
Program
Büyük Dil Modelleri Geliştirme
16 sa
DeepSeek V4 Flash, DeepSeek V4 önizleme serisindeki daha küçük, daha hızlı ve daha maliyet-etkin modeldir. Pratik çıkarım iş yükleri için tasarlanmıştır; DeepSeek V4 Pro’ya göre daha az aktif parametreye ve uzun bağlam görevlerine destek sunar. Bu kılavuzda kullanılan GGUF sürümü, yoğun ağırlıkları FP8’de ve MoE uzman ağırlıklarını FP4’te saklar; bu da özel bir llama.cpp derlemesiyle yerel çıkarım için uygun hale getirir.
Bu kılavuzda, DeepSeek V4 Flash’ı RunPod üzerinde yerel olarak, bir RTX PRO 6000 GPU ve değiştirilmiş bir llama.cpp derlemesi kullanarak çalıştıracağız. GPU pod’unu nasıl kuracağınızı, gerekli bağımlılıkları nasıl yükleyeceğinizi, llama.cpp’yi DeepSeek V4 desteğiyle nasıl derleyeceğinizi, FP4/FP8 GGUF modelini Hugging Face’ten nasıl indireceğinizi ve tarayıcı tabanlı llama.cpp Web UI üzerinden nasıl sunacağınızı öğreneceksiniz.
Başlamadan önce şunlara sahip olduğunuzdan emin olun:
Bir RunPod hesabı
RunPod hesabınızda en az 5 $ bakiye
Linux terminal komutlarına temel düzeyde aşinalık
Bir Hugging Face hesabı
HF_TOKEN olarak kaydedilmiş bir Hugging Face erişim belirteci
Modeli daha hızlı ve daha güvenilir indirmek için Hugging Face belirtecini kullanacaksınız.
Modelin OpenAI’nin tescilli rakipleriyle nasıl karşılaştığını görmek isterseniz, DeepSeek V4 Flash vs GPT-5.4 Mini ve Nano karşılaştırma kılavuzumuzu okumanızı öneririm.
Öncelikle, RunPod üzerinde yeni bir GPU pod’u oluşturun.
Bu kılavuz için RTX PRO 6000 GPU kullanıyoruz; çünkü 96 GB VRAM’i H100’e göre çok daha düşük maliyetle sunuyor. Bu da, tam DeepSeek V4 Flash modelini tek bir GPU’da H100’ün yüksek fiyatını ödemeden çalıştırmak için pratik bir seçenek haline getiriyor.
RunPod kontrol panelinde bir RTX PRO 6000 GPU pod’u seçin ve taban imaj olarak en güncel PyTorch şablonunu kullanın.
Pod’u dağıtmadan önce, şablon ayarlarını düzenleyin ve depolama, yayınlanan port ve ortam değişkenlerini yapılandırın.
Aşağıdaki önerilen kurulumu kullanın:
|
Ayar |
Önerilen Değer |
|
GPU |
RTX PRO 6000 |
|
Konteyner Diski |
50 GB |
|
Birim (Volume) Diski |
300 GB |
|
Yayınlanan Port |
8910 |
|
Şablon |
En güncel PyTorch şablonu |
|
Ortam Değişkeni |
|
Yayınlanan 8910 portu önemlidir; çünkü tarayıcınızdan llama.cpp Web UI’a erişmek için bu portu kullanacaksınız.
Pod dağıtıldıktan sonra, RunPod kontrol panelinin JupyterLab bağlantısını göstermesi için birkaç saniye bekleyin.
JupyterLab’i açın ve bir terminal başlatın. GPU’nun kullanılabilir olduğunu doğrulamak için şunu çalıştırın:
nvidia-smi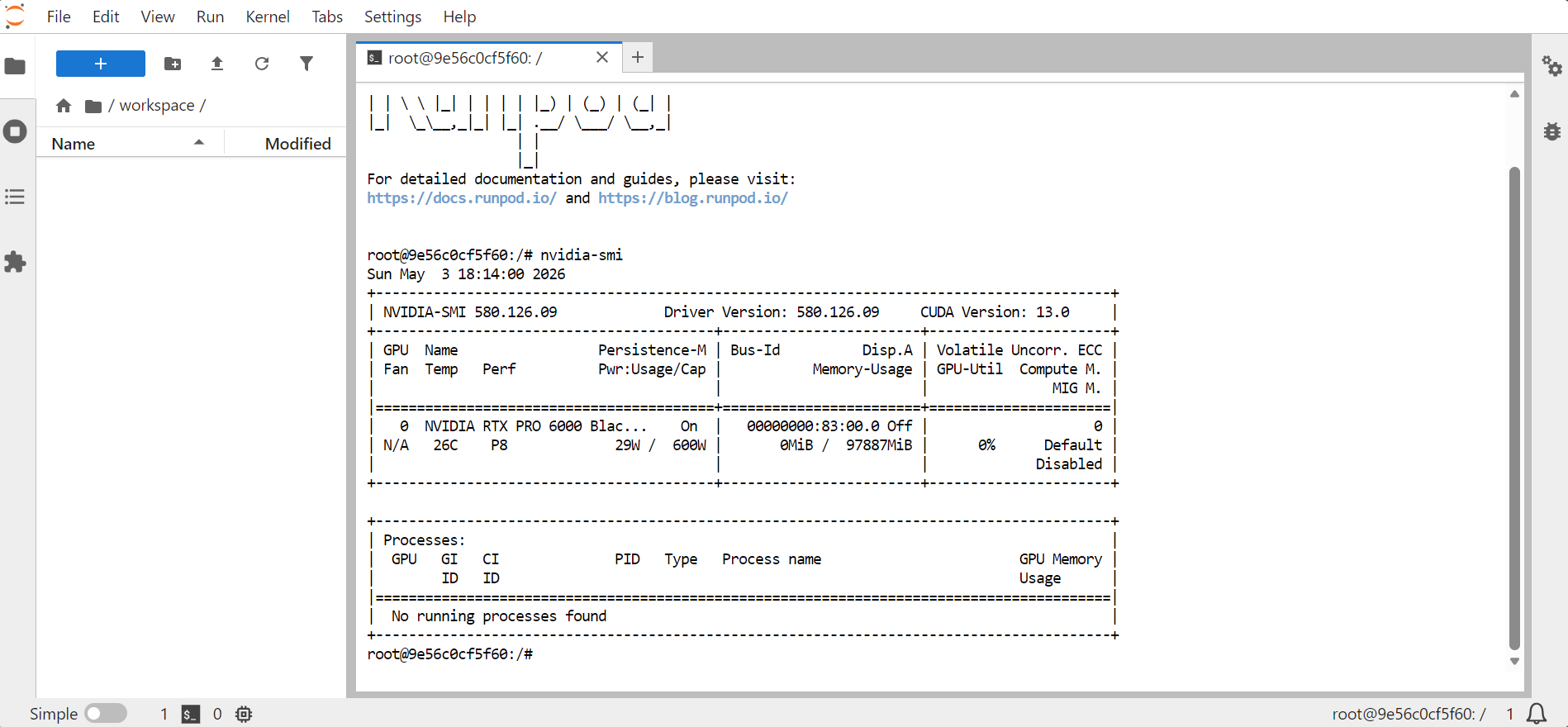
Bu, GPU, bellek, CUDA sürümü ve sürücü sürümü hakkında bilgiler göstermelidir.
Sonraki adımda, llama.cpp’yi derlemek ve çalıştırmak için gereken sistem bağımlılıklarını yükleyin.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvBu paketler; derleme araçları, CMake, Git, Python ve llama.cpp’yi kaynaktan derlemek için gereken diğer yardımcı programları içerir.
DeepSeek V4 Flash hâlâ çok yeni; bu nedenle yerel destek, daha eski modellere kıyasla o kadar doğrudan değildir. Yazım anı itibarıyla, tam modeli standart yukarı akış llama.cpp üzerinden çalıştırmak için, Unsloth gibi büyük topluluk sağlayıcılarından yaygın olarak benimsenmiş resmi bir GGUF sürümü bulunmuyor.
Resmi DeepSeek V4 Flash modeli Hugging Face’te mevcut; ancak yerel GGUF yolu hâlâ topluluk dönüştürmelerine ve deneysel çalışma zamanı desteğine bağlı. Bu kılavuzda kullanılan GGUF, stok yukarı akış llama.cpp’nin bunu yükleyemediğini ve DeepSeek V4 Flash mimari desteği, yerel FP8 ve MXFP4 desteği olan devam etmekte olan bir derleme gerektirdiğini açıkça belirtiyor.
Bu nedenle, bu kurulum standart yukarı akış sürümü yerine bir açık kaynak katılımcısının değiştirilmiş llama.cpp dalını kullanır. Şu anda, tam DeepSeek V4 Flash GGUF’yi yerelde test etmek için pratik yol budur.
Yukarı akış llama.cpp projesinde, DeepSeek V4 desteği için açık bir model isteği de bulunuyor; bu da resmi desteğin hâlâ ana projeye tam olarak birleştirilmek yerine üzerinde çalışıldığını gösteriyor.
Çalışma alanı dizinine geçin:
cd /workspaceDeğiştirilmiş depoyu klonlayın:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Şimdi CMake ile derlemeyi yapılandırın:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseBu, CUDA desteğini etkinleştirir; böylece model GPU hızlandırmasını kullanabilir.
Gerekli ikilileri (binary) derleyin:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitDerleme tamamlandıktan sonra ikilileri ana proje klasörüne kopyalayın:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Son olarak, sunucu ikilisinin çalıştığını kontrol edin:
llama.cpp-deepseek-v4/llama-server --helpYardım menüsü görünürse derleme başarılı olmuştur.
Şimdi Hugging Face indirme araçlarını yükleyin. Daha önce eklediğiniz HF_TOKEN burada önem kazanır. Bu büyük boyutlu bir model dosyası olduğundan, Hugging Face belirteciyle oturum açmak indirme güvenilirliğini artırır ve daha hızlı indirme yöntemlerine erişmenizi sağlar.
Gerekli paketleri yükleyin:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferDaha hızlı Hugging Face indirmelerini etkinleştirin:
export HF_HUB_ENABLE_HF_TRANSFER=1Model için bir klasör oluşturun:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8GGUF model dosyasını indirin:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8hf_transfer etkin ve HF_TOKEN RunPod ortamında önceden ayarlanmış olduğundan, model indirimi çok yüksek hızlara ulaşabilir.
Bu kurulumda indirme hızı neredeyse saniyede 2 GB seviyesine çıktı; bu da büyük bir GGUF dosyasını indirmeyi çok daha pratik hale getiriyor. Bu hız yalnızca Hugging Face belirteciniz doğru şekilde yapılandırılmışsa ve pod, Hugging Face ile kimlik doğrulayabiliyorsa mümkündür.

İndirme tamamlandığında, dosyayı doğrulayın:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Şuna benzer bir dosya görmelisiniz:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufModel indirildiğine ve değiştirilmiş llama.cpp derlemesi hazır olduğuna göre, bir sonraki adım tarayıcı tabanlı Web UI ve API uç noktası üzerinden DeepSeek V4 Flash’a erişebilmeniz için yerel çıkarım sunucusunu başlatmaktır.
llama.cpp dizinine geçin:
cd /workspace/llama.cpp-deepseek-v4Model sunucusunu başlatın:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfBu komut, GGUF modelini yükler, sunucuyu 0.0.0.0:8910 üzerinde yayınlar, Jinja sohbet şablonunu uygular, modeli mevcut GPU ve sistem belleğine sığdırmak için --fit on parametresini kullanır, 32K bağlam penceresi ayarlar, CUDA dostu batch’lemeyi ve Flash Attention’ı daha hızlı çıkarım için etkinleştirir ve çalışmayı izleyebilmeniz için metrikleri ve performans günlüğünü açar.
Modelin GPU ve CPU belleğine yüklenmesi en az bir dakika sürebilir.

Sunucu hazır olduğunda, “http://0.0.0.0:8910 üzerinde dinleniyor” mesajını görmelisiniz.

Bu, model sunucusunun çalıştığı ve istek almaya hazır olduğu anlamına gelir.
RunPod kontrol panelinize geri dönün. Yayınlanan 8910 portunu bulun ve bağlantıya tıklayın.
Bu, tarayıcınızda llama.cpp Web UI’ı açacaktır. Arayüz, temel bir ChatGPT tarzı sohbet arayüzüne benzer görünür.
Sayfa açıldığında modelin hâlihazırda yüklenmiş olması gerekir. Tarayıcıdan doğrudan sohbet etmeye başlayabilirsiniz.
Sunucu çalıştıktan sonra, modeli farklı türde yönlendirmelerle (prompt) test edebilirsiniz.
Amacınız, aşağıdaki alanlardaki performansını kontrol etmektir:
Aşağıdaki yönlendirmeyi kullanın:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
Bu testte model, HTML sayfasını yaklaşık 2 dakikada oluşturdu; bu makul bir süre.
Oluşturulan sayfayı önizlemek için Web UI’daki kod çıktısının yanındaki göz simgesini arayın. İşlenmiş web sayfasını açmak için tıklayın.
Sayfa çalıştı, ancak görsel kalite çok etkileyici değildi. Düzen işlevseldi; fakat tasarım basit kaldı. Daha küçük modeller bazen daha cilalı ön uç çıktıları üretebildiğinden, UI üretimi açısından sonuç beklentinin altındaydı.
Şimdi modelin yazma becerisini test edin.
Şu yönlendirmeyi kullanın:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
Model, net ve iyi yapılandırılmış bir rapor üretti. Ana fikirleri sade bir dille açıkladı ve araç kullanımı, planlama, bellek, yansıtma ve iş otomasyonu üzerine faydalı örnekler sundu.
Bununla birlikte çıktı, özellikle sonuç bölümüne yakın yerlerde biraz genel-geçer ve tanıtım havasında hissettirdi. Ayrıca tutarsız kalın biçimlendirme ve “Mainate Context” gibi yazım hataları dahil çeşitli biçimlendirme ve yazım sorunları vardı.
Şimdi modelin akıl yürütme yeteneğini basit bir cebir problemiyle test edin.
Şu yönlendirmeyi kullanın:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
Model problemi doğru çözdü.
Değişkenleri doğru tanımladı, doğru denklemleri kurdu, değerleri uygun şekilde yerine koydu ve nihai yanıtı kontrol etti.
Tam yanıt şuydu:
Ondalık olarak yaklaşık değerler:
Bu değerler, toplam 156 $’ı doğru şekilde verir.
Son olarak, modelin eksiksiz ve yeni başlayanlara uygun bir kodlama projesi üretip üretemeyeceğini test edin.
Şu yönlendirmeyi kullanın:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
Yanıt ilk bakışta eksiksiz görünüyordu ve proje yapısı mantıklıydı. Ancak, üretilen kodda birkaç ciddi sorun vardı.
Çıktıda şunlar yer aldı:
Yeni başlayanlara uygun bir proje için bu önemli bir sorundur. Başlangıç seviyesindeki birinin kodu minimum düzeltmeyle kopyalayıp çalıştırabilmesi ve anlayabilmesi gerekir. Bu örnekte, üretilen projenin kullanılmadan önce ciddi şekilde hata ayıklanması gerekecektir.
DeepSeek V4 Flash’ı UI üretimi, yazma, akıl yürütme ve proje üretimi üzerinde test ettikten sonra modelin karışık sonuçlar verdiğini gördük.
Yapılandırılmış akıl yürütme ve temel açıklayıcı yazımda iyi performans gösterdi. Ayrıca, llama.cpp Web UI üzerinden çıktıları hızlı şekilde üretebildi.
Bununla birlikte, cilalı bir ön uç tasarımı ve güvenilir tam proje kod üretimi konusunda zorlandı. Python proje çıktısı eksiksiz görünse de, elle hata ayıklama olmadan kullanışlı olmayacak kadar fazla sözdizimi ve adlandırma hatası içeriyordu.
|
Görev |
Performans |
|
UI üretimi |
Orta |
|
Yazma ve açıklama |
İyi |
|
Matematiksel akıl yürütme |
Güçlü |
|
Tam proje üretimi |
Zayıf |
|
Hız |
İyi |
|
Genel güvenilirlik |
Karışık |
DeepSeek V4 Flash’ı yerelde çalıştırmak açıkçası kabustu.
Önce bir sglang Docker Compose yapılandırması kullanarak 4× H100 kurulumunda çalıştırmayı denedim; yine de başarısız oldu. Ardından, vLLM ile 4× H100 RunPod üzerinde Python kullanarak çalıştırmayı denedim; o da başarısız oldu. Hata, en güncel sürümü kullanmama rağmen, transformers’ın en yeni sürümünde DeepSeek V4 desteğine işaret edip durdu. Bu da uygun çatı (framework) desteğinin hâlâ tam olarak mevcut olmadığını netleştirdi.
Resmi Hugging Face model sayfası bile basit, standart bir çıkarım örneği sunmuyor. Bunun yerine, çok daha ağır ve kurulumu daha zahmetli olan bir özel torchrun yaklaşımına yönlendiriyor.
Topluluk tarafından sağlanan GGUF dosyalarını da test ettim; ancak llama.cpp uyumluluk sorunlarıyla karşılaştım. Genellikle, hızlı, güvenilir ve çalıştırması kolay oldukları için Unsloth GGUF dosyalarını tercih ederim; fakat DeepSeek V4 Flash için basit bir tak-çalıştır yolu yoktu.
Tüm bu denemelerden sonra, bu kılavuzda gösterilen yöntem, tam modeli yerelde çalıştırmanın en kolay ve en güvenilir yolu oldu. Hâlâ topluluk GGUF dosyasına ve değiştirilmiş bir llama.cpp derlemesine bağlı; ancak diğer seçeneklerle kıyaslandığında, bu kurulum gerçekten çalıştı.
Bununla birlikte, DeepSeek V4 Flash’ın şu anda yerelde çalıştırılmaya değdiğini düşünmüyorum. Kurulum çok zahmetli, çatı desteği olgunlaşmamış ve çıktı kalitesi çabayı haklı çıkarmıyor.
Daha sorunsuz bir yerel model deneyimi isterseniz, MiniMax M2.7 veya Qwen3.6-27B gibi güçlü niceleme yapılmış modelleri denemenizi öneririm. Bu modeller, çalıştırması daha kolay, büyük çatıların çoğunda daha iyi destekleniyor, pratikte daha hızlı ve çok daha az kurulum sıkıntısıyla çoğu zaman daha yüksek kaliteli sonuçlar üretiyor.
En İyi LLM Kursları
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
