но для DeepSeek V4 Flash не оказалось простого «включил и работай».
После всех этих попыток метод из этого руководства оказался самым простым и надёжным способом запустить полную модель локально. Он всё ещё зависит от GGUF‑файла от сообщества и модифицированной сборки llama.cpp, но по сравнению с другими вариантами этот сетап действительно сработал.
Тем не менее, я не считаю, что сейчас стоит запускать DeepSeek V4 Flash локально. Настройка слишком болезненна, поддержка фреймворками ещё сырая, а качество вывода не оправдывает усилий.
Если хотите более гладкий опыт с локальными моделями, рекомендую попробовать такие модели, как MiniMax M2.7 или сильные квантизованные модели, например Qwen3.6-27B. Их проще запускать, они лучше поддерживаются во всех ключевых фреймворках, работают быстрее на практике и часто выдают более качественные результаты при куда меньших трудозатратах на настройку.
Лучшие курсы по LLM
Track
Course
Course