Track
Inżynier AI Associate dla Data Scientistów
40 godz.
GLM-5.2 to najnowszy flagowy otwarty model Z.ai, stworzony do zadań programistycznych o długim horyzoncie, rozumowania i agentowego inżynierowania. Oferuje okno kontekstu 1M tokenów, wiele trybów myślenia, obsługę wywoływania narzędzi oraz ulepszenia, które pomagają zachować spójność w dużych bazach kodu i zadaniach wieloetapowych.
Choć pełny model jest ogromny, kwantyzacje GGUF umożliwiają uruchomienie GLM-5.2 lokalnie przy użyciu llama.cpp na odpowiednim sprzęcie.
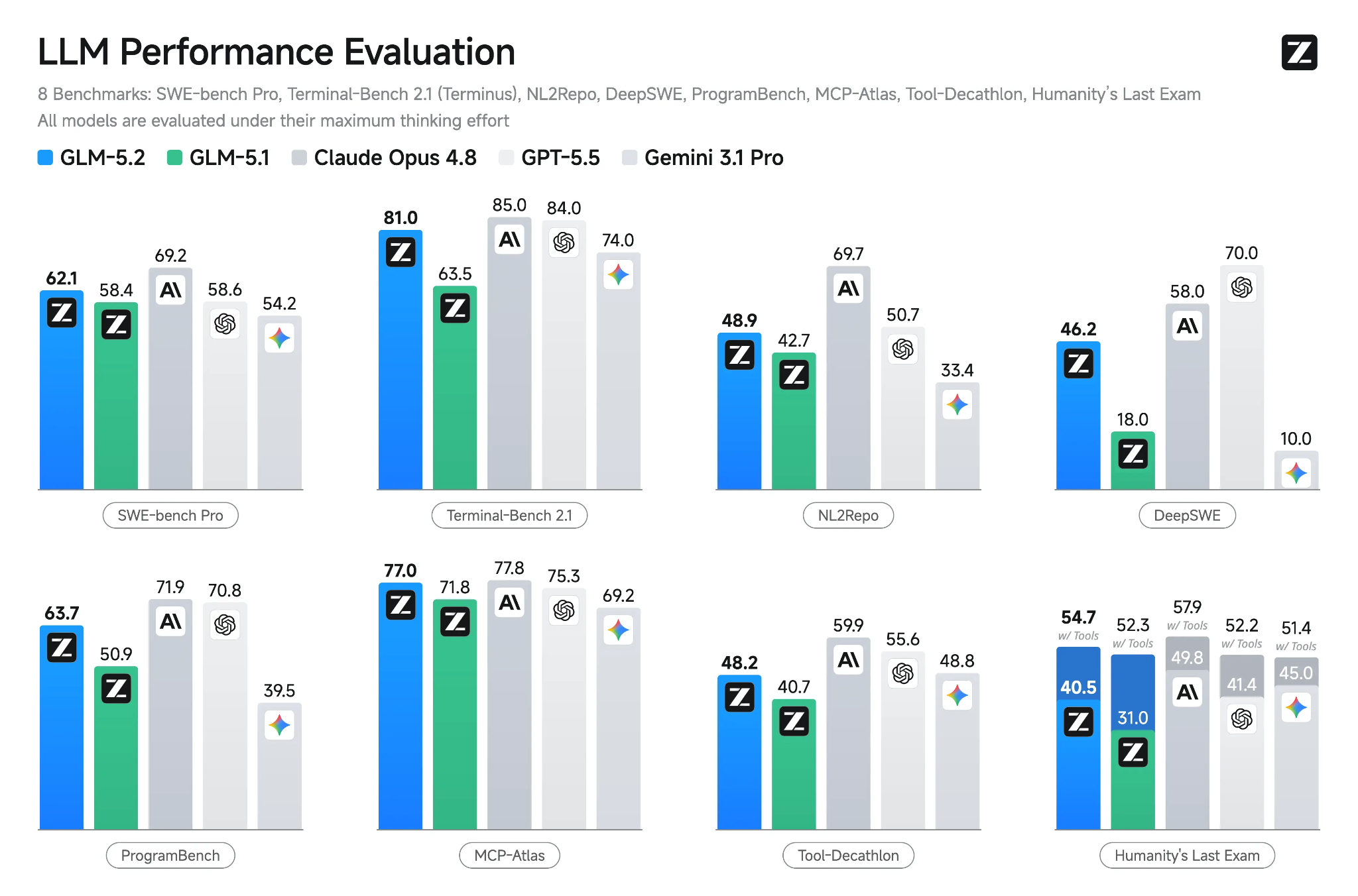
Źródło: GLM-5.2: Built for Long-Horizon Tasks
W tym przewodniku pokażę ci, jak zainstalować prekompilowany pakiet llama.cpp i użyć go do serwowania GLM-5.2 na instancji GPU RunPod.
Uruchomisz serwer z kluczem API, przetestujesz jego punkt końcowy zgodny z OpenAI za pomocą cURL oraz użyjesz wbudowanego Web UI llama.cpp w przeglądarce.
Następnie wystawisz serwer przez adres proxy RunPod, aby można go było bezpiecznie osiągać z twojego laptopa lub innych aplikacji.
Na końcu połączysz ten hostowany serwer GLM-5.2 z OpenCode uruchomionym lokalnie obok twojego projektu, co pozwoli OpenCode czytać pliki, edytować kod, uruchamiać testy i używać lokalnej powłoki, podczas gdy GLM-5.2 będzie wykonywał rozumowanie zdalnie.
Przejdź do swojego panelu RunPod i utwórz nowy Pod. Zanim go uruchomisz, upewnij się, że twoje konto ma co najmniej 25 USD środków, ponieważ GLM-5.2 wymaga dużej konfiguracji z wieloma GPU.
Wybierz maszynę z 4× RTX PRO 6000, co zapewnia:
Przed wdrożeniem edytuj szablon Pod. Zwiększ przestrzeń dyskową kontenera do co najmniej 550 GB i dodaj poniższe w sekcji Expose HTTP Ports:
8910Ten port będzie później używany przez serwer llama.cpp, Web UI i API zgodne z OpenAI.
Dla szybszego i bardziej niezawodnego pobierania modeli dodaj swój token Hugging Face jako zmienną środowiskową w szablonie:
HF_TOKEN=your_hugging_face_token
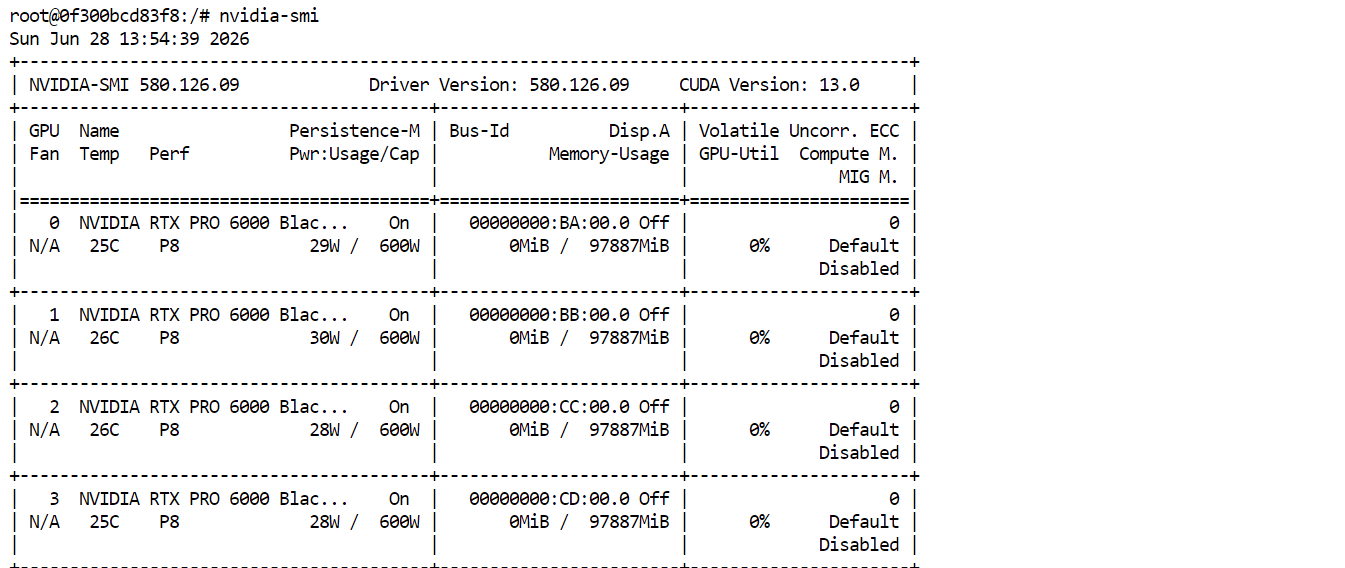
Gdy wszystko skonfigurujesz, wdroż Pod. Po uruchomieniu kliknij Connect i otwórz JupyterLab. Uruchom nowy terminal i wykonaj:
nvidia-smiPowinieneś zobaczyć wszystkie cztery RTX PRO 6000 na liście i dostępne. To potwierdza, że Pod jest gotowy do pobrania i uruchomienia GLM-5.2.
Zamiast kompilować llama.cpp ze źródeł, zainstaluj najnowszą prekompilowaną wersję, używając oficjalnego instalatora llama.app. Uruchom poniższe polecenie w terminalu JupyterLab:
curl -LsSf https://llama.app/install.sh | shNastępnie dodaj folder instalacyjny llama.cpp do swojego PATH, aby móc uruchamiać polecenie llama z dowolnego terminala:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcPrzeładuj konfigurację Basha, aby zastosować zmianę:
source ~/.bashrcNa koniec potwierdź, że llama.cpp zainstalowano poprawnie:
llama helpPowinieneś zobaczyć dostępne polecenia llama.cpp.

Skonfiguruj teraz trwałą lokalizację dla plików modelu.
Katalog /workspace w RunPod pozostaje dostępny nawet po wstrzymaniu poda, więc to lepsze miejsce na przechowywanie pamięci podręcznej Hugging Face niż domyślna lokalizacja.
Uruchom w terminalu JupyterLab następujące polecenia:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"To zapewnia, że pobrane pliki modelu będą przechowywane w /workspace/huggingface.
Teraz utwórz klucz API dla twojego serwera llama.cpp. Użyj długiej, losowej wartości i zachowaj ją w tajemnicy — będziesz potrzebować tego samego klucza później podczas testowania API i łączenia z OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Na koniec ustaw prosty alias dla modelu:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode użyje dokładnie tego aliasu modelu później, więc pozostaw go bez zmian w całym przewodniku.
Jesteś gotów, by uruchomić serwer GLM-5.2. Wykonaj poniższe polecenie w tym samym terminalu:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaPrzy pierwszym uruchomieniu tego polecenia llama.cpp pobierze z Hugging Face kwantyzację GGUF UD-IQ3_S modelu GLM-5.2 i zapisze ją w skonfigurowanym wcześniej katalogu pamięci podręcznej.
Pobieranie może chwilę potrwać, ponieważ model jest bardzo duży.
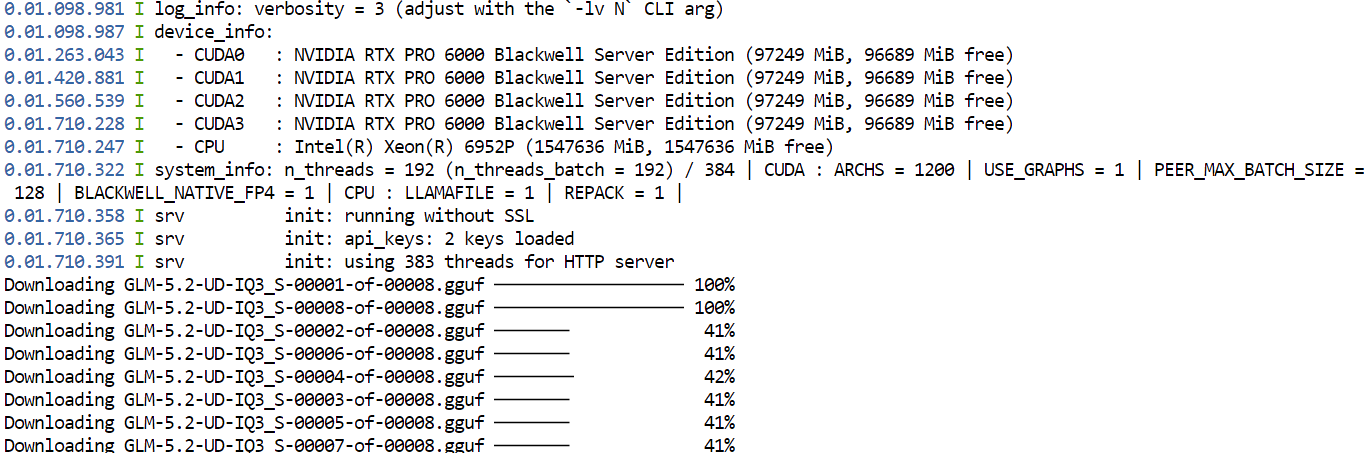
Po zakończeniu pobierania llama.cpp załaduje model na wszystkie cztery GPU. Ustawienia --split-mode layer i --tensor-split 1,1,1,1 dzielą model równomiernie między dostępne GPU, a Flash Attention pomaga poprawić wydajność.
Gdy model załaduje się pomyślnie, lokalny serwer będzie dostępny pod adresem:
http://127.0.0.1:8910
Serwer jest chroniony kluczem API ustawionym wcześniej. Pozostaw ten terminal otwarty podczas korzystania z modelu — jego zamknięcie zatrzyma serwer.
Otwórz swój Pod RunPod i przejdź do zakładki Connect. W sekcji odsłoniętych portów HTTP kliknij link powiązany z portem 8910. Otworzy to w przeglądarce Web UI llama.cpp.
Adres URL będzie miał format:
https://YOUR_POD_ID-8910.proxy.runpod.netZastąp YOUR_POD_ID swoim rzeczywistym ID Pod RunPod, jeśli będziesz wpisywać adres ręcznie.
W Web UI llama.cpp otwórz Settings i przejdź do General. Wklej ten sam klucz API, którego użyłeś przy uruchamianiu serwera llama.cpp.
To pozwala Web UI uwierzytelniać żądania i komunikować się z chronionym serwerem.
Możesz teraz przetestować model prostym poleceniem dotyczącym kodu:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
W tej konfiguracji GLM-5.2 generował średnio około 41 tokenów na sekundę, co jest dobrym tempem jak na model tej wielkości.
Jakość odpowiedzi była także wysoka — powstała uporządkowana implementacja z jasnymi zasadami walidacji i przypadkami testowymi.
Otwórz drugi terminal w JupyterLab. Pierwszy terminal musi pozostać otwarty, ponieważ działa w nim serwer llama.cpp.
W nowym terminalu ustaw lokalny adres API, użyj ponownie tego samego klucza API i ustaw alias modelu:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Najpierw sprawdź, czy serwer działa i czy GLM-5.2 jest dostępny:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"W odpowiedzi powinieneś zobaczyć alias modelu:
glm-5.2-iq3sNastępnie wyślij testowe żądanie do punktu końcowego chat completions zgodnego z OpenAI:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
Serwer zwróci odpowiedź JSON zawierającą wynik modelu.
W tym teście GLM-5.2 wygenerował uporządkowaną implementację w Pythonie z logiką walidacji i przypadkami testowymi pytest, ze średnią prędkością generowania około 41 tokenów na sekundę.
Ten lokalny adres URL działa tylko wewnątrz poda RunPod. Aby wywołać ten sam serwer z twojego laptopa, OpenCode lub innej zewnętrznej aplikacji, użyj adresu proxy RunPod:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Zastąp YOUR_POD_ID swoim rzeczywistym ID Pod RunPod i nadal używaj tego samego klucza API w nagłówku Authorization.
Zainstaluj OpenCode na komputerze, na którym znajduje się twój projekt. Otwórz terminal i uruchom:
curl -fsSL https://opencode.ai/install | bashPrzejdź następnie do folderu projektu:
cd /path/to/your/projectWyeksportuj ten sam klucz API, którego użyłeś przy uruchamianiu serwera llama.cpp na RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode działa lokalnie obok twojego projektu, a GLM-5.2 nadal działa zdalnie na twoim Pod RunPod. Taka konfiguracja pozwala OpenCode czytać twoje pliki, edytować kod, uruchamiać testy i korzystać z twojego lokalnego terminala, a GLM-5.2 realizuje rozumowanie przez zabezpieczone API RunPod.
Utwórz plik o nazwie opencode.json w katalogu głównym projektu i dodaj poniższą konfigurację:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Zastąp YOUR_POD_ID swoim rzeczywistym ID Pod RunPod. Adres URL musi odpowiadać adresowi proxy RunPod, którego użyłeś do otwarcia Web UI llama.cpp.
Gdy zapiszesz plik opencode.json, otwórz terminal w tym samym folderze projektu i uruchom OpenCode:
opencodeNastępnie wykonaj:
/modelsWybierz:
GLM-5.2 UD-IQ3_S
OpenCode jest teraz połączony z twoim serwerem GLM-5.2. Będzie używać zdalnego modelu do rozumowania, jednocześnie utrzymując pliki projektu, polecenia terminala, edycje kodu i uruchamianie testów na twoim własnym laptopie.
Zacznij od prostego testu, aby potwierdzić, że OpenCode może dotrzeć do twojego serwera GLM-5.2 i zwrócić odpowiedź.
W OpenCode wpisz:
hey
Następnie poproś OpenCode, aby przeanalizował i wyjaśnił twój istniejący projekt:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
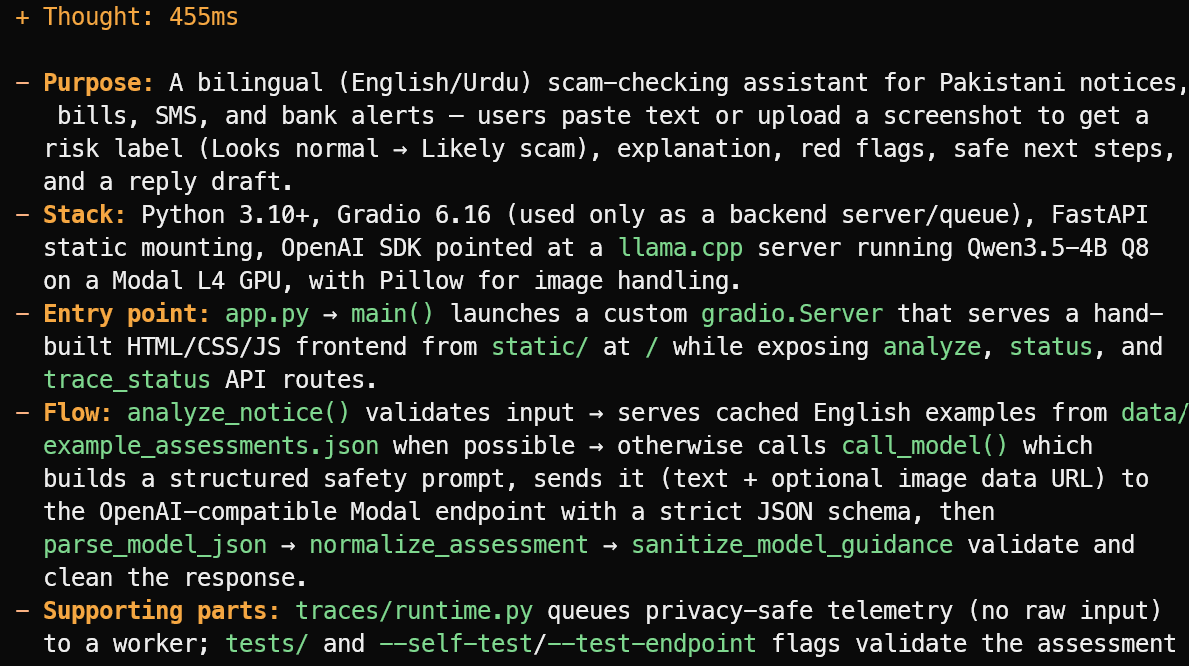
OpenCode czyta pliki projektu i daje zwięzły przegląd zamiast zgadywać. W tym przykładzie poprawnie rozpoznał, że projekt to dwujęzyczny angielsko/urdu asystent do sprawdzania oszustw dla pakistańskich ogłoszeń, rachunków, SMS-ów i alertów bankowych.
Wyjaśnił też główny stos technologiczny, punkt wejścia app.py, przebieg oceny oraz wspierające pliki testów i telemetryczne.
Prompt:
Suggest one useful new feature that fits the project's current scope.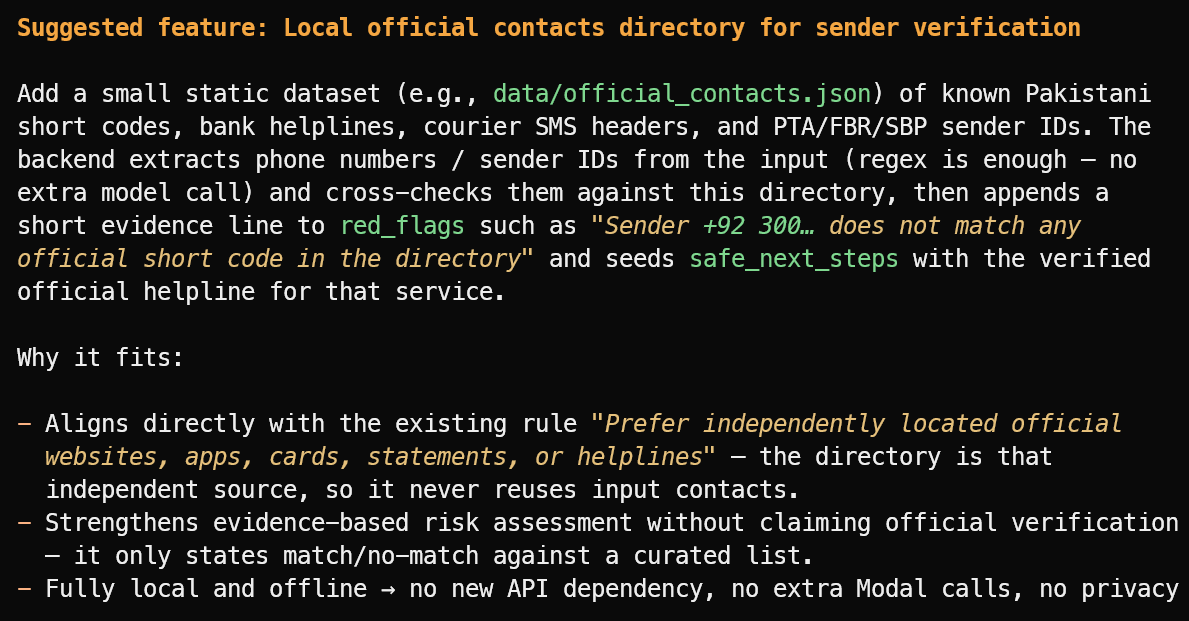
Zaproponował przydatną funkcję: lokalny katalog zweryfikowanych oficjalnych identyfikatorów nadawców, infolinii banków, nagłówków kurierów i publicznych short code’ów.
Aby przetestować OpenCode na większym zadaniu, utwórz nowy folder projektu na laptopie:
mkdir ml-app
cd ml-app
opencodeNastępnie podaj OpenCode poniższy prompt:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode najpierw tworzy listę zadań i dzieli projekt na przyswajalne kroki.
Następnie tworzy wymagane pliki aplikacji, logikę uczenia maszynowego, interfejs Streamlit, zależności i zestaw testów.
Po zakończeniu implementacji uruchamia testy, naprawia napotkane problemy i dostarcza jasne podsumowanie gotowego projektu wraz z poleceniem potrzebnym do jego uruchomienia.
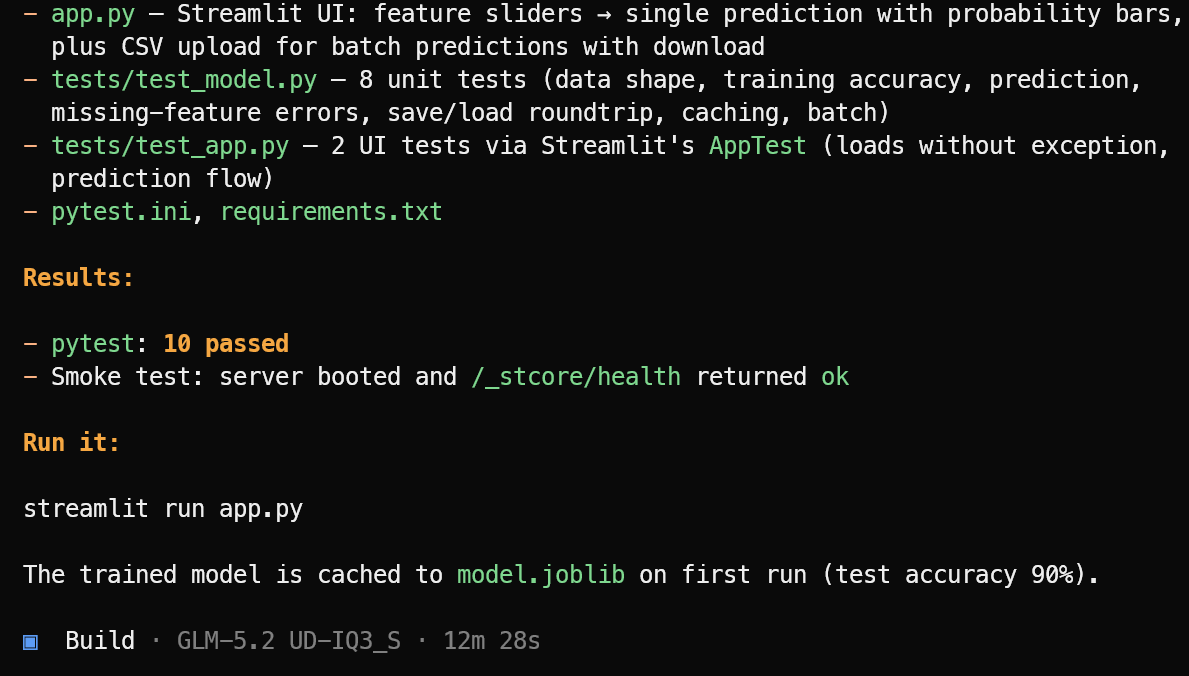
W tym teście OpenCode ukończył 10 przechodzących testów i potwierdził, że aplikacja Streamlit uruchomiła się pomyślnie. Uruchom aplikację ML poleceniem:
streamlit run app.pyPowstała aplikacja wygląda schludnie i działa zgodnie z oczekiwaniami.
Nawet przy 3-bitowej kwantyzacji GLM-5.2 jakość rozumowania była w tych testach wysoka.
Model zrozumiał istniejący projekt, zaproponował trafną funkcję, stworzył kompletną aplikację webową, używał narzędzi do inspekcji i modyfikacji plików oraz uruchomił testy weryfikujące swoją pracę.
Ta konfiguracja daje ci coś, czego nie zapewniają standardowi dostawcy API: twój własny, prywatnie hostowany serwer GLM-5.2.
Zamiast wysyłać każde żądanie do współdzielonej platformy modelowej z ustalonymi limitami, ustawieniami i rozliczaniem za token, wynajmujesz maszynę GPU, sam wdrażasz model i kontrolujesz cały stos serwowania.
To ty wybierasz kwantyzację modelu, konfigurację GPU, okno kontekstu, ustawienia serwera, klucz API oraz to, kto ma dostęp do endpointu.
Twój kod, prompty, kontekst projektu i odpowiedzi API pozostają w infrastrukturze, którą kontrolujesz: na twoim własnym laptopie i we własnym wdrożeniu RunPod.
Nie są wysyłane do dodatkowego hostowanego dostawcy inferencji. Jest to szczególnie przydatne, gdy pracujesz z prywatnymi repozytoriami, wewnętrznymi narzędziami, wrażliwym kodem lub danymi firmowymi.
Unikasz też kosztu i wysiłku zakupu, utrzymania i zarządzania własnym, wysokiej klasy serwerem wielo-GPU.
Zamiast tego możesz wynajmować mocne GPU tylko wtedy, gdy ich potrzebujesz, serwować GLM-5.2 z llama.cpp, zabezpieczyć endpoint własnym kluczem API i łączyć się z laptopa przez OpenCode.
W tym przewodniku skonfigurowałeś maszynę RunPod z wieloma GPU, zainstalowałeś prekompilowany pakiet llama.cpp, pobrałeś i zaserwowałeś model GLM-5.2 GGUF oraz zabezpieczyłeś serwer kluczem API.
Następnie przetestowałeś model przez Web UI llama.cpp i jego API cURL zgodne z OpenAI, zanim wystawiłeś zabezpieczony adres RunPod do dostępu zewnętrznego.
Na końcu połączyłeś ten prywatny endpoint modelu z OpenCode uruchomionym na twoim laptopie. Powstaje praktyczny hybrydowy workflow: GLM-5.2 działa na mocnych, wynajętych GPU, a OpenCode pozostaje w twoim lokalnym projekcie i może przeglądać pliki, edytować kod, uruchamiać testy oraz korzystać z twojej powłoki.
Zyskujesz wydajność modelu najwyższej klasy, elastyczność samodzielnego hostingu i znacznie więcej kontroli niż przy standardowym hostowanym API.
Najlepsze kursy DataCamp
Track
course
course