track
Dezvoltarea modelelor lingvistice mari
16 oră
DeepSeek V4 Flash este modelul mai mic, mai rapid și mai rentabil din seria de previzualizare DeepSeek V4. Este conceput pentru sarcini practice de inferență, cu un număr mai mic de parametri activi decât DeepSeek V4 Pro și suport pentru sarcini cu context lung. Versiunea GGUF utilizată în acest ghid stochează greutățile dense în FP8 și greutățile MoE în FP4, făcând-o potrivită pentru inferență locală printr-un build personalizat llama.cpp.
În acest ghid, vom rula DeepSeek V4 Flash local pe RunPod folosind un GPU RTX PRO 6000 și un build modificat llama.cpp. Veți învăța cum să configurați podul GPU, să instalați dependențele necesare, să compilați llama.cpp cu suport pentru DeepSeek V4, să descărcați modelul GGUF FP4/FP8 de pe Hugging Face și să-l serviți prin interfața web llama.cpp bazată pe browser.
Înainte de a începe, asigurați-vă că aveți:
Un cont RunPod
Cel puțin 5 $ credit în RunPod
Familiaritate de bază cu comenzile terminalului Linux
Un cont Hugging Face
Un token de acces Hugging Face salvat ca HF_TOKEN
Veți folosi tokenul Hugging Face pentru a descărca modelul mai rapid și mai fiabil.
Dacă doriți să vedeți cum se compară modelul cu competitorii săi proprietari de la OpenAI, recomand să citiți ghidul nostru comparativ DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Mai întâi, creați un pod GPU nou pe RunPod.
Pentru acest ghid, folosim GPU-ul RTX PRO 6000 deoarece oferă 96 GB de VRAM la un cost mult mai mic decât un H100. Aceasta îl face o opțiune practică pentru rularea întregului model DeepSeek V4 Flash pe un singur GPU fără a plăti prețurile premium ale H100.
În panoul RunPod, selectați un pod cu RTX PRO 6000 GPU și utilizați cel mai recent șablon PyTorch ca imagine de bază.
Înainte de a implementa podul, editați setările șablonului și configurați stocarea, portul expus și variabilele de mediu.
Folosiți următoarea configurare recomandată:
|
Setare |
Valoare recomandată |
|
GPU |
RTX PRO 6000 |
|
Container Disk |
50 GB |
|
Volume Disk |
300 GB |
|
Exposed Port |
8910 |
|
Template |
Cel mai recent șablon PyTorch |
|
Variabilă de mediu |
|
Portul expus 8910 este important deoarece acesta este portul pe care îl veți folosi pentru a accesa Interfața Web llama.cpp din browser.
După ce podul este implementat, așteptați câteva secunde până când panoul RunPod afișează linkul JupyterLab.
Deschideți JupyterLab, apoi lansați un terminal. Pentru a confirma că GPU-ul este disponibil, rulați:
nvidia-smi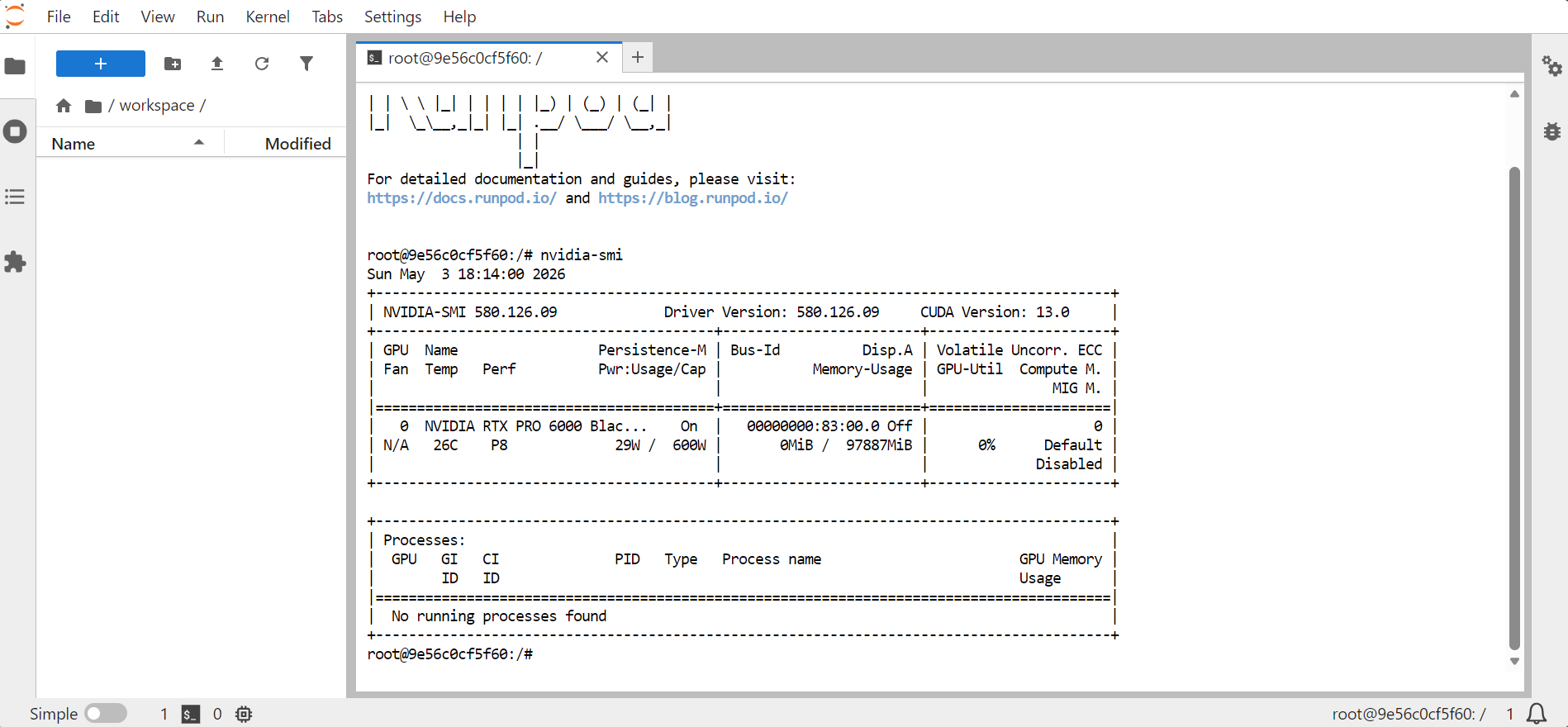
Ar trebui să apară informații despre GPU, memorie, versiunea CUDA și versiunea driverului.
În continuare, instalați dependențele de sistem necesare pentru a compila și rula llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvAceste pachete includ unelte de build, CMake, Git, Python și alte utilitare necesare pentru a compila llama.cpp din sursă.
DeepSeek V4 Flash este încă foarte nou, astfel încât suportul local nu este la fel de simplu ca pentru modelele mai vechi. La momentul scrierii, nu există un release oficial GGUF larg adoptat de la furnizori majori din comunitate, precum Unsloth, pentru rularea întregului model prin llama.cpp upstream standard.
Modelul oficial DeepSeek V4 Flash este disponibil pe Hugging Face, dar ruta GGUF locală depinde încă de conversii din comunitate și de suport runtime experimental. GGUF-ul utilizat în acest ghid menționează în mod specific că versiunea upstream standard de llama.cpp nu îl poate încărca și necesită un build în lucru, cu suport pentru arhitectura DeepSeek V4 Flash, FP8 nativ și MXFP4.
Din acest motiv, această configurare folosește o ramură modificată de llama.cpp a unui contribuitor open-source, în locul versiunii upstream standard. Aceasta este în prezent calea practică pentru testarea locală a întregului GGUF DeepSeek V4 Flash.
Proiectul llama.cpp upstream are, de asemenea, o solicitare deschisă de model pentru suportul DeepSeek V4, ceea ce arată că suportul oficial este încă în lucru și nu a fost încă îmbinat complet în proiectul principal.
Mutați-vă în directorul workspace:
cd /workspaceClonați depozitul modificat:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Configurați acum build-ul folosind CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseAceasta activează suportul CUDA, astfel încât modelul să poată folosi accelerarea GPU.
Compilați binarele necesare:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitDupă ce build-ul se finalizează, copiați binarele în dosarul principal al proiectului:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/În cele din urmă, verificați că binarul serverului funcționează:
llama.cpp-deepseek-v4/llama-server --helpDacă apare meniul de ajutor, build-ul a reușit.
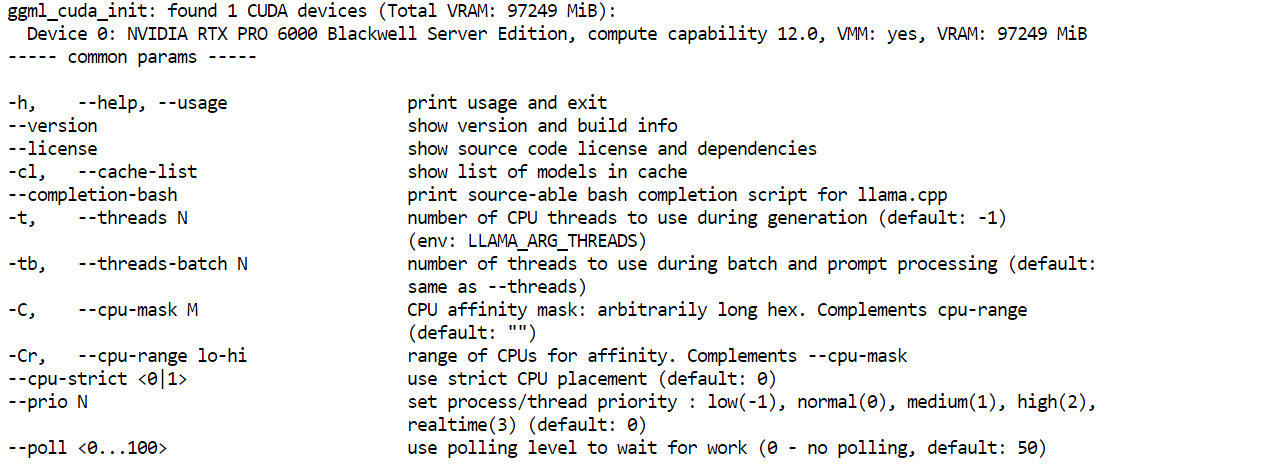
În continuare, instalați instrumentele de descărcare Hugging Face. Aici devine important HF_TOKEN-ul pe care l-ați adăugat mai devreme. Deoarece acesta este un fișier mare de model, autentificarea cu tokenul Hugging Face îmbunătățește fiabilitatea descărcării și vă oferă acces la metode mai rapide de descărcare.
Instalați pachetele necesare:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferActivați descărcări Hugging Face mai rapide:
export HF_HUB_ENABLE_HF_TRANSFER=1Creați un folder pentru model:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Descărcați fișierul de model GGUF:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Cu hf_transfer activat și cu HF_TOKEN deja setat în mediul RunPod, descărcarea modelului poate atinge viteze foarte mari.
În această configurare, descărcarea a ajuns la aproape 2 GB pe secundă, ceea ce face mult mai practică descărcarea unui fișier GGUF mare. Această viteză este posibilă doar când tokenul Hugging Face este configurat corect, iar podul se poate autentifica la Hugging Face.

După ce descărcarea este completă, verificați fișierul:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Ar trebui să vedeți un fișier similar cu acesta:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufAcum că modelul este descărcat și build-ul modificat llama.cpp este gata, următorul pas este să porniți serverul local de inferență, astfel încât să puteți accesa DeepSeek V4 Flash prin Interfața Web bazată pe browser și endpointul API.
Mutați-vă în directorul llama.cpp:
cd /workspace/llama.cpp-deepseek-v4Porniți serverul de model:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfAceastă comandă încarcă modelul GGUF, expune serverul pe 0.0.0.0:8910, aplică șablonul de chat Jinja, folosește --fit on pentru a încadra modelul în memoria GPU și de sistem disponibilă, setează o fereastră de context 32K, activează batching prietenos cu CUDA și Flash Attention pentru o inferență mai rapidă și pornește metricele și jurnalizarea performanței pentru a putea monitoriza rularea.
Încărcarea modelului în memoria GPU și CPU poate dura cel puțin un minut.

Când serverul este gata, ar trebui să vedeți un mesaj care arată că „ascultă pe http://0.0.0.0:8910”.

Aceasta înseamnă că serverul modelului rulează și este gata să primească cereri.
Întoarceți-vă la panoul RunPod. Căutați portul expus 8910, apoi faceți clic pe linkul portului.
Se va deschide Interfața Web llama.cpp în browser. Interfața seamănă cu o interfață de chat de tip ChatGPT.
După ce se deschide pagina, modelul ar trebui să fie deja încărcat. Puteți începe să discutați cu el direct din browser.
După ce serverul rulează, puteți testa modelul folosind diferite tipuri de prompturi.
Scopul este să verificați cât de bine performează în:
Folosiți următorul prompt:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
În acest test, modelul a generat pagina HTML în aproximativ 2 minute, ceea ce este un timp rezonabil.
Pentru a previzualiza pagina generată, căutați pictograma ochi din apropierea rezultatului de cod din Interfața Web. Faceți clic pentru a deschide pagina web redată.
Pagina a funcționat, dar calitatea vizuală nu a fost foarte impresionantă. Layoutul a fost funcțional, dar designul a părut de bază. Modelele mai mici pot produce uneori rezultate front-end mai finisate, așa că acest rezultat a fost modest pentru generarea de UI.
În continuare, testați capacitatea de scriere a modelului.
Folosiți acest prompt:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Modelul a produs un raport clar și bine structurat. A explicat ideile principale într-un mod simplu și a inclus exemple utile de utilizare a uneltelor, planificare, memorie, reflecție și automatizare în afaceri.
Totuși, pe alocuri, rezultatul a părut ușor generic și promoțional, în special spre concluzie. Au fost și câteva probleme de formatare și ortografie, cum ar fi aldine inconsistente și erori de redactare precum „Mainate Context”.
Acum testați capacitatea de raționament a modelului cu o problemă simplă de algebră.
Folosiți acest prompt:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Modelul a rezolvat corect problema.
A definit corect variabilele, a construit ecuațiile corecte, a substituit valorile corect și a verificat răspunsul final.
Răspunsul exact a fost:
Ca zecimale, aproximativ:
Valorile însumează corect totalul de 156 $.
În final, testați dacă modelul poate genera un proiect de programare complet, prietenos pentru începători.
Folosiți acest prompt:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
Răspunsul a părut complet la prima vedere, iar structura proiectului a avut sens. Totuși, codul generat a avut mai multe probleme serioase.
Ieșirea a inclus:
Pentru un proiect prietenos pentru începători, aceasta este o problemă majoră. Un începător ar trebui să poată copia, rula și înțelege codul cu corecții minime. În acest caz, proiectul generat ar avea nevoie de o depanare semnificativă înainte de a putea fi folosit.
După testarea DeepSeek V4 Flash la generare UI, scriere, raționament și generarea unui proiect, modelul a arătat rezultate mixte.
A performat bine la raționament structurat și scriere explicativă de bază. A reușit, de asemenea, să genereze rapid rezultate prin Interfața Web llama.cpp.
Totuși, a avut dificultăți la designul frontend finisat și la generarea fiabilă a unui proiect complet de cod. Ieșirea pentru proiectul Python a părut completă, dar a conținut prea multe erori de sintaxă și denumire pentru a fi utilă fără depanare manuală.
|
Sarcină |
Performanță |
|
Generare UI |
Mediocră |
|
Scriere și explicații |
Bună |
|
Raționament matematic |
Puternic |
|
Generarea unui proiect complet |
Slabă |
|
Viteză |
Bună |
|
Fiabilitate generală |
Mixtă |
Să rulez local DeepSeek V4 Flash a fost, sincer, un coșmar.
Am încercat mai întâi să-l rulez pe o configurație 4x H100 folosind o configurație sglang cu Docker Compose, dar tot a eșuat. Apoi am încercat să-l rulez cu vLLM pe 4x H100 RunPod folosind Python, dar nici asta nu a reușit. Eroarea indica în mod constant suportul DeepSeek V4 în ultima versiune de transformers, deși foloseam deja cea mai recentă versiune. A devenit clar că suportul adecvat în framework-uri nu este încă pe deplin disponibil.
Chiar și pagina oficială a modelului pe Hugging Face nu oferă un exemplu simplu și standard de inferență. În schimb, îi direcționează pe utilizatori către o abordare personalizată torchrun, care este mult mai greoaie și necesită mai mult efort pentru configurare.
Am testat și fișiere GGUF furnizate de comunitate, dar m-am lovit de probleme de compatibilitate cu llama.cpp. De obicei, prefer fișierele GGUF Unsloth deoarece sunt rapide, fiabile și ușor de rulat, dar pentru DeepSeek V4 Flash nu a existat o cale simplă plug-and-play.
După toate aceste teste, metoda prezentată în acest ghid a fost cea mai ușoară și mai fiabilă modalitate pe care am găsit-o pentru a rula local întregul model. Depinde totuși de un fișier GGUF din comunitate și de un build llama.cpp modificat, dar, comparativ cu celelalte opțiuni, această configurare chiar a funcționat.
Cu toate acestea, nu cred că DeepSeek V4 Flash merită rulat local în acest moment. Configurarea este prea anevoioasă, suportul în framework-uri este încă imatur, iar calitatea rezultatelor nu justifică efortul.
Dacă doriți o experiență mai lină cu modele locale, aș recomanda să încercați modele precum MiniMax M2.7 sau modele puternic cuantizate precum Qwen3.6-27B. Sunt mai ușor de rulat, mai bine susținute în principalele framework-uri, mai rapide în practică și, adesea, produc rezultate de calitate mai bună cu mult mai puțină frustrare la configurare.
Top cursuri LLM
track
course
course