
Program
Insinyur AI Asisten untuk Ilmuwan Data
40 Hr
GLM-5.2 adalah model terbuka andalan terbaru dari Z.ai, dibuat untuk tugas coding jangka panjang, penalaran, dan rekayasa berbasis agen. Model ini memiliki jendela konteks 1 juta token, beberapa mode berpikir, dukungan pemanggilan alat, serta berbagai peningkatan yang dirancang agar model tetap konsisten di seluruh basis kode besar dan tugas multi-langkah.
Meskipun model penuhnya sangat besar, kuantisasi GGUF memungkinkan Anda menjalankan GLM-5.2 secara lokal menggunakan llama.cpp pada perangkat keras yang tepat.
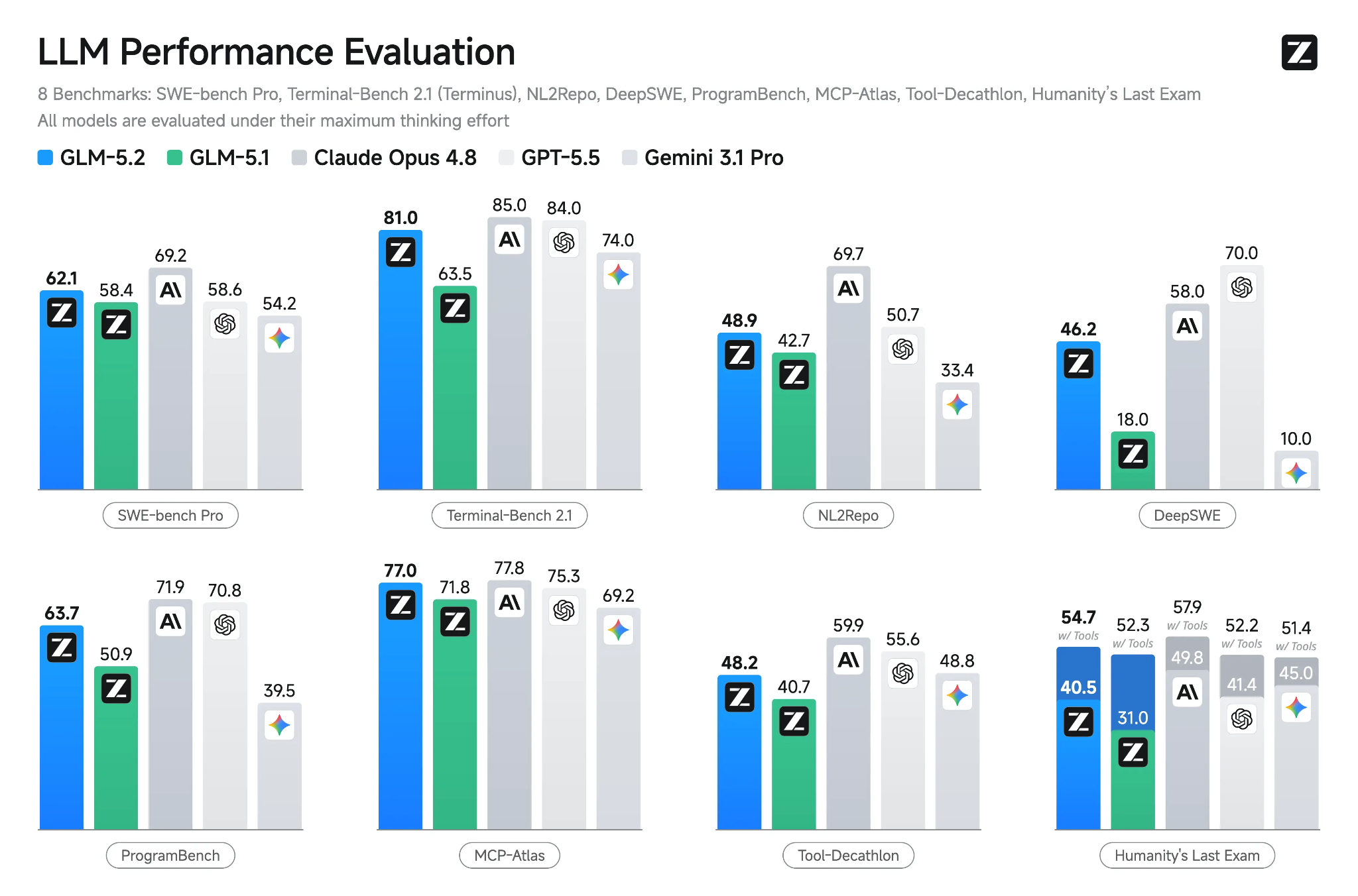
Sumber: GLM-5.2: Built for Long-Horizon Tasks
Dalam panduan ini, saya akan menunjukkan cara memasang paket llama.cpp yang sudah dibangun dan menggunakannya untuk menyajikan GLM-5.2 pada instance GPU RunPod.
Anda akan memulai server dengan kunci API, menguji endpoint kompatibel OpenAI dengan cURL, dan menggunakan Web UI bawaan llama.cpp di browser Anda.
Selanjutnya, Anda akan mengekspos server melalui URL proxy RunPod agar dapat diakses dengan aman dari laptop atau aplikasi lain.
Terakhir, Anda akan menghubungkan server GLM-5.2 yang dihosting tersebut ke OpenCode yang berjalan secara lokal di samping proyek Anda, sehingga OpenCode dapat membaca file, mengedit kode, menjalankan pengujian, dan menggunakan shell lokal Anda sementara GLM-5.2 menangani penalaran dari jarak jauh.
Buka dasbor RunPod Anda dan buat Pod baru. Sebelum meluncurkannya, pastikan akun Anda memiliki setidaknya kredit $25, karena GLM-5.2 memerlukan penyiapan multi-GPU berskala besar.
Pilih mesin dengan 4× RTX PRO 6000 GPU, yang menyediakan:
Sebelum melakukan deploy, edit templat Pod. Tingkatkan ruang disk kontainer menjadi setidaknya 550 GB dan tambahkan hal berikut di bawah Expose HTTP Ports:
8910Port ini akan digunakan nanti untuk server llama.cpp, Web UI, dan API yang kompatibel dengan OpenAI.
Untuk unduhan model yang lebih cepat dan andal, tambahkan token Hugging Face Anda sebagai variabel lingkungan dalam templat:
HF_TOKEN=your_hugging_face_token
Setelah semuanya dikonfigurasi, deploy Pod. Setelah berjalan, klik Connect dan buka JupyterLab. Luncurkan terminal baru dan jalankan:
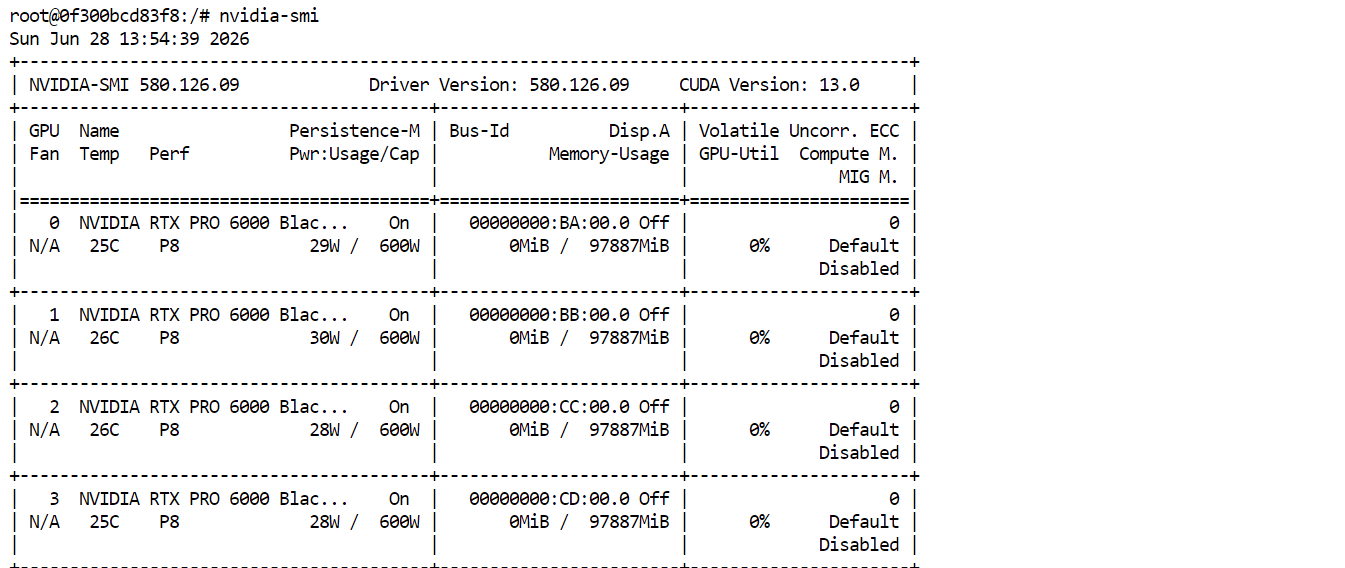
nvidia-smiAnda seharusnya melihat keempat GPU RTX PRO 6000 tercantum dan tersedia. Ini mengonfirmasi bahwa Pod siap mengunduh dan menjalankan GLM-5.2.
Alih-alih mengompilasi llama.cpp dari sumber, pasang versi prebuilt terbaru menggunakan penginstal resmi llama.app. Jalankan perintah berikut di terminal JupyterLab Anda:
curl -LsSf https://llama.app/install.sh | shSelanjutnya, tambahkan folder instalasi llama.cpp ke PATH agar Anda dapat menjalankan perintah llama dari terminal mana pun:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcMuat ulang konfigurasi Bash Anda untuk menerapkan perubahan:
source ~/.bashrcTerakhir, pastikan bahwa llama.cpp terpasang dengan benar:
llama helpAnda akan melihat perintah-perintah yang tersedia di llama.cpp.

Berikutnya, konfigurasikan lokasi persisten untuk file model.
Direktori /workspace milik RunPod tetap tersedia bahkan saat Anda menjeda pod, sehingga menjadi tempat yang lebih baik untuk menyimpan cache Hugging Face dibanding lokasi baku.
Jalankan perintah berikut di terminal JupyterLab:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Ini memastikan bahwa file model yang diunduh disimpan di /workspace/huggingface.
Sekarang buat kunci API untuk server llama.cpp Anda. Gunakan nilai yang panjang dan acak serta simpan secara privat, karena Anda akan memerlukan kunci yang sama nanti saat menguji API dan menghubungkan OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Terakhir, tetapkan alias sederhana untuk model:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode akan menggunakan alias model ini persis nanti, jadi biarkan tidak berubah sepanjang panduan.
Sekarang Anda siap menyalakan server GLM-5.2. Jalankan perintah berikut di terminal yang sama:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaSaat pertama kali menjalankan perintah ini, llama.cpp akan mengunduh kuantisasi GGUF UD-IQ3_S dari GLM-5.2 melalui Hugging Face dan menyimpannya di direktori cache yang Anda konfigurasi sebelumnya.
Unduhan mungkin memakan waktu karena modelnya sangat besar.
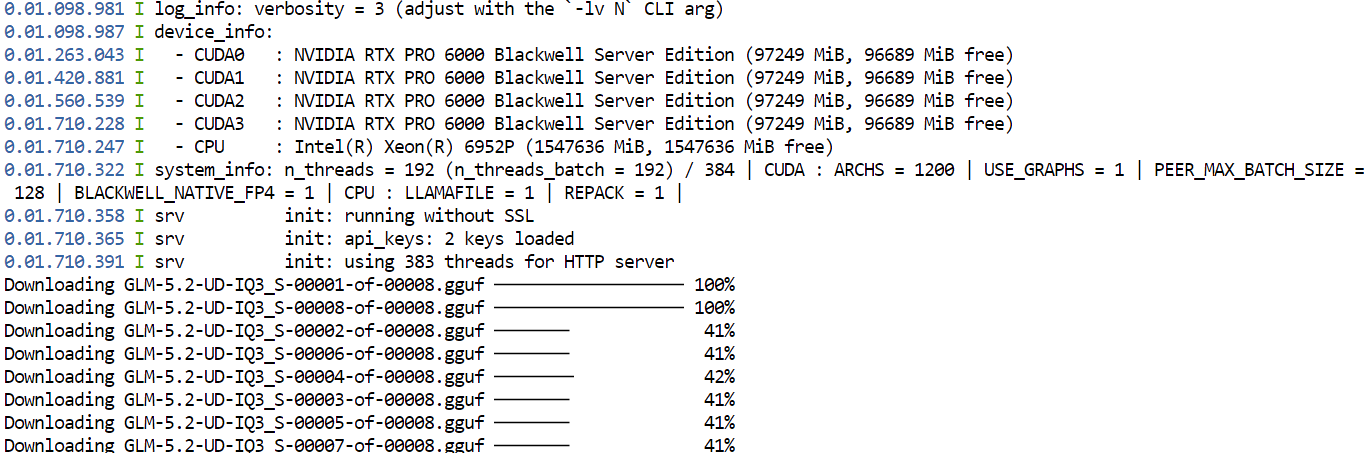
Setelah unduhan selesai, llama.cpp akan memuat model ke semua empat GPU. Pengaturan --split-mode layer dan --tensor-split 1,1,1,1 membagi model secara merata di seluruh GPU yang tersedia, sementara Flash Attention membantu meningkatkan kinerja.
Setelah model berhasil dimuat, server lokal akan tersedia di:
http://127.0.0.1:8910
Server dilindungi oleh kunci API yang Anda tetapkan sebelumnya. Biarkan terminal ini tetap terbuka saat menggunakan model, karena menutupnya akan menghentikan server.
Buka Pod RunPod Anda dan pergi ke tab Connect. Di bawah port HTTP yang diekspos, klik tautan yang terkait dengan port 8910. Ini akan membuka Web UI llama.cpp di browser Anda.
URL akan mengikuti format ini:
https://YOUR_POD_ID-8910.proxy.runpod.netGanti YOUR_POD_ID dengan ID Pod RunPod Anda yang sebenarnya jika Anda perlu memasukkan URL secara manual.
Di Web UI llama.cpp, buka Settings lalu ke General. Tempelkan kunci API yang sama dengan yang Anda gunakan saat menyalakan server llama.cpp.
Ini memungkinkan Web UI mengautentikasi permintaannya dan berkomunikasi dengan server yang terlindungi.
Sekarang Anda dapat menguji model dengan prompt coding sederhana:
Tulislah fungsi Python yang memvalidasi alamat email tanpa paket eksternal.
Sertakan tiga pengujian pytest.
Dalam penyiapan ini, GLM-5.2 menghasilkan sekitar 41 token per detik secara rata-rata, yang merupakan kecepatan baik untuk model sebesar ini.
Kualitas respons juga kuat, menghasilkan implementasi terstruktur dengan aturan validasi dan kasus uji yang jelas.
Buka terminal kedua di JupyterLab. Terminal pertama harus tetap terbuka karena menjalankan server llama.cpp.
Di terminal baru, tetapkan URL API lokal, gunakan kembali kunci API yang sama, dan tetapkan alias model:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Pertama, periksa bahwa server berjalan dan GLM-5.2 tersedia:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Anda akan melihat alias model dalam respons:
glm-5.2-iq3sBerikutnya, kirim permintaan uji ke endpoint chat completions yang kompatibel dengan OpenAI:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
Server akan mengembalikan respons JSON yang berisi jawaban model.
Dalam pengujian ini, GLM-5.2 menghasilkan implementasi Python terstruktur dengan logika validasi dan kasus uji pytest pada kecepatan rata-rata sekitar 41 token per detik.
URL lokal ini hanya berfungsi di dalam Pod RunPod. Untuk memanggil server yang sama dari laptop Anda, OpenCode, atau aplikasi eksternal lain, gunakan URL proxy RunPod sebagai gantinya:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Ganti YOUR_POD_ID dengan ID Pod RunPod Anda yang sebenarnya, dan terus gunakan kunci API yang sama pada header Authorization.
Pasang OpenCode pada komputer tempat proyek kode Anda disimpan. Buka terminal dan jalankan:
curl -fsSL https://opencode.ai/install | bashSelanjutnya, masuk ke folder proyek Anda:
cd /path/to/your/projectEkspor kunci API yang sama dengan yang Anda gunakan saat menyalakan server llama.cpp di RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode berjalan secara lokal di samping proyek Anda, sementara GLM-5.2 tetap berjalan dari jarak jauh pada Pod RunPod Anda. Penyiapan ini memungkinkan OpenCode membaca file Anda, mengedit kode, menjalankan pengujian, dan menggunakan terminal lokal Anda, sementara GLM-5.2 menangani penalaran melalui API RunPod yang diamankan.
Buat file bernama opencode.json di root proyek Anda dan tambahkan konfigurasi berikut:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Ganti YOUR_POD_ID dengan ID Pod RunPod Anda yang sebenarnya. URL harus sama dengan URL proxy RunPod yang Anda gunakan untuk membuka Web UI llama.cpp.
Setelah file opencode.json disimpan, buka terminal di folder proyek yang sama dan jalankan OpenCode:
opencodeLalu jalankan:
/modelsPilih:
GLM-5.2 UD-IQ3_S
OpenCode kini terhubung ke server GLM-5.2 Anda. Ia akan menggunakan model jarak jauh untuk penalaran sembari menjaga file proyek, perintah terminal, pengeditan kode, dan eksekusi pengujian tetap di laptop Anda sendiri.
Mulailah dengan uji sederhana untuk memastikan OpenCode dapat menjangkau server GLM-5.2 Anda dan mengembalikan respons.
Di OpenCode, ketik:
hey
Berikutnya, minta OpenCode untuk meninjau dan menjelaskan proyek Anda yang ada:
Jelaskan proyek dalam 3-5 poin singkat, termasuk tujuannya, teknologi utama,
entry point, dan bagaimana bagian-bagian utamanya bekerja bersama.
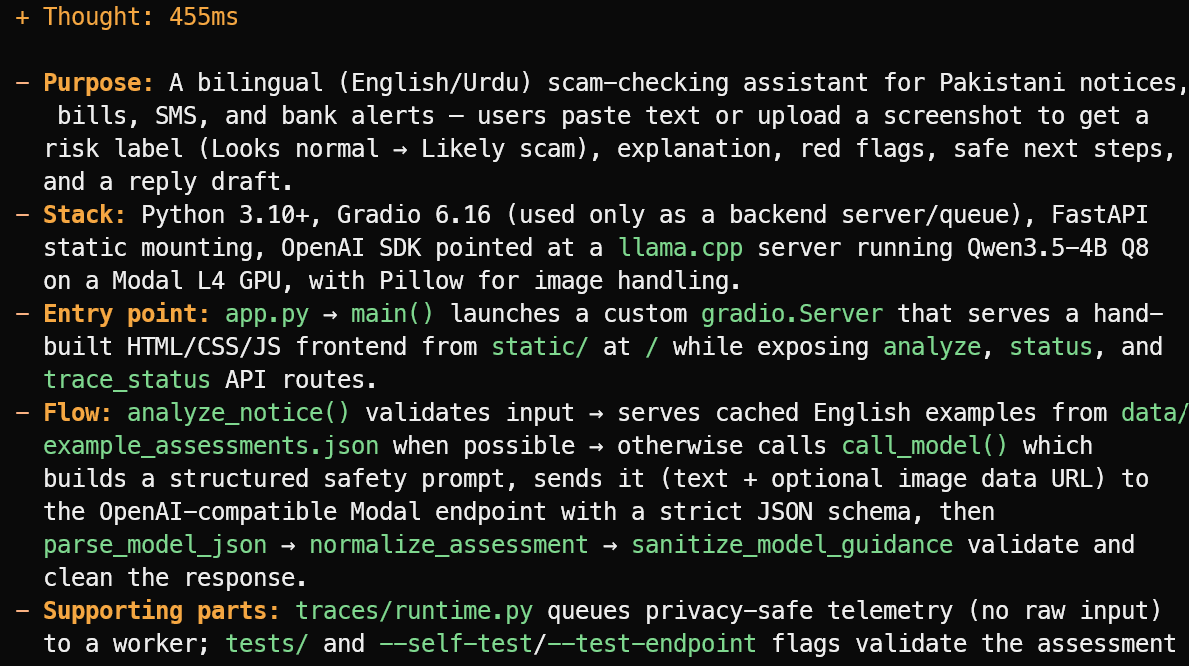
OpenCode membaca file proyek dan memberikan ringkasan singkat alih-alih menebak. Dalam contoh ini, ia secara tepat mengidentifikasi bahwa proyek tersebut adalah asisten pemeriksa penipuan dwibahasa Inggris/Urdu untuk pengumuman, tagihan, pesan SMS, dan peringatan bank di Pakistan.
Ia juga menjelaskan tumpukan utama, app.py sebagai entry point, alur asesmen, serta file uji dan telemetri pendukung.
Prompt:
Sarankan satu fitur baru yang berguna yang sesuai dengan cakupan proyek saat ini.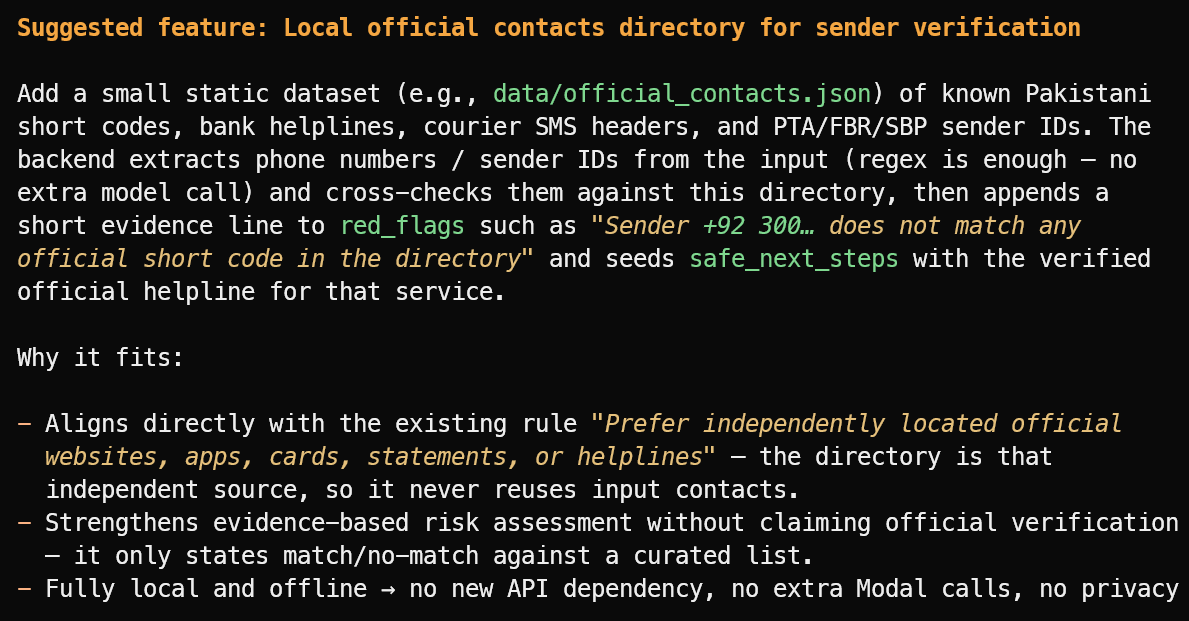
Ia menyarankan fitur yang berguna: direktori lokal berisi ID pengirim resmi terverifikasi, nomor bantuan bank, header kurir, dan short code publik.
Untuk menguji OpenCode pada tugas yang lebih besar, buat folder proyek baru di laptop Anda:
mkdir ml-app
cd ml-app
opencodeLalu berikan prompt berikut ke OpenCode:
Bangun dan uji antarmuka web berbasis Python yang lengkap untuk aplikasi machine learning ini.
OpenCode terlebih dahulu membuat daftar tugas dan memecah proyek menjadi langkah-langkah yang dapat dikelola.
Kemudian ia membuat file aplikasi yang diperlukan, logika machine learning, antarmuka Streamlit, dependensi, dan rangkaian pengujian.
Setelah implementasi selesai, ia menjalankan pengujian, memperbaiki masalah yang ditemukan, dan memberikan ringkasan jelas tentang proyek yang telah selesai beserta perintah yang diperlukan untuk meluncurkannya.
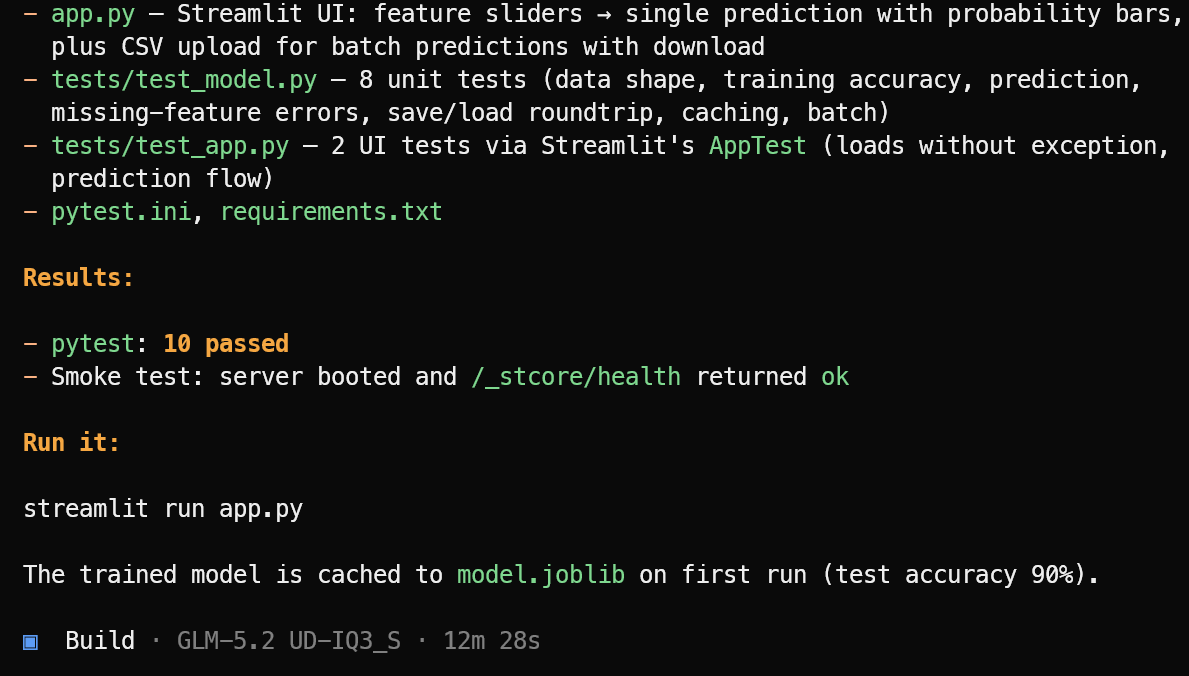
Dalam pengujian ini, OpenCode menyelesaikan 10 pengujian lulus dan memverifikasi bahwa aplikasi Streamlit berhasil diluncurkan. Jalankan aplikasi machine learning dengan:
streamlit run app.pyAplikasi yang dihasilkan tampak rapi dan bekerja sebagaimana mestinya.
Bahkan dengan versi GLM-5.2 yang dikuantisasi 3-bit, kualitas penalarannya tetap kuat dalam pengujian ini.
Model memahami proyek yang ada, mengusulkan fitur yang relevan, membuat aplikasi web lengkap, menggunakan alat untuk meninjau dan memodifikasi file, serta menjalankan pengujian untuk memverifikasi hasil kerjanya.
Penyiapan ini memberi Anda sesuatu yang tidak ditawarkan penyedia API standar: server GLM-5.2 milik Anda sendiri yang dihosting secara privat.
Alih-alih mengirim setiap permintaan ke platform model bersama dengan batas tetap, pengaturan model, dan harga per token, Anda menyewa mesin GPU, melakukan deploy model sendiri, dan mengendalikan seluruh tumpukan serving.
Anda memilih kuantisasi model, konfigurasi GPU, jendela konteks, pengaturan server, kunci API, serta siapa yang dapat mengakses endpoint.
Kode, prompt, konteks proyek, dan respons API tetap berada dalam infrastruktur yang Anda kendalikan: laptop Anda sendiri dan deployment RunPod Anda sendiri.
Mereka tidak dikirim ke penyedia inferensi terhosting tambahan untuk diproses. Ini sangat berguna saat Anda bekerja dengan repositori privat, alat internal, kode sensitif, atau data perusahaan.
Anda juga menghindari biaya dan upaya membeli, menjalankan, serta memelihara server multi-GPU kelas atas sendiri.
Sebagai gantinya, Anda dapat menyewa GPU bertenaga hanya saat diperlukan, menyajikan GLM-5.2 dengan llama.cpp, mengamankan endpoint dengan kunci API Anda sendiri, dan terhubung dari laptop melalui OpenCode.
Dalam panduan ini, Anda mengonfigurasi mesin RunPod multi-GPU, memasang paket llama.cpp prebuilt, mengunduh dan menyajikan model GLM-5.2 GGUF, serta melindungi server dengan kunci API.
Anda kemudian menguji model melalui Web UI llama.cpp dan API cURL yang kompatibel dengan OpenAI sebelum mengekspos URL RunPod yang diamankan untuk akses eksternal.
Terakhir, Anda menghubungkan endpoint model privat tersebut ke OpenCode yang berjalan di laptop Anda. Ini menciptakan alur kerja hibrida yang praktis: GLM-5.2 berjalan pada GPU sewaan yang bertenaga, sementara OpenCode tetap berada di dalam proyek lokal Anda dan dapat meninjau file, mengedit kode, menjalankan pengujian, serta menggunakan shell Anda.
Anda mendapatkan performa model papan atas, fleksibilitas self-hosting, dan kontrol yang jauh lebih besar dibandingkan API terhosting standar.
Kursus Teratas DataCamp
Program
Kursus
Kursus