Tracks
大規模言語モデル(LLM)の開発
16時間
DeepSeek V4 Flash は、DeepSeek V4 プレビューシリーズの中で小型・高速・高コスト効率のモデルです。実運用の推論ワークロード向けに設計されており、DeepSeek V4 Pro よりアクティブパラメータが少なく、長文コンテキストのタスクをサポートします。本ガイドで使用する GGUF 版は、密結合重みを FP8、MoE エキスパート重みを FP4 で保持しており、カスタムの llama.cpp ビルドでローカル推論が可能です。
本ガイドでは、RunPod 上で DeepSeek V4 Flash をローカル実行します。使用するのは RTX PRO 6000 GPU と修正済みの llama.cpp ビルドです。GPU ポッドのセットアップ、必要な依存関係のインストール、DeepSeek V4 対応での llama.cpp のコンパイル、Hugging Face からの FP4/FP8 GGUF モデルのダウンロード、そしてブラウザベースの llama.cpp Web UI を通じた提供方法を学びます。
開始前に、次をご用意ください。
RunPod アカウント
RunPod クレジット $5 以上
Linux 端末コマンドの基礎知識
Hugging Face アカウント
HF_TOKEN として保存した Hugging Face アクセストークン
Hugging Face トークンは、モデルのダウンロードを高速かつ安定的に行うために使用します。
モデルが OpenAI のプロプライエタリ競合と比べてどうか知りたい場合は、DeepSeek V4 Flash と GPT-5.4 Mini/Nano の比較ガイドをおすすめします。
まず、RunPod で新しい GPU ポッドを作成します。
本ガイドでは、RTX PRO 6000 GPU を使用します。これは 96GB の VRAM を備え、H100 よりも大幅に低コストです。単一 GPU で DeepSeek V4 Flash のフルモデルを、H100 のプレミアム価格を払わずに実行する実用的な選択肢となります。
RunPod ダッシュボードで RTX PRO 6000 GPU のポッドを選び、ベースイメージには最新の PyTorch テンプレートを使用してください。
ポッドをデプロイする前に、テンプレート設定を編集して、ストレージ、公開ポート、環境変数を構成します。
以下の推奨設定を使用してください。
|
設定 |
推奨値 |
|
GPU |
RTX PRO 6000 |
|
コンテナディスク |
50 GB |
|
ボリュームディスク |
300 GB |
|
公開ポート |
8910 |
|
テンプレート |
最新の PyTorch テンプレート |
|
環境変数 |
|
公開ポート 8910 は重要です。ブラウザから llama.cpp の Web UI にアクセスする際にこのポートを使用します。
ポッドがデプロイされたら、RunPod ダッシュボードに JupyterLab のリンクが表示されるまで数秒待ちます。
JupyterLab を開き、ターミナルを起動します。GPU が利用可能か確認するには次を実行してください:
nvidia-smi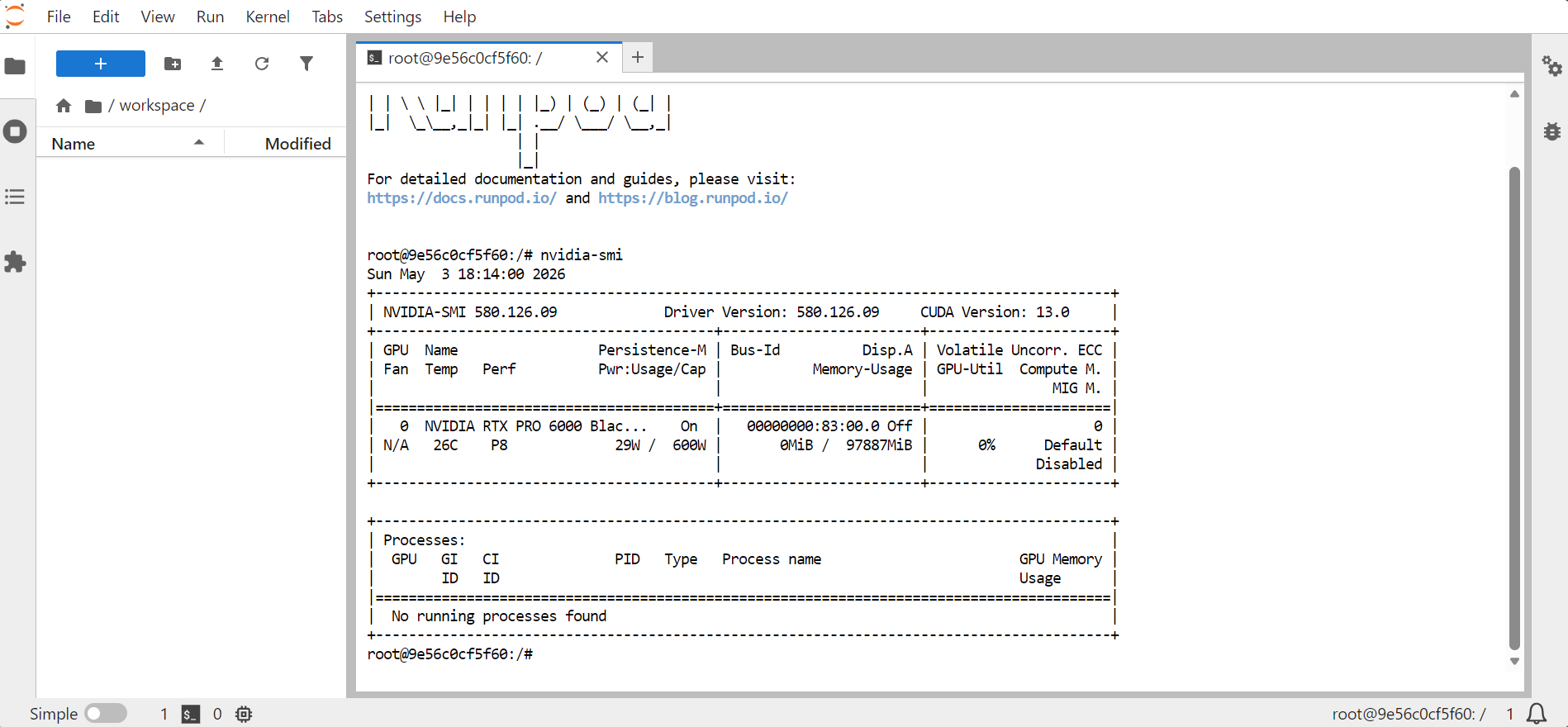
GPU、メモリ、CUDA バージョン、ドライババージョンの情報が表示されるはずです.
次に、llama.cpp のビルドと実行に必要なシステム依存関係をインストールします。
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvこれらのパッケージには、ビルドツール、CMake、Git、Python、その他 llama.cpp をソースからコンパイルするために必要なユーティリティが含まれます。
DeepSeek V4 Flash はまだ登場したばかりで、ローカル対応は従来モデルほど単純ではありません。執筆時点では、Unsloth のような主要コミュニティ提供元から、標準の上流版 llama.cpp でフルモデルを実行できる広く採用された公式 GGUF リリースはありません。
公式の DeepSeek V4 Flash モデルは Hugging Face 上で提供されていますが、ローカルの GGUF ルートはコミュニティによる変換と実験的なランタイム対応に依存しています。本ガイドで使用する GGUF は、標準の上流版 llama.cpp では読み込めず、DeepSeek V4 Flash のアーキテクチャ対応、ネイティブ FP8、MXFP4 対応を備えた作業中のビルドが必要であると明記しています。
そのため本セットアップでは、標準の上流版ではなく、オープンソース貢献者による修正ブランチの llama.cpp を使用します。これは現時点で、DeepSeek V4 Flash のフル GGUF をローカルで試す実用的な方法です。
上流の llama.cpp プロジェクトでも DeepSeek V4 対応に関するオープンなモデルリクエストがあり、正式対応が進行中でメインプロジェクトに完全統合されていないことが示されています。
作業ディレクトリに移動します:
cd /workspace修正リポジトリをクローンします:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4次に CMake でビルド設定を行います:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Releaseこれは CUDA 対応を有効にし、GPU アクセラレーションを利用できるようにします。
必要なバイナリをビルドします:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitビルド完了後、バイナリをメインのプロジェクトフォルダにコピーします:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/最後に、サーバーバイナリが動作するか確認します:
llama.cpp-deepseek-v4/llama-server --helpヘルプメニューが表示されれば、ビルドは成功です。
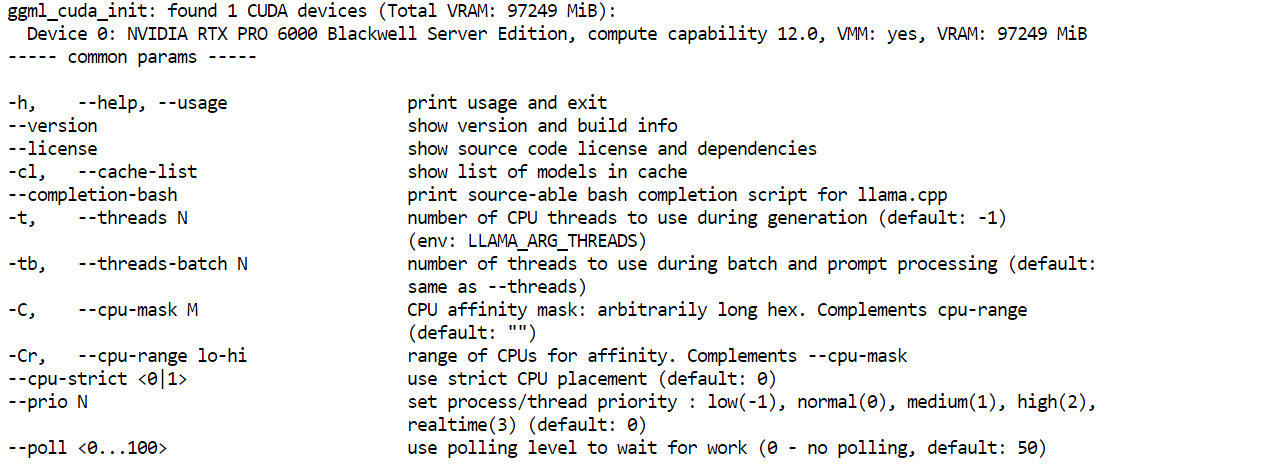
次に、Hugging Face のダウンロードツールをインストールします。ここで、先ほど追加した HF_TOKEN が重要になります。大きなモデルファイルのため、Hugging Face トークンでログインすると、より安定して高速なダウンロード方法が利用できます。
必要なパッケージをインストールします:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferHugging Face の高速ダウンロードを有効化します:
export HF_HUB_ENABLE_HF_TRANSFER=1モデル用のフォルダを作成します:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8GGUF モデルファイルをダウンロードします:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8hf_transfer を有効化し、RunPod 環境に HF_TOKEN が設定されていれば、モデルのダウンロードは非常に高速になります。
本セットアップでは、ダウンロード速度が 毎秒 2 GB 近くに達しました。大容量の GGUF ファイルでも実用的な速度です。この速度は、Hugging Face トークンが適切に設定され、ポッドが Hugging Face に認証できている場合にのみ可能です。

ダウンロードが完了したら、ファイルを検証します:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8次のようなファイルが表示されるはずです:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufモデルのダウンロードと修正済み llama.cpp の準備ができたら、ローカル推論サーバーを起動し、ブラウザベースの Web UI と API エンドポイントから DeepSeek V4 Flash にアクセスできるようにします.
llama.cpp ディレクトリに移動します:
cd /workspace/llama.cpp-deepseek-v4モデルサーバーを起動します:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfこのコマンドは GGUF モデルを読み込み、0.0.0.0:8910 でサーバーを公開し、Jinja チャットテンプレートを適用します。--fit on で利用可能な GPU・システムメモリに合わせてモデルを収め、32K のコンテキストウィンドウを設定し、CUDA に適したバッチ処理と Flash Attention を有効にして推論を高速化、さらにメトリクスとパフォーマンスログを有効化して実行状況を監視できるようにします。
モデルの読み込みには、GPU と CPU メモリへの展開で少なくとも 1 分ほどかかる場合があります。

サーバーの準備が整うと、「listening on http://0.0.0.0:8910」というメッセージが表示されます。

これでモデルサーバーが起動し、リクエストを受け付ける準備ができました。
RunPod のダッシュボードに戻ります。公開ポート 8910 を探して、リンクをクリックします。
ブラウザで llama.cpp の Web UI が開きます。インターフェースは、基本的な ChatGPT 風のチャット画面に似ています。
ページが開いた時点で、モデルはすでに読み込まれているはずです。ブラウザからそのまま会話を開始できます。
サーバーが起動したら、さまざまな種類のプロンプトでモデルをテストできます。
以下の観点での性能を確認します:
次のプロンプトを使用します:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
このテストでは、モデルは約 2 分で HTML ページを生成しました。妥当な時間です。
生成されたページをプレビューするには、Web UI のコード出力付近にある目のアイコンを探してください。クリックすると、レンダリングされた Web ページが開きます。
ページは動作しましたが、見た目のクオリティはあまり高くありませんでした。レイアウトは機能しているものの、デザインは基本的すぎる印象です。小型モデルのほうがフロントエンドの完成度が高いこともあるため、UI 生成としてはやや物足りない結果でした。
次に、モデルの文章作成能力をテストします。
このプロンプトを使用します:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
モデルは明快で構造化されたレポートを生成しました。主要な概念を平易に説明し、ツール使用、計画、メモリ、内省、業務自動化の有用な例を含んでいました。
一方で、結論付近を中心に、やや凡庸で宣伝的に感じられる箇所も見受けられました。また、太字の不整合や「Mainate Context」のような表記ミスなど、フォーマットやスペルの問題もいくつかありました。
次に、簡単な代数の問題でモデルの推論能力をテストします。
このプロンプトを使用します:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
モデルは正しく問題を解きました。
変数の定義、方程式の構築、値の代入、最終結果の検算まで適切に行われていました。
厳密解は次のとおりです:
小数ではおよそ次の値です:
これらの値は合計で $156 となり、正しく一致します。
最後に、初心者向けのコーディングプロジェクトを完全に生成できるかをテストします。
このプロンプトを使用します:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
一見すると回答は完結しており、プロジェクト構成も理にかなっていました。しかし、生成コードにはいくつか重大な問題がありました。
出力には次が含まれていました:
初心者向けプロジェクトとしては大きな問題です。初心者は最小限の修正でコピーして実行・理解できるべきですが、このケースでは実用に足るまでに相当なデバッグが必要でした。
UI 生成、ライティング、推論、プロジェクト生成で DeepSeek V4 Flash をテストした結果は、まちまちでした。
構造化された推論や基本的な解説文では良好に動作し、llama.cpp の Web UI で素早く出力を生成できました。
一方で、フロントエンドの洗練度や、信頼性の高いフルプロジェクトのコード生成には苦戦しました。Python プロジェクトは一見完結して見えるものの、構文や命名の誤りが多く、手作業のデバッグなしでは有用とは言えませんでした。
|
タスク |
パフォーマンス |
|
UI 生成 |
平均的 |
|
ライティングと説明 |
良好 |
|
数学的推論 |
強い |
|
フルプロジェクト生成 |
弱い |
|
速度 |
良好 |
|
総合的な信頼性 |
混在 |
正直なところ、DeepSeek V4 Flash をローカルで動かすのは悪戦苦闘でした。
最初は sglang と Docker Compose 構成で 4x H100 セットアップ上での実行を試しましたが、失敗しました。次に、Python と vLLM を使い RunPod の 4x H100 で実行を試みましたが、これも失敗。エラーは一貫して最新の transformers における DeepSeek V4 対応を指摘しており、最新バージョンを使っているにもかかわらず同様でした。フレームワークの正式対応がまだ十分ではないことが明らかでした。
Hugging Face の公式モデルページも、単純で標準的な推論例を提供していません。代わりにカスタムの torchrun アプローチを案内しており、これははるかに重く、セットアップの手間も増えます。
コミュニティ提供の GGUF も試しましたが、llama.cpp との互換性問題に直面しました。通常は、高速・信頼性・実行の容易さから Unsloth の GGUF ファイルを好んで使用しますが、DeepSeek V4 Flash については簡単なプラグアンドプレイの道筋がありませんでした。
そうした検証の末、本ガイドの方法が、フルモデルをローカルで実行する最も簡単で確実な手段でした。コミュニティの GGUF と修正済み llama.cpp に依存はしますが、他の選択肢に比べて実際に動作しました。
とはいえ、現時点で DeepSeek V4 Flash をローカル実行する価値は高くないと考えます。セットアップが煩雑で、フレームワーク対応は未成熟、出力品質も労力に見合いません。
よりスムーズなローカルモデル体験を求めるなら、MiniMax M2.7 や、高品質な量子化モデルである Qwen3.6-27B などをおすすめします。主要フレームワークでの対応が手厚く、実運用で速く、セットアップのストレスも少なく、高品質な結果を得やすいです。
おすすめの LLM 講座
Tracks
Courses
Courses