
Leerpad
Grote taalmodellen ontwikkelen
16 Hr
DeepSeek V4 Flash is het kleinere, snellere en kostenefficiëntere model in de DeepSeek V4-previewserie. Het is ontworpen voor praktische inference-workloads, met minder actieve parameters dan DeepSeek V4 Pro en ondersteuning voor long-contexttaken. De in deze gids gebruikte GGUF-versie slaat dichte gewichten op in FP8 en MoE-expertgewichten in FP4, waardoor het geschikt is voor lokale inference via een aangepaste llama.cpp-build.
In deze gids draaien we DeepSeek V4 Flash lokaal op RunPod met een RTX PRO 6000 GPU en een aangepaste llama.cpp-build. Je leert hoe je de GPU-pod opzet, de vereiste afhankelijkheden installeert, llama.cpp compileert met ondersteuning voor DeepSeek V4, het FP4/FP8 GGUF-model van Hugging Face downloadt en het via de browsergebaseerde llama.cpp Web UI serveert.
Voordat je begint, zorg dat je het volgende hebt:
Een RunPod-account
Minstens $5 RunPod-tegoed
Basiskennis van Linux-terminalcommando's
Een Hugging Face-account
Een Hugging Face-toegangstoken opgeslagen als HF_TOKEN
Je gebruikt het Hugging Face-token om het model sneller en betrouwbaarder te downloaden.
Wil je zien hoe het model zich verhoudt tot propriëtaire concurrenten van OpenAI, lees dan onze vergelijkingsgids DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Maak eerst een nieuwe GPU-pod aan op RunPod.
Voor deze gids gebruiken we de RTX PRO 6000 GPU omdat die 96GB VRAM biedt tegen een veel lagere prijs dan een H100. Dit maakt het een praktische optie om het volledige DeepSeek V4 Flash-model op één GPU te draaien zonder H100-premieprijzen te betalen.
Selecteer in het RunPod-dashboard een RTX PRO 6000 GPU-pod en gebruik de nieuwste PyTorch-template als basisimage.
Bewerk de templatesettings voordat je de pod uitrolt en configureer de opslag, de openstaande poort en de omgevingsvariabelen.
Gebruik de volgende aanbevolen setup:
|
Instelling |
Aanbevolen waarde |
|
GPU |
RTX PRO 6000 |
|
Containerdisk |
50 GB |
|
Volumedisk |
300 GB |
|
Openstaande poort |
8910 |
|
Template |
Nieuwste PyTorch-template |
|
Omgevingsvariabele |
|
De openstaande poort 8910 is belangrijk, want dit is de poort waarmee je de llama.cpp Web UI vanuit je browser benadert.
Zodra de pod is uitgerold, wacht je een paar seconden tot het RunPod-dashboard de link naar JupyterLab toont.
Open JupyterLab en start vervolgens een terminal. Om te controleren of de GPU beschikbaar is, voer je uit:
nvidia-smi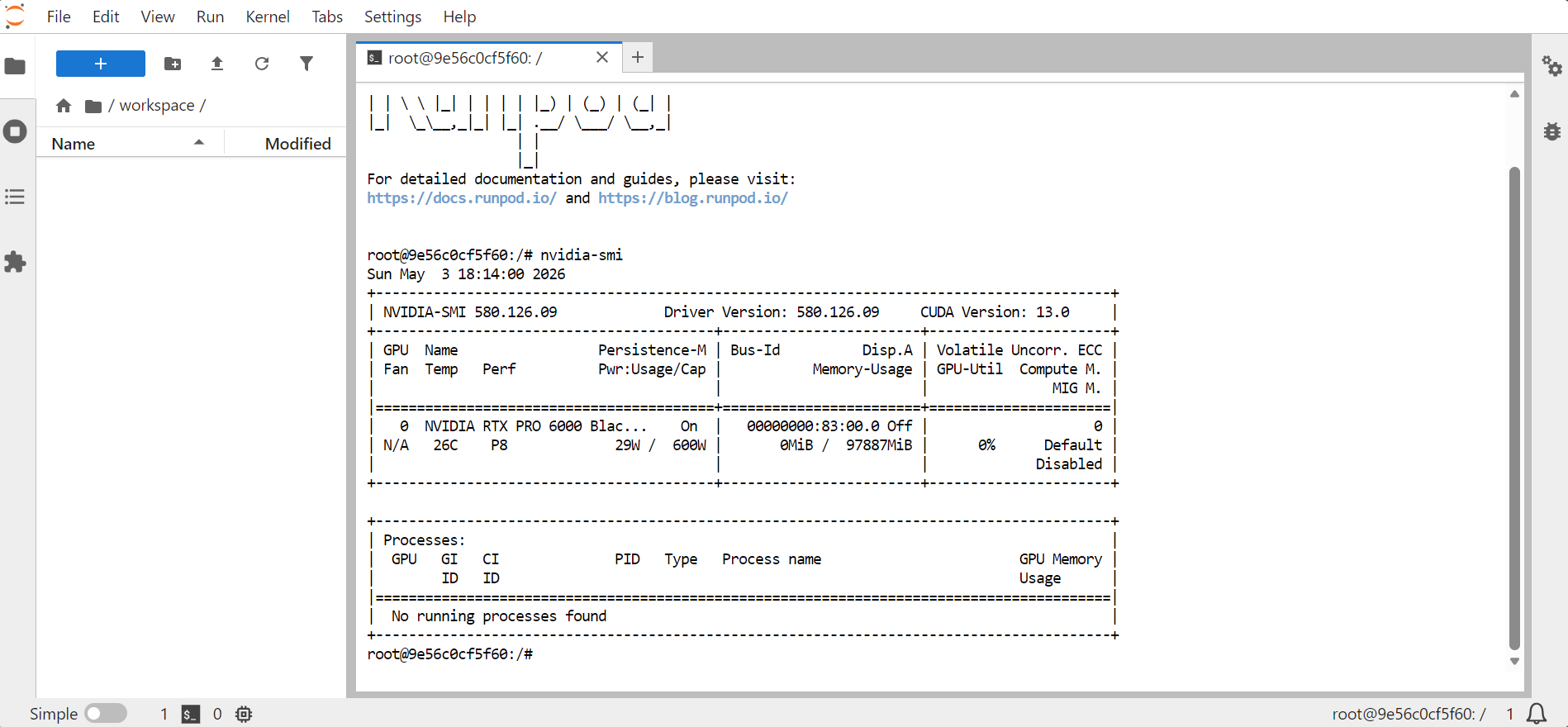
Dit zou informatie moeten tonen over de GPU, het geheugen, de CUDA-versie en de stuurprogrammaversie.
Installeer vervolgens de systeema afhankelijkheden die nodig zijn om llama.cpp te bouwen en uit te voeren.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvDeze pakketten omvatten buildtools, CMake, Git, Python en andere hulpprogramma's die nodig zijn om llama.cpp vanuit de bron te compileren.
DeepSeek V4 Flash is nog erg nieuw, waardoor lokale ondersteuning minder rechttoe rechtaan is dan bij oudere modellen. Op het moment van schrijven is er geen breed geaccepteerde officiële GGUF-release van grote community-providers zoals Unsloth om het volledige model via de standaard upstreamversie van llama.cpp te draaien.
Het officiële DeepSeek V4 Flash-model is beschikbaar op Hugging Face, maar de lokale GGUF-route is nog afhankelijk van communityconversies en experimentele runtime-ondersteuning. De in deze gids gebruikte GGUF vermeldt specifiek dat de standaard upstream llama.cpp deze niet kan laden en een work-in-progress-build vereist met ondersteuning voor de DeepSeek V4 Flash-architectuur, native FP8 en MXFP4-ondersteuning.
Daarom gebruikt deze setup de aangepaste branch van een opensource-bijdrager van llama.cpp in plaats van de standaard upstreamversie. Dit is momenteel het praktische pad om de volledige DeepSeek V4 Flash GGUF lokaal te testen.
Het upstreamproject llama.cpp heeft ook een open modelverzoek voor DeepSeek V4-ondersteuning, wat laat zien dat officiële ondersteuning nog in ontwikkeling is en nog niet volledig in het hoofdproject is samengevoegd.
Ga naar de werkmap:
cd /workspaceKloon de aangepaste repository:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Configureer nu de build met CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseDit schakelt CUDA-ondersteuning in, zodat het model GPU-versnelling kan gebruiken.
Bouw de vereiste binaries:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitKopieer na het voltooien van de build de binaries naar de hoofdprojectmap:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Controleer ten slotte of de serverbinary werkt:
llama.cpp-deepseek-v4/llama-server --helpAls het helpmenu verschijnt, is de build geslaagd.
Installeer vervolgens de downloadtools van Hugging Face. Hier wordt het eerder toegevoegde HF_TOKEN belangrijk. Omdat dit een groot modelbestand is, zorgt inloggen met je Hugging Face-token voor betrouwbaardere downloads en toegang tot snellere downloadmethoden.
Installeer de vereiste pakketten:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferSchakel snellere Hugging Face-downloads in:
export HF_HUB_ENABLE_HF_TRANSFER=1Maak een map voor het model:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Download het GGUF-modelbestand:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Met hf_transfer ingeschakeld en je HF_TOKEN al ingesteld in de RunPod-omgeving, kan de modeldownload zeer hoge snelheden bereiken.
In deze setup bereikte de download bijna 2 GB per seconde, wat het downloaden van een groot GGUF-bestand veel praktischer maakt. Deze snelheid is alleen mogelijk wanneer je Hugging Face-token correct is geconfigureerd en de pod kan authenticeren bij Hugging Face.

Controleer het bestand zodra de download is voltooid:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Je zou een bestand moeten zien dat hierop lijkt:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufNu het model is gedownload en de aangepaste llama.cpp-build klaar is, is de volgende stap het starten van de lokale inference-server, zodat je DeepSeek V4 Flash kunt benaderen via de browsergebaseerde Web UI en API-endpoint.
Ga naar de llama.cpp-map:
cd /workspace/llama.cpp-deepseek-v4Start de modelserver:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfDit commando laadt het GGUF-model, stelt de server bloot op 0.0.0.0:8910, past de Jinja-chattemplate toe, gebruikt --fit on om het model in het beschikbare GPU- en systeemgeheugen te laten passen, stelt een 32K contextvenster in, schakelt CUDA-vriendelijke batching en Flash Attention in voor snellere inference, en schakelt metrics- en prestatielogging in zodat je de run kunt monitoren.
Het laden van het model in het GPU- en CPU-geheugen kan minstens een minuut duren.

Wanneer de server klaar is, zou je een bericht moeten zien dat aangeeft dat hij “listening on http://0.0.0.0:8910”.

Dit betekent dat de modelserver draait en klaar is om verzoeken te ontvangen.
Ga terug naar je RunPod-dashboard. Zoek naar de openstaande poort 8910 en klik vervolgens op de poortlink.
Dit opent de llama.cpp Web UI in je browser. De interface lijkt op een eenvoudige ChatGPT-achtige chatinterface.
Zodra de pagina opent, zou het model al geladen moeten zijn. Je kunt direct vanuit de browser met het model chatten.
Nadat de server draait, kun je het model testen met verschillende soorten prompts.
Het doel is te controleren hoe goed het presteert bij:
Gebruik de volgende prompt:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
In deze test genereerde het model de HTML-pagina in ongeveer 2 minuten, wat een redelijke tijd is.
Om de gegenereerde pagina te bekijken, zoek je naar het oogpictogram bij de code-uitvoer in de Web UI. Klik erop om de gerenderde webpagina te openen.
De pagina werkte, maar de visuele kwaliteit was niet heel indrukwekkend. De lay-out was functioneel, maar het ontwerp voelde basic aan. Kleinere modellen kunnen soms strakkere frontendresultaten opleveren, dus dit resultaat was teleurstellend voor UI-generatie.
Test vervolgens het schrijfvermogen van het model.
Gebruik deze prompt:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Het model produceerde een helder en goed gestructureerd rapport. Het legde de kernideeën eenvoudig uit en bevatte nuttige voorbeelden van toolgebruik, planning, geheugen, reflectie en zakelijke automatisering.
De output voelde echter op sommige plekken wat algemeen en promotioneel aan, vooral richting de conclusie. Ook zaten er enkele opmaak- en spelfouten in, zoals inconsistente vetgedrukte tekst en formuleringen als “Mainate Context”.
Test nu het redeneervermogen van het model met een eenvoudige algebravraag.
Gebruik deze prompt:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Het model loste het probleem correct op.
Het definieerde de variabelen correct, maakte de juiste vergelijkingen, verving waarden goed en controleerde het eindantwoord.
Het exacte antwoord was:
Als decimalen is dit ongeveer:
De waarden komen samen correct uit op het totaal van $156.
Test tot slot of het model een compleet, beginnersvriendelijk programmeerproject kan genereren.
Gebruik deze prompt:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
De reactie leek in eerste instantie compleet en de projectstructuur was logisch. Maar de gegenereerde code had meerdere serieuze problemen.
De output bevatte:
Voor een beginnersvriendelijk project is dit een groot probleem. Een beginner moet de code met minimale fixes kunnen kopiëren, draaien en begrijpen. In dit geval zou het gegenereerde project aanzienlijk gedebugd moeten worden voordat het bruikbaar is.
Na het testen van DeepSeek V4 Flash op UI-generatie, schrijven, redeneren en projectgeneratie, liet het model gemengde resultaten zien.
Het presteerde goed bij gestructureerd redeneren en basisuitleg. Het kon ook snel outputs genereren via de llama.cpp Web UI.
Het had echter moeite met verzorgde frontendontwerpen en betrouwbare codegeneratie voor volledige projecten. De Python-projectoutput leek compleet maar bevatte te veel syntax- en naamgevingsfouten om zonder handmatig debuggen nuttig te zijn.
|
Taak |
Prestaties |
|
UI-generatie |
Gemiddeld |
|
Schrijven en uitleggen |
Goed |
|
Wiskundig redeneren |
Sterk |
|
Volledige projectgeneratie |
Zwak |
|
Snelheid |
Goed |
|
Algemene betrouwbaarheid |
Gemengd |
DeepSeek V4 Flash lokaal draaien was eerlijk gezegd een nachtmerrie.
Ik probeerde het eerst op een 4x H100-setup met een sglang Docker Compose-configuratie, maar dat mislukte. Daarna probeerde ik het met vLLM op 4x H100 RunPod met Python, maar ook dat mislukte. De fout wees steeds naar DeepSeek V4-ondersteuning in de nieuwste versie van transformers, terwijl ik die al gebruikte. Dat maakte duidelijk dat de juiste frameworkondersteuning nog niet volledig aanwezig is.
Zelfs de officiële modelpagina op Hugging Face biedt geen eenvoudig, standaard inference-voorbeeld. In plaats daarvan worden gebruikers verwezen naar een aangepaste torchrun-aanpak, die veel zwaarder is en meer werk kost om op te zetten.
Ik testte ook door de community geleverde GGUF-bestanden, maar liep tegen compatibiliteitsproblemen met llama.cpp aan. Gewoonlijk geef ik de voorkeur aan Unsloth-GGUF-bestanden omdat ze snel, betrouwbaar en eenvoudig te draaien zijn, maar voor DeepSeek V4 Flash was er geen eenvoudige plug-and-play-route.
Na al dat testen was de methode in deze gids de makkelijkste en meest betrouwbare manier die ik vond om het volledige model lokaal te draaien. Het is nog steeds afhankelijk van een community-GGUF-bestand en een aangepaste llama.cpp-build, maar vergeleken met de andere opties werkte deze setup daadwerkelijk.
Dat gezegd hebbende, vind ik niet dat DeepSeek V4 Flash het momenteel waard is om lokaal te draaien. De setup is te pijnlijk, de frameworkondersteuning is nog onvolwassen en de outputkwaliteit rechtvaardigt de moeite niet.
Wil je een soepelere lokale modelervaring, probeer dan modellen zoals MiniMax M2.7 of sterk gequantiseerde modellen zoals Qwen3.6-27B. Ze zijn eenvoudiger te draaien, beter ondersteund in gangbare frameworks, in de praktijk sneller en leveren vaak met veel minder setupfrustratie resultaten van hogere kwaliteit.
Topcursussen over LLM's
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
