
programa
Desarrollar grandes modelos lingüísticos
16 h
DeepSeek V4 Flash es el modelo más pequeño, rápido y rentable de la serie de vista previa DeepSeek V4. Está diseñado para cargas de inferencia prácticas, con menos parámetros activos que DeepSeek V4 Pro y compatibilidad con tareas de contexto largo. La versión GGUF utilizada en esta guía guarda pesos densos en FP8 y pesos de MoE en FP4, lo que la hace adecuada para inferencia local mediante una build personalizada de llama.cpp.
En esta guía ejecutaremos DeepSeek V4 Flash en local en RunPod usando una GPU RTX PRO 6000 y una build modificada de llama.cpp. Aprenderás a configurar el pod de GPU, instalar las dependencias necesarias, compilar llama.cpp con soporte para DeepSeek V4, descargar el modelo GGUF FP4/FP8 desde Hugging Face y servirlo a través de la interfaz web de llama.cpp en el navegador.
Antes de empezar, asegúrate de tener:
Una cuenta de RunPod
Al menos 5 $ de crédito en RunPod
Conocimientos básicos de comandos de terminal en Linux
Una cuenta de Hugging Face
Un token de acceso de Hugging Face guardado como HF_TOKEN
Usarás el token de Hugging Face para descargar el modelo de forma más rápida y fiable.
Si quieres ver cómo se compara el modelo con sus competidores propietarios de OpenAI, te recomiendo leer nuestra guía de comparación DeepSeek V4 Flash vs GPT-5.4 Mini and Nano.
Primero, crea un nuevo pod de GPU en RunPod.
Para esta guía usamos la GPU RTX PRO 6000 porque ofrece 96 GB de VRAM a un coste mucho menor que una H100. Es una opción práctica para ejecutar el modelo completo DeepSeek V4 Flash en una sola GPU sin pagar el sobreprecio de una H100.
En el panel de RunPod, selecciona un pod con RTX PRO 6000 y usa la plantilla más reciente de PyTorch como imagen base.
Antes de desplegar el pod, edita los ajustes de la plantilla y configura el almacenamiento, el puerto expuesto y las variables de entorno.
Usa la siguiente configuración recomendada:
|
Ajuste |
Valor recomendado |
|
GPU |
RTX PRO 6000 |
|
Disco del contenedor |
50 GB |
|
Disco de volumen |
300 GB |
|
Puerto expuesto |
8910 |
|
Plantilla |
Última plantilla de PyTorch |
|
Variable de entorno |
|
El puerto expuesto 8910 es importante porque será el que uses para acceder a la interfaz web de llama.cpp desde tu navegador.
Cuando el pod esté desplegado, espera unos segundos hasta que el panel de RunPod muestre el enlace de JupyterLab.
Abre JupyterLab y lanza una terminal. Para confirmar que la GPU está disponible, ejecuta:
nvidia-smi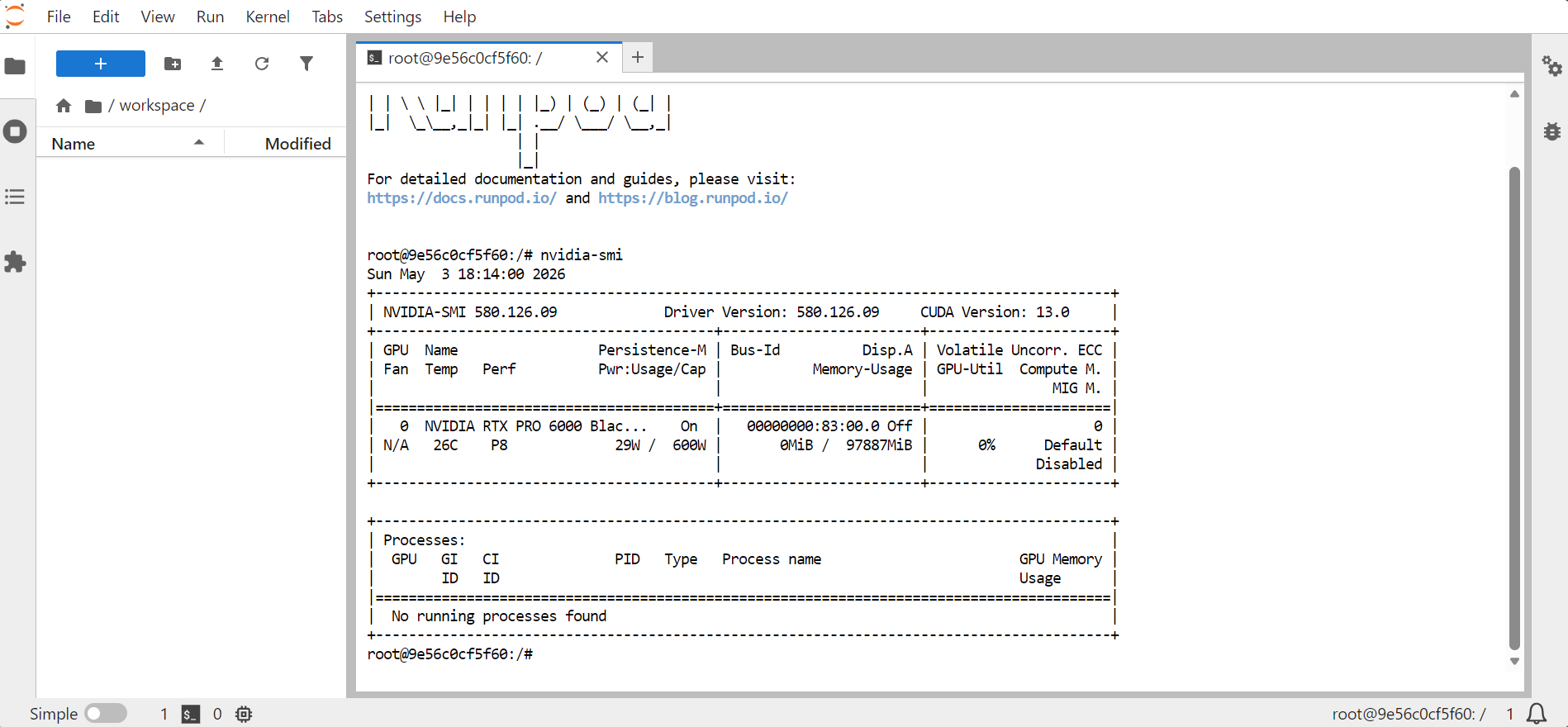
Deberías ver información sobre la GPU, la memoria, la versión de CUDA y la versión del driver.
A continuación, instala las dependencias del sistema necesarias para compilar y ejecutar llama.cpp.
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvEstos paquetes incluyen herramientas de compilación, CMake, Git, Python y otras utilidades necesarias para compilar llama.cpp desde el código fuente.
DeepSeek V4 Flash es muy reciente, así que el soporte local no es tan directo como en modelos anteriores. En el momento de escribir esto, no hay un lanzamiento oficial de GGUF ampliamente adoptado por grandes proveedores de la comunidad como Unsloth para ejecutar el modelo completo con el llama.cpp upstream estándar.
El modelo oficial de DeepSeek V4 Flash está disponible en Hugging Face, pero la ruta local con GGUF aún depende de conversiones de la comunidad y soporte de runtime experimental. El GGUF usado en esta guía indica específicamente que el llama.cpp upstream estándar no puede cargarlo y que requiere una build en desarrollo con soporte de arquitectura DeepSeek V4 Flash y compatibilidad nativa con FP8 y MXFP4.
Por eso, esta configuración utiliza una rama modificada de llama.cpp de un colaborador open-source en lugar de la versión upstream estándar. A día de hoy, es la vía práctica para probar en local el GGUF completo de DeepSeek V4 Flash.
El proyecto llama.cpp upstream también tiene una solicitud de modelo abierta para dar soporte a DeepSeek V4, lo que muestra que el soporte oficial aún se está trabajando y no se ha integrado del todo en el proyecto principal.
Muévete al directorio de trabajo:
cd /workspaceClona el repositorio modificado:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4Ahora configura la build con CMake:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=ReleaseEsto activa el soporte CUDA para que el modelo use aceleración por GPU.
Compila los binarios necesarios:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitCuando termine la compilación, copia los binarios a la carpeta principal del proyecto:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/Por último, comprueba que el binario del servidor funciona:
llama.cpp-deepseek-v4/llama-server --helpSi aparece el menú de ayuda, la build se ha completado correctamente.
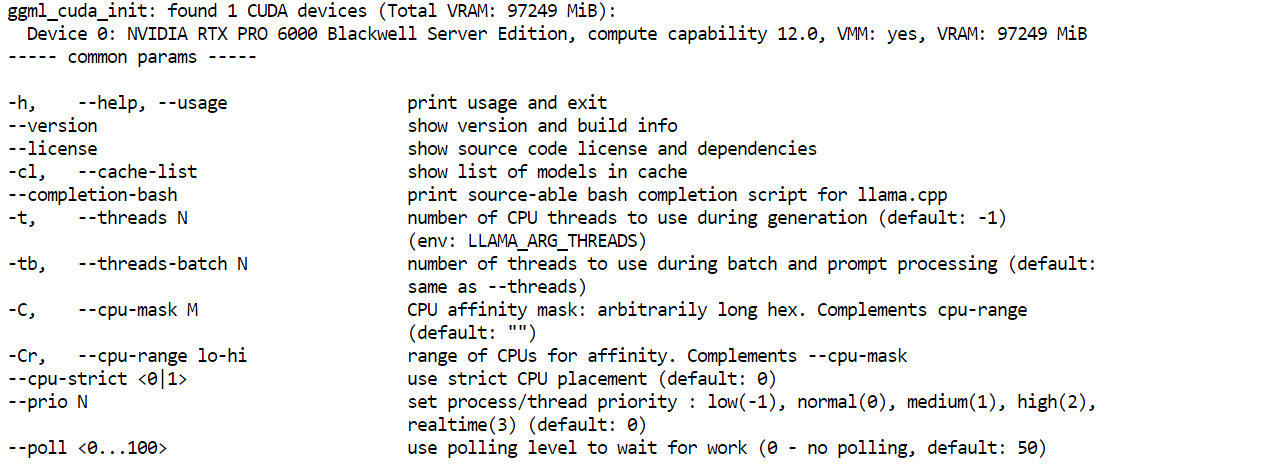
A continuación, instala las herramientas de descarga de Hugging Face. Aquí es donde tu HF_TOKEN cobra importancia. Dado que es un archivo de modelo grande, iniciar sesión con tu token de Hugging Face mejora la fiabilidad de la descarga y te da acceso a métodos más rápidos.
Instala los paquetes necesarios:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferActiva descargas más rápidas desde Hugging Face:
export HF_HUB_ENABLE_HF_TRANSFER=1Crea una carpeta para el modelo:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8Descarga el archivo de modelo GGUF:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8Con hf_transfer activado y tu HF_TOKEN ya configurado en el entorno de RunPod, la descarga del modelo puede alcanzar velocidades muy altas.
En esta configuración, la descarga alcanzó casi 2 GB por segundo, lo que hace que bajar un GGUF grande sea mucho más práctico. Esta velocidad solo es posible si tu token de Hugging Face está bien configurado y el pod puede autenticarse con Hugging Face.

Cuando finalice la descarga, verifica el archivo:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8Deberías ver un archivo similar a este:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufAhora que el modelo está descargado y la build modificada de llama.cpp está lista, el siguiente paso es iniciar el servidor de inferencia local para acceder a DeepSeek V4 Flash desde la interfaz web y el endpoint de la API.
Muévete al directorio de llama.cpp:
cd /workspace/llama.cpp-deepseek-v4Inicia el servidor del modelo:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfEste comando carga el modelo GGUF, expone el servidor en 0.0.0.0:8910, aplica la plantilla de chat Jinja, usa --fit on para ajustar el modelo a la memoria disponible de GPU y sistema, establece una ventana de contexto de 32K, activa el batching compatible con CUDA y Flash Attention para acelerar la inferencia, y habilita métricas y registros de rendimiento para que puedas monitorizar la ejecución.
El modelo puede tardar al menos un minuto en cargarse en la memoria de la GPU y la CPU.

Cuando el servidor esté listo, verás un mensaje indicando que está «listening on http://0.0.0.0:8910».

Esto significa que el servidor del modelo está en ejecución y listo para recibir peticiones.
Vuelve a tu panel de RunPod. Busca el puerto expuesto 8910 y haz clic en el enlace del puerto.
Se abrirá la interfaz web de llama.cpp en tu navegador. La interfaz es similar a un chat básico al estilo ChatGPT.
Cuando se abra la página, el modelo debería estar ya cargado. Puedes empezar a chatear con él directamente desde el navegador.
Con el servidor en marcha, puedes probar el modelo con distintos tipos de prompts.
El objetivo es comprobar qué tal rinde en:
Usa el siguiente prompt:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
En esta prueba, el modelo generó la página HTML en unos 2 minutos, un tiempo razonable.
Para previsualizar la página generada, busca el icono del ojo cerca de la salida de código en la interfaz web. Haz clic para abrir la página renderizada.
La página funcionó, pero la calidad visual no fue especialmente destacable. El layout era funcional, pero el diseño resultaba básico. Modelos más pequeños a veces producen frontends más pulidos, así que el resultado fue algo flojo en generación de UI.
Ahora, prueba la capacidad de redacción del modelo.
Usa este prompt:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
El modelo produjo un informe claro y bien estructurado. Explicó las ideas principales de forma sencilla e incluyó ejemplos útiles sobre uso de herramientas, planificación, memoria, reflexión y automatización en negocios.
Sin embargo, el texto resultaba algo genérico y promocional en algunos pasajes, especialmente hacia la conclusión. También incluía varios problemas de formato y ortografía, como negritas inconsistentes y errores de redacción como «Mainate Context».
Ahora pon a prueba el razonamiento del modelo con un problema sencillo de álgebra.
Usa este prompt:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
El modelo resolvió el problema correctamente.
Definió bien las variables, planteó las ecuaciones correctas, sustituyó valores de forma adecuada y comprobó la respuesta final.
La respuesta exacta fue:
En decimales, aproximadamente:
Los valores suman correctamente el total de 156 $.
Por último, comprueba si el modelo puede generar un proyecto de programación completo para principiantes.
Usa este prompt:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
A primera vista, la respuesta parecía completa y la estructura del proyecto tenía sentido. Sin embargo, el código generado presentaba varios problemas graves.
El resultado incluía:
Para un proyecto para principiantes, esto es un problema serio. Un principiante debería poder copiar, ejecutar y entender el código con ajustes mínimos. En este caso, el proyecto generado necesitaría una depuración considerable antes de poder usarse.
Tras probar DeepSeek V4 Flash en generación de UI, redacción, razonamiento y generación de proyectos, el modelo arrojó resultados dispares.
Rindió bien en razonamiento estructurado y redacción explicativa básica. Además, pudo generar resultados con rapidez desde la Web UI de llama.cpp.
Sin embargo, flojeó en diseño frontend pulido y en generación fiable de código de proyectos completos. La salida del proyecto en Python parecía completa, pero contenía demasiados errores de sintaxis y nombres como para ser útil sin depuración manual.
|
Tarea |
Rendimiento |
|
Generación de UI |
Media |
|
Redacción y explicación |
Buena |
|
Razonamiento matemático |
Sólido |
|
Generación de proyecto completo |
Débil |
|
Velocidad |
Buena |
|
Fiabilidad general |
Mixta |
Ejecutar DeepSeek V4 Flash en local ha sido, sinceramente, un quebradero de cabeza.
Primero intenté ejecutarlo en una configuración con 4× H100 usando sglang y Docker Compose, pero falló. Luego lo probé con vLLM en 4× H100 en RunPod con Python, y también falló. El error apuntaba al soporte de DeepSeek V4 en la última versión de transformers, aunque ya estaba usando la versión más reciente. Quedó claro que el soporte en los frameworks aún no está maduro.
Incluso la página oficial del modelo en Hugging Face no ofrece un ejemplo de inferencia estándar y sencillo. En su lugar, remite a un enfoque personalizado con torchrun, mucho más pesado y laborioso de configurar.
También probé archivos GGUF de la comunidad, pero me encontré con problemas de compatibilidad con llama.cpp. Normalmente prefiero los GGUF de Unsloth porque son rápidos, fiables y fáciles de ejecutar, pero en DeepSeek V4 Flash no había una vía simple de «enchufar y listo».
Después de todas esas pruebas, el método de esta guía fue la forma más sencilla y fiable que encontré para ejecutar el modelo completo en local. Sigue dependiendo de un GGUF de la comunidad y de una build modificada de llama.cpp, pero, comparado con las otras opciones, este montaje funcionó de verdad.
Aun así, no creo que ahora mismo merezca la pena ejecutar DeepSeek V4 Flash en local. La configuración es demasiado engorrosa, el soporte de los frameworks es inmaduro y la calidad de salida no compensa el esfuerzo.
Si quieres una experiencia más fluida con modelos locales, te recomiendo probar modelos como MiniMax M2.7 o modelos cuantizados potentes como Qwen3.6-27B. Son más fáciles de ejecutar, tienen mejor soporte en los principales frameworks, son más rápidos en la práctica y a menudo ofrecen resultados de mayor calidad con mucha menos frustración de configuración.
Los mejores cursos de LLM
programa
Curso
Curso
Tutorial
Dimitri Didmanidze
Tutorial
Arunn Thevapalan
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial

