
Program
Veri Bilimcileri için Yardımcı Yapay Zeka Mühendisi
40 sa
GLM-5.2, Z.ai’ın uzun vadeli kodlama, akıl yürütme ve ajans mühendisliği görevleri için geliştirilmiş en yeni amiral gemisi açık modelidir. 1M token bağlam penceresi, birden çok düşünme modu, araç çağırma desteği ve modelin geniş kod tabanları ve çok adımlı görevlerde tutarlı kalmasına yardımcı olacak iyileştirmelerle birlikte gelir.
Tam model çok büyük olsa da, GGUF kuantizasyonları, uygun donanımda llama.cpp kullanarak GLM-5.2’yi yerel olarak çalıştırmayı mümkün kılar.
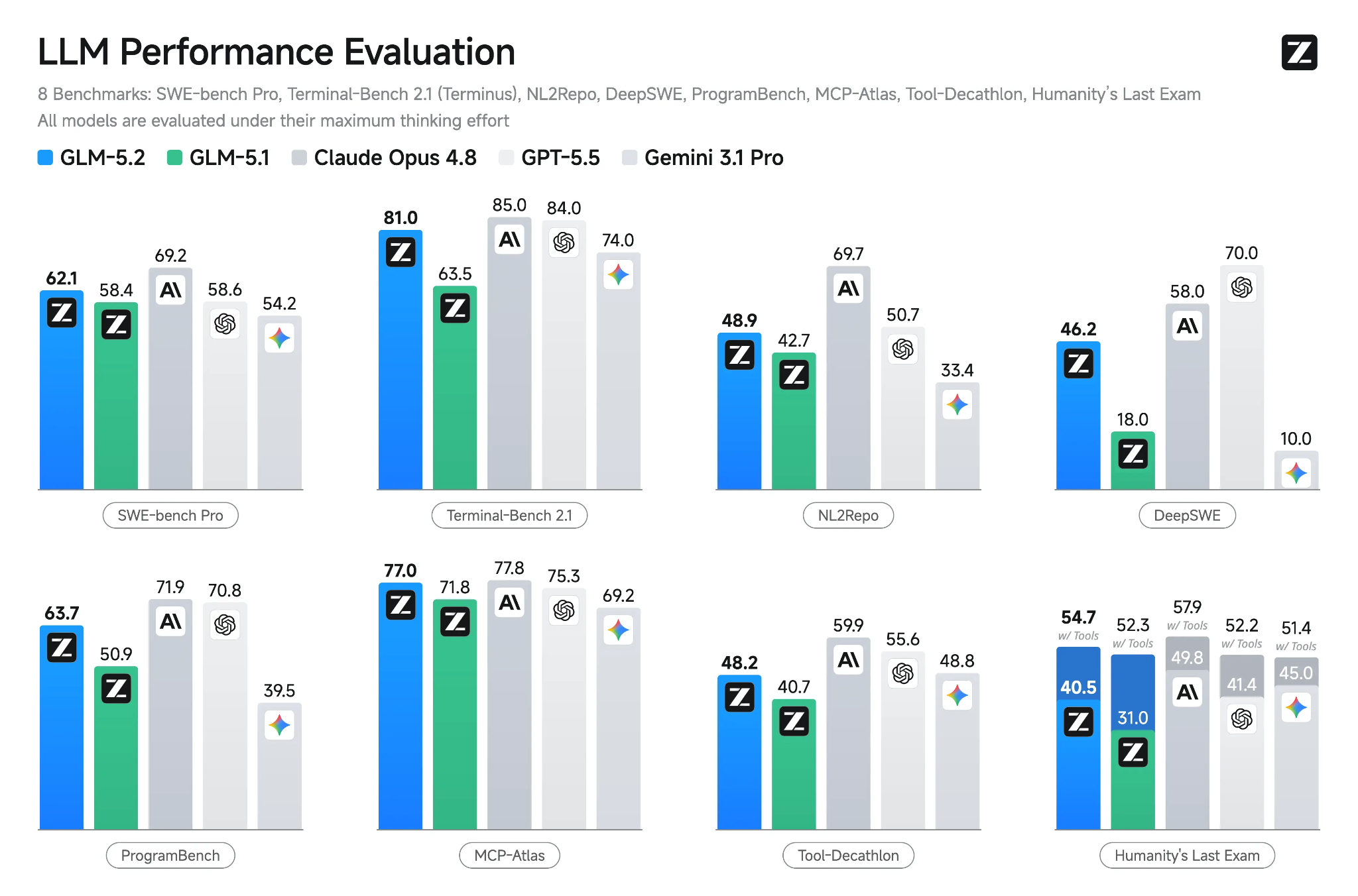
Kaynak: GLM-5.2: Uzun Vadeli Görevler İçin Tasarlandı
Bu kılavuzda, önceden derlenmiş llama.cpp paketini nasıl kuracağınızı ve GLM-5.2’yi bir RunPod GPU örneğinde sunmak için nasıl kullanacağınızı göstereceğim.
Sunucuyu bir API anahtarıyla başlatacak, OpenAI uyumlu uç noktasını cURL ile test edecek ve llama.cpp’nin yerleşik Web UI’ını tarayıcınızda kullanacaksınız.
Ardından, sunucuyu RunPod’un vekil (proxy) URL’si üzerinden dışarı açarak dizüstü bilgisayarınızdan veya diğer uygulamalardan güvenli şekilde erişilebilmesini sağlayacaksınız.
Son olarak, barındırılan bu GLM-5.2 sunucusunu projenizin yanında yerel olarak çalışan OpenCode’a bağlayacak, böylece OpenCode dosyaları okuyup düzenleyebilir, testleri çalıştırabilir ve yerel kabuğunuzu kullanırken GLM-5.2 akıl yürütmeyi uzaktan üstlenir.
RunPod kontrol panelinize gidin ve yeni bir Pod oluşturun. Başlatmadan önce hesabınızda en az 25 $ kredi bulunduğundan emin olun; çünkü GLM-5.2 büyük, çoklu GPU kurulumuna ihtiyaç duyar.
Şu özellikleri sağlayan 4× RTX PRO 6000 GPU’lu bir makine seçin:
Dağıtmadan önce Pod şablonunu düzenleyin. Konteyner disk alanını en az 550 GB’a çıkarın ve Expose HTTP Ports bölümüne şunu ekleyin:
8910Bu bağlantı noktası daha sonra llama.cpp sunucusu, Web UI ve OpenAI uyumlu API için kullanılacaktır.
Daha hızlı ve güvenilir model indirmeleri için Hugging Face belirtecinizi (token) şablonda bir ortam değişkeni olarak ekleyin:
HF_TOKEN=your_hugging_face_token
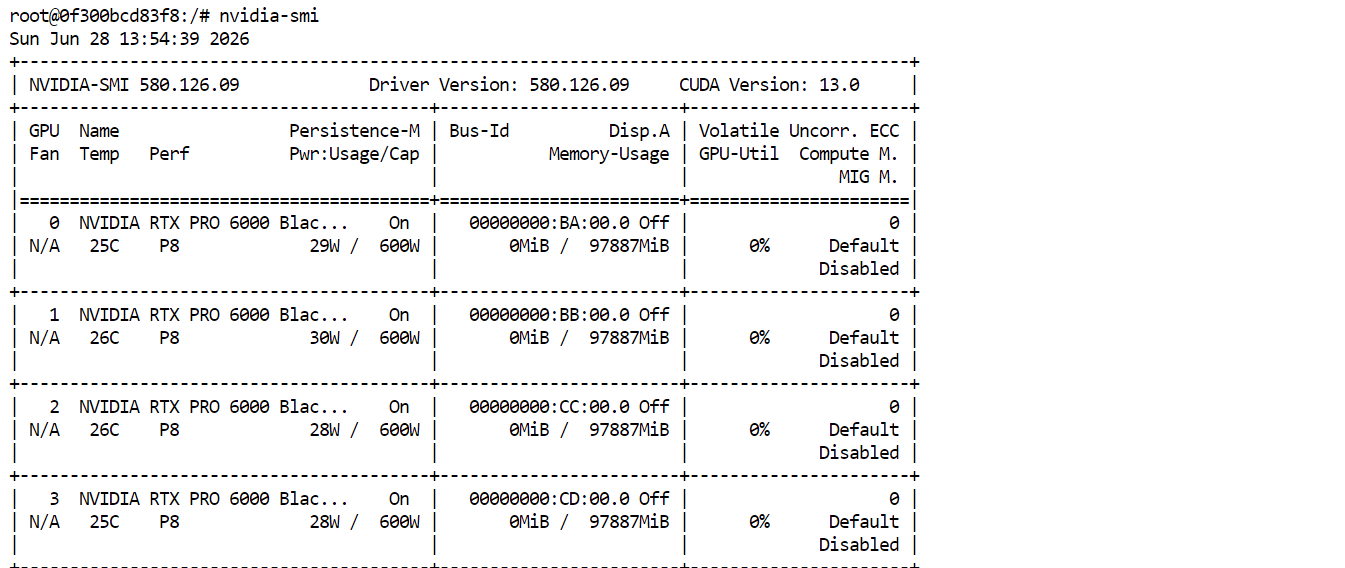
Her şey yapılandırıldıktan sonra Pod’u dağıtın. Başladıktan sonra Connect’e tıklayın ve JupyterLab’i açın. Yeni bir terminal başlatın ve şunu çalıştırın:
nvidia-smiDört adet RTX PRO 6000 GPU’nun listelendiğini ve kullanılabilir olduğunu görmelisiniz. Bu, Pod’un GLM-5.2’yi indirmeye ve çalıştırmaya hazır olduğunu doğrular.
llama.cpp’yi kaynaktan derlemek yerine, resmi llama.app yükleyicisini kullanarak en son önceden derlenmiş sürümü kurun. JupyterLab terminalinizde aşağıdaki komutu çalıştırın:
curl -LsSf https://llama.app/install.sh | shArdından, llama komutunu herhangi bir terminalden çalıştırabilmek için llama.cpp kurulum klasörünü PATH’inize ekleyin:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcDeğişikliği uygulamak için Bash yapılandırmanızı yeniden yükleyin:
source ~/.bashrcSon olarak, llama.cpp’nin doğru kurulduğunu doğrulayın:
llama helpKullanılabilir llama.cpp komutlarını görmelisiniz.

Sırada, model dosyaları için kalıcı bir konum yapılandırmak var.
RunPod’un /workspace dizini, pod’u duraklatsanız bile erişilebilir kaldığından, Hugging Face önbelleğini varsayılan konum yerine burada tutmak daha iyidir.
JupyterLab terminalinde aşağıdaki komutları çalıştırın:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Bu, indirilen model dosyalarının /workspace/huggingface konumunda saklanmasını sağlar.
Şimdi llama.cpp sunucunuz için bir API anahtarı oluşturun. Uzun ve rastgele bir değer kullanın ve gizli tutun; çünkü aynı anahtara API’yi test ederken ve OpenCode’a bağlanırken de ihtiyaç duyacaksınız:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Son olarak, model için basit bir takma ad (alias) belirleyin:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode daha sonra tam olarak bu model takma adını kullanacaktır; bu kılavuz boyunca değiştirmeyin.
Artık GLM-5.2 sunucusunu başlatmaya hazırsınız. Aynı terminalde aşağıdaki komutu çalıştırın:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaBu komutu ilk kez çalıştırdığınızda, llama.cpp Hugging Face’ten GLM-5.2’nin UD-IQ3_S GGUF kuantizasyonunu indirir ve daha önce yapılandırdığınız önbellek dizinine kaydeder.
Model çok büyük olduğundan indirme biraz zaman alabilir.
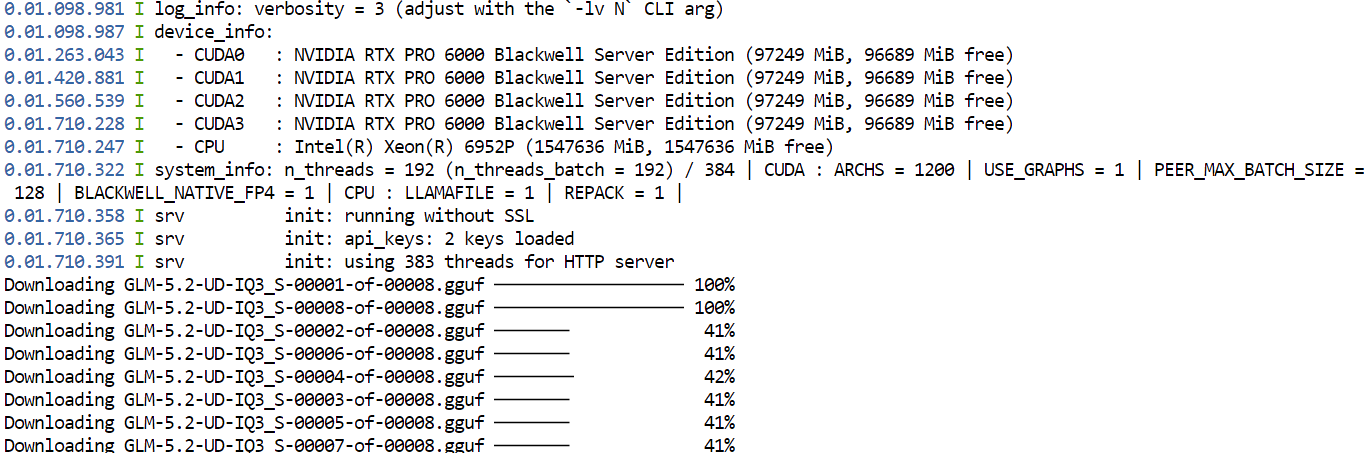
İndirme tamamlandıktan sonra, llama.cpp modeli dört GPU’nun tamamına yükleyecektir. --split-mode layer ve --tensor-split 1,1,1,1 ayarları modeli mevcut GPU’lara eşit şekilde dağıtırken Flash Attention performansı artırmaya yardımcı olur.
Model başarıyla yüklendiğinde, yerel sunucu şu adreste kullanılabilir olacaktır:
http://127.0.0.1:8910
Sunucu, daha önce belirlediğiniz API anahtarıyla korunur. Modeli kullanırken bu terminali açık tutun; kapatırsanız sunucu durur.
RunPod Pod’unuzu açın ve Connect sekmesine gidin. Dışarı açılan HTTP portları altında, 8910 portuyla ilişkili bağlantıya tıklayın. Bu, tarayıcınızda llama.cpp Web UI’ını açacaktır.
URL şu biçimde olacaktır:
https://YOUR_POD_ID-8910.proxy.runpod.netYOUR_POD_ID’yi URL’yi elle girmeniz gerektiğinde gerçek RunPod Pod ID’nizle değiştirin.
llama.cpp Web UI’ında Settings’i açın ve General bölümüne gidin. llama.cpp sunucusunu başlatırken kullandığınız aynı API anahtarını yapıştırın.
Bu işlem, Web UI’ın isteklerini doğrulamasına ve korumalı sunucuyla iletişim kurmasına olanak tanır.
Artık modeli basit bir kodlama istemiyle test edebilirsiniz:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
Bu kurulumda, GLM-5.2 ortalama olarak saniyede 41 token civarında üretim yaptı; bu boyuttaki bir model için iyi bir hızdır.
Yanıt kalitesi de güçlüydü; açık doğrulama kuralları ve testlerle yapılandırılmış bir uygulama üretti.
JupyterLab’de ikinci bir terminal açın. İlk terminal llama.cpp sunucusunu çalıştırdığı için açık kalmalıdır.
Yeni terminalde yerel API URL’sini ayarlayın, aynı API anahtarını yeniden kullanın ve model takma adını belirleyin:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Önce sunucunun çalıştığını ve GLM-5.2’nin kullanılabilir olduğunu kontrol edin:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Yanıtta model takma adını görmelisiniz:
glm-5.2-iq3sArdından, OpenAI uyumlu sohbet tamamlama uç noktasına bir test isteği gönderin:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
Sunucu, modelin yanıtını içeren bir JSON döndürecektir.
Bu testte, GLM-5.2 ortalama yaklaşık saniyede 41 token hızında, doğrulama mantığı ve pytest testleri içeren yapılandırılmış bir Python uygulaması üretti.
Bu yerel URL yalnızca RunPod Pod’unun içinde çalışır. Aynı sunucuyu dizüstü bilgisayarınızdan, OpenCode’dan veya başka bir harici uygulamadan çağırmak için bunun yerine RunPod proxy URL’sini kullanın:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"YOUR_POD_ID’yi gerçek RunPod Pod ID’nizle değiştirin ve Authorization başlığında aynı API anahtarını kullanmaya devam edin.
Kod projenizin bulunduğu bilgisayara OpenCode’u kurun. Bir terminal açın ve şunu çalıştırın:
curl -fsSL https://opencode.ai/install | bashArdından proje klasörünüze geçin:
cd /path/to/your/projectRunPod’da llama.cpp sunucusunu başlatırken kullandığınız aynı API anahtarını dışa aktarın:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode projenizin yanında yerel olarak çalışırken GLM-5.2 RunPod Pod’unuzda uzaktan çalışmayı sürdürür. Bu kurulum, OpenCode’un dosyalarınızı okumasına, kodu düzenlemesine, testleri çalıştırmasına ve yerel terminalinizi kullanmasına olanak tanır; GLM-5.2 ise güvenli RunPod API’si üzerinden akıl yürütmeyi üstlenir.
Proje kök dizininizde opencode.json adlı bir dosya oluşturun ve aşağıdaki yapılandırmayı ekleyin:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}YOUR_POD_ID’yi gerçek RunPod Pod ID’nizle değiştirin. URL, llama.cpp Web UI’ını açarken kullandığınız RunPod proxy URL’siyle eşleşmelidir.
opencode.json dosyası kaydedildikten sonra aynı proje klasöründe bir terminal açın ve OpenCode’u başlatın:
opencodeArdından şunu çalıştırın:
/modelsŞunu seçin:
GLM-5.2 UD-IQ3_S
OpenCode artık GLM-5.2 sunucunuza bağlı. Mantık yürütme için uzak modeli kullanırken proje dosyalarını, terminal komutlarını, kod düzenlemelerini ve test yürütmeyi kendi dizüstü bilgisayarınızda tutacaktır.
OpenCode’un GLM-5.2 sunucunuza erişip yanıt döndürebildiğini onaylamak için basit bir testle başlayın.
OpenCode’da şunu yazın:
hey
Ardından OpenCode’dan mevcut projenizi inceleyip açıklamasını isteyin:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
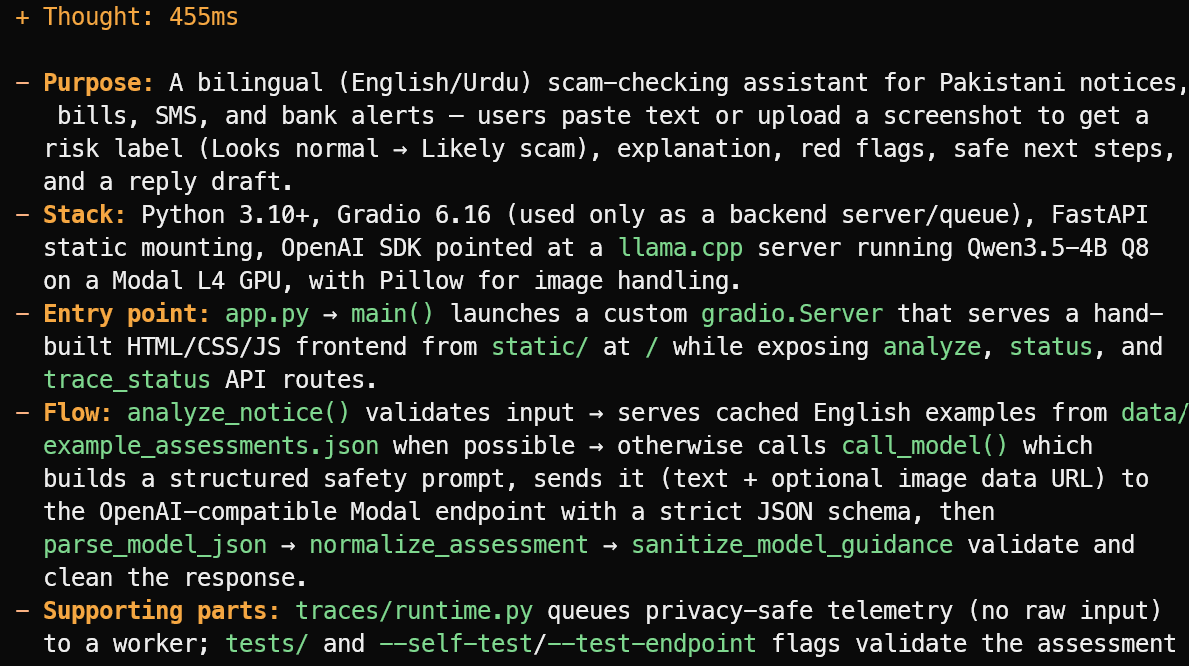
OpenCode proje dosyalarını okuyarak tahmin etmek yerine özlü bir genel bakış verir. Bu örnekte, projenin Pakistan’daki bildirimler, faturalar, SMS’ler ve banka uyarıları için iki dilli İngilizce/Urdu dolandırıcılık kontrol asistanı olduğunu doğru şekilde belirledi.
Ayrıca ana yığını, app.py giriş noktasını, değerlendirme akışını ve destekleyici test ile telemetri dosyalarını açıkladı.
İstem:
Suggest one useful new feature that fits the project's current scope.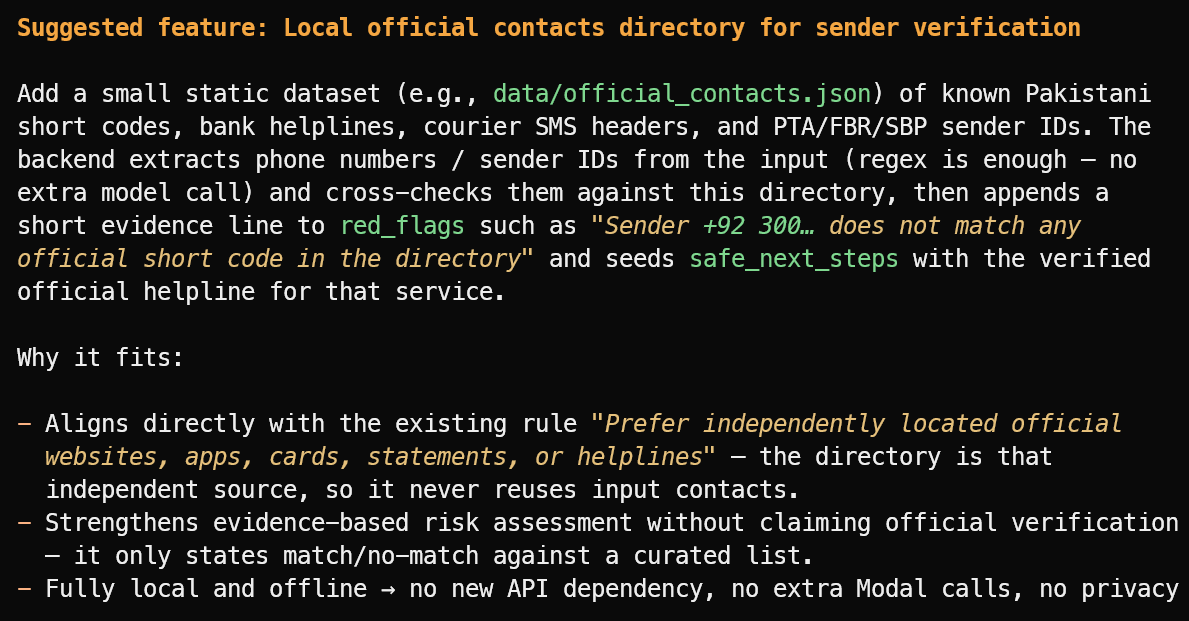
Faydalı bir özellik önerdi: doğrulanmış resmi gönderici kimlikleri, banka yardım hatları, kargo başlıkları ve kamu kısa kodlarının yerel bir dizini.
OpenCode’u daha büyük bir görevde test etmek için dizüstü bilgisayarınızda yeni bir proje klasörü oluşturun:
mkdir ml-app
cd ml-app
opencodeArdından OpenCode’a şu istemi verin:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode önce bir görev listesi oluşturur ve projeyi yönetilebilir adımlara böler.
Daha sonra gerekli uygulama dosyalarını, makine öğrenimi mantığını, Streamlit arayüzünü, bağımlılıkları ve test paketini oluşturur.
Uygulama tamamlandığında, testleri çalıştırır, bulduğu sorunları düzeltir ve tamamlanan projeye dair net bir özet ile onu başlatmak için gereken komutu sağlar.
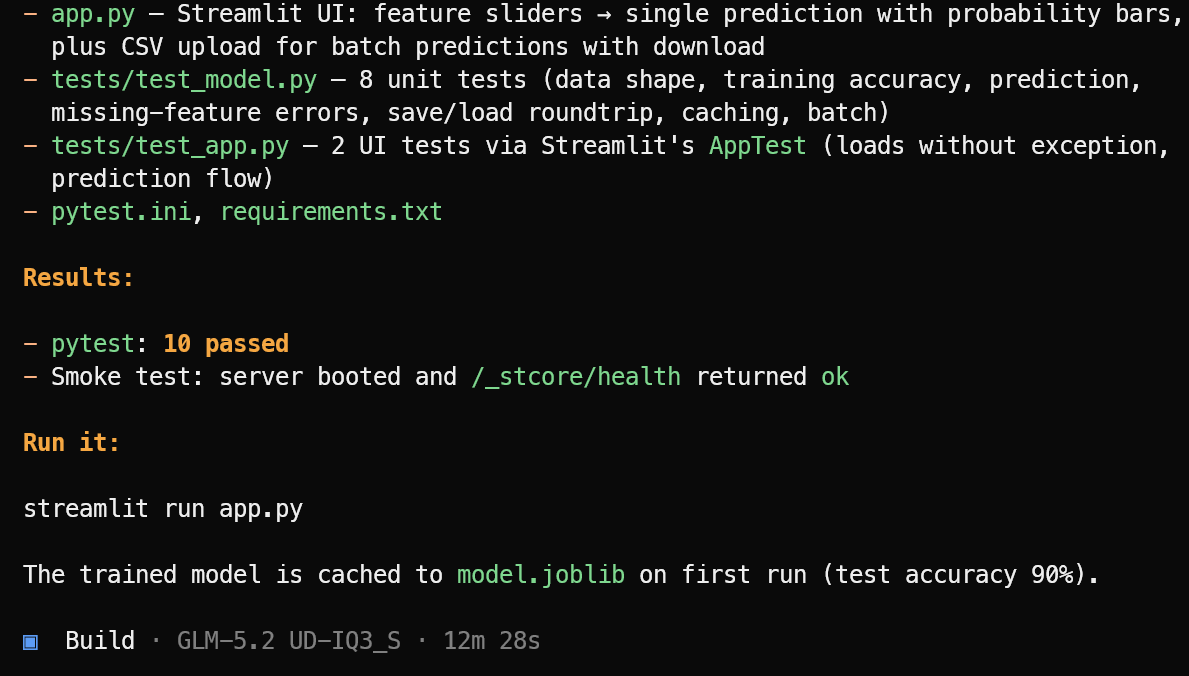
Bu testte, OpenCode 10 geçen testi tamamladı ve Streamlit uygulamasının başarıyla başlatıldığını doğruladı. Makine öğrenimi uygulamasını şu komutla başlatın:
streamlit run app.pyOrtaya çıkan uygulama temiz görünüyor ve beklendiği gibi çalışıyor.
GLM-5.2’nin 3 bit kuantize sürümüyle bile, bu testlerde akıl yürütme kalitesi güçlüydü.
Mevcut projeyi anladı, ilgili bir özellik önerdi, eksiksiz bir web uygulaması oluşturdu, dosyaları incelemek ve değiştirmek için araçlar kullandı ve çalışmasını doğrulamak için testler yürüttü.
Bu kurulum size standart API sağlayıcılarının sunmadığı bir şey verir: size özel barındırılan bir GLM-5.2 sunucusu.
Sabit limitler, model ayarları ve token başına fiyatlandırmaya sahip paylaşımlı bir model platformuna her isteği göndermek yerine, GPU makinesini kiralar, modeli kendiniz dağıtır ve tüm servis yığınını kontrol edersiniz.
Model kuantizasyonunu, GPU yapılandırmasını, bağlam penceresini, sunucu ayarlarını, API anahtarını ve uç noktaya kimin erişebileceğini siz seçersiniz.
Kodunuz, istemleriniz, proje bağlamınız ve API yanıtlarınız sizin kontrolünüzdeki altyapıda kalır: kendi dizüstü bilgisayarınız ve kendi RunPod dağıtımınız.
İşleme için ek bir barındırılan çıkarım sağlayıcısına gönderilmezler. Bu, özel depolar, dahili araçlar, hassas kod veya şirket verileriyle çalışırken özellikle kullanışlıdır.
Ayrıca yüksek düzey çoklu GPU’lu bir sunucuyu satın alma, çalıştırma ve bakım maliyeti ile uğraşmazsınız.
Bunun yerine, güçlü GPU’ları yalnızca ihtiyaç duyduğunuzda kiralayabilir, GLM-5.2’yi llama.cpp ile sunabilir, uç noktayı kendi API anahtarınızla güvence altına alabilir ve dizüstü bilgisayarınızdan OpenCode aracılığıyla bağlanabilirsiniz.
Bu kılavuzda çoklu GPU’lu bir RunPod makinesi yapılandırdınız, önceden derlenmiş llama.cpp paketini kurdunuz, GLM-5.2 GGUF modelini indirip sundunuz ve sunucuyu bir API anahtarıyla korudunuz.
Ardından, güvenli RunPod URL’sini dış erişim için açmadan önce modeli hem llama.cpp Web UI hem de OpenAI uyumlu cURL API’si üzerinden test ettiniz.
Son olarak, bu özel model uç noktasını dizüstü bilgisayarınızda çalışan OpenCode’a bağladınız. Böylece pratik bir hibrit iş akışı oluştu: GLM-5.2 güçlü kiralık GPU’larda çalışırken OpenCode yerel projenizin içinde kalır ve dosyaları inceleyebilir, kodu düzenleyebilir, testleri çalıştırabilir ve kabuğunuzu kullanabilir.
Üst düzey bir modelin performansını, kendi kendine barındırmanın esnekliğini ve standart barındırılan bir API’ye kıyasla çok daha fazla kontrol elde edersiniz.
En İyi DataCamp Kursları
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
