Tracks
开发大型语言模型
16小时
DeepSeek V4 Flash 是 DeepSeek V4 预览系列中更小、更快、性价比更高的模型。它专为实际推理工作负载而设计,活跃参数量低于 DeepSeek V4 Pro,并支持长上下文任务。本指南使用的 GGUF 版本将稠密权重存储为 FP8,MoE 专家权重存储为 FP4,使其适合通过自定义构建的 llama.cpp 在本地进行推理。
在本指南中,我们将在 RunPod 上本地运行 DeepSeek V4 Flash,使用 RTX PRO 6000 GPU 和修改版的 llama.cpp 构建。您将学习如何设置 GPU pod、安装依赖、编译带有 DeepSeek V4 支持的 llama.cpp、从 Hugging Face 下载 FP4/FP8 GGUF 模型,并通过基于浏览器的 llama.cpp Web UI 对其进行服务。
在开始之前,请确保您已具备:
一个 RunPod 账号
至少 5 美元的 RunPod 余额
对 Linux 终端命令有基础了解
一个 Hugging Face 账号
已保存为 HF_TOKEN 的 Hugging Face 访问令牌
您将使用 Hugging Face 令牌更快速、更稳定地下载模型。
如果您想了解该模型与 OpenAI 等专有竞品的对比,建议阅读我们的DeepSeek V4 Flash 与 GPT-5.4 Mini 和 Nano 对比指南。
首先,在 RunPod 上创建一个新的 GPU pod。
在本指南中,我们使用RTX PRO 6000 GPU,因为它提供96GB 的显存,成本远低于 H100。这使其成为在单张 GPU 上运行完整 DeepSeek V4 Flash 模型的实用选择,无需支付 H100 的高昂价格。
在 RunPod 控制台中,选择RTX PRO 6000 GPU pod,并使用最新的PyTorch 模板作为基础镜像。
在部署 pod 之前,编辑模板设置并配置存储、暴露端口和环境变量。
使用以下推荐设置:
|
设置项 |
推荐值 |
|
GPU |
RTX PRO 6000 |
|
容器磁盘 |
50 GB |
|
卷磁盘 |
300 GB |
|
暴露端口 |
8910 |
|
模板 |
最新 PyTorch 模板 |
|
环境变量 |
|
暴露端口 8910 很重要,因为您将通过该端口从浏览器访问 llama.cpp Web UI。
pod 部署后,等待几秒钟,直到 RunPod 控制台显示 JupyterLab 链接。
打开 JupyterLab,然后启动一个终端。为确认 GPU 可用,运行:
nvidia-smi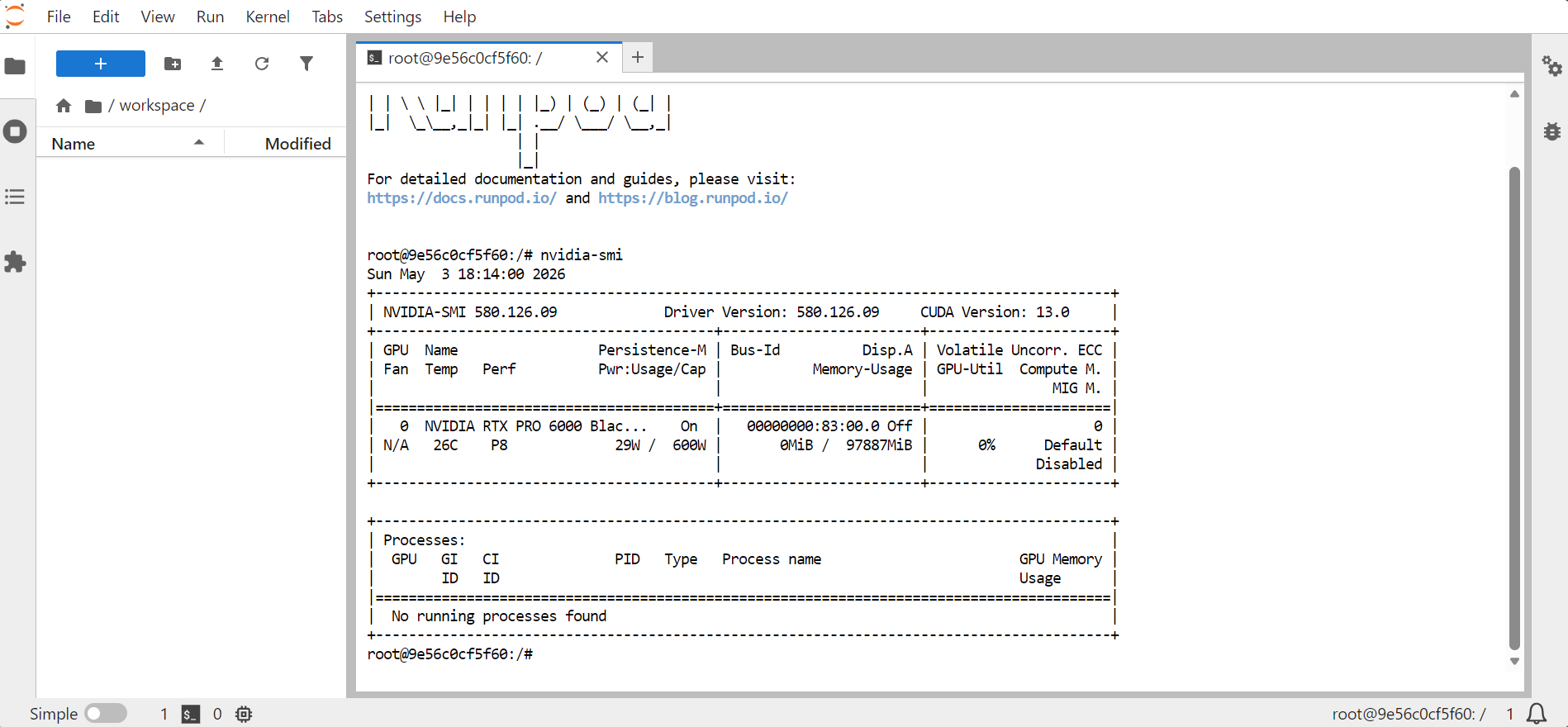
这将显示有关 GPU、显存、CUDA 版本和驱动版本的信息。
接下来,安装用于构建和运行 llama.cpp 的系统依赖。
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venv这些软件包包括构建工具、CMake、Git、Python,以及从源码编译 llama.cpp 所需的其他实用程序。
DeepSeek V4 Flash 仍然非常新,因此本地支持不如旧模型那样顺畅。撰写时,诸如 Unsloth 等主要社区提供者尚无广泛采用的官方 GGUF 发布,可通过标准上游 llama.cpp 运行完整模型。
官方 DeepSeek V4 Flash 模型可在 Hugging Face 上获得,但本地 GGUF 路径仍依赖社区转换和实验性运行时支持。本指南使用的 GGUF 明确指出,原生上游 llama.cpp 无法加载,需使用正在开发中的构建,以支持 DeepSeek V4 Flash 架构、原生 FP8 和 MXFP4。
因此,本次设置使用一位开源贡献者修改的 llama.cpp 分支,而非标准上游版本。这目前是本地测试完整 DeepSeek V4 Flash GGUF 的务实途径。
上游 llama.cpp 项目也有关于 DeepSeek V4 支持的开放模型请求,表明官方支持仍在推进中,尚未完全合并进主项目。
进入工作区目录:
cd /workspace克隆修改后的代码库:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4使用 CMake 配置构建:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release这将启用 CUDA 支持,使模型能够使用 GPU 加速。
构建所需的二进制文件:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-split构建完成后,将二进制文件复制到主项目文件夹:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/最后,检查服务端二进制是否可用:
llama.cpp-deepseek-v4/llama-server --help如果显示帮助菜单,则说明构建成功。
接下来,安装 Hugging Face 下载工具。这就是之前添加的 HF_TOKEN 发挥作用的地方。由于这是一个大型模型文件,使用 Hugging Face 令牌登录可以提升下载稳定性,并让您使用更快的下载方式。
安装所需软件包:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transfer启用更快的 Hugging Face 下载:
export HF_HUB_ENABLE_HF_TRANSFER=1为模型创建文件夹:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8下载 GGUF 模型文件:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8在启用 hf_transfer 且 RunPod 环境中已设置 HF_TOKEN 的情况下,模型下载速度可以非常快。
在本次设置中,下载速度接近每秒 2 GB,这让下载大型 GGUF 文件变得更可行。该速度仅在正确配置 Hugging Face 令牌并且 pod 可以通过 Hugging Face 认证时才可能实现。

下载完成后,验证文件:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8您应看到类似这样的文件:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.gguf现在模型已下载且修改版 llama.cpp 构建就绪,下一步是启动本地推理服务器,这样您就可以通过基于浏览器的 Web UI 和 API 端点访问 DeepSeek V4 Flash。
进入 llama.cpp 目录:
cd /workspace/llama.cpp-deepseek-v4启动模型服务:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perf该命令将加载 GGUF 模型,将服务器暴露在 0.0.0.0:8910,应用 Jinja 聊天模板,使用 --fit on 将模型适配到可用的 GPU 与系统内存,设置 32K 上下文窗口,启用对 CUDA 友好的批处理和 Flash Attention 以获得更快的推理,并开启指标与性能日志以便监控运行。
模型可能需要至少一分钟加载到 GPU 和 CPU 内存中。

当服务器就绪时,您应看到显示“listening on http://0.0.0.0:8910”的消息。

这意味着模型服务器已运行并可接收请求。
返回 RunPod 控制台。找到暴露端口 8910,然后点击该端口链接。
这会在浏览器中打开 llama.cpp Web UI。界面看起来类似基础的 ChatGPT 聊天界面。
页面打开后,模型应已加载。您可以直接在浏览器中开始对话。
服务器运行后,您可以用不同类型的提示测试模型。
目标是检查其在以下方面的表现:
使用以下提示:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
在该测试中,模型大约用 2 分钟生成了 HTML 页面,这一用时尚可接受。
要预览生成的页面,请在 Web UI 的代码输出附近寻找“眼睛”图标。点击即可打开渲染后的网页。
页面可用,但视觉质量不够出色。布局可用,但设计较为基础。较小的模型有时能生成更精致的前端输出,因此对于 UI 生成而言,该结果略显平庸。
接下来测试模型的写作能力。
使用以下提示:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
模型生成了一篇清晰、结构良好的报告。它以简明方式阐述了核心概念,并包含工具使用、规划、记忆、反思与业务自动化等有用示例。
不过,输出在某些段落(尤其接近结尾)略显通用且带有推介色彩。此外,还存在多处格式与拼写问题,比如加粗不一致,以及诸如“Mainate Context.” 这类措辞错误。
现在用一个简单的代数题测试模型的推理能力。
使用以下提示:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
模型正确解出了该题。
它正确定义变量、建立方程、进行代入并核对最终答案。
精确答案为:
换算为小数,约为:
这些数值相加后可正确得到总额 $156。
最后,测试模型是否能生成一个完整、适合初学者的编程项目。
使用以下提示:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
该回复乍看完整、项目结构也合理。但生成的代码存在若干严重问题。
输出包括:
对于面向初学者的项目,这是一个重大问题。初学者应当能够在极少修改下复制、运行并理解代码。在此情形下,生成的项目需大量调试后方可使用。
在 UI 生成、写作、推理和项目生成上的测试结果喜忧参半。
在结构化推理和基础解释性写作方面表现良好,并且能通过 llama.cpp Web UI 快速生成输出。
但在精致的前端设计和可靠的完整项目代码生成方面表现欠佳。尽管 Python 项目看似完整,但包含过多语法与命名错误,不经手动调试难以实用。
|
任务 |
表现 |
|
UI 生成 |
一般 |
|
写作与解释 |
良好 |
|
数学推理 |
强 |
|
完整项目生成 |
较弱 |
|
速度 |
良好 |
|
整体可靠性 |
混合 |
坦白说,在本地运行 DeepSeek V4 Flash 非常折腾。
我最初尝试在 4× H100 的设置上使用 sglang 和Docker Compose 配置运行,但仍然失败。随后我又尝试在 RunPod 的 4× H100 上用 Python 搭配 vLLM 运行,同样失败。错误指向最新版本 transformers 对 DeepSeek V4 的支持问题,尽管我已使用最新版本。这表明框架的正式支持仍未完全到位。
甚至官方 Hugging Face 模型页也未提供简单、标准的推理示例,而是引导用户使用自定义的 torchrun 方案,这更臃肿、搭建工作量更大。
我也测试了社区提供的 GGUF 文件,但遇到了 llama.cpp 兼容性问题。通常我更偏好使用Unsloth 的 GGUF 文件,因为其速度快、可靠、易用,但针对 DeepSeek V4 Flash,尚无可即插即用的简便路径。
经过上述测试,本指南展示的方法是我发现的最简单、最可靠的本地运行完整模型的方式。它仍依赖社区的 GGUF 文件和修改版 llama.cpp 构建,但与其他方案相比,这套配置确实可行。
话虽如此,我认为目前不值得在本地运行 DeepSeek V4 Flash。搭建过程过于痛苦,框架支持仍不成熟,输出质量也不足以支撑这番投入。
如果您想要更顺畅的本地模型体验,我建议尝试如 MiniMax M2.7 或强量化模型(如Qwen3.6-27B)等。它们更易运行,在主流框架中的支持更好,实际速度更快,且通常能以更少的搭建挫折产出更高质量的结果。
热门 LLM 课程
Tracks
Courses
Courses