tracks
대형 언어 모델 개발
16
DeepSeek V4 Flash는 DeepSeek V4 프리뷰 시리즈 중 더 작고 빠르며 비용 효율적인 모델입니다. 실용적인 추론 워크로드를 위해 설계되었으며, DeepSeek V4 Pro보다 활성 파라미터가 적고 긴 컨텍스트 작업을 지원합니다. 본 가이드에서 사용하는 GGUF 버전은 조밀 가중치를 FP8로, MoE 전문가 가중치를 FP4로 저장하여 커스텀 llama.cpp 빌드를 통한 로컬 추론에 적합합니다.
이 가이드에서는 RunPod에서 DeepSeek V4 Flash를 로컬로 실행합니다. RTX PRO 6000 GPU와 수정된 llama.cpp 빌드를 사용합니다. GPU 파드를 구성하고 필수 종속성을 설치한 뒤, DeepSeek V4 지원으로 llama.cpp를 컴파일하고, Hugging Face에서 FP4/FP8 GGUF 모델을 다운로드해 브라우저 기반 llama.cpp Web UI로 제공하는 방법을 배웁니다.
시작하기 전에 다음을 준비하세요:
RunPod 계정
RunPod 크레딧 최소 $5
리눅스 터미널 명령 기본 지식
Hugging Face 계정
HF_TOKEN으로 저장된 Hugging Face 액세스 토큰
Hugging Face 토큰은 더 빠르고 안정적으로 모델을 다운로드하는 데 사용합니다.
모델이 OpenAI의 독점 경쟁작들과 어떻게 비교되는지 보고 싶다면, DeepSeek V4 Flash vs GPT-5.4 Mini and Nano 비교 가이드를 읽어보세요.
먼저 RunPod에서 새 GPU 파드를 생성하세요.
이 가이드에서는 RTX PRO 6000 GPU를 사용합니다. VRAM 96GB를 제공하면서 H100보다 훨씬 저렴합니다. 덕분에 H100 프리미엄 비용 없이 단일 GPU로 전체 DeepSeek V4 Flash 모델을 실행하기에 현실적인 선택지입니다.
RunPod 대시보드에서 RTX PRO 6000 GPU 파드를 선택하고, 베이스 이미지는 최신 PyTorch 템플릿을 사용하세요.
파드를 배포하기 전에 템플릿 설정을 열고 스토리지, 노출 포트, 환경 변수를 구성합니다.
다음과 같은 권장 설정을 사용하세요:
|
설정 |
권장 값 |
|
GPU |
RTX PRO 6000 |
|
컨테이너 디스크 |
50 GB |
|
볼륨 디스크 |
300 GB |
|
노출 포트 |
8910 |
|
템플릿 |
최신 PyTorch 템플릿 |
|
환경 변수 |
|
노출 포트 8910은 브라우저에서 llama.cpp Web UI에 접속할 때 사용할 포트이므로 중요합니다.
파드가 배포되면 RunPod 대시보드에 JupyterLab 링크가 표시될 때까지 잠시 기다리세요.
JupyterLab을 열고 터미널을 실행합니다. GPU 사용 가능 여부를 확인하려면 다음을 실행하세요:
nvidia-smi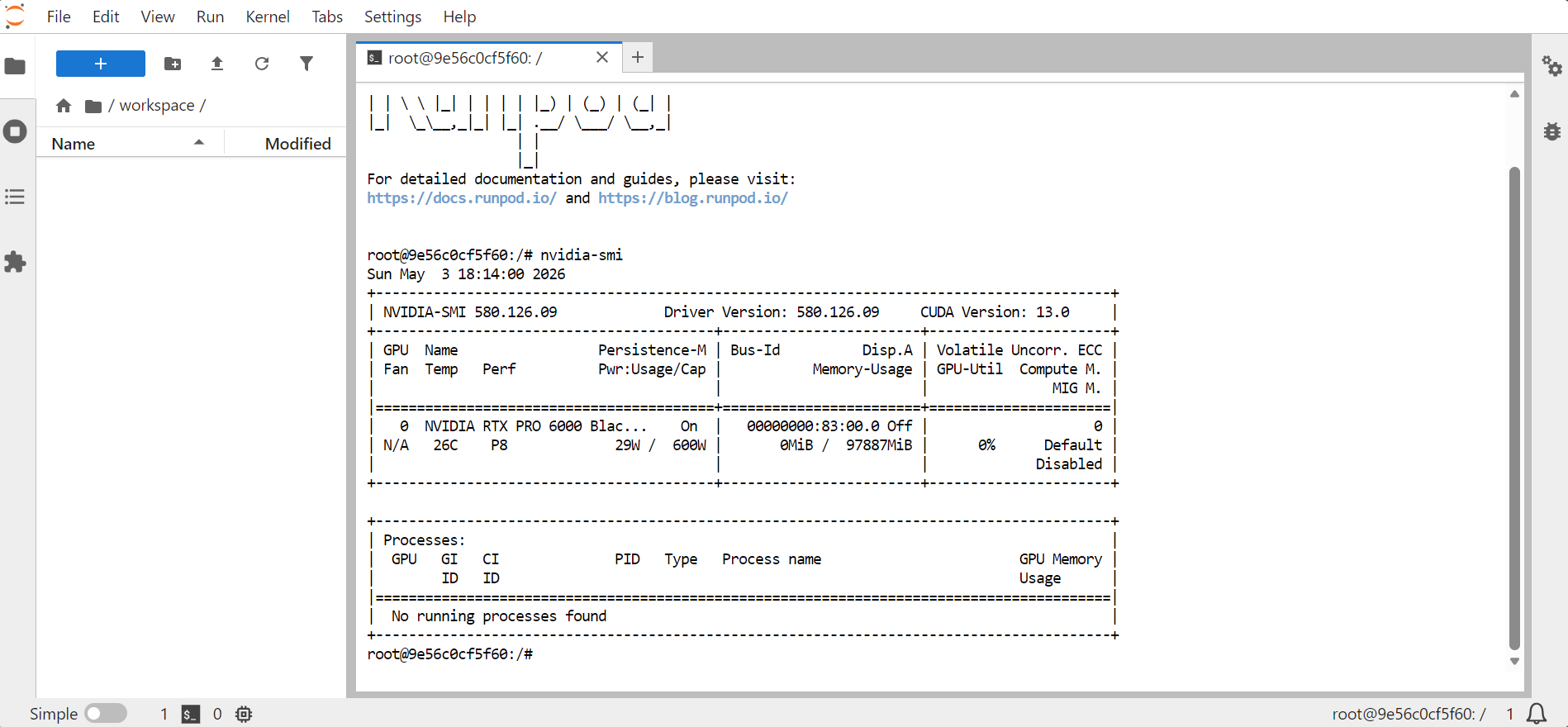
GPU, 메모리, CUDA 버전, 드라이버 버전 정보가 표시되어야 합니다.
다음으로 llama.cpp를 빌드하고 실행하는 데 필요한 시스템 종속성을 설치합니다.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venv이 패키지에는 빌드 도구, CMake, Git, Python 등 소스에서 llama.cpp를 컴파일하는 데 필요한 유틸리티가 포함됩니다.
DeepSeek V4 Flash는 아직 출시 초기여서, 로컬 지원이 기존 모델만큼 간단하지 않습니다. 작성 시점 기준으로 표준 업스트림 llama.cpp에서 전체 모델을 실행할 수 있는, Unsloth 같은 주요 커뮤니티 제공자들의 널리 채택된 공식 GGUF 릴리스가 없습니다.
공식 DeepSeek V4 Flash 모델은 Hugging Face에 있지만, 로컬 GGUF 경로는 여전히 커뮤니티 변환과 실험적 런타임 지원에 의존합니다. 본 가이드에서 사용하는 GGUF는 기본 업스트림 llama.cpp로는 로드할 수 없고, DeepSeek V4 Flash 아키텍처 지원과 네이티브 FP8, MXFP4 지원이 포함된 진행 중인 빌드가 필요하다고 명시합니다.
이 때문에 표준 업스트림 버전이 아닌 오픈 소스 기여자의 수정된 llama.cpp 브랜치를 사용합니다. 현재 전체 DeepSeek V4 Flash GGUF를 로컬에서 테스트하기에 현실적인 경로입니다.
업스트림 llama.cpp 프로젝트에도 DeepSeek V4 지원에 대한 오픈 모델 요청이 있어, 공식 지원이 아직 메인 프로젝트에 완전히 병합되지 않았음을 보여줍니다.
워크스페이스 디렉터리로 이동합니다:
cd /workspace수정된 리포지토리를 클론합니다:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4이제 CMake로 빌드를 구성합니다:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseCUDA 지원을 활성화하여 모델이 GPU 가속을 사용할 수 있게 합니다.
필요한 바이너리를 빌드합니다:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-split빌드가 끝나면 바이너리를 메인 프로젝트 폴더로 복사합니다:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/마지막으로 서버 바이너리가 작동하는지 확인합니다:
llama.cpp-deepseek-v4/llama-server --help도움말 메뉴가 나타나면 빌드가 성공한 것입니다.
다음으로 Hugging Face 다운로드 도구를 설치합니다. 앞서 추가한 HF_TOKEN이 여기서 중요합니다. 큰 모델 파일이므로 Hugging Face 토큰으로 로그인하면 다운로드 안정성이 높아지고 더 빠른 다운로드 방식에 접근할 수 있습니다.
필요한 패키지를 설치합니다:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferHugging Face 고속 다운로드를 활성화합니다:
export HF_HUB_ENABLE_HF_TRANSFER=1모델용 폴더를 만듭니다:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8GGUF 모델 파일을 다운로드합니다:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8hf_transfer가 활성화되어 있고 RunPod 환경에 HF_TOKEN이 설정되어 있으면 모델 다운로드 속도가 매우 빨라질 수 있습니다.
이 설정에서는 다운로드 속도가 거의 초당 2GB에 도달해 대용량 GGUF 파일 다운로드가 훨씬 실용적이었습니다. 이 속도는 Hugging Face 토큰이 올바르게 구성되어 파드가 Hugging Face에 인증할 수 있을 때만 가능합니다.

다운로드가 완료되면 파일을 확인합니다:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8다음과 유사한 파일이 보여야 합니다:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.gguf모델 다운로드와 수정된 llama.cpp 빌드 준비가 끝났으므로, 로컬 추론 서버를 시작해 브라우저 기반 Web UI와 API 엔드포인트로 DeepSeek V4 Flash에 접근합니다.
llama.cpp 디렉터리로 이동합니다:
cd /workspace/llama.cpp-deepseek-v4모델 서버를 시작합니다:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perf이 명령은 GGUF 모델을 로드하고 0.0.0.0:8910에서 서버를 노출합니다. Jinja 채팅 템플릿을 적용하고, --fit on으로 가용 GPU/시스템 메모리에 모델을 맞추며, 32K 컨텍스트 윈도우를 설정하고, CUDA 친화적 배칭과 Flash Attention을 활성화해 추론을 가속합니다. 또한 메트릭과 성능 로깅을 켜서 실행을 모니터링할 수 있게 합니다.
모델이 GPU와 CPU 메모리에 로드되는 데 최소 1분 정도 걸릴 수 있습니다.

서버가 준비되면 “listening on http://0.0.0.0:8910” 메시지가 표시됩니다.

이는 모델 서버가 실행 중이며 요청을 받을 준비가 되었음을 의미합니다.
RunPod 대시보드로 돌아가 노출 포트 8910을 찾고 포트 링크를 클릭하세요.
그러면 브라우저에서 llama.cpp Web UI가 열립니다. 인터페이스는 기본 ChatGPT 스타일의 채팅 인터페이스와 비슷합니다.
페이지가 열리면 모델이 이미 로드되어 있을 것입니다. 브라우저에서 바로 대화를 시작할 수 있습니다.
서버가 실행 중이면 다양한 유형의 프롬프트로 모델을 테스트할 수 있습니다.
다음 영역에서의 성능을 확인하는 것이 목표입니다:
다음 프롬프트를 사용하세요:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
이 테스트에서 모델은 약 2분 만에 HTML 페이지를 생성했으며, 합리적인 속도였습니다.
생성된 페이지를 미리 보려면 Web UI의 코드 출력 근처 눈 아이콘을 찾으세요. 클릭하면 렌더링된 웹 페이지가 열립니다.
페이지는 동작했지만 시각적 퀄리티가 썩 인상적이지는 않았습니다. 레이아웃은 기능적이었으나 디자인은 기본적이었습니다. 더 작은 모델이 더 다듬어진 프런트엔드 결과물을 내놓는 경우도 있어, UI 생성 측면에서는 아쉬운 결과였습니다.
다음으로 모델의 글쓰기 능력을 테스트합니다.
이 프롬프트를 사용하세요:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
모델은 명확하고 구조화된 보고서를 생성했습니다. 핵심 개념을 쉽게 설명하고 도구 사용, 계획 수립, 메모리, 성찰, 업무 수행 등 유용한 예시를 포함했습니다.
다만 결론 부근 등 일부에서는 다소 일반적이고 홍보성 어조가 느껴졌습니다. 또한 굵게 표시의 불일치, “Mainate Context” 같은 표기 오류 등 몇 가지 서식 및 철자 문제가 있었습니다.
이제 간단한 대수 문제로 모델의 추론 능력을 테스트합니다.
이 프롬프트를 사용하세요:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
모델은 문제를 올바르게 해결했습니다.
변수를 적절히 정의하고, 정확한 방정식을 세운 뒤 값을 올바르게 대입했으며 최종 답을 검산했습니다.
정확한 해는 다음과 같았습니다:
소수로는 대략 다음과 같습니다:
값을 합하면 총액 $156과 정확히 일치합니다.
마지막으로, 초보자 친화적인 완전한 코딩 프로젝트를 생성할 수 있는지 테스트합니다.
이 프롬프트를 사용하세요:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
응답은 처음엔 완전해 보였고 프로젝트 구조도 그럴듯했습니다. 그러나 생성된 코드에는 심각한 문제가 여럿 있었습니다.
출력에는 다음과 같은 문제가 포함되었습니다:
초보자 친화적인 프로젝트로서는 큰 문제입니다. 초보자는 최소한의 수정으로 코드를 복사해 실행하고 이해할 수 있어야 합니다. 이 경우 생성된 프로젝트는 사용 전에 상당한 디버깅이 필요합니다.
UI 생성, 글쓰기, 추론, 프로젝트 생성에 대해 DeepSeek V4 Flash를 테스트한 결과는 혼재되어 있었습니다.
구조화된 추론과 기본 설명형 글쓰기는 잘 수행했으며, llama.cpp Web UI를 통해 빠르게 결과를 생성했습니다.
하지만 정교한 프런트엔드 디자인과 신뢰할 수 있는 전체 프로젝트 코드 생성에서는 어려움을 보였습니다. Python 프로젝트 출력은 겉보기엔 완전해 보였지만, 문법 및 명명 오류가 너무 많아 수동 디버깅 없이는 유용하지 않았습니다.
|
작업 |
성능 |
|
UI 생성 |
보통 |
|
글쓰기 및 설명 |
양호 |
|
수학적 추론 |
강함 |
|
전체 프로젝트 생성 |
약함 |
|
속도 |
양호 |
|
전반적 신뢰성 |
혼합 |
솔직히 DeepSeek V4 Flash를 로컬에서 실행하는 과정은 악몽에 가까웠습니다.
sglang Docker Compose 구성을 사용해 4x H100 세팅에서 먼저 시도했지만 실패했습니다. 이후 vLLM을 사용해 RunPod의 4x H100에서 Python으로 실행을 시도했지만 역시 실패했습니다. 오류는 최신 transformers 버전의 DeepSeek V4 지원을 가리켰고, 이미 최신 버전을 사용 중이었음에도 같은 문제가 발생했습니다. 이는 프레임워크의 적절한 지원이 아직 완전하지 않다는 점을 분명히 보여줬습니다.
공식 Hugging Face 모델 페이지조차 간단한 표준 추론 예제를 제공하지 않습니다. 대신 훨씬 무겁고 설정 작업이 많은 커스텀 torchrun 접근을 안내합니다.
커뮤니티 제공 GGUF 파일도 테스트했지만 llama.cpp 호환성 문제를 겪었습니다. 보통은 빠르고 안정적이며 실행이 쉬운 Unsloth GGUF 파일을 선호하지만, DeepSeek V4 Flash의 경우 단순한 플러그앤플레이 경로가 없었습니다.
그 모든 테스트 이후, 이 가이드에서 소개한 방법이 전체 모델을 로컬에서 실행하는 가장 쉽고 신뢰할 만한 방법이었습니다. 커뮤니티 GGUF 파일과 수정된 llama.cpp 빌드에 의존하긴 하지만, 다른 옵션과 비교하면 실제로 작동했습니다.
그럼에도 현시점에서 DeepSeek V4 Flash를 로컬로 실행할 가치는 크지 않다고 봅니다. 설정 과정이 너무 고통스럽고, 프레임워크 지원이 미성숙하며, 출력 품질도 그 노력을 정당화하지 못합니다.
더 부드러운 로컬 모델 경험을 원한다면 MiniMax M2.7 또는 강하게 양자화된 Qwen3.6-27B 같은 모델을 권장합니다. 실행이 더 쉽고 주요 프레임워크 전반에서 지원이 잘 되며, 실제로 더 빠르고, 훨씬 적은 설정 스트레스로 더 높은 품질의 결과를 내는 경우가 많습니다.
최고의 LLM 코스
tracks
courses
courses