Tracks
การพัฒนาโมเดลภาษาขนาดใหญ่
16 ชม.
DeepSeek V4 Flash เป็นโมเดลที่เล็กกว่า เร็วกว่า และคุ้มค่ากว่าในซีรีส์พรีวิว DeepSeek V4 ออกแบบมาสำหรับงานอินเฟอเรนซ์จริง มีจำนวนพารามิเตอร์ที่ทำงานอยู่ต่ำกว่า DeepSeek V4 Pro และรองรับงานที่ต้องใช้บริบทยาว เวอร์ชัน GGUF ที่ใช้ในคู่มือนี้จัดเก็บเวทแบบ dense ใน FP8 และเวท MoE ใน FP4 ทำให้เหมาะสำหรับการอินเฟอเรนซ์แบบโลคัลผ่านบิลด์ llama.cpp แบบกำหนดเอง
ในคู่มือนี้ เราจะรัน DeepSeek V4 Flash แบบโลคัลบน RunPod โดยใช้ GPU รุ่น RTX PRO 6000 และบิลด์ llama.cpp ที่ปรับแต่ง คุณจะได้เรียนรู้การตั้งค่า GPU pod ติดตั้ง dependency ที่ต้องใช้ คอมไพล์ llama.cpp ให้รองรับ DeepSeek V4 ดาวน์โหลดโมเดล GGUF แบบ FP4/FP8 จาก Hugging Face และให้บริการผ่าน llama.cpp Web UI บนเบราว์เซอร์
ก่อนเริ่มต้น โปรดตรวจสอบว่ามีสิ่งต่อไปนี้:
บัญชี RunPod
เครดิต RunPod อย่างน้อย $5
คุ้นเคยกับคำสั่งพื้นฐานบนเทอร์มินัล Linux
บัญชี Hugging Face
โทเค็นเข้าถึง Hugging Face ที่บันทึกเป็น HF_TOKEN
คุณจะใช้โทเค็น Hugging Face เพื่อดาวน์โหลดโมเดลได้เร็วและเสถียรกว่า
หากต้องการดูว่าโมเดลนี้เทียบกับคู่แข่งเชิงกรรมสิทธิ์จาก OpenAI อย่างไร แนะนำให้อ่านคู่มือเปรียบเทียบ DeepSeek V4 Flash vs GPT-5.4 Mini and Nano
ก่อนอื่น ให้สร้าง GPU pod ใหม่บน RunPod
สำหรับคู่มือนี้ เราใช้ RTX PRO 6000 GPU เพราะให้ VRAM 96GB ในราคาต่ำกว่า H100 มาก จึงเป็นตัวเลือกที่ใช้งานได้จริงสำหรับการรันโมเดล DeepSeek V4 Flash ฉบับเต็มบน GPU เดียวโดยไม่ต้องจ่ายราคาแพงระดับ H100
บนแดชบอร์ด RunPod ให้เลือก pod แบบ RTX PRO 6000 GPU และใช้ เทมเพลต PyTorch เวอร์ชันล่าสุด เป็นอิมเมจฐาน
ก่อนดีพลอย pod ให้แก้ไขการตั้งค่าเทมเพลตและกำหนดพื้นที่จัดเก็บ พอร์ตที่เปิด และตัวแปรสภาพแวดล้อม
ใช้การตั้งค่าที่แนะนำต่อไปนี้:
|
การตั้งค่า |
ค่าที่แนะนำ |
|
GPU |
RTX PRO 6000 |
|
Container Disk |
50 GB |
|
Volume Disk |
300 GB |
|
Exposed Port |
8910 |
|
Template |
เทมเพลต PyTorch เวอร์ชันล่าสุด |
|
Environment Variable |
|
พอร์ตที่เปิด 8910 สำคัญเพราะเป็นพอร์ตที่ใช้เข้าถึง llama.cpp Web UI จากเบราว์เซอร์
เมื่อดีพลอย pod แล้ว ให้รอสักครู่จนแดชบอร์ด RunPod แสดงลิงก์ JupyterLab
เปิด JupyterLab แล้วเปิดเทอร์มินัล เพื่อยืนยันว่า GPU พร้อมใช้งาน ให้รัน:
nvidia-smi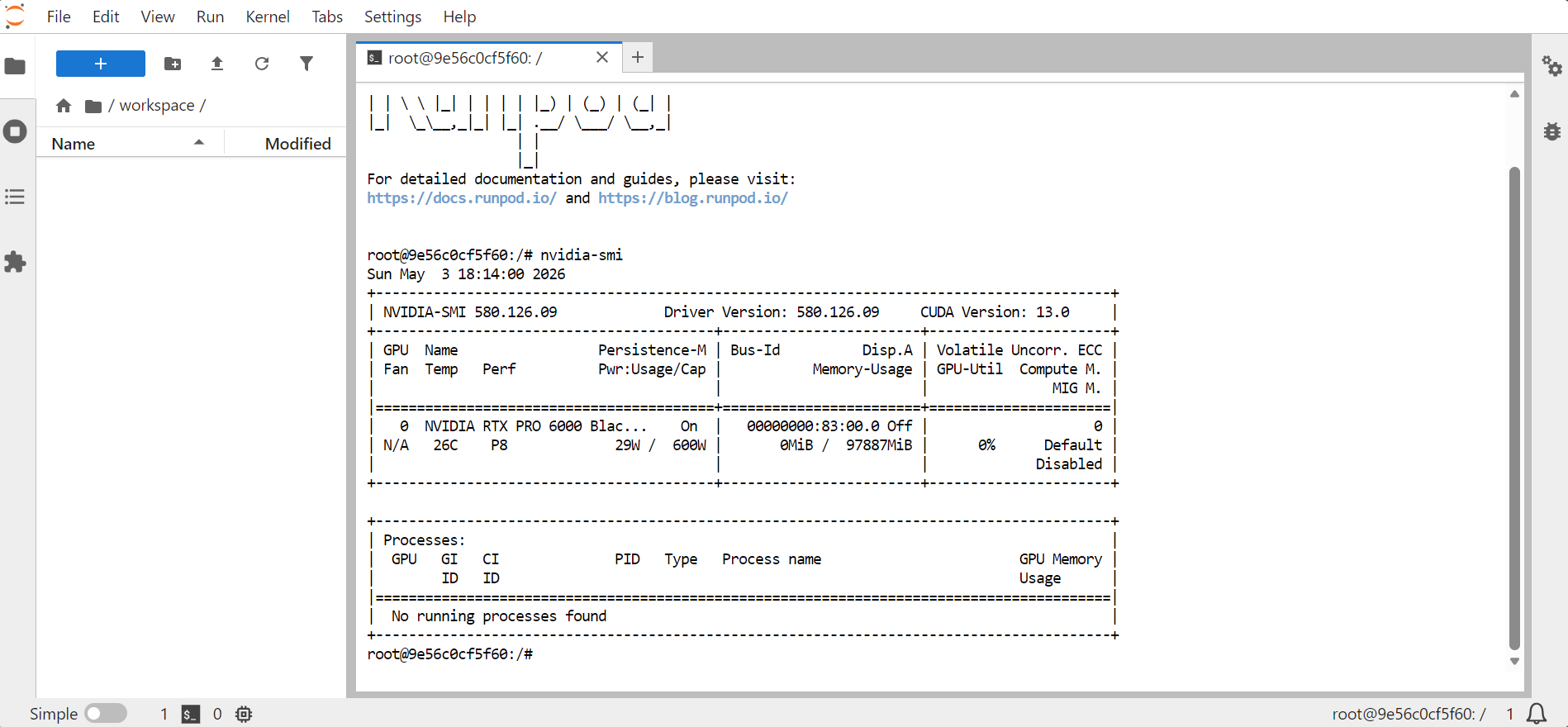
ควรแสดงข้อมูลเกี่ยวกับ GPU หน่วยความจำ เวอร์ชัน CUDA และเวอร์ชันไดรเวอร์
ถัดไป ติดตั้ง system dependency ที่ต้องใช้ในการบิลด์และรัน llama.cpp
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvแพ็กเกจเหล่านี้รวมถึงเครื่องมือสำหรับบิลด์ CMake Git Python และยูทิลิตีอื่น ๆ ที่จำเป็นต่อการคอมไพล์ llama.cpp จากซอร์ส
DeepSeek V4 Flash ยังใหม่มาก ดังนั้นการรองรับแบบโลคัลจึงยังไม่ตรงไปตรงมาเหมือนโมเดลรุ่นเก่า ณ ตอนเขียน ยังไม่มีการออก GGUF อย่างเป็นทางการที่ถูกใช้งานแพร่หลายจากผู้ให้บริการในคอมมูนิตี้ เช่น Unsloth สำหรับการรันโมเดลเต็มผ่าน llama.cpp ต้นน้ำมาตรฐาน
โมเดล DeepSeek V4 Flash อย่างเป็นทางการมีให้บน Hugging Face แต่เส้นทาง GGUF แบบโลคัวยังพึ่งพาการคอนเวอร์ชันจากคอมมูนิตี้และการรองรับรันไทม์เชิงทดลอง GGUF ที่ใช้ในคู่มือนี้ระบุชัดว่า llama.cpp ต้นน้ำแบบสต็อกไม่สามารถโหลดได้ และต้องใช้บิลด์ที่ยังอยู่ระหว่างการพัฒนา ซึ่งรองรับสถาปัตยกรรม DeepSeek V4 Flash, FP8 แบบ native และ MXFP4
ด้วยเหตุนี้ การตั้งค่านี้จึงใช้สาขา llama.cpp ที่ผู้มีส่วนร่วมโอเพ่นซอร์สปรับแต่ง แทนที่จะใช้เวอร์ชันต้นน้ำมาตรฐาน ขณะนี้นี่คือวิธีที่ใช้งานได้จริงสำหรับทดสอบ GGUF ของ DeepSeek V4 Flash ฉบับเต็มแบบโลคัล
โปรเจ็กต์ llama.cpp ต้นน้ำยังมีคำขอรองรับโมเดล DeepSeek V4 อยู่ แสดงว่าการรองรับอย่างเป็นทางการยังอยู่ระหว่างดำเนินการและยังไม่ถูกรวมเข้ากับโปรเจ็กต์หลักเต็มรูปแบบ
ย้ายไปยังไดเรกทอรี workspace:
cd /workspaceโคลนรีโพสิทอรีที่ปรับแต่ง:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4จากนั้นคอนฟิกการบิลด์ด้วย CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Releaseนี่จะเปิดใช้การรองรับ CUDA ทำให้โมเดลใช้งานการเร่งบน GPU ได้
บิลด์ไบนารีที่ต้องใช้:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitหลังบิลด์เสร็จ ให้คัดลอกไบนารีไปยังโฟลเดอร์โปรเจ็กต์หลัก:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/สุดท้าย ตรวจสอบว่าไบนารีของเซิร์ฟเวอร์ทำงานได้:
llama.cpp-deepseek-v4/llama-server --helpหากเมนูช่วยเหลือปรากฏ แสดงว่าบิลด์สำเร็จ
ถัดไป ติดตั้งเครื่องมือดาวน์โหลดของ Hugging Face ตรงนี้ HF_TOKEN ที่เพิ่มไว้ก่อนหน้าจะมีความสำคัญ เนื่องจากไฟล์โมเดลมีขนาดใหญ่ การล็อกอินด้วยโทเค็น Hugging Face จะช่วยให้ดาวน์โหลดได้เสถียรขึ้นและเข้าถึงวิธีดาวน์โหลดที่เร็วขึ้น
ติดตั้งแพ็กเกจที่ต้องใช้:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferเปิดใช้การดาวน์โหลดจาก Hugging Face ที่เร็วขึ้น:
export HF_HUB_ENABLE_HF_TRANSFER=1สร้างโฟลเดอร์สำหรับโมเดล:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8ดาวน์โหลดไฟล์โมเดล GGUF:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8เมื่อเปิดใช้ hf_transfer และตั้งค่า HF_TOKEN ในแวดล้อม RunPod แล้ว ความเร็วในการดาวน์โหลดโมเดลจะสูงมาก
ในการตั้งค่านี้ ความเร็วดาวน์โหลดเกือบ 2 GB ต่อวินาที ทำให้การดาวน์โหลดไฟล์ GGUF ขนาดใหญ่เป็นเรื่องที่ทำได้จริง ความเร็วระดับนี้จะเกิดขึ้นได้ก็ต่อเมื่อกำหนดค่าโทเค็น Hugging Face ถูกต้อง และ pod สามารถยืนยันตัวตนกับ Hugging Face ได้

เมื่อดาวน์โหลดเสร็จ ให้ตรวจสอบไฟล์:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8ควรเห็นไฟล์ลักษณะนี้:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufตอนนี้ดาวน์โหลดโมเดลเสร็จแล้วและมีบิลด์ llama.cpp ที่ปรับแต่งพร้อมใช้งาน ขั้นตอนถัดไปคือเริ่มต้นเซิร์ฟเวอร์อินเฟอเรนซ์แบบโลคัล เพื่อเข้าถึง DeepSeek V4 Flash ผ่าน Web UI บนเบราว์เซอร์และเอ็นด์พอยต์ API
ย้ายไปยังไดเรกทอรี llama.cpp:
cd /workspace/llama.cpp-deepseek-v4เริ่มต้นเซิร์ฟเวอร์โมเดล:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfคำสั่งนี้จะโหลดโมเดล GGUF เปิดให้เข้าถึงเซิร์ฟเวอร์ที่ 0.0.0.0:8910 ใช้ Jinja chat template ใช้ --fit on เพื่อทำให้โมเดลพอดีกับหน่วยความจำ GPU และระบบที่มีอยู่ ตั้งค่าหน้าต่างบริบท 32K เปิดใช้การแบตช์ที่เหมาะกับ CUDA และ Flash Attention เพื่อให้ทำอินเฟอเรนซ์ได้เร็วขึ้น และเปิด metrics กับบันทึกประสิทธิภาพเพื่อให้ติดตามการรันได้
โมเดลอาจใช้เวลาอย่างน้อยหนึ่งนาทีในการโหลดเข้าสู่หน่วยความจำ GPU และ CPU

เมื่อเซิร์ฟเวอร์พร้อม คุณควรเห็นข้อความว่า “listening on http://0.0.0.0:8910”

นั่นหมายความว่าเซิร์ฟเวอร์โมเดลกำลังทำงานและพร้อมรับคำขอ
กลับไปที่แดชบอร์ด RunPod มองหาพอร์ตที่เปิด 8910 แล้วคลิกลิงก์พอร์ต
จากนั้นจะเปิด llama.cpp Web UI ในเบราว์เซอร์ อินเทอร์เฟซมีลักษณะคล้ายหน้าตาแชตแบบ ChatGPT พื้นฐาน
เมื่อหน้าเปิด โมเดลควรถูกโหลดเรียบร้อยแล้ว สามารถเริ่มสนทนาผ่านเบราว์เซอร์ได้ทันที
หลังเซิร์ฟเวอร์ทำงานแล้ว สามารถทดสอบโมเดลด้วยพรอมป์ตหลายรูปแบบ
เป้าหมายคือทดสอบว่าทำงานได้ดีเพียงใดในด้านต่อไปนี้:
ใช้พรอมป์ตต่อไปนี้:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
การทดสอบนี้ โมเดลใช้เวลาประมาณ 2 นาทีในการสร้างหน้า HTML ซึ่งถือว่าใช้ได้
หากต้องการพรีวิวหน้า ให้มองหาไอคอนรูปตาใกล้เอาต์พุตโค้ดใน Web UI คลิกเพื่อเปิดหน้าเว็บที่เรนเดอร์
หน้าที่ได้ทำงานได้ แต่คุณภาพด้านภาพยังไม่ประทับใจนัก เลย์เอาต์ใช้งานได้แต่ดีไซน์ค่อนข้างพื้นฐาน โมเดลที่เล็กกว่าบางรุ่นยังให้ผลลัพธ์งานหน้าบ้านที่ดูเรียบร้อยกว่า ดังนั้นผลลัพธ์นี้จึงไม่น่าตื่นเต้นสำหรับการสร้าง UI
ถัดไป ทดสอบความสามารถด้านงานเขียนของโมเดล
ใช้พรอมป์ตนี้:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
โมเดลสร้างรายงานที่ชัดเจนและมีโครงสร้างดี อธิบายแนวคิดหลักได้อย่างเรียบง่าย พร้อมยกตัวอย่างที่เป็นประโยชน์เกี่ยวกับการใช้เครื่องมือ การวางแผน หน่วยความจำ การสะท้อนคิด และระบบอัตโนมัติทางธุรกิจ
อย่างไรก็ตาม เนื้อหาบางส่วนค่อนข้างทั่วไปและติดเชิงส่งเสริม โดยเฉพาะช่วงสรุป นอกจากนี้ยังมีปัญหาด้านรูปแบบและการสะกด เช่น ตัวหนาไม่สม่ำเสมอ และคำผิดอย่าง “Mainate Context.”
ตอนนี้ทดสอบความสามารถด้านการให้เหตุผลด้วยโจทย์พีชคณิตง่าย ๆ
ใช้พรอมป์ตนี้:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
โมเดลแก้ปัญหาได้ถูกต้อง
กำหนดตัวแปรได้เหมาะสม สร้างสมการถูกต้อง แทนค่าถูกต้อง และตรวจคำตอบสุดท้ายแล้ว
คำตอบอย่างเป็นเศษส่วนคือ:
แปลงเป็นทศนิยมโดยประมาณ:
ค่าทั้งสองรวมกันได้ถูกต้องเป็น $156
สุดท้าย ทดสอบว่าโมเดลสามารถสร้างโปรเจ็กต์โค้ดระดับผู้เริ่มต้นที่ครบถ้วนได้หรือไม่
ใช้พรอมป์ตนี้:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
ตอนแรกคำตอบดูเหมือนครบถ้วน และโครงสร้างโปรเจ็กต์ก็สมเหตุสมผล อย่างไรก็ตาม โค้ดที่สร้างมีปัญหาร้ายแรงหลายจุด
เอาต์พุตมี:
สำหรับโปรเจ็กต์ที่เป็นมิตรกับผู้เริ่มต้น นี่เป็นปัญหาใหญ่ ผู้เริ่มต้นควรคัดลอก รัน และเข้าใจโค้ดได้โดยแทบไม่ต้องแก้ไข ในกรณีนี้ โปรเจ็กต์ที่สร้างต้องแก้ดีบักอย่างมากก่อนใช้งานได้
หลังทดสอบ DeepSeek V4 Flash ในด้านการสร้าง UI งานเขียน การให้เหตุผล และการสร้างโปรเจ็กต์ โมเดลให้ผลลัพธ์หลากหลาย
ทำได้ดีในงานให้เหตุผลเชิงโครงสร้างและงานเขียนอธิบายพื้นฐาน และสามารถสร้างเอาต์พุตได้รวดเร็วผ่าน llama.cpp Web UI
อย่างไรก็ตาม ยังติดขัดในงานออกแบบส่วนหน้าที่ดูเนี้ยบ และการสร้างโค้ดโปรเจ็กต์แบบครบถ้วนที่เชื่อถือได้ เอาต์พุตโปรเจ็กต์ Python ดูเหมือนครบ แต่มีข้อผิดพลาดด้านไวยากรณ์และการตั้งชื่อมากเกินไป จนใช้งานไม่ได้หากไม่แก้เอง
|
งาน |
ประสิทธิภาพ |
|
การสร้าง UI |
ปานกลาง |
|
งานเขียนและการอธิบาย |
ดี |
|
การให้เหตุผลทางคณิตศาสตร์ |
แข็งแรง |
|
การสร้างโปรเจ็กต์ครบถ้วน |
อ่อน |
|
ความเร็ว |
ดี |
|
ความเชื่อถือโดยรวม |
ผสมผสาน |
พูดกันตรง ๆ การรัน DeepSeek V4 Flash แบบโลคัลเป็นฝันร้าย
ผมเริ่มจากพยายามรันบนชุด 4x H100 โดยใช้การคอนฟิก sglang กับ Docker Compose แต่ก็ยังล้มเหลว จากนั้นลองรันด้วย vLLM บน RunPod แบบ 4x H100 ด้วย Python ก็ยังล้มเหลว ข้อผิดพลาดชี้ไปที่การรองรับ DeepSeek V4 ในเวอร์ชันล่าสุดของ transformers ทั้งที่ใช้เวอร์ชันล่าสุดแล้ว แสดงให้เห็นว่าการรองรับในเฟรมเวิร์กยังไม่สมบูรณ์
แม้แต่หน้าระบุโมเดลอย่างเป็นทางการบน Hugging Face ก็ไม่ให้ตัวอย่างอินเฟอเรนซ์มาตรฐานง่าย ๆ แต่ชี้ไปที่แนวทาง torchrun แบบกำหนดเอง ซึ่งหนักกว่าและตั้งค่ายากกว่า
ผมยังทดสอบไฟล์ GGUF จากคอมมูนิตี้ แต่เจอปัญหาความเข้ากันได้กับ llama.cpp ปกติแล้วผมชอบใช้ ไฟล์ Unsloth GGUF เพราะเร็ว เชื่อถือได้ และรันง่าย แต่สำหรับ DeepSeek V4 Flash ยังไม่มีวิธีเสียบแล้วใช้ได้ทันที
หลังจากทดสอบทั้งหมด วิธีในคู่มือนี้เป็นวิธีที่ง่ายและเชื่อถือได้ที่สุดที่ผมพบสำหรับการรันโมเดลฉบับเต็มแบบโลคัล แม้ยังต้องพึ่งไฟล์ GGUF จากคอมมูนิตี้และบิลด์ llama.cpp ที่ปรับแต่ง แต่เมื่อเทียบกับทางเลือกอื่น การตั้งค่านี้ใช้งานได้จริง
อย่างไรก็ตาม ผมไม่คิดว่าเวลานี้ DeepSeek V4 Flash จะคุ้มค่าที่จะรันแบบโลคัล การตั้งค่ายุ่งยาก การรองรับเฟรมเวิร์กยังไม่สุกงอม และคุณภาพเอาต์พุตยังไม่คุ้มกับความพยายาม
หากต้องการประสบการณ์โมเดลโลคัลที่ลื่นไหลกว่า ผมแนะนำให้ลองโมเดล อย่าง MiniMax M2.7 หรือ โมเดลควอนไตซ์ประสิทธิภาพสูงอย่าง Qwen3.6-27B แทน จะรันได้ง่ายกว่า รองรับในเฟรมเวิร์กหลักดีกว่า เร็วกว่าในการใช้งานจริง และมักให้ผลลัพธ์คุณภาพสูงกว่าด้วยการตั้งค่าน้อยกว่ามาก
คอร์ส LLM แนะนำ
Tracks
Courses
Courses