
Lernpfad
Associate AI Engineer für Datenwissenschaftler
40 Std.
GLM-5.2 ist Z.ai’s neuestes offenes Vorzeigemodell, entwickelt für Coding über lange Aufgabenketten, komplexes Reasoning und agentische Engineering-Tasks. Es bietet ein Kontextfenster mit 1 Mio. Tokens, mehrere Denkmodi, Tool-Aufrufe und Verbesserungen, die dem Modell helfen, in großen Codebasen und mehrstufigen Aufgaben konsistent zu bleiben.
Das Vollmodell ist riesig, aber GGUF-Quantisierungen machen es möglich, GLM-5.2 lokal mit llama.cpp auf der passenden Hardware auszuführen.
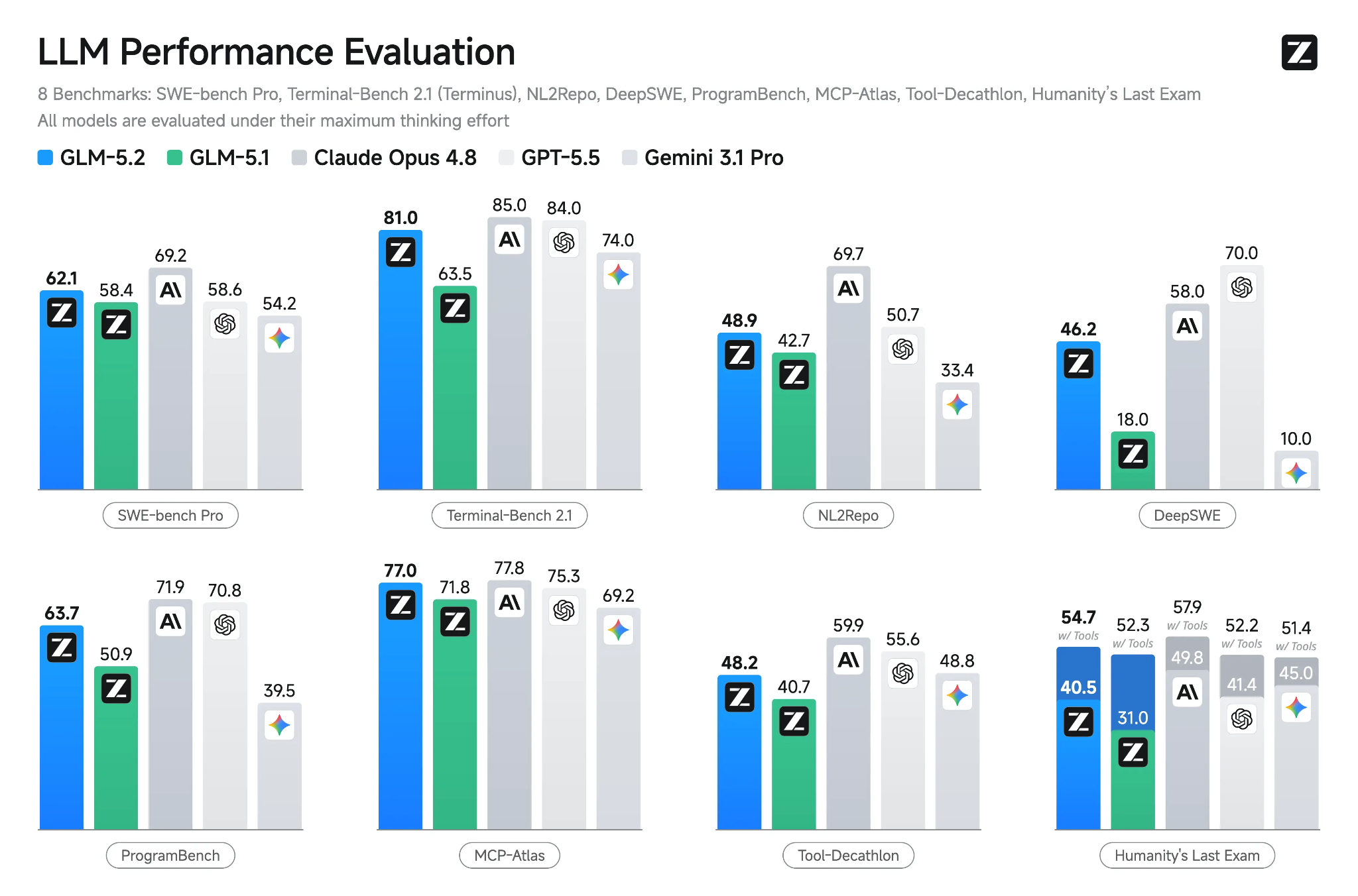
Quelle: GLM-5.2: Built for Long-Horizon Tasks
In diesem Guide zeige ich dir, wie du das vorgefertigte llama.cpp-Paket installierst und damit GLM-5.2 auf einer RunPod-GPU-Instanz bereitstellst.
Du startest den Server mit einem API-Schlüssel, testest den OpenAI-kompatiblen Endpunkt mit cURL und nutzt die integrierte Weboberfläche von llama.cpp im Browser.
Anschließend machst du den Server über die Proxy-URL von RunPod erreichbar, sodass du sicher von deinem Laptop oder anderen Anwendungen zugreifen kannst.
Zum Schluss verbindest du diesen gehosteten GLM-5.2-Server mit OpenCode, das lokal neben deinem Projekt läuft. So kann OpenCode Dateien lesen, Code bearbeiten, Tests ausführen und dein lokales Terminal nutzen, während GLM-5.2 das Reasoning remote übernimmt.
Wechsle in dein RunPod-Dashboard und erstelle einen neuen Pod. Bevor du ihn startest, stelle sicher, dass dein Konto mindestens 25 $ Guthaben hat, da GLM-5.2 ein großes Multi-GPU-Setup benötigt.
Wähle eine Maschine mit 4× RTX PRO 6000 GPUs. Sie bietet:
Bearbeite vor dem Deployment das Pod-Template. Erhöhe den Container-Speicher auf mindestens 550 GB und füge unter Expose HTTP Ports Folgendes hinzu:
8910Diesen Port verwendest du später für den llama.cpp-Server, die Weboberfläche und die OpenAI-kompatible API.
Für schnellere und stabilere Modelldownloads füge deinen Hugging-Face-Token als Umgebungsvariable ins Template ein:
HF_TOKEN=your_hugging_face_token
Wenn alles konfiguriert ist, deploye den Pod. Klicke nach dem Start auf Connect und öffne JupyterLab. Starte ein neues Terminal und führe aus:
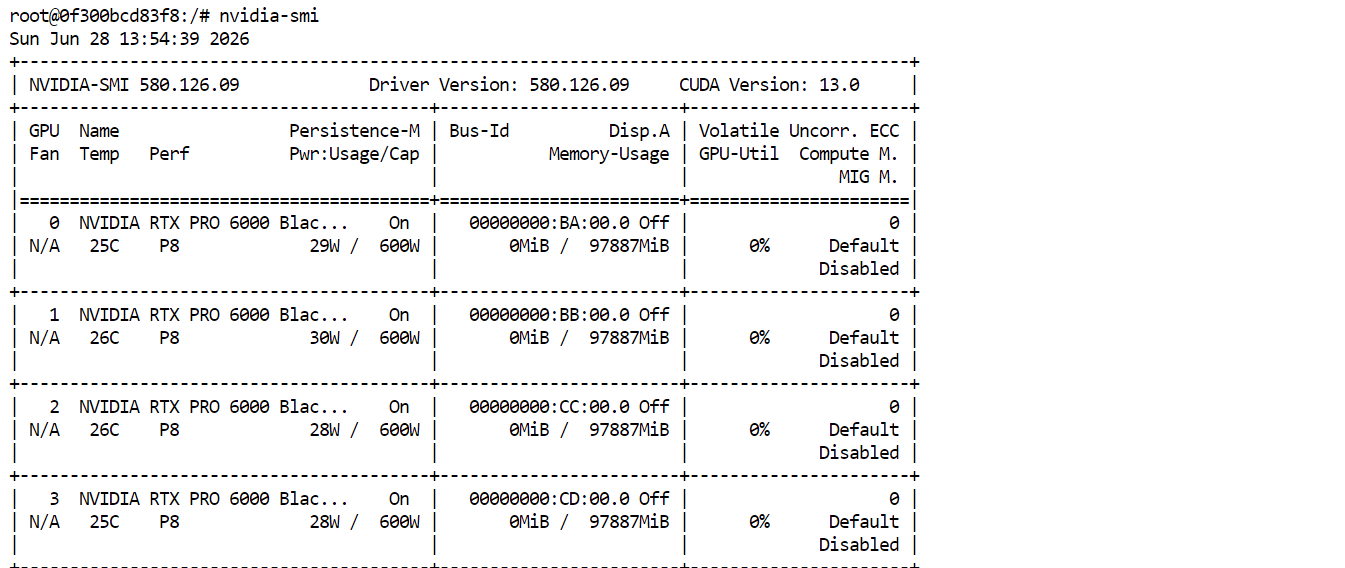
nvidia-smiDu solltest alle vier RTX PRO 6000 GPUs gelistet und verfügbar sehen. Das bestätigt, dass der Pod bereit ist, GLM-5.2 herunterzuladen und auszuführen.
Anstatt llama.cpp aus dem Quellcode zu kompilieren, installiere die neueste vorgefertigte Version mit dem offiziellen llama.app-Installer. Führe im JupyterLab-Terminal Folgendes aus:
curl -LsSf https://llama.app/install.sh | shFüge als Nächstes den Installationsordner von llama.cpp zu deinem PATH hinzu, damit du den Befehl llama in jedem Terminal ausführen kannst:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcLade deine Bash-Konfiguration neu, um die Änderung zu übernehmen:
source ~/.bashrcPrüfe abschließend, ob llama.cpp korrekt installiert wurde:
llama helpDu solltest die verfügbaren llama.cpp-Befehle sehen.

Lege als Nächstes einen persistenten Speicherort für die Modelldateien fest.
Das Verzeichnis /workspace von RunPod bleibt auch bei pausiertem Pod verfügbar. Es ist daher ein besserer Ort für den Hugging-Face-Cache als der Standardpfad.
Führe im JupyterLab-Terminal folgende Befehle aus:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"So werden heruntergeladene Modelldateien in /workspace/huggingface gespeichert.
Erstelle nun einen API-Schlüssel für deinen llama.cpp-Server. Verwende einen langen, zufälligen Wert und halte ihn privat. Du brauchst denselben Schlüssel später zum Testen der API und für die Verbindung mit OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Lege abschließend einen einfachen Alias für das Modell fest:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode verwendet später genau diesen Modell-Alias. Lass ihn in diesem Guide unverändert.
Jetzt kannst du den GLM-5.2-Server starten. Führe im selben Terminal folgenden Befehl aus:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaBeim ersten Lauf lädt llama.cpp die UD-IQ3_S-GGUF-Quantisierung von GLM-5.2 von Hugging Face herunter und speichert sie im zuvor konfigurierten Cache-Verzeichnis.
Der Download kann dauern, da das Modell sehr groß ist.
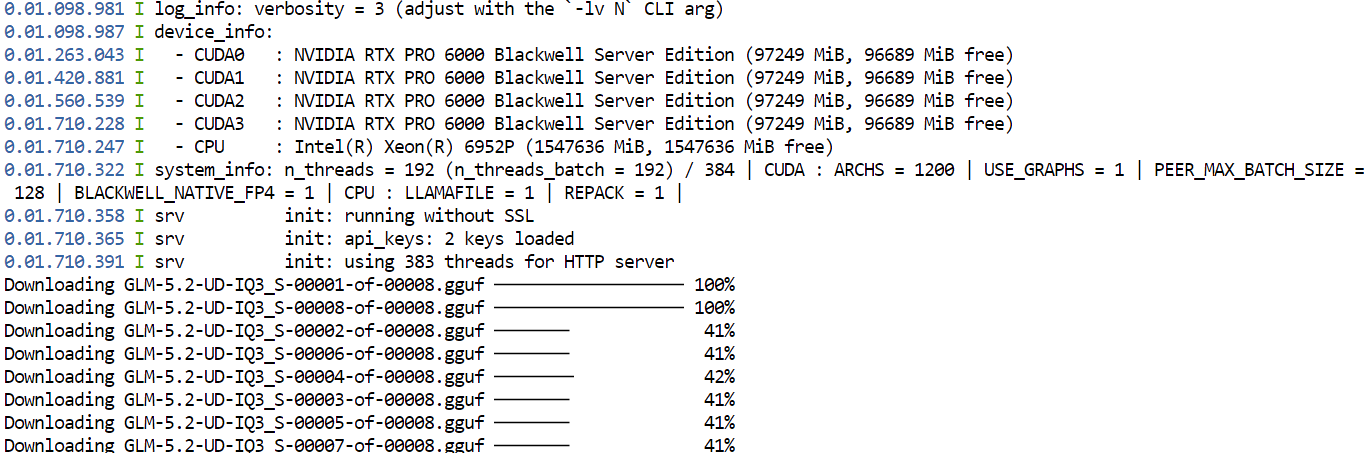
Nach dem Download lädt llama.cpp das Modell auf alle vier GPUs. Die Optionen --split-mode layer und --tensor-split 1,1,1,1 teilen das Modell gleichmäßig auf die verfügbaren GPUs auf, während Flash Attention die Performance verbessert.
Sobald das Modell erfolgreich geladen ist, ist der lokale Server hier erreichbar:
http://127.0.0.1:8910
Der Server ist durch den zuvor gesetzten API-Schlüssel geschützt. Lass dieses Terminal geöffnet, solange du das Modell nutzt; beim Schließen wird der Server gestoppt.
Öffne deinen RunPod-Pod und gehe zum Tab Connect. Klicke unter den freigegebenen HTTP-Ports auf den Link zu Port 8910. Dadurch öffnet sich die Weboberfläche von llama.cpp im Browser.
Die URL folgt diesem Muster:
https://YOUR_POD_ID-8910.proxy.runpod.netErsetze YOUR_POD_ID durch deine tatsächliche RunPod-Pod-ID, falls du die URL manuell eingeben musst.
Öffne in der Weboberfläche von llama.cpp die Settings und gehe zu General. Füge denselben API-Schlüssel ein, den du beim Starten des llama.cpp-Servers verwendet hast.
So kann die Weboberfläche ihre Anfragen authentifizieren und mit dem geschützten Server kommunizieren.
Du kannst das Modell jetzt mit einem einfachen Coding-Prompt testen:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
In diesem Setup generierte GLM-5.2 im Schnitt 41 Tokens pro Sekunde – ein guter Wert für ein Modell dieser Größe.
Auch die Antwortqualität war überzeugend: eine strukturierte Implementierung mit klaren Validierungsregeln und Testfällen.
Öffne ein zweites Terminal in JupyterLab. Das erste Terminal muss geöffnet bleiben, da dort der llama.cpp-Server läuft.
Setze im neuen Terminal die lokale API-URL, verwende denselben API-Schlüssel und setze den Modell-Alias:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Prüfe zuerst, ob der Server läuft und GLM-5.2 verfügbar ist:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Du solltest den Modell-Alias in der Antwort sehen:
glm-5.2-iq3sSende als Nächstes eine Testanfrage an den OpenAI-kompatiblen Chat-Completions-Endpunkt:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
Der Server gibt eine JSON-Antwort mit der Modellreaktion zurück.
In diesem Test erzeugte GLM-5.2 eine strukturierte Python-Implementierung mit Validierungslogik und pytest-Testfällen bei einer durchschnittlichen Generationsgeschwindigkeit von etwa 41 Tokens pro Sekunde.
Diese lokale URL funktioniert nur innerhalb des RunPod-Pods. Um denselben Server von deinem Laptop, OpenCode oder einer anderen externen Anwendung aus aufzurufen, verwende stattdessen die RunPod-Proxy-URL:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Ersetze YOUR_POD_ID durch deine tatsächliche RunPod-Pod-ID und verwende weiterhin denselben API-Schlüssel im Authorization-Header.
Installiere OpenCode auf dem Rechner, auf dem dein Codeprojekt liegt. Öffne ein Terminal und führe aus:
curl -fsSL https://opencode.ai/install | bashWechsle anschließend in deinen Projektordner:
cd /path/to/your/projectExportiere denselben API-Schlüssel, den du beim Start des llama.cpp-Servers auf RunPod verwendet hast:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode läuft lokal neben deinem Projekt, während GLM-5.2 weiterhin remote auf deinem RunPod-Pod ausgeführt wird. Dieses Setup erlaubt es OpenCode, deine Dateien zu lesen, Code zu bearbeiten, Tests auszuführen und dein lokales Terminal zu nutzen, während GLM-5.2 das Reasoning über die abgesicherte RunPod-API übernimmt.
Erstelle im Projektstamm eine Datei namens opencode.json und füge folgende Konfiguration hinzu:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Ersetze YOUR_POD_ID durch deine tatsächliche RunPod-Pod-ID. Die URL muss der RunPod-Proxy-URL entsprechen, mit der du die llama.cpp-Weboberfläche geöffnet hast.
Sobald die Datei opencode.json gespeichert ist, öffne im selben Projektordner ein Terminal und starte OpenCode:
opencodeFühre dann aus:
/modelsWähle:
GLM-5.2 UD-IQ3_S
OpenCode ist nun mit deinem GLM-5.2-Server verbunden. Es nutzt das Remote-Modell fürs Reasoning, während Projektdateien, Terminalbefehle, Code-Edits und Testausführung auf deinem eigenen Laptop bleiben.
Starte mit einem einfachen Test, um zu prüfen, ob OpenCode deinen GLM-5.2-Server erreicht und eine Antwort zurückgibt.
Gib in OpenCode ein:
hey
Bitte OpenCode anschließend, dein bestehendes Projekt zu inspizieren und zu erklären:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
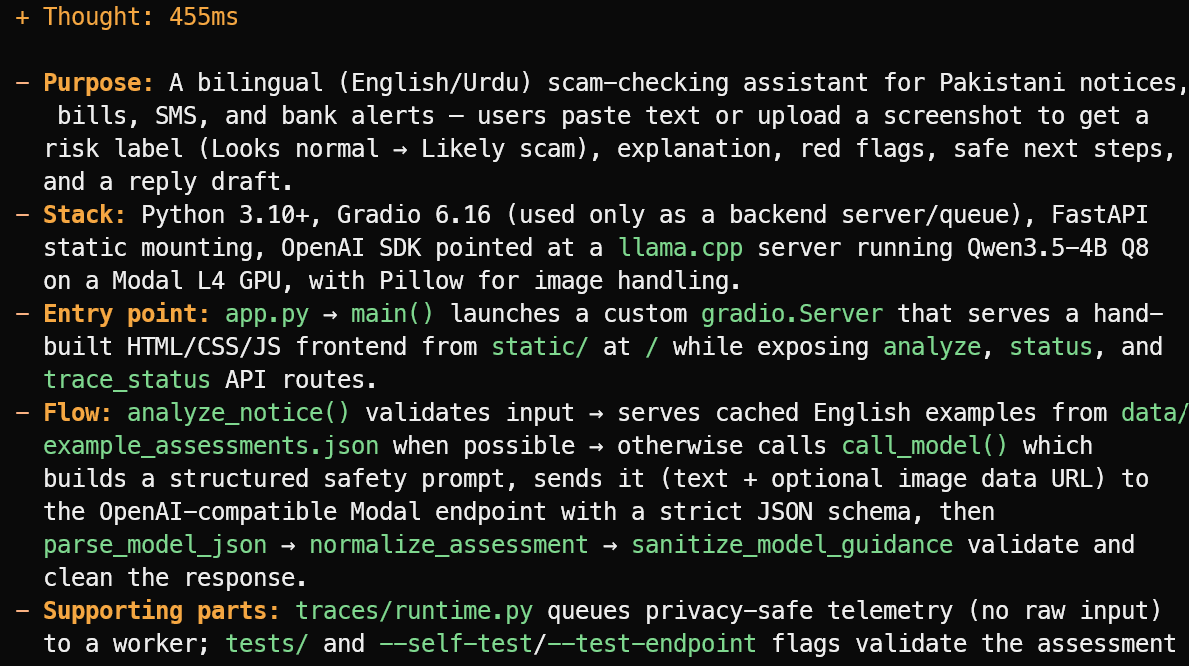
OpenCode liest die Projektdateien und liefert eine präzise Übersicht, statt zu raten. In diesem Beispiel hat es korrekt erkannt, dass das Projekt ein zweisprachiger (Englisch/Urdu) Scam-Checking-Assistent für pakistanische Bekanntmachungen, Rechnungen, SMS und Bankhinweise ist.
Außerdem erklärte es den Haupt-Stack, den Einstiegspunkt app.py, den Bewertungsfluss sowie unterstützende Test- und Telemetrie-Dateien.
Prompt:
Suggest one useful new feature that fits the project's current scope.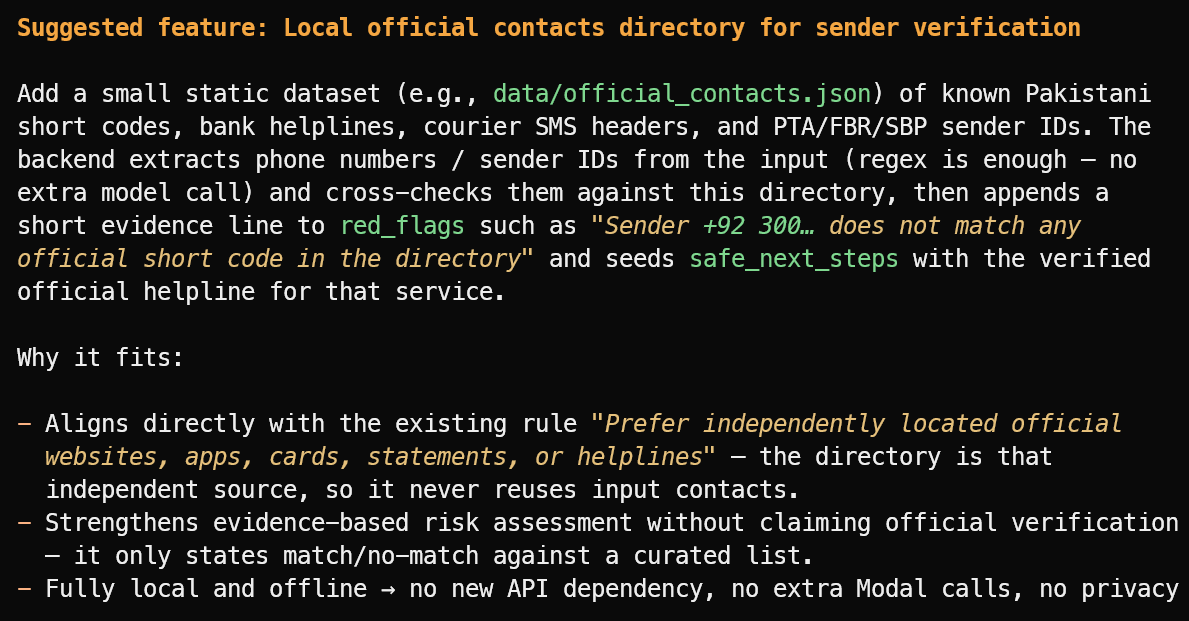
Vorgeschlagen wurde eine sinnvolle Erweiterung: ein lokales Verzeichnis verifizierter offizieller Absender-IDs, Bank-Hotlines, Kurier-Header und öffentlicher Kurzwahlnummern.
Um OpenCode an einer größeren Aufgabe zu testen, erstelle auf deinem Laptop einen neuen Projektordner:
mkdir ml-app
cd ml-app
opencodeGib OpenCode anschließend folgenden Prompt:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode erstellt zunächst eine Aufgabenliste und zerlegt das Projekt in handhabbare Schritte.
Dann erzeugt es die benötigten Anwendungsdateien, ML-Logik, Streamlit-Oberfläche, Abhängigkeiten und Test-Suite.
Nach Abschluss der Implementierung führt es die Tests aus, behebt gefundene Probleme und liefert eine klare Zusammenfassung des fertigen Projekts inklusive des Startbefehls.
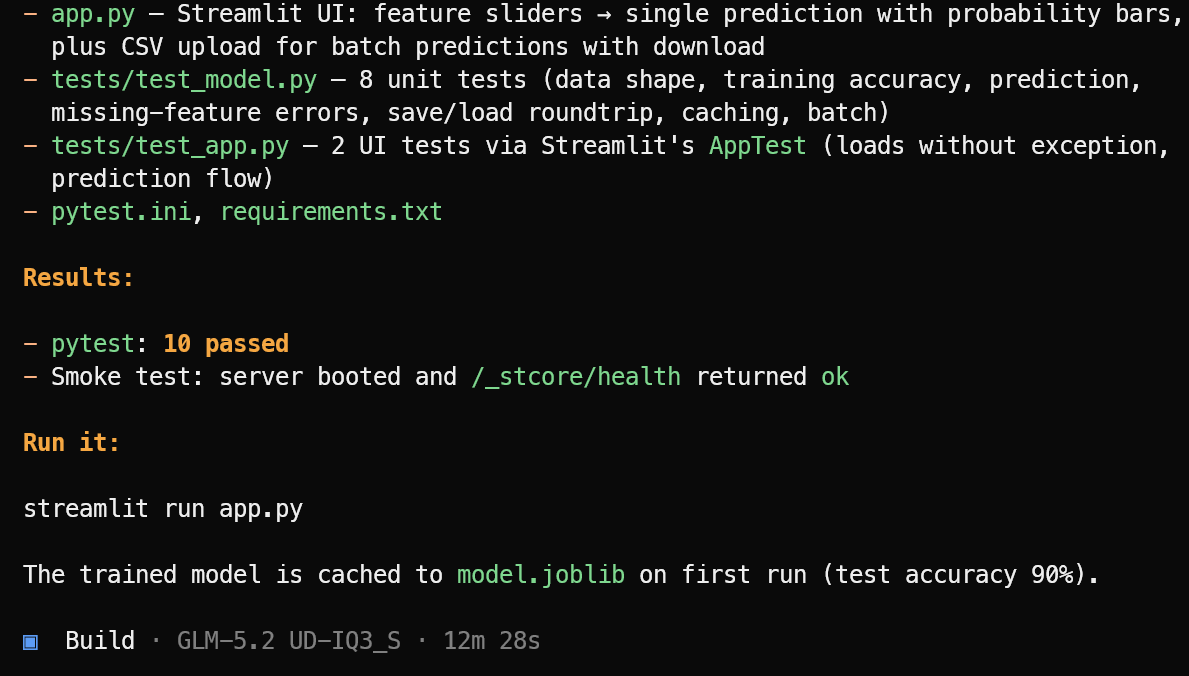
In diesem Test schloss OpenCode 10 erfolgreiche Tests ab und verifizierte, dass die Streamlit-App erfolgreich startete. Starte die Machine-Learning-Anwendung mit:
streamlit run app.pyDie resultierende Anwendung ist aufgeräumt und funktioniert wie erwartet.
Selbst mit der 3-Bit-Quantisierung von GLM-5.2 war die Reasoning-Qualität in diesen Tests stark.
Das Modell verstand das bestehende Projekt, schlug eine passende Funktion vor, erstellte eine komplette Webanwendung, nutzte Tools zum Inspizieren und Ändern von Dateien und führte Tests zur Verifikation aus.
Dieses Setup gibt dir etwas, das Standard-API-Anbieter nicht liefern: deinen eigenen, privat gehosteten GLM-5.2-Server.
Anstatt jede Anfrage an eine geteilte Modellplattform mit festen Limits, Voreinstellungen und Tokenpreisen zu senden, mietest du die GPU-Maschine, deployst das Modell selbst und kontrollierst den gesamten Serving-Stack.
Du bestimmst die Quantisierung, GPU-Konfiguration, das Kontextfenster, die Servereinstellungen, den API-Schlüssel und, wer Zugriff auf den Endpunkt hat.
Dein Code, deine Prompts, der Projektkontext und die API-Antworten bleiben in der Infrastruktur, die du kontrollierst: auf deinem eigenen Laptop und deiner eigenen RunPod-Installation.
Sie werden nicht an einen zusätzlichen gehosteten Inferenz-Anbieter gesendet. Das ist besonders hilfreich, wenn du mit privaten Repositories, internen Tools, vertraulichem Code oder Unternehmensdaten arbeitest.
Gleichzeitig vermeidest du Kosten und Aufwand für Kauf, Betrieb und Wartung eines eigenen High-End-Multi-GPU-Servers.
Stattdessen kannst du leistungsstarke GPUs nur bei Bedarf mieten, GLM-5.2 mit llama.cpp serven, den Endpunkt mit deinem eigenen API-Schlüssel absichern und über OpenCode von deinem Laptop aus verbinden.
In diesem Guide hast du eine Multi-GPU-RunPod-Maschine konfiguriert, das vorgefertigte llama.cpp-Paket installiert, das GLM-5.2-GGUF-Modell heruntergeladen und bereitgestellt und den Server mit einem API-Schlüssel geschützt.
Anschließend hast du das Modell sowohl über die llama.cpp-Weboberfläche als auch über die OpenAI-kompatible cURL-API getestet, bevor du die abgesicherte RunPod-URL für den externen Zugriff freigegeben hast.
Zum Schluss hast du diesen privaten Modell-Endpunkt mit OpenCode auf deinem Laptop verbunden. Das ergibt einen praktischen Hybrid-Workflow: GLM-5.2 läuft auf leistungsstarken gemieteten GPUs, während OpenCode in deinem lokalen Projekt bleibt und Dateien inspizieren, Code bearbeiten, Tests ausführen und dein Shell-Umfeld nutzen kann.
So bekommst du die Performance eines Top-Modells, die Flexibilität des Self-Hostings und deutlich mehr Kontrolle als mit einer Standard-API.
Top-DataCamp-Kurse
Lernpfad
Kurs
Kurs