Track
Tworzenie dużych modeli językowych
16 godz.
DeepSeek V4 Flash to mniejszy, szybszy i bardziej opłacalny model z serii podglądowej DeepSeek V4. Jest przeznaczony do praktycznych zadań inferencyjnych, ma mniej aktywnych parametrów niż DeepSeek V4 Pro i obsługuje zadania z długim kontekstem. Wersja GGUF użyta w tym przewodniku przechowuje gęste wagi w FP8, a wagi MoE w FP4, co czyni ją odpowiednią do lokalnej inferencji poprzez niestandardową kompilację llama.cpp.
W tym przewodniku uruchomimy DeepSeek V4 Flash lokalnie na RunPod, używając GPU RTX PRO 6000 i zmodyfikowanej kompilacji llama.cpp. Dowiedzą się Państwo, jak skonfigurować pod GPU, zainstalować wymagane zależności, skompilować llama.cpp ze wsparciem DeepSeek V4, pobrać model FP4/FP8 GGUF z Hugging Face i udostępnić go przez przeglądarkowy interfejs Web UI llama.cpp.
Zanim Państwo zaczną, proszę upewnić się, że mają:
Konto RunPod
Co najmniej 5 USD środków w RunPod
Podstawową znajomość poleceń terminala Linuksa
Konto Hugging Face
Token dostępu Hugging Face zapisany jako HF_TOKEN
Token Hugging Face posłuży do szybszego i bardziej niezawodnego pobierania modelu.
Jeśli chcą Państwo zobaczyć, jak model wypada na tle konkurencyjnych, własnościowych modeli OpenAI, polecam nasz przewodnik porównawczy DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Najpierw proszę utworzyć nowy pod GPU na RunPod.
W tym przewodniku używamy GPU RTX PRO 6000, ponieważ oferuje 96 GB pamięci VRAM przy znacznie niższym koszcie niż H100. To praktyczna opcja do uruchomienia pełnego modelu DeepSeek V4 Flash na pojedynczym GPU, bez płacenia „premium” za H100.
W panelu RunPod proszę wybrać pod z RTX PRO 6000 i użyć najnowszego szablonu PyTorch jako obrazu bazowego.
Przed wdrożeniem poda proszę edytować ustawienia szablonu i skonfigurować przestrzeń dyskową, wystawiony port oraz zmienne środowiskowe.
Proszę użyć następującej zalecanej konfiguracji:
|
Ustawienie |
Zalecana wartość |
|
GPU |
RTX PRO 6000 |
|
Dysk kontenera |
50 GB |
|
Dysk woluminu |
300 GB |
|
Wystawiony port |
8910 |
|
Szablon |
Najnowszy szablon PyTorch |
|
Zmienna środowiskowa |
|
Wystawiony port 8910 jest istotny, ponieważ to przez niego uzyskają Państwo dostęp do Web UI llama.cpp z poziomu przeglądarki.
Po wdrożeniu poda proszę odczekać kilka sekund, aż w panelu RunPod pojawi się link do JupyterLab.
Proszę otworzyć JupyterLab, a następnie uruchomić terminal. Aby potwierdzić dostępność GPU, proszę wykonać:
nvidia-smi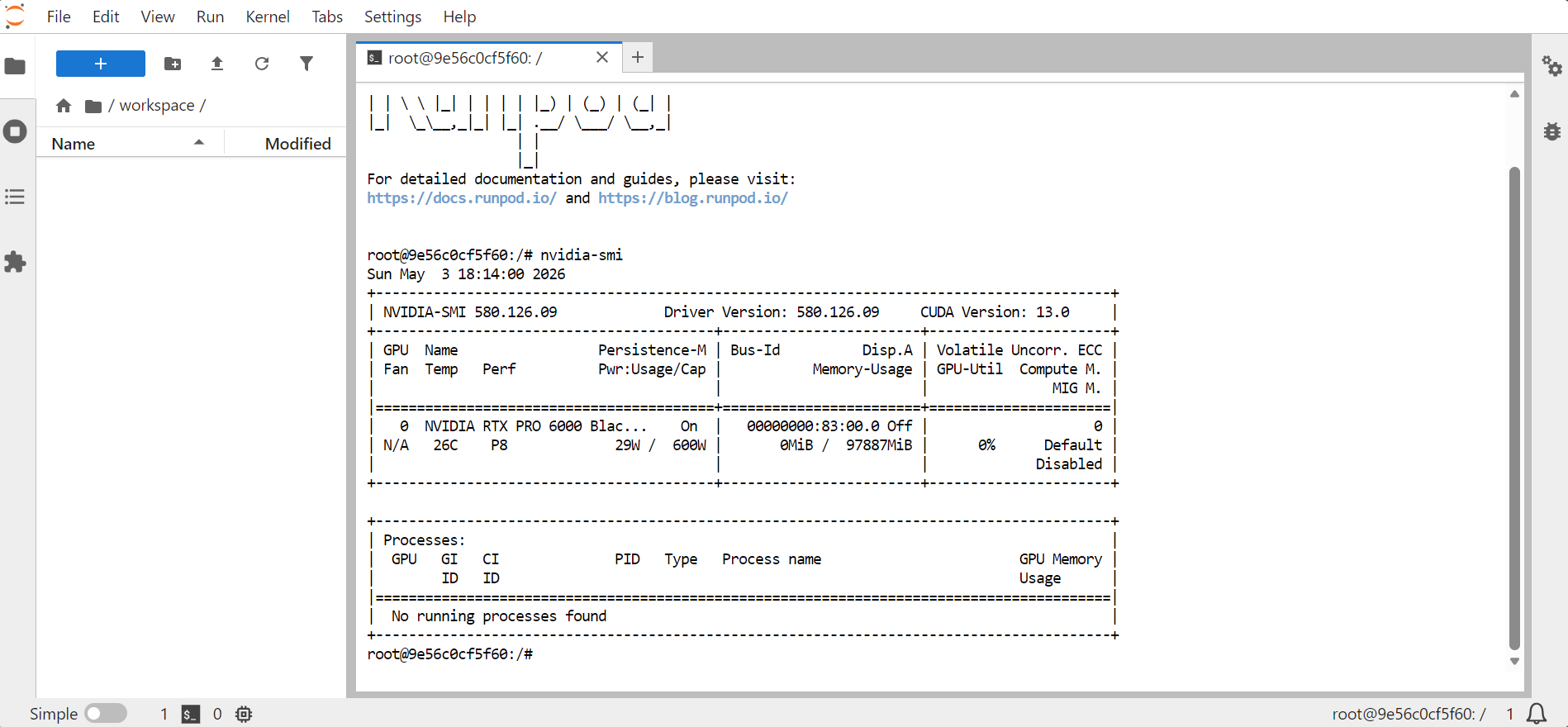
Powinny wyświetlić się informacje o GPU, pamięci, wersji CUDA i wersji sterownika.
Następnie proszę zainstalować zależności systemowe wymagane do zbudowania i uruchomienia llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvPakiety te obejmują narzędzia budowania, CMake, Git, Pythona i inne narzędzia potrzebne do kompilacji llama.cpp ze źródeł.
DeepSeek V4 Flash jest wciąż bardzo nowy, więc wsparcie lokalne nie jest tak proste jak w przypadku starszych modeli. W momencie pisania nie ma powszechnie przyjętego, oficjalnego wydania GGUF od głównych dostawców społecznościowych, takich jak Unsloth, do uruchamiania pełnego modelu przez standardowe, główne repozytorium llama.cpp.
Oficjalny model DeepSeek V4 Flash jest dostępny na Hugging Face, ale lokalna ścieżka GGUF wciąż zależy od konwersji społeczności i eksperymentalnego wsparcia czasu wykonania. GGUF użyty w tym przewodniku wyraźnie wskazuje, że standardowy, główny llama.cpp nie potrafi go załadować i wymaga będącej w toku kompilacji z obsługą architektury DeepSeek V4 Flash oraz natywną obsługą FP8 i MXFP4.
Z tego powodu w tej konfiguracji używamy zmodyfikowanej gałęzi llama.cpp od współtwórcy open source, a nie standardowej wersji głównej. To obecnie praktyczna droga do testowania pełnego GGUF DeepSeek V4 Flash lokalnie.
Projekt główny llama.cpp ma również otwartą prośbę o dodanie modelu DeepSeek V4, co pokazuje, że oficjalne wsparcie jest nadal w toku i nie zostało w pełni scalone z głównym projektem.
Proszę przejść do katalogu workspace:
cd /workspaceSklonować zmodyfikowane repozytorium:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Teraz proszę skonfigurować kompilację przy użyciu CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseTo włącza obsługę CUDA, dzięki czemu model może korzystać z akceleracji GPU.
Zbudować wymagane binaria:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitPo zakończeniu kompilacji proszę skopiować binaria do głównego folderu projektu:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Na koniec proszę sprawdzić, czy działa plik wykonywalny serwera:
llama.cpp-deepseek-v4/llama-server --helpJeśli pojawi się menu pomocy, kompilacja zakończyła się powodzeniem.
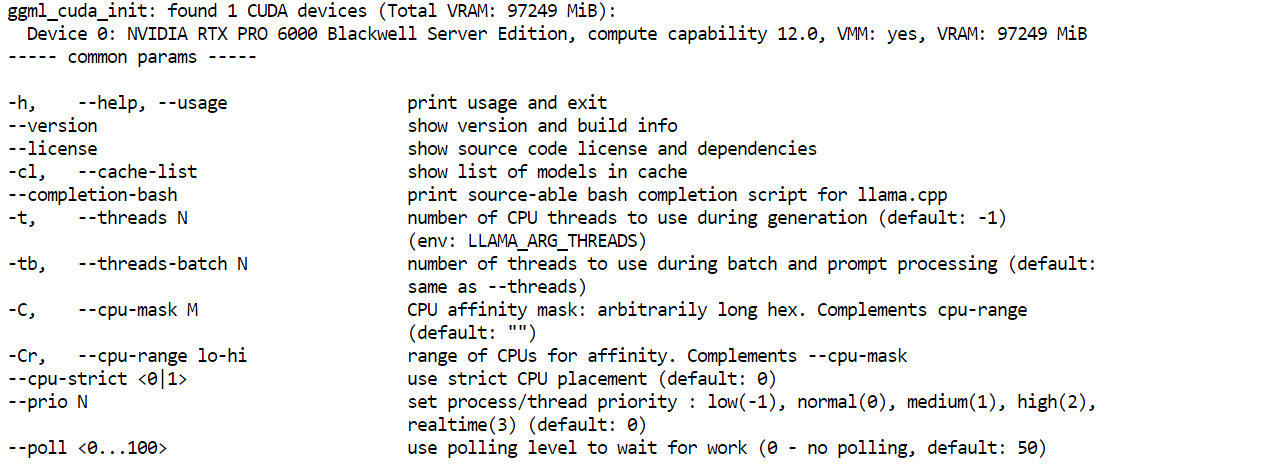
Następnie proszę zainstalować narzędzia do pobierania z Hugging Face. W tym miejscu staje się ważny HF_TOKEN, który dodano wcześniej. Ponieważ to duży plik modelu, logowanie za pomocą tokenu Hugging Face poprawia niezawodność pobierania i daje dostęp do szybszych metod pobierania.
Proszę zainstalować wymagane pakiety:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferWłączyć szybsze pobieranie z Hugging Face:
export HF_HUB_ENABLE_HF_TRANSFER=1Utworzyć folder na model:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Pobrać plik modelu GGUF:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Z włączonym hf_transfer i poprawnie ustawionym HF_TOKEN w środowisku RunPod, pobieranie modelu może osiągać bardzo wysokie prędkości.
W tej konfiguracji prędkość pobierania osiągnęła niemal 2 GB na sekundę, co znacznie ułatwia pobranie dużego pliku GGUF. Taka szybkość jest możliwa tylko wtedy, gdy token Hugging Face jest poprawnie skonfigurowany, a pod może się uwierzytelnić w Hugging Face.

Po zakończeniu pobierania proszę zweryfikować plik:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Powinni Państwo zobaczyć plik podobny do tego:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufSkoro model jest pobrany, a zmodyfikowana kompilacja llama.cpp gotowa, kolejnym krokiem jest uruchomienie lokalnego serwera inferencji, aby uzyskać dostęp do DeepSeek V4 Flash przez przeglądarkowy Web UI i punkt końcowy API.
Proszę przejść do katalogu llama.cpp:
cd /workspace/llama.cpp-deepseek-v4Uruchomić serwer modelu:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfTo polecenie ładuje model GGUF, wystawia serwer na 0.0.0.0:8910, stosuje szablon czatu Jinja, używa --fit on, aby dopasować model do dostępnej pamięci GPU i systemowej, ustawia okno kontekstu 32K, włącza przyjazne dla CUDA batchowanie oraz Flash Attention dla szybszej inferencji oraz włącza metryki i logowanie wydajności, aby mogli Państwo monitorować przebieg.
Załadowanie modelu do pamięci GPU i CPU może potrwać co najmniej minutę.

Gdy serwer będzie gotowy, powinna pojawić się informacja, że „nasłuchuje na http://0.0.0.0:8910”.

Oznacza to, że serwer modelu działa i jest gotowy do przyjmowania żądań.
Proszę wrócić do panelu RunPod. Proszę znaleźć wystawiony port 8910 i kliknąć link portu.
Otworzy się przeglądarkowy Web UI llama.cpp. Interfejs przypomina podstawowy czat w stylu ChatGPT.
Po otwarciu strony model powinien być już załadowany. Można zacząć rozmowę bezpośrednio z poziomu przeglądarki.
Po uruchomieniu serwera można przetestować model, używając różnych typów promptów.
Celem jest sprawdzenie, jak radzi sobie w obszarach:
Proszę użyć następującego promptu:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
W tym teście model wygenerował stronę HTML w około 2 minuty, co jest rozsądnym czasem.
Aby podejrzeć wygenerowaną stronę, proszę poszukać ikony oka w pobliżu wyjścia z kodem w Web UI. Proszę ją kliknąć, aby otworzyć wyrenderowaną stronę.
Strona działała, ale jakość wizualna nie robiła wrażenia. Układ był funkcjonalny, jednak projekt wyglądał podstawowo. Mniejsze modele czasem tworzą bardziej dopracowane frontendy, więc rezultat w zakresie generowania UI był rozczarowujący.
Następnie proszę przetestować zdolności pisarskie modelu.
Proszę użyć tego promptu:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Model wygenerował klarowny i dobrze ustrukturyzowany raport. Prosto wyjaśnił główne idee i zawarł użyteczne przykłady użycia narzędzi, planowania, pamięci, autorefleksji i automatyzacji biznesu.
Jednak miejscami brzmiał nieco ogólnikowo i promocyjnie, zwłaszcza pod koniec. Zawierał też kilka problemów z formatowaniem i pisownią, jak niespójne pogrubienia i błędy słowne typu „Mainate Context”.
Teraz proszę przetestować zdolności rozumowania modelu na prostym zadaniu algebraicznym.
Proszę użyć tego promptu:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Model rozwiązał zadanie poprawnie.
Poprawnie zdefiniował zmienne, utworzył właściwe równania, poprawnie podstawiał wartości i sprawdził wynik końcowy.
Dokładne odpowiedzi to:
W zapisie dziesiętnym to w przybliżeniu:
Wartości poprawnie sumują się do łącznej kwoty 156 USD.
Na koniec proszę sprawdzić, czy model potrafi wygenerować kompletny, przyjazny dla początkujących projekt programistyczny.
Proszę użyć tego promptu:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
Odpowiedź początkowo wyglądała na kompletną, a struktura projektu miała sens. Jednak wygenerowany kod zawierał kilka poważnych problemów.
Wynik obejmował:
Dla projektu przyjaznego dla początkujących to poważny problem. Początkujący powinien móc skopiować, uruchomić i zrozumieć kod przy minimalnych poprawkach. W tym przypadku wygenerowany projekt wymagałby znacznego debugowania, zanim nadawałby się do użycia.
Po przetestowaniu DeepSeek V4 Flash w zakresie generowania UI, pisania, rozumowania i generowania projektów, model wykazał mieszane wyniki.
Dobrze poradził sobie ze strukturalnym rozumowaniem i podstawowym pisaniem wyjaśniającym. Potrafił też szybko generować wyniki przez Web UI llama.cpp.
Jednak miał trudności z dopracowanym projektem frontendowym i niezawodnym generowaniem pełnego kodu projektu. Wyjście projektu w Pythonie wyglądało na kompletne, ale zawierało zbyt wiele błędów składni i nazw, by było użyteczne bez ręcznego debugowania.
|
Zadanie |
Wydajność |
|
Generowanie UI |
Przeciętna |
|
Pisanie i wyjaśnianie |
Dobra |
|
Rozumowanie matematyczne |
Silne |
|
Generowanie pełnego projektu |
Słaba |
|
Szybkość |
Dobra |
|
Ogólna niezawodność |
Mieszana |
Uruchomienie DeepSeek V4 Flash lokalnie było, szczerze mówiąc, koszmarem.
Najpierw próbowałem uruchomić go na konfiguracji 4x H100, używając sglang i Docker Compose, ale to również nie zadziałało. Następnie próbowałem uruchomić go z vLLM na 4x H100 w RunPod przy użyciu Pythona, ale i to się nie powiodło. Błąd wciąż wskazywał na obsługę DeepSeek V4 w najnowszej wersji transformers, mimo że używałem najnowszej wersji. Stało się jasne, że odpowiednie wsparcie frameworków nie jest jeszcze w pełni gotowe.
Nawet oficjalna strona modelu na Hugging Face nie podaje prostego, standardowego przykładu inferencji. Zamiast tego kieruje użytkowników w stronę niestandardowego podejścia z torchrun, które jest znacznie cięższe i wymaga więcej pracy przy konfiguracji.
Testowałem też pliki GGUF stworzone przez społeczność, ale napotkałem problemy ze zgodnością llama.cpp. Zwykle preferuję pliki GGUF od Unsloth, ponieważ są szybkie, niezawodne i łatwe w uruchomieniu, ale w przypadku DeepSeek V4 Flash nie było prostego, „podłącz i uruchom”.
Po całej tej serii testów metoda opisana w tym przewodniku okazała się najłatwiejszym i najbardziej niezawodnym sposobem na uruchomienie pełnego modelu lokalnie. Nadal opiera się na pliku GGUF ze społeczności i zmodyfikowanej kompilacji llama.cpp, ale w porównaniu z innymi opcjami ta konfiguracja faktycznie zadziałała.
Niemniej uważam, że na ten moment nie warto uruchamiać DeepSeek V4 Flash lokalnie. Konfiguracja jest zbyt uciążliwa, wsparcie frameworków wciąż niedojrzałe, a jakość wyników nie uzasadnia wysiłku.
Jeśli zależy Państwu na płynniejszym doświadczeniu z lokalnym modelem, polecam wypróbować modele takie jak MiniMax M2.7 lub silnie kwantyzowane modele, takie jak Qwen3.6-27B. Są łatwiejsze w uruchomieniu, lepiej wspierane przez główne frameworki, szybsze w praktyce i często dają wyższej jakości wyniki przy znacznie mniejszej frustracji związanej z konfiguracją.
Najlepsze kursy o LLM
Track
course
course