Track
Ассоциированный AI-инженер для специалистов по данным
40 ч
GLM-5.2 — это новейшая флагманская открытая модель Z.ai, созданная для длительных циклов кодинга, рассуждений и агентных инженерных задач. Она предлагает контекстное окно на 1M токенов, несколько режимов размышления, поддержку вызова инструментов и улучшения, помогающие сохранять согласованность на больших кодовых базах и в многошаговых задачах.
Полная модель огромна, но квантизации GGUF позволяют запускать GLM-5.2 локально с помощью llama.cpp на подходящем оборудовании.
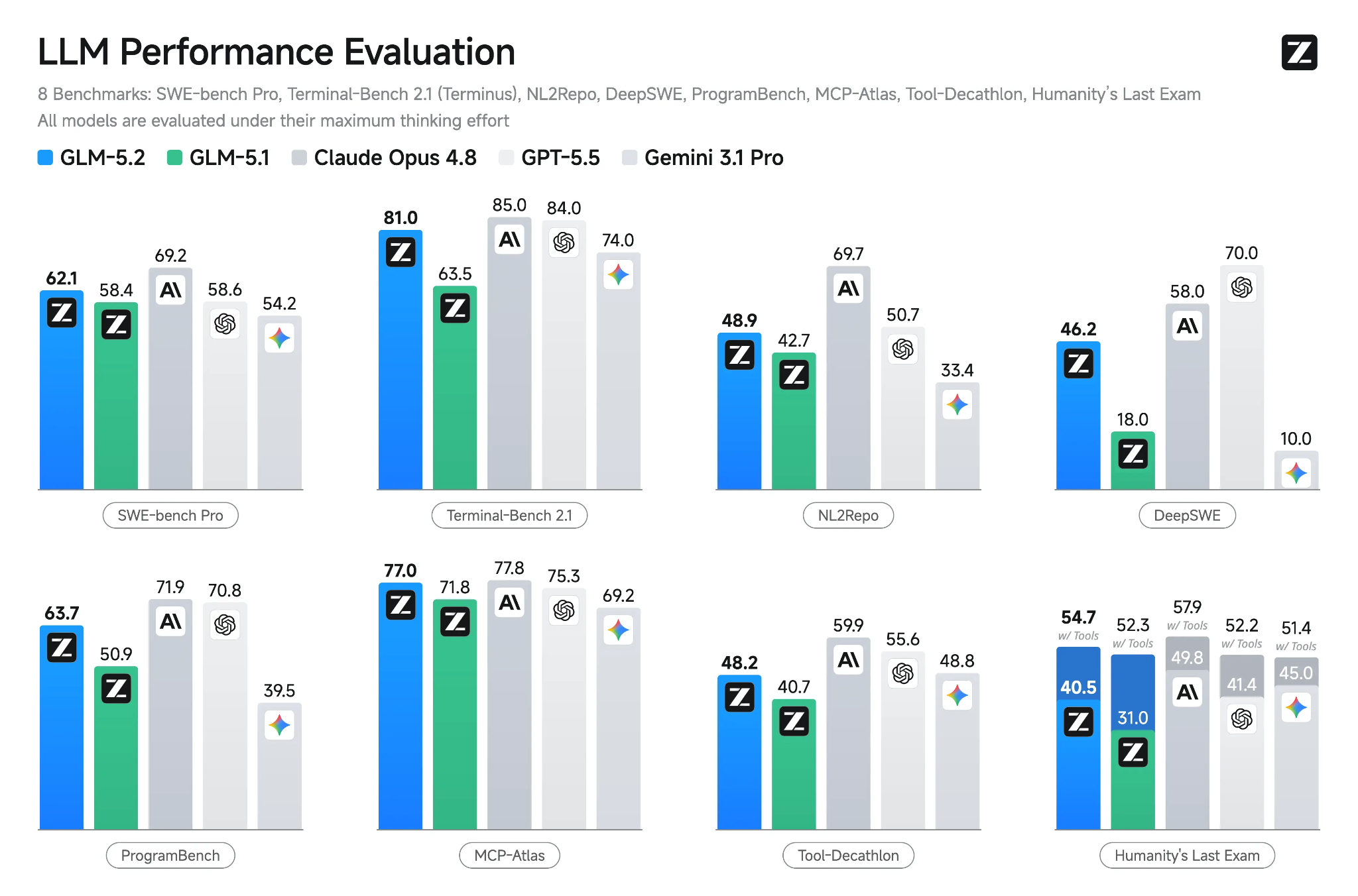
Источник: GLM-5.2: Built for Long-Horizon Tasks
В этом руководстве я покажу, как установить предсобранный пакет llama.cpp и использовать его для сервинга GLM-5.2 на GPU-инстансе RunPod.
Вы запустите сервер с API-ключом, протестируете его OpenAI-совместимую конечную точку через cURL и воспользуетесь встроенным Web UI llama.cpp в браузере.
Затем вы опубликуете сервер через прокси-URL RunPod, чтобы к нему можно было безопасно подключаться с ноутбука и из других приложений.
Наконец, вы подключите размещённый сервер GLM-5.2 к OpenCode, запущенному локально рядом с вашим проектом, чтобы OpenCode мог читать файлы, редактировать код, запускать тесты и использовать локальную оболочку, пока GLM-5.2 выполняет рассуждения удалённо.
Перейдите в панель управления RunPod и создайте новый Pod. Перед запуском убедитесь, что на вашем счёте есть не менее $25 кредита, поскольку GLM-5.2 требует крупной мульти-GPU конфигурации.
Выберите машину с 4× RTX PRO 6000 GPUs, которая предоставляет:
Перед развёртыванием отредактируйте шаблон Pod. Увеличьте пространство контейнера как минимум до 550 ГБ и добавьте следующее в раздел Expose HTTP Ports:
8910Этот порт позже будет использоваться сервером llama.cpp, Web UI и OpenAI-совместимым API.
Для более быстрых и надёжных загрузок моделей добавьте токен Hugging Face как переменную окружения в шаблон:
HF_TOKEN=your_hugging_face_token
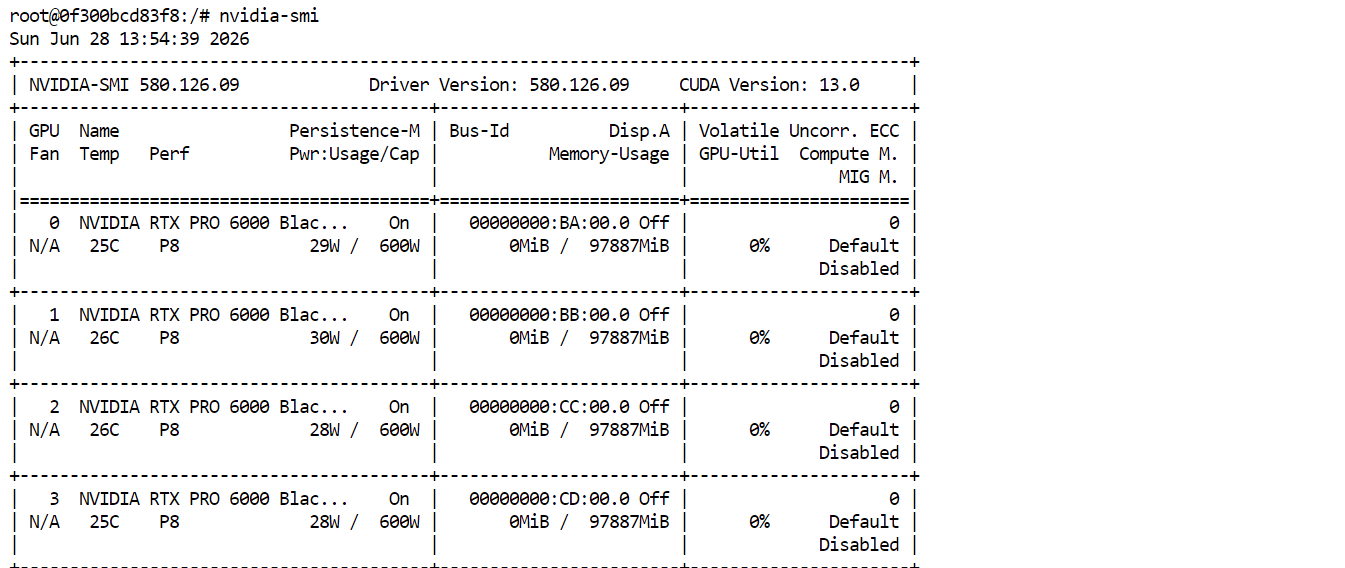
Когда всё настроено, разверните Pod. После запуска нажмите Connect и откройте JupyterLab. Запустите новый терминал и выполните:
nvidia-smiВы должны увидеть все четыре GPU RTX PRO 6000 в списке и доступные. Это подтверждает, что Pod готов к загрузке и запуску GLM-5.2.
Вместо сборки llama.cpp из исходников установите последнюю предсобранную версию с помощью официального установщика llama.app. Выполните следующую команду в терминале JupyterLab:
curl -LsSf https://llama.app/install.sh | shДалее добавьте папку установки llama.cpp в ваш PATH, чтобы можно было запускать команду llama из любого терминала:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcПерезагрузите конфигурацию Bash, чтобы применить изменения:
source ~/.bashrcНаконец, проверьте, что llama.cpp установлена корректно:
llama helpВы увидите список доступных команд llama.cpp.

Теперь настройте постоянное место для файлов модели.
Каталог /workspace RunPod остаётся доступным даже при паузе pod, поэтому это лучшее место для хранения кэша Hugging Face, чем расположение по умолчанию.
Выполните следующие команды в терминале JupyterLab:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Это гарантирует, что загруженные файлы моделей будут храниться в /workspace/huggingface.
Теперь создайте API-ключ для вашего сервера llama.cpp. Используйте длинное случайное значение и держите его в секрете — этот же ключ понадобится позже при тестировании API и подключении OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"И, наконец, задайте простой алиас для модели:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode позже будет использовать именно этот алиас модели, поэтому оставьте его без изменений на протяжении всего руководства.
Теперь вы готовы запустить сервер GLM-5.2. Выполните следующую команду в том же терминале:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaПри первом запуске этой команды llama.cpp загрузит квантизацию GGUF UD-IQ3_S модели GLM-5.2 из Hugging Face и сохранит её в настроенном ранее каталоге кэша.
Загрузка может занять время, так как модель очень большая.
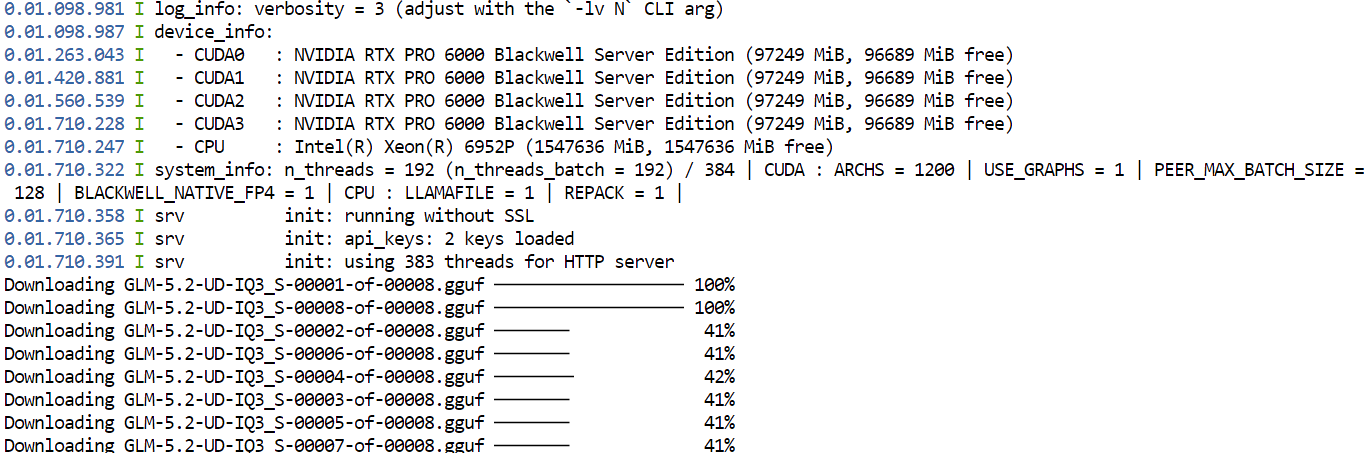
После завершения загрузки llama.cpp распределит модель по всем четырём GPU. Параметры --split-mode layer и --tensor-split 1,1,1,1 делят модель равномерно между доступными GPU, а Flash Attention помогает повысить производительность.
После успешной загрузки модели локальный сервер будет доступен по адресу:
http://127.0.0.1:8910
Сервер защищён API-ключом, который вы задали ранее. Держите этот терминал открытым во время работы с моделью — закрытие остановит сервер.
Откройте ваш RunPod Pod и перейдите на вкладку Connect. В разделе опубликованных HTTP-портов нажмите ссылку для порта 8910. Откроется Web UI llama.cpp в вашем браузере.
URL будет в формате:
https://YOUR_POD_ID-8910.proxy.runpod.netЗамените YOUR_POD_ID на фактический ID вашего RunPod Pod, если нужно ввести URL вручную.
В Web UI llama.cpp откройте Settings и перейдите в раздел General. Вставьте тот же API-ключ, который вы использовали при запуске сервера llama.cpp.
Это позволит Web UI аутентифицировать запросы и взаимодействовать с защищённым сервером.
Теперь вы можете проверить модель простым запросом по программированию:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
В этой конфигурации GLM-5.2 генерировала в среднем около 41 токена/с — хороший показатель для модели такого размера.
Качество ответа тоже было высоким: модель выдала структурированную реализацию с понятными правилами валидации и тест-кейсами.
Откройте второй терминал в JupyterLab. Первый терминал должен оставаться открытым, поскольку в нём работает сервер llama.cpp.
В новом терминале задайте локальный URL API, переиспользуйте тот же API-ключ и укажите алиас модели:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Сначала проверьте, что сервер запущен и GLM-5.2 доступна:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"В ответе вы должны увидеть алиас модели:
glm-5.2-iq3sДалее отправьте тестовый запрос на OpenAI-совместимый endpoint чат-комплишнов:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
Сервер вернёт JSON с ответом модели.
В этом тесте GLM-5.2 выдала структурированную Python-реализацию с логикой валидации и тестами pytest со средней скоростью генерации примерно 41 токен/с.
Этот локальный URL работает только внутри Pod RunPod. Чтобы обращаться к тому же серверу с вашего ноутбука, из OpenCode или другого внешнего приложения, используйте вместо него прокси-URL RunPod:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Замените YOUR_POD_ID на фактический ID вашего RunPod Pod и продолжайте использовать тот же API-ключ в заголовке Authorization.
Установите OpenCode на компьютер, где хранится ваш проект. Откройте терминал и выполните:
curl -fsSL https://opencode.ai/install | bashЗатем перейдите в папку проекта:
cd /path/to/your/projectЭкспортируйте тот же API-ключ, который вы использовали при запуске сервера llama.cpp на RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode работает локально рядом с вашим проектом, а GLM-5.2 продолжает работать удалённо на вашем Pod RunPod. Такая связка позволяет OpenCode читать файлы, редактировать код, запускать тесты и использовать ваш локальный терминал, в то время как GLM-5.2 выполняет рассуждения через защищённый API RunPod.
Создайте файл opencode.json в корне проекта и добавьте следующую конфигурацию:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Замените YOUR_POD_ID на фактический ID вашего RunPod Pod. URL должен совпадать с прокси-URL RunPod, который вы использовали для открытия Web UI llama.cpp.
После сохранения файла opencode.json откройте терминал в этой же папке проекта и запустите OpenCode:
opencodeЗатем выполните:
/modelsВыберите:
GLM-5.2 UD-IQ3_S
OpenCode теперь подключён к вашему серверу GLM-5.2. Он будет использовать удалённую модель для рассуждений, сохраняя файлы проекта, команды терминала, правки кода и запуск тестов на вашем ноутбуке.
Начните с простого теста, чтобы подтвердить, что OpenCode может достучаться до вашего сервера GLM-5.2 и вернуть ответ.
В OpenCode введите:
hey
Затем попросите OpenCode изучить и объяснить ваш текущий проект:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
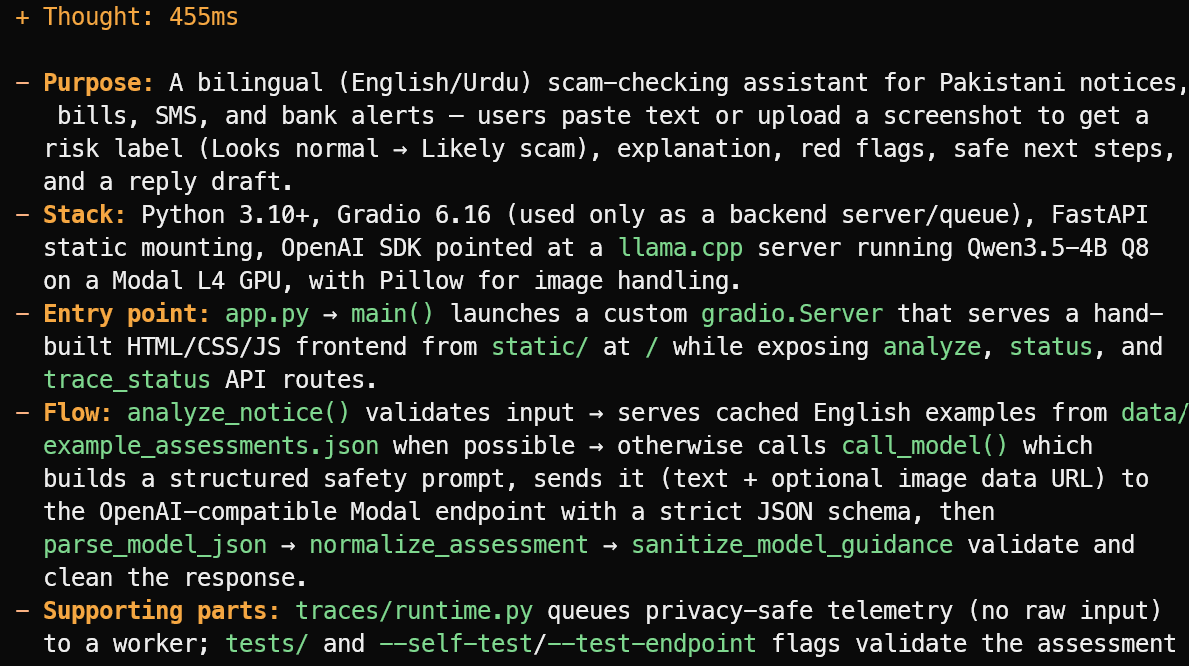
OpenCode читает файлы проекта и даёт краткий обзор, а не гадает. В этом примере он верно определил, что проект — двуязычный англо/урду помощник по проверке мошеннических уведомлений: объявлений, счетов, SMS и банковских оповещений для Пакистана.
Он также объяснил основной стек, входную точку app.py, поток оценки и вспомогательные файлы тестов и телеметрии.
Подсказка:
Suggest one useful new feature that fits the project's current scope.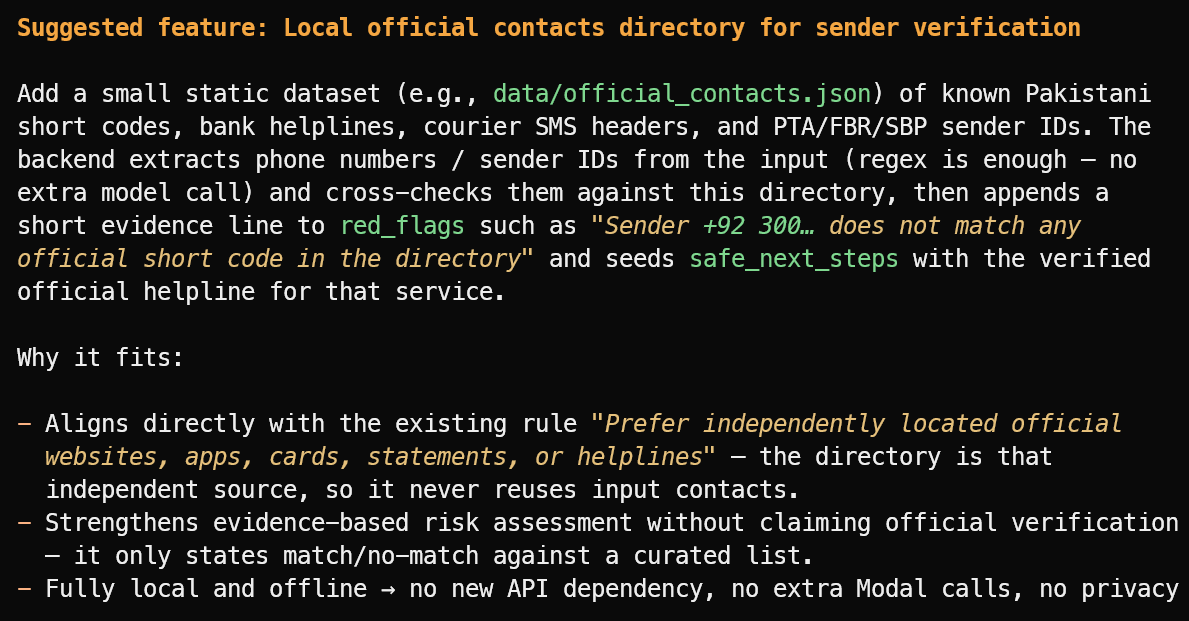
Он предложил полезную функцию: локальный справочник проверенных официальных идентификаторов отправителей, банковских горячих линий, заголовков курьерских служб и публичных коротких кодов.
Чтобы протестировать OpenCode на более крупной задаче, создайте новую папку проекта на ноутбуке:
mkdir ml-app
cd ml-app
opencodeЗатем дайте OpenCode следующую подсказку:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode сначала создаёт список задач и разбивает проект на управляемые шаги.
Затем он создаёт необходимые файлы приложения, логику машинного обучения, интерфейс Streamlit, зависимости и тестовый набор.
После завершения реализации он запускает тесты, исправляет обнаруженные проблемы и предоставляет понятное резюме готового проекта вместе с командой для его запуска.
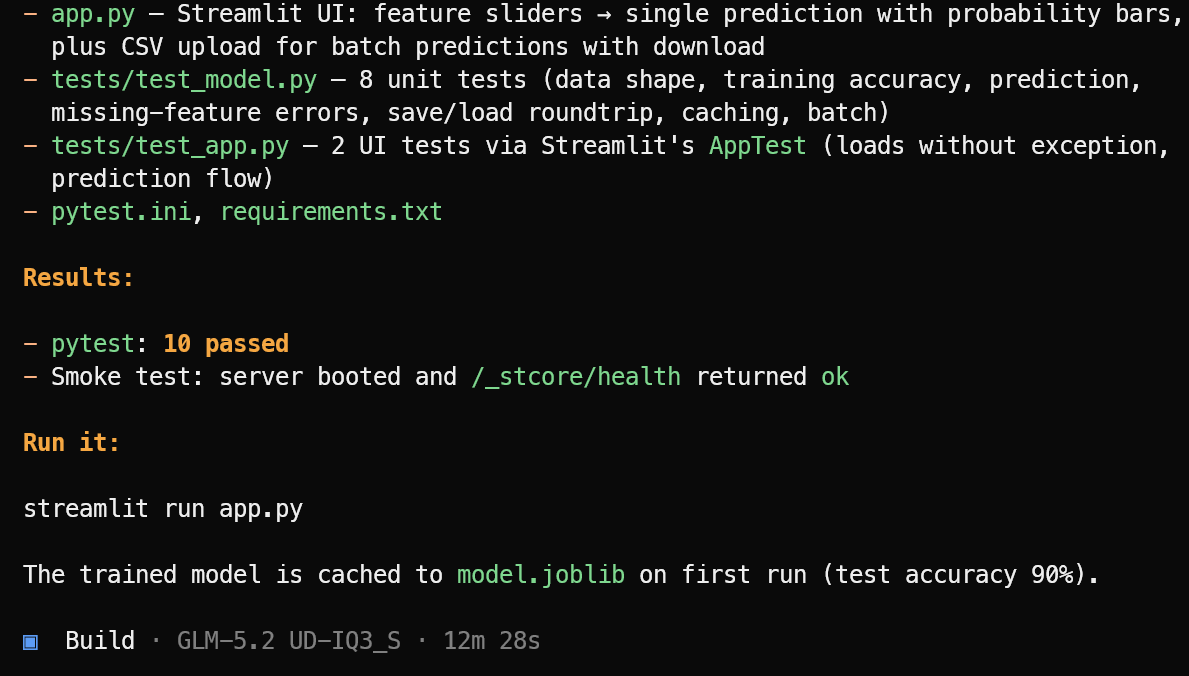
В этом тесте OpenCode выполнил 10 успешных тестов и подтвердил успешный запуск приложения Streamlit. Запустите приложение машинного обучения командой:
streamlit run app.pyПолучившееся приложение выглядит аккуратно и работает как ожидается.
Даже с 3-битной квантизацией GLM-5.2 качество рассуждений в этих тестах было высоким.
Модель поняла существующий проект, предложила релевантную функцию, создала полноценное веб-приложение, использовала инструменты для изучения и модификации файлов и запустила тесты для проверки своей работы.
Такой стек даёт то, чего нет у стандартных провайдеров API: ваш собственный приватно размещённый сервер GLM-5.2.
Вместо отправки каждого запроса на общую платформу с фиксированными лимитами, настройками модели и тарификацией по токенам, вы арендуете GPU‑машину, разворачиваете модель сами и контролируете весь стек сервинга.
Вы выбираете квантизацию модели, конфигурацию GPU, размер контекста, настройки сервера, API-ключ и определяете, кто может обращаться к endpoint.
Ваш код, подсказки, контекст проекта и ответы API остаются в инфраструктуре под вашим контролем: на вашем ноутбуке и в вашем развёртывании RunPod.
Они не отправляются дополнительному хостинговому провайдеру инференса для обработки. Это особенно полезно при работе с приватными репозиториями, внутренними инструментами, чувствительным кодом или данными компании.
Вы также избегаете затрат и усилий на покупку, эксплуатацию и обслуживание собственного высокопроизводительного multi-GPU сервера.
Вместо этого вы арендуете мощные GPU по мере необходимости, сервите GLM-5.2 с llama.cpp, защищаете endpoint собственным API-ключом и подключаетесь с ноутбука через OpenCode.
В этом руководстве вы настроили мульти-GPU машину RunPod, установили предсобранный пакет llama.cpp, загрузили и запустили модель GLM-5.2 в формате GGUF и защитили сервер API-ключом.
Затем вы протестировали модель как через Web UI llama.cpp, так и через её OpenAI-совместимый cURL API, прежде чем опубликовать защищённый URL RunPod для внешнего доступа.
Наконец, вы подключили этот приватный endpoint модели к OpenCode, запущенному на вашем ноутбуке. Так формируется практичный гибридный процесс: GLM-5.2 работает на мощных арендованных GPU, а OpenCode остаётся внутри вашего локального проекта и может читать файлы, редактировать код, запускать тесты и использовать вашу оболочку.
Вы получаете производительность топовой модели, гибкость самостоятельного хостинга и гораздо больший контроль, чем со стандартным хостинговым API.
Лучшие курсы DataCamp
Track
Course
Course