
Tracks
Phát triển các mô hình ngôn ngữ quy mô lớn
16 giờ
DeepSeek V4 Flash là mô hình nhỏ hơn, nhanh hơn và tiết kiệm chi phí hơn trong loạt bản xem trước DeepSeek V4. Mô hình được thiết kế cho các khối lượng công việc suy luận thực tế, với số tham số hoạt động thấp hơn DeepSeek V4 Pro và hỗ trợ các tác vụ ngữ cảnh dài. Phiên bản GGUF dùng trong hướng dẫn này lưu trọng số dày đặc ở FP8 và trọng số MoE ở FP4, phù hợp để suy luận cục bộ thông qua bản dựng tuỳ chỉnh llama.cpp.
Trong hướng dẫn này, chúng ta sẽ chạy DeepSeek V4 Flash cục bộ trên RunPod bằng GPU RTX PRO 6000 và bản dựng llama.cpp đã chỉnh sửa. Bạn sẽ học cách thiết lập GPU pod, cài đặt các phụ thuộc cần thiết, biên dịch llama.cpp với hỗ trợ DeepSeek V4, tải mô hình GGUF FP4/FP8 từ Hugging Face và phục vụ mô hình qua giao diện Web UI của llama.cpp trên trình duyệt.
Trước khi bắt đầu, hãy đảm bảo bạn có:
Một tài khoản RunPod
Tối thiểu $5 tín dụng RunPod
Hiểu biết cơ bản về lệnh terminal Linux
Một tài khoản Hugging Face
Một mã truy cập Hugging Face lưu dưới dạng HF_TOKEN
Bạn sẽ dùng token Hugging Face để tải mô hình nhanh hơn và ổn định hơn.
Nếu bạn muốn xem mô hình so sánh như thế nào với các đối thủ độc quyền từ OpenAI, tôi khuyên bạn đọc bài DeepSeek V4 Flash vs GPT-5.4 Mini and Nano so sánh của chúng tôi.
Trước tiên, tạo một GPU pod mới trên RunPod.
Trong hướng dẫn này, chúng tôi sử dụng GPU RTX PRO 6000 vì nó cung cấp 96GB VRAM với chi phí thấp hơn nhiều so với H100. Điều này giúp bạn có thể chạy toàn bộ mô hình DeepSeek V4 Flash trên một GPU duy nhất mà không phải trả mức giá cao của H100.
Trong bảng điều khiển RunPod, chọn một pod RTX PRO 6000 GPU và dùng mẫu PyTorch mới nhất làm image nền tảng.
Trước khi triển khai pod, hãy chỉnh sửa cài đặt mẫu và cấu hình dung lượng lưu trữ, cổng mở và biến môi trường.
Sử dụng cấu hình khuyến nghị sau:
|
Cài đặt |
Giá trị khuyến nghị |
|
GPU |
RTX PRO 6000 |
|
Container Disk |
50 GB |
|
Volume Disk |
300 GB |
|
Exposed Port |
8910 |
|
Template |
Mẫu PyTorch mới nhất |
|
Biến môi trường |
|
Cổng mở 8910 rất quan trọng vì đây là cổng bạn sẽ dùng để truy cập Web UI của llama.cpp từ trình duyệt.
Khi pod được triển khai, đợi vài giây để bảng điều khiển RunPod hiển thị liên kết JupyterLab.
Mở JupyterLab, sau đó khởi chạy một terminal. Để xác nhận GPU khả dụng, chạy:
nvidia-smi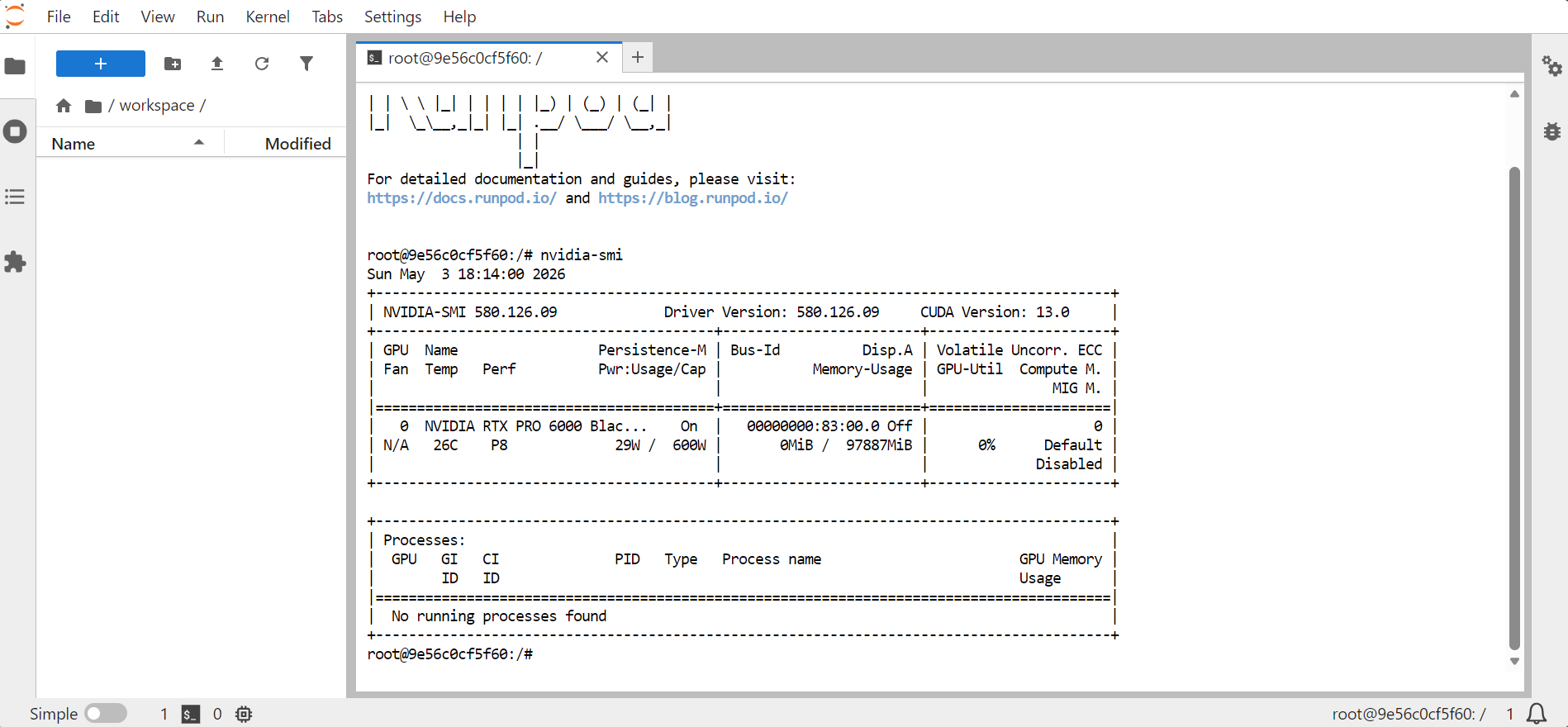
Lệnh này sẽ hiển thị thông tin về GPU, bộ nhớ, phiên bản CUDA và phiên bản driver.
Tiếp theo, cài đặt các phụ thuộc hệ thống cần thiết để build và chạy llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvCác gói này bao gồm công cụ build, CMake, Git, Python và các tiện ích khác cần để biên dịch llama.cpp từ mã nguồn.
DeepSeek V4 Flash vẫn còn rất mới, nên hỗ trợ cục bộ chưa đơn giản như các mô hình cũ hơn. Tại thời điểm viết bài, chưa có bản phát hành GGUF chính thức được cộng đồng lớn như Unsloth chấp nận rộng rãi để chạy toàn bộ mô hình qua llama.cpp upstream tiêu chuẩn.
Mô hình DeepSeek V4 Flash chính thức có trên Hugging Face, nhưng phương án GGUF cục bộ vẫn phụ thuộc vào chuyển đổi từ cộng đồng và hỗ trợ runtime thử nghiệm. GGUF dùng trong hướng dẫn này nêu rõ rằng llama.cpp upstream gốc không thể tải nó và cần một bản dựng đang phát triển có hỗ trợ kiến trúc DeepSeek V4 Flash, FP8 gốc và MXFP4.
Vì vậy, thiết lập này sử dụng một nhánh llama.cpp đã chỉnh sửa của một cộng tác viên mã nguồn mở thay vì phiên bản upstream tiêu chuẩn. Hiện tại đây là cách thực tế để thử nghiệm GGUF đầy đủ của DeepSeek V4 Flash cục bộ.
Dự án llama.cpp upstream cũng có yêu cầu hỗ trợ mô hình mở cho DeepSeek V4, cho thấy hỗ trợ chính thức vẫn đang được triển khai thay vì đã hợp nhất hoàn toàn vào dự án chính.
Chuyển vào thư mục workspace:
cd /workspaceClone kho mã đã chỉnh sửa:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Bây giờ cấu hình build bằng CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseThiết lập này bật hỗ trợ CUDA để mô hình có thể dùng tăng tốc GPU.
Build các binary cần thiết:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitSau khi build xong, sao chép các binary vào thư mục dự án chính:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Cuối cùng, kiểm tra binary server hoạt động:
llama.cpp-deepseek-v4/llama-server --helpNếu menu trợ giúp xuất hiện, quá trình build đã thành công.
Tiếp theo, cài đặt công cụ tải xuống của Hugging Face. Đây là lúc HF_TOKEN bạn đã thêm trước đó trở nên quan trọng. Vì đây là tệp mô hình lớn, đăng nhập bằng token Hugging Face giúp cải thiện độ ổn định tải xuống và cho phép dùng các phương thức tải nhanh hơn.
Cài đặt các gói cần thiết:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferBật tính năng tải nhanh của Hugging Face:
export HF_HUB_ENABLE_HF_TRANSFER=1Tạo thư mục cho mô hình:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Tải tệp mô hình GGUF:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Với hf_transfer được bật và HF_TOKEN đã được thiết lập sẵn trong môi trường RunPod, tốc độ tải mô hình có thể đạt rất cao.
Trong thiết lập này, tốc độ tải đạt gần 2 GB mỗi giây, giúp việc tải tệp GGUF lớn thực tế hơn nhiều. Tốc độ này chỉ khả thi khi token Hugging Face của bạn được cấu hình đúng và pod có thể xác thực với Hugging Face.

Khi tải xong, hãy kiểm tra tệp:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Bạn sẽ thấy một tệp tương tự như sau:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufGiờ đây, khi mô hình đã được tải xuống và bản dựng llama.cpp đã sẵn sàng, bước tiếp theo là khởi chạy máy chủ suy luận cục bộ để bạn có thể truy cập DeepSeek V4 Flash qua Web UI trên trình duyệt và qua endpoint API.
Chuyển vào thư mục llama.cpp:
cd /workspace/llama.cpp-deepseek-v4Khởi động máy chủ mô hình:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfLệnh này tải mô hình GGUF, mở máy chủ tại 0.0.0.0:8910, áp dụng mẫu chat Jinja, dùng --fit on để nhét mô hình vào bộ nhớ GPU và hệ thống hiện có, đặt cửa sổ ngữ cảnh 32K, bật batching thân thiện với CUDA và Flash Attention để tăng tốc suy luận, và bật ghi log chỉ số cùng hiệu năng để bạn theo dõi quá trình chạy.
Mô hình có thể mất ít nhất một phút để nạp vào bộ nhớ GPU và CPU.

Khi máy chủ sẵn sàng, bạn sẽ thấy thông báo “listening on http://0.0.0.0:8910”.

Điều này có nghĩa là máy chủ mô hình đang chạy và đã sẵn sàng nhận yêu cầu.
Quay lại bảng điều khiển RunPod của bạn. Tìm cổng mở 8910, rồi nhấp vào liên kết cổng.
Thao tác này sẽ mở Web UI của llama.cpp trong trình duyệt. Giao diện trông giống một giao diện chat kiểu ChatGPT cơ bản.
Khi trang mở, mô hình sẽ được nạp sẵn. Bạn có thể bắt đầu trò chuyện trực tiếp từ trình duyệt.
Sau khi máy chủ chạy, bạn có thể kiểm thử mô hình bằng nhiều loại prompt khác nhau.
Mục tiêu là kiểm tra mức độ hiệu quả của mô hình với:
Dùng prompt sau:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
Trong bài kiểm thử này, mô hình tạo trang HTML trong khoảng 2 phút, một thời gian hợp lý.
Để xem trước trang đã tạo, tìm biểu tượng con mắt gần phần mã trong Web UI. Nhấp vào đó để mở trang web đã render.
Trang hoạt động, nhưng chất lượng thị giác không ấn tượng. Bố cục ổn nhưng thiết kế khá cơ bản. Các mô hình nhỏ hơn đôi khi cho ra giao diện frontend chỉn chu hơn, nên kết quả này chưa thuyết phục cho tác vụ tạo UI.
Tiếp theo, kiểm thử khả năng viết của mô hình.
Dùng prompt này:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Mô hình tạo ra một báo cáo rõ ràng và có cấu trúc tốt. Nội dung giải thích ý chính đơn giản và có ví dụ hữu ích về sử dụng công cụ, lập kế hoạch, bộ nhớ, phản tư và tự động hoá trong kinh doanh.
Tuy nhiên, một vài chỗ cảm giác hơi chung chung và mang tính quảng bá, nhất là gần phần kết. Ngoài ra có vài lỗi định dạng và chính tả, như bôi đậm không nhất quán và lỗi từ ngữ như “Mainate Context.”
Giờ hãy kiểm tra khả năng lý luận của mô hình với một bài toán đại số đơn giản.
Dùng prompt sau:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Mô hình giải đúng bài toán.
Mô hình định nghĩa biến đúng, lập phương trình chính xác, thế giá trị đúng và kiểm tra đáp án cuối.
Đáp án chính xác là:
Dưới dạng thập phân, xấp xỉ:
Các giá trị cộng lại chính xác bằng tổng $156.
Cuối cùng, kiểm tra xem mô hình có thể tạo một dự án lập trình thân thiện cho người mới bắt đầu hay không.
Dùng prompt sau:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
Phản hồi ban đầu có vẻ đầy đủ và cấu trúc dự án hợp lý. Tuy nhiên, mã sinh ra có vài vấn đề nghiêm trọng.
Kết quả bao gồm:
Với một dự án thân thiện cho người mới, đây là vấn đề lớn. Người mới nên có thể sao chép, chạy và hiểu mã với ít chỉnh sửa nhất. Trong trường hợp này, dự án sinh ra cần gỡ lỗi đáng kể trước khi có thể dùng được.
Sau khi kiểm thử DeepSeek V4 Flash ở các tác vụ tạo UI, viết, lý luận và tạo dự án, mô hình cho kết quả lẫn lộn.
Mô hình thể hiện tốt ở suy luận có cấu trúc và viết giải thích cơ bản. Nó cũng có thể tạo đầu ra nhanh qua Web UI của llama.cpp.
Tuy nhiên, mô hình gặp khó với thiết kế frontend chỉn chu và tạo mã dự án hoàn chỉnh đáng tin cậy. Dự án Python trông có vẻ đủ nhưng chứa quá nhiều lỗi cú pháp và đặt tên để có thể dùng mà không gỡ lỗi thủ công.
|
Nhiệm vụ |
Hiệu năng |
|
Tạo UI |
Trung bình |
|
Viết và giải thích |
Tốt |
|
Lý luận toán |
Mạnh |
|
Tạo dự án hoàn chỉnh |
Yếu |
|
Tốc độ |
Tốt |
|
Độ tin cậy tổng thể |
Lẫn lộn |
Thành thật mà nói, chạy DeepSeek V4 Flash cục bộ là một cơn ác mộng.
Lúc đầu tôi thử chạy trên cấu hình 4x H100 dùng sglang Docker Compose cấu hình, nhưng vẫn thất bại. Sau đó tôi thử chạy với vLLM trên 4x H100 RunPod bằng Python, nhưng cũng thất bại. Lỗi luôn trỏ tới hỗ trợ DeepSeek V4 trong phiên bản transformers mới nhất, dù tôi đã dùng bản mới nhất. Điều này cho thấy hỗ trợ framework phù hợp vẫn chưa đầy đủ.
Ngay cả trang mô hình chính thức trên Hugging Face cũng không cung cấp ví dụ suy luận tiêu chuẩn, đơn giản. Thay vào đó, họ hướng người dùng tới cách dùng torchrun tuỳ chỉnh, nặng nề hơn và tốn nhiều công thiết lập hơn.
Tôi cũng thử các tệp GGUF do cộng đồng cung cấp, nhưng gặp vấn đề tương thích với llama.cpp. Thông thường, tôi thích dùng GGUF của Unsloth vì nhanh, ổn định và dễ chạy, nhưng với DeepSeek V4 Flash, không có con đường plug-and-play đơn giản.
Sau tất cả thử nghiệm, phương pháp trong hướng dẫn này là cách dễ và đáng tin cậy nhất tôi tìm được để chạy toàn bộ mô hình cục bộ. Nó vẫn phụ thuộc vào tệp GGUF của cộng đồng và bản dựng llama.cpp đã chỉnh sửa, nhưng so với các lựa chọn khác, thiết lập này thực sự hoạt động.
Dù vậy, tôi không nghĩ DeepSeek V4 Flash đáng để chạy cục bộ ở thời điểm hiện tại. Thiết lập quá vất vả, hỗ trợ framework còn non và chất lượng đầu ra không xứng đáng với công sức bỏ ra.
Nếu bạn muốn trải nghiệm mô hình cục bộ mượt mà hơn, tôi khuyên thử các mô hình như MiniMax M2.7 hoặc các mô hình lượng tử hoá mạnh như Qwen3.6-27B. Chúng dễ chạy hơn, được hỗ trợ tốt trên các framework lớn, nhanh hơn trong thực tế và thường cho ra kết quả chất lượng cao hơn với ít phiền toái thiết lập.
Các khóa học LLM hàng đầu
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút