
Cursus
Ingénieur IA associé pour les scientifiques de données
40 h
GLM-5.2 est le dernier modèle phare open source de Z.ai, conçu pour le code sur des horizons longs, le raisonnement et les tâches d’ingénierie agentique. Il propose une fenêtre de contexte d’un million de tokens, plusieurs modes de pensée, le support du tool calling, et des améliorations destinées à maintenir la cohérence sur de larges bases de code et des tâches multi-étapes.
Bien que le modèle complet soit massif, les quantifications GGUF rendent possible l’exécution de GLM-5.2 en local avec llama.cpp sur le bon matériel.
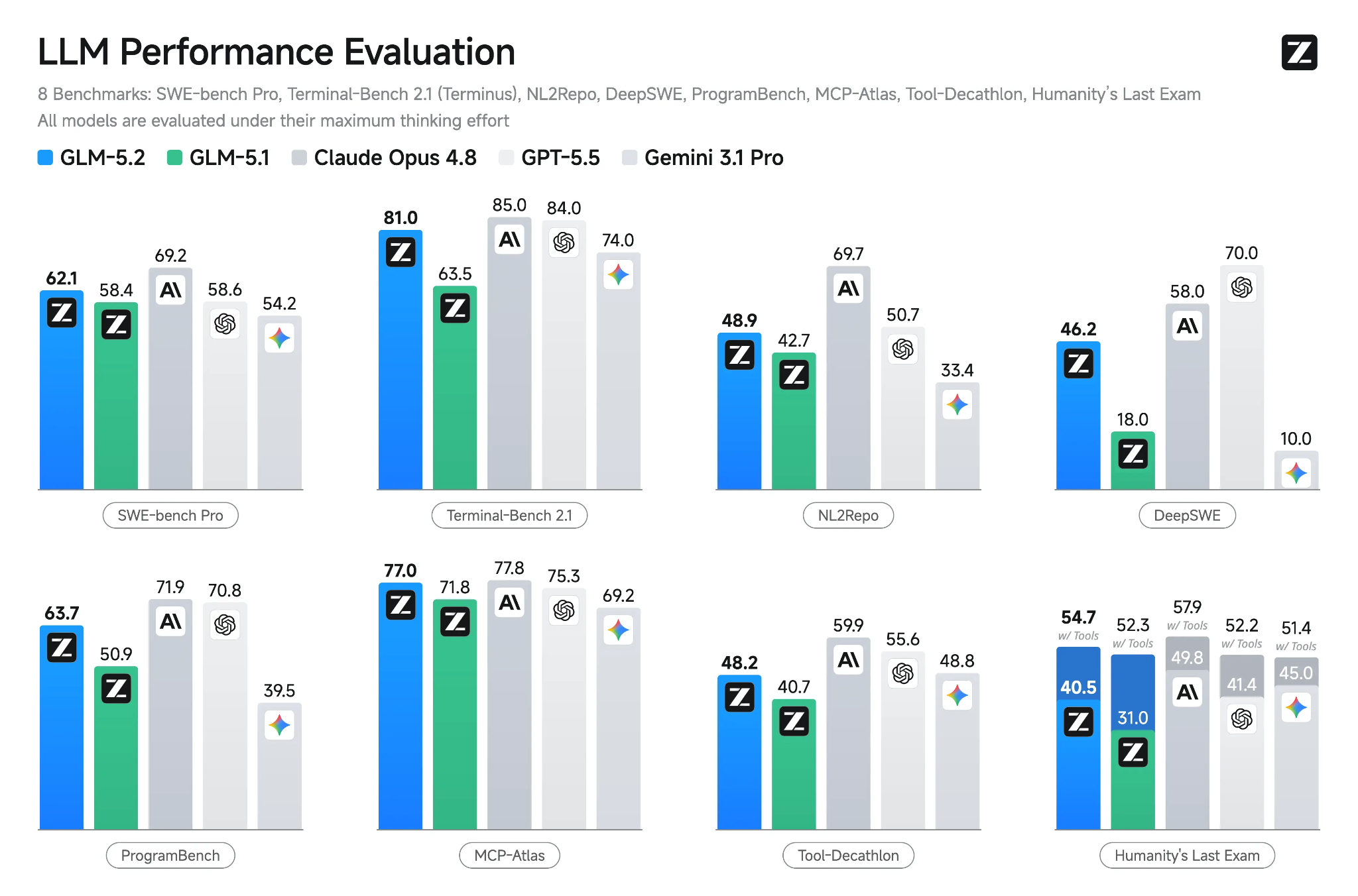
Source : GLM-5.2: Built for Long-Horizon Tasks
Dans ce guide, je vous montre comment installer le paquet précompilé llama.cpp et l’utiliser pour servir GLM-5.2 sur une instance GPU RunPod.
Vous démarrerez le serveur avec une clé API, testerez son endpoint compatible OpenAI avec cURL, et utiliserez l’interface Web intégrée de llama.cpp dans votre navigateur.
Ensuite, vous exposerez le serveur via l’URL proxy de RunPod pour y accéder en toute sécurité depuis votre ordinateur portable ou d’autres applications.
Enfin, vous connecterez ce serveur GLM-5.2 hébergé à OpenCode exécuté localement à côté de votre projet, ce qui permettra à OpenCode de lire les fichiers, modifier le code, exécuter des tests et utiliser votre shell local tandis que GLM-5.2 gère le raisonnement à distance.
Accédez à votre tableau de bord RunPod et créez un nouveau Pod. Avant de le lancer, assurez-vous que votre compte dispose d’au moins 25 $ de crédit, car GLM-5.2 nécessite une configuration multi-GPU conséquente.
Sélectionnez une machine avec 4× RTX PRO 6000, offrant :
Avant le déploiement, modifiez le template du Pod. Augmentez l’espace disque du conteneur à au moins 550 Go et ajoutez ce qui suit sous Expose HTTP Ports :
8910Ce port sera utilisé plus tard pour le serveur llama.cpp, l’interface Web et l’API compatible OpenAI.
Pour accélérer et fiabiliser les téléchargements de modèles, ajoutez votre jeton Hugging Face comme variable d’environnement dans le template :
HF_TOKEN=your_hugging_face_token
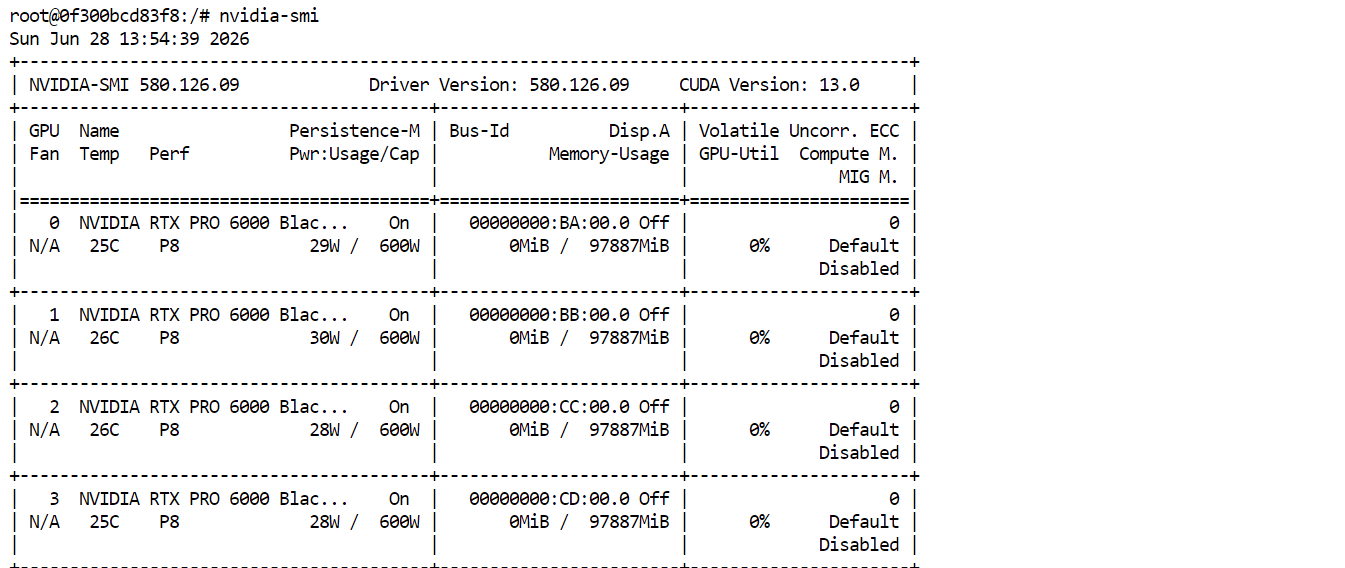
Une fois tout configuré, déployez le Pod. Après le démarrage, cliquez sur Connect et ouvrez JupyterLab. Lancez un nouveau terminal et exécutez :
nvidia-smiVous devriez voir les quatre RTX PRO 6000 listées et disponibles. Cela confirme que le Pod est prêt à télécharger et exécuter GLM-5.2.
Plutôt que de compiler llama.cpp depuis les sources, installez la dernière version précompilée avec l’installateur officiel llama.app. Exécutez la commande suivante dans votre terminal JupyterLab :
curl -LsSf https://llama.app/install.sh | shAjoutez ensuite le dossier d’installation de llama.cpp à votre PATH afin de pouvoir exécuter la commande llama depuis n’importe quel terminal :
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcRechargez votre configuration Bash pour appliquer la modification :
source ~/.bashrcEnfin, vérifiez que llama.cpp a bien été installé :
llama helpVous devriez voir les commandes disponibles de llama.cpp.

Configurez ensuite un emplacement persistant pour les fichiers du modèle.
Le répertoire /workspace de RunPod reste disponible même lorsque vous mettez le pod en pause, c’est donc un meilleur emplacement pour stocker le cache Hugging Face que l’emplacement par défaut.
Exécutez les commandes suivantes dans le terminal JupyterLab :
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Cela garantit que les fichiers téléchargés sont stockés dans /workspace/huggingface.
Créez maintenant une clé API pour votre serveur llama.cpp. Utilisez une valeur longue et aléatoire, et gardez-la privée : vous en aurez besoin plus tard pour tester l’API et connecter OpenCode :
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Enfin, définissez un alias simple pour le modèle :
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode utilisera exactement cet alias plus tard, conservez-le tel quel tout au long du guide.
Vous êtes prêt à démarrer le serveur GLM-5.2. Exécutez la commande suivante dans le même terminal :
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaLa première fois, llama.cpp téléchargera la quantification GGUF UD-IQ3_S de GLM-5.2 depuis Hugging Face et la stockera dans le répertoire de cache configuré plus haut.
Le téléchargement peut être long car le modèle est très volumineux.
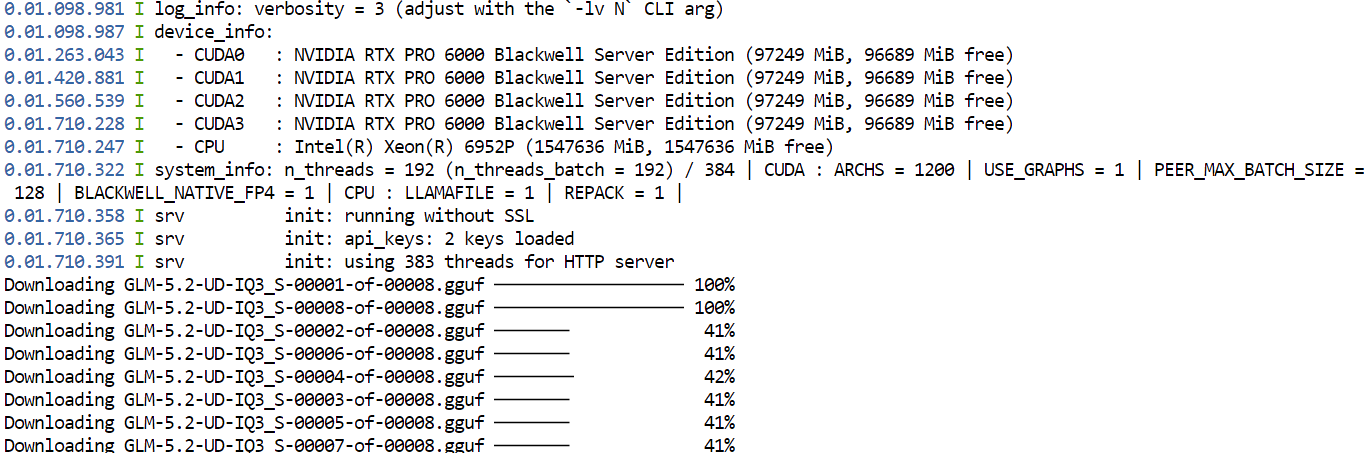
Après le téléchargement, llama.cpp chargera le modèle sur les quatre GPUs. Les options --split-mode layer et --tensor-split 1,1,1,1 répartissent le modèle équitablement sur les GPUs disponibles, tandis que Flash Attention améliore les performances.
Une fois le modèle chargé, le serveur local sera disponible à l’adresse :
http://127.0.0.1:8910
Le serveur est protégé par la clé API définie précédemment. Gardez ce terminal ouvert pendant l’utilisation du modèle, car le fermer arrêterait le serveur.
Ouvrez votre Pod RunPod et allez dans l’onglet Connect. Sous les ports HTTP exposés, cliquez sur le lien associé au port 8910. L’interface Web de llama.cpp s’ouvrira dans votre navigateur.
L’URL suit ce format :
https://YOUR_POD_ID-8910.proxy.runpod.netRemplacez YOUR_POD_ID par l’identifiant réel de votre Pod RunPod si vous saisissez l’URL manuellement.
Dans l’interface Web de llama.cpp, ouvrez Settings puis General. Collez la même clé API que celle utilisée au démarrage du serveur llama.cpp.
Cela permet à l’interface d’authentifier ses requêtes et de communiquer avec le serveur protégé.
Vous pouvez maintenant tester le modèle avec une invite de code simple :
Write a Python function that validates an email address without external packages.
Include three pytest tests.
Dans cette configuration, GLM-5.2 a généré en moyenne 41 tokens par seconde, une bonne vitesse pour un modèle de cette taille.
La qualité de la réponse était également au rendez-vous, avec une implémentation structurée, des règles de validation claires et des tests.
Ouvrez un second terminal dans JupyterLab. Le premier doit rester ouvert car il exécute le serveur llama.cpp.
Dans le nouveau terminal, définissez l’URL de l’API locale, réutilisez la même clé API et définissez l’alias du modèle :
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Vérifiez d’abord que le serveur fonctionne et que GLM-5.2 est disponible :
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Vous devriez voir l’alias du modèle dans la réponse :
glm-5.2-iq3sEnvoyez ensuite une requête de test à l’endpoint de complétions de chat compatible OpenAI :
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
Le serveur renverra une réponse JSON contenant la sortie du modèle.
Dans ce test, GLM-5.2 a produit une implémentation Python structurée avec logique de validation et tests pytest, à une vitesse moyenne d’environ 41 tokens par seconde.
Cette URL locale ne fonctionne qu’à l’intérieur du Pod RunPod. Pour appeler le même serveur depuis votre ordinateur, OpenCode ou une autre application externe, utilisez plutôt l’URL proxy RunPod :
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Remplacez YOUR_POD_ID par l’identifiant réel de votre Pod RunPod, et continuez d’utiliser la même clé API dans l’en-tête Authorization.
Installez OpenCode sur l’ordinateur où se trouve votre projet. Ouvrez un terminal et exécutez :
curl -fsSL https://opencode.ai/install | bashAccédez ensuite au dossier de votre projet :
cd /path/to/your/projectExportez la même clé API que celle utilisée lors du démarrage du serveur llama.cpp sur RunPod :
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode s’exécute localement à côté de votre projet, tandis que GLM-5.2 tourne à distance sur votre Pod RunPod. Cette configuration permet à OpenCode de lire vos fichiers, modifier le code, exécuter des tests et utiliser votre terminal local, tandis que GLM-5.2 gère le raisonnement via l’API sécurisée de RunPod.
Créez un fichier nommé opencode.json à la racine du projet et ajoutez la configuration suivante :
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Remplacez YOUR_POD_ID par l’identifiant réel de votre Pod RunPod. L’URL doit correspondre à celle du proxy RunPod utilisée pour ouvrir l’interface Web de llama.cpp.
Une fois le fichier opencode.json enregistré, ouvrez un terminal dans le même dossier de projet et lancez OpenCode :
opencodePuis exécutez :
/modelsSélectionnez :
GLM-5.2 UD-IQ3_S
OpenCode est maintenant connecté à votre serveur GLM-5.2. Il utilisera le modèle distant pour le raisonnement tout en conservant les fichiers du projet, les commandes de terminal, les modifications de code et l’exécution des tests sur votre propre machine.
Commencez par un test simple pour vérifier qu’OpenCode atteint votre serveur GLM-5.2 et renvoie une réponse.
Dans OpenCode, tapez :
hey
Demandez ensuite à OpenCode d’inspecter et d’expliquer votre projet existant :
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
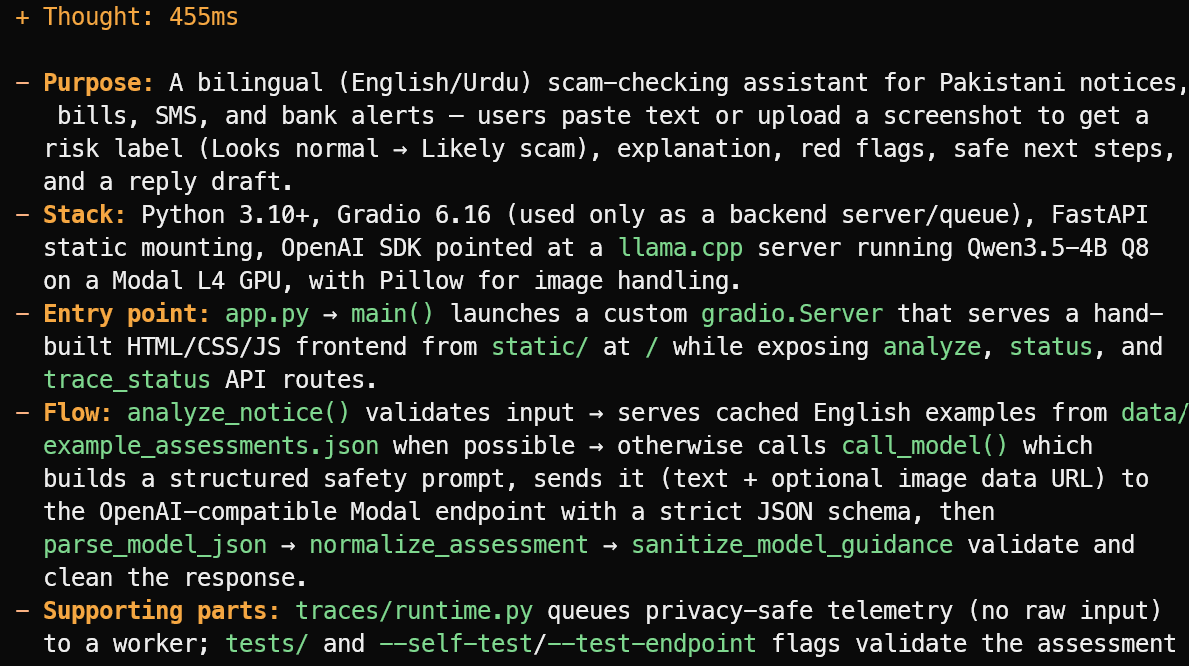
OpenCode lit les fichiers du projet et propose une synthèse concise plutôt que de deviner. Dans cet exemple, il a correctement identifié qu’il s’agit d’un assistant bilingue anglais/ourdou de détection d’arnaques pour des avis, factures, SMS et alertes bancaires pakistanais.
Il a également expliqué la stack principale, le point d’entrée app.py, le flux d’évaluation, ainsi que les fichiers de tests et de télémétrie associés.
Invite :
Suggest one useful new feature that fits the project's current scope.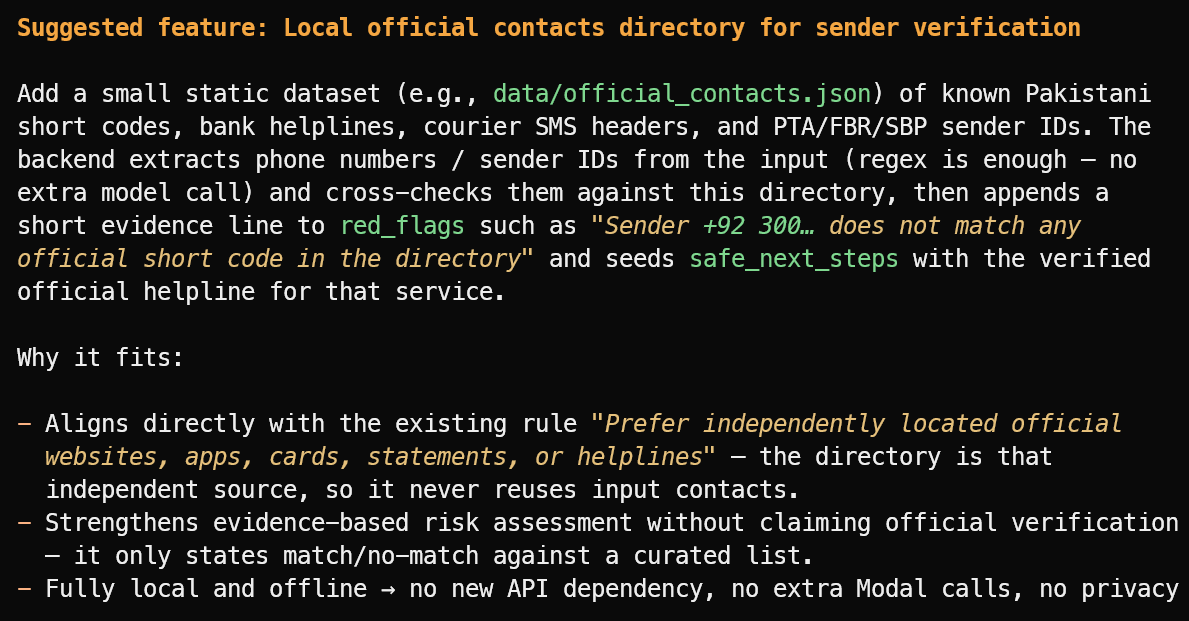
Il a suggéré une fonctionnalité utile : un répertoire local d’expéditeurs officiels vérifiés, de lignes d’assistance des banques, d’identifiants d’expéditeurs des transporteurs et de numéros courts publics.
Pour tester OpenCode sur une tâche plus ambitieuse, créez un nouveau dossier de projet sur votre ordinateur :
mkdir ml-app
cd ml-app
opencodePuis donnez à OpenCode l’invite suivante :
Build and test a complete Python-based web UI for this machine learning application.
OpenCode commence par créer une liste de tâches et découpe le projet en étapes gérables.
Il crée ensuite les fichiers applicatifs requis, la logique de machine learning, l’interface Streamlit, les dépendances et la suite de tests.
Une fois l’implémentation terminée, il lance les tests, corrige les problèmes détectés et fournit un résumé clair du projet finalisé ainsi que la commande nécessaire pour le démarrer.
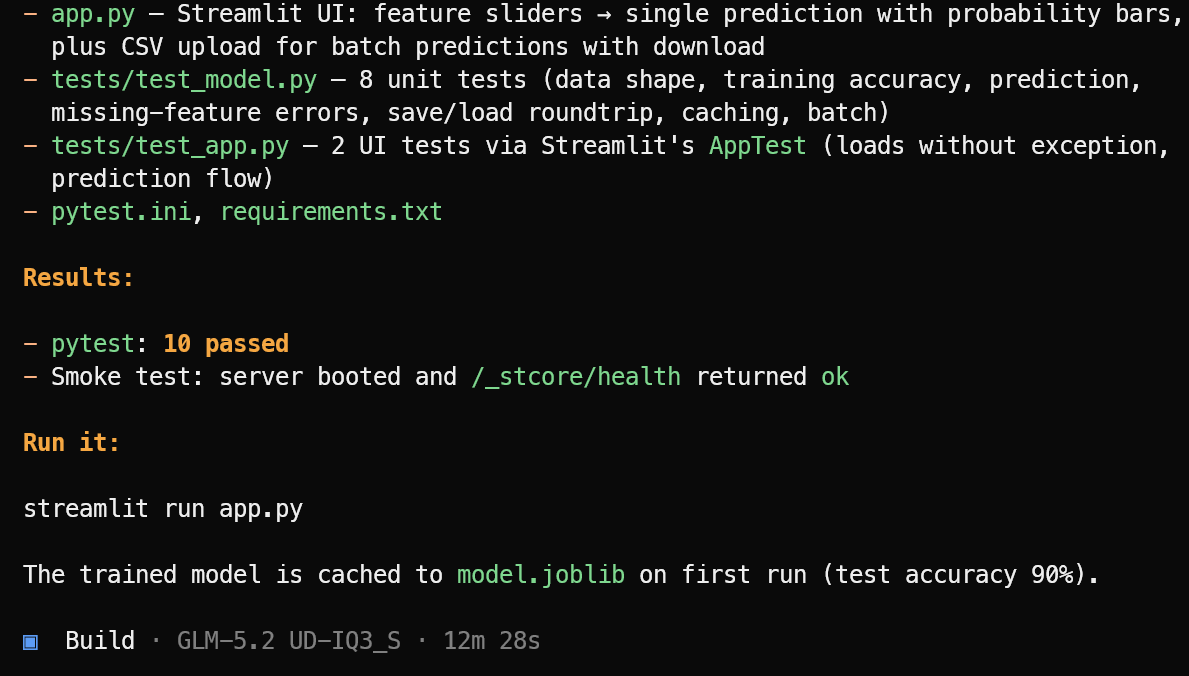
Dans ce test, OpenCode a terminé 10 tests passants et vérifié que l’application Streamlit se lançait correctement. Démarrez l’application de machine learning avec :
streamlit run app.pyL’application obtenue est soignée et fonctionne comme prévu.
Même avec la version quantifiée en 3 bits de GLM-5.2, la qualité de raisonnement s’est révélée solide dans ces tests.
Il a compris le projet existant, proposé une fonctionnalité pertinente, créé une application Web complète, utilisé des outils pour inspecter et modifier des fichiers, et exécuté des tests pour valider son travail.
Cette configuration vous apporte ce que les fournisseurs d’API standard n’offrent pas : votre propre serveur GLM-5.2 hébergé en privé.
Au lieu d’envoyer chaque requête vers une plateforme partagée avec des limites fixes, des réglages imposés et une tarification au token, vous louez la machine GPU, déployez le modèle vous-même et contrôlez toute la pile de service.
Vous choisissez la quantification du modèle, la configuration GPU, la fenêtre de contexte, les réglages du serveur, la clé API et les personnes autorisées à accéder à l’endpoint.
Votre code, vos invites, le contexte de projet et les réponses d’API restent dans une infrastructure que vous contrôlez : votre ordinateur et votre déploiement RunPod.
Elles ne sont pas envoyées à un prestataire d’inférence supplémentaire. C’est particulièrement utile lorsque vous travaillez avec des dépôts privés, des outils internes, du code sensible ou des données d’entreprise.
Vous évitez aussi le coût et l’effort d’acheter, d’exploiter et de maintenir vous-même un serveur multi-GPU haut de gamme.
À la place, louez des GPUs puissants uniquement quand vous en avez besoin, servez GLM-5.2 avec llama.cpp, sécurisez l’endpoint avec votre propre clé API et connectez-vous depuis votre ordinateur via OpenCode.
Dans ce guide, vous avez configuré une machine RunPod multi-GPU, installé le paquet précompilé llama.cpp, téléchargé et servi le modèle GLM-5.2 GGUF, et protégé le serveur avec une clé API.
Vous avez ensuite testé le modèle via l’interface Web de llama.cpp et son API cURL compatible OpenAI, avant d’exposer l’URL sécurisée de RunPod pour un accès externe.
Enfin, vous avez connecté cet endpoint privé à OpenCode exécuté sur votre ordinateur. Cela crée un workflow hybride efficace : GLM-5.2 tourne sur des GPUs puissants loués, tandis qu’OpenCode reste à l’intérieur de votre projet local pour inspecter les fichiers, modifier le code, lancer les tests et utiliser votre shell.
Vous bénéficiez des performances d’un modèle de premier plan, de la flexibilité du self-hosting et d’un contrôle nettement supérieur à celui d’une API hébergée standard.
Meilleures formations DataCamp
Cursus
Cours
Cours