
Cursus
Développer des LLM
16 h
DeepSeek V4 Flash est le modèle le plus compact, le plus rapide et le plus économique de la série de prévisualisation DeepSeek V4. Il est conçu pour des charges d'inférence concrètes, avec moins de paramètres actifs que DeepSeek V4 Pro et la prise en charge des tâches à long contexte. La version GGUF utilisée dans ce guide stocke les poids denses en FP8 et les poids MoE en FP4, ce qui la rend adaptée à l'inférence locale via une build personnalisée de llama.cpp.
Dans ce guide, nous allons exécuter DeepSeek V4 Flash en local sur RunPod en utilisant un GPU RTX PRO 6000 et une build modifiée de llama.cpp. Vous apprendrez à préparer le pod GPU, installer les dépendances nécessaires, compiler llama.cpp avec la prise en charge de DeepSeek V4, télécharger le modèle GGUF FP4/FP8 depuis Hugging Face et l'exposer via l'interface Web de llama.cpp.
Avant de commencer, assurez-vous d'avoir :
Un compte RunPod
Au moins 5 $ de crédit RunPod
Des bases en commandes du terminal Linux
Un compte Hugging Face
Un jeton d'accès Hugging Face enregistré sous HF_TOKEN
Vous utiliserez le jeton Hugging Face pour télécharger le modèle plus rapidement et de manière plus fiable.
Si vous souhaitez voir comment le modèle se positionne face à ses concurrents propriétaires d'OpenAI, nous vous recommandons de lire notre guide de comparaison DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Commencez par créer un nouveau pod GPU sur RunPod.
Pour ce guide, nous utilisons le GPU RTX PRO 6000 car il offre 96 Go de VRAM à un coût bien inférieur à celui d'un H100. C'est une option pratique pour exécuter l'intégralité du modèle DeepSeek V4 Flash sur un seul GPU sans payer le prix premium d'un H100.
Dans le tableau de bord RunPod, sélectionnez un pod RTX PRO 6000 et utilisez le template PyTorch le plus récent comme image de base.
Avant de déployer le pod, modifiez les paramètres du template et configurez le stockage, le port exposé et les variables d'environnement.
Utilisez la configuration recommandée suivante :
|
Paramètre |
Valeur recommandée |
|
GPU |
RTX PRO 6000 |
|
Disque du conteneur |
50 Go |
|
Disque du volume |
300 Go |
|
Port exposé |
8910 |
|
Template |
Dernier template PyTorch |
|
Variable d'environnement |
|
Le port exposé 8910 est important, car c'est celui que vous utiliserez pour accéder à l'interface Web de llama.cpp depuis votre navigateur.
Une fois le pod déployé, attendez quelques secondes que le tableau de bord RunPod affiche le lien JupyterLab.
Ouvrez JupyterLab, puis lancez un terminal. Pour confirmer que le GPU est disponible, exécutez :
nvidia-smi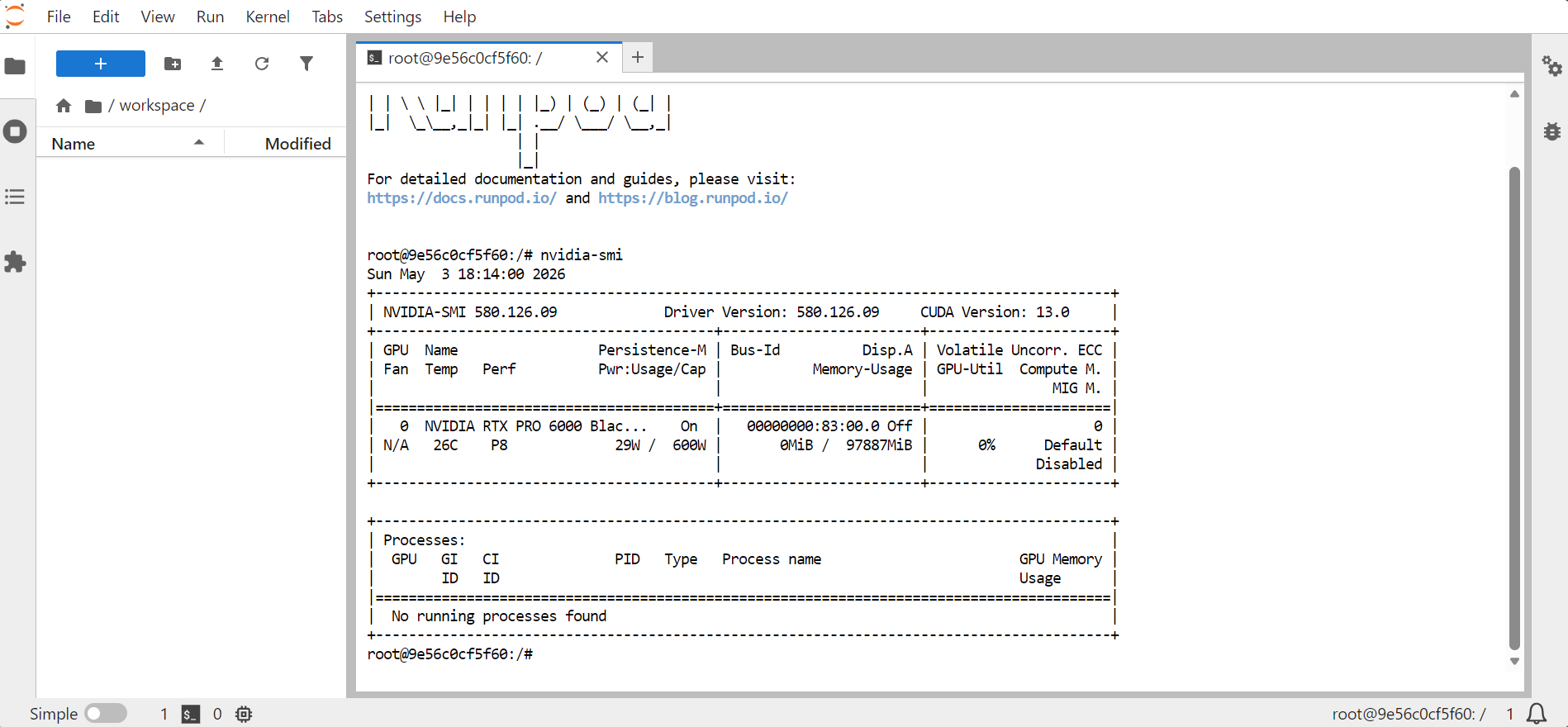
Vous devriez voir s'afficher des informations sur le GPU, la mémoire, la version de CUDA et la version du pilote.
Ensuite, installez les dépendances système nécessaires pour construire et exécuter llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvCes paquets incluent des outils de build, CMake, Git, Python et d'autres utilitaires nécessaires pour compiler llama.cpp à partir des sources.
DeepSeek V4 Flash est encore très récent, donc la prise en charge locale n'est pas aussi simple que pour les modèles plus anciens. Au moment d'écrire ces lignes, il n'existe pas de version GGUF officielle largement adoptée par de grands acteurs de la communauté tels qu'Unsloth pour exécuter le modèle complet via la branche amont standard de llama.cpp.
Le modèle officiel DeepSeek V4 Flash est disponible sur Hugging Face, mais la voie GGUF locale dépend encore de conversions communautaires et d'une prise en charge expérimentale au runtime. Le GGUF utilisé dans ce guide indique explicitement que la version amont standard de llama.cpp ne peut pas le charger et nécessite une build en cours de développement avec la prise en charge de l'architecture DeepSeek V4 Flash, du FP8 natif et de MXFP4.
Pour cette raison, cette configuration utilise la branche modifiée de llama.cpp d'un contributeur open source plutôt que la version amont standard. C'est actuellement la voie la plus pratique pour tester le GGUF complet de DeepSeek V4 Flash en local.
Le projet llama.cpp amont a également une demande ouverte pour la prise en charge de DeepSeek V4, ce qui montre que le support officiel est encore en cours de travail et pas totalement fusionné dans le projet principal.
Placez-vous dans le répertoire de travail :
cd /workspaceClonez le dépôt modifié :
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Configurez maintenant la build avec CMake :
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseCela active la prise en charge CUDA, afin que le modèle profite de l'accélération GPU.
Compilez les binaires requis :
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitUne fois la compilation terminée, copiez les binaires dans le dossier principal du projet :
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Enfin, vérifiez que le binaire serveur fonctionne :
llama.cpp-deepseek-v4/llama-server --helpSi le menu d'aide apparaît, la build a réussi.
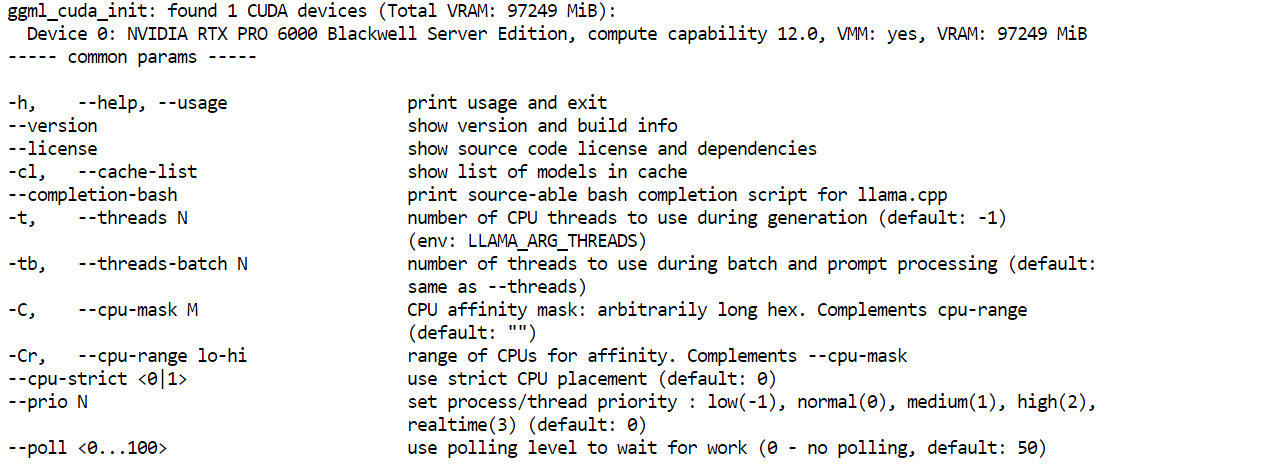
Installez maintenant les outils de téléchargement Hugging Face. C'est ici que le HF_TOKEN que vous avez ajouté plus tôt devient important. Comme il s'agit d'un fichier de modèle volumineux, se connecter avec votre jeton Hugging Face améliore la fiabilité du téléchargement et vous donne accès à des méthodes plus rapides.
Installez les paquets requis :
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferActivez des téléchargements Hugging Face plus rapides :
export HF_HUB_ENABLE_HF_TRANSFER=1Créez un dossier pour le modèle :
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Téléchargez le fichier modèle GGUF :
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Avec hf_transfer activé et votre HF_TOKEN déjà défini dans l'environnement RunPod, le téléchargement du modèle peut atteindre des vitesses très élevées.
Dans cette configuration, le débit a frôlé les 2 Go par seconde, ce qui rend le téléchargement d'un gros fichier GGUF bien plus praticable. Cette vitesse n'est possible que si votre jeton Hugging Face est correctement configuré et que le pod peut s'authentifier auprès de Hugging Face.

Une fois le téléchargement terminé, vérifiez le fichier :
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Vous devriez voir un fichier similaire à ceci :
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufMaintenant que le modèle est téléchargé et que la build modifiée de llama.cpp est prête, l'étape suivante consiste à démarrer le serveur d'inférence local pour accéder à DeepSeek V4 Flash via l'interface Web et le point de terminaison API.
Placez-vous dans le répertoire llama.cpp :
cd /workspace/llama.cpp-deepseek-v4Lancez le serveur du modèle :
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfCette commande charge le modèle GGUF, expose le serveur sur 0.0.0.0:8910, applique le template de chat Jinja, utilise --fit on pour adapter le modèle à la mémoire GPU et système disponible, définit une fenêtre de contexte à 32K, active un batching optimisé pour CUDA et Flash Attention pour une inférence plus rapide, et active les métriques ainsi que les logs de performance pour suivre l'exécution.
Le chargement du modèle dans la mémoire GPU et CPU peut prendre au moins une minute.

Lorsque le serveur est prêt, vous devriez voir un message indiquant qu'il « écoute sur http://0.0.0.0:8910 ».

Cela signifie que le serveur du modèle est en cours d'exécution et prêt à recevoir des requêtes.
Retournez sur votre tableau de bord RunPod. Repérez le port exposé 8910, puis cliquez sur le lien du port.
Cela ouvrira l'interface Web de llama.cpp dans votre navigateur. L'interface ressemble à un chat de type ChatGPT.
Une fois la page ouverte, le modèle devrait déjà être chargé. Vous pouvez commencer à discuter avec lui directement depuis le navigateur.
Après le démarrage du serveur, vous pouvez tester le modèle avec différents types de prompts.
L'objectif est d'évaluer ses performances sur :
Utilisez le prompt suivant :
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
Dans ce test, le modèle a généré la page HTML en environ 2 minutes, ce qui est raisonnable.
Pour prévisualiser la page générée, cherchez l'icône en forme d'œil près de la sortie de code dans l'interface Web. Cliquez pour ouvrir la page rendue.
La page fonctionnait, mais la qualité visuelle n'était pas remarquable. La mise en page était fonctionnelle, mais le design restait très basique. Des modèles plus petits produisent parfois des interfaces plus soignées : le résultat s'est donc révélé décevant pour la génération d'UI.
Testez ensuite la capacité de rédaction du modèle.
Utilisez ce prompt :
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Le modèle a produit un rapport clair et bien structuré. Il a expliqué les idées principales simplement et inclus des exemples utiles d'utilisation d'outils, de planification, de mémoire, de réflexion et d'automatisation métier.
Cependant, la sortie paraissait un peu générique et promotionnelle par endroits, notamment vers la conclusion. Elle contenait aussi plusieurs problèmes de mise en forme et d'orthographe, comme des mises en gras incohérentes et des coquilles du type « Mainate Context ».
Testez maintenant la capacité de raisonnement du modèle avec un problème d'algèbre simple.
Utilisez ce prompt :
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Le modèle a résolu correctement le problème.
Il a défini correctement les variables, établi les bonnes équations, effectué les substitutions adéquates et vérifié la réponse finale.
La réponse exacte était :
En décimales, cela donne environ :
Les valeurs totalisent bien 156 $.
Enfin, testez si le modèle peut générer un projet de code complet adapté aux débutants.
Utilisez ce prompt :
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
La réponse paraissait complète au premier abord, et la structure du projet était pertinente. Toutefois, le code généré comportait plusieurs problèmes sérieux.
La sortie incluait :
Pour un projet destiné aux débutants, c'est problématique. Un débutant doit pouvoir copier, exécuter et comprendre le code avec un minimum de corrections. Ici, le projet généré nécessiterait un débogage conséquent avant d'être utilisable.
Après avoir testé DeepSeek V4 Flash sur la génération d'UI, la rédaction, le raisonnement et la génération de projet, les résultats sont mitigés.
Il s'en sort bien en raisonnement structuré et en rédaction explicative de base. Il génère aussi rapidement des sorties via l'interface Web de llama.cpp.
En revanche, il peine à produire un design frontend soigné et un code de projet complet fiable. Le projet Python semblait complet, mais comportait trop d'erreurs de syntaxe et de nommage pour être utile sans interventions manuelles.
|
Tâche |
Performance |
|
Génération d'UI |
Moyenne |
|
Rédaction et explication |
Bonne |
|
Raisonnement mathématique |
Solide |
|
Génération d'un projet complet |
Faible |
|
Vitesse |
Bonne |
|
Fiabilité globale |
Mitigée |
Faire tourner DeepSeek V4 Flash en local a, honnêtement, été un cauchemar.
J'ai d'abord tenté de l'exécuter sur une configuration 4× H100 avec sglang et une configuration Docker Compose, sans succès. J'ai ensuite essayé avec vLLM sur 4× H100 RunPod via Python, mais cela a également échoué. L'erreur renvoyait sans cesse à la prise en charge de DeepSeek V4 dans la dernière version de transformers, alors que j'utilisais déjà la plus récente. Il est donc clair que le support au niveau des frameworks n'est pas encore au point.
Même la page officielle du modèle sur Hugging Face ne fournit pas d'exemple d'inférence simple et standard. Elle oriente plutôt vers une approche personnalisée avec torchrun, bien plus lourde et plus fastidieuse à mettre en place.
J'ai aussi testé des fichiers GGUF fournis par la communauté, mais j'ai rencontré des problèmes de compatibilité avec llama.cpp. En général, je préfère les fichiers Unsloth GGUF car ils sont rapides, fiables et faciles à exécuter, mais pour DeepSeek V4 Flash, il n'existait pas de solution plug-and-play simple.
Après tous ces essais, la méthode présentée dans ce guide s'est avérée la plus simple et la plus fiable pour exécuter le modèle complet en local. Elle repose toujours sur un GGUF communautaire et une build modifiée de llama.cpp, mais, comparée aux autres options, cette configuration a réellement fonctionné.
Cela dit, je ne pense pas que DeepSeek V4 Flash vaille la peine d'être exécuté en local pour l'instant. La mise en place est trop pénible, le support des frameworks reste immature, et la qualité des sorties ne justifie pas l'effort.
Si vous souhaitez une expérience plus fluide avec un modèle local, je vous recommande d'essayer des modèles comme MiniMax M2.7 ou des modèles fortement quantifiés comme Qwen3.6-27B. Ils sont plus simples à exécuter, mieux pris en charge par les grands frameworks, plus rapides en pratique et produisent souvent des résultats de meilleure qualité avec beaucoup moins de frustration à l'installation.
Meilleures formations LLM
Cursus
Cours
Cours
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Stephen Gruppetta
Tutoriel
Aditya Sharma
Tutoriel
Matt Crabtree
Tutoriel
Satyabrata Pal
