
Leerpad
AI-ingenieur voor datawetenschappers
40 Hr
GLM-5.2 is het nieuwste open vlaggenschipmodel van Z.ai, gebouwd voor coding op lange termijn, redeneren en agentic engineering-taken. Het heeft een contextvenster van 1M tokens, meerdere denkmodi, ondersteuning voor tool-calling en verbeteringen die het model helpen consistent te blijven over grote codebases en meerstapstaken.
Hoewel het volledige model enorm is, maken GGUF-kwantisaties het mogelijk om GLM-5.2 lokaal te draaien met llama.cpp op de juiste hardware.
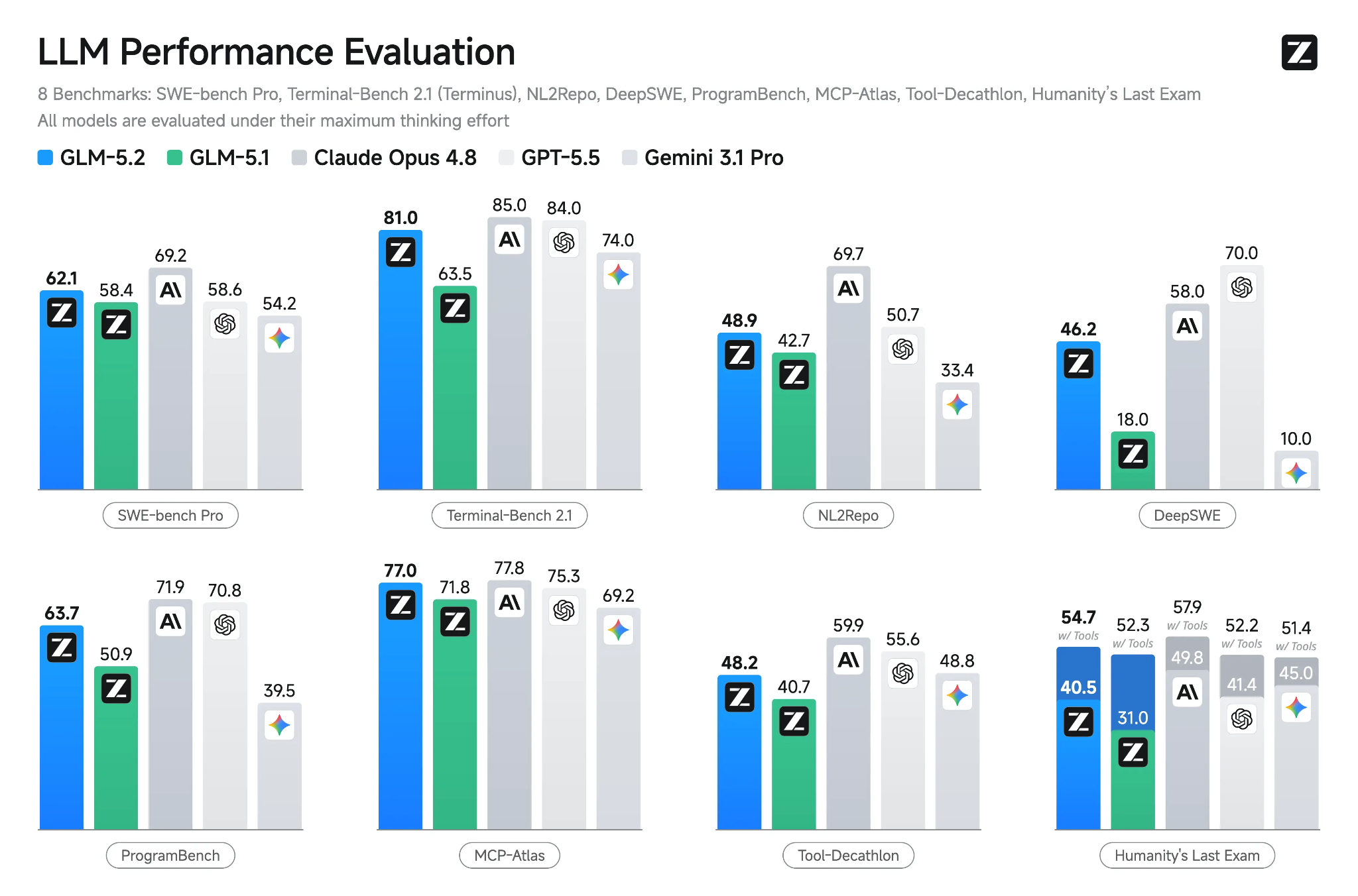
Bron: GLM-5.2: Built for Long-Horizon Tasks
In deze gids laat ik je zien hoe je het vooraf gebouwde llama.cpp-pakket installeert en het gebruikt om GLM-5.2 te serven op een RunPod GPU-instance.
Je start de server met een API-sleutel, test het OpenAI-compatibele endpoint met cURL en gebruikt de ingebouwde Web UI van llama.cpp in je browser.
Vervolgens stel je de server bloot via de proxy-URL van RunPod zodat deze veilig bereikbaar is vanaf je laptop of andere toepassingen.
Tot slot koppel je die gehoste GLM-5.2-server aan OpenCode die lokaal naast je project draait, zodat OpenCode bestanden kan lezen, code kan bewerken, tests kan uitvoeren en je lokale shell kan gebruiken terwijl GLM-5.2 op afstand het redeneren verzorgt.
Ga naar je RunPod-dashboard en maak een nieuwe Pod. Zorg ervoor dat je account minstens $25 tegoed heeft voordat je hem start, omdat GLM-5.2 een grote multi-GPU-setup vereist.
Selecteer een machine met 4× RTX PRO 6000 GPU's, die het volgende biedt:
Bewerk vóór het deployen de Pod-template. Verhoog de container-schijfruimte naar minstens 550 GB en voeg het volgende toe onder Expose HTTP Ports:
8910Deze poort wordt later gebruikt voor de llama.cpp-server, Web UI en OpenAI-compatibele API.
Voor snellere en betrouwbaardere modeldownloads voeg je je Hugging Face-token toe als omgevingsvariabele in de template:
HF_TOKEN=your_hugging_face_token
Als alles is geconfigureerd, deploy je de Pod. Klik nadat hij is gestart op Connect en open JupyterLab. Start een nieuwe terminal en voer uit:
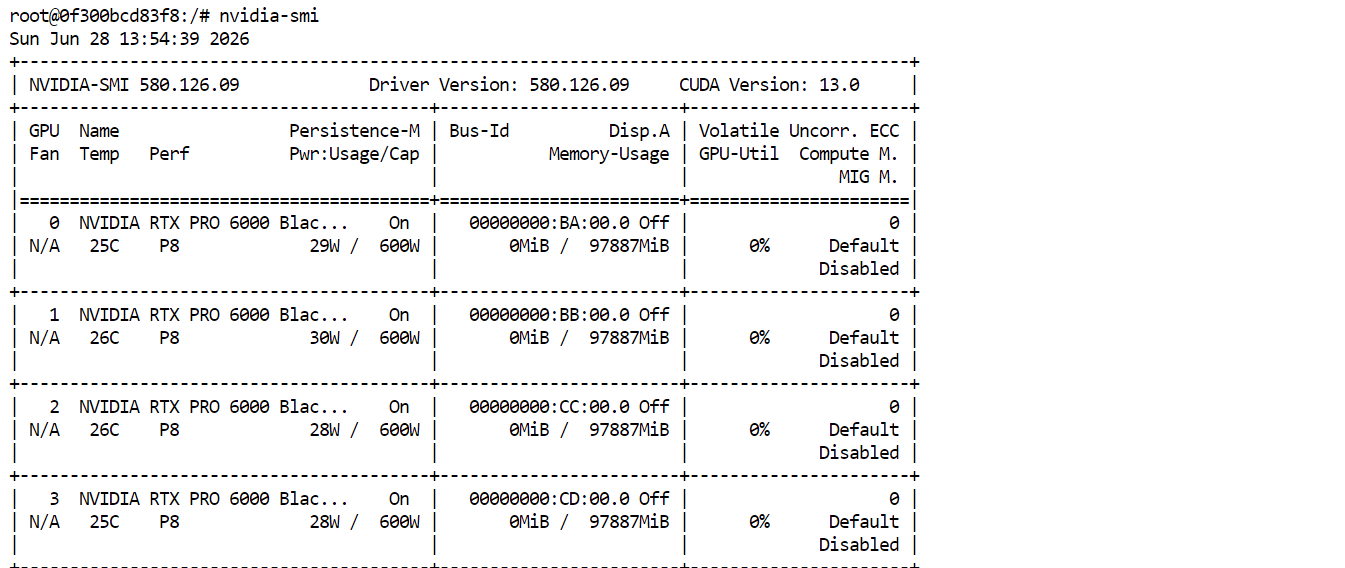
nvidia-smiJe zou alle vier de RTX PRO 6000 GPU's moeten zien en beschikbaar hebben. Dit bevestigt dat de Pod klaar is om GLM-5.2 te downloaden en te draaien.
In plaats van llama.cpp uit de bron te compileren, installeer je de nieuwste vooraf gebouwde versie met de officiële installer van llama.app. Voer de volgende opdracht uit in je JupyterLab-terminal:
curl -LsSf https://llama.app/install.sh | shVoeg vervolgens de installatie-map van llama.cpp toe aan je PATH zodat je het llama-commando vanuit elke terminal kunt uitvoeren:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrcHerlaad je Bash-configuratie om de wijziging toe te passen:
source ~/.bashrcControleer tot slot dat llama.cpp correct is geïnstalleerd:
llama helpJe zou de beschikbare llama.cpp-commando's moeten zien.

Configureer vervolgens een persistente locatie voor de modelbestanden.
De /workspace-map van RunPod blijft beschikbaar, zelfs wanneer je de pod pauzeert, dus dat is een betere plek om de Hugging Face-cache op te slaan dan de standaardlocatie.
Voer de volgende commando's uit in de JupyterLab-terminal:
export HF_HOME="/workspace/huggingface"
mkdir -p "$HF_HOME"Dit zorgt ervoor dat gedownloade modelbestanden worden opgeslagen in /workspace/huggingface.
Maak nu een API-sleutel voor je llama.cpp-server. Gebruik een lange, willekeurige waarde en houd deze privé, want je hebt dezelfde sleutel later nodig bij het testen van de API en het koppelen van OpenCode:
export LLAMA_API_KEY="replace-this-with-a-long-random-secret"Stel tot slot een simpele alias in voor het model:
export MODEL_ALIAS="glm-5.2-iq3s"OpenCode gebruikt later exact deze modelalias, dus laat hem ongewijzigd gedurende de hele gids.
Je bent nu klaar om de GLM-5.2-server te starten. Voer de volgende opdracht uit in dezelfde terminal:
CUDA_VISIBLE_DEVICES=0,1,2,3 llama serve \
-hf unsloth/GLM-5.2-GGUF:UD-IQ3_S \
--alias "$MODEL_ALIAS" \
--host 0.0.0.0 \
--port 8910 \
--api-key "$LLAMA_API_KEY" \
--n-gpu-layers 999 \
--split-mode layer \
--tensor-split 1,1,1,1 \
--ctx-size 100000 \
--parallel 1 \
--flash-attn on \
--jinjaDe eerste keer dat je dit commando draait, downloadt llama.cpp de UD-IQ3_S GGUF-kwantisatie van GLM-5.2 van Hugging Face en slaat deze op in de cachemap die je eerder hebt geconfigureerd.
Het downloaden kan even duren omdat het model zeer groot is.
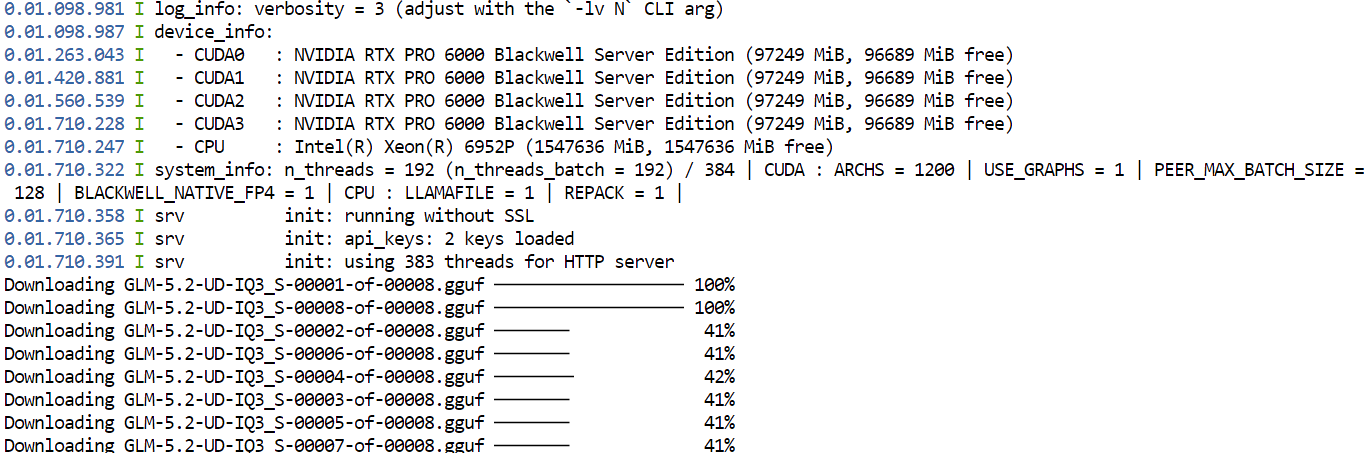
Na het downloaden laadt llama.cpp het model over alle vier GPU's. De instellingen --split-mode layer en --tensor-split 1,1,1,1 verdelen het model gelijkmatig over de beschikbare GPU's, terwijl Flash Attention helpt de performance te verbeteren.
Zodra het model succesvol is geladen, is de lokale server beschikbaar op:
http://127.0.0.1:8910
De server is beveiligd met de API-sleutel die je eerder hebt ingesteld. Laat deze terminal open terwijl je het model gebruikt, want het sluiten ervan stopt de server.
Open je RunPod Pod en ga naar het tabblad Connect. Klik onder de blootgestelde HTTP-poorten op de link die hoort bij poort 8910. Dit opent de Web UI van llama.cpp in je browser.
De URL volgt dit formaat:
https://YOUR_POD_ID-8910.proxy.runpod.netVervang YOUR_POD_ID door je echte RunPod Pod-ID als je de URL handmatig moet invoeren.
Open in de Web UI van llama.cpp Settings en ga naar General. Plak dezelfde API-sleutel die je gebruikte bij het starten van de llama.cpp-server.
Dit stelt de Web UI in staat om zijn verzoeken te authenticeren en te communiceren met de beveiligde server.
Je kunt het model nu testen met een eenvoudige codingprompt:
Write a Python function that validates an email address without external packages.
Include three pytest tests.
In deze setup genereerde GLM-5.2 gemiddeld ongeveer 41 tokens per seconde, wat een goede snelheid is voor een model van dit formaat.
De kwaliteit van het antwoord was ook sterk, met een gestructureerde implementatie met duidelijke validatieregels en testcases.
Open een tweede terminal in JupyterLab. De eerste terminal moet open blijven omdat daar de llama.cpp-server draait.
Stel in de nieuwe terminal de lokale API-URL in, hergebruik dezelfde API-sleutel en stel de modelalias in:
export BASE_URL="http://127.0.0.1:8910/v1"
export LLAMA_API_KEY="replace-this-with-the-same-server-key"
export MODEL_ALIAS="glm-5.2-iq3s"Controleer eerst of de server draait en of GLM-5.2 beschikbaar is:
curl --fail-with-body -sS \
"$BASE_URL/models" \
-H "Authorization: Bearer $LLAMA_API_KEY"Je zou de modelalias in het antwoord moeten zien:
glm-5.2-iq3sStuur daarna een testverzoek naar het OpenAI-compatibele chat completions-endpoint:
glm-5.2-iq3s
Next, send a test request to the OpenAI-compatible chat completions endpoint:
curl --fail-with-body -sS \
--connect-timeout 15 \
--max-time 600 \
-X POST "$BASE_URL/chat/completions" \
-H "Authorization: Bearer $LLAMA_API_KEY" \
-H "Content-Type: application/json" \
--data @- <<JSON
{
"model": "$MODEL_ALIAS",
"messages": [
{
"role": "system",
"content": "You are a precise senior software engineer."
},
{
"role": "user",
"content": "Write a Python function that validates an email address without external packages. Include three pytest tests."
}
],
"temperature": 0.2,
"max_tokens": 1500,
"stream": false
}
JSON
De server geeft een JSON-antwoord terug met het antwoord van het model.
In deze test produceerde GLM-5.2 een gestructureerde Python-implementatie met validatielogica en pytest-testcases met een gemiddelde genereersnelheid van ongeveer 41 tokens per seconde.
Deze lokale URL werkt alleen binnen de RunPod Pod. Om dezelfde server aan te roepen vanaf je laptop, OpenCode of een andere externe toepassing, gebruik je in plaats daarvan de RunPod-proxy-URL:
export BASE_URL="https://YOUR_POD_ID-8910.proxy.runpod.net/v1"Vervang YOUR_POD_ID door je echte RunPod Pod-ID, en blijf dezelfde API-sleutel gebruiken in de Authorization-header.
Installeer OpenCode op de computer waar je codeproject staat. Open een terminal en voer uit:
curl -fsSL https://opencode.ai/install | bashGa daarna naar je projectmap:
cd /path/to/your/projectExporteer dezelfde API-sleutel die je gebruikte bij het starten van de llama.cpp-server op RunPod:
export LLAMA_API_KEY="replace-with-the-same-server-key"OpenCode draait lokaal naast je project, terwijl GLM-5.2 op afstand blijft draaien op je RunPod Pod. Deze setup stelt OpenCode in staat om je bestanden te lezen, code te bewerken, tests te draaien en je lokale terminal te gebruiken, terwijl GLM-5.2 via de beveiligde RunPod-API het redeneren afhandelt.
Maak een bestand genaamd opencode.json in de hoofdmap van je project en voeg de volgende configuratie toe:
{
"$schema": "https://opencode.ai/config.json",
"enabled_providers": ["llama-runpod"],
"provider": {
"llama-runpod": {
"npm": "@ai-sdk/openai-compatible",
"name": "GLM-5.2 on RunPod",
"options": {
"baseURL": "https://YOUR_POD_ID-8910.proxy.runpod.net/v1",
"apiKey": "{env:LLAMA_API_KEY}",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"glm-5.2-iq3s": {
"name": "GLM-5.2 UD-IQ3_S",
"limit": {
"context": 100000,
"output": 32000
}
}
}
}
},
"model": "llama-runpod/glm-5.2-iq3s",
"small_model": "llama-runpod/glm-5.2-iq3s"
}Vervang YOUR_POD_ID door je echte RunPod Pod-ID. De URL moet overeenkomen met de RunPod-proxy-URL die je gebruikte om de Web UI van llama.cpp te openen.
Zodra het opencode.json-bestand is opgeslagen, open je een terminal in dezelfde projectmap en start je OpenCode:
opencodeVoer daarna uit:
/modelsSelecteer:
GLM-5.2 UD-IQ3_S
OpenCode is nu verbonden met je GLM-5.2-server. Het gebruikt het externe model voor redeneren, terwijl projectbestanden, terminalcommando's, codebewerkingen en testuitvoering op je eigen laptop blijven.
Begin met een eenvoudige test om te bevestigen dat OpenCode je GLM-5.2-server kan bereiken en een antwoord kan teruggeven.
Typ in OpenCode:
hey
Vraag OpenCode vervolgens om je bestaande project te inspecteren en uit te leggen:
Explain the project in 3-5 short bullet points, including its purpose, main technologies,
entry point, and how the main parts work together.
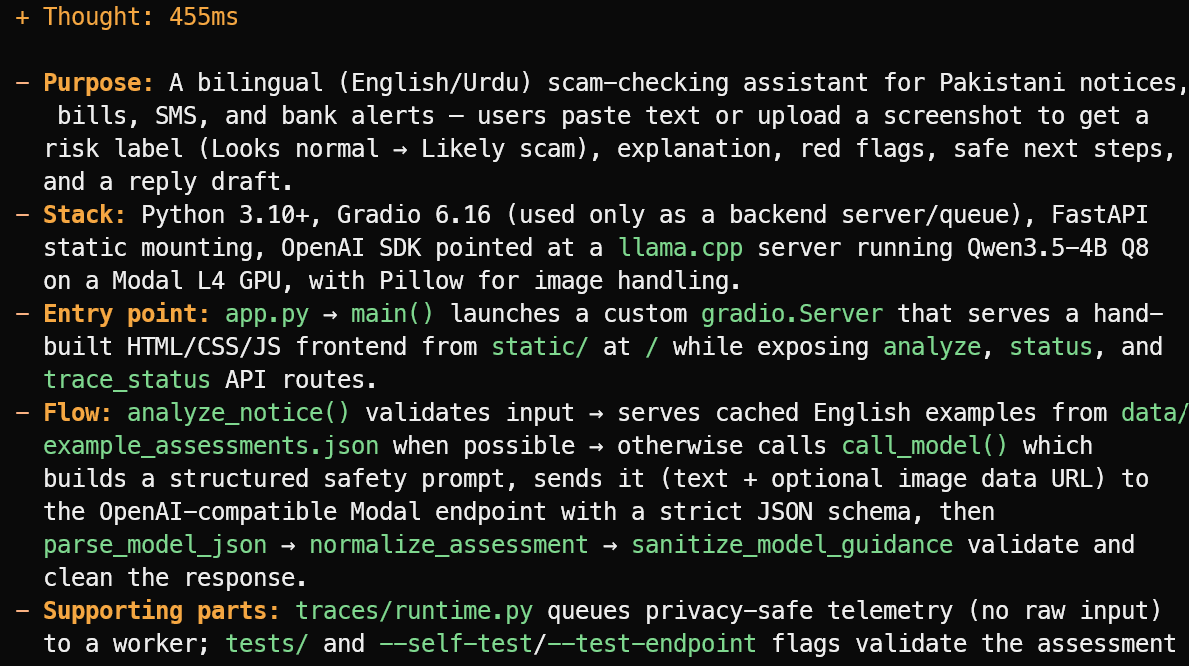
OpenCode leest de projectbestanden en geeft een beknopt overzicht in plaats van te gokken. In dit voorbeeld herkende het correct dat het project een tweetalige Engels/Urdu scam-checking-assistent is voor Pakistaanse berichten, rekeningen, sms-berichten en bankalerts.
Het legde ook de hoofdstack uit, het app.py-entrypoint, de beoordelingsflow en de ondersteunende test- en telemetrybestanden.
Prompt:
Suggest one useful new feature that fits the project's current scope.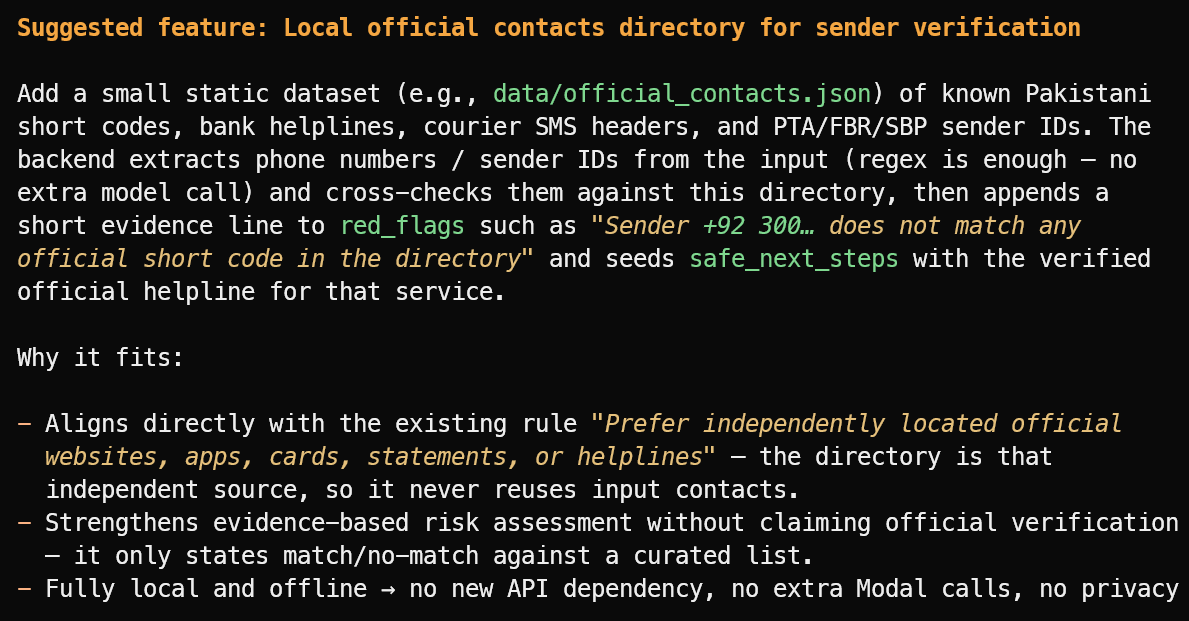
Het stelde een nuttige feature voor: een lokale directory met geverifieerde officiële afzender-ID's, bank-helpdesks, koerier-headers en publieke shortcodes.
Om OpenCode op een grotere taak te testen, maak je een nieuwe projectmap op je laptop:
mkdir ml-app
cd ml-app
opencodeGeef OpenCode daarna de volgende prompt:
Build and test a complete Python-based web UI for this machine learning application.
OpenCode maakt eerst een takenlijst en splitst het project op in behapbare stappen.
Daarna maakt het de benodigde applicatiebestanden, machinelearning-logica, Streamlit-interface, afhankelijkheden en test-suite.
Na de implementatie draait het de tests, fixt eventuele issues en geeft een duidelijke samenvatting van het voltooide project plus het commando om het te starten.
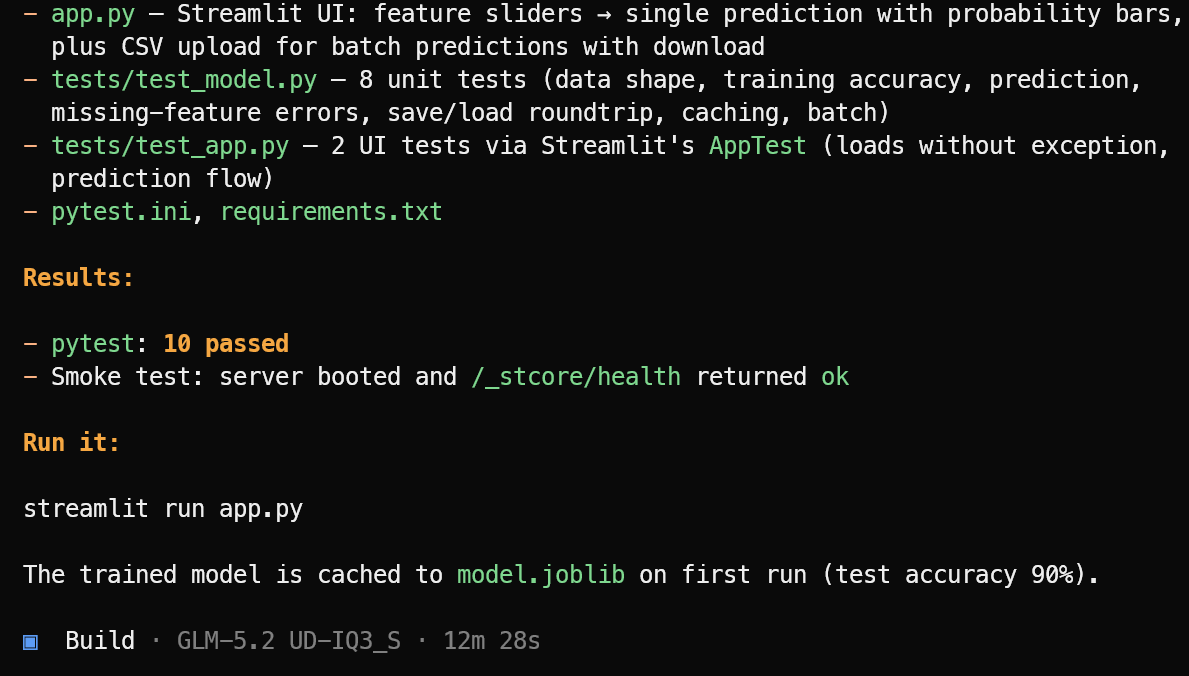
In deze test voltooide OpenCode 10 geslaagde tests en verifieerde dat de Streamlit-applicatie succesvol startte. Start de machinelearning-applicatie met:
streamlit run app.pyDe resulterende applicatie ziet er strak uit en werkt zoals verwacht.
Zelfs met de 3-bit gequantiseerde versie van GLM-5.2 was de redeneerkwaliteit sterk in deze tests.
Het begreep het bestaande project, stelde een relevante feature voor, creëerde een complete webapplicatie, gebruikte tools om bestanden te inspecteren en te wijzigen, en draaide tests om zijn werk te verifiëren.
Deze setup geeft je iets wat standaard API-providers niet bieden: je eigen privé gehoste GLM-5.2-server.
In plaats van elk verzoek te sturen naar een gedeeld modelplatform met vaste limieten, modelinstellingen en kosten per token, huur je de GPU-machine, deploy je het model zelf en beheer je de volledige servingstack.
Je kiest de modelkwantisatie, GPU-configuratie, contextvenster, serverinstellingen, API-sleutel en wie toegang heeft tot het endpoint.
Je code, prompts, projectcontext en API-antwoorden blijven binnen de infrastructuur die jij beheert: je eigen laptop en je eigen RunPod-deployment.
Ze worden niet naar een extra gehoste inferenceprovider gestuurd voor verwerking. Dit is vooral nuttig wanneer je werkt met private repositories, interne tools, gevoelige code of bedrijfsdata.
Je vermijdt ook de kosten en moeite van het zelf kopen, draaien en onderhouden van een high-end multi-GPU-server.
In plaats daarvan kun je alleen krachtige GPU's huren wanneer je ze nodig hebt, GLM-5.2 serven met llama.cpp, het endpoint beveiligen met je eigen API-sleutel en via OpenCode vanaf je laptop verbinden.
In deze gids heb je een multi-GPU RunPod-machine geconfigureerd, het vooraf gebouwde llama.cpp-pakket geïnstalleerd, het GLM-5.2 GGUF-model gedownload en geservet, en de server beschermd met een API-sleutel.
Vervolgens testte je het model via zowel de Web UI van llama.cpp als de OpenAI-compatibele cURL-API, voordat je de beveiligde RunPod-URL voor externe toegang exposeerde.
Tot slot heb je dat private model-endpoint gekoppeld aan OpenCode op je laptop. Dit creëert een praktische hybride workflow: GLM-5.2 draait op krachtige gehuurde GPU's, terwijl OpenCode binnen je lokale project blijft en bestanden kan inspecteren, code kan bewerken, tests kan draaien en je shell kan gebruiken.
Je krijgt de performance van een topmodel, de flexibiliteit van zelfhosting en veel meer controle dan met een standaard gehoste API.
Top DataCamp-cursussen
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
