track
Associate AI Engineer för data scientists
40 timmar
GLM-5.2 är Z.ai:s senaste öppna flaggskeppsmodell, byggd för långsiktig kodning, resonemang och agentiska ingenjörsuppgifter. Den har ett kontextfönster på 1M tokens, flera tänkelägen, stöd för verktygsanrop och förbättringar som hjälper modellen att vara konsekvent över stora kodbaser och flerstegsuppgifter.
Även om fullmodellen är massiv gör GGUF-kvantiseringar det möjligt att köra GLM-5.2 lokalt med llama.cpp på rätt hårdvara.
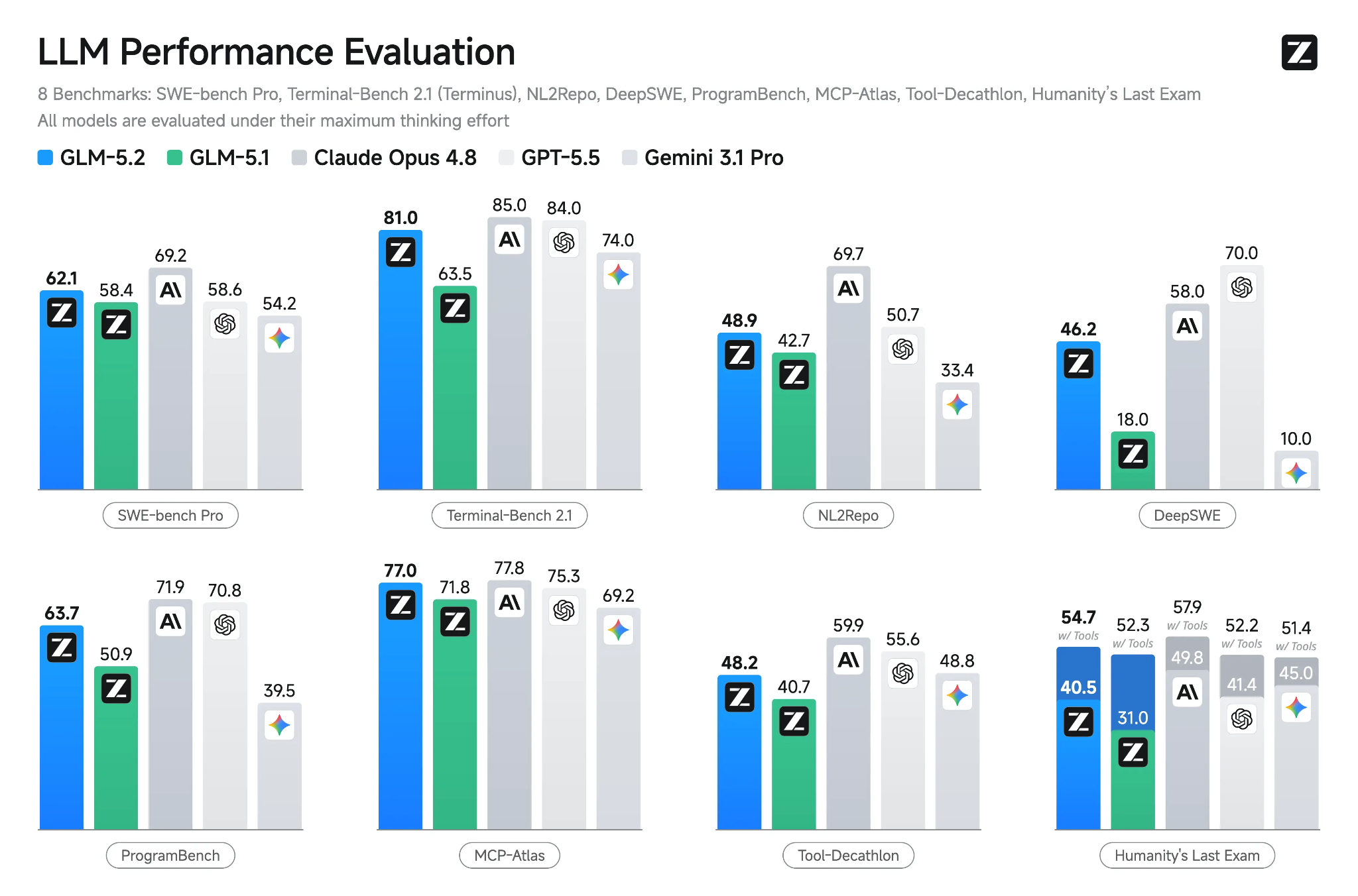
Källa: GLM-5.2: Built for Long-Horizon Tasks
I den här guiden visar jag hur du installerar det förbyggda paketet llama.cpp och använder det för att köra GLM-5.2 på en RunPod GPU-instans.
Du startar servern med en API-nyckel, testar dess OpenAI-kompatibla slutpunkt med cURL och använder llama.cpp:s inbyggda Web UI i din webbläsare.
Därefter exponerar du servern via RunPods proxy-URL så att den kan nås säkert från din laptop eller andra applikationer.
Slutligen kopplar du den hostade GLM-5.2-servern till OpenCode som körs lokalt bredvid ditt projekt, så att OpenCode kan läsa filer, redigera kod, köra tester och använda ditt lokala skal medan GLM-5.2 sköter resonemanget på distans.
Gå till din RunPod-instrumentpanel och skapa en ny Pod. Innan du startar den, se till att ditt konto har minst 25 USD i kredit, eftersom GLM-5.2 kräver en stor multi-GPU-uppsättning.
Välj en maskin med 4× RTX PRO 6000 GPU:er, vilket ger:
Innan distribution, redigera Pod-mallen. Öka containerns diskutrymme till minst 550 GB och lägg till följande under Expose HTTP Ports:
8910Denna port kommer senare att användas för llama.cpp-servern, Web UI och den OpenAI-kompatibla API:n.
För snabbare och mer tillförlitliga modellnedladdningar, lägg till din Hugging Face-token som en miljövariabel i mallen:
HF_TOKEN=your_hugging_face_token
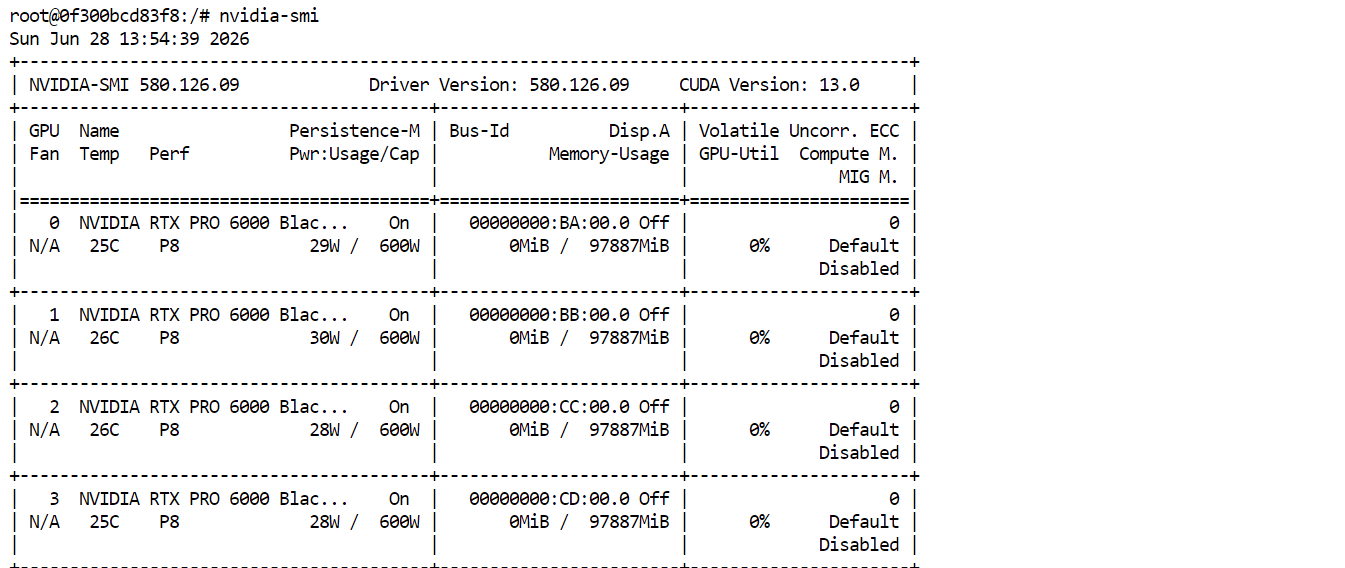
När allt är konfigurerat, distribuera Pod:en. När den startat, klicka på Connect och öppna JupyterLab. Starta en ny terminal och kör:
nvidia-smiDu bör se alla fyra RTX PRO 6000-GPU:er listade och tillgängliga. Detta bekräftar att Pod:en är redo att ladda ner och köra GLM-5.2.
I stället för att kompilera llama.cpp från källkod, installera den senaste förbyggda versionen med den officiella llama.app-installern. Kör följande kommando i din JupyterLab-terminal:
curl -LsSf https://llama.app/install.sh | shLägg sedan till installationsmappen för llama.cpp i din PATH så att du kan köra kommandot llama från valfri terminal:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcLäs in din Bash-konfiguration igen för att tillämpa ändringen:
source ~/.bashrcBekräfta till sist att llama.cpp installerades korrekt:
llama helpDu bör se de tillgängliga kommandona för llama.cpp.

Konfigurera sedan en beständig plats för modellfilerna.
RunPods katalog /workspace finns kvar även när du pausar poden, så det är en bättre plats att spara Hugging Face-cachen på än standardplatsen.
Kör följande kommandon i JupyterLab-terminalen:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Detta säkerställer att nedladdade modellfiler lagras i /workspace/huggingface.
Skapa nu en API-nyckel för din llama.cpp-server. Använd ett långt, slumpmässigt värde och håll det privat, eftersom du behöver samma nyckel senare när du testar API:et och kopplar OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Sätt slutligen ett enkelt alias för modellen:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode kommer att använda just detta modellalias senare, så låt det vara oförändrat genom hela guiden.
Du är nu redo att starta GLM-5.2-servern. Kör följande kommando i samma terminal:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaFörsta gången du kör detta kommando kommer llama.cpp att ladda ner GGUF-kvantiseringen UD-IQ3_S av GLM-5.2 från Hugging Face och spara den i cachekatalogen som du konfigurerade tidigare.
Nedladdningen kan ta tid eftersom modellen är mycket stor.
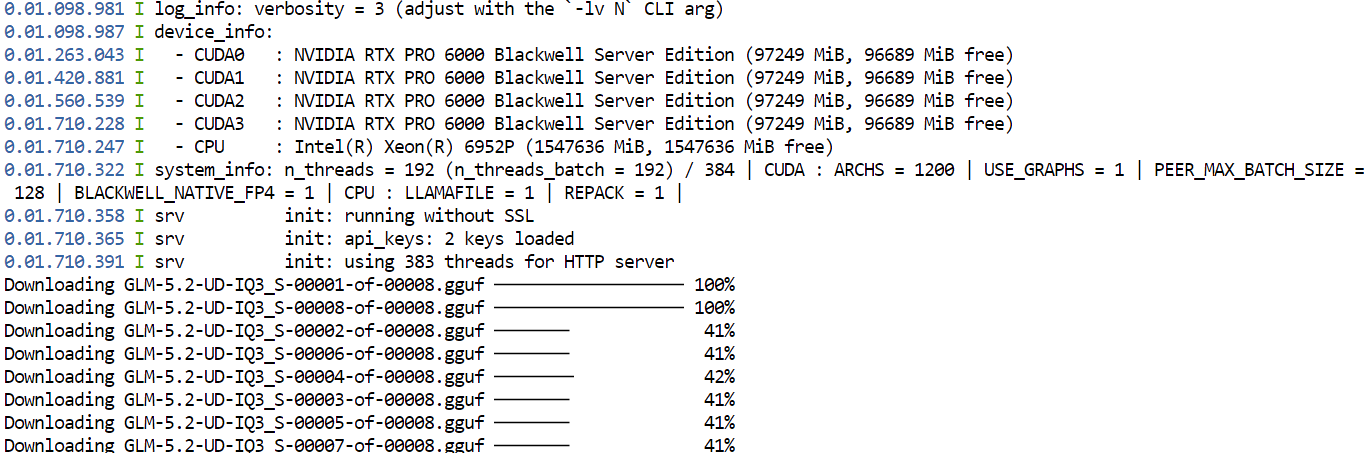
När nedladdningen är klar kommer llama.cpp att ladda modellen över alla fyra GPU:er. Inställningarna --split-mode layer och --tensor-split 1,1,1,1 delar upp modellen jämnt mellan de tillgängliga GPU:erna, medan Flash Attention bidrar till bättre prestanda.
När modellen har laddats framgångsrikt kommer den lokala servern att vara tillgänglig på:
http://127.0.0.1:8910
Servern skyddas av API-nyckeln du satte tidigare. Håll denna terminal öppen medan du använder modellen, eftersom servern stoppas om du stänger den.
Öppna din RunPod Pod och gå till fliken Connect. Under de exponerade HTTP-portarna, klicka på länken som är kopplad till port 8910. Detta öppnar llama.cpp Web UI i din webbläsare.
URL:en följer detta format:
https://YOUR_POD_ID-8910.proxy.runpod.netErsätt YOUR_POD_ID med din faktiska RunPod Pod-ID om du behöver ange URL:en manuellt.
I llama.cpp Web UI, öppna Settings och gå till General. Klistra in samma API-nyckel som du använde när du startade llama.cpp-servern.
Detta gör att Web UI kan autentisera sina förfrågningar och kommunicera med den skyddade servern.
Du kan nu testa modellen med en enkel kodningsprompt:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
I den här uppsättningen genererade GLM-5.2 i genomsnitt 41 tokens per sekund, vilket är en bra hastighet för en modell av denna storlek.
Svarskvaliteten var också stark och gav en strukturerad implementation med tydliga valideringsregler och testfall.
Öppna en andra terminal i JupyterLab. Den första terminalen måste förbli öppen eftersom den kör llama.cpp-servern.
I den nya terminalen, sätt den lokala API-URL:en, återanvänd samma API-nyckel och sätt modellaliaset:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Kontrollera först att servern körs och att GLM-5.2 är tillgänglig:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Du bör se modellaliaset i svaret:
glm-5.2-iq3sSkicka sedan en testrådgivning till den OpenAI-kompatibla chat-completions-slutpunkten:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
Servern kommer att returnera ett JSON-svar som innehåller modellens svar.
I detta test producerade GLM-5.2 en strukturerad Python-implementation med valideringslogik och pytest-testfall med en genomsnittlig genereringshastighet på ungefär 41 tokens per sekund.
Denna lokala URL fungerar bara inne i RunPod Pod:en. För att anropa samma server från din laptop, OpenCode eller en annan extern applikation, använd i stället RunPod-proxy-URL:en:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Ersätt YOUR_POD_ID med din faktiska RunPod Pod-ID och fortsätt använda samma API-nyckel i Authorization-huvudet.
Installera OpenCode på datorn där ditt kodprojekt finns. Öppna en terminal och kör:
curl -fsSL https://opencode.ai/install | bashGå sedan in i din projektmapp:
cd /path/to/your/projectExportera samma API-nyckel som du använde när du startade llama.cpp-servern på RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode körs lokalt bredvid ditt projekt, medan GLM-5.2 fortsätter att köra på distans på din RunPod Pod. Denna uppsättning gör att OpenCode kan läsa dina filer, redigera kod, köra tester och använda din lokala terminal, medan GLM-5.2 hanterar resonemanget via det säkrade RunPod-API:et.
Skapa en fil med namnet opencode.json i projektroten och lägg till följande konfiguration:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Ersätt YOUR_POD_ID med din faktiska RunPod Pod-ID. URL:en måste matcha RunPod-proxy-URL:en som du använde för att öppna llama.cpp Web UI.
När filen opencode.json är sparad, öppna en terminal i samma projektmapp och starta OpenCode:
opencodeKör sedan:
/modelsVälj:
GLM-5.2 UD-IQ3_S
OpenCode är nu anslutet till din GLM-5.2-server. Den använder den fjärrkörande modellen för resonemang, medan projektfiler, terminalkommandon, kodändringar och testkörning sker på din egen laptop.
Börja med ett enkelt test för att bekräfta att OpenCode kan nå din GLM-5.2-server och returnera ett svar.
Skriv i OpenCode:
hey
Be OpenCode därefter att inspektera och förklara ditt befintliga projekt:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
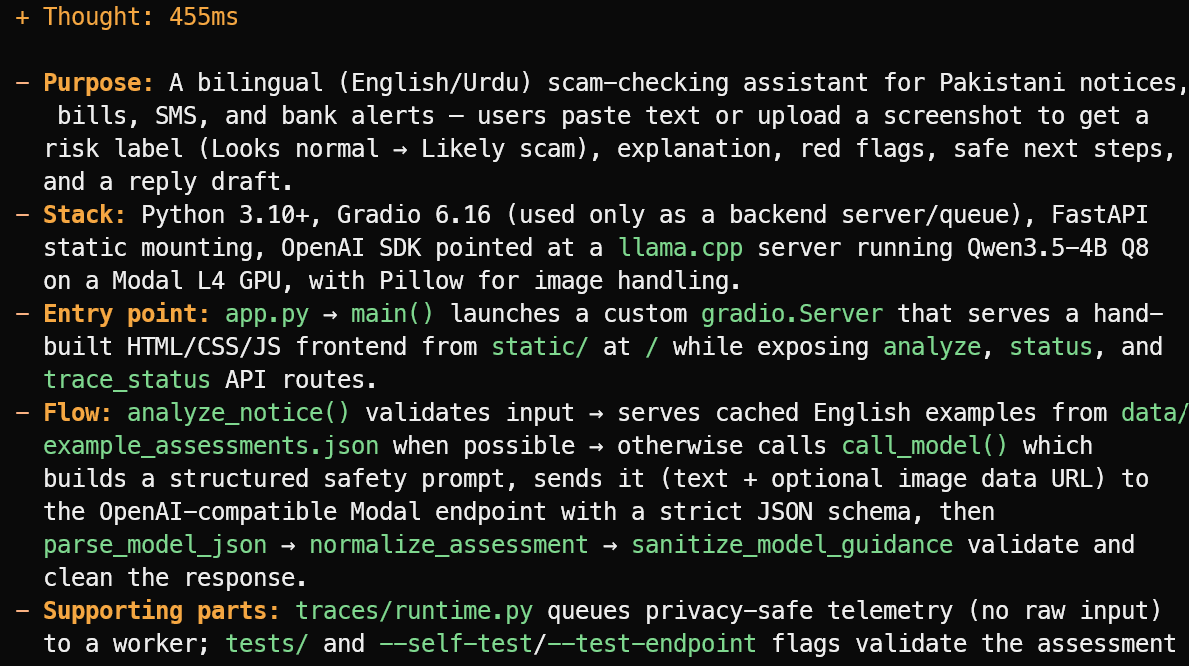
OpenCode läser projektfilerna och ger en kärnfull översikt i stället för att gissa. I detta exempel identifierade det korrekt att projektet är en tvåspråkig engelsk/urdu-bedrägerikontrollassistent för pakistanska meddelanden, räkningar, SMS och bankvarningar.
Det förklarade också huvudstacken, app.py som entrypoint, flödet för bedömning och stödfilerna för testning och telemetri.
Prompt:
Suggest one useful new feature that fits the project's current scope.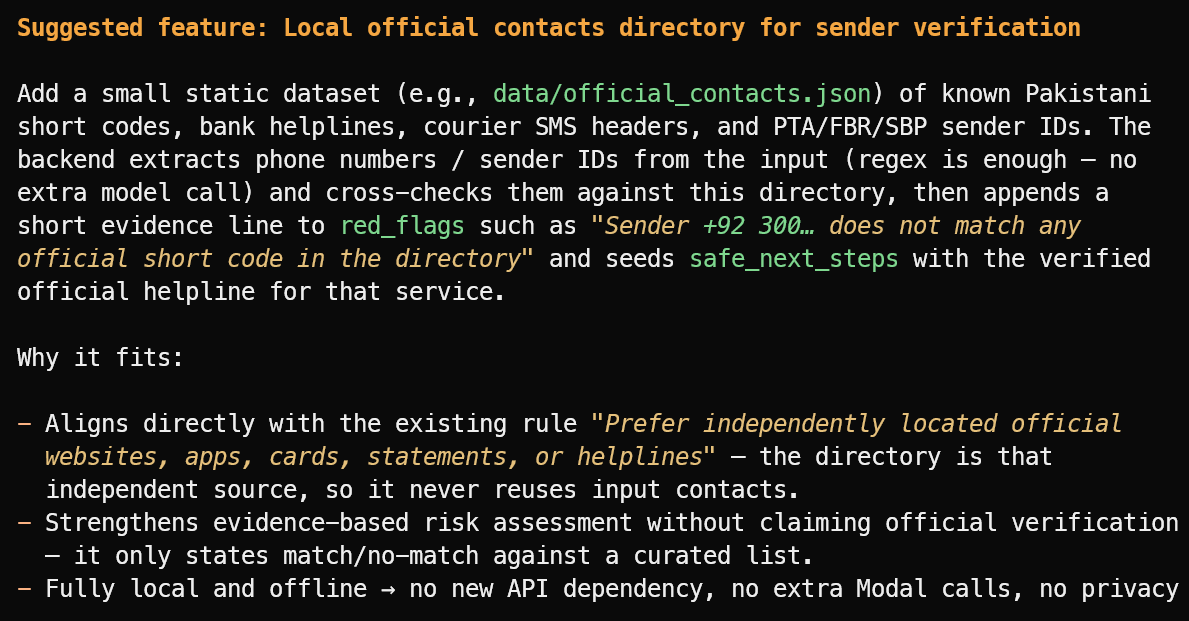
Det föreslog en användbar funktion: ett lokalt register över verifierade officiella avsändar-ID:n, bankernas hjälplinjer, kurirhuvuden och publika kortkoder.
För att testa OpenCode på en större uppgift, skapa en ny projektmapp på din laptop:
mkdir ml-app
cd ml-app
opencodeGe sedan OpenCode följande prompt:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode skapar först en uppgiftslista och delar upp projektet i hanterbara steg.
Det skapar därefter nödvändiga applikationsfiler, maskininlärningslogik, Streamlit-gränssnitt, beroenden och testsvit.
När implementationen är klar körs testerna, eventuella problem åtgärdas och en tydlig sammanfattning av det färdiga projektet ges tillsammans med kommandot som behövs för att starta det.
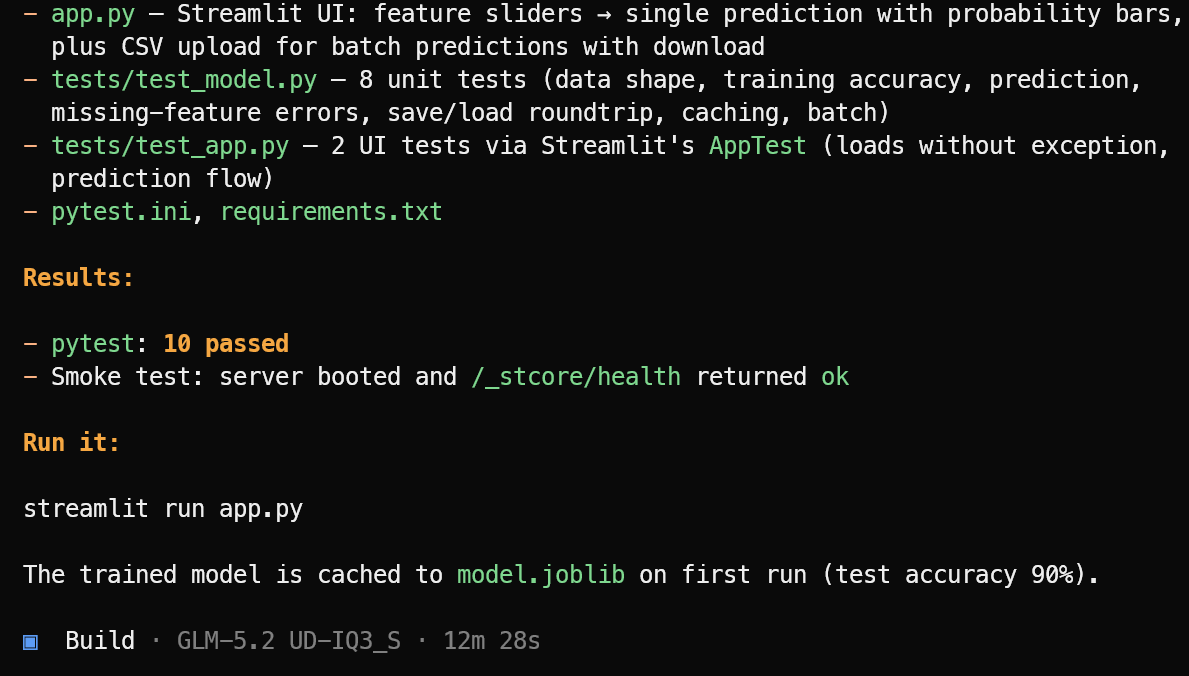
I detta test klarade OpenCode 10 godkända tester och verifierade att Streamlit-applikationen startade korrekt. Starta maskininlärningsapplikationen med:
streamlit run app.pyDen resulterande applikationen ser ren ut och fungerar som förväntat.
Även med den 3-bitars kvantiserade versionen av GLM-5.2 var resonemangskvaliteten stark i dessa tester.
Den förstod det befintliga projektet, föreslog en relevant funktion, skapade en komplett webbapplikation, använde verktyg för att inspektera och modifiera filer och körde tester för att verifiera sitt arbete.
Denna uppsättning ger dig något som vanliga API-leverantörer inte gör: din egen privat hostade GLM-5.2-server.
I stället för att skicka varje förfrågan till en delad modellplattform med fasta begränsningar, modellinställningar och per-token-prissättning hyr du GPU-maskinen, distribuerar modellen själv och kontrollerar hela serverstacken.
Du väljer modellkvantisering, GPU-konfiguration, kontextfönster, serverinställningar, API-nyckel och vem som får åtkomst till slutpunkten.
Din kod, dina prompts, projektkontext och API-svar stannar inom den infrastruktur du kontrollerar: din egen laptop och din egen RunPod-distribution.
De skickas inte till en ytterligare hostad inferensleverantör för bearbetning. Detta är särskilt användbart när du arbetar med privata repos, interna verktyg, känslig kod eller företagsdata.
Du undviker också kostnaden och arbetet med att själv köpa, köra och underhålla en avancerad multi-GPU-server.
I stället kan du hyra kraftfulla GPU:er bara när du behöver dem, serva GLM-5.2 med llama.cpp, säkra slutpunkten med din egen API-nyckel och koppla från din laptop via OpenCode.
I den här guiden konfigurerade du en multi-GPU RunPod-maskin, installerade det förbyggda paketet llama.cpp, laddade ner och servade GLM-5.2 GGUF-modellen och skyddade servern med en API-nyckel.
Du testade sedan modellen via både llama.cpp Web UI och dess OpenAI-kompatibla cURL-API innan du exponerade den säkrade RunPod-URL:en för extern åtkomst.
Slutligen kopplade du den privata modellslutpunkten till OpenCode som körs på din laptop. Det skapar ett praktiskt hybridflöde: GLM-5.2 körs på kraftfulla hyrda GPU:er, medan OpenCode stannar i ditt lokala projekt och kan inspektera filer, redigera kod, köra tester och använda ditt skal.
Du får prestandan hos en toppmodell, flexibiliteten hos självhosting och betydligt mer kontroll än med ett vanligt hostat API.
Toppkurser från DataCamp
track
course
course