
Programma
Sviluppare modelli linguistici di grandi dimensioni
16 h
DeepSeek V4 Flash è il modello più piccolo, veloce ed economico della serie di anteprima DeepSeek V4. È progettato per carichi di inferenza pratici, con un numero di parametri attivi inferiore rispetto a DeepSeek V4 Pro e supporto per attività a lungo contesto. La versione GGUF usata in questa guida memorizza i pesi densi in FP8 e i pesi MoE in FP4, rendendola adatta all’inferenza locale tramite una build personalizzata di llama.cpp.
In questa guida, eseguiremo DeepSeek V4 Flash in locale su RunPod usando una GPU RTX PRO 6000 e una build modificata di llama.cpp. Imparerai come configurare il pod GPU, installare le dipendenze richieste, compilare llama.cpp con supporto per DeepSeek V4, scaricare il modello GGUF FP4/FP8 da Hugging Face e servirlo tramite la Web UI di llama.cpp basata su browser.
Prima di iniziare, assicurati di avere:
Un account RunPod
Almeno 5 $ di credito RunPod
Familiarità di base con i comandi del terminale Linux
Un account Hugging Face
Un token di accesso Hugging Face salvato come HF_TOKEN
Userai il token Hugging Face per scaricare il modello in modo più veloce e affidabile.
Se vuoi vedere come il modello si confronta con i concorrenti proprietari di OpenAI, ti consiglio di leggere la nostra guida di confronto DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Per prima cosa, crea un nuovo pod GPU su RunPod.
Per questa guida, usiamo la GPU RTX PRO 6000 perché offre 96 GB di VRAM a un costo molto inferiore rispetto a una H100. Questo la rende un’opzione pratica per eseguire l’intero modello DeepSeek V4 Flash su una singola GPU senza pagare il prezzo premium di una H100.
Nel dashboard di RunPod, seleziona un pod RTX PRO 6000 e usa come immagine di base l’ultimo template PyTorch.
Prima di distribuire il pod, modifica le impostazioni del template e configura lo storage, la porta esposta e le variabili d’ambiente.
Usa la seguente configurazione consigliata:
|
Impostazione |
Valore consigliato |
|
GPU |
RTX PRO 6000 |
|
Container Disk |
50 GB |
|
Volume Disk |
300 GB |
|
Exposed Port |
8910 |
|
Template |
Ultimo template PyTorch |
|
Variabile d’ambiente |
|
La porta esposta 8910 è importante perché è la porta che userai per accedere alla Web UI di llama.cpp dal browser.
Una volta distribuito il pod, attendi qualche secondo finché il dashboard di RunPod non mostra il link a JupyterLab.
Apri JupyterLab, poi avvia un terminale. Per confermare che la GPU è disponibile, esegui:
nvidia-smi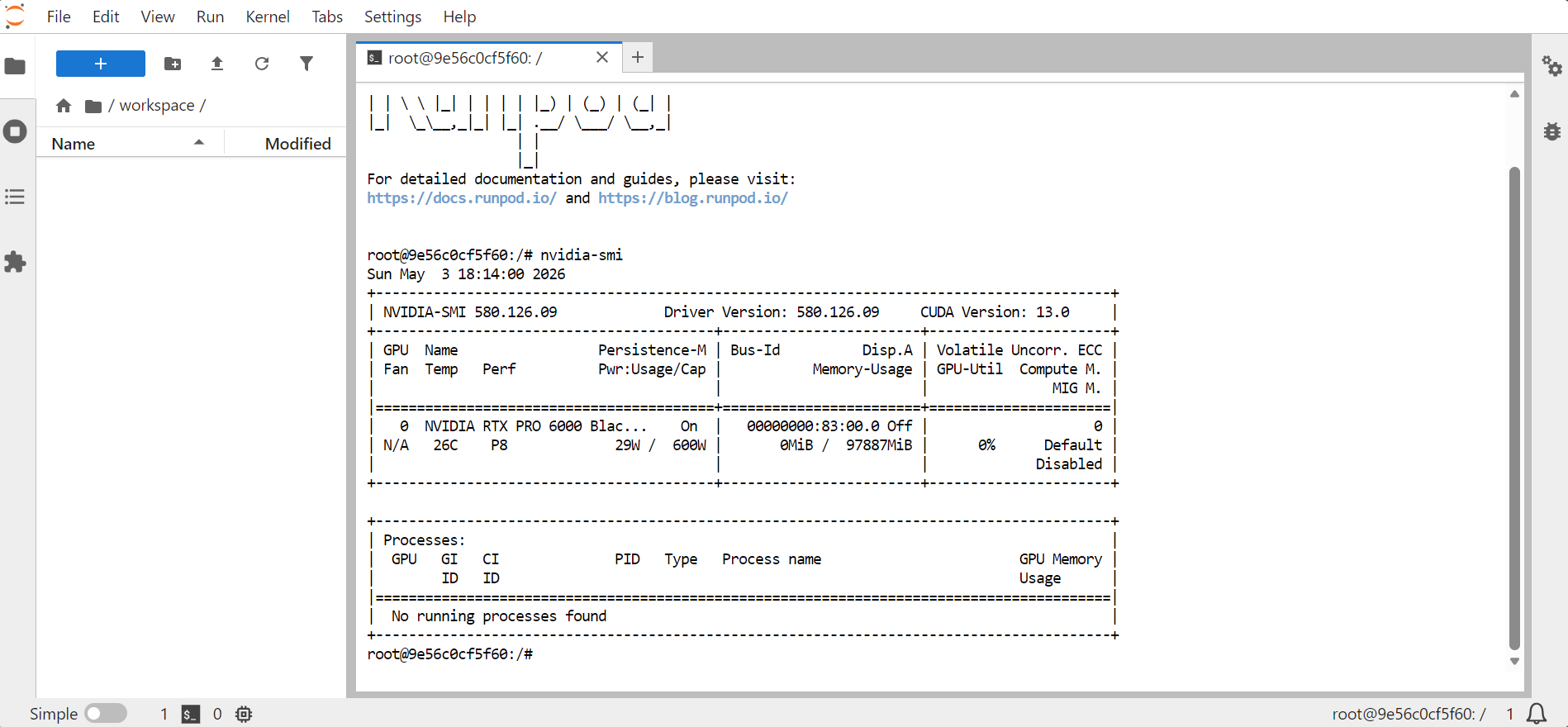
Dovrebbe mostrare informazioni sulla GPU, sulla memoria, sulla versione di CUDA e sulla versione del driver.
Successivamente, installa le dipendenze di sistema necessarie per compilare ed eseguire llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvQuesti pacchetti includono strumenti di build, CMake, Git, Python e altre utility necessarie per compilare llama.cpp dai sorgenti.
DeepSeek V4 Flash è ancora molto nuovo, quindi il supporto locale non è semplice come per i modelli più datati. Al momento della scrittura, non esiste una release GGUF ufficiale ampiamente adottata da importanti provider della community come Unsloth per eseguire l’intero modello tramite l’upstream standard di llama.cpp.
Il modello ufficiale DeepSeek V4 Flash è disponibile su Hugging Face, ma il percorso GGUF locale dipende ancora da conversioni della community e supporto runtime sperimentale. La GGUF usata in questa guida specifica chiaramente che l’upstream standard di llama.cpp non può caricarla e richiede una build in lavorazione con supporto all’architettura DeepSeek V4 Flash, FP8 nativo e supporto MXFP4.
Per questo motivo, questa configurazione utilizza un branch modificato di llama.cpp realizzato da un contributor open source, invece della versione upstream standard. Al momento è il percorso più pratico per testare in locale la GGUF completa di DeepSeek V4 Flash.
Il progetto upstream llama.cpp ha anche una richiesta aperta per il supporto a DeepSeek V4, il che mostra che il supporto ufficiale è ancora in lavorazione e non è stato ancora completamente integrato nel progetto principale.
Spostati nella directory di lavoro:
cd /workspaceClona il repository modificato:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Ora configura la build con CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseQuesto abilita il supporto CUDA, così il modello può usare l’accelerazione GPU.
Compila i binari necessari:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitAl termine della compilazione, copia i binari nella cartella principale del progetto:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Infine, verifica che il binario del server funzioni:
llama.cpp-deepseek-v4/llama-server --helpSe appare il menu di help, la build è riuscita.
Ora installa gli strumenti di download di Hugging Face. Qui diventa importante il HF_TOKEN che hai aggiunto in precedenza. Poiché si tratta di un file modello di grandi dimensioni, l’accesso con il tuo token Hugging Face migliora l’affidabilità del download e ti dà accesso a metodi più veloci.
Installa i pacchetti richiesti:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferAbilita download Hugging Face più rapidi:
export HF_HUB_ENABLE_HF_TRANSFER=1Crea una cartella per il modello:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Scarica il file modello GGUF:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Con hf_transfer abilitato e il tuo HF_TOKEN già impostato nell’ambiente RunPod, il download del modello può raggiungere velocità molto elevate.
In questa configurazione, il download ha raggiunto quasi 2 GB al secondo, il che rende molto più pratico scaricare un grande file GGUF. Questa velocità è possibile solo quando il tuo token Hugging Face è configurato correttamente e il pod può autenticarsi con Hugging Face.

Una volta completato il download, verifica il file:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Dovresti vedere un file simile a questo:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufOra che il modello è stato scaricato e la build modificata di llama.cpp è pronta, il passaggio successivo è avviare il server di inferenza locale così da poter accedere a DeepSeek V4 Flash tramite la Web UI basata su browser e l’endpoint API.
Spostati nella directory di llama.cpp:
cd /workspace/llama.cpp-deepseek-v4Avvia il server del modello:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfQuesto comando carica il modello GGUF, espone il server su 0.0.0.0:8910, applica il template chat Jinja, usa --fit on per adattare il modello alla memoria GPU e di sistema disponibile, imposta una finestra di contesto da 32K, abilita il batching ottimizzato per CUDA e Flash Attention per un’inferenza più rapida e abilita metriche e logging delle prestazioni così puoi monitorare l’esecuzione.
Il modello potrebbe impiegare almeno un minuto per caricarsi nella memoria di GPU e CPU.

Quando il server è pronto, dovresti vedere un messaggio che indica che è “in ascolto su http://0.0.0.0:8910”.

Questo significa che il server del modello è in esecuzione ed è pronto a ricevere richieste.
Torna al tuo dashboard RunPod. Cerca la porta esposta 8910, poi fai clic sul link della porta.
Si aprirà la Web UI di llama.cpp nel tuo browser. L’interfaccia è simile a una chat in stile ChatGPT di base.
Una volta aperta la pagina, il modello dovrebbe essere già caricato. Puoi iniziare a chattare direttamente dal browser.
Dopo l’avvio del server, puoi testare il modello usando diversi tipi di prompt.
L’obiettivo è verificare quanto bene si comporta in:
Usa il seguente prompt:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
In questo test, il modello ha generato la pagina HTML in circa 2 minuti, un tempo ragionevole.
Per visualizzare l’anteprima della pagina generata, cerca l’icona a forma di occhio vicino all’output del codice nella Web UI. Cliccala per aprire la pagina web renderizzata.
La pagina funzionava, ma la qualità visiva non era molto impressionante. Il layout era funzionale, ma il design risultava basilare. Modelli più piccoli a volte producono output frontend più rifiniti, quindi questo risultato è stato deludente per la generazione di UI.
Ora testa la capacità di scrittura del modello.
Usa questo prompt:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Il modello ha prodotto un report chiaro e ben strutturato. Ha spiegato le idee principali in modo semplice e ha incluso esempi utili di uso degli strumenti, pianificazione, memoria, riflessione e automazione aziendale.
Tuttavia, l’output è risultato leggermente generico e promozionale in alcuni punti, soprattutto verso la conclusione. Ha anche incluso diversi problemi di formattazione e ortografia, come grassetti incoerenti ed errori di dicitura come “Mainate Context”.
Ora testa la capacità di ragionamento del modello con un semplice problema di algebra.
Usa questo prompt:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Il modello ha risolto correttamente il problema.
Ha definito correttamente le variabili, creato le equazioni giuste, sostituito i valori in modo corretto e verificato la risposta finale.
La risposta esatta è stata:
In decimali, è approssimativamente:
I valori sommano correttamente al totale di $156.
Infine, verifica se il modello può generare un progetto di programmazione completo adatto ai principianti.
Usa questo prompt:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
La risposta sembrava completa all’inizio e la struttura del progetto aveva senso. Tuttavia, il codice generato presentava diversi problemi seri.
L’output includeva:
Per un progetto adatto ai principianti, questo è un grosso problema. Un principiante dovrebbe poter copiare, eseguire e comprendere il codice con poche correzioni. In questo caso, il progetto generato richiederebbe un debug significativo prima di poter essere usato.
Dopo aver testato DeepSeek V4 Flash su generazione UI, scrittura, ragionamento e generazione di progetto, il modello ha mostrato risultati contrastanti.
Si è comportato bene nel ragionamento strutturato e nella scrittura esplicativa di base. È stato anche in grado di generare output rapidamente tramite la Web UI di llama.cpp.
Tuttavia, ha faticato con design frontend rifiniti e una generazione affidabile di codice per progetti completi. L’output del progetto Python sembrava completo ma conteneva troppi errori di sintassi e denominazione per essere utile senza debug manuale.
|
Attività |
Prestazioni |
|
Generazione UI |
Nella media |
|
Scrittura e spiegazione |
Buone |
|
Ragionamento matematico |
Forte |
|
Generazione progetto completo |
Debole |
|
Velocità |
Buona |
|
Affidabilità complessiva |
Mista |
Eseguire DeepSeek V4 Flash in locale è stato, onestamente, un incubo.
Ho provato prima a eseguirlo su una configurazione 4x H100 usando una configurazione sglang con Docker Compose, ma ha comunque fallito. Poi ho provato a eseguirlo con vLLM su 4x H100 su RunPod usando Python, ma anche quello è fallito. L’errore continuava a indicare il supporto a DeepSeek V4 nell’ultima versione di transformers, anche se stavo già usando l’ultima versione. Questo ha reso chiaro che il supporto a livello di framework non è ancora completo.
Perfino la pagina ufficiale del modello su Hugging Face non fornisce un esempio di inferenza semplice e standard. Invece, indirizza gli utenti verso un approccio personalizzato con torchrun, che è molto più pesante e richiede più lavoro per essere configurato.
Ho testato anche file GGUF forniti dalla community, ma ho incontrato problemi di compatibilità con llama.cpp. Di solito preferisco usare i file GGUF di Unsloth perché sono veloci, affidabili e facili da eseguire, ma per DeepSeek V4 Flash non c’era un percorso semplice plug-and-play.
Dopo tutti questi test, il metodo mostrato in questa guida è stato il modo più semplice e affidabile che ho trovato per eseguire il modello completo in locale. Dipende comunque da un file GGUF della community e da una build modificata di llama.cpp, ma rispetto alle altre opzioni, questa configurazione ha effettivamente funzionato.
Detto questo, non penso che al momento valga la pena eseguire DeepSeek V4 Flash in locale. La configurazione è troppo dolorosa, il supporto dei framework è ancora immaturo e la qualità dell’output non giustifica lo sforzo.
Se vuoi un’esperienza più fluida con i modelli locali, ti consiglio di provare modelli come MiniMax M2.7 o modelli fortemente quantizzati come Qwen3.6-27B invece. Sono più facili da eseguire, meglio supportati nei principali framework, più veloci in pratica e spesso producono risultati di qualità superiore con molta meno frustrazione in fase di setup.
I migliori corsi sugli LLM
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

