track
Utveckla stora språkmodeller
16 timmar
DeepSeek V4 Flash är den mindre, snabbare och mer kostnadseffektiva modellen i förhandsserien DeepSeek V4. Den är utformad för praktiska inferensarbetslaster, med färre aktiva parametrar än DeepSeek V4 Pro och stöd för uppgifter med långa kontexter. GGUF-versionen som används i denna guide lagrar täta vikter i FP8 och MoE-expertvikter i FP4, vilket gör den lämplig för lokal inferens via en anpassad llama.cpp-build.
I denna guide kommer vi att köra DeepSeek V4 Flash lokalt på RunPod med ett RTX PRO 6000-GPU och en modifierad llama.cpp-build. Du lär dig hur du sätter upp GPU-poden, installerar nödvändiga beroenden, kompilerar llama.cpp med stöd för DeepSeek V4, laddar ned FP4/FP8 GGUF-modellen från Hugging Face och serverar den via det webbläsarbaserade Web UI:t för llama.cpp.
Innan du börjar, se till att du har:
Ett RunPod-konto
Minst 5 USD i RunPod-kredit
Grundläggande vana vid Linux-terminalkommandon
Ett Hugging Face-konto
En Hugging Face-åtkomsttoken sparad som HF_TOKEN
Du använder Hugging Face-tokenen för att ladda ned modellen snabbare och mer tillförlitligt.
Om du vill se hur modellen står sig mot proprietära konkurrenter från OpenAI rekommenderar jag vår jämförelseguide DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Skapa först en ny GPU-pod på RunPod.
För den här guiden använder vi RTX PRO 6000-GPU eftersom den erbjuder 96 GB VRAM till en mycket lägre kostnad än en H100. Det gör den till ett praktiskt alternativ för att köra hela DeepSeek V4 Flash-modellen på ett enda GPU utan att betala H100-priser i premiumklassen.
I RunPods dashboard väljer du en RTX PRO 6000-GPU-pod och använder den senaste PyTorch-mallen som basimage.
Innan du distribuerar poden, redigera mallinställningarna och konfigurera lagring, exponerad port och miljövariabler.
Använd följande rekommenderade konfiguration:
|
Inställning |
Rekommenderat värde |
|
GPU |
RTX PRO 6000 |
|
Containerdisk |
50 GB |
|
Volymdisk |
300 GB |
|
Exponerad port |
8910 |
|
Mall |
Senaste PyTorch-mallen |
|
Miljövariabel |
|
Den exponerade porten 8910 är viktig eftersom det är porten du använder för att komma åt llama.cpp:s Web UI från din webbläsare.
När poden har distribuerats väntar du några sekunder tills RunPods dashboard visar länken till JupyterLab.
Öppna JupyterLab och starta en terminal. För att bekräfta att GPU:n är tillgänglig, kör:
nvidia-smi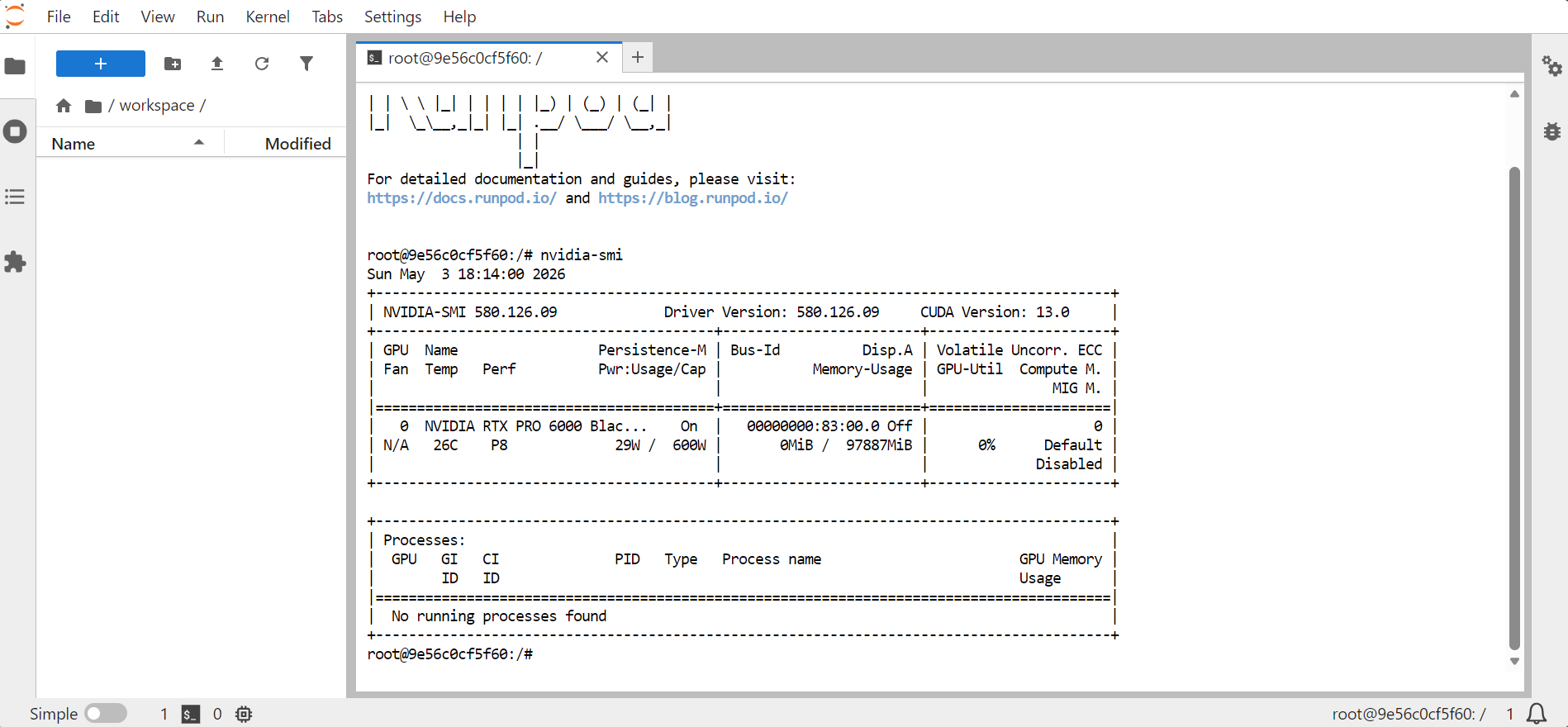
Detta bör visa information om GPU, minne, CUDA-version och drivrutinsversion.
Installera sedan systemberoenden som krävs för att bygga och köra llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvDessa paket inkluderar byggverktyg, CMake, Git, Python och andra verktyg som behövs för att kompilera llama.cpp från källkod.
DeepSeek V4 Flash är fortfarande mycket ny, så lokalt stöd är inte lika rakt på sak som för äldre modeller. När detta skrivs finns det ingen brett antagen officiell GGUF-release från större community-aktörer som Unsloth för att köra hela modellen via standard-upstream llama.cpp.
Den officiella DeepSeek V4 Flash-modellen finns på Hugging Face, men den lokala GGUF-vägen beror fortfarande på community-konverteringar och experimentellt runtime-stöd. GGUF:en som används i denna guide anger uttryckligen att standard-upstream llama.cpp inte kan ladda den och kräver en pågående WIP-build med stöd för DeepSeek V4 Flash-arkitektur, inbyggd FP8 och MXFP4-stöd.
På grund av detta använder den här uppsättningen en öppen källkods-bidragares modifierade llama.cpp-gren i stället för standard-upstream-versionen. Detta är för närvarande den praktiska vägen för att testa hela DeepSeek V4 Flash GGUF lokalt.
Upstream-projektet llama.cpp har också en öppen modellförfrågan för DeepSeek V4-stöd, vilket visar att officiellt stöd fortfarande är under arbete och ännu inte fullt ut sammanslaget i huvudprojektet.
Gå till arbetskatalogen:
cd /workspaceKlona det modifierade repositoriet:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Konfigurera nu builden med CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseDetta aktiverar CUDA-stöd så att modellen kan använda GPU-acceleration.
Bygg de nödvändiga binärerna:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitNär builden är klar, kopiera binärerna till huvudmappens projekt:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Kontrollera slutligen att serverbinären fungerar:
llama.cpp-deepseek-v4/llama-server --helpOm hjälpmenyn visas lyckades builden.
Installera härnäst Hugging Face-verktygen för nedladdning. Det är här HF_TOKEN du lade till tidigare blir viktig. Eftersom detta är en stor modellfil förbättrar inloggning med din Hugging Face-token tillförlitligheten och ger tillgång till snabbare nedladdningsmetoder.
Installera nödvändiga paket:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferAktivera snabbare Hugging Face-nedladdningar:
export HF_HUB_ENABLE_HF_TRANSFER=1Skapa en mapp för modellen:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Ladda ned GGUF-modellfilen:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Med hf_transfer aktiverat och din HF_TOKEN redan inställd i RunPod-miljön kan modellnedladdningen nå mycket höga hastigheter.
I denna uppsättning nådde nedladdningen nästan 2 GB per sekund, vilket gör det mycket mer praktiskt att ladda ned en stor GGUF-fil. Denna hastighet är bara möjlig när din Hugging Face-token är korrekt konfigurerad och poden kan autentisera mot Hugging Face.

När nedladdningen är klar, verifiera filen:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Du bör se en fil liknande denna:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufNu när modellen är nedladdad och den modifierade llama.cpp-builden är redo, är nästa steg att starta den lokala inferensservern så att du kan komma åt DeepSeek V4 Flash via det webbläsarbaserade Web UI:t och API-slutpunkten.
Gå till katalogen llama.cpp:
cd /workspace/llama.cpp-deepseek-v4Starta modellservern:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfDetta kommando laddar GGUF-modellen, exponerar servern på 0.0.0.0:8910, tillämpar Jinja-chattmallen, använder --fit on för att få in modellen i tillgängligt GPU- och systemminne, sätter ett 32K-kontextfönster, aktiverar CUDA-vänlig batchning och Flash Attention för snabbare inferens, samt slår på mätvärden och prestandaloggar så att du kan övervaka körningen.
Det kan ta minst en minut att läsa in modellen i GPU- och CPU-minnet.

När servern är redo bör du se ett meddelande som visar att den ”lyssnar på http://0.0.0.0:8910”.

Detta betyder att modellservern kör och är redo att ta emot förfrågningar.
Gå tillbaka till din RunPod-dashboard. Leta efter den exponerade porten 8910 och klicka sedan på portlänken.
Detta öppnar llama.cpp:s Web UI i din webbläsare. Gränssnittet ser ut som ett enkelt ChatGPT-liknande chattgränssnitt.
När sidan öppnas ska modellen redan vara inläst. Du kan börja chatta med den direkt från webbläsaren.
När servern kör kan du testa modellen med olika typer av uppmaningar.
Målet är att kontrollera hur väl den presterar inom:
Använd följande prompt:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
I detta test genererade modellen HTML-sidan på cirka 2 minuter, vilket är en rimlig tid.
För att förhandsgranska den genererade sidan letar du efter ögonikonen nära kodutmatningen i Web UI:t. Klicka på den för att öppna den renderade webbsidan.
Sidan fungerade, men den visuella kvaliteten var inte särskilt imponerande. Layouten var funktionell, men designen kändes grundläggande. Mindre modeller kan ibland producera mer polerade frontend-resultat, så detta var en besvikelse för UI-generering.
Testa därefter modellens skrivförmåga.
Använd denna prompt:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Modellen producerade en tydlig och välstrukturerad rapport. Den förklarade huvudidéerna på ett enkelt sätt och inkluderade användbara exempel på verktygsanvändning, planering, minne, reflektion och affärsautomation.
Dock kändes resultatet något generiskt och reklamaktigt på vissa ställen, särskilt mot slutet. Det innehöll också flera formaterings- och stavfel, som inkonsekvent fetstil och ordvalsfel som ”Mainate Context”.
Testa nu modellens resonemangsförmåga med ett enkelt algebra-problem.
Använd denna prompt:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Modellen löste problemet korrekt.
Den definierade variablerna korrekt, skapade rätt ekvationer, gjorde korrekta insättningar och kontrollerade slutsvaret.
Det exakta svaret var:
Som decimaltal är detta ungefär:
Värdena summerar korrekt till totalt 156 USD.
Slutligen testar du om modellen kan generera ett komplett, nybörjarvänligt kodprojekt.
Använd denna prompt:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
Svaret såg komplett ut vid första anblick, och projektstrukturen var rimlig. Men den genererade koden hade flera allvarliga problem.
Utmatningen innehöll:
För ett nybörjarvänligt projekt är detta ett stort problem. En nybörjare ska kunna kopiera, köra och förstå koden med minimala justeringar. I detta fall skulle det genererade projektet behöva omfattande felsökning innan det kan användas.
Efter att ha testat DeepSeek V4 Flash på UI-generering, skrivande, resonemang och projektgenerering visade modellen blandade resultat.
Den presterade bra på strukturerat resonemang och grundläggande förklarande skrivande. Den kunde också generera utdata snabbt via llama.cpp:s Web UI.
Men den hade svårt med polerad frontend-design och tillförlitlig generering av kompletta projekt. Python-projektet såg komplett ut men innehöll för många syntax- och namngivningsfel för att vara användbart utan manuell felsökning.
|
Uppgift |
Prestanda |
|
UI-generering |
Medel |
|
Skrivande och förklaring |
Bra |
|
Matematiskt resonemang |
Starkt |
|
Generering av komplett projekt |
Svagt |
|
Hastighet |
Bra |
|
Övergripande tillförlitlighet |
Blandad |
Att köra DeepSeek V4 Flash lokalt var ärligt talat ett mardrömsscenario.
Jag försökte först köra den på en 4× H100-uppsättning med en sglang-Docker Compose-konfiguration, men det misslyckades ändå. Jag försökte sedan köra den med vLLM på 4× H100 RunPod med Python, men även det misslyckades. Felet pekade hela tiden på DeepSeek V4-stöd i den senaste versionen av transformers, trots att jag redan använde den senaste versionen. Det stod klart att ordentligt ramverksstöd fortfarande inte är fullt på plats.
Inte ens den officiella modelsidan på Hugging Face ger ett enkelt, standardiserat inferensexempel. I stället hänvisas användare till ett anpassat torchrun-upplägg, som är betydligt tyngre och kräver mer arbete att sätta upp.
Jag testade också GGUF-filer från communityn, men stötte på kompatibilitetsproblem med llama.cpp. Vanligtvis föredrar jag att använda Unsloth-GGUF-filer eftersom de är snabba, tillförlitliga och lätta att köra, men för DeepSeek V4 Flash fanns det ingen enkel plug-and-play-väg.
Efter allt detta testande var metoden som visas i denna guide det enklaste och mest tillförlitliga sättet jag hittade för att köra hela modellen lokalt. Den är fortfarande beroende av en GGUF-fil från communityn och en modifierad llama.cpp-build, men jämfört med andra alternativ fungerade den här uppsättningen faktiskt.
Med det sagt tycker jag inte att DeepSeek V4 Flash är värd att köra lokalt just nu. Uppsättningen är för plågsam, ramverksstödet är fortfarande omoget och output-kvaliteten motiverar inte ansträngningen.
Om du vill ha en smidigare lokal modellupplevelse rekommenderar jag att du testar modeller som MiniMax M2.7 eller starkt kvantiserade modeller som Qwen3.6-27B i stället. De är enklare att köra, bättre stödda i stora ramverk, snabbare i praktiken och ger ofta högre kvalitet med betydligt mindre frustrationsmoment vid uppsättning.
Toppkurser om LLM
track
course
course