
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
DeepSeek V4 Flash ist das kleinere, schnellere und kosteneffizientere Modell der DeepSeek V4 Preview-Serie. Es ist für praktische Inferenz-Workloads konzipiert, hat weniger aktive Parameter als DeepSeek V4 Pro und unterstützt Aufgaben mit langem Kontext. Die in diesem Guide verwendete GGUF-Version speichert dichte Gewichte in FP8 und MoE-Expertengewichte in FP4 – ideal für lokale Inferenz über einen angepassten llama.cpp-Build.
In diesem Guide führen wir DeepSeek V4 Flash lokal auf RunPod mit einer RTX PRO 6000 GPU und einem modifizierten llama.cpp-Build aus. Du lernst, wie du das GPU-Pod einrichtest, benötigte Abhängigkeiten installierst, llama.cpp mit DeepSeek V4 Support kompilierst, das FP4/FP8-GGUF-Modell von Hugging Face lädst und es über die browserbasierte llama.cpp Web UI bereitstellst.
Bevor du startest, stelle sicher, dass du Folgendes hast:
Ein RunPod-Konto
Mindestens 5 $ RunPod-Guthaben
Grundkenntnisse in Linux-Terminalbefehlen
Ein Hugging Face Konto
Einen Hugging Face Access Token als HF_TOKEN gespeichert
Den Hugging Face Token nutzt du, um das Modell schneller und stabiler herunterzuladen.
Wenn du sehen willst, wie sich das Modell gegenüber proprietären Konkurrenzmodellen von OpenAI schlägt, lies unseren Vergleich DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Erstelle zuerst ein neues GPU-Pod auf RunPod.
Für diesen Guide verwenden wir die RTX PRO 6000 GPU, weil sie 96 GB VRAM zu deutlich geringeren Kosten als eine H100 bietet. Damit kannst du das komplette DeepSeek V4 Flash Modell auf einer einzelnen GPU betreiben – ohne H100-Preispremium.
Wähle im RunPod-Dashboard ein RTX PRO 6000 GPU-Pod und setze als Basis-Image das neueste PyTorch-Template.
Bearbeite vor dem Deployment die Template-Einstellungen und konfiguriere Storage, freigegebenen Port und Umgebungsvariablen.
Nutze die folgende empfohlene Konfiguration:
|
Einstellung |
Empfohlener Wert |
|
GPU |
RTX PRO 6000 |
|
Container Disk |
50 GB |
|
Volume Disk |
300 GB |
|
Exposed Port |
8910 |
|
Template |
Latest PyTorch template |
|
Environment Variable |
|
Der freigegebene Port 8910 ist wichtig, weil du ihn nutzt, um die llama.cpp Web UI im Browser zu öffnen.
Sobald das Pod deployed ist, warte ein paar Sekunden, bis im RunPod-Dashboard der Link zu JupyterLab erscheint.
Öffne JupyterLab und starte ein Terminal. Um zu prüfen, ob die GPU verfügbar ist, führe aus:
nvidia-smi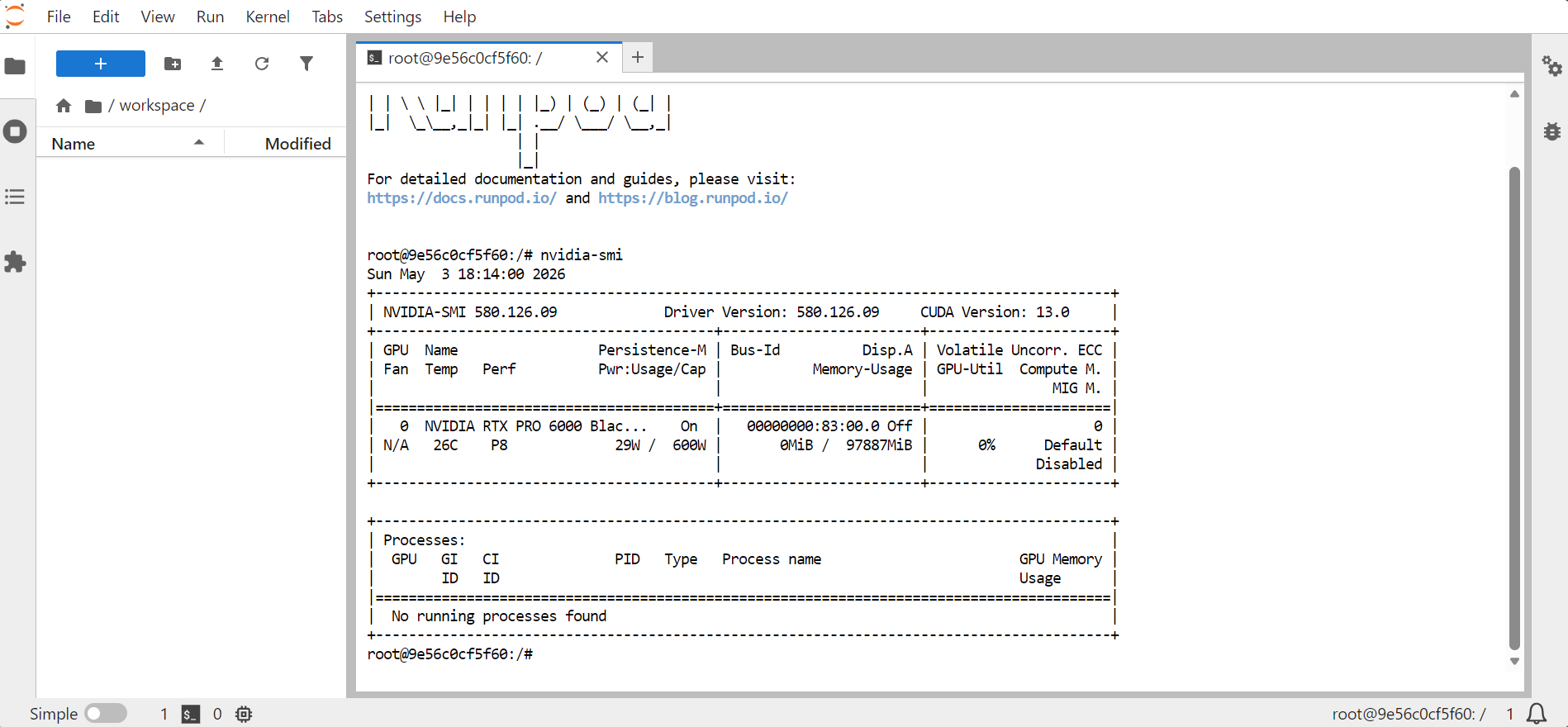
Du solltest Informationen zur GPU, zum Speicher, zur CUDA-Version und zur Treiberversion sehen.
Installiere anschließend die Systemabhängigkeiten, die zum Bauen und Ausführen von llama.cpp benötigt werden.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvDiese Pakete umfassen Build-Tools, CMake, Git, Python und weitere Utilities, die für das Kompilieren von llama.cpp aus dem Quellcode erforderlich sind.
DeepSeek V4 Flash ist noch sehr neu, daher ist der lokale Support nicht so unkompliziert wie bei älteren Modellen. Zum Zeitpunkt des Schreibens gibt es noch keine breit akzeptierte, offizielle GGUF-Version großer Community-Anbieter wie Unsloth für das Ausführen des vollständigen Modells mit dem Standard-llama.cpp-Upstream.
Das offizielle DeepSeek V4 Flash Modell ist auf Hugging Face verfügbar, aber der lokale GGUF-Weg hängt weiterhin von Community-Konvertierungen und experimentellem Runtime-Support ab. Das in diesem Guide genutzte GGUF weist ausdrücklich darauf hin, dass der Standard-llama.cpp-Upstream es nicht laden kann und einen Work-in-Progress-Build mit DeepSeek V4 Flash Architektursupport sowie nativem FP8- und MXFP4-Support erfordert.
Aus diesem Grund verwendet dieses Setup den modifizierten llama.cpp-Branch eines Open-Source-Contributors statt der Standard-Upstream-Version. Aktuell ist das der praktikable Weg, um das vollständige DeepSeek V4 Flash GGUF lokal zu testen.
Im Upstream-Projekt llama.cpp existiert auch ein offener Model-Request für DeepSeek V4 Support, was zeigt, dass offizieller Support noch in Arbeit ist und nicht vollständig in das Hauptprojekt gemerged wurde.
Wechsle in das Arbeitsverzeichnis:
cd /workspaceKlonen des modifizierten Repos:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Konfiguriere nun den Build mit CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseDamit aktivierst du CUDA-Support, sodass das Modell GPU-Beschleunigung nutzen kann.
Baue die benötigten Binaries:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitKopiere nach Abschluss die Binaries in den Hauptordner des Projekts:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Prüfe abschließend, ob das Server-Binary funktioniert:
llama.cpp-deepseek-v4/llama-server --helpWenn das Hilfemenü erscheint, war der Build erfolgreich.
Installiere als Nächstes die Hugging Face Download-Tools. Hier wird dein HF_TOKEN wichtig. Da es sich um eine sehr große Modelldatei handelt, verbessert das Einloggen mit deinem Hugging Face Token die Zuverlässigkeit und ermöglicht schnellere Download-Methoden.
Installiere die benötigten Pakete:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferAktiviere schnellere Hugging Face Downloads:
export HF_HUB_ENABLE_HF_TRANSFER=1Erstelle einen Ordner für das Modell:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Lade die GGUF-Modelldatei herunter:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Mit aktiviertem hf_transfer und korrekt gesetztem HF_TOKEN in der RunPod-Umgebung erreichst du sehr hohe Download-Geschwindigkeiten.
In diesem Setup lag die Geschwindigkeit bei fast 2 GB pro Sekunde. So wird das Herunterladen einer großen GGUF-Datei deutlich praktikabler. Diese Geschwindigkeit ist nur möglich, wenn dein Hugging Face Token korrekt konfiguriert ist und das Pod sich bei Hugging Face authentifizieren kann.

Sobald der Download abgeschlossen ist, prüfe die Datei:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Du solltest eine Datei ähnlich dieser sehen:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufNachdem das Modell heruntergeladen und der modifizierte llama.cpp-Build fertig ist, startest du den lokalen Inferenz-Server, um DeepSeek V4 Flash über die browserbasierte Web UI und den API-Endpunkt zu nutzen.
Wechsle in das llama.cpp-Verzeichnis:
cd /workspace/llama.cpp-deepseek-v4Starte den Model-Server:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfDieser Befehl lädt das GGUF-Modell, stellt den Server auf 0.0.0.0:8910 bereit, wendet das Jinja-Chat-Template an, nutzt --fit on, um das Modell in den verfügbaren GPU- und Systemspeicher zu packen, setzt ein 32K-Kontextfenster, aktiviert CUDA-freundliches Batching und Flash Attention für schnellere Inferenz und schaltet Metriken sowie Performance-Logging ein, damit du den Lauf beobachten kannst.
Das Laden des Modells in GPU- und CPU-Speicher kann mindestens eine Minute dauern.

Wenn der Server bereit ist, siehst du die Meldung „listening on http://0.0.0.0:8910“.

Das bedeutet, der Model-Server läuft und ist bereit für Anfragen.
Wechsle zurück in dein RunPod-Dashboard. Suche den freigegebenen Port 8910 und klicke auf den Port-Link.
Daraufhin öffnet sich die llama.cpp Web UI in deinem Browser. Die Oberfläche erinnert an ein einfaches ChatGPT-Interface.
Sobald die Seite offen ist, sollte das Modell bereits geladen sein. Du kannst direkt im Browser damit chatten.
Nachdem der Server läuft, kannst du das Modell mit verschiedenen Prompt-Typen testen.
Ziel ist es zu prüfen, wie gut es abschneidet bei:
Nutze den folgenden Prompt:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
In diesem Test generierte das Modell die HTML-Seite in etwa 2 Minuten – ein vertretbarer Wert.
Um die erzeugte Seite zu prüfen, suche in der Web UI nach dem Auge-Symbol neben der Codeausgabe. Klicke darauf, um die gerenderte Webseite zu öffnen.
Die Seite funktionierte, aber die visuelle Qualität war nicht beeindruckend. Das Layout war brauchbar, das Design jedoch sehr schlicht. Kleinere Modelle liefern teils poliertere Frontend-Ergebnisse – für UI-Generierung war das hier eher enttäuschend.
Teste als Nächstes die Schreibfähigkeiten des Modells.
Nutze diesen Prompt:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Das Modell lieferte einen klaren, gut strukturierten Report. Es erklärte die Kernideen verständlich und nannte sinnvolle Beispiele zu Toolnutzung, Planung, Gedächtnis, Reflexion und Business-Automatisierung.
Allerdings wirkte der Text stellenweise etwas generisch und werblich, besonders zum Schluss. Außerdem gab es einige Formatierungs- und Schreibfehler, etwa uneinheitliche Fettschrift und Formulierungen wie „Mainate Context“.
Teste jetzt die Argumentationsfähigkeit mit einem einfachen Algebra-Problem.
Nutze diesen Prompt:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Das Modell löste die Aufgabe korrekt.
Es definierte die Variablen sauber, stellte die richtigen Gleichungen auf, setzte korrekt ein und prüfte die Lösung.
Die exakte Antwort war:
Als Dezimalwerte entspricht das ungefähr:
Die Werte ergeben in Summe korrekt die $156.
Zum Schluss prüfen wir, ob das Modell ein vollständiges, anfängerfreundliches Coding-Projekt erstellen kann.
Nutze diesen Prompt:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
Die Antwort wirkte zunächst vollständig, und die Projektstruktur ergab Sinn. Dennoch enthielt der generierte Code mehrere gravierende Probleme.
Die Ausgabe enthielt:
Für ein anfängerfreundliches Projekt ist das kritisch. Einsteiger sollten den Code mit minimalen Anpassungen kopieren, ausführen und verstehen können. Hier wäre umfangreiches Debugging nötig, bevor das Projekt nutzbar wäre.
Nach Tests zu UI-Generierung, Schreiben, Reasoning und Projektgenerierung zeigt DeepSeek V4 Flash ein gemischtes Bild.
Bei strukturiertem Denken und grundlegenden Erklärtexten performte es gut. Über die llama.cpp Web UI lieferte es zudem zügig Ergebnisse.
Bei poliertem Frontend-Design und verlässlicher End-to-End-Codegenerierung tat sich das Modell jedoch schwer. Das Python-Projekt wirkte zwar vollständig, enthielt aber zu viele Syntax- und Namensfehler, um ohne manuelle Korrekturen nützlich zu sein.
|
Aufgabe |
Performance |
|
UI-Generierung |
Durchschnittlich |
|
Schreiben und Erklären |
Gut |
|
Mathematisches Denken |
Stark |
|
Komplette Projektgenerierung |
Schwach |
|
Geschwindigkeit |
Gut |
|
Gesamtzuverlässigkeit |
Gemischt |
DeepSeek V4 Flash lokal auszuführen war ehrlich gesagt eine ziemliche Tortur.
Ich habe es zuerst auf einem 4x H100-Setup mit einer sglang-Docker Compose-Konfiguration versucht – ohne Erfolg. Dann habe ich es mit vLLM auf 4x H100 RunPod via Python probiert – ebenfalls ohne Erfolg. Die Fehlermeldung verwies immer wieder auf DeepSeek V4 Support in der neuesten Version von transformers, obwohl ich bereits die aktuelle Version nutzte. Das machte deutlich: Der Framework-Support ist noch nicht ausgereift.
Selbst die offizielle Hugging Face Modellseite liefert kein simples, standardisiertes Inferenz-Beispiel. Stattdessen verweist sie auf einen individuellen torchrun-Ansatz, der deutlich schwergewichtiger ist und mehr Setup erfordert.
Ich habe auch Community-GGUF-Dateien getestet, stieß aber auf llama.cpp-Kompatibilitätsprobleme. Üblicherweise nutze ich Unsloth GGUF-Dateien, weil sie schnell, verlässlich und leicht zu betreiben sind. Für DeepSeek V4 Flash gab es jedoch keinen einfachen Plug-and-Play-Weg.
Nach all den Tests war die in diesem Guide gezeigte Methode der einfachste und verlässlichste Weg, das komplette Modell lokal auszuführen. Sie hängt zwar von einer Community-GGUF-Datei und einem modifizierten llama.cpp-Build ab, funktionierte im Vergleich zu anderen Optionen aber tatsächlich.
Trotzdem halte ich es derzeit nicht für sinnvoll, DeepSeek V4 Flash lokal zu betreiben. Das Setup ist zu mühsam, der Framework-Support noch unreif, und die Ergebnisqualität rechtfertigt den Aufwand nicht.
Wenn du ein reibungsloseres lokales Modellerlebnis möchtest, empfehle ich Modelle wie MiniMax M2.7 oder stark quantisierte Modelle wie Qwen3.6-27B. Sie sind leichter zu betreiben, in großen Frameworks besser unterstützt, in der Praxis schneller und liefern oft mit deutlich weniger Setup-Frust qualitativ hochwertigere Ergebnisse.
Top LLM-Kurse
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Matt Crabtree
Tutorial
Adel Nehme
Tutorial
Moez Ali
Tutorial
Laiba Siddiqui
