Track
बड़े भाषा मॉडल विकसित करना
16 घंटा
DeepSeek V4 Flash DeepSeek V4 प्रीव्यू सीरीज़ का छोटा, तेज़ और अधिक किफायती मॉडल है। यह व्यावहारिक इन्फ़रेंस वर्कलोड्स के लिए डिज़ाइन किया गया है, जिसमें DeepSeek V4 Pro की तुलना में कम सक्रिय पैरामीटर्स हैं और लंबी-कॉन्टेक्स्ट टास्क का समर्थन है। इस गाइड में उपयोग किया गया GGUF संस्करण घने वेट्स को FP8 और MoE विशेषज्ञ वेट्स को FP4 में स्टोर करता है, जिससे यह एक कस्टम llama.cpp बिल्ड के ज़रिए लोकल इन्फ़रेंस के लिए उपयुक्त बनता है।
RunPod पर DeepSeek V4 Flash को लोकली चलाएँ—हम RTX PRO 6000 GPU और संशोधित llama.cpp बिल्ड का उपयोग करेंगे। आप सीखेंगे कि GPU पॉड कैसे सेटअप करें, आवश्यक डिपेंडेंसीज़ इंस्टॉल करें, DeepSeek V4 सपोर्ट के साथ llama.cpp को कंपाइल करें, Hugging Face से FP4/FP8 GGUF मॉडल डाउनलोड करें, और इसे ब्राउज़र-आधारित llama.cpp Web UI के माध्यम से सर्व करें।
शुरू करने से पहले, सुनिश्चित करें कि आपके पास ये हैं:
एक RunPod खाता
RunPod क्रेडिट में कम से कम $5
Linux टर्मिनल कमांड्स की बुनियादी जानकारी
एक Hugging Face खाता
HF_TOKEN के रूप में सेव किया गया Hugging Face एक्सेस टोकन
आप मॉडल को तेज़ और अधिक विश्वसनीय तरीके से डाउनलोड करने के लिए Hugging Face टोकन का उपयोग करेंगे।
यदि आप देखना चाहते हैं कि यह मॉडल OpenAI जैसे स्वामित्व वाले प्रतिस्पर्धियों की तुलना में कैसा है, तो हमारा DeepSeek V4 Flash बनाम GPT-5.4 Mini और Nano तुलना गाइड पढ़ने की सलाह देता हूँ।
सबसे पहले, RunPod पर एक नया GPU पॉड बनाएँ।
इस गाइड के लिए, हम RTX PRO 6000 GPU का उपयोग कर रहे हैं क्योंकि यह 96GB VRAM बहुत कम लागत पर प्रदान करता है, H100 की तुलना में। इससे एक सिंगल GPU पर पूरा DeepSeek V4 Flash मॉडल चलाने के लिए यह व्यावहारिक विकल्प बनता है, बिना प्रीमियम H100 कीमत चुकाए।
RunPod डैशबोर्ड में, RTX PRO 6000 GPU पॉड चुनें और बेस इमेज के रूप में नवीनतम PyTorch टेम्पलेट का उपयोग करें।
पॉड को डिप्लॉय करने से पहले, टेम्पलेट सेटिंग्स एडिट करें और स्टोरेज, एक्सपोज़्ड पोर्ट, और एनवायरनमेंट वेरिएबल्स कॉन्फ़िगर करें।
निम्न अनुशंसित सेटअप का उपयोग करें:
|
सेटिंग |
अनुशंसित मान |
|
GPU |
RTX PRO 6000 |
|
कंटेनर डिस्क |
50 GB |
|
वॉल्यूम डिस्क |
300 GB |
|
एक्सपोज़्ड पोर्ट |
8910 |
|
टेम्पलेट |
नवीनतम PyTorch टेम्पलेट |
|
एनवायरनमेंट वेरिएबल |
|
एक्सपोज़्ड पोर्ट 8910 महत्वपूर्ण है क्योंकि इसी पोर्ट का उपयोग आप अपने ब्राउज़र से llama.cpp Web UI एक्सेस करने के लिए करेंगे।
पॉड डिप्लॉय होने के बाद, RunPod डैशबोर्ड में JupyterLab लिंक दिखने के लिए कुछ सेकंड प्रतीक्षा करें।
JupyterLab खोलें, फिर एक टर्मिनल लॉन्च करें। यह जांचने के लिए कि GPU उपलब्ध है, चलाएँ:
nvidia-smi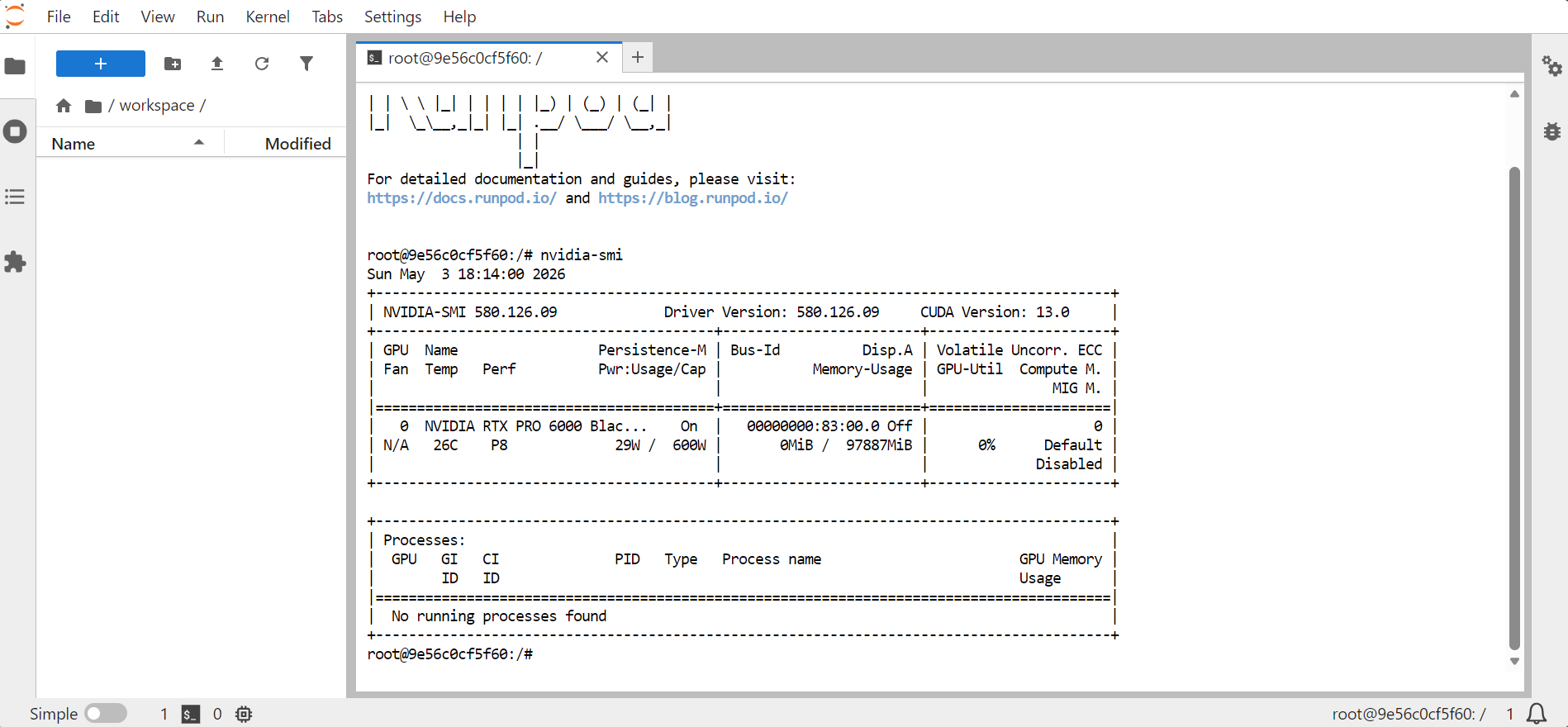
इससे GPU, मेमोरी, CUDA संस्करण और ड्राइवर संस्करण की जानकारी प्रदर्शित होनी चाहिए।
अब llama.cpp को बिल्ड और रन करने के लिए आवश्यक सिस्टम डिपेंडेंसीज़ इंस्टॉल करें।
apt-get update
apt-get install -y \
pciutils \
build-essential \
cmake \
git \
curl \
wget \
libcurl4-openssl-dev \
tmux \
python3 \
python3-pip \
Python3-venvइन पैकेजों में बिल्ड टूल्स, CMake, Git, Python और अन्य यूटिलिटीज़ शामिल हैं, जो स्रोत से llama.cpp को कंपाइल करने के लिए जरूरी हैं।
DeepSeek V4 Flash अभी काफ़ी नया है, इसलिए लोकल सपोर्ट पुराने मॉडलों जितना सीधा नहीं है। लिखते समय, मानक अपस्ट्रीम llama.cpp के ज़रिए पूरा मॉडल चलाने के लिए Unsloth जैसे प्रमुख समुदाय प्रदाताओं की ओर से व्यापक रूप से अपनाया गया आधिकारिक GGUF रिलीज़ उपलब्ध नहीं है।
आधिकारिक DeepSeek V4 Flash मॉडल Hugging Face पर उपलब्ध है, लेकिन लोकल GGUF मार्ग अभी भी सामुदायिक कन्वर्ज़न और प्रायोगिक रनटाइम सपोर्ट पर निर्भर है। इस गाइड में उपयोग किए गए GGUF में स्पष्ट रूप से कहा गया है कि स्टॉक अपस्ट्रीम llama.cpp इसे लोड नहीं कर सकता और DeepSeek V4 Flash आर्किटेक्चर सपोर्ट, नेटिव FP8 और MXFP4 सपोर्ट वाले वर्क-इन-प्रोग्रेस बिल्ड की आवश्यकता है।
इसी कारण, इस सेटअप में मानक अपस्ट्रीम संस्करण के बजाय एक ओपन-सोर्स कंट्रीब्यूटर की संशोधित llama.cpp ब्रांच का उपयोग किया गया है। फिलहाल यही पूरा DeepSeek V4 Flash GGUF लोकली टेस्ट करने का व्यावहारिक तरीका है।
अपस्ट्रीम llama.cpp प्रोजेक्ट में भी DeepSeek V4 सपोर्ट के लिए एक ओपन मॉडल रिक्वेस्ट है, जो दर्शाता है कि आधिकारिक सपोर्ट अभी मुख्य प्रोजेक्ट में पूरी तरह मर्ज नहीं हुआ है और उस पर काम चल रहा है।
वर्कस्पेस डायरेक्टरी में जाएँ:
cd /workspaceसंशोधित रिपॉज़िटरी क्लोन करें:
git clone -b wip/deepseek-v4-support https://github.com/nisparks/llama.cpp.git llama.cpp-deepseek-v4अब CMake का उपयोग करके बिल्ड कॉन्फ़िगर करें:
cmake llama.cpp-deepseek-v4 \
-B llama.cpp-deepseek-v4/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Releaseयह CUDA सपोर्ट सक्षम करता है, ताकि मॉडल GPU एक्सेलरेशन का उपयोग कर सके।
आवश्यक बाइनरी बिल्ड करें:
cmake --build llama.cpp-deepseek-v4/build \
--config Release \
-j \
--clean-first \
--target llama-cli llama-server llama-gguf-splitबिल्ड पूरा होने के बाद, बाइनरीज़ को मुख्य प्रोजेक्ट फ़ोल्डर में कॉपी करें:
cp llama.cpp-deepseek-v4/build/bin/llama-* llama.cpp-deepseek-v4/अंत में, जाँचें कि सर्वर बाइनरी काम कर रही है:
llama.cpp-deepseek-v4/llama-server --helpयदि हेल्प मेनू दिखाई देता है, तो बिल्ड सफल रहा।
अब Hugging Face डाउनलोड टूल्स इंस्टॉल करें। यहीं पहले से जोड़ा गया आपका HF_TOKEN महत्वपूर्ण हो जाता है। चूंकि यह एक बड़ा मॉडल फ़ाइल है, Hugging Face टोकन के साथ लॉगिन करने से डाउनलोड विश्वसनीयता बेहतर होती है और तेज़ तरीकों तक पहुँच मिलती है।
आवश्यक पैकेज इंस्टॉल करें:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferतेज़ Hugging Face डाउनलोड सक्षम करें:
export HF_HUB_ENABLE_HF_TRANSFER=1मॉडल के लिए फ़ोल्डर बनाएँ:
mkdir -p /workspace/models/deepseek-v4-flash-fp4-fp8GGUF मॉडल फ़ाइल डाउनलोड करें:
hf download nsparks/DeepSeek-V4-Flash-FP4-FP8-GGUF \
DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--local-dir /workspace/models/deepseek-v4-flash-fp4-fp8hf_transfer सक्षम होने और RunPod वातावरण में आपका HF_TOKEN पहले से सेट होने पर, मॉडल डाउनलोड बहुत अधिक गति तक पहुंच सकता है।
इस सेटअप में डाउनलोड गति लगभग 2 GB प्रति सेकंड तक पहुँची, जिससे बड़ा GGUF फ़ाइल डाउनलोड करना कहीं अधिक व्यावहारिक हो गया। यह गति तभी संभव है जब आपका Hugging Face टोकन सही तरीके से कॉन्फ़िगर हो और पॉड Hugging Face से प्रमाणित हो सके।

डाउनलोड पूरा होने के बाद, फ़ाइल सत्यापित करें:
ls -lh /workspace/models/deepseek-v4-flash-fp4-fp8आपको इसके समान एक फ़ाइल दिखनी चाहिए:
total 146G
-rw-rw-rw- 1 root root 146G May 3 18:27 DeepSeek-V4-Flash-FP4-FP8-native.ggufअब जब मॉडल डाउनलोड हो चुका है और संशोधित llama.cpp बिल्ड तैयार है, अगला कदम लोकल इन्फ़रेंस सर्वर शुरू करना है ताकि आप ब्राउज़र-आधारित Web UI और API एंडपॉइंट के माध्यम से DeepSeek V4 Flash एक्सेस कर सकें।
llama.cpp डायरेक्टरी में जाएँ:
cd /workspace/llama.cpp-deepseek-v4मॉडल सर्वर शुरू करें:
./llama-server \
--model /workspace/models/deepseek-v4-flash-fp4-fp8/DeepSeek-V4-Flash-FP4-FP8-native.gguf \
--alias "DeepSeek-V4-Flash" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfयह कमांड GGUF मॉडल लोड करता है, सर्वर को 0.0.0.0:8910 पर एक्सपोज़ करता है, Jinja चैट टेम्पलेट लागू करता है, --fit on का उपयोग कर मॉडल को उपलब्ध GPU और सिस्टम मेमोरी में फिट कराता है, 32K कॉन्टेक्स्ट विंडो सेट करता है, CUDA-फ्रेंडली बैचिंग और Flash Attention सक्षम करता है ताकि इन्फ़रेंस तेज़ हो, और रन की मॉनिटरिंग के लिए मेट्रिक्स व परफॉर्मेंस लॉगिंग चालू करता है।
मॉडल को GPU और CPU मेमोरी में लोड होने में कम से कम एक मिनट लग सकता है।

जब सर्वर तैयार हो जाएगा, तो आपको संदेश दिखेगा कि यह “listening on http://0.0.0.0:8910” है।

इसका मतलब है कि मॉडल सर्वर चल रहा है और अनुरोध प्राप्त करने के लिए तैयार है।
अपने RunPod डैशबोर्ड पर वापस जाएँ। एक्सपोज़्ड पोर्ट 8910 ढूँढ़ें, फिर पोर्ट लिंक पर क्लिक करें।
यह आपके ब्राउज़र में llama.cpp Web UI खोलेगा। इंटरफ़ेस एक बुनियादी ChatGPT-स्टाइल चैट इंटरफ़ेस जैसा दिखता है।
पेज खुलने के बाद, मॉडल पहले से लोड होना चाहिए। आप सीधे ब्राउज़र से इससे चैटिंग शुरू कर सकते हैं।
सर्वर चलने के बाद, आप विभिन्न प्रकार के प्रॉम्प्ट्स के साथ मॉडल का परीक्षण कर सकते हैं।
उद्देश्य यह जाँचना है कि यह इन क्षेत्रों में कैसा प्रदर्शन करता है:
निम्न प्रॉम्प्ट का उपयोग करें:
Build a simple, single-screen HTML landing page for a fictional company called NovaGrid AI, with a centered headline, one short paragraph, three feature cards, and a "Get Started" button, using clean modern styling with no scrolling.
इस टेस्ट में, मॉडल ने लगभग 2 मिनट में HTML पेज जनरेट किया, जो उचित समय है।
जनरेटेड पेज का प्रीव्यू देखने के लिए Web UI में कोड आउटपुट के पास आईकन (आंख) देखें। उस पर क्लिक कर रेंडर्ड वेब पेज खोलें।
पेज काम कर रहा था, लेकिन दृश्य गुणवत्ता बहुत प्रभावशाली नहीं थी। लेआउट फ़ंक्शनल था, पर डिज़ाइन बुनियादी लगा। छोटे मॉडल कभी-कभी अधिक पॉलिश्ड फ्रंटएंड आउटपुट देते हैं, इसलिए UI जनरेशन के लिए यह परिणाम निराशाजनक था।
अब मॉडल की लेखन क्षमता का परीक्षण करें।
यह प्रॉम्प्ट उपयोग करें:
Write an 800-word report on Agentic Skills, explaining what they are, why they matter for AI agents, key examples such as tool use, planning, memory, reflection, and task execution, and how they can help businesses automate complex workflows.
मॉडल ने स्पष्ट और सुव्यवस्थित रिपोर्ट तैयार की। इसने मुख्य विचारों को सरल तरीके से समझाया और टूल उपयोग, योजना, मेमोरी, रिफ्लेक्शन और बिज़नेस ऑटोमेशन के उपयोगी उदाहरण शामिल किए।
हालाँकि, आउटपुट कुछ जगहों पर थोड़ा जनरल और प्रमोशनल लगा, विशेषकर निष्कर्ष के पास। इसमें कई फ़ॉर्मैटिंग और स्पेलिंग संबंधी समस्याएँ भी थीं, जैसे असंगत बोल्डिंग और “Mainate Context” जैसी शब्दगत त्रुटियाँ।
अब एक सरल बीजगणित समस्या से मॉडल की तर्क क्षमता का परीक्षण करें।
यह प्रॉम्प्ट उपयोग करें:
Solve the following math problem step by step. Show your reasoning clearly, check your work, and provide the final answer in a boxed format.
Problem:
A small online store sells notebooks and pens. A notebook costs $4 more than a pen. On Monday, the store sold 12 notebooks and 30 pens for a total of $156. What is the price of one notebook and one pen?
मॉडल ने समस्या को सही तरीके से हल किया।
इसने वेरिएबल्स को ठीक से परिभाषित किया, सही समीकरण बनाए, मानों को सही तरीके से प्रतिस्थापित किया, और अंतिम उत्तर की जाँच की।
सटीक उत्तर था:
दशमलव के रूप में, लगभग:
ये मान कुल $156 तक सही जोड़ते हैं।
अंत में, जाँचें कि क्या मॉडल एक पूर्ण, शुरुआती-अनुकूल कोडिंग प्रोजेक्ट जनरेट कर सकता है।
यह प्रॉम्प्ट उपयोग करें:
Create a complete beginner-friendly Python project called Expense Tracker CLI.
Requirements:
- Use only Python standard libraries.
- Create a command-line app where users can add expenses, view all expenses, filter expenses by category, and see the total spending.
- Store expenses in a local JSON file called expenses.json.
- Include a clear file structure.
- Provide the full code for each file.
- Add comments where helpful.
- Include setup instructions and example commands to run the app.
- Keep the code clean, simple, and easy to understand.
प्रतिक्रिया पहली नज़र में पूरी लग रही थी, और प्रोजेक्ट संरचना समझ में आती थी। हालांकि, जनरेटेड कोड में कई गंभीर समस्याएँ थीं।
आउटपुट में शामिल थे:
शुरुआती-अनुकूल प्रोजेक्ट के लिए, यह एक बड़ी समस्या है। शुरुआती उपयोगकर्ता को कोड को न्यूनतम सुधारों के साथ कॉपी, रन और समझ पाने में सक्षम होना चाहिए। इस मामले में, जनरेटेड प्रोजेक्ट उपयोगी होने से पहले पर्याप्त डीबगिंग की मांग करेगा।
UI जनरेशन, लेखन, तर्क और प्रोजेक्ट जनरेशन पर DeepSeek V4 Flash का परीक्षण करने के बाद, मॉडल ने मिश्रित परिणाम दिखाए।
यह संरचित तर्क और बुनियादी व्याख्यात्मक लेखन में अच्छा प्रदर्शन करता है। यह llama.cpp Web UI के माध्यम से तेज़ी से आउटपुट भी जनरेट कर सका।
हालाँकि, पॉलिश्ड फ्रंटएंड डिज़ाइन और भरोसेमंद फुल-प्रोजेक्ट कोड जनरेशन में इसे कठिनाई हुई। Python प्रोजेक्ट आउटपुट पूरा दिखा, लेकिन उसमें इतने सिंटैक्स और नेमिंग एरर थे कि बिना मैनुअल डीबगिंग के उपयोगी नहीं था।
|
कार्य |
प्रदर्शन |
|
UI जनरेशन |
औसत |
|
लेखन और व्याख्या |
अच्छा |
|
गणितीय तर्क |
मजबूत |
|
पूरा प्रोजेक्ट जनरेशन |
कमज़ोर |
|
गति |
अच्छी |
|
समग्र विश्वसनीयता |
मिश्रित |
ईमानदारी से कहूँ तो DeepSeek V4 Flash को लोकली चलाना एक कठिन अनुभव रहा।
मैंने पहले sglang Docker Compose कॉन्फ़िगरेशन का उपयोग करते हुए 4x H100 सेटअप पर इसे चलाने की कोशिश की, लेकिन फिर भी यह असफल रहा। इसके बाद, मैंने Python का उपयोग करते हुए 4x H100 RunPod पर vLLM के साथ चलाने की कोशिश की, पर वह भी विफल रहा। एरर लगातार transformers के नवीनतम संस्करण में DeepSeek V4 सपोर्ट की ओर इशारा करता रहा, जबकि मैं पहले से ही नवीनतम संस्करण उपयोग कर रहा था। इससे स्पष्ट हुआ कि उचित फ़्रेमवर्क सपोर्ट अभी पूरी तरह मौजूद नहीं है।
यहाँ तक कि आधिकारिक Hugging Face मॉडल पेज भी कोई सरल, मानक इन्फ़रेंस उदाहरण प्रदान नहीं करता। इसके बजाय, यह उपयोगकर्ताओं को कस्टम torchrun तरीके की ओर निर्देशित करता है, जो कहीं अधिक भारी है और सेटअप में अधिक मेहनत माँगता है।
मैंने समुदाय द्वारा प्रदान की गई GGUF फ़ाइलों का भी परीक्षण किया, लेकिन llama.cpp संगतता संबंधी समस्याओं का सामना करना पड़ा। आम तौर पर, मैं Unsloth GGUF फ़ाइलें पसंद करता/करती हूँ क्योंकि वे तेज़, विश्वसनीय और चलाने में आसान होती हैं, लेकिन DeepSeek V4 Flash के लिए कोई सरल प्लग-एंड-प्ले रास्ता नहीं था।
इतना सारा परीक्षण करने के बाद, इस गाइड में दिखाया गया तरीका ही मुझे लोकली पूरा मॉडल चलाने का सबसे आसान और विश्वसनीय तरीका लगा। यह अभी भी एक सामुदायिक GGUF फ़ाइल और संशोधित llama.cpp बिल्ड पर निर्भर है, लेकिन अन्य विकल्पों की तुलना में यह सेटअप वास्तव में काम कर गया।
फिर भी, मुझे नहीं लगता कि फिलहाल DeepSeek V4 Flash को लोकली चलाना सार्थक है। सेटअप बहुत कष्टसाध्य है, फ़्रेमवर्क सपोर्ट अभी अपरिपक्व है, और आउटपुट गुणवत्ता इस प्रयास को जायज़ नहीं ठहराती।
यदि आप एक अधिक स्मूद लोकल मॉडल अनुभव चाहते हैं, तो मैं MiniMax M2.7 या मज़बूत क्वांटाइज़्ड मॉडल जैसे Qwen3.6-27B आज़माने की सलाह दूँगा/दूँगी। वे चलाने में आसान हैं, प्रमुख फ़्रेमवर्क्स में बेहतर सपोर्टेड हैं, व्यवहार में तेज़ हैं, और अक्सर बहुत कम सेटअप झंझट के साथ उच्च-गुणवत्ता वाले परिणाम देते हैं।
शीर्ष LLM पाठ्यक्रम
Track
course
course